
下载掌阅APP,畅读海量书库
立即打开



语块的提取,首先需要解决的是标准问题:达到什么条件可以作为一个语块来处理。其次是技术问题,包括语料库的建设、计算程序的设置等。
在英语界,语块提取的技术已经比较成熟。在标准方面,最常提及的标准是频率。Biber (2006)提出语块即在语料库中的出现频率和分布达到一定标准的语言片段,通常词块的操作定义为每百万词出现F次且有一定分布的N词组合。这个频率,Cortes(2004)、 Hyland(2008)认为每百万词出现20次,Biber(2006)认为每百万词出现40次。马广惠(2011)指出这种定义的缺陷是各人有各人的提取标准,提取频点的设定比较随意。
但是,提取语块的困难在于其心理预制性,这些绝不是频率可以解决的问题。为此,Wray (2002)提出除了频率、结构和语音形式这三个常被提及的标准外,直觉和共享知识在判断语块过程中也很重要。Schmitt (2004)采用了多方印证法选择目标词块,首先从文献中选出候选词块,然后考察它们在学术语料库中出现的频率,接着从教材中选出适量候选词块,与前面选出的词块进行比较,并从中选出部分语块请一些经验丰富的语言教师进行辨认,最终确定目标词块,由此多方印证法是保证词块识别信度和效度的不错选择。
在技术层面,语块的提取需要建立专门的语料库和计算机提取程序,目前这些方面都有了长足进展。英语中有N-Gram Phrase Extractor、 Sketch Engine、Concgram、 AntConc等诸多软件,可以满足不管有无既定中心词均可提取连续或不连续的语块的要求,检索、统计和提取都比较方便。在汉语中,姜柄圭等(2007)首先采用N-gram串频算法抽取词语串,然后删除同频子串。其次,从内部来看,语块内部词语之间的结合紧密度主要取决于它们的共现频度,可以使用互信息(MI)和对数似然(Log-likelihood)方法来判断;从外部来看,可以使用最大熵的方法(Maximum Entropy Model)来判别候选语块的独立性和边界。最后,基于语块组合规则和停用词的过滤,输出重复出现的多词语块。虽然过程复杂耗时,但是结果让人基本满意。通过分析也证明了语块是可以清晰呈现出来的凝固性强、整存整取、出现频率高并表达一定内容的一类固定的语言形式。
但是,英语语块的提取技术并不能应用到汉语中,例如《留学生毕业论文写作教程》(李英、邓淑兰,2012)曾总结的表达过渡和照应的常用语言形式“在……方面”,以及在摘要、引言、调查研究和结语中经常使用的语言形式“拟/将从……(角度/方面)探讨/分析/研究”“本文将通过……,探讨/分析……”等,显然不属于“连续的”多词序列,而英语中提取的都是连续的语块。目前汉语语块的提取基本靠语感。董艳(2010)、王文龙(2013)对对外汉语初级阶段教材中的语块的研究,李素建等(2003)和谌贻荣(2005)对语块提取的计算,都主要依靠语感。虽然熊秋平、管新潮(2011)将经典工业工程中的“工作研究”方法,应用到双语平行语料库语块提取软件的编制中,取得了不错的效果,但是这种基于计算机语言学和自然语言处理的汉语语块提取技术尚不成熟。
由于目前汉语语块的提取没有可普遍应用的软件程序,因此,本书结合英语和汉语的相关提取方法,并联系实际情况,确定了手工提取语块的标准。
首先,母语语感。李泉(1995)指出:“语感在语言学及其许多分支学科和领域中都有着重要的作用。” Wray(2002)也曾说语感(intuition)是“最不科学、却又最常用”的选取方法。由此,我们认为在语言研究过程中,不应该忽视和规避语感,而应该充分利用。
其次,频数。前文我们已经提到,Biber (2006)提出了提取频点的概念:在学术英语文本中,语块在至少 5%的文本中的出现频率大于每50万词10次。而且马广惠(2011)也指出每百万词10次、20 次或者40次使得提取频点的设定标准并不固定。鉴于此,本书结合统计的结果,将频数设为 3,即只有在一篇论文中至少出现3次的语块,才是我们需要重点分析的高频语块。
再次,篇章分布域。Hunston (2002)提出语块的互信息值如果达到了 3,则被认为具有统计学上的显著性。Cortes(2004)、 Hyland(2008)指出要能够同时在 10%的文本中出现。语块的分布域阈值通常被设定得很低,只要在2篇以上文章中出现即可。本书将篇章分布域确定为 3,即统计那些在3篇论文中同时出现的语块。
最后,综合考虑结构形式、意义、功能、使用者心理四个方面,对于不能确定的可以暂时保留,最后再进行取舍。参照Schmitt (2004)采用多方印证法选择目标词块,首先从文献中选出候选词块,然后考察它们在学术语料库中出现的频率,接着从教材中选出适量候选词块,与前面选出的词块进行比较,并从中选出部分词块请一些经验丰富的语言教师进行辨认,最终确定目标词块。因此多方印证法是保证词块识别信度和效度的不错选择。同时,有的语块还可以进一步切分为更小的语块,如“本文在前人研究的基础上对……做出了”可以视为一个较大语块,其中的“在前人研究的基础上”“对……做出了”是更小的语块。因此是提取“最小组合语块”,还是“较大组合语块”,可以根据具体的语境和语块的使用频率来进行判断。
结合已有的相关研究和上文所制定的语块提取标准,鉴于手工提取手段,制定了如下鉴别语块的具体步骤:
第一步,确定所要考察的语块语料库。
首先,选择“中国优秀硕士学位论文全文数据库”作为主要来源。我们从中选取了30篇优秀论文,其中,语言学及应用语言学专业的有10篇,汉语言文字学专业的有10篇,汉语言文学专业的有10篇。这样做的目的是扩大学科范围,使语块更具代表性。
其次,用权威语言类期刊论文作为补充和参照。我们共选取了9篇期刊论文。《中国语文》3篇:《吴语名词性短语的指称特点——以富阳话为例》《再说“差一点”》《释古越语“巿(姊)”及相关音韵现象——兼论‹颜氏家训›“南染吴越”的词汇表现》;《世界汉语教学》3篇:《论语体语法的基本原理、单位层级和语体系统》《现代汉语的非论元性句法成分》《提高语块意识的教学对汉语第二语言学习者口语产出的影响》;《外国语》3篇:《人际语用学视角下人际关系管理的人情原则》《徐志摩诗歌创作与翻译的互动生成》《‹系统功能语言学的杂合性研究:语法、语篇和话语语境›(2016)评介》。
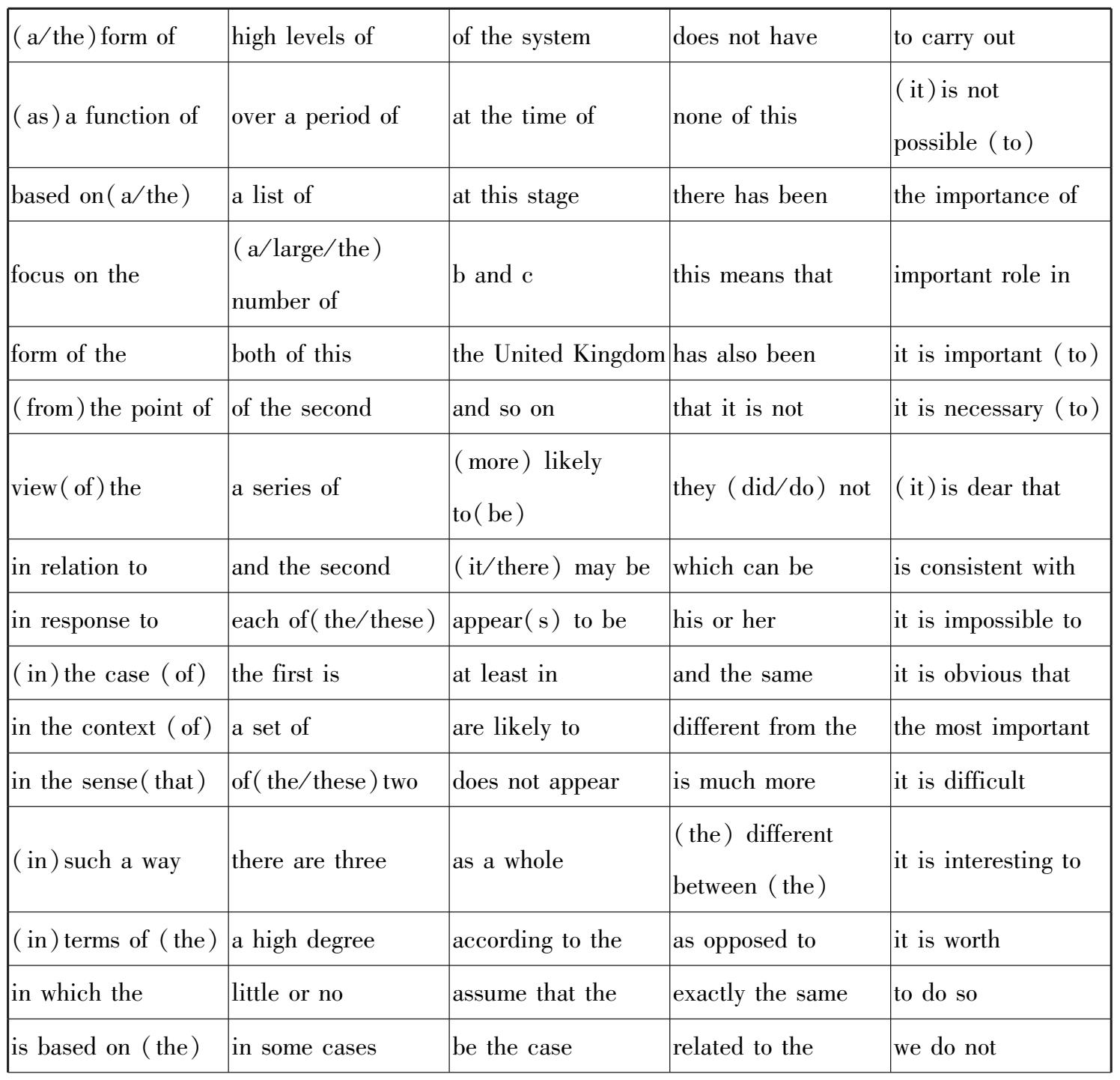
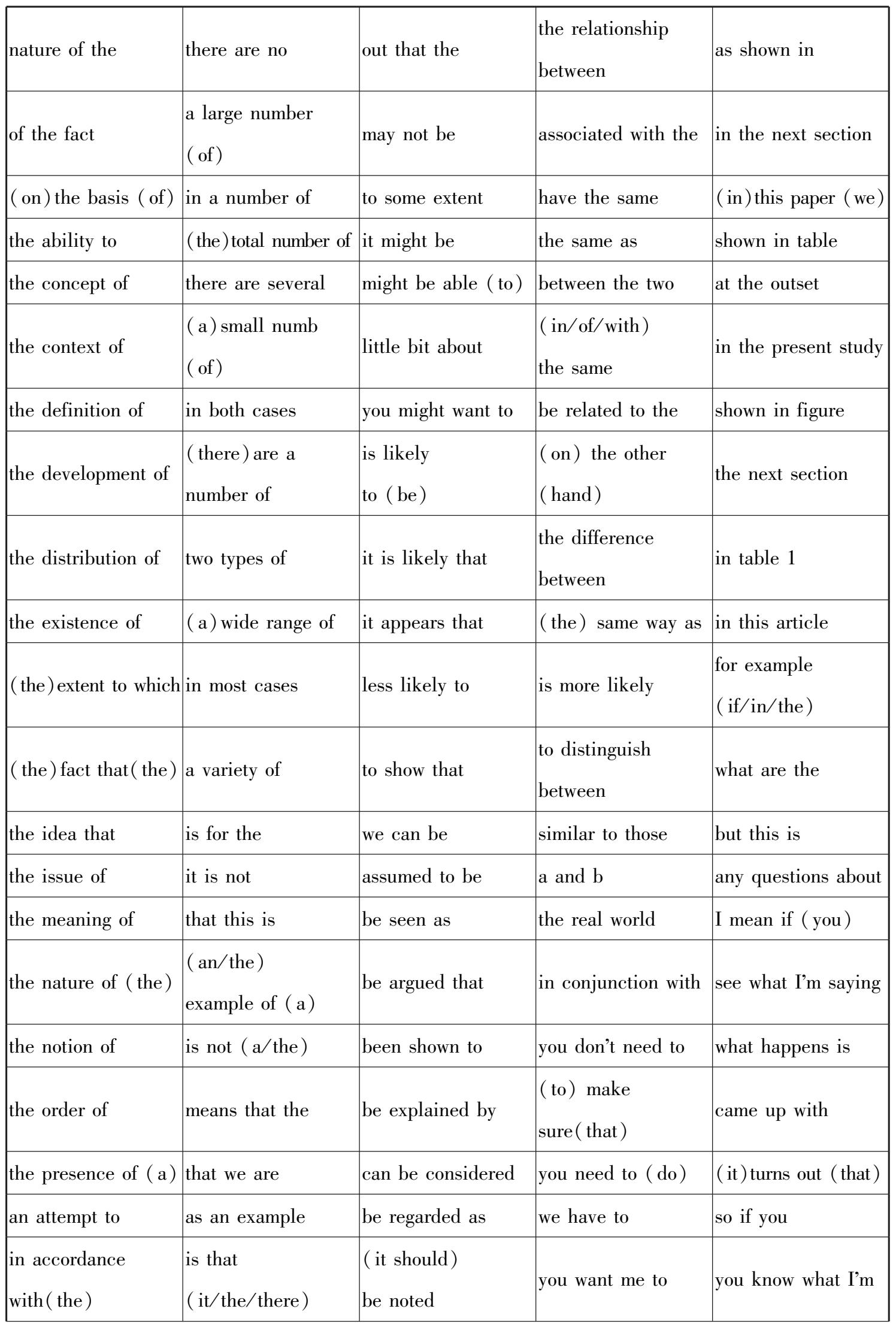
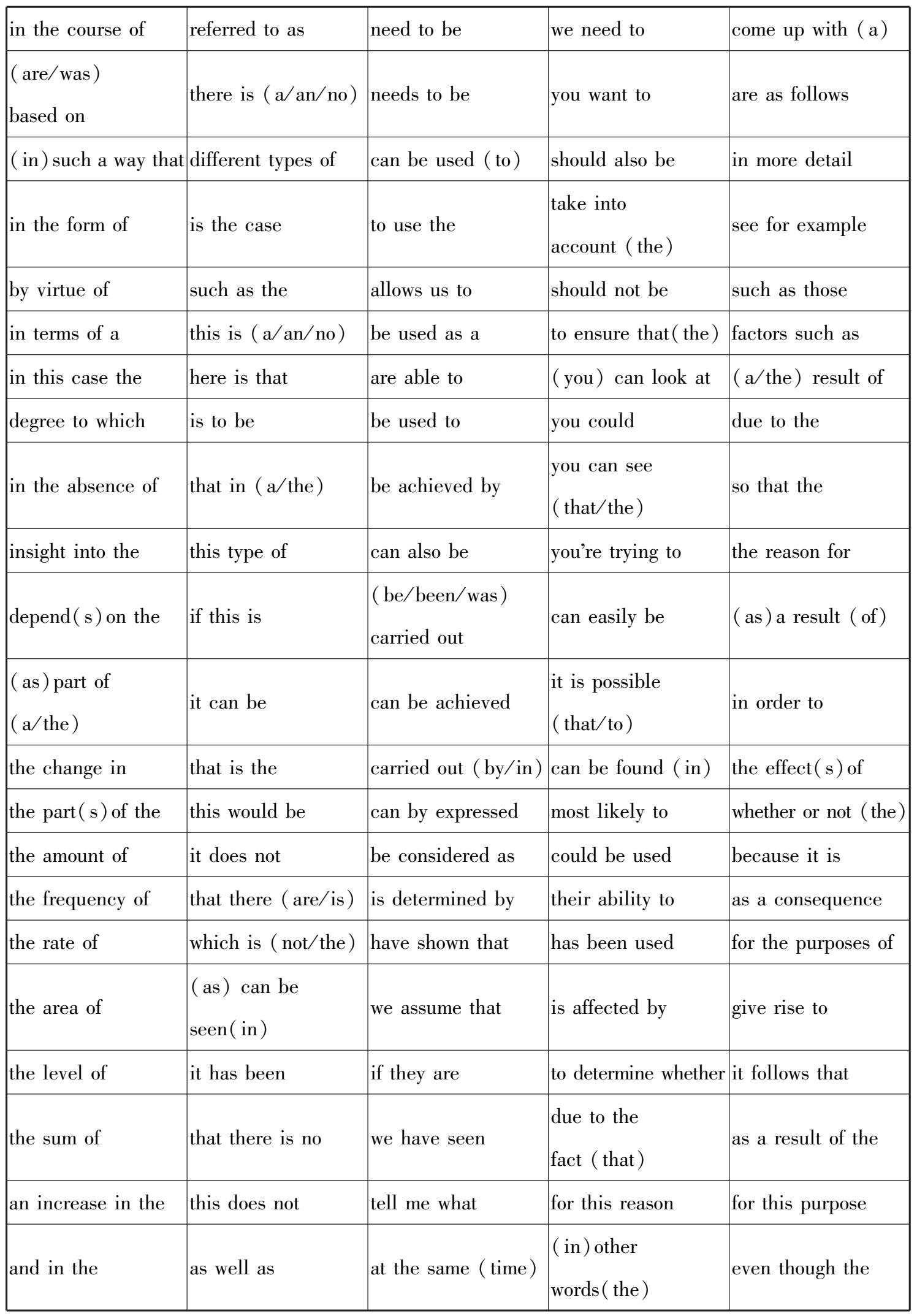
最后,使用英语学术语块表做参考。胡富茂、张克亮(2018)指出英汉语块的完全对应关系达到了92.65%。所以学术英语中的语块,尤其是核心语块,同样可以作为学术汉语语块的有效补充。我们使用的是Simpson-Vlach和Ellis(2010)创建的英语学术语块表(Academic Formulas List,AFL),该表包括核心语块和常见语块,如表2-1 所示。
表2-1 英语学术语块表(AFL)
(续上表)
(续上表)
第二步,运用制定的原则和标准,对每一篇论文中的语块项目进行提取。由于成语、俗语、歇后语这样的语块,其出现受论文内容影响较大,很少同时在几篇论文中出现,因此不作为本书的提取对象。为计数方便,我们区分典型和变式,如把“某某指出”和“某某认为”处理为语块“某某指出/认为”的两个变式,“因为……,所以……”和“……,所以……”则记为“(因为……)所以”。在形式上统一使用“……”表示省略,“/”表示“或者”,如“第……部分/章总结了/概括了/归纳了/界定了/分析了”。
第三步,依据学术语块语料库,将语块的关键词逐一输入硕士学位论文中进行检索,然后从中分析、统计并提取出含有关键词的高频语块,形成学位论文通用语块表和期刊论文通用语块表。
第四步,与议论文常用语块相比较,最终确定适合在论文写作教学阶段作为教学对象的汉语通用学术语块表。议论文写作是论文写作的预备阶段,因此,议论文教学中已掌握的内容,不需要作为论文写作教学阶段的教学对象,所以我们选择了5部当前通行的高级写作教材,提取其中常见的议论文常用语块,与学位论文、期刊论文中搜集的语块相比较,最终确定汉语通用学术语块表。