
下载掌阅APP,畅读海量书库
立即打开



大部分的现代大语言模型基于 Transformer 架构,这是一种深度神经网络架构,该架构是在谷歌于 2017 年发表的论文“Attention Is All You Need”中首次提出的。为了理解大语言模型,我们需要简单回顾一下最初的 Transformer。Transformer 最初是为机器翻译任务(比如将英文翻译成德语和法语)开发的。Transformer 架构的一个简化版本如图1-4 所示。
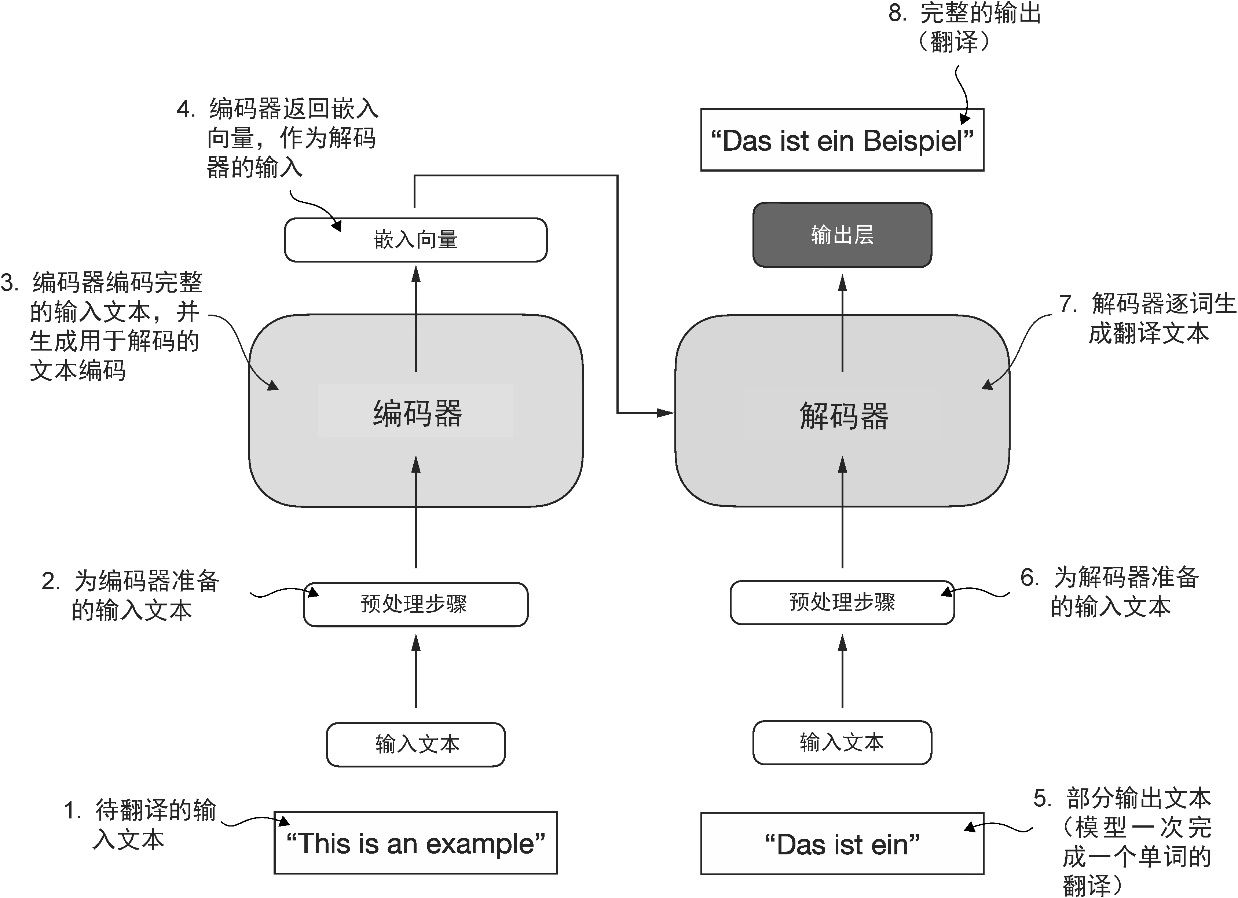
图1-4 原始 Transformer 架构的简化描述,这是一种用于机器翻译的深度学习模型。Transformer 由两部分组成:一个是编码器,用于处理输入文本并生成文本嵌入(一种能够在不同维度中捕获许多不同因素的数值表示);另一个是解码器,用于使用这些文本嵌入逐词生成翻译后的文本。请注意,图中展示的是翻译过程的最后阶段,此时解码器根据原始输入文本(“This is an example”)和部分翻译的句子(“Das ist ein”),生成最后一个单词(“Beispiel”)以完成翻译
Transformer 架构由两个子模块构成:编码器和解码器。 编码器 (encoder)模块负责处理输入文本,将其编码为一系列数值表示或向量,以捕捉输入的上下文信息。然后, 解码器 (decoder)模块接收这些编码向量,并据此生成输出文本。以翻译任务为例,编码器将源语言的文本编码成向量,解码器则解码这些向量以生成目标语言的文本。编码器和解码器都是由多层组成,这些层通过自注意力机制连接。关于如何对输入进行预处理和编码,我们将在后续章节中逐步解答。
Transformer 和大语言模型的一大关键组件是 自注意力机制 (self-attention mechanism),它允许模型衡量序列中不同单词或词元之间的相对重要性。这一机制使得模型能够捕捉到输入数据中长距离的依赖和上下文关系,从而提升其生成连贯且上下文相关的输出的能力。然而,由于自注意力机制较为复杂,我们将在第3章中详细解释并逐步实现。
为了适应不同类型的下游任务,Transformer 的后续变体,如 BERT (Bidirectional Encoder Representations from Transformer, 双向编码预训练 Transformer )和各种 GPT (Generative Pretrained Transformer, 生成式预训练 Transformer )模型,都基于这一理念构建。如果你对此感兴趣,可以参见附录B。
BERT 基于原始 Transformer 的编码器模块构建,其训练方法与 GPT 不同。GPT 主要用于生成任务,而 BERT 及其变体专注于 掩码预测 (masked word prediction),即预测给定句子中被掩码的词,如图1-5 所示。这种独特的训练策略使 BERT 在情感预测、文档分类等文本分类任务中具有优势。例如,截至本书撰写时,X(以前的 Twitter)在检测有害内容时使用的是 BERT。
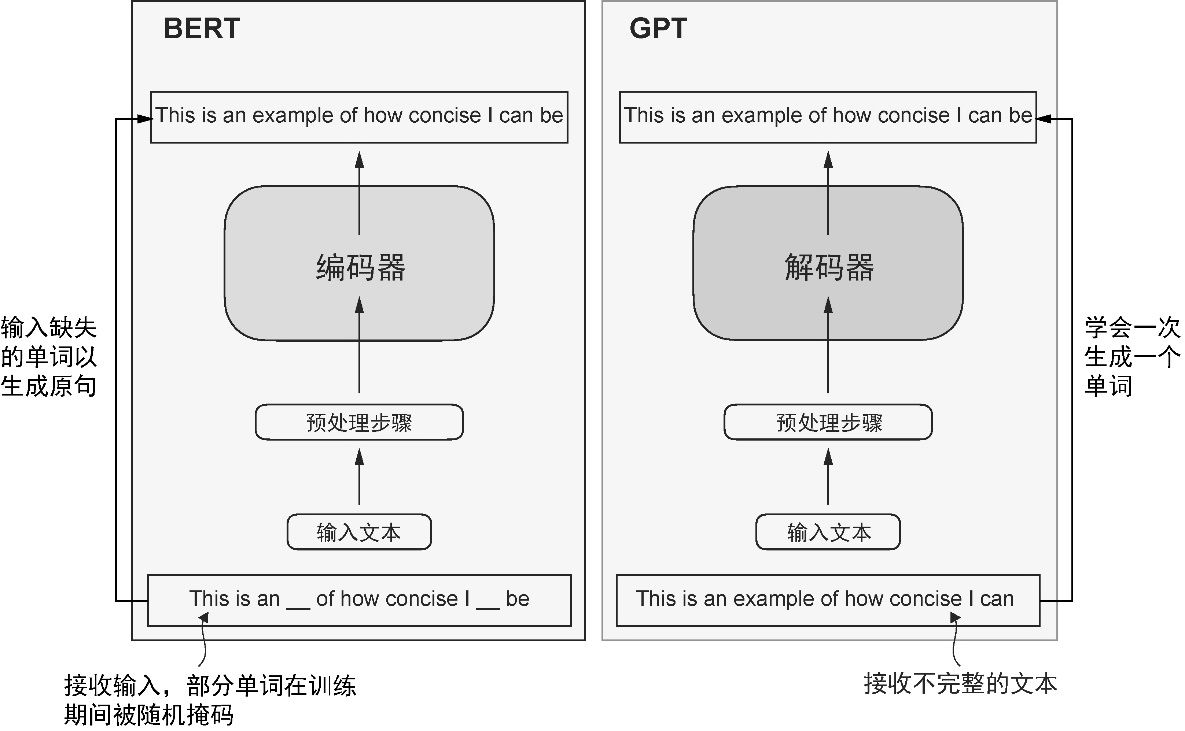
图1-5 Transformer 编码器和解码器的可视化展示。左侧的编码器部分展示了专注于掩码预测的类 BERT 大语言模型,主要用于文本分类等任务。右侧的解码器部分展示了类 GPT 大语言模型,主要用于生成任务和生成文本序列
GPT 则侧重于原始 Transformer 架构的解码器部分,主要用于处理生成文本的任务,包括机器翻译、文本摘要、小说写作、代码编写等。
GPT 模型主要被设计和训练用于 文本补全 (text completion)任务,但它们表现出了出色的可扩展性。这些模型擅长执行零样本学习任务和少样本学习任务。 零样本学习 (zero-shot learning)是指在没有任何特定示例的情况下,泛化到从未见过的任务,而 少样本学习 (few-shot learning)是指从用户提供的少量示例中进行学习,如图1-6 所示。
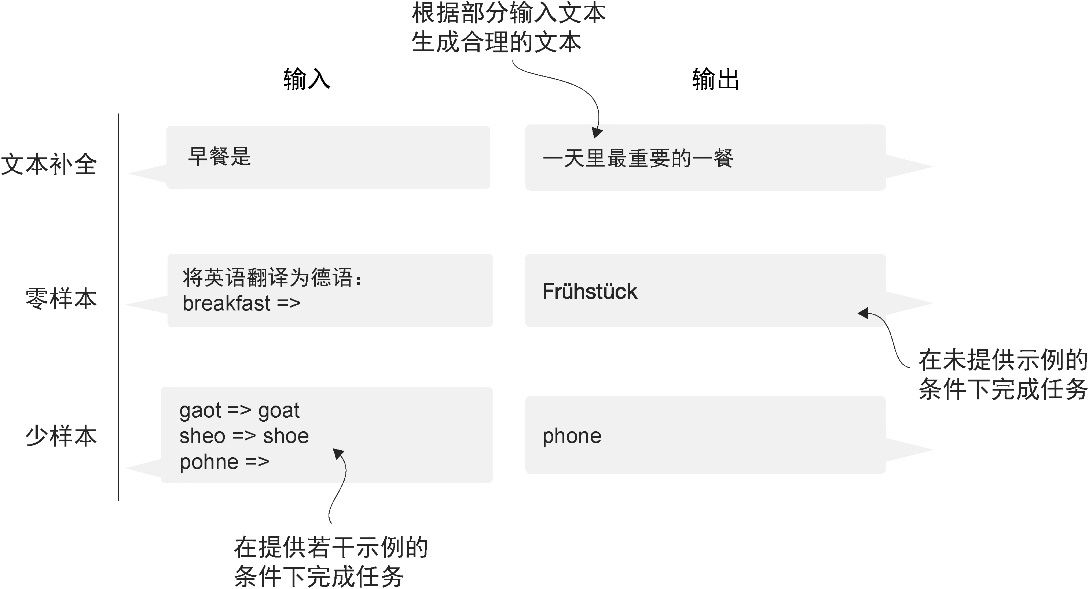
图1-6 除了文本补全,类 GPT 大语言模型还可以根据输入执行各种任务,而无须重新训练、微调或针对特定任务更改模型架构。有时,在输入中提供目标示例会很有帮助,这被称为“少样本设置”。然而,类 GPT 大语言模型也能够在没有特定示例的情况下执行任务,这被称为“零样本设置”
当今的大语言模型大多基于前文介绍的 Transformer 架构,因此,Transformer 和大语言模型在文献中常常被作为同义词使用。然而,并非所有的 Transformer 都是大语言模型,因为 Transformer 也可用于计算机视觉领域。同样,并非所有的大语言模型都基于 Transformer 架构,因为还存在基于循环和卷积架构的大语言模型。推动这些新架构发展的主要动机在于提高大语言模型的计算效率。然而,这些非 Transformer 架构的大语言模型是否能够与基于 Transformer 的大语言模型相媲美,以及它们是否会在实践中被广泛应用,还有待观察。为简便起见,本书中使用“大语言模型”一词来指代类似于 GPT 的基于 Transformer 的大语言模型。(如果你对此感兴趣,可以在附录B 中找到描述这些架构的参考文献。)