
下载掌阅APP,畅读海量书库
立即打开



本章内容
● 为大语言模型训练准备文本
● 将文本分割为单词词元和子词词元
● 使用更高级的文本分词方法——字节对编码
● 利用滑动窗口方法对训练样本进行采样
● 将词元转换为输入到大语言模型中的向量
在第1章中,我们深入探讨了大语言模型的一般结构,并认识到这些模型是在海量文本数据上进行预训练的。我们特别关注的是基于 Transformer 架构的纯解码器大语言模型,Transformer 架构是 ChatGPT 和其他类 GPT 大语言模型的基础。
在预训练阶段,大语言模型一次处理一个单词。通过使用下一单词预测任务,我们能够训练那些拥有数百万甚至数十亿参数的大语言模型,从而打造出能力优异的模型。这些模型经过进一步微调,便可以遵循通用指令或执行特定的目标任务。但是,在实现和训练大语言模型之前需要先准备好训练数据集,如图2-1 所示。
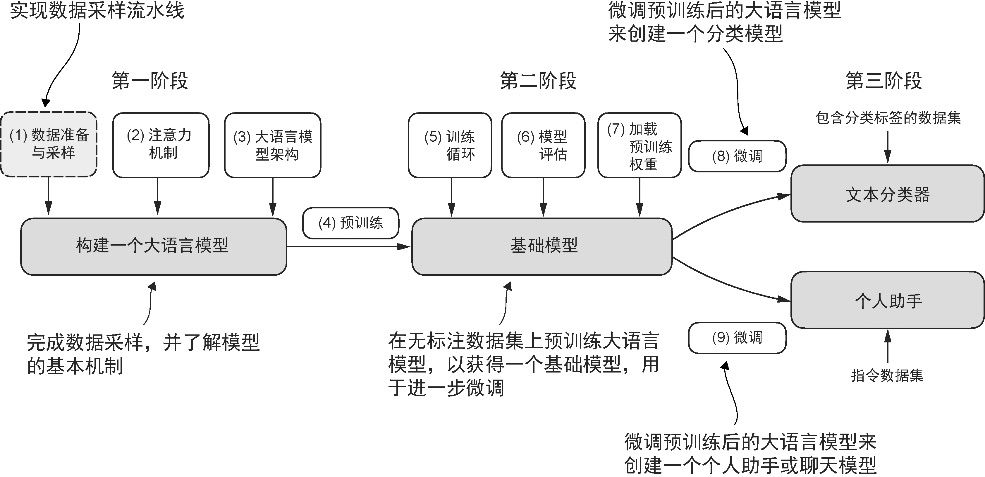
图2-1 构建大语言模型的 3 个主要阶段。本章重点讨论第一阶段中的第(1) 步:实现数据采样流水线
在本章中,你将学习如何为训练大语言模型准备输入文本。这涉及将文本分割为独立的单词词元和子词词元,然后将其编码为大语言模型所使用的向量表示。你还将了解到高级的分词技术,比如 字节对编码 (byte pair encoding,BPE),这是一种在 GPT 等流行的大语言模型中广泛使用的方法。最后,我们将实现一种采样和数据加载策略,来生成训练大语言模型所需的输入-输出对。