
下载掌阅APP,畅读海量书库
立即打开



包括大语言模型在内的深度神经网络模型无法直接处理原始文本。由于文本数据是离散的,因此我们无法直接用它来执行神经网络训练所需的数学运算。我们需要一种将单词表示为连续值的向量格式的方法。
注意 如果你不熟悉计算上下文中的向量和张量,可以到 A.2.2 节中了解更多信息。
将数据转换为向量格式的过程通常称为 嵌入 (embedding)。我们可以通过特定的神经网络层或利用另一个预训练的神经网络模型来嵌入不同类型的数据(如视频、音频和文本),如图2-2 所示。然而,需要注意的是,不同的数据格式需要使用不同的嵌入模型。例如,为文本设计的嵌入模型并不适用于嵌入音频数据或视频数据。
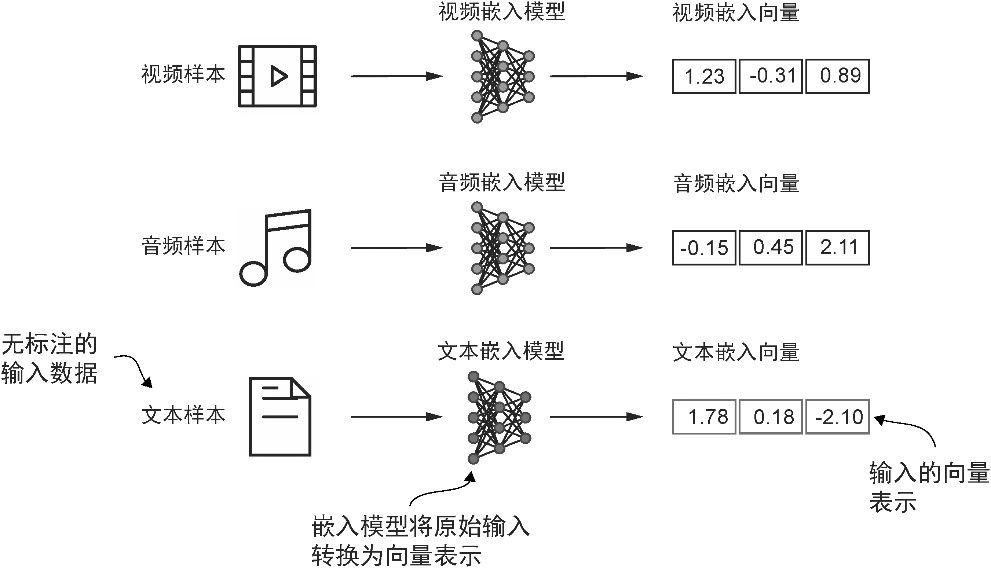
图2-2 深度学习模型无法直接处理视频、音频、文本等原始格式的数据。因此,我们使用嵌入模型将这些原始数据转换为深度学习架构容易理解和处理的密集向量表示。图中展示了将原始数据转换为三维数值向量的过程
嵌入的本质是将离散对象(如单词、图像甚至整个文档)映射到连续向量空间中的点,其主要目的是将非数值的数据转换为神经网络可以处理的格式。
尽管词嵌入是文本嵌入中最常见的形式,但也存在针对句子、段落乃至整个文档的嵌入技术。句子嵌入或段落嵌入在 检索增强生成 (retrieval-augmented generation)领域非常流行。通过将生成(如生成文本)与检索(如搜索外部知识库)相结合,检索增强生成能够在生成过程中引入与上下文相关的外部信息,但这一技术超出了本书的讨论范畴。我们的目标是训练类 GPT 大语言模型,而这些模型专注于逐词生成文本,因此,本书将集中探讨词嵌入。
目前,人们已经开发出多种算法和框架来生成词嵌入,其中 word2vec 是早期最流行的方法之一。通过训练神经网络架构,word2vec 实现了根据目标词预测上下文,或根据上下文预测目标词,从而生成词嵌入。word2vec 的核心思想是,出现在相似上下文中的词往往具有相似的含义。因此,当这些词嵌入被投影到二维空间并进行可视化时,我们可以看到意义相似的词聚集在一起,如图2-3 所示。
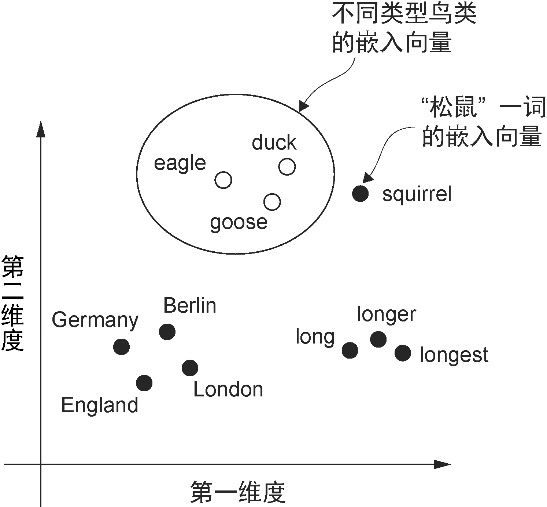
图2-3 如果词嵌入是二维的,那么就可以将它们绘制在二维散点图中进行可视化。在使用词嵌入技术(如 word2vec)时,表示相似概念的词通常会在嵌入空间中彼此接近。例如,在嵌入空间中,不同类型的鸟类的距离通常比国家和城市之间的距离更近
词嵌入的 维度 (dimension)可以从一维到数千维不等。更高的维度有助于捕捉到更细微的关系,但这通常以牺牲计算效率为代价。
虽然可以使用 word2vec 等预训练模型为机器学习模型生成嵌入,但大语言模型通常会自行生成嵌入。这些嵌入是输入层的一部分,并且会在训练过程中进行更新。与使用 word2vec 相比,将嵌入作为大语言模型训练的一部分进行优化的优势在于,嵌入可以针对特定的任务和数据进行优化。本章将在后面实现这样的嵌入层。(此外,大语言模型还能生成与上下文相关的输出嵌入,第3章将对此进行讨论。)
遗憾的是,高维嵌入难以进行可视化。这是因为我们的感官以及常见的图形表示方法本质上局限于三维或更低的维度,这也是图2-3 中采用二维散点图来展示二维嵌入的原因。然而,在处理大语言模型时,我们通常使用更高维度的嵌入。GPT-2 和 GPT-3 的嵌入维度(通常称为“模型隐藏状态的维度”)根据模型的版本与规模的差异而有所不同,这是性能与效率之间的权衡。最小的 GPT-2 模型(参数量为 1.17 亿)使用的嵌入维度为 768,而最大的 GPT-3 模型(参数量为 1750 亿)使用的嵌入维度为 12 288。
接下来,我们将逐步了解为大语言模型准备嵌入向量的过程,包括将文本分割为单词、将单词转换为词元,以及将词元转化为嵌入向量。