
下载掌阅APP,畅读海量书库
立即打开



理解人类的听觉系统一直被视为设计机器听觉的主要策略。与视觉研究相似,人类对听觉机制的探索也源远流长,可以追溯至17世纪,并在过去几个世纪里取得了令人赞叹的进展。制造出兼具视听功能的机器的想法可以追溯到19世纪中叶,距今已有超过一个世纪的历史。由于计算能力的限制,直到最近几十年真正实现这一目标才变得可能。正如计算机行业中所说的那样,实现机器听觉目前看似只是一个简单的编程问题。然而,事实并非如此。人们对于耳朵进行声音分析的理解还远远不够深入,在揭示人类大脑庞大的听觉处理能力这一领域,仍有大量工作有待完成。只有对人类听觉机制有了更全面的理解,才能将其抽象概括,为发展机器听觉系统提供更坚实的理论基础。
本章将深入探讨听觉智能感知的基础理论和关键技术。4.1节将介绍听觉智能感知的基本概念和特性,包括听觉生理学原理、听觉中的关键问题,以及机器听觉的基本原理。通过这些基础内容的学习,读者将理解听觉感知的本质特征。
4.2节将详细讲解听觉感知的关键技术。首先介绍听觉感知的基本处理系统架构,包括声音信号的采集、处理和分析流程;然后深入探讨语音识别技术的原理和方法。这些内容将帮助读者掌握听觉智能感知的核心技术实现。
4.3节将探讨听觉智能感知的实际应用。通过具体的应用案例,读者将了解听觉感知技术在各个领域中的实际运用,加深对听觉智能感知系统的整体认识。
通过本章的学习,读者将系统掌握听觉智能感知的基本原理和核心技术,了解从听觉生理到智能识别的完整技术链条。
我们所介绍的关于机器听觉的方法是通过机器模型来描述人类的听觉,听觉研究领域的很多人对此采取了不同的方法。听觉心理学家和生理学家积累了大量的实验数据,以及针对这些数据的各种理论、假设、描述和解释。本节试图构建这些知识,总结一些建模和解释的历史,并将其与机器模型联系起来。“关于人类听觉系统的智慧”的真正考验,是在模型复制听觉的重要特征和功能方面,不仅是在受控实验中,而且是在处理真实世界声音混合的成功应用中。Schouten特别关注音高感知问题,这是听觉中的几个关键问题之一。音高可能是导致机器听觉采用听觉图像方法的一个最重要的问题。本章将介绍人类听觉中的几个关键方面。
关于人类听觉的大部分知识来自心理物理实验和动物生理学实验。猫、沙鼠、豚鼠、雪貂和其他实验动物已经被广泛研究,我们有理由相信,从它们身上学到的知识可以很好地应用于其他哺乳动物。
听觉诱发电位是耳蜗内或耳蜗附近电极、各种神经或大脑结构拾取的电信号,其早期研究在听觉理论中发挥了重要作用 [ 1 ] 。当人们发现听神经附近的诱发电位可以重现可理解的语音时,神经不能携带高于几百赫兹频率的想法必须加以修正。在猫的听觉诱发电位中,高达4kHz的音调被复制出来。
在对猫的听觉诱发电位研究中还有一个重大突破,它能够从听神经的单纤维记录动作电位和离散的放电事件,以响应各种水平的刺激。研究人员发现,从耳蜗传递到大脑的不仅是简单的声音信号,其中还包含细微的时间结构细节。这些细节信息可以通过刺激周围时间直方图来可视化展示,直方图反映了神经元放电发生的时间分布,近似展现了神经元对重复声音刺激的响应概率随时间的变化特征。
1971年,罗德利用松鼠猴开发了一种观察耳蜗基底膜机械反应的新技术。这项技术让他能够观测到耳蜗在很低声压级的声音下的机械反应行为。在这些实验中,首次观察到了健康耳蜗在低强度声刺激下表现出的非线性压缩行为,而早期的力学实验所观察到的通常是受损耳蜗在被动状态下的反应,或者是高强度声刺激下,健康耳蜗的反应呈现出被动线性特征。然而,在罗德对健康耳蜗的大动态范围进行观察后的很长一段时间里,机械调谐的锐度(似乎很宽)和神经调谐的锐度(似乎更尖锐)之间仍然存在着脱节。在接下来的几十年里,机械实验得到了改进,并用新的技术进行了复制,脱节的问题得到了解决:当以相同的方式绘制等响应曲线或频率-阈值曲线时,通过机械测量和神经测量所得到的曲线呈现出陡峭的谐振峰,它们在响应精度和健康状态上也是基本等同的。用这种方法测量的机械和神经响应,比固定强度下的响应与频率的非锐化图要尖锐得多。在线性系统中,这样的测量是等效的,它们的曲线同样陡峭。因此,神经频率-阈值曲线的锐度在很大程度上被理解为耳蜗非线性和调谐曲线测量方式的副产品,并且与以不同方式测量的不太尖锐的曲线没有冲突。
对动物听觉神经系统众多不同结构中的单个单位和诱发电位记录的研究增加了大量数据,但得到的并不都是清晰的整体图像。一些清晰的结果来自于特殊的动物,而且不一定是哺乳动物。例如,谷仓猫头鹰可以在完全黑暗的环境中从空中俯冲下来捕捉奔跑的老鼠,它仅通过聆听就可以在视顶盖中记录听觉/视觉空间相关的神经活动图,这些活动模式是由早于视顶盖的听觉加工通路解码双耳时间和强度差信号后,投射到视顶盖并形成的。
近几十年来,研究耳蜗产生的耳声发射和从耳朵发出的实际声音也很有价值,它可以评估人类耳蜗的功能和模型的合理性,如图4.1所示,耳蜗位于内耳的最内侧,其蜗旋管状结构中包含着基底膜和有机鞘等关键的听觉感受器。当声波通过外耳、中耳的传递而达到内耳时,会激发基底膜及其上的耳毛细胞产生机械振动。这种微小的机械振动不仅会引起听觉神经纤维放电,传递声音信息到大脑,同时也会在一定程度上引起耳蜗内部液体的反向波动,从而使整个耳蜗结构发出极细微的声辐射,被称为“耳声发射”。
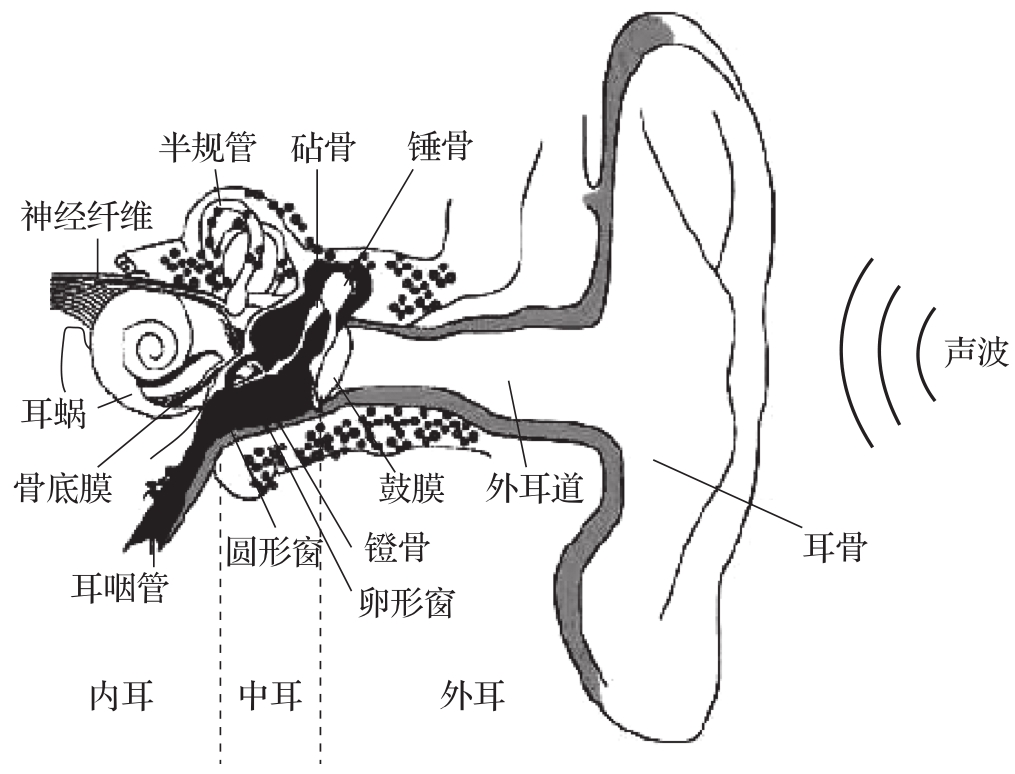
图4.1 人耳构造图
研究人员可以利用高灵敏度的声学测量设备,从外耳道捕捉和分析这些极微弱的耳声发射信号,从而评估内耳特别是耳蜗的功能状态,检验相关听觉理论模型的合理性和准确性。耳声发射测试已成为了一种重要的临床听力检查手段,在听力医学及相关基础研究领域具有广泛的应用价值。
许多关于声音和听觉的介绍会讲述声音,或者音调、音高、响度、音色或其他属性。很多时候,声音可以简单理解为正弦波,在这种情况下,可以说感知的音高是由频率决定的,而对于任何固定频率,响度是由幅度或功率构成的 [ 2 ] 。这些关系看起来很简单,但对于不是正弦波的声音(这意味着基本上所有的声音)情况要复杂得多。
为什么不同频率的声音有不同的响度与声功率的关系曲线?为什么对于大带宽,噪声频带的响度如此依赖于带宽,而在带宽较小时,则相对独立于带宽?为了回答这些问题,心理和物理学实验提供了多样而复杂的数据,如何解释感知响度与物理刺激参数之间的关系一直是听觉科学中一个长期存在的重要问题。
对于周期性的人声和音乐声,感知的音调通常与压力波形的重复频率相对应;100Hz正弦波的螺距几乎与任何波形每秒重复100次的螺距相同。然而,对于某些波形,即使没有200Hz的周期性,螺距也将接近200Hz。例如,与100Hz的奇数谐波之和相对应的交替正脉冲和负脉冲,通常会由受试者与接近200Hz的脉冲序列相匹配,尤其是在最低频率被滤除或被噪声掩盖的情况下。在过去的几个世纪里,试图描述这些奇怪刺激的物理声学属性和感知音高之间的微妙联系推动了听力方面的许多进步。
音色通常被定义为在相同响度、音调和持续时间的声音下,人耳感知到的声音特征或质感上的差异。音量除了作为响度的同义词,其他旧维度没有保存下来。
音乐和谐与不和谐的研究也是一个激发听觉研究和进步的关键问题。古希腊人早已认识到,弦长或管长的比例关系与产生辅音的频率有着密切联系。随着时间的推移,这些观察和理论在音乐理论的发展中得到了进一步的阐述和深化。与此同时,听力科学领域一直在努力探索这些现象背后的解释。如今,借助于能够生成听觉图像的现代听觉模型,得以洞察和谐与不和谐如何在大脑中得以体现。这些发现不仅将这一问题从生理学领域扩展到了模式识别领域,还为我们提供了更深层次的理解。
言语交流可能是人类正常生活中最重要的一种声音。对语音感知的描述和理解是工业界和学术界一百多年来的一个关键问题,最初是由电话业务的需求驱动的。
人类听觉的一个最重要的用途是了解周围发生的事情。正如Wenzel所说,“耳朵的功能是指向眼睛”。这一概念与在谷仓猫头鹰顶盖中发现已登记的听觉和视觉空间图有关,并得到听觉定位灵敏度和最佳视觉区域宽度之间的多物种相关性的支持。因此,对双耳听觉的研究是理解听觉工作原理的一个重要部分。
人类将声音解析为听觉流的自然倾向是一种更高层次的功能,它是音乐感知和在干扰声音中跟踪语音的能力的基础。“鸡尾酒会问题”指的是一个人从混合的语音和音乐源中提取有用声音的能力,有时甚至一次处理多个声音流。与分析复杂视觉场景的能力类似,这种能力也被称为听觉场景分析。
除了人类听觉的这些心理声学方面,听觉的研究和进展也受到听觉神经生理学发现的推动,尤其是在哺乳动物中,但也在鸟类、爬行动物、鱼类和昆虫中。例如,猫听神经中单个神经元的动作电位记录提供了对耳朵功能的早期关键洞察,并提供了数据来限制关于如何解释听觉的许多特性理论。
大脑处理声音的区域被认为是有组织的,就像视觉区域一样,分为一个what路径和一个where路径。what路径处理声音的分类,例如不同元音或乐器的分类,而where路径处理空间中的位置和方向。这些路径的相互作用是复杂的,因为它们在更高的皮层水平上并不完全分开。从这种生理组织的角度理解心身效应是听觉研究的一个关键问题。
线性和非线性的概念出现在许多领域。神经元的行为很容易被认为是非线性的。非线性在听觉过程中的机械部分也很重要,这一观点很令人惊讶,尽管它在一个多世纪以来一直是讨论的焦点。
以上主题都需要一定程度的熟悉和理解,以了解它们如何激励和约束机器听觉系统的设计。面向该领域提出简单的机器模型,从中产生符合人类和动物听觉的所有复杂实验细节的行为。
我们已经拥有可以像人类一样听到声音的机器,我们希望这些机器能够轻松区分语音、音乐和背景噪声,提取语音和音乐部分进行特殊处理,知道声音来自哪个方向,学习哪些噪声是典型的,哪些是值得注意的。无论是在工厂、音乐表演还是电话交谈中,这些机器应该能够实时聆听并做出反应,在听到值得注意的事件时采取适当的行动,参与正在进行的活动。
虽然大多数的声音分析工作都应用于语音和音乐中,但更普遍的现场机器听觉值得关注。与机器视觉的多样性和活跃性相比,机器听觉领域仍处于初级阶段,尽管已掌握了多样性听觉应用所需的大部分技术。
在机器听觉中,我们关注实用的系统结构和真实环境中真实声音混合的实际应用 [ 3 ] 。希望避免多年来视觉领域在工业界的“机器视觉”和学术界的“计算机视觉”之间出现的分裂,而通过专注于更一般的声音处理,将语音、音乐和听觉研究人员更紧密地联系在一起,这为合作提供了明确的机会。
在实用性方面,假设机器听觉系统在像人类一样听到声音时工作得最好,因为它们模拟了人类的听觉装置,并且它们根据事物“听起来像什么”创建内部表示,而不是直接分析发声结构(如声带)的表示。假设输入的声音是杂乱无章的,因此避免使用针对一种声音类型或一个声源进行优化的表示。人们希望机器听觉能像机器视觉和机器学习一样成为一流的学术和工业领域。
图4.2展示了意大利理工学院(IIT)开发的双耳人形机器人iCub。该机器人头部装有两个类似于人类外耳的语音传感器,用于模拟人类双耳听觉系统。

图4.2 意大利IIT开发的双耳人形机器人iCub
iCub机器人的双耳传感器能够借助时间差和强度差原理,精确定位声源方位并分离出不同声源,实现对复杂声场环境中的目标声音的分离和跟踪。此外,其语音处理系统还具备语音识别和理解能力,能够根据语义内容与人类进行交互对话。
作为一个人形机器人平台,iCub不仅在听觉上追求对人类的模拟,在视觉、运动控制等多个感知系统上也力求最大限度地模拟人类。通过将先进的计算机视觉、语音识别、运动规划等技术与人性化设计相结合,iCub展现了机器视听觉系统向真正的人工智能系统迈进的雄心和潜力。
作为基线方法使用的机器听觉系统结构在一些成功的机器视觉应用程序上应用,并且已经在一些声音分析应用程序中运行良好。这样一个系统由4个主要模块组成 [ 4 ] :
1.外围分析仪
所有机器应用中常见的是声音分析前端,它模拟了耳蜗,将声音分离为一组重叠带通通道,压缩声音动态范围,并产生半波整流表示,其在所有信道波形中保持功率和精细时间结构。
2.一个或多个听觉图像发生器
这一阶段,系统将精细的时间结构解调成更缓慢变化的表示形式,即在听觉中脑中发现并投射到听觉皮层的二维(2D)运动图像图。例如,它生成一个稳定的听觉图像或相关图,根据利克利德的音高感知双重理论体现联合频谱和时间细节,或根据杰弗里斯的双耳定位位置理论体现双耳相关图。
3.特征提取模块
在机器视觉系统中,该阶段获取运动(听觉)图像作为输入,并提取各种局部和全局(或多尺度)特征,这些特征将与以下可训练分类器配合使用。
4.一个可训练的分类器或决策模块
对于所选择的应用程序,应用适当的机器学习技术来学习从先前阶段提取的特征到应用程序所需决策类型的映射。该模块可以像单层感知器一样在一个步骤中操作,也可以使用或学习多层内部结构。
前两个模块旨在尊重人类的听觉本质,其目标是产生对声音流“听起来是什么”的表示形式,同时将机器听觉问题转化为可供机器处理的计算形式,类似于机器视觉将视觉问题转化为可解决的计算问题一样。无论这种转化是否能够完全解决问题,都可以有效借鉴和利用后两个模块中行之有效的技术成果,并为各阶段留有充分的改进空间。
声音和图像技术之间可以共享的重要概念包括稀疏表示、压缩、多尺度分析、三维(3D)图像空间运动分析和关键点检测等。例如,该表示可能早在第一模块的输出时就被稀疏化,其中带通滤波声音的每个半波波形驼峰可以由指示驼峰的时间和大小的离散事件代替。
2008年,电影《钢铁侠》中托尼·斯塔克有一个虚拟管家JARVIS,JARVIS最初是一个计算机界面,最终升级为运行业务并提供全球安全性的人工智能系统。JARVIS让人类眼睛和耳朵看到和听到了语音识别技术固有的可能性,虽然我们可能还没有完全做到这一点,但各种设备正在以多种方式进步。语音识别技术允许以多种语言免提控制智能手机、扬声器甚至车辆。这是一项几十年来一直梦想努力达到的进步,目标是让人们的生活更简单、更安全。本小节将简要介绍语音识别技术的历史、工作原理、一些使用它的设备,以及对未来发展的展望。
1.语音识别技术发展史
语音识别技术很有价值,因为它可以节省消费者和公司的时间和金钱。台式计算机的平均打字速度约为40字/min,而在智能手机和移动设备上打字时,速度还会有所下降,但通过语言输入,每分钟可以说125~150个字。因此,语音识别可以帮助人们更快地完成所有事情如创建文档,与自动化客户服务代理交谈。语音识别技术的实质是使用自然语言来触发动作。现代语音技术始于20世纪50年代,并在几十年间迅猛发展 [ 5 ] :
20世纪50年代,贝尔实验室开发了“Audrey”,这是一个能够识别通过单个声音说出数字1~9的系统;20世纪60年代,IBM公司推出了一款名为“Shoebox”的设备,可以识别和区分16个英语口语单词;20世纪70年代,卡内基梅隆大学的“Harpy”系统可以理解超过1000个单词;20世纪90年代,个人计算机的出现带来了更快的处理器,并为听写技术打开了大门,贝尔再次使用拨入式交互式语音识别系统;21世纪初,语音识别的准确率接近80%,Google Voice的出现让数百万用户可以使用该技术,并允许谷歌公司收集有价值的数据;21世纪10年代,苹果公司推出Siri,亚马逊公司推出Alexa与谷歌公司竞争。
随着技术的不断演进,开发人员已经朝着使机器能够理解和响应人们越来越多口头命令的目标迈进。如果没有早期开拓者铺平道路,如今领先的语音识别系统(谷歌助手、Alexa和Siri)不会有如此伟大的成就。
得益于云处理等新技术的集成以及语音数据收集带来的持续改进,这些语音系统不断提高其“听”和理解更广泛的词语、语言和口音的能力。
2.语音识别技术工作原理
随着物联网技术的不断发展,智能汽车、智能家电和语音助手等新兴技术已经出现在人们的日常生活中,那么语音识别技术是如何工作的呢?
即使是现在,语音识别技术也非常复杂。以孩子学习语言为例,从第一天起,他们就会听到周围都在使用的词语。孩子会吸收各种语言提示:语调、句法和发音。他们大脑的任务是根据周围人使用语言的方式识别复杂的模式和联系。语音识别开发人员必须自己构建类似的,语言学习机制,因为有成千上万种语言、口音和方言需要考虑。
但这并没有阻止语音识别技术的发展。在2020年初,谷歌公司的研究人员终于能够在广泛的语言理解任务上击败人类,他们的更新模型现在在标记句子和找到问题的正确答案方面比人类表现得更好。语音识别技术工作的基本步骤如下 [ 6 ] :
1)传声器将人声的振动传输成波状电信号。
2)该信号依次由系统硬件(例如计算机的声卡)转换为数字信号。
3)语音识别软件分析数字信号以记录音素,音素是区分特定语言中一个词与另一个词的声音单位。
4)将其重构为词语。
程序要选择正确的词语,必须依赖上下文提示,通过三元组分析完成。该方法依赖于频繁三词集群的数据库,其中分配了任意两个词后跟给定第三个词的概率。
例如手机输入键盘上的预测文本,当你输入“How are”时,你的手机会提示“you?”,而且使用它的次数越多,它就越了解你的倾向并会给出常用短语。
语音识别软件的工作原理是将语音记录的音频分解成单独的声音,分析每个声音,使用算法找到最适合该语音的词语,然后将这些声音转录成文本。
3.语音识别技术应用场景
语音识别技术在21世纪初取得了突飞猛进的发展,并且已经真正开始立足于人们的生活中,下面列举了一些语音识别技术的应用场景 [ 7 ] 。
(1)苹果公司的Siri苹果公司的Siri于2011年首次亮相后成为第一个流行的语音助手,如图4.3所示。从那时起,它已集成在所有iPhone、iPad、Apple Watch、HomePod、Mac计算机和Apple TV上。Siri甚至被用作CarPlay信息娱乐系统、无线AirPod耳塞和HomePod Mini的关键用户界面。尽管苹果在Siri方面取得了很大的领先优势,但许多用户对其无法正确理解和解释语音命令表示失望。如果要求Siri代替自己发送短信或拨打电话,它可以轻松完成,然而在与第三方应用程序交互方面,与竞争对手相比,Siri的功能稍逊一筹。但现在,iPhone用户可以说“嘿Siri,我想打车去机场”或“嘿Siri,给我订一辆车”,Siri会打开手机上的任何乘车服务应用程序并预订旅行。

图4.3 苹果Siri语音助手
专注于系统处理后续问题、语言翻译以及将Siri的声音改造成更人性化声音的能力,有助于改善语音助手的用户体验。截至2021年,苹果公司在按国家/地区划分的可用性方面强于其竞争对手,Siri可在30多个国家/地区和21种语言中使用,在某些情况下,还可以使用多种不同的方言。
(2)亚马逊公司的Alexa亚马逊公司于2014年向全球发布了Alexa(见图4.4) 和Echo,开启了智能扬声器的时代。Alexa现在安装在Echo、Echo Show(语音控制平板电脑)、Echo Spot(语音控制闹钟)和Echo Buds耳机(亚马逊版的AirPods)中。

图4.4 亚马逊Alexa语音助手
与苹果公司相比,亚马逊公司一直认为拥有最多“技能”的语音助手(在其Echo助手设备上的语音应用程序)将获得忠实的追随者,即使它有时会犯错误并需要花费更多精力去使用。尽管一些用户认为Alexa的单词识别率落后于其他语音平台,但Alexa会随着时间的推移适应用户的声音,解决它与用户的特定口音或方言有关的很多问题。在技能方面,亚马逊的Alexa Skills Kit(ASK)可能是推动Alexa成为真正平台的原因。ASK允许第三方开发人员创建应用程序并利用Alexa的强大功能,而无须原生支持。
Alexa在与智能家居设备(如摄像头、门锁、娱乐系统、照明和恒温器)的集成方面处于领先地位,无论是坐在沙发上还是在旅途中,用户都可以完全控制自己的家。借助亚马逊公司的Smart Home Skill API,用户可以从数以千万计的支持Alexa的端点控制他们连接的设备。
当要求Siri将某样物品添加到购物车时,它会照做。然而,Alexa则会更加人性化,用户可以毫不费力地从亚马逊订购数百万种产品,这也是Alexa超越其竞争对手的一种自然而独特的能力。
(3)车载语音识别 声控设备和数字语音助手不仅仅是为了让事情变得更简单,在车载语音识别等方面也涉及安全问题。
苹果、谷歌和Nuance等公司已经彻底重塑了驾驶员的车辆体验——旨在消除开车时低头看手机的干扰,让驾驶员能够将注意力集中在道路上。用户可以告诉汽车需要给谁打电话或导航到哪家餐厅,而不是在开车时发短信;无须滚动Apple Music,只须让Siri为查找并播放自己喜欢的音乐即可;如果车内燃油不足,车载语音系统不仅可以提醒你需要加油,还可以指出最近的加油站并询问你是否对特定品牌有偏好,它也可能会警告你想去的加油站太远,剩余燃料无法到达。
在安全方面,有一个重要的警告需要注意。英国交通研究实验室(Transport Research Laboratory,TRL)发布的一份报告显示,与触摸屏系统相比,使用语音激活系统技术时驾驶员的分心程度要低得多。但是,它建议要进行进一步的研究,使语音指令成为未来车内控制最安全的方法,因为最有效的安全预防措施是完全消除干扰,这就需要现场数据收集的作用。公司需要在车辆中进行交流的术语和短语的精确和全面的数据。现场数据收集在特定选择的物理位置或环境中进行,而不是远程进行。这些数据是通过结构松散的场景收集的,其中包括文化、教育、方言和社会环境等元素,这些元素可能会影响用户表达请求的方式。
(4)声控视频游戏 语音识别技术也在游戏行业取得长足进步。声控视频游戏已经开始从经典的主机和计算机扩展到声控手机游戏和应用程序。
创建视频游戏非常困难,需要发展多年才能充实情节、游戏玩法、角色发展、可定制的装备、世界等,游戏还必须能够根据每个玩家的行为进行更改和调整。现在,想象一下通过语音识别技术为游戏添加另一个玩法,许多支持这一想法的公司目的是让视觉或身体受损的玩家更容易玩游戏,并允许玩家通过另一种方式来进一步沉浸在游戏中。
语音控制也可能会缩短初学者的学习曲线。玩家可以立即开始交谈,展望未来。文本转语音(Text to Speech,TTS)、合成语音和生成神经网络将帮助开发人员创建口语和动态对话。
4.语音识别技术发展前景
语音识别的未来会怎样?以下是可以期待的几个重要领域。
(1)移动应用语音集成 将语音技术集成到移动应用程序中已成为一种热门趋势,该趋势还将继续延续,因为语音是一种自然用户界面(Natural User Interface,NUI) [ 8 ] 。语音驱动的应用程序增加了功能并使用户免于复杂的导航,用户可以更轻松地浏览应用程序——即使不知道要查找项目的确切名称或在应用程序菜单中的何处找到它。语音集成将很快成为用户期望的标准。
(2)个性化体验 语音助手也将继续提供更加个性化的体验,因为它们能够更好地区分不同的声音。例如,Google Home不仅可以支持多达6个用户账户,还可以检测独特的声音,从而允许用户自定义许多功能。用户可以询问“今天我的行程有哪些”或“我今天都需要做什么”,助手将口述通勤时间、天气和量身定制的新闻信息。它还包括昵称、工作地点、付款信息和关联账户(如Google Play、Spotify和Netflix)等功能。
同样,对于使用Alexa的人,说“学习我的声音”将允许您创建单独的语音配置文件,以便它可以检测谁在说话。
(3)智能显示器 虽然智能音箱很受大众欢迎,但人们现在真正追求的是智能显示器,本质上是一个带有触摸屏的智能音箱。与2023年相比,智能显示器的销量增至950万台,增长了21%而同期基础智能音箱的销量下降了3%,而且这种趋势很可能会持续下去。例如,俄罗斯Sber门户或中国智能屏幕小度等智能显示器已经配备了多种人工智能功能,包括远场语音交互、面部识别、手势控制和眼睛手势检测。
John Treichler的“探索性数字信号处理器(Digital Signal Processor,DSP)”专栏提到了许多处于长期发展轨迹中的信号处理领域,与声音相关的包括超声、地震勘探、电话、音乐记录和压缩、装有计算机的汽车、远程呈现、语音合成和识别,以及声呐目标检测和分类 [ 9 ] 。设想将Treichler提到的远程呈现、装有计算机的汽车、语音和音乐领域整合到一个可以与其居住者交谈的“智能环境”系统中,由于此时设计和构建如此全面的系统对于任何人来说都可能是一项艰巨的任务,因此通过扩散原始助听器来处理它可能是有意义的,这些助听器可以安装在汽车、家庭、会议室和便携式计算机中,允许添加应用程序以利用这些听力前端,而无须重新发明或重新部署它们。显然,这样的前端需要能够很好地处理语音、音乐和各种混合环境声音,因此需要采用基于听觉的方法。在一些领域中,基于听觉模型的前端已被利用,并有望取得进一步进展。
除了这些实时和交互式的应用之外,在分析存储的声音媒体方面还有很多应用。现有计算机目前几乎不知道它们存储和服务的声音代表什么,虽然存储了很多声音,包括一些语音数据库,但大部分是未经分析的视频音轨。近年来,基于内容的图像和视频分析领域稳步发展,但基于内容的音轨分析却有些滞后。基于视频内容进行分析的系统对于机器听觉来说是一个很容易实现的目标,因为视频不仅包含音频信息,还有与之相关的视觉信息,这些相互补充的多模态信息有助于提高声音理解和分析的准确性。
通过融合音视频的多模态信息,机器听觉系统能更好地从视频中提取语义上的上下文线索,结合画面场景、人物动作等视觉线索,对音频内容进行更精准的理解和分析,例如语音识别、音乐流派识别、环境音识别等。
因此,基于视频内容的声音分析是机器听觉一个重要且相对容易实现的应用场景,足以展现多模态感知融合的优势所在。当前这一领域的研究和应用都有了长足的进步。
1.语音检索
机器听觉领域首次报道的大规模应用是一个基于Grangier和Bengio描述的帕米尔图像搜索系统的声音搜索系统 [ 10 ] 。这是一种“文本查询中的文档排序和检索”形式,用于图像和声音文档。
虽然目前人们在语音和音乐识别与索引方面付出了相当大的努力,但对于人和机器在日常生活中可能遇到的各种声音的研究却很少。这些声音涵盖了各种物体、动作、事件和通信:从自然环境中动物和人类的发声,到现代环境中丰富的人工声音。
建立一个处理和分类多种声音的人工系统存在两大挑战。首先,需要开发高效的算法,可以学习对大量不同的声音进行分类或排序,机器学习为这项任务提供了几种有效的算法。其次,更具挑战性的是,需要开发一种声音表示法,以捕获人类用来辨别和识别不同声音的全部听觉特征,使机器也有机会做到这一点。但是,目前对如何表达大量自然声音的理解仍然非常有限。
为了评估和比较听觉表征,在给定文本查询的情况下,使用基于内容的声音文档排序和检索真实任务测试。在这个应用程序中,用户输入一个文本进行查询,作为响应,一个有序的声音文档列表将显示出来,按照与查询的相关性排序。例如,用户键入“dog”将收到一组有序的文件,其中最上面的文件应该包含狗吠声。重要的是,声音文档的排序完全基于声音内容,而非文本注释或其他元数据。相反,在训练时,使用一组带注释的声音文档(带有文本标记的声音文件),允许系统学习将狗吠声的声学特征与文本标记“dog”匹配,也可以用于大量与声音相关的文本查询。通过这种方式,可以使用一个小的标记集从一个更大的、未标记的集进行基于内容的检索。
以往研究已经解决了基于内容的声音检索问题,主要集中在该任务的机器学习和信息检索方面,使用标准声学表示法。在这里,我们关注互补问题,即使用给定的学习算法寻找声音的良好表示。
2.音乐旋律匹配
机器听觉还可以应用于音乐旋律匹配系统 [ 11 ] ,该系统使用一种新的基于色度的表示法(称为“间隔图”)来表示短段音频的旋律内容,该表示法是对音乐片段中音乐间隔的局部模式的总结。间隔图是基于从俯仰图或稳定听觉图像的时间剖面图导出的色度表示。通过对局部参考的“软”基音变换,使每个间隔帧具有局部关键点不变性。间隔图是使用多个重叠窗口为一段音乐生成的。这些间隔图集被用作在音乐数据库中检测相同旋律的系统基础。使用类似于动态规划的方法比较参考和歌曲数据库,在数据集上评估性能。基于该数据集的间隔图系统的第一次测试产生了53.8%的最高精度,精度-召回曲线显示了非常高的精度和中等召回率,这表明间隔图擅长识别数据集中更容易匹配的封面歌曲,且具有很高的稳健性。间隔图被设计为支持对位置敏感的散列,使得从每个间隔图特征中进行索引查找具有中等的检索匹配的概率,而错误匹配相对较少。使用这种索引方法,可以像以前的内容识别系统一样,在进行更详细的匹配之前快速修剪大型参考数据库。
1.请简述机器听觉的基本概念。
2.机器听觉有哪些特性?
3.听觉中的关键问题有哪些?
4.用机器去模仿人耳可以为人们提供哪些服务?
5.什么是机器听觉感知技术?
6.请简述机器听觉感知的体系结构。
7.语音识别技术的工作原理是什么?
8.语音识别技术有哪些应用?
9.听觉智能感知的应用有哪些?
10.谈一谈你对机器听觉的理解。
[1]LAMONT L A,TRANQUILLI W J,GRIMM K A.Physiology of pain[J].Veterinary clinics: small animal practice,2000,30(4): 703-728.
[2]KEMP,D.T.Stimulated acoustic emissions from within the human auditory system[J].Journal of the acoustical society of america,1998,64(5):1386-1391.
[3]LYON R F.Human and machine hearing: extracting meaning from sound[M].Cambridge: Combridge University Press.2017.
[4]LYON R F.Machine hearing: an emerging field[Exploratory DSP][J].IEEE Signal processing magazine,2010,27(5):131-139.
[5]OWNER D.Speech recognition technology[J].Handbook of brain theory & neural networks.2006.
[6]Johnson M,Lapkin S,Long V,et al.A systematic review of speech recognition technology in health care[J].BMC Medical informatics and decision making,2014,14: 1-14.
[7]KITA K,ASHIBE K,YANO Y,et al.Voicedic: a practical application of speech recognition technology[J].Advances in human factors/ergonomics,1995,20:535-540.
[8]BHATT S,JAIN A,DEV A.Continuous speech recognition technologies—a review[C]//Recent Developments in Acoustics: Select Proceedings of the 46th National Symposium on Acoustics.Berlin: Springer Singapore,2021: 85-94.
[9]TREICHLER J.Digital signal processing and control and estimation theory[J].IEEE Transactions on acoustics speech and signal processing,1980,28(5):602-603.
[10]MANDAL A,KUMAR K,MITRA P.Recent developments in spoken term detection: a survey[J].International journal of speech technology,2013,17(2): 183-198.
[11]SUN J,WANG H.A cognitive method for musicology based melody transcription[J].International journal of computational intelligence systems,2015,8(6): 1165-1177.