
下载掌阅APP,畅读海量书库
立即打开



一种受大脑及其神经元和复杂的突触互连启发的机器学习(也许有点夸张)被称为神经网络,或神经网络(也简称神经网)。前面提到的感知机,也叫节点,就是一个生物神经元的计算模型。
与刚才讨论的机器学习技术相比,更复杂的神经网络和深度学习技术(有时有数百层的神经元)特别适合用非线性和复杂的关系,这在生物医学和医疗保健中并不罕见。这类神经网络包括感知器(包括简单的感知机和多层感知机)、自编码器、GAN、卷积神经网络和循环神经网络(见表 5.8)。
表 5.8 神经网络

感知机本质上是一种单层神经网络,是所有神经计算模型中最简单的。它本质上是一个二元线性分类器。这个节点或神经元模型具有生物启发结构,以数据的形式接受输入,执行指定的计算函数(也称为激活函数,见下文),然后形成输出。简而言之,节点或神经元是计算功能发生的地方。尽管神经元和感知机在结构上有相似之处(树突和轴突分别相当于输入和输出),但这两种模型的一个主要区别是连接的数量:虽然感知机可以连接到其他几个感知机连接,而生物神经元可以与多达 10000 个其他神经元连接。
这些节点通过它们的连接,分别被称为权重的参数所调制。这些权重决定了每个连接的传输信号的相对强度,可以是正的也可以是负的。换句话说,这个权重影响着输入对神经元的影响,调整后可使神经网络进行“学习”。同时还存在偏差,这个数字告诉人们在神经元被激活之前,加权总和需要达到多高。总之,需要将输入的总和乘以权重,然后再考虑偏差。
此外,还有一个神经网络的激活函数,它通过输入和输出之间的连接进行学习(并能限制神经元输出的宽度)。激活函数决定了感知机的输出值。因此,激活函数可以提高神经网络的性能;神经元的激活函数通常是一个S形,因为它是线性和非线性行为之间的平衡。
神经网络的训练分为两个不同的阶段:正向传播和反向传播。正向传播本质上是输入和预测标签(与真实标签相比)的加权和,反向传播(错误反向传播的简称)则是神经网络可以学习(或微调)的一种机制。实际输出和期望输出之间的差异被用来计算一个被称为损失或成本函数的修正(见下文),以实现期望的结果。
因此,多层感知器是具有一个或多个隐藏层的多层前馈网络。每个神经网络都有一个输入层、一个隐藏层和一个输出层(见图 5.14)。隐藏层执行从输入层接收的计算,并将结果传递给输出层。因此,学习不仅是为了让网络找到正确的权重,还要找到最佳偏差(通常前者比后者多得多),以便正确执行。
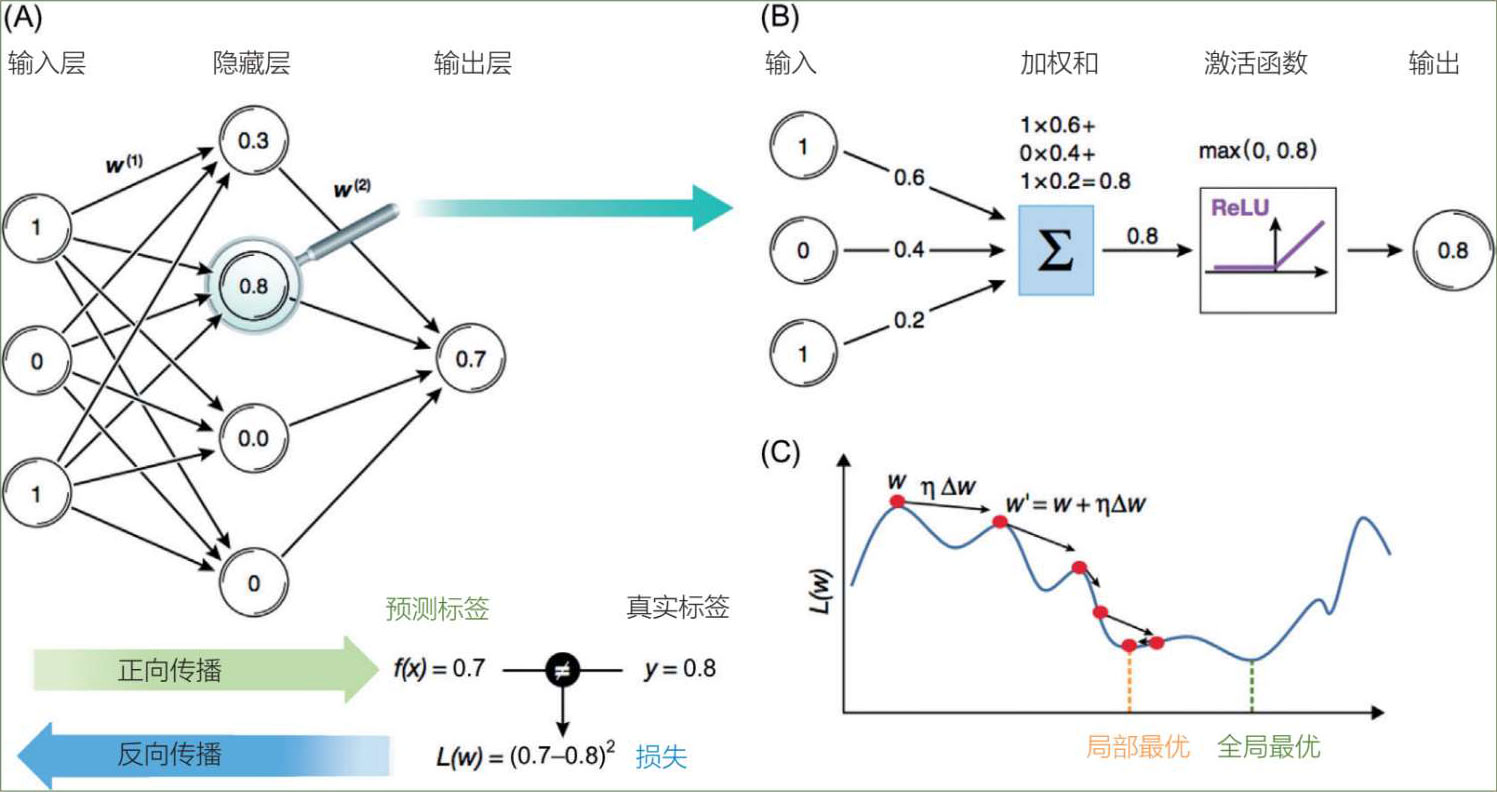
图 5.14 多层感知器
损失或成本函数是对网络的所有权重和偏差的评估,并提供一个数字作为网络的性能“等级”;数字越小,网络的性能越好。一些作者确实将损失函数(或误差)作为区分单一训练实例的元素,而成本函数是针对整个训练集的。从本质上讲,网络中的“学习”是通过以迭代的方式将这个损失最小化或成本函数来体现的。
梯度下降是一种优化算法,用于改进机器学习模型的参数(线性回归中的系数和神经网络中的权重),使这些模型的成本函数最低(或精度最高)。这种策略是通过迭代的方式降低梯度来进行的,直到达到成本函数的全局最小值,因为局部最小值通常不是最低值(见图 5.15)。
多层感知器的优点包括它的自适应学习能力,还有它的反向传播算法可以很好地完成输入和输出之间的映射;缺点是学习速度相对较慢,而且需要标记数据。此外,多层感知器还有可能出现过度拟合的情况。
在最近的生物医学文献中,有一篇报告使用放射学特征和多层感知网络分类器进行相对稳健的MRI分类策略(与GLM甚至与CNN相比),以区分胶质母细胞瘤和原发性中央神经系统淋巴瘤 [18] 。
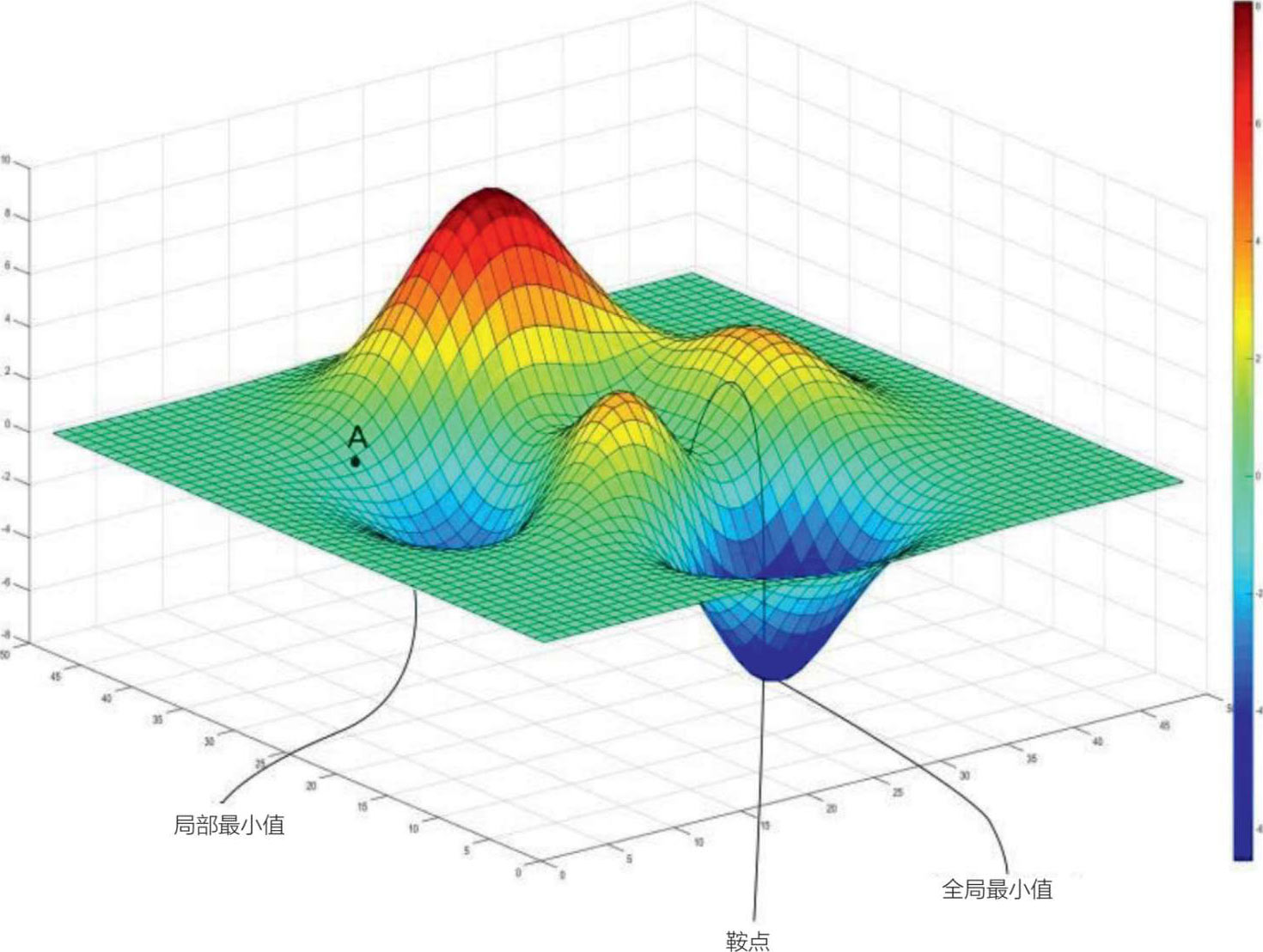
图 5.15 梯度下降和全局最小值
深度学习的发布受到三种不同因素的影响。首先,方法的演变从早期的数学家到 1989 年杨立昆的卷积神经网络,再到后来杰弗里·辛顿在 2012 年发布的ImageNet的工作。其次,计算机的存储能力从早期的穿孔卡到互联网,再到现在的云存储形式,有了飞速提升。最后,计算能力也从最初的ENIAC计算机提升到现在的GPU,GPU是有内存的专用微处理器,是显卡的一部分,比CPU拥有更多的处理核心。
2012 年,由杰弗里·辛顿领导的多伦多大学的团队使用了一种具有 65 万个神经元和 5 个卷积层的深度学习算法,在ImageNet计算机视觉挑战中,将错误率降低了一半 [19] 。继这一里程碑之后,斯坦福大学和谷歌的吴恩达以及其他人通过增加层和神经元的数量来合成巨大的神经网络,训练越来越大的数据集来发布深度学习 [20-22] 。有了强大的开源软件工具(如TensorFlow、PyTorch和Keras)、强大的超级计算机(如NVIDIA DGX-1)以及丰富的多种类型数据,深度学习成了机器学习的一个令人兴奋但也神秘莫测的新扩展。目前深度学习的应用包括语音识别和自然语言处理、计算机视觉与视觉对象识别和检测、语音识别和自动车辆驾驶。
一篇有关医学中深度学习的优秀评论讨论了计算机视觉、自然语言处理、强化学习和广义方法中的深度学习 [23] 。现在将讨论以下类型的深度学习:自编码器、GANs、CNN、RNN及其他。
这是一个相对简单的三层(或更多层)神经网络,是一种无监督学习工具,它将输入数据(作为向量)“编码”成一个更压缩的表示(见图 5.16),因此它是一种降维形式。
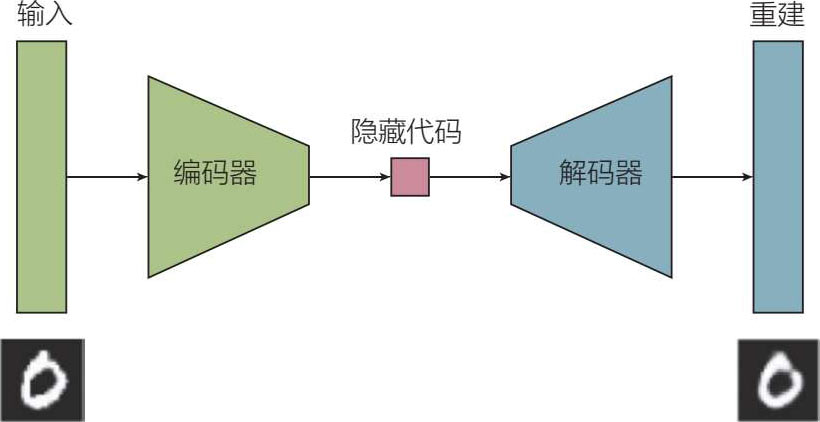
图 5.16 自编码器
自编码器在网络中有意设置了一个“瓶颈”,这样这个区域就会迫使原始输入的知识被压缩(或精确副本);一个解码器通常与这个编码器配对,以重建被压缩的输入数据。自编码器也被用于数据去噪。与PCA及其降维能力不同,自编码器以非线性的方式进行降维。自编码器的一个有趣的应用是变分自编码器(VAE),它不仅压缩输入数据,而且具有生成性——它能合成自编码器所观察到的类似的新数据(基本上是从旧图像中提取的新图像)。
自编码器可以应用于计算机视觉、异常检测和信息检索。
自编码器的优点是比PCA更容易用于降维,而且更准确。此外,由于自编码器是一个神经网络,因此它很适合用于图像和音频数据。自编码器的一个缺点是,人们可能会错过关于输入数据的理论见解和信息,特别是对于VAE来说。另一个潜在的缺点是,它需要相对较多的数据来训练。
在最近的生物医学文献中,自编码器的一个例子是使用一种新的预测方法来预测帕金森病基因,该方法使用了三步策略:基于网络提取基因的特征,自编码器形式的深度神经网络降维,并应用机器学习方法(支持向量机)预测帕金森病基因 [24] 。
GAN是由伊恩·古德弗洛在 2014 年提出的,它是一种深度神经网络架构,由两个相互竞争的网络组成,但可以从头生成数据 [25] 。此外,根据脸书人工智能总监杨立昆的说法,GAN是“过去 10 年中机器学习领域最有趣的想法”。在GAN中,两个对抗式模型(称为“生成器”和“鉴别器”)可以以无监督学习的形式,通过反向传播进行协同训练(从而使计算机具有“想象”的能力)。GAN在计算机视觉和图像方面有许多应用,包括训练半监督分类器,以及从低分辨率的原始图像中生成更高分辨率的图像。
深度学习的概念如下(见图 5.17):生成器,一个生成新数据实例的神经网络,与另一个被称为鉴别器的神经网络是一对搭档,后者评估从生成器创建的数据实例的真实性。实质上,鉴别器作为一个“法官”,使生成器生成更多的真实图像,因此这两个神经网络是同时训练的。GAN已经与CNN结合起来,创建了无监督学习的深度卷积GAN(DCGAN) [26] 。DCGAN与CNN的不同之处在于它只有卷积层而没有池化层,也没有全连接层。
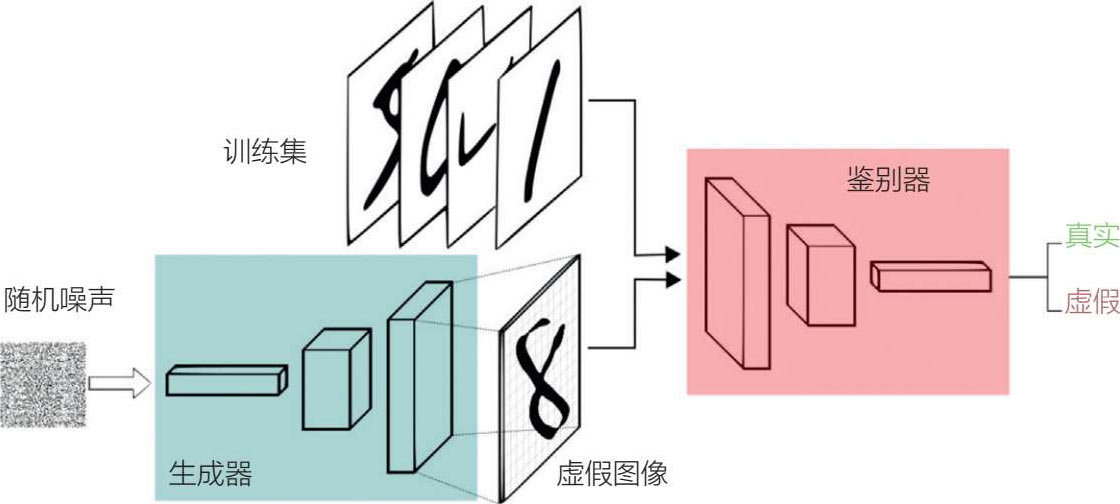
图 5.17 生成式对抗网络
GAN擅长以半监督的方式训练分类器,因为它不需要标记数据;对于这种深度学习方法来说,产生新的(人工的但良好的)数据相对容易。GAN擅长生成图像数据,但生成文本数据对这些神经网络来说并不容易。此外,一些专家认为,训练GAN并不容易,因为需要相对巨量的计算。最后,当生成器产生的样本种类极少时,GAN中会出现“模式崩溃”,这被认为是GAN的弱点。
在最近的生物医学文献中,有关GAN的一个例子是Guan最近关于将GAN和迁移学习同时用于卷积神经网络的乳腺癌检测的工作,作为缺乏图像训练的创新双重解决方案 [27] 。简而言之,作者将GAN用于图像增强并将卷积神经网络中的迁移学习用于乳腺癌检测。
受限于玻尔兹曼机是一种浅层(两层)的神经网络,本质上是一种无监督生成式深度学习算法;第一层被称为可见层或输入层,另一层是隐藏层。“受限”一词来自同一层中没有任何两个节点有连接。RBM也可以被认为是深度信念网络(DBM)的构建模块,可用于分类和降维。总的来说,现在RBM的使用频率不高,因为大多数用户已经改用GAN或VAE(如前所述)。
这是一个非常流行的深度神经网络,由三维特征组成的卷积层或块组成,灵感来自认知神经科学和视觉皮层功能。Cox对与计算机视觉关联的视觉生物结构进行了全面的评述,这篇评述还讨论了诸如移动图像和其他元素的细微差别 [28] 。卷积神经网络特别适用于具有层次或空间数据(通常是图像或字符)的计算机视觉以及自然语言处理。
CNN可以通过三种方式应用于医学图像:(1)分类-确定一个类别(不存在/存在恶性肿瘤或恶性肿瘤的类型);(2)分割-识别构成感兴趣区域(如某一器官或出血区域)的像素/体积元素;(3)检测-预测感兴趣区域。
注意:计算机视觉通常被认为是人工智能的一个分支,包括图像处理、物体识别、光学标记识别和其他领域,但由于后面的会讨论涉及计算机视觉与医学的关系,因此这里将不单独介绍。
首先,有必要介绍一个概念,即计算机“看到”的是一个代表像素亮度的数字矩阵,而不是人眼看到的灰影(见图 5.18)。
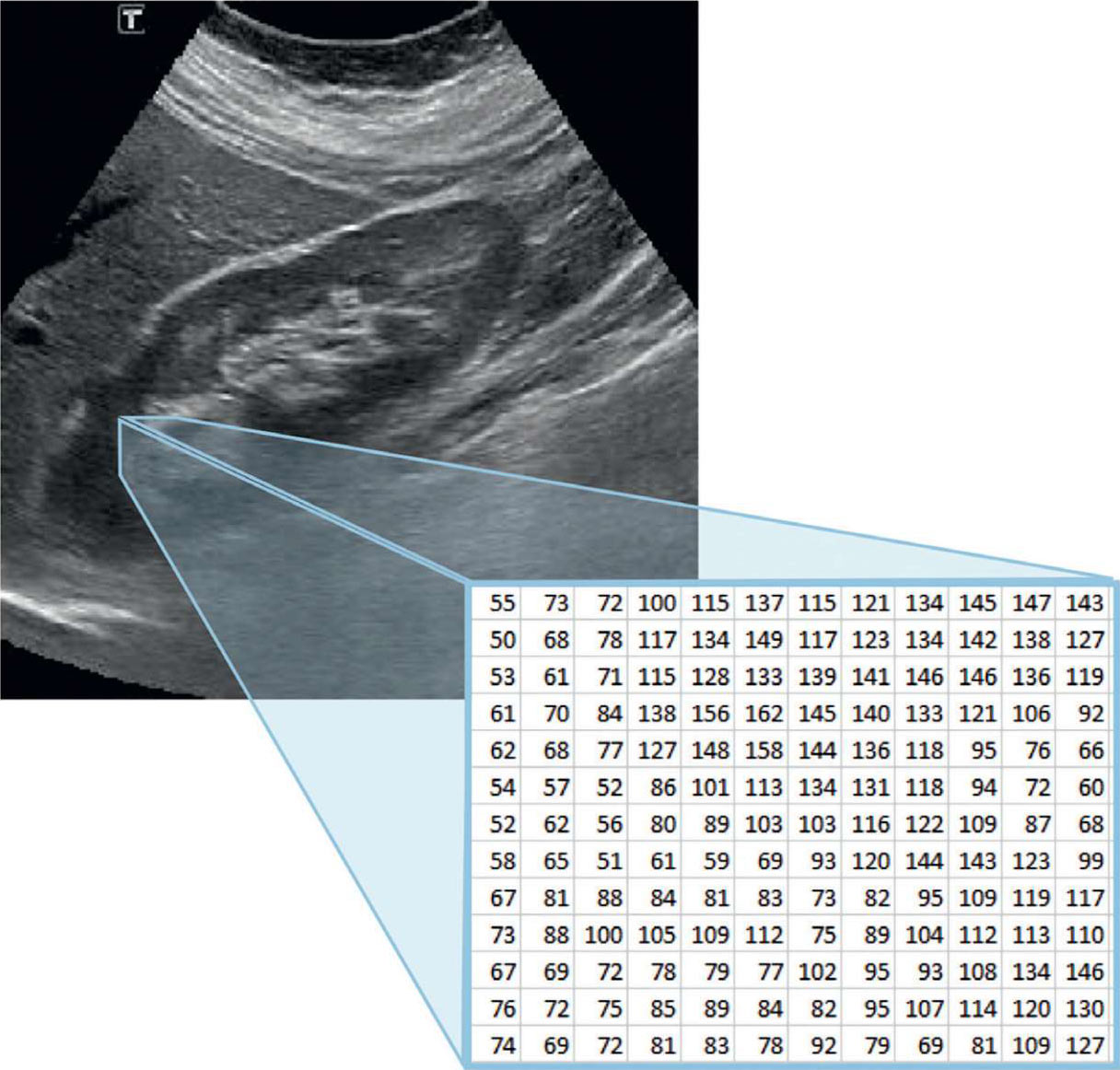
图 5.18 人类和计算机的视觉差异
卷积神经网络架构的构件包括卷积层、池化层、全连接层以及整流线性单元(见图 5.19) [29] 。构造这些层是为了使卷积神经网络能够学习特征图的空间层次,讨论如下。
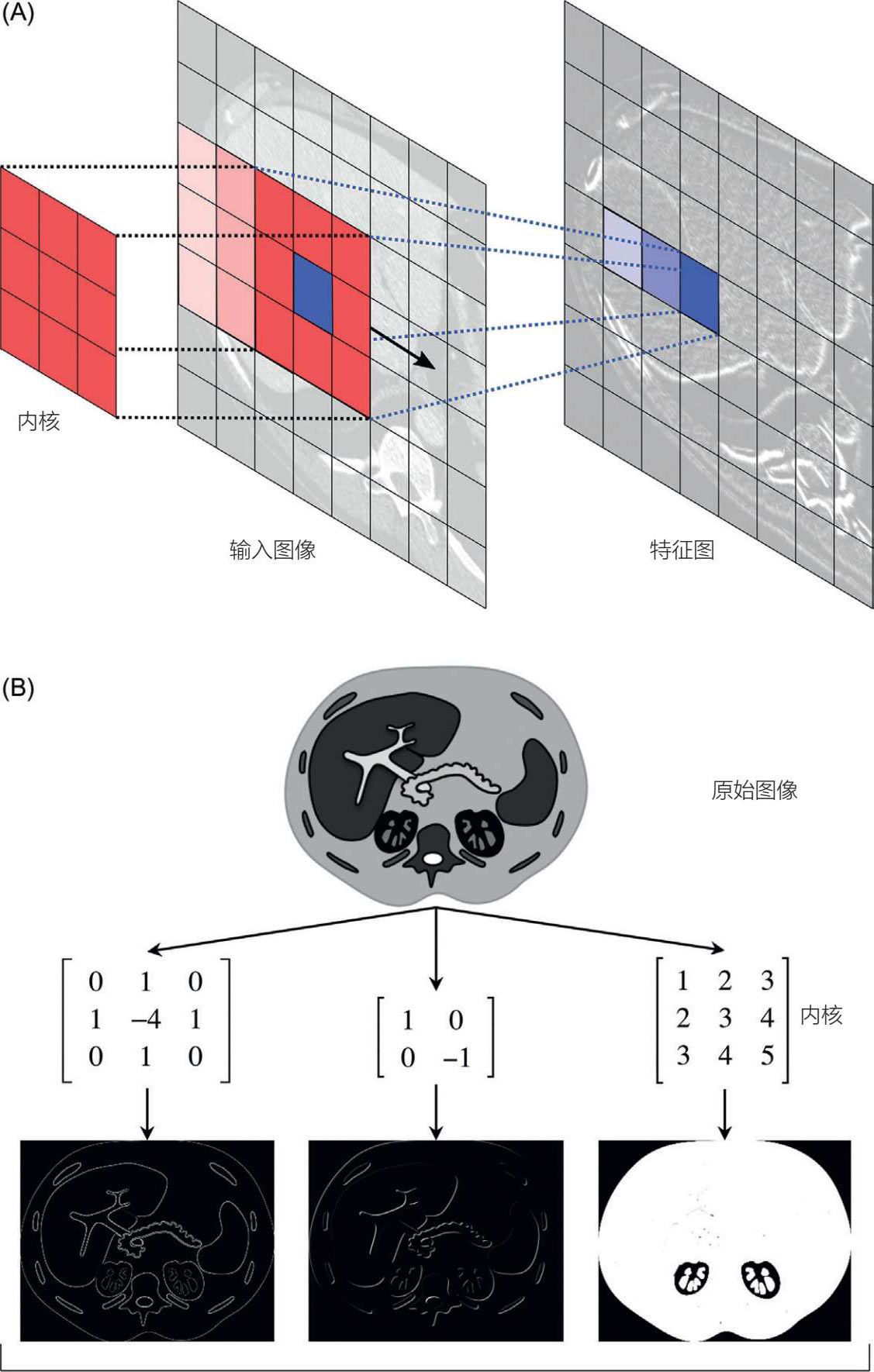
图 5.19 卷积
1.卷积层(用于特征图提取)涉及一个卷积“过滤器”或“内核”,它被放置在源像素或输入图像上。这个卷积过滤器(或内核)将源像素或输入图像转化为一个新的像素值,然后它成为目标像素或输出特征图。换句话说,这一层会将图像中的像素集合整合并转换为输出特征图上的重要特征。从本质上讲,卷积标志着“过滤”,过滤矩阵被应用于图像矩阵上,产生“卷积”的特征图或矩阵。简而言之,第三个函数(特征图)是由两个函数(输入数据和卷积核)导出的。
步幅是指在输入矩阵上移动或滑动的像素数(步幅为 1 表示移动一个像素)。不存在 0 步幅。
ReLU是一个激活函数,是卷积神经网络的一个关键组成部分,它确保了线性运算的非线性性;它通过加快训练速度来改进卷积神经网络。ReLU不同于其他可能的函数(S形切线或双曲切线);在这一方面,它对正的输入是完全线性的,而阻挡负的输入,因此更适合卷积神经网络。
2.池化层(用于特征聚合)通常跟随前面描述的卷积层,接收卷积层的输出作为其输入,但减少了参数的数量(以减少过度拟合)。由于输入参数的数量减少,这个过程也能使计算速度加快。因此,这个“池化”(也叫“下采样”)过程在保留重要信息的同时减少了维度。
最大池化的过程(通常优于最小、平均和池化,如图 5.20 所示,将前几层中更重要的信息压缩成一个更小的张量(张量是一个术语,指比简单矢量或高维矩阵更复杂的多维阵列)。池化层提高了模型的准确性以及训练速度。总体而言,由于维度的减少,随着池化层的发展,分辨率必然降低,但是(每个空间)图像的信息会变得越来越丰富,越来越相关。
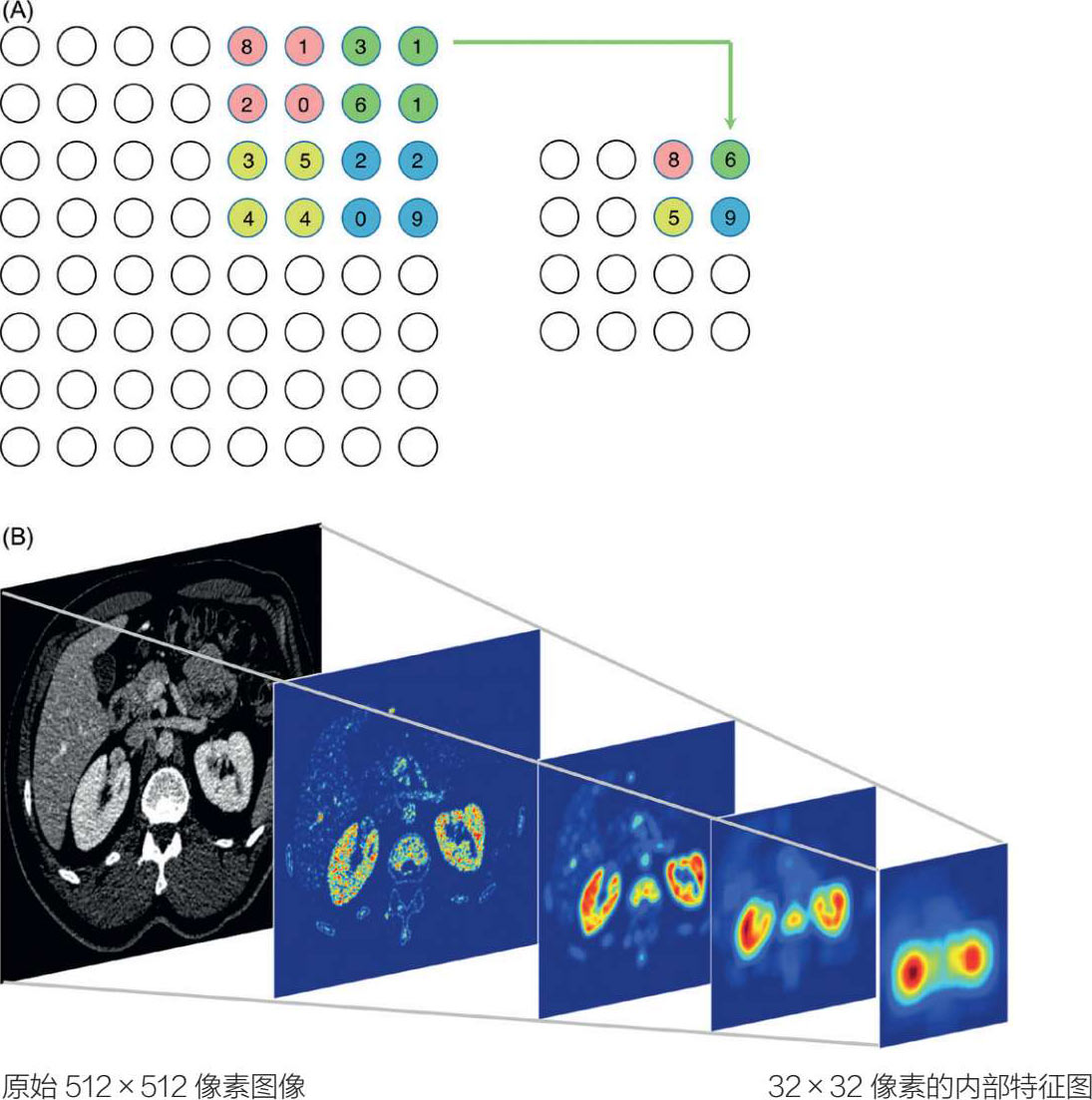
图 5.20 CNN池化过程
总的来说,卷积神经网络的第一层更多的是涉及基本的图像特征(如边缘或形状),而后续层则更多的是关注抽象特征。正是这些后面的层包含了深度学习的鲁棒性以及缺乏完全可解释性。换句话说,卷积神经网络的特征在前面几层比较通用,在后面几层则比较复杂。
3.全连接层(用于分类)将特征映射到最终输出。后面几层中一个被称为上采样的过程通过减少图像的存储和传输要求来提高卷积神经网络的分辨率。卷积神经网络的最后一个输出是通过一个称为扁平化的过程对感兴趣的区域进行地形显示。这将卷积神经网络卷积部分的输出转换为特征向量,以便应用分类器。Softmax激活应用在最后一层(而不是ReLU)上,因此输出可以被转换为概率分布(见图 5.21 和 5.22)。
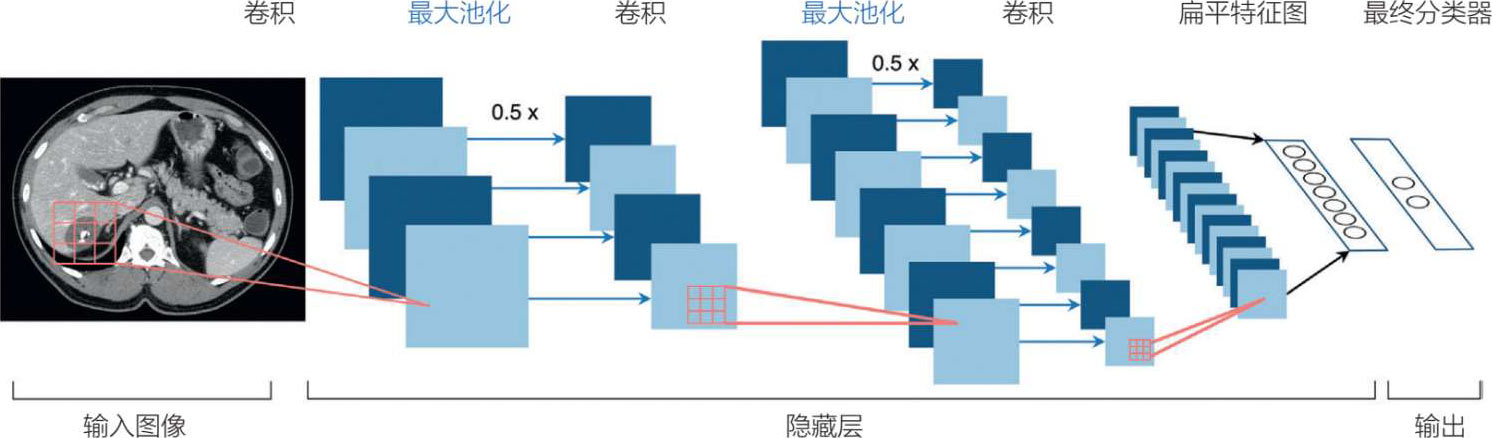
图 5.21 卷积神经网络
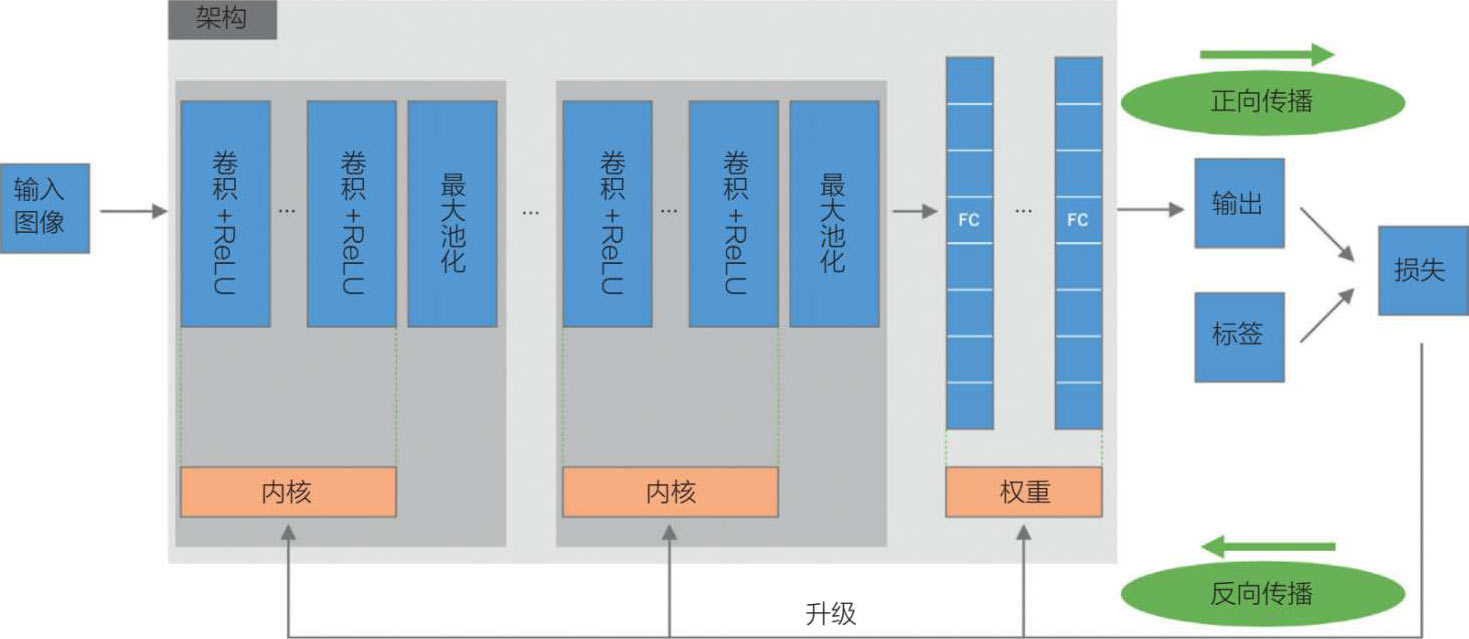
图 5.22 卷积神经网络架构
整个卷积和池化(下采样或子采样)过程可以总结为图 5.23。
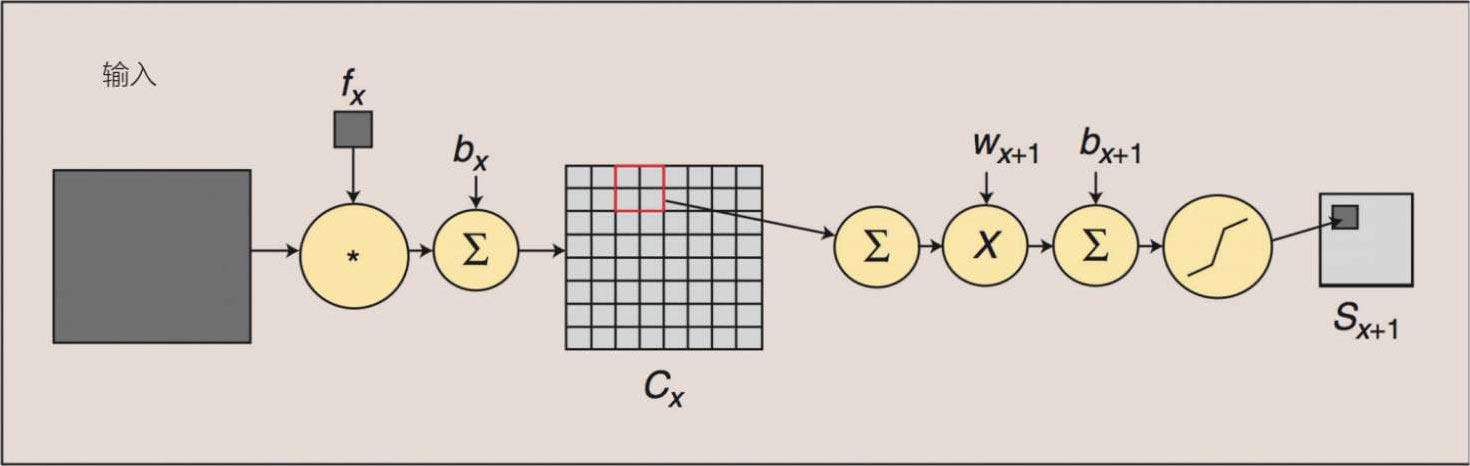
图 5.23 卷积和池化(下采样或子采样)
训练和测试的深度学习过程如图 5.24 所示。
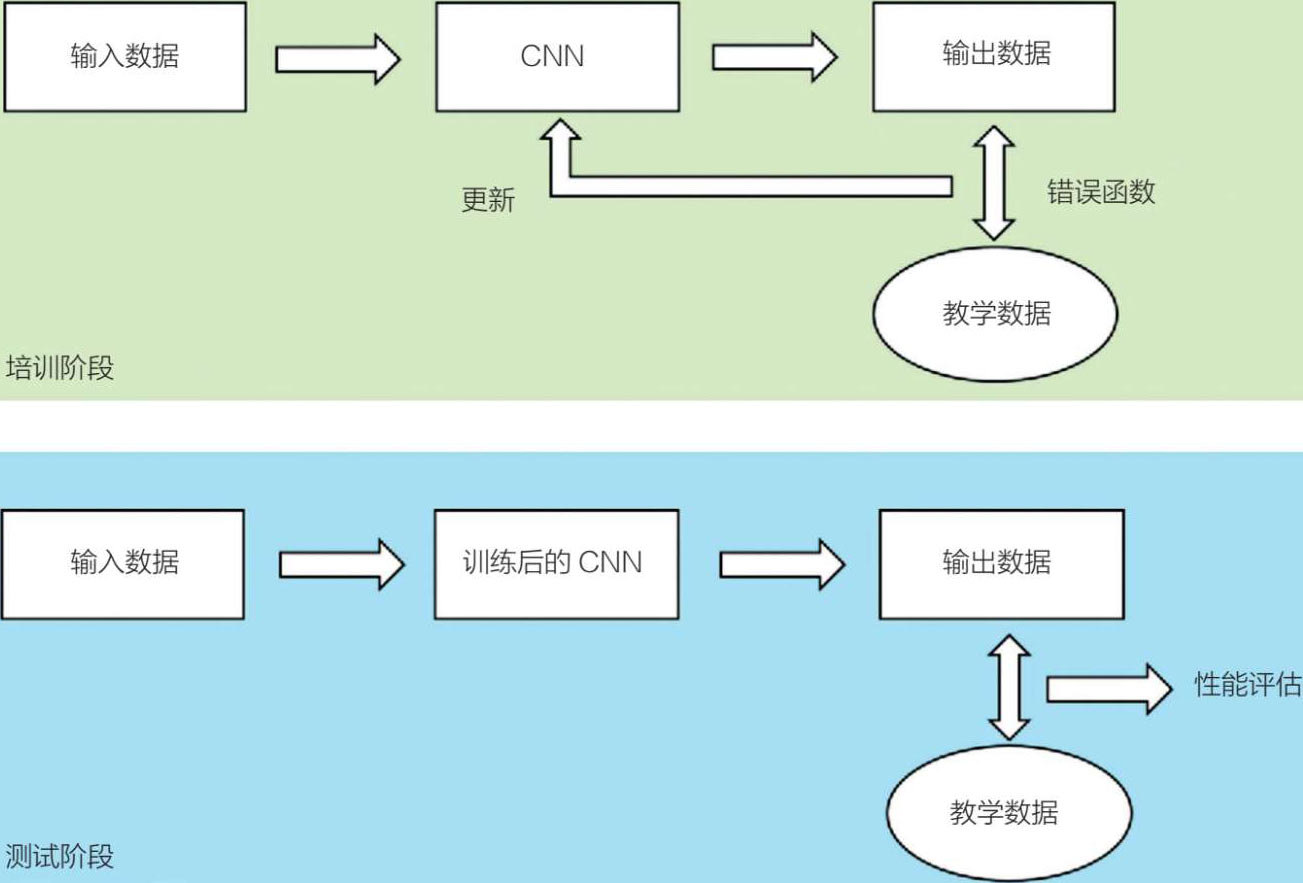
图 5.24 深度学习的训练和测试过程概述
比吉尔·塔梅尔索伊,布里安·特谢拉和托拜厄斯·海曼
比吉尔·塔梅尔索伊、布里安·特谢拉和托拜厄斯·海曼是一个专注于卷积神经网络开发的优秀研发团队的成员,他们以工程的角度撰写了这篇关于卷积神经网络的评论,讨论了卷积神经网络从编码到解码阶段的细微差别。
近年来,卷积神经网络帮助我们在各种医学图像处理任务中达到或超过了人类的表现。有多种因素促成了这种成功。
与其他深度神经网络一样,卷积神经网络也建立在学习越来越高的抽象层次的概念上。例如,一个被训练来定位拓扑图像中的解剖标志的卷积神经网络 [1] 可以在早期层中检测低级图像特征,如“边缘”或“斑点”,在中间层处理特定器官的结构,然后在最终层基于这些信息来检索实际的地标位置。图 5.25 表示出了这样一个卷积神经网络。
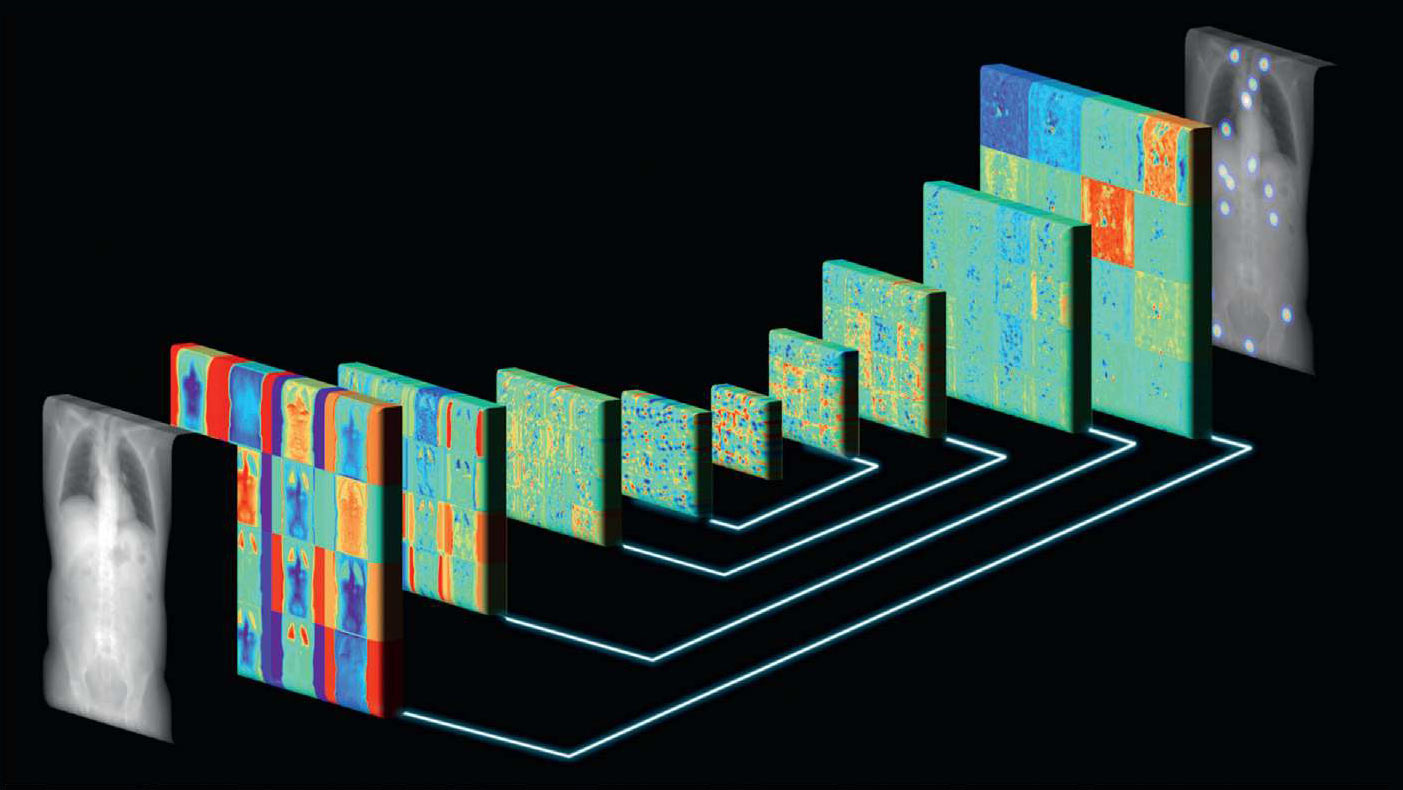
图 5.25 在地形图图像中定位解剖标志
类似于图 5.25 所示的蝶形卷积神经网络,在医学图像处理领域的作用尤为突出。这些卷积神经网络(通常被称为“U-Net” [2] )有两个主要阶段:编码阶段,在智能和特定任务的压缩中概括输入信息;解码阶段,提取压缩的信息以获得期望的结果。
通过U-Net的编码阶段,图像分辨率会逐渐降低。这通常是通过一个叫作“最大池化”的操作来实现的,其中一个层的输出的空间子区域在被用作下一层的输入之前将被汇总。通过多个阶段的“最大池化”,扩展了后续层过滤器的有效“接受区域”,或者换句话说,这些过滤器暴露于原始输入图像的更大区域。拥有这种输入的全局视图对于产生全局一致的结果至关重要,这在医学图像处理中非常重要。
U-Net的解码阶段采用这种严重压缩的信息,并通过一种称为“上采样”的操作逐步提高其分辨率。在解码阶段使用“跳过连接”是很常见的,编码阶段的信息被重新纳入处理。跳过连接有效地将高分辨率的局部背景与低分辨率的全局背景结合起来,并允许U-Net具有全局一致和局部精确的结果。
医学图像处理领域的卷积神经网络被用来对非常复杂的输入/输出关系进行建模。为了实现这一点,使用的网络不仅要非常深入,还需要采用非线性激活函数。传统上,如sigmoid或双曲正切的挤压函数应用于此目的。然而,对于较大的绝对输入值,这些函数的梯度可能变得非常小,以致在训练期间试图通过网络反向传播时,会遇到数值限制。这种梯度消失的问题在很长一段时间内限制了神经网络的合理深度。整流线性单元(ReLU)对于负值(非激活)的导数为0,对于正值(激活)的导数为1。鉴于此,梯度可以通过任意数量的层在活动节点上传播 [3] 。因此,ReLU激活函数的使用有助于训练医学图像处理领域更深层次的网络。
卷积神经网络也使得深度强化学习概念在医学图像处理领域的成功应用成为可能。最近的一个例子是使用人工代理对大型医疗数据进行有效解析 [4] ,其中代理采用卷积神经网络来确定其在有限的本地环境中的下一步行动。随着近年来卷积神经网络的大受欢迎,以及在这项技术上投入的大量研究工作,我们期望卷积神经网络在医学图像处理领域保持长期的价值。
[1] Teixeira B,Singh V,Chen T,Ma K,Tamersoy B,Wu Y,et al. Generating synthetic X-ray images of a person from the surface geometry. Proceedings of the conference on computer vision and pattern recognition,CVPR 2018. June 1823,2018,Salt Lake City,UT. IEEE; 2018. p. 905967.
[2] Ronneberger O,Fischer P,Brox T. U-Net: convolutional networks for biomedical image segmentation. Proceedings of the international conference on medical image computing and computer-assisted intervention,MICCAI 2015. October 59,2015,Munich,Germany. Springer LNCS 9351; 2015. p. 23441.
[3] Maas AL,Hannun AY,Ng AY. Rectifier nonlinearities improve neural network acoustic models. In:Proceedings of the ICML workshop on deep learning for audio,speech,and language processing,WDLASL 2013. June 16,2013,Atlanta,GA.
[4] Ghesu FC,Georgescu B,Zheng Y,Grbic S,Maier AK,Hornegger J,et al. Multi-scale deep reinforcement learning for real-time 3D-landmark detection in CT scans. IEEE Trans Pattern Anal Mach Intell 2019; 41.
卷积神经网络与传统的机器学习不同的是,卷积神经网络需要大量的数据来进行模型训练;另一方面,卷积神经网络不需要人工(人为)提取特征,也不需要图像分割(见图 5.26)。虽然卷积神经网络在图像识别和分类方面特别出色,但如果图像有改变(如旋转或任何与先前呈现不同的方向),它就会有困难。卷积神经网络和医学图像的其他问题是它对小数据集的限制,以及它的过度拟合问题。最后,由于深度学习很难解释,其缺乏透明度是采用卷积神经网络的一个严重问题。
有许多关于深度学习和医学图像的优秀的综述文章(见“放射学和心脏病学”),可通过有用的图表进行深度讨论。在最近的生物医学文献中,卷积神经网络的一个例子是斯坦福大学的研究小组使用超过 5 万名患者的单导联心电图对 12 个节律类别的各种诊断类别的心电图进行了解释,受试者工作特征曲线(ROC)的AUC为 0.97,平均F1 score(阳性预测值和灵敏度的加权平均值)为 0.84 [30] 。
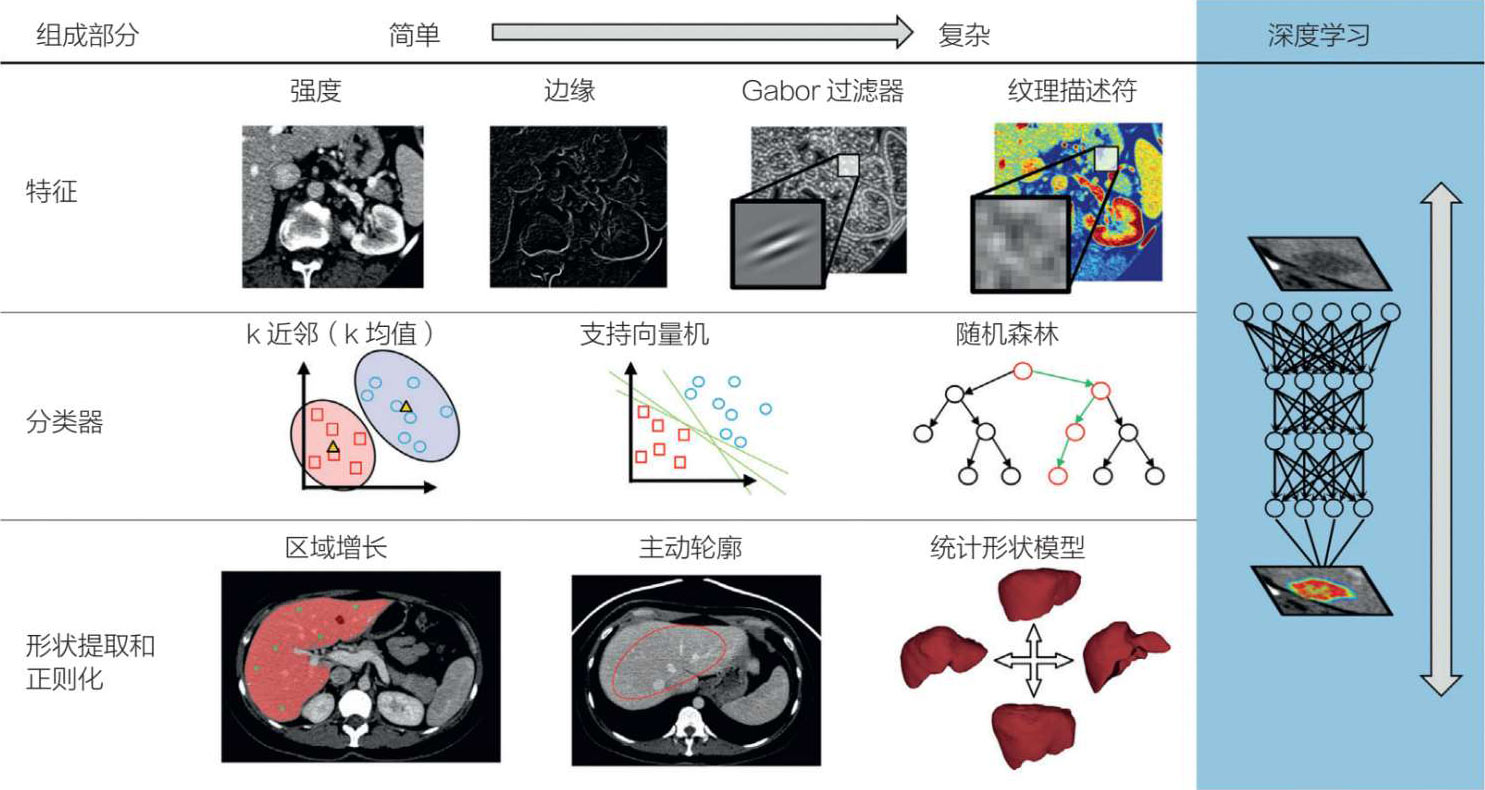
图 5.26 深度学习和特征
埃斯特班·鲁宾斯
作为一名人工智能和数据存储专家,埃斯特班·鲁宾斯撰写的这篇评论讨论了一个美好愿景,即卷积神经网络和人工智能用于医学图像解读,加上联合学习,将医学图像解读和教育带到世界各地。
根据泛美卫生组织(世界卫生组织的一部分)的数据,世界上约有三分之二的人口无法获得诊断成像。此外,70%至 80%的诊断问题可以通过基本的X射线或超声波检查来解决 [1] 。在医疗界,“少花钱,多办事”是一句口号,而寻找“唾手可得的果实”是首要任务。因此,将诊断成像技术带给大约 50 亿缺乏这种技术的人,似乎是一个成功的提议。不幸的是,障碍是巨大的:成像模式很昂贵,而在这些医疗服务不足的人群中,放射科医生很稀缺 [2] 。
成像方式的进化并没有使最基本的成像方式(X射线和超声)变得更加普遍,尤其是在发展中国家的偏远地区。幸运的是,最近固态技术的进步引发了超声成像的革命性飞跃。传统的超声模式需要基于压电晶体的昂贵且易碎的换能器,而现在有可能通过利用制造计算机芯片的技术来生产被称为“电容式微机械超声换能器”的微型机器,从而超越这一模式 [3] 。这些新的固态传感器生产成本低,足够坚固,可以在现场使用,更重要的是可以连接到智能手机上,而不需要一个笨重的专用计算机控制台。即使是最基本的智能手机,其重要的计算和网络能力也为这些新的传感器和所需的软件提供了一个强大的平台。
我们可以设想,只具备基本技能的医疗工作者将这些新的便携式即时超声(POCUS)设备带到以前没有超声成像的地方。它们可以脚踏实地获取图像,甚至受益于嵌入式人工智能来引导它们进行最佳的探头定位,从而采集最佳的图像。然而,将成像技术带到世界的偏远地区只是第一步。如果没有放射科医生来解释这些图像,那么获取好的图像又有什么用呢?
也许不出意外,人工智能可以弥补这一差距。众所周知,人工智能的一个子集,深度学习——以卷积神经网络和其他类似算法的形式,与诸如在放射学、心脏病学和其他类型的医学成像中遇到的计算机视觉问题完全匹配 [4] 。卷积神经网络可以按照通常意义上的敏感性和特异性进行非常准确的培训,公认的标准是,卷积神经网络至少应该与接受过专业培训的放射科医生一样好。达到这种准确度要求的关键是要有大量的标记数据。在医学成像的背景下,“标记数据”是指图像本身和放射学报告以及所有可用的元数据,如注释、分割数据和其他任何由放射科医生(或其他医生)阅读图像时作为解释过程一部分产生的数据。
一旦有了标记数据的训练数据集,就可以对深度学习模型进行训练。这个训练过程是迭代的,需要多次运行,并在每个阶段调整神经网络的参数,以达到尽可能低的误差。最终的目标是建立一个训练有素的模型,在接触到未标记数据时提供准确的推断或预测。那么,一个合理的设想就是将这样一个训练有素的卷积神经网络嵌入到低成本、耐用、便携式的POCUS中,可以在全球范围内应用,以改善数十亿人的健康状况,这些人在此之前一直被医疗系统边缘化。这些人工智能驱动的POCUS(人工智能-POCUS)将大大增强人类放射科医生的能力,通过快速分流正常图像,将它们从PACS阅读工作列表摘取出来,自动解释明确的病例(正常或有结果被发现),并只将有相关病理的非明显图像传送到PACS,由放射科医生来解释。
但解决方案并不那么简单。我们知道用单一人群的数据训练卷积神经网络的结果是,模型不能很好地推广到全球人群 [5,6] 。因此,有必要用标记的图像编制庞大的全球训练数据集,以训练可以在世界上大片地区有效使用的卷积神经网络。这种大规模的健康数据收集工作是不现实的,甚至是不可能的。私人健康数据,包括成像数据在世界范围内受到严格监管,这是有充分和适当理由的。此外,许多国家限制健康数据的流动性,使其无法离开其国界,这就是所谓的数据驻留要求 [7] 。
那么,如何才能确保人工智能-POCUS为全世界数十亿医疗服务不足的人带来好处,同时又不侵害他们的健康数据隐私,并在无数不同的法律框架的指导下保护这些数据呢?了解一下联合学习。联合学习 [8] 是由谷歌研究人员在 2017 年首次提出的,它的工作原理是将一个卷积神经网络模型提供给多种便携式设备。每个设备都用自己的本地数据进一步训练卷积神经网络,这些数据永远不会离开设备。重新训练的模型被上传到中央存储库,那里附加的软件将所有新接收的模型合并成一个新训练的卷积神经网络,其中包含了每个本地设备贡献的所有改进方案。这个过程反复进行,直到达到所需的精度水平,或者持续不断地继续改进。
训练数据不能脱离每个本地设备,模型是加密的,并且这一方法使得合并前不会检查本地设备的任何一个更新。联合学习,最初与放射科医生一起,可以成为实现全球模型训练合作的关键,从而实现预期的目标,向数十亿从未从中获益的人首次提供医学成像。我们不可能对这一重要前景不抱希望,这种新技术(POCUS和联合学习)的结合能够对数十亿人的生活产生巨大的积极影响,而这些人无法从现代医学成像中获益并不是自己的过错。
[1] Pan American Health Organization. World radiography day: two-thirds of the world’s population has no access to diagnostic imaging,https://www.paho.org/hq/index.php? option5com_content&vie w5article&id57410:2012-dia-radiografia-dos-tercios-poblacion-mundial-no-tieneacceso-diagnostico imagen&Itemid51926&lang5en.; 2012 [accessed 30.04.19].
[2] Lungren MP,Hussain S. Global radiology: the case for a new subspecialty. J Glob Radiol 2016;2(1) Article 4.
[3] IEEE Spectrum. New“ultrasound on a chip”tool could revolutionize medical imaging,https://spectrum.ieee.org/the-human-os/biomedical/imaging/new-ultrasound-on-a-chip-tool-could-revolutionize medical-imaging.; 2017 [accessed 30.04.19].
[4] Chartrand G,Cheng PM,et al. Deep learning: a primer for radiologists. RadioGraphics 2017;37:211331,https://doi.org/10.1148/rg.2017170077.; [accessed 30.04.19].
[5] Saria S,Butte A,Sheikh A. Better medicine through machine learning: what’s real,and what’s artificial. PLoS Med 2018;15(12):e1002721 ,https://doi.org/10.1371/journal.pmed.1002721. [accessed 30.04.19].
[6] Zech JR,Badgeley MA,Liu M,Costa AB,Titano JJ,Oermann EK. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study. PLoS Med 2018;15(11): e1002683 ,https://doi.org/10.1371/journal.pmed.1002683. [accessed 30.04.19].
[7] Information Technology & Innovation Foundation. Cross-border data flows: where are the barriers,and what do they cost?,https://www.itif.org/publications/2017/05/01/cross-border-data-flows-where-are barriers-andwhat-do-they-cost.; 2017 [accessed 30.04.19].
[8] Federated Learning. Collaborative machine learning without centralized training data,https://ai.googleblog.com/2017/04/federated-learning-collaborative.html.; 2017 [accessed 30.04.19].
这是另一种类型的深度神经网络,包括一个反馈回路,后一个状态取决于之前的状态,如图5.27 所示 [31] 。简而言之,每个神经元都有元素的嵌入式存储。因此,循环神经网络能够拥有一个活跃的数据记忆网络,称为长短期记忆网络,或LSTM网络。门控循环单元(GRU)是LSTM的一个变体,它在结构上与LSTM相似,但更简单(2 个“门”对比 3 个),不占用内部存储器。因此,循环神经网络能够调用存储器,因为有更长期的依赖关系(与卷积神经网络相比),所以它适合于时间性或连续数据(金融交易数据、音乐段落或语言模式以及连续的生物测量,如血压和心率)。
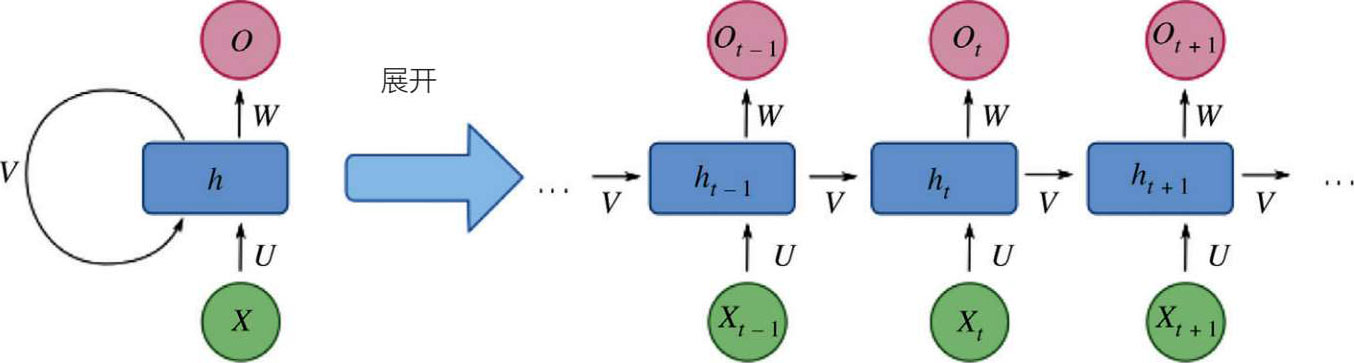
图 5.27 循环神经网络
对循环神经网络的简单讨论包括两个实体:隐马尔可夫模型和神经网络图灵机。隐马尔可夫模型更像一个基于马尔可夫链的随机过程,并做出马尔可夫假设(未来的状态只取决于现在的状态,而不取决于之前的状态;因此是“无记忆的”)。隐马尔可夫模型和循环神经网络一样,处理连续数据,但它是一个更简单的线性模型,而循环神经网络则更复杂(更具适应性)并且是非线性的。此外,循环神经网络没有马尔可夫特性,所以它们可以容纳长距离的依赖关系。NTM是一种循环神经网络,它扩展了神经网络的概念,并将其与逻辑流和外部(无限)存储源结合起来。NTM有四个组成部分:控制器、神经网络、存储器以及读写头。
因此,循环神经网络有两个优点:它可以通过使用反馈连接来存储信息,并且可以学习连续数据。这种类型深度学习可以用来重复相同的任务,以获得相互依赖的连续信息(如ICU环境中的时间序列或股票市场分析以及语言生成或翻译)。循环神经网络的缺点是循环计算速度慢,而且往往很难获取过去的信息。
最近生物医学文献中有一个例子是使用独立的循环神经网络通过脑电图对癫痫发作(相对于非癫痫发作)进行分类,用一种新的方法来扩大时间尺度,对诊断有卓越的效果 [32] 。另一个例子说明了循环神经网络在电子病历上的工作,它表明可以直接从电子病历数据中用FHIR标准为各种临床场景建立准确的预测模型(见图 5.28) [33] 。
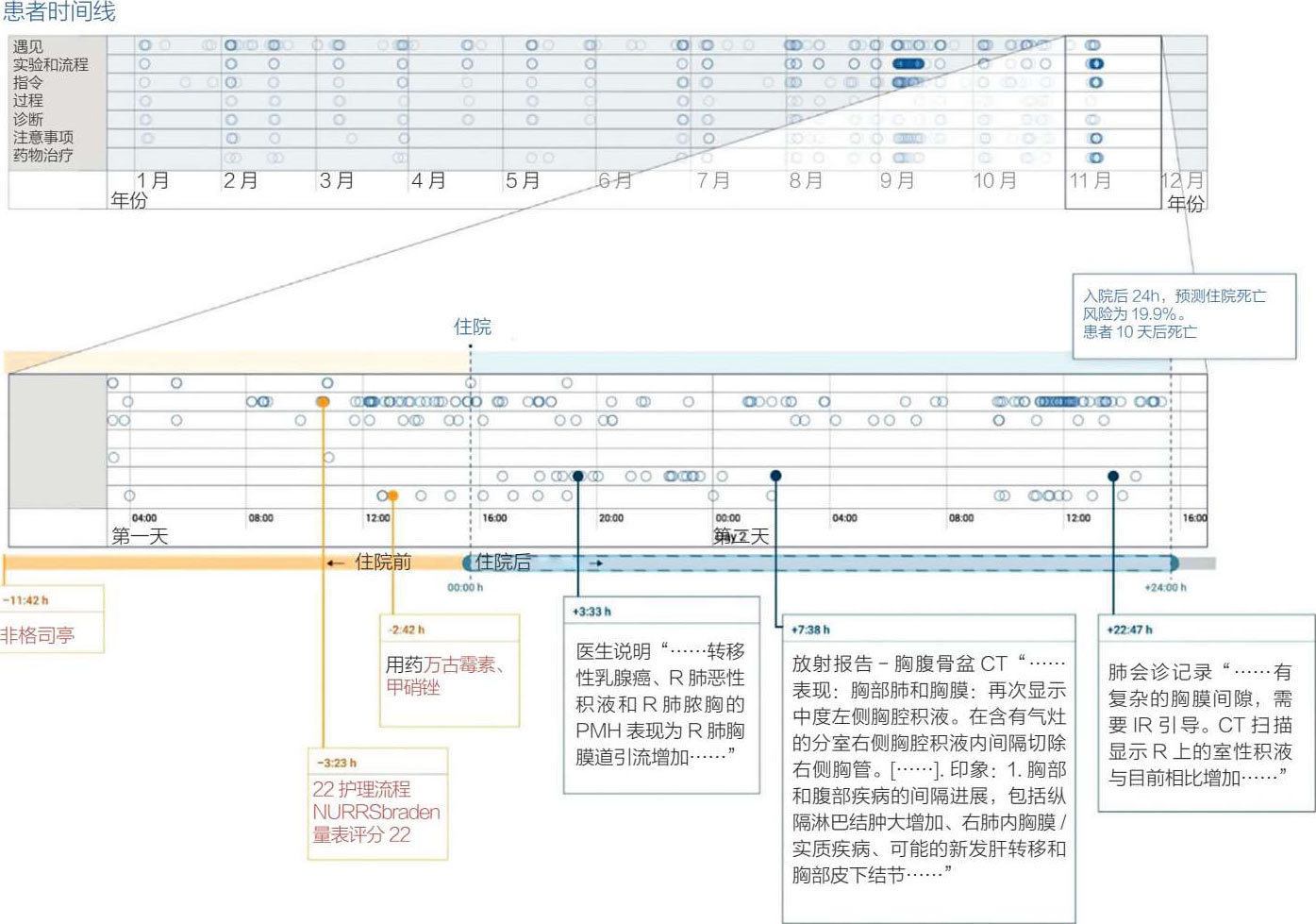
图 5.28 患者记录和死亡率预测
简而言之,卷积神经网络适合于空间数据,而循环神经网络是为顺序或时间数据设计的。然而,有一种混合的“CNNRNN”模型(也称为循环卷积神经网络,或循环卷积神经网络(RCNN),但不要与区域卷积神经网络、R-CNN混淆),在生物医学数据中具有一定的潜力,如多标签图像分类和序列复杂生物医学数据。
在最近的生物医学文献中,RCNN的一个例子是可摄取的无线胶囊内窥镜技术,使用RCNN为内窥镜胶囊机器人操作提供可靠的实时单眼视觉观察方法 [34] 。新颖的RCNN结构对内窥镜视频帧之间的顺序依赖和复杂的运动动态进行建模。