
下载掌阅APP,畅读海量书库
立即打开



数据科学包含数据挖掘以及机器学习,这两个领域有一些重叠,因此读者可能会混淆。数据科学家可以利用数据挖掘结合数据库和统计方法来从数据中提取信息(比如显现模式),而机器学习被数据科学家用来给机器提供学习的机会。换句话说,数据挖掘更多是一种信息来源,机器学习从中受益(具有自动学习和预测能力)。这两种数据挖掘方法是关联规则挖掘,它描述了属性之间的关系,但受到其二进制性质的限制和为连续和时间数据设计的连续模式发现的限制。
机器学习被定义为机器从其任务的经验中学习的能力,在我们的社会中被广泛使用(从搜索引擎到垃圾邮件过滤)。机器学习这一术语最初由阿瑟·塞缪尔在 1959 年提出的,是人工智能的一个越来越流行的子学科,是计算机编程的艺术,使计算机在没有外部程序指示时能够学习并提高性能。换句话说,在机器学习中,算法会自我改进,并从试验和错误中“学习”,就像人从经验中学习那样。
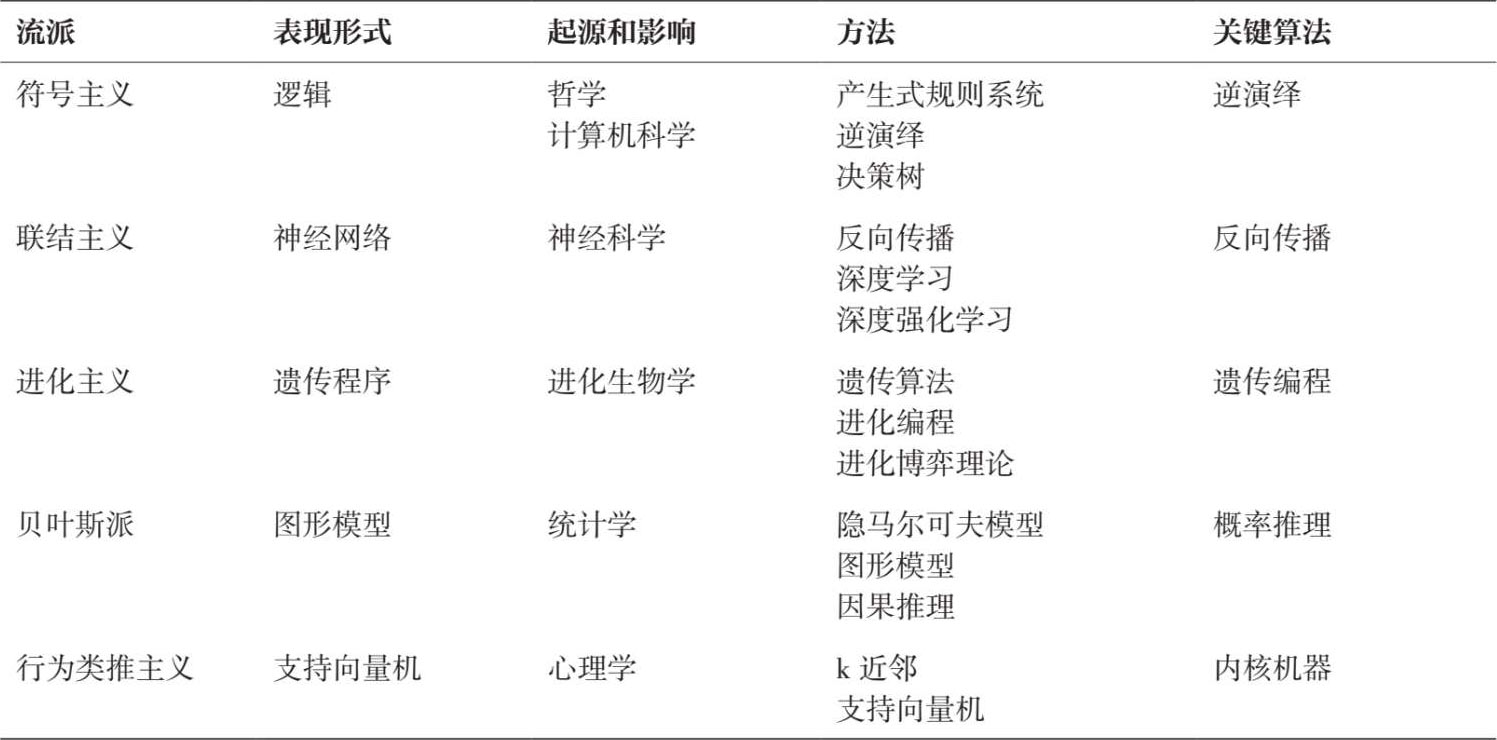
派多·多明哥在他的《主算法》一书中描述了机器学习的五个流派或“部落”,它们共享一个范式,即发掘隐藏在数据中的知识。他提出,一个主算法需要来自五个流派的每一个元素(见表 5.1)。
符号主义显然是早期人工智能时代的主力军,贝叶斯派在这一时期也有不错的表现,但很明显,目前的时代主要由联结主义主导(特别是自 2012 年以来流行的深度学习算法激增)。希望某一天能努力将所有五个流派统一成一个“主算法”。
表 5.1 机器学习中的五个流派
在传统编程中(见图 5.1A),数据(输入)和计算机程序(规则)输入计算机(步骤 1)后得出答案(输出)(步骤 2)。然而,在机器学习中(见图 5.1B),计算机同时使用数据(输入)和相应答案(输出)(步骤 1),通过检查数据中的模式(步骤 2)得出“规则”(从而从数据中“学习”)。然后将这些新的规则应用于新的数据以获得答案(预测)(步骤 3)。后一种“自下而上”的方法明显不同于传统编程(如前面提到的基于规则的专家系统),传统编程中,人将指令输入计算机,让它遵循指令(因此是一种“自上而下”的方法)。机器学习也不同于传统的统计分析(也是像编程一样“自上而下”的,通过统计规则分析数据以产生输出或答案)。简而言之,机器学习从输入和输出数据中“学习”,并找到将输入数据与输出数据联系起来的模式,然后将从机器学习中学习到的这些模式(以模型的形式)应用于新数据,看模型如何拟合数据。
复杂而高效的算法(完成特定任务的一组步骤)的出现不仅可用于计算和数据处理,还可用于自动推理,这提高了机器智能的能力。目前使用的复杂算法的例子包括皮克斯为虚拟空间中的3D人物着色(渲染算法)和NASA对国际空间站的太阳能板的操作(优化算法)。甚至最近有史以来首次拍摄的Messier 87 星系的黑洞照片也是由数据科学家和一种新的算法(使用补丁先验的连续高分辨率图像重建,也叫CHIRP)帮助完成的,该算法将来自一系列虚拟望远镜的数据放在一起,将其渲染成一个地球大小的巨型望远镜。
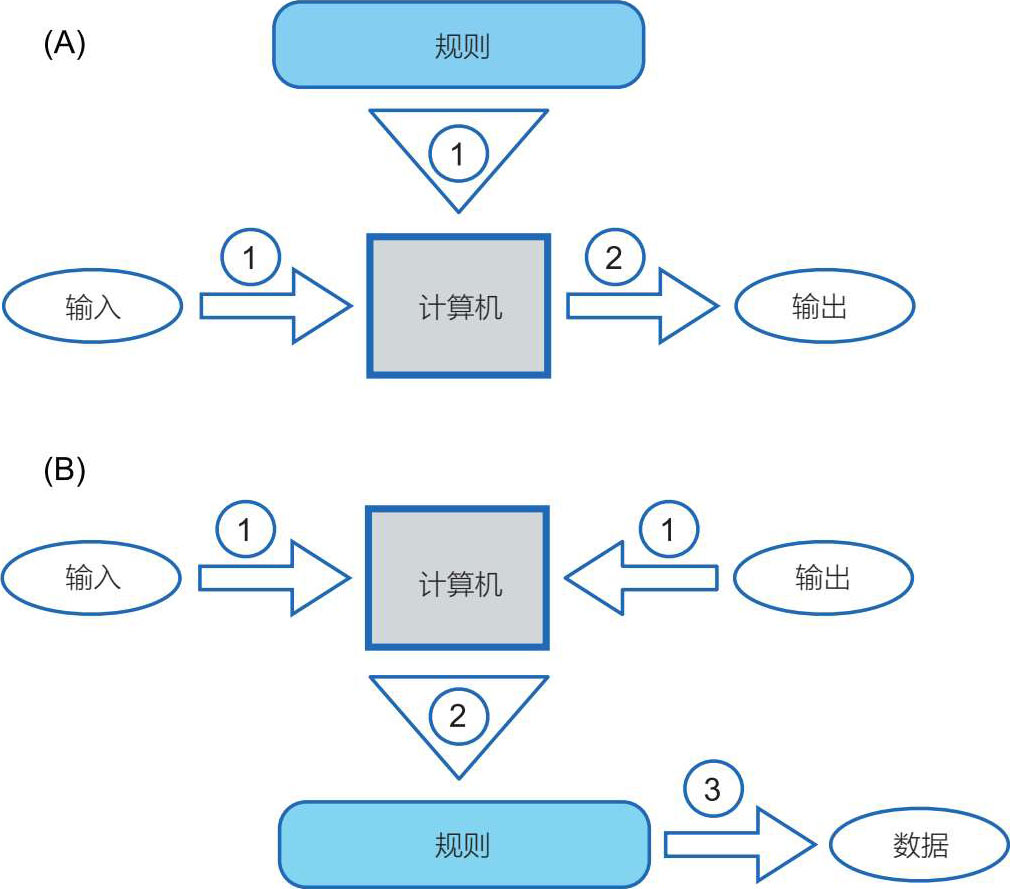
图 5.1(A)传统编程和(B)机器学习
以下是对有监督学习的机器学习工作流程步骤的简要描述,也适用于无监督学习,只需稍作改动(见图 5.2)。
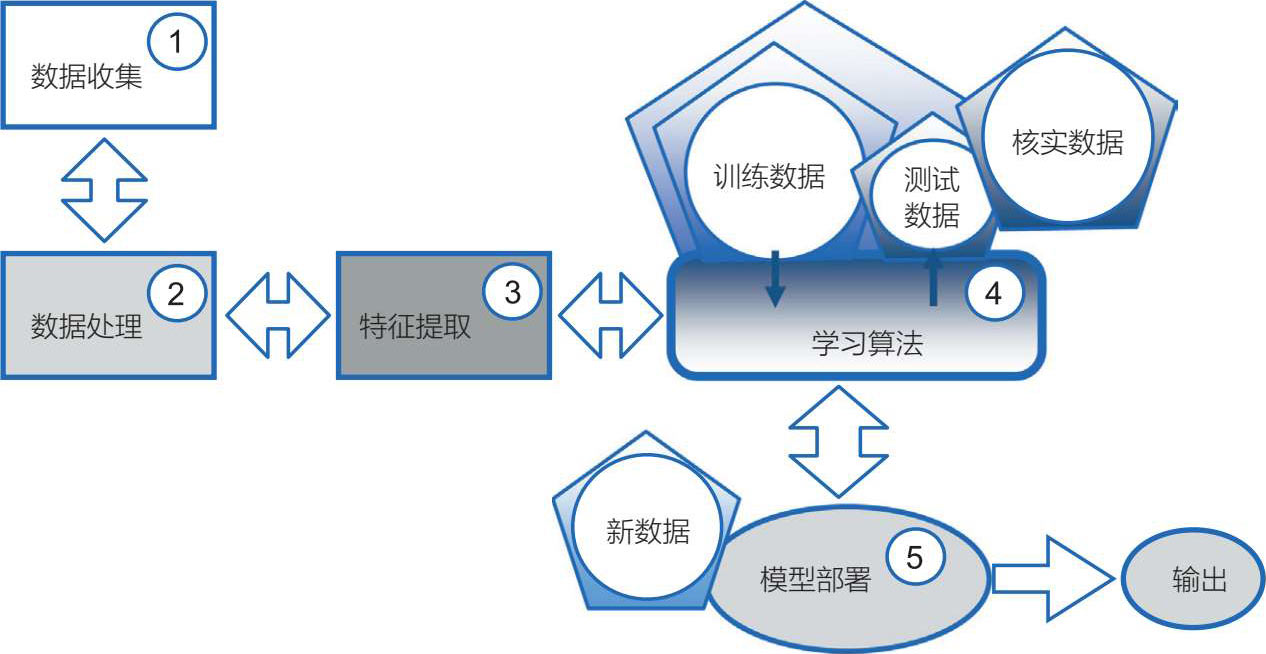
图 5.2 机器学习的工作流程
数据收集(步骤 1)。在收集数据之前,团队小组应该讨论项目的预期目标,明确收集数据的方向。达成共识后,成员们就可以帮助收集相关的数据,以进行下一个重要步骤,即准备数据。数据收集有时是具有挑战性的,这取决于机构的数据采集和存储能力。在医疗领域,数据大多是非结构化的,并以许多不同的格式存储(当前的程序术语和ICD-10 代码、遭遇信息、人口统计数据、药物、护士和医生记录、生命体征等),数据场所也不同(医院、诊所和现在的可穿戴设备),这使得数据收集的过程特别繁琐。
数据处理(步骤 2)。收集数据后的这一步涉及利用数据处理工具,将数据清理、准备并组织成更结构化的格式,以便使用机器学习方法。数据准备包括缺失值处理、不平衡数据处理、离群点检测和标准化等措施,还有数据整理或数据挖掘,这些术语描述了将数据从步骤 1 的原始形式转换和映射到另一种对后续步骤更友好的格式的过程。这一步可能需要数据转换(表、逗号分隔值等)和数据平台(使用Hadoop、MapReduce、Cassandra等)。数据整理涉及疾病诊断数据的分组(手术及操作、并发症、合并症等)。
收集和处理数据的步骤经常会占用数据科学家做项目所需的大部分精力和时间,特别是在临床环境中。随着人工智能在医学领域的项目变得更加普遍、水平更加成熟,希望这两个步骤在未来更加高效。
特征提取(步骤 3)。特征,也被称为变量或参数,是数据的“列名”(如血压、患者姓名和药物),而例子是实际的数字或数据。特征提取的这一步骤首先涉及特征的选择,这是一种战略性的选择,只选择能建立良好预测模型的相关特征。特征选择之后是特征提取,它将现有的特征转化为一组新的特征,而这组特征最有可能形成一个好模型。特征工程是利用领域的专业知识对特征提取进行完善。值得注意的是,表征学习是一种不涉及特征工程的机器学习,是一种在建立分类器时更容易提取到数据的有用信息的方法。
学习算法(步骤 4)。这一步涉及算法的学习,以得出最佳的预测模型,对未来的新数据产生从卓越性能的预测。这一子步骤涉及一个数据集的使用,并将其分为两个较小的数据集:训练数据(通常是两个中较大的,约占 70%)用于训练(或“适应”)模型或算法,较小的测试数据子集被封存,然后在最后以无偏的方式用于评估最终选择的模型的泛化误差。根据标记数据集的可用性和大小,可以分配第三个较小的数据集作为验证数据(也比训练数据集小,与测试数据集大小相似),用于估计模型选择的预测误差。过度拟合(后文的欠拟合会进行详细讨论)发生在数据与训练数据的拟合过于紧密时,但最终对其他数据集的泛化效果不佳。
模型部署(步骤 5)。最后一步是为了应用和完善新数据在现实生活中的预测模型。评估模型的性能,必要时完善新数据或项目的算法。机器学习算法中内置的优化或损失函数等措施能够提高预测能力或性能,这使得机器学习“学习”并自我改进。
朱斯·佘曼
本篇评论的作者朱斯·佘曼是生物医学中设计思维的坚定支持者,这篇评论的内容是设计科学,及其如何通过这个问题的解决来影响医疗领域的数据科学。
设计思维从很多方面来看是一个明显的人类过程。它要求设计者与用户感同身受,以了解用户的真正需求,它坚持“以人为本”的方法,通过想象出满足明确需求或潜在需求的理想解决方案来解决问题 [1] 。虽然我喜欢用现有的工具成为一名研究员和医疗设备设计师,但我可以想象出通过人工智能优化我工作的无数方法。也就是说,人工智能将加强设计思维过程中的迭代和测试阶段。
人工智能已经从多方面改变了生物医学领域。举几个例子,它有助于为临床试验收集实时、真实的数据;它可以在几秒内测试数百万种复杂的相互作用以评估药物疗效;它已被证明可以评估大量的数据,来提供高度准确的诊断,有时甚至超过受过训练的专家。假肢设计是一个很好的例子,它证明了人工智能的应用可以带来更好的结果 [2] 。机器实时测量能够帮助制造商了解用户的步态如何变化,或者他们的身体是如何适应于一个额外的人造肢体。这些数据使制造商能够对这些可穿戴产品进行个性化设计,远比最初的设计要好。
从本质上说,人工智能将提供个性化的解决方案。一旦人工智能成为设计思维过程的常规部分,它将使生物医学产品更好地适用每个人。由于人工智能能够动态合成一致的用户反馈,它将帮助设计师、工程师和制造商能够更精确地进行快速迭代。
想象一下另一幅场景——一套护肤品自带配套的智能手机应用程序,这套应用程序会提醒消费者在使用产品时拍摄皮肤照片,这样人工智能就可以扫描图像,以评估肤色、痤疮或细纹的改善情况,然后应用程序可以将信息反馈给产品制造商,这样制造商就可以调整配方,在消费者重新订购产品时给他带来更好的效果。产品将与之前不同。它将随着消费者的皮肤改变而变化,不断改善结果。这就是生物医学人工智能的未来:基于测量结果的快速迭代改进,是设计思维过程的支柱。
我们正处于一场革命的开始。人类现在正以一种前所未有的方式与计算机融合。数据汇总方面的创新和增材制造工艺的进步代表了字节和原子的惊人融合。因此,机器将逐渐接管设计思维的许多步骤,除了构思、测试和完善之外,还包括研究和综合推理。
在一个越来越自动化的世界里,人类的主要角色将更加“元化”。曾经负责从头开始起草概念并将规格传递给开发者或制造商的设计师们,将转型为“设计科学家”。这些设计科学家将为嵌入软件系统的人工智能校准价值、选择参数,并应用相关的美学模型。它们将被用来构思程序和工具,这些程序和工具将协调一系列复杂的步骤,以便模拟我们曾经以手工方式来做的事情。
设计科学家将与程序员、数学家和统计学家一起工作,以创建实用的设计流程工具,利用各领域成功创新的数据,将这些知识应用于医学和医疗产品设计的创新之中。这种新模式确实会使设计思维过程自动化,但是,机器可能仍然无法改进寻找需求的最初步骤,这往往需要人与人之间的共情和长期的愿景。然而,在人工智能的帮助下,人类将能够使用综合数据(即有意义的数据)来增强他们对用户的同理心。
“设计科学”正在诞生。为了充分发挥其潜力,医生、计算机科学家、患者和设计师之间的跨学科合作将是关键的方式。
[1] Brown T. Design thinking. Harv Bus Rev,June 2008;8495.
[2] Berboucha M. Artificial intelligence and prosthetics join forces to create new generation bionic hand. Forbes Jul 13,2018.
数据科学被认为是数学和统计学(包括建模和生物统计学)以及计算机科学(编程、数据概念和数据挖掘)的交叉。目前的人工智能在医学中用于生物医学数据科学的范式正在为计算机科学和数学开拓另一个知识领域:生物医学(生物信息学和临床信息学以及生物学、遗传学和基因组学、医学和健康科学)。生物信息学是一个专注于收集和分析复杂生物数据(特别是遗传信息)的领域,而临床信息学(或生物-医学信息学)是对医疗数据和信息方法的研究和实践。两者不仅与生物医学数据科学有关,而且与医学和医疗保健中的人工智能密切相关。
现在一些项目和医院提供生物医学信息学的奖学金,有临床信息学的委员会认证。在奥兰治县儿童医院,有一个试点项目配有一名在生物医学数据科学和人工智能领域的高级研究员。在不久的将来,将有许多类似这样的专业培训职位和教育,作为大多数子专业的子领域。
瑞恩·康奈尔
病理学家和信息学家瑞恩·康奈尔撰写了这篇关于敏捷数据科学这一未来概念的评论,在这一医学领域,人们可以在很短的时间内,不需要几周或几个月,只需要几分钟到几小时,就可以查询大型数据库并回答问题。
敏捷数据科学的理念与不断提高的能力有关,即:
1.获取大型数据集;
2.快速解析数据;
3.实时积极调整查询;
4. 使用已有的平台和库,而不是重新开发工具。
尽管存在许多监管和财政障碍,用于研究的健康信息数据库的可用性正在缓慢提高。其中一个数据库是重症监护医疗数据库III(MIMIC-III),它包含了 2001 年至 2012 年期间在贝斯以色列女执事医疗中心接受重症监护的 4 万多名患者的去标识化数据。下载MIMIC-III数据库有几种选择,包括数据库表的平面文件副本。还有用于成像研究的数据库,如NIH发布的胸部X射线 14 数据集,其中包含超过 10 万张胸部X射线图像。
一旦获得这些数据集,无论是否符合HIPAA,都可以很容易地购买存储和计算能力,该领域内的供应商数量越来越多。分析大型数据集所需的计算能力通常可以通过云计算资源来满足,亚马逊Web Services和微软Azure是云计算服务的最大供应商。对云计算工具的需求主要取决于专门的弹性计算实例的可用性。弹性意味着可以实时评估更多的计算资源,或根据需要缩小规模。这种向弹性云资源的转变使得主要的电子病历供应商之一开发了使用云计算资源作为基础计算引擎的敏捷数据科学工具。这些用于数据科学的敏捷云计算工具通常使用Jupyter作为基础前端编程界面。Jupyter Notebook的开源计算环境支持Python和R等这样的解析数据所用的编程语言,因为Jupyter的使用与编程语言无关,并支持多人协作。这也有助于调查人员实时解析数据、操作查询和可视化结果。快速循环提问和可视化数据的过程可以对临床问题或理论进行反复评估和改进。最后,一旦确定了有临床影响的项目,使用开源的机器学习库,如Pytorch和TensorFlow,可以大大缩短十年前可能需要几个月的时间的开发过程。这些云计算工具还提供了使用Apache Spark进行大数据分析的最新技术。Spark是一个并行的分布式云计算编程范式,它提供了一个更快速的分析、预处理和模型开发方式,它处理的数据集往往过大,无法存储在一台计算机中。事实上它是实时模型开发、更新和实施的工具。
为了说明敏捷数据科学的概念,推荐的实验是获取一个免费使用的数据集,并组成一个包含至少一名临床专家和一名数据科学家的团队。然后让临床专家确定他们感兴趣的患者队列,并提出他们在该队列中最关心的结果。然后,团队审查数据集中的可用元素,并确定哪些变量可能有助于确定结果。可以使用患者人数和简单的描述性统计作为整个过程的“完整性检查”,当队列变得很小或数据未能通过“完整性检查”时,团队可以迅速转换他们的调查或深入研究字段中可能存在的错误(缺失或重复计算)的原因。这个阶段的分析是数据预处理的一部分,通常需要数据科学家或其他分析师花费最多的时间。但利用敏捷数据科学工具,可以进行极为快速的预处理,以确定研究的可行性,并建立初始模型作为预测模型的预期性能衡量标准。数据科学家、领域专家(如供应商)和敏捷数据科学工具的结合将有助于彻底改变整个数据科学过程,加速医学以及其他应用领域的发现。
生物医学数据科学团队由以下成员组成。
数据科学家是非常全面的,他可以承担一个数据科学项目,通过机器学习开始数据收集,到数据可视化结束。数据科学家的技能包括数学和统计分析、数据仓储、工程以及编程技能(尤其是R、Python和SQL)。
数据工程师(也被称为数据库管理员或数据架构师)主要专注于用软件工程处理和管理大型数据集,以便数据科学家可以处理这些数据集。数据工程师主要使用Hadoop、NoSQL和Python(但通常不使用R,因为机器学习通常不在他的技能范围内)。
数据分析师通常更关注业务,利用Excel、Tableau和SQL等工具为企业提供数据的可视化展示和交流。数据分析师通常不直接开展数据科学项目,所以他们的技能通常不包括机器和深度学习而是专注于数据仓储和基于Hadoop的分析,并熟悉数据架构和提取、转换及加载工具。取决于机构的情况,这些人员可能向C-suite中的同一个人或不同的领导报告。根据个人的技能和经验以及偏好情况,这些职位的描述有相当多的重叠。
这一数据科学团队通常与医疗机构的领导团队或公司的首席执行官合作。首席信息官(或信息技术总监)通常是该组织信息技术部门的最高层管理人员。首席医疗信息官(或首席健康信息官)通常负责组织中的健康信息部门,是临床和信息技术领域之间的联络人。首席技术官(公司中比医疗机构中更常见)通常是知道如何将软件货币化并处理软件工程问题的人。最后,首席智能官或首席人工智能官(目前非常少,医疗机构中尤其少)全面了解人工智能,也对人工智能项目的评估和部署有经验。
戴维·兰德拜特
戴维·兰德拜特是一家儿童医院的高级数据科学家,他很长时间都在重症监护环境中与临床医生一起度过。他撰写的这篇评论,阐明了临床医生和数据科学家之间的文化差异以及合作过程。
数据科学家现在是医疗机构中的一个重要资源。他们的多种技能可以增强机构的能力,包括帮助分析和可视化数据,建立数据基础设施,以及最典型的训练机器学习模型以做出具体的预测。尽管如此,绝大多数数据科学家缺乏必要的临床基础,这使得他们难以正确理解临床环境。他们很难知道哪些问题是与临床相关的,这阻碍了他们提供可操作情报的能力。
另一方面,临床医生因为每天治疗患者,非常熟悉临床环境和术语,而这些对数据科学家来说可能是难懂的,甚至更糟。临床医生知道自己面临什么问题,也知道需要什么信息来做出更明智的决定,以及这些信息用于临床工作流程中的哪个环节。然而,大多数临床医生不是数学家,他们不适应那些大到无法用Excel分析的数据集。临床医生通常被训练成从P值和R值的角度来考虑问题,而不是使用更务实的样本外的表现来评估。
临床医生和数据科学团队之间存在着天壤之别。最重要的是,这两组人所使用的语言对彼此来说很难理解,比如增压剂、流体或呋塞米等专业术语。临床医生考虑的问题是解决方案如何适用于临床工作流程及其易用性(比如需要在电子病历中点击多少次),而数据科学家往往关注深奥的误差函数,如接收操作特性或算法的技术新颖性(比如是否能将此提交给NeurIPS),如果二者没有相互沟通的能力,就会存在无法克服的问题。要解决这些问题,需要两种思维方式的合作。
为了帮他们减少这种分歧,重要的是为数据科学家提供尽可能多的接触临床的机会,一个好方法是让数据科学家们观察晨间查房。这提供了一个很好的视角,让数据科学家了解到临床部门的运作和真正紧急的生死问题。数据科学家可以亲眼看到信息是如何在护士、医生、家长和患者之间传递的,并深入了解了临床团队使用哪些信息以及如何在临床工作流程中做出决策。他们可以开始了解他们解决方案之间的相关性。
数据科学家与临床医生合作解决具体问题也很重要,这保证了问题可以从临床和数据科学的角度分析,从而可以协同实现适合临床工作流程的可行方案。数据科学家能够与临床医生一起讨论问题,实现关键性的突破,从单纯优化成本函数到理解在选定阈值下部署模型的临床意义以及成本分析的四个象限(真阳性、真阴性、假阳性和假阴性)的影响。
合集涉及下列过程中的每一步:
1.构思——我在ICU中发现了什么问题?
2.设计——在什么时间提供什么信息会有帮助?
3.整理——这些值实际上意味着什么?
4.评估——这是否可以在病床边使用?
能够从临床角度分析模型的失败,往往会对模型中出现的问题产生实际性的见解;找到共同的线索和系统性的问题将额外细化和改进模型。
在数据科学和临床团队之间建立一种共同的文化尤为重要,这一点怎么强调都不为过。提醒这两个团队,数据科学家不仅仅是坐在电脑屏幕后面的机器人,医生也不仅仅是……医生。采取一些辅助性的活动,如一起团建享受快乐时光,或一起去唱卡拉OK,使两个小组都能感受到对方人性化的一面。
让临床医生接触到数据科学世界也很重要。让临床医生旁听数据科学讲座,从概念上了解数据科学家是如何思考问题的。临床医生努力理解和揭开数据科学家的工作内容、方式和限制,从而获益。数据科学家所做的事没有比逻辑回归更复杂的了。随机森林只是大量的随机二元分割;神经网络只是堆叠的逻辑回归。说到底,数据科学家只是试图通过数据拟合一条线。
优秀的数据科学家和优秀的临床医生最宝贵的特征是沟通、倾听和学习的能力。不幸的是,不是每个人都是天生的沟通者,但沟通是一种技能,它可以像其他技能一样通过练习和磨练而获得。没有沟通能力,总会有一些力不能及的项目。
重要的是要记住,这两个群体都想解决问题,以帮助改善患者的医疗状况。携手同行,火星和金星可以理解真正的问题是什么、如何做出决定,以及在临床工作流程中可以提供哪些可行的信息。
安娜·古登伯格
安娜·古登伯格是一名数据科学家,曾经进入一家儿童医院的临床科室,这段经历对她来说是一笔宝贵的财富。她这篇评论就这两个领域的文化差异以及如何在医疗环境中有效实施人工智能提供了个人观点。
学习交流。什么是特征?是输入空间的一个维度。什么是输入空间?是所有你想用来进行结果预测的数据。你实际上如何学习模型?我们优化目标函数。什么是目标函数?是一个数学结构,通常代表预测结果和实际结果之间的误差,即我们目标减少的数量。还有很多像这样的例子。临床医生需要知道所有这些术语吗?不需要。机器学习者在与临床医生讨论时,会不会无意中使用这些类似的术语?很可能。在开始与临床医生合作之前,我并没有意识到机器学习的语言到底有多高的技术含量。经过多年的实践以及与临床医生和生物学家的交谈,我才明白,我们的合作者想知道的是我的模型将为他们做什么,而不是它到底是如何工作的。
接受不确定性。机器学习的一个重要部分是不确定性。我们经常开发概率模型来评估患者A是否患有疾病亚型X或Y,而不是直接预测诊断。考虑到我们用于学习的不完美数据,用概率比用确定性来表示模型的结果更令人满意。然而,在临床实践的早期我就被告知,我的临床合作者必须给患者一个诊断,他们想看看我的算法预测的是什么诊断,而不是概率。但事实是,医学上的意见不尽相同。从最不确定的急诊科到最确定的重症监护室,不确定性是无处不在的。承认我们知识的局限性并接受概率是很重要的。我相信在临床领域,理解不确定性将有助于在未来更好地利用机器学习工具。作为机器学习者,我们必须继续努力,使我们的概率结果更经得起临床解释的检验。
解释黑箱模型,或者不解释。另一个有趣的、热议的、持续的讨论是围绕人工智能的不可解释性,即黑箱模型。许多临床医生表示他们永远无法信任这样的系统。同时,许多临床医生承认他们不能总是解释他们所做的决定,而是根据他们以前的经验来做决定,这是他们多年来观察患者而形成的“内部分类器”。如果连人类都在创造内部复杂的模型,对其进行事后解释,为什么人工智能算法的标准会高得多?当临床医生要求设计他们能理解的模型时,又出现了另一个问题,即人类推理显然不能在高维度上进行,那么谁说人类的推理是最好的方法?也许,对模型可解释性的要求是根据这些工具的及时性和强大的功能来要求的,或者临床医生只是要求有一个清晰可信的方式来与系统互动。尽管机器学习从业者对可解释性的原因和目的存在分歧,甚至对可解释性在这一背景下的真正定义也存在分歧,但追求建立可信和可靠的模型以及用户可以轻松互动的模型在目前看来是许多建立医疗人工智能模型努力的核心。我非常希望通过临床医生和计算机科学家的共同努力,找到一条建立精确、值得信赖的模型的道路。
带着计算机科学的背景来到临床领域,就像搬到一个新的国家,需要学习一种新的语言,进入一个陌生的价值体系、规则和条例中,当然还有陌生的习性。这是一个学习和沉浸在专业知识中的绝佳机会,同时也会让人感到沮丧,因为无法获取相关数据、即使数据可用也可能存在许多缺失的数值和记录。尽管临床数据有许多不完善之处,与之打交道很困难,但通过与临床专家的多次交流,可以填补许多空白。总的来说,能够帮助具有疾病谱和特定条件的弱势群体获得更精确的诊断、预后和治疗是令人振奋的。正如我的研究生导师所说,能说这句话真的很棒——“让我看看,我是一个计算机科学家!”我相信我正在实现这个梦想。
有几种编程语言对于对人工智能和生物医学数据科学感兴趣的人尤其有用:
Python是一种非常灵活且相对简单的编程语言,可用于多种用途,它可以说是数据科学中最流行的语言。此外,Python有许多特殊的库(包括NumPy和Pybrain,分别用于科学计算和机器学习)。
R是统计学习和数据分析的常用编程语言,在数据的可视化呈现方面非常强大。R往往在学术机构中更受欢迎。像Python一样,R也是开源的,在R综合档案网络(简称CRAN)中有许多机器学习的库(如Gmodels、Class和Tm)。
MATLAB是MathWorks公司的高级编程语言,具有用于数值计算以及可视化和编程的交互环境。被广泛用于科学和工程领域。
统计分析系统是一种相对昂贵的商业分析软件,提供大量的统计函数。
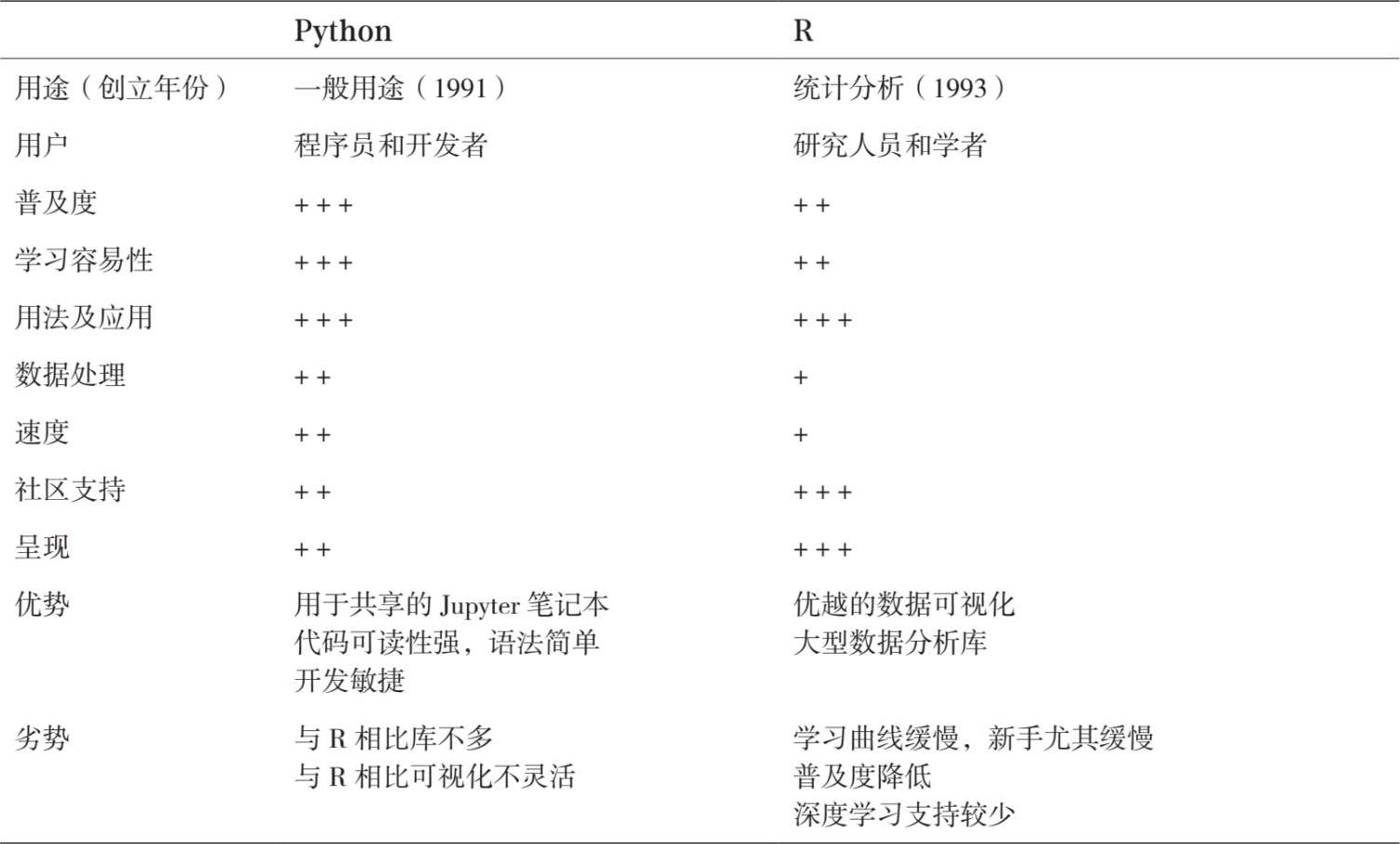
然而,生物医学数据科学领域中进行的大多数争论是关于Python和R哪种作为首选语言。表 5.2 有助于说明它们各自的优势和劣势。
对于那些在预测分析领域工作的人来说,R比Python更受欢迎(SAS在编程偏好上与R接近)。对于数据科学家来说,Python在普及程度上比R略胜一筹(而且这种差异似乎正在扩大)。总的来说,如果对高效部署更感兴趣,Python更有优势;如果更注重统计分析,特别是数据的图形展示,R会是一个稍好的选择。
这两种编程语言对于机器学习和人工智能来说都很出色。一位数据科学家巧妙地打了一个比方:R更像蝙蝠侠,他聪明,脑力大于体力;而Python更像超人,他强壮,体力大于脑力(与蝙蝠侠相比) [1] 。作者同样打了个比方,Python更像你日常上班用车,功能齐全,能完成工作;而R是你周末用的高级跑车,适合炫耀。也许,我们可以考虑一个综合的视觉效果:开着丰田普锐斯的超人(代表Python)和开着保时捷的蝙蝠侠(代表R)。
表 5.2 数据科学与人工智能中的编程语言:Python与R的对比
还有几个框架和库经常用于人工智能项目中。Hadoop(Apache软件基金会)不是一种编程语言,而是一个开源的框架(通常用Java编写,但并非总是如此),它包含一套工具(比如分布式文件系统和Map Reduce编程模型),用于在商品硬件上存储和处理大量数据。TensorFlow(Google Brain)可能是用于DL的最知名的人工智能库(用C+ +、Python或CUDA编写)。其灵活的架构能够适应各种平台,不仅有中央处理单元(CPU)和图形处理单元(GPU),还有TPU,Google的张量处理单元。最后,Keras是一个开源库(用Python编写),可以在TensorFlow之上运行,但它更像是一个高级应用编程接口,用于训练深度学习模型。其他深度学习库和框架包括Caffe(B人工智能R)、Theano和MXNet。
罗伯特·霍伊特
罗伯特·霍伊特是一位临床信息学医生,他热衷于向临床医生教授临床信息学和数据科学。他撰写的这篇评论,为新手数据科学家提供了一个简短的介绍以及机器学习的实用资源。
人工智能普遍存在于所有行业,包括医疗行业,并且是生物医学数据科学家的重要技能。人工智能最重要的组成部分之一是机器学习,它使用算法,从简单的决策树到复杂的神经网络来进行预测并解决问题。机器学习是当今临床决策支持和风险预测的中坚力量。
由于机器学习起源于计算机科学,非计算机科学系通常不教授。教授时通常需要高级数学和/或编程经验。因此,大多数信息学的研究生没有学习过机器学习。同样,临床和护士信息学家通常也不了解机器学习。虽然他们不一定需要在机器学习方面有丰富的经验,但他们应该熟悉机器学习的核心概念,并熟悉可用的软件。随着医学领域接触到生物医学数据科学和人工智能,我们需要探寻如何改善教育方法,并寻找为完成这项任务需要的软件。
较新的工具(很多是开源的)正在开发中,这些工具简化了统计学、编程语言和机器学习,使得非计算机科学专业的学生和医疗工作者可以更多地参与到生物医学数据科学中。此外,这些较新的工具大多支付得起,不需要昂贵的软件使用权。例如,Jamovi是一个基于R编程语言的免费统计程序 [1] 。Rattle是R的免费图形用户界面,面向预测性分析,并与教科书关联 [2] 。
也有负担得起并且直观的机器学习软件。WEKA、KNIME、Orange和RapidMiner等程序是机器学习的主要开源软件 [3-6] 。不同于KNIME和Orange,WEKA不需要操作视觉运算符来创建工作流程。WEKA是相当直观的,并且与大量的算法、教科书和许多免费的在线课程相关联 [7,8] 。
最容易学习和使用的现代机器学习软件平台之一是RapidMiner,这个平台对教师和学生免费。它包括TurboPrep等工具,可以加速早期数据准备(探索性数据分析)。自动模型是一个直观的功能,可以进行监督和无监督学习,自动选择并同时运行多个适当的算法,例如分类或回归。还可以使用标准参数(如曲线下面积)自动生成性能结果,并对其进行比较。还可以使用滑块创建动态模型,以便调整预测变量(自变量)并查看对结果(因变量)的影响。
无监督学习也同样是直观的。可以选择使用k-均值,必须设置聚类的数量或选择x-均值,由它决定数据集中聚类的数量。
使用WEKA时,可以调整算法,但在RapidMiner中不能。对于大多数机器学习用户来说,在他们学习基础知识和适应机器学习的时候,这是可以接受的。
这些机器学习程序的简单性将使教师更容易教授基本的机器学习。有了今天的机器学习软件选择,不再有理由不熟悉机器学习,所以机器学习有可能被更多人理解和采用。
[1] Jamovi. ,https://www.jamovi.org.
[2] Rattle. ,https://rattle.togaware.com/.
[3] WEKA. ,https://www.cs.waikato.ac.nz/ml/weka/.
[4] KNIME. ,https://www.knime.com/.
[5] Orange. ,https://orange.biolab.si/.
[6] RapidMiner. ,https://rapidminer.com/.
[7] Witten I,Eibe F,Hall M. Data mining: practical tools and techniques. 4th ed. Morgan-Kaufmann;2017. ,https://www.cs.waikato.ac.nz/ml/weka/book.html.
[8] Free online courses on data mining with machine learning techniques in WEKA. ,https://www.cs.waikato.ac. nz/ml/weka/courses.html.
罗布·布里斯克
罗布·布里斯克是一位具有数据科学背景的心脏病专家,他以临床医生和数据科学家的双重视角撰写了这篇评论,并对机器学习/深度学习的可解释性提出了自己的见解,认为机器学习/深度学习并不是非常难以实现的。
机器学习:通往未来医学的敲门砖
人工智能是一种广泛应用的技术,但如今机器学习的技术爆炸特别推动了其在医疗中的应用的讨论。从广义术语的角度,“经典”编程要求人类软件工程师阐述一套精确详尽的基于语言的规则,使计算机能够将一些输入数据转化为预期的输出数据,而机器学习允许我们通过获得(通常是大量的)输入数据和输出数据的匹配来生成计算机程序,然后让机器学习算法识别一套基于逻辑的规则,将输入数据转化为输出数据。
这在两种情况下是有利的:第一,在自动化任务中,人类在部分潜意识水平上执行,因此不能阐明所有需要的步骤;第二,可访问的一组输入数据可能与一组输出数据具有某种因果联系,但是人类专家不能辨别前者映射到后者的模式。临床领域的两个例子分别是:从动态心电图信号中检测心律异常,以及从脑成像中检测初期阿尔茨海默病,脑成像似乎包含诊断线索,但放射科医生无法检测出异常 [1,2] 。
“黑箱效应”:没有透明度还能有信任吗?
当软件工程师为一个计算机程序编写内部逻辑时,他们通常以一种基于语言的格式来编写,这样可以由理解该语言的人询问。相反,管理机器学习系统行为的规则往往被编码在意识头脑无法解释的复杂数学架构中。图 5.3 所示的是一个可视化的基本人工神经网络算法(最复杂的机器学习算法类型,它是深度学习应用的基础)。已经有很多人试图用显著性图、卷积网络的去卷积等方法来解释这种算法中的编码规则。这些方法可以对系统功能的某些方面提供有用的见解,但更广泛的内部逻辑仍然是不透明的。
这在临床环境中的重要性在于,即使一个机器学习系统已经经过高质量数据的广泛了解和验证,也很难预测它何时以及如何违背操作者的期望。家长都能很好地理解这个概念:我们可以根据大量的观察数据来开发和验证儿童行为的预测模型,这个模型在绝大多数时候是可靠的。然而,支配儿童行为冲动的内部逻辑的不透明性意味着家长不可能预见到儿童何时以及如何混淆预期。例如,我们大多数人预见到,如果我们离开房间一会儿,我们的孩子会继续好好玩耍——这很可能是基于以前无数次观察到的模式——但当我们回来时却发现墙上涂满了蜡笔痕迹。
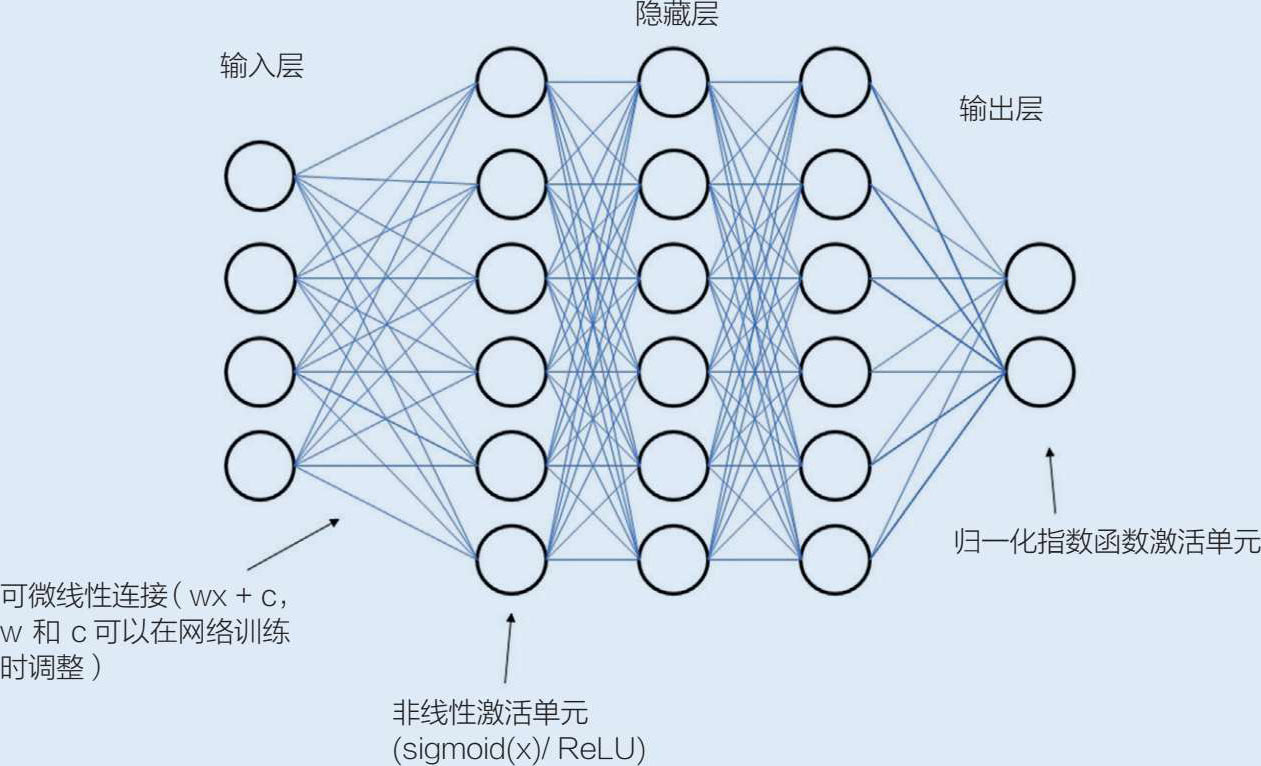
图 5.3 一个基本的人工神经网络
现实世界的例子可以考虑Google算法,它将一对加勒比黑人夫妇的照片标记为大猩猩,还有特斯拉的自动驾驶系统由于没有检测到卡车停在路上而导致了致命的碰撞,尽管事故报告得出的结论是,在卡车撞击前整整 7 秒内对汽车可见 [3,4] 。前一个例子发人深省,因为如果Google都不能对他们的机器学习算法施加足够的控制来避免公共关系方面的灾难,那么人们一定会思考数字健康领域的小公司将如何发展。从医疗保健的角度来看,后者甚至更引人担忧,因为它体现了在高风险环境中依赖不透明技术的潜在严重后果。
人们正在广泛认可对人工智能透明度的需求,尽管如何实现这一点对于监管机构来说仍然是一个未解决的问题 [5,6] 。在这一方面,DeepMind和Moorfields眼科医院之间的合作取得了显著的成功,对光学相干断层成像术的解释可以分为几个部分,并在每个步骤中生成人类可读的可视化诊断过程 [7] 。医学的其他领域也逐渐开发出了类似的方法,尽管将这种框架应用于对人类来说不太直观的任务可能是具有挑战性的,如多元组学分析。
归根结底,作为临床医生,我们有责任为患者提供高质量的医疗服务。因此,至关重要的是,我们要共同了解新兴技术,并开始研讨各种机制,使我们能够以安全负责的方式利用机器学习的巨大潜力。
[1] Rajpurkar P,Hannun AY,Haghpanahi M,Bourn C,Ng AY. Cardiologist-level arrhythmia detection with convolutional neural networks. July 6,2017. arXiv: 1707.01836.
[2] Ding Y,Sohn JH,Kawczynski MG,et al. A deep learning model to predict a diagnosis of Alzheimer disease by using F-FDG PET of the brain.Radiology 2019;290(2):456-64.
[3] Hern A. Google’s solution to accidental algorithmic racism: ban gorillas. The GuardianJan12,2018.,https://www.theguardian.com/technology/2018/jan/12/google-racism-ban-gorilla-black people. [accessed 09.06.19].
[4] Stewart J. Tesla’s autopilot was involved in another deadly car crash. Wired Mar 30,2018.,https://www.wired.com/story/tesla-autopilot-self-driving-crash-california/. [accessed 09.06.19].
[5] The European Commission High Level Expert Group on Artificial Intelligence. Ethics guidelines for trustworthy AI.,https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai.; 2019[accessed 09.06.19].
[6] The US Food & Drug Administration. Proposed regulatory framework for modifications to artificial intelligence/machine learning (AI/ML)-based software as a medical device (SaMD)——discussion paper and request for feedback. ,https://www.fda.gov/media/122535/download.; 2019 [accessed 09.06.19].
[7] De Fauw J,Ledsam JR,Romera-Paredes B,et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat Med 2018;24(9):1342-50.
机器学习,或更准确地说,经典机器学习,更适合于较小的、不太复杂的数据集以及特征较少的临床场景。经典机器学习分为两种类型:监督学习和无监督学习(见图 5.4)。后文也会对半监督和集成学习以及深度学习进行补充讨论。
图 5.4 机器(经典)和深度学习
监督学习采用优化的原始数据,并使用一种算法来预测结果(该算法源自之前研究的标记数据,标记数据来自之前描述的过程中的训练数据集)。换句话说,训练数据有助于通过算法引导机器进行正确的预测或输出,从而使模型可以用来对新数据进行预测。主动学习是一种监督学习,它通过抛出查询让用户确定数据的标签,避免手工标记大量的样本。
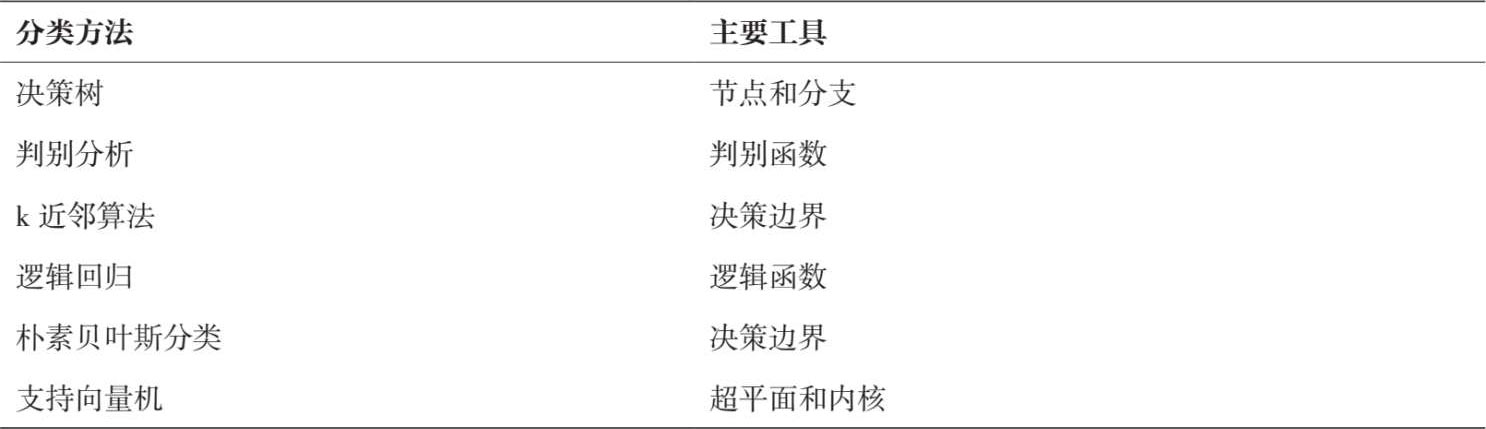
简而言之,监督学习从输入和输出数据(后者由人工标记)中开发出一个预测模型,然后这个模型被用来对新的数据集进行预测。这些监督学习方法引导了分类(二分法或明确类别)或回归(连续变量)。对于分类,常用的方法是支持向量机(支持向量机s)、朴素贝叶斯分类、k近邻算法和决策树(增强算法或袋装算法);逻辑回归这一说法是错误的,它实际上也是一种分类方法。对于回归,线性和多项式回归方法是最常用的,但其他类型(如岭回归和LASSO回归)在未来可能会变得更受欢迎。
这种方法可以得到预测或者分配一个标签或类别给未标记样本,例如,磁共振成像的“肿瘤”与“非肿瘤”。分类策略有利于欺诈检测和面部识别。在医学和医疗保健领域,分类有利于医学图像、表型分型和队列识别。
表 5.3 列出了监督分类方法,但其只对较常见的方法进行详细描述。逻辑回归(这其实不恰当,因为它不是一个真正的回归,而是一个分类方法)包括在这个分类中。
表 5.3 监督学习:分类方法
(1)支持向量机(SVM)
这种“最大距离”的分类方法是通过在高维空间中创建一条线或一个最佳超平面(一个决策面)来实现的,该超平面代表了两个类之间的最大分离(见图 5.5)。一般来说,这种分离度越大,支持向量机的性能就越好。最接近边界的点被称为“支持向量”。支持向量机有两种形式:一种是线性支持向量机:使用线性优化来实现线性分离(如果可能的话),这种方法相对较快(类似于逻辑回归);另一种是内核支持向量机:使用许多不同种类的分割结构,称为内核(注:我们说的内核技巧是一种数学技巧,它增加了一个额外的维度。在有限的维度中不可能实现的事情现在可以用更多的维度来实现)。简而言之,内核以非线性的方式划定边界(可以是曲线,也可以是最佳平面)。
常见的用途是垃圾邮件过滤、情感分析、图像分类和分离、手写字符的识别和欺诈检测。
这种流行但相对复杂的机器学习方法的优点是可以很好地处理输入特征和输出之间复杂的非线性关系。这种方法通常被认为是最准确的分类算法之一,特别是当有大量特征(与数据点的数量相比)时,因此它对高维数据很有效。支持向量机也很稳健,因此可以避免干扰,并尽量减少过度拟合。小的训练数据集不能很好地扩展到更大的数据集,因此经常使用支持向量机(更大的训练集可能更适合其他分类方法,甚至DL)。线性支持向量机被认为是相对较快的(但准确度较低),而内核支持向量机的分类可能更准确(但速度较慢)。
它的缺点是支持向量机需要高水平的内存和处理能力,而且难以解释输入特征和输出之间的精确关系。
最近生物医学文献中的一个例子表明,支持向量机在基于CT的影像组学特征中的应用,仅在 227 名患者中有效地识别了高和低等级的透明细胞肾细胞癌,曲线下面积(AUC)值为 0.880.91 [2] 。
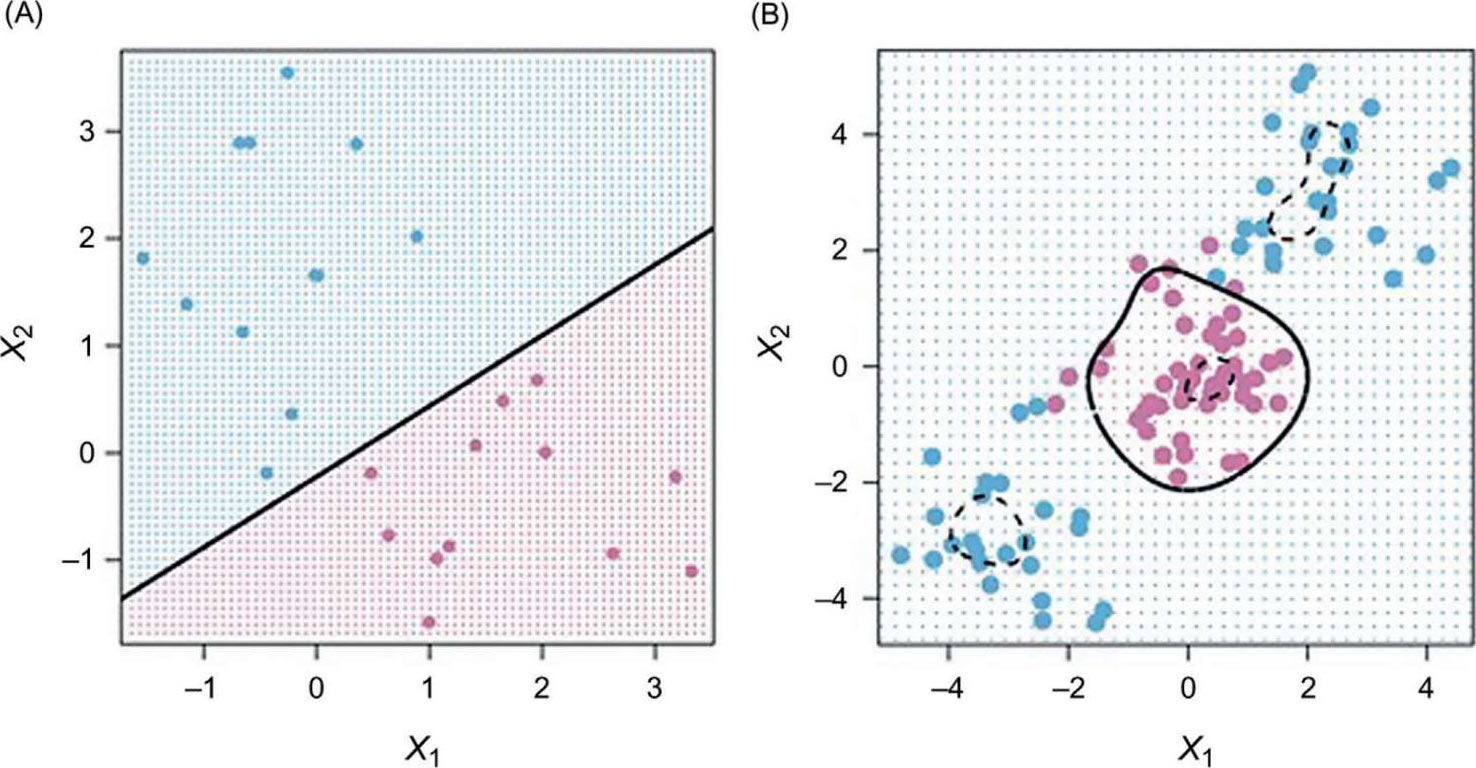
图 5.5 支持向量机
(2)朴素贝叶斯分类
这种监督学习方法应用概率对数据进行划分或分类,并基于贝叶斯定理(其先验概率的概念指选择概率最高的结果)。其假定是,预测因子是相互独立的(因此称为“朴素的”),所以模型本质上成为一个概率表,其中某个特征的存在不依赖于任何其他特征。简而言之,某一结果的概率是由特征给出的概率的乘积。分界线,即贝叶斯决策边界(见图 5.6),用于将样本分成两个总体。
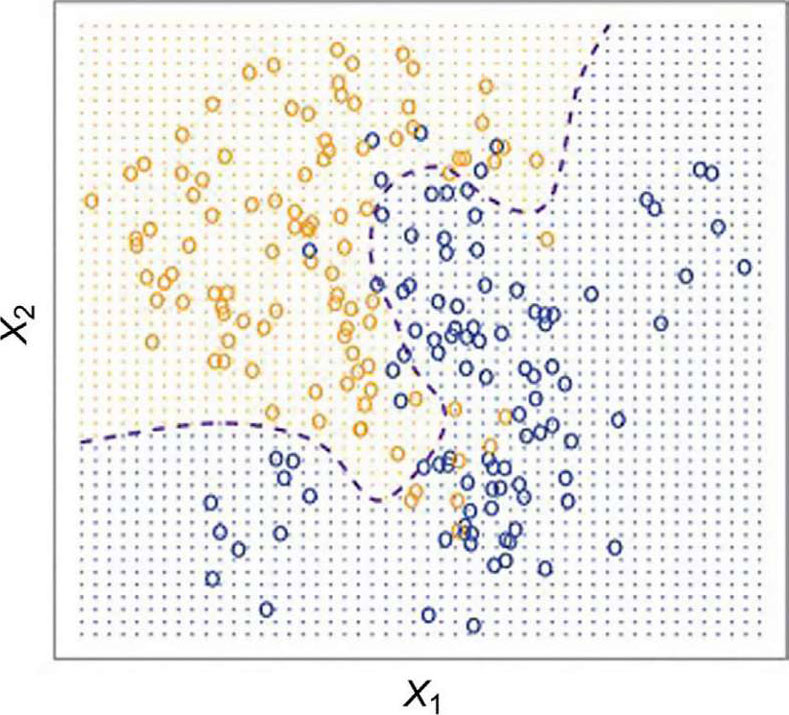
图 5.6 朴素的贝叶斯分类器
这种方法非常适用于实时预测、文本分类/垃圾邮件过滤和推荐系统。
这种监督学习方法的优点是利用统计建模,具有相对较快的速度(给定并行过程),并且存在高维输入时也较好。贝叶斯概率方法的另一个优点是它不需要大量的训练集,并且实施和解释起来相对简单。然而,由于其相对较快的速度,在准确性方面有所折衷(与刚才讨论的内核支持向量机相比)。
它的缺点是由于基本原则是特征完全独立(这种情况不常见),在低维数据中性能水平相对较低。
最近生物医学文献中的一个例子是将贝叶斯网络模型应用于病理信息学,通过构建几个贝叶斯网络模型来评估个体对后续特定病理诊断的患者特异性风险,并与妇科细胞病理学和乳腺病理学的预后相关 [3] 。
(3)k近邻算法
这种监督学习算法既可用于分类,也可用于回归,它可以识别任何元素的近邻数量,因此k近邻这个名字很贴切(见图 5.7)。k是特征空间中最接近指定点的近邻的整数,类别由该空间中观察到的多数决定,例如,如果k是 3,3 个邻居中有 2 个是某个类别,那么这个类别“胜出”。与刚才讨论的贝叶斯分类类似,决策边界称为k近邻决策边界。
k近邻算法很适合用于文本挖掘或分类,以及股市趋势预测。
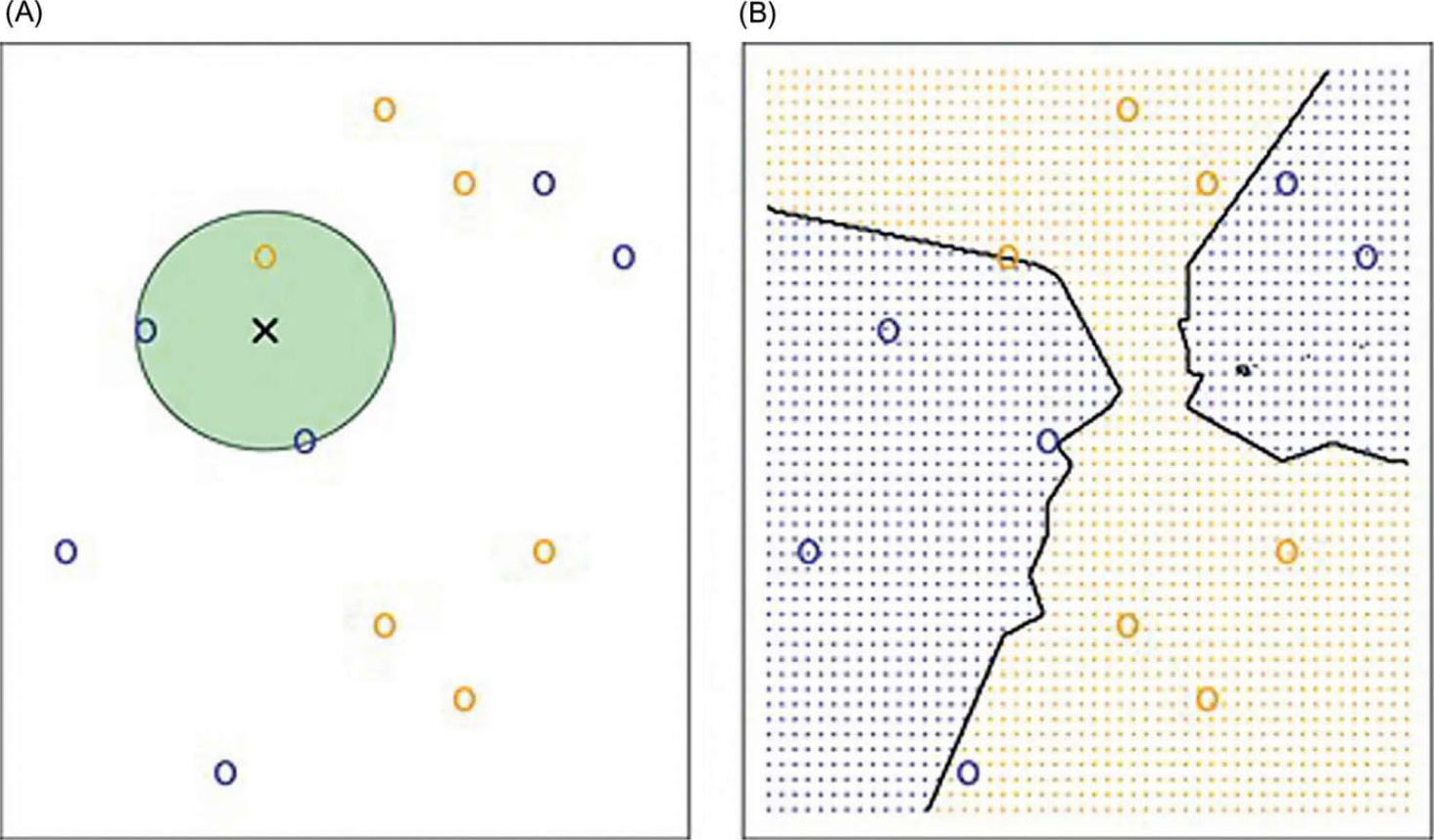
图 5.7 k近邻算法
这种方法的优点是解释相对简单,因此被认为是一种基于实例的“懒惰”学习(与基于模型的学习相比)。k近邻算法很适合于那些没有关于数据分布的先验知识的数据集。像上述提到的一些监督方法一样,它对有噪训练数据相对稳健。
缺点是k近邻算法在处理高维数据或可能包含噪声和细微差别(如缺失数据)的大量数据时表现不佳,但这种算法本身可以用来进行缺失值的估算、噪声过滤和数据还原 [4] 。k近邻也容易受到维度的影响的出现过度拟合。还有就是k值对模型的性能有很大的影响。
最近的生物医学文献中的一个例子是将改进的k近邻算法(实例增强权重)应用于糖尿病视网膜病变患者,以获得更准确的诊断 [5] 。
(4)决策树
决策树方法是最直接的方法(也称为分类和回归树,或CART),树是倒着画的,决策点被称为节点,连接节点的树段被称为分支(见图 5.8)。因此,叶子是结果。为了保持树状结构,计算中的“修剪”过程可以在不牺牲模型精度的情况下缩小树的大小。这种有监督的方法在决策中使用树枝来实现分类(但也可用于回归);然而,人们认为决策树不像上述其他方法那样准确。因此,要用决策树建立更强大的预测模型,有三种策略是必要的:袋装算法(bagging)、自适应增强算法(boosting)和堆算法(stacking)(见后文集成学习)。
这种方法的优点具有更高的可解释性,因为它有更高的关联性(与前面讨论的其他分类方法相比),并且更容易可视化,因为它有良好的图形表示。决策树对噪声和不完整的数据相对稳健。决策树对非线性关系以及异常值也非常包容。与其他方法相比,它也有相对较快的速度。
决策树的缺点包括,它们不像监督学习方法中的其他方法那样准确(但像逻辑回归那样相对快速和高效)。然而,这些树通常需要是集成格式,更精确并且不容易过度拟合。另外决策树往往不能很好地处理小的训练数据集。
图 5.8 决策树
最近生物医学文献中的一个例子是将决策树(与风险评分相比)应用于预测耐药性感染,在对 1200 多名患者的研究中,发现决策树(使用 5 个预测因子)对用户更友好,最终用户变量更少 [6] 。
有监督的回归方法输出变量的数值表示,以预测一个数字。回归适用于市场预测、增长预测和预期寿命计算。在医学和医疗保健领域,回归有利于风险预测和结果预测。
表 5.4 列出了回归方法,但这里仅详细讨论线性回归和多项式回归。
表 5.4 监督学习:回归方法

(1)线性回归
这种回归可能是临床医生最熟悉的方法。这种机器学习方法(源于统计学)描述了两个连续变量(x是自变量,y是因变量)之间的关系强度。线性回归中拟合回归线的方法是相关系数为r的最小二乘法。当存在单个输入变量时,这种回归被称为“简单回归”,当存在多个输入变量时,被称为“多元回归”(见图 5.9)。还有一种是多项式(或非线性)回归,其中的关系不是线性的。此外,广义线性模型(GLM)是一种泛化的普通线性回归,适应非正态分布的变量。最后,LASSO回归通过执行正则化(一个减少过度拟合的过程)和变量选择来提高其预测精度。
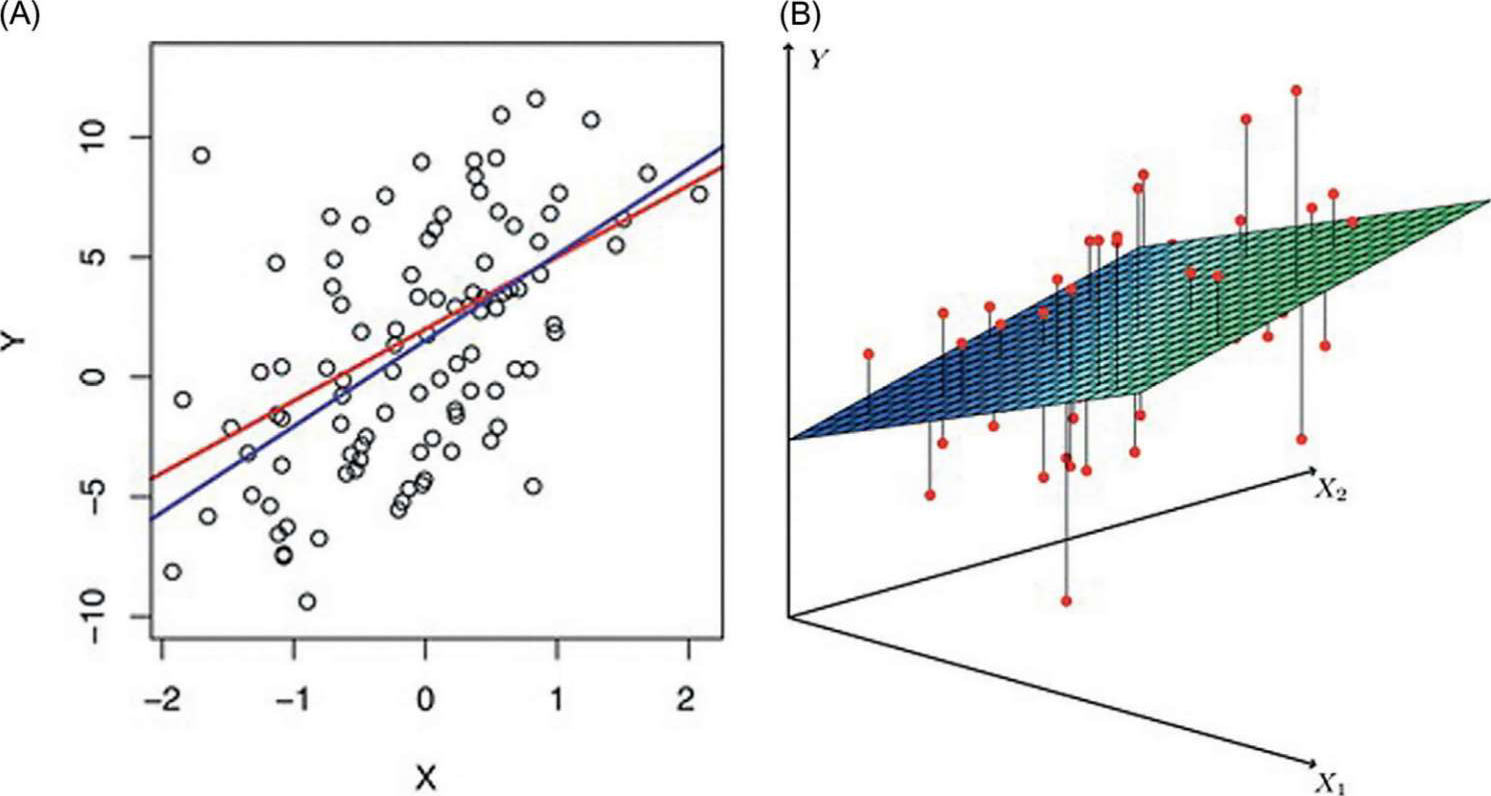
图 5.9 线性回归
对于没有接受过正式数据科学教育的人来说,线性回归的优点是它是最熟悉的回归方法。与其他回归方法相比,线性回归快速但可能不精确。当存在非线性关系时,线性回归的表现较差。简单线性回归通常不那么准确,考虑到LASSO和岭回归是正则化的(惩罚大系数),过度拟合现象较少。
最近的生物医学文献中,有一个例子是对慢性非特异性腰痛患者的分层线性回归分析,以及这种情况如何与情绪困扰相关 [7] 。
(2)逻辑回归
这是上述线性回归对二元分类的调整(通过逻辑函数产生最大可能性),因此,它不是像线性回归那样真正的回归。多重逻辑回归利用了多个预测因子,通常被用作患者研究的统计工具。与逻辑回归密切相关的分类器是线性判别分析(Linear Discriminant Analysis ,LDA),它在某些情况下比逻辑回归更稳定。
与其他监督分类技术如内核支持向量机或集成方法相比(见本书后文),逻辑回归的速度相对较快这是它的优点,但其准确性在一定程度上受到影响。它也有与线性回归相同的问题,因为这两种技术对于变量之间的复杂关系来说都太简单了。另外,当决策边界为非线性时,逻辑回归往往表现不佳。
最近的生物医学文献中的一个例子是使用逻辑回归(与其他三种机器学习方法相比较)对少数具有高维数据集的异质胶质瘤患者(76 名)进行 2 年死亡率预测研究 [8] 。
无监督学习采用未标记数据,并在无人工干预的情况下使用算法来预测数据集中的模式或分组。它比监督学习更具挑战性,因为不存在“答案”,但可以与监督学习相结合。这种类型的学习更多的是用于探索性目的(如发现市场细分)或分析和标记新数据。在医学和医疗保健领域,这种无监督学习在基于基因表达的各种癌症的亚组中得到了应用。
这些无监督学习方法导致了聚类、泛化、关联或异常检测。
1. 聚类
这些方法通过相似的特征对数据进行分组,没有任何人工干预。聚类可用于客户细分和推荐系统。在医学和医疗保健领域,聚类有利于生成生物假说,识别新的人群或疗法,以及新的表型。
表 5.5 中列出了聚类方法和简要描述,正文仅对k-均值聚类进行详细描述(见图 5.10)。
表 5.5 无监督学习:聚类方法

续表


图 5.10 k-均值聚类
k-均值聚类是一个常用的简单无监督学习算法,该算法基于相似性在自然形成的k个组的数据中找到聚类或组。使用距离公式最终会产生k个特征向量,称为聚类中心。未指定k时,分类器将根据两种技术来确定最佳的k值,这两种技术是重构误差(所有点与它们的中心之间的均方误差之和)或峰度(最佳k值是指其聚类与其他其他聚类相比具有最高峰值)。
k-均值聚类的一个优点是,它的实施相对容易。特别是在变量数量较多的情况下,它也比其他聚类方法快。另外,这种方法还能产生相对紧密的聚类。这种方法的缺点是有时很难预测K值。此外,k-均值聚类缺乏其他聚类方法可能产生的层次意义和一致性。
最近生物医学文献中的一个例子是,在 224 名受试者中,有效地使用了k-均值聚类,对双相情感障碍这一异质性疾病进行了聚类分类策略(基于严重性) [9] 。
2.泛化
泛化(或降维)是一种降低数据维度的方法,通常是通过合并特征实现。这样的抽象化模型的优点是这些模型可以更有效,使用特征更少。这种方法也被用于数据的可视化和压缩数据。在医学和医疗保健方面,泛化有利于数据可视化、数据压缩和变量选择。
这些方法包括流行的主成分分析(PCA)和其他泛化方法,表 5.6 中列出了这些泛化方法,并进行了简要说明。
表 5.6 无监督学习:泛化方法

3. 主成分分析
主成分分析识别分类中最重要的特征,随后使用这些选中的特征用于计算;它是一种降维方法,因为它通过这种特征提取将大量的变量集减少到数据集的低维表示。每个主成分都是压缩变量的线性组合。主成分分析也可以作为降维技术用于回归。主成分分析经常被用于数据可视化或在使用监督方法之前进行数据预处理。
这种方法的优点有几个:噪声灵敏度低,对容量和内存的要求降低,效率提高。这种方法的缺点主要是围绕其假设,即线性和主成分的正交性。此外,新的原理很难解释。
最近生物医学文献中的一个例子是,一项研究使用主成分分析来消除不需要的低频信号漂移以及 4D功能MRI中自发的高频全局信号波动,以便将这些伪影作为研究数据采集阶段的更复杂的预处理步骤的一部分 [10] 。
无监督学习下的其他类别包括关联规则,模式搜索或识别以及识别数据中的序列或关系。关联无监督方法包括Apriori、FP-Growth和等价类变换(ECLAT)算法,这些算法可以用于销售和营销策略,因为它们可以预测买家行为。
此外,还有一种异常检测(也叫离群点检测),可以通过无监督学习来实现,有监督以及半监督技术也可以应用于异常检测。除了金融领域的欺诈检测和工业领域的结构缺陷外,最后一类无监督学习在生物医学领域也非常有用,可以检测到医疗问题或错误。恰恰是生物医学中的异常或异常值,可以成为新知识的重要来源。
最近生物医学文献中的一个例子是使用离群点检测来预防用药错误,使用名为密度-距离-中心的无监督方法来检测超过 56 万个处方药的数据集中的潜在异常值 [11] 。
最后,玻尔兹曼机是一个由对称连接的节点组成的网络(每个节点都与其他节点相连),它是一种无监督的机器学习算法,可以发现数据集中的潜在特征。限制玻尔兹曼机将在后文讨论。
半监督学习是有监督和无监督学习的混合技术,它使用少量的标记数据,然后使用较多量的未标记数据。半监督学习也可以在未标记数据上产生代理标签。
因此,这些方法的优点是可以在少量标记数据和大量未标记数据的混合中进行训练,这更有效,因为它节省了时间和精力。未标记数据的引入实际上可以减少人为偏差,提高最终模型的准确性。
最近生物医学文献中的一个例子是关于半监督学习方法即结合生成式对抗网络的报告,它提供少量的标记医疗数据以建立一个基于物联网的医疗数据平台,解释作为这种新的医疗数据来源的决策支持的一部分 [12] 。
这种集成学习策略(bagging、boosting和stacking)涉及训练大量的模型,这些模型组合在一起将超过单个模型的性能。简而言之,就是建立一个预测更好、更稳定的元模型。这种模型的集合可以减少噪声、偏差和变异。常见的情况是利用决策树算法来实现这种集成,以提高准确性(尽管一般来说,这些集成学习策略会比其他方法慢一些)。
有三种集成学习策略可以提高性能(见图 5.11)。
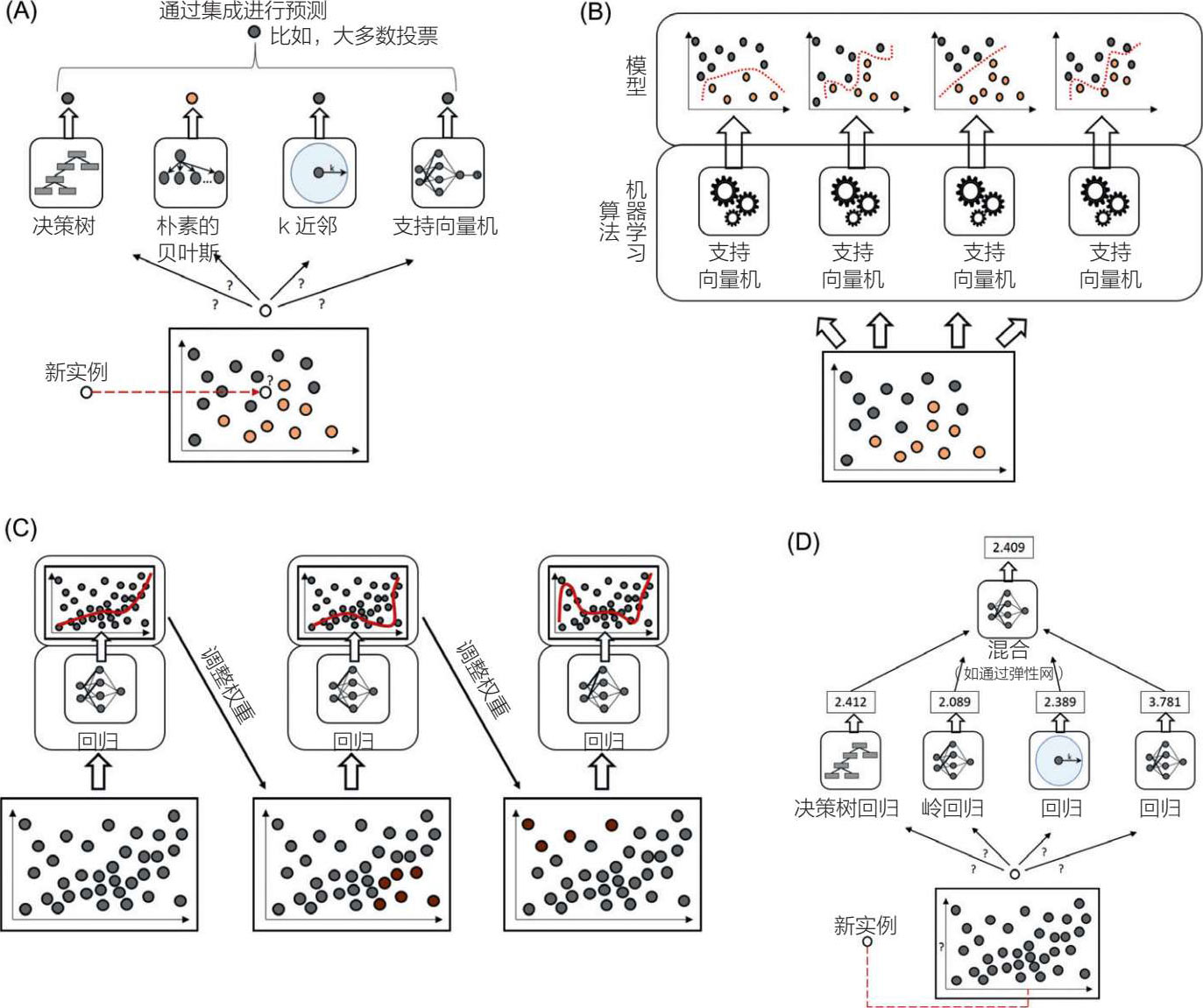
图 5.11 集成学习
第一,bagging算法(也称引导聚集算法)涉及创建多个重复或不同的训练数据集,然后使用相同的模型或算法进行训练,最终产生所有模型的平均值,减少方差。这个构建模型的过程是并行完成的。随机森林是一种流行的监督学习算法,由多个决策树的集成组成,这些决策树共同产生准确的预测并最大限度地减少过度拟合。随机森林的一个主要限制是其缓慢的特性(决策树数量大),因此它不适合实时的预测。随机森林是一种用于检测欺诈和股票预测的方法。
第二,boosting算法涉及使用训练数据创建许多模型,以使每个新的算法能够纠正前一个算法的错误,从而将弱的模型变成强的模型,减少偏差。这个建立模型的过程是按顺序进行的。bagging算法中所有的模型都有相同的权重,而在boosting算法中,模型的表现决定了模型的权重。梯度提升是一种通常使用决策树的集成算法,另一种是自适应增强算法(或AdaBoost)。此boosting函数的其他工具包括XGBoost、LightGBM和CatBoost。
第三,stacking算法涉及几个不同的算法,它们将输出交付给最后一个算法也就是仲裁算法,以做出最终决定,提高预测精度。
这种组合算法策略的优点是,几个或多个模型的组合强度比单个模型好得多,尤其是决策树。此外,不太稳定或较为脆弱的算法实际上可以(自相矛盾地)为模型的集合提高质量。最后,bagging可以减少方差,从而减少过度拟合,而boosting可以减少偏差(但可能会增加过度拟合),所以这两种集成方法都有自己的优势。
在最近的生物医学文献中,关于集成方法的一个例子是对创伤风险预测的集成机器学习模型的研究,该模型被证明优于三个既定的风险预测模型(包括一个使用贝叶斯逻辑的模型) [13] 。
通常不被认为是“经典”或传统机器学习的另外两类机器学习,强化学习以及神经网络和DL。这些更精细的机器学习类型更适用于大型数据集或复杂的数据类型(如图像或视频);这种概括的推论是,对于相对直接、特征很少的数据集使用这些先进的方法可能是过度的和不必要的,换句话说,前面讨论的经典机器学习方法可能已经足够了。
除了上述的监督(任务驱动的分类或回归)和无监督(数据驱动的聚类)学习,还有一种学习类型是强化学习。尽管强化学习经常被描述为与监督和无监督学习之外的第三种或附加类型的机器学习,它与前两种类型的机器学习明显不同。
强化学习起源于 100 多年前的心理学家爱德华·桑代克和他的猫咪实验,在实验中,猫咪学会了用推杆的适当行为来“强化”它们的积极结果。1951 年,哈佛大学的马文·明斯基设计了一种设备来模仿这种自然界的强化学习;这种设备被称为随机神经类比强化计算机(SNARC),由发动机、管子和离合器组成,其功能如同几十个神经元和突触,有利于引发积极结果的行为。
谷歌DeepMind的阿尔法狗项目及其最近成功击败围棋冠军李世石很好地证明了强化学习及其奇妙的能力(连同蒙特卡洛树搜索算法)。DeepMind(总部在伦敦,成立于 2010 年)及其创始人戴密斯·哈萨比斯的目标是实现人工智能领域的阿波罗计划,它拥有大量训练有素的人工智能和机器学习科学家,并专注于通过深度强化学习实现通用的、自我学习的人工智能。凭借创新的强化学习形式,AlphaGo Zero能够完全自学围棋,并能够在短短 40 天内酣畅淋漓地击败其前辈阿尔法狗。DeepMind在 2014 年被谷歌以 5 亿美元收购,DeepMind Health专注于人工智能在医疗方面的应用。
在强化学习中,模型本身与数据不相关,而是通过探索找到最佳方法,以在动态环境中接收输入数据时获得最理想的结果(类似于人类试图在游戏中达到最高分)(见图 5.12)。换句话说,算法的解存在正反馈和负反馈,所以强化学习的目标是学习策略(定义为在长期环境下使奖励最大化的函数,或奖励最大化)。因此,强化学习非常适用于电子游戏、自动交易和机器人导航所需的顺序决策过程。
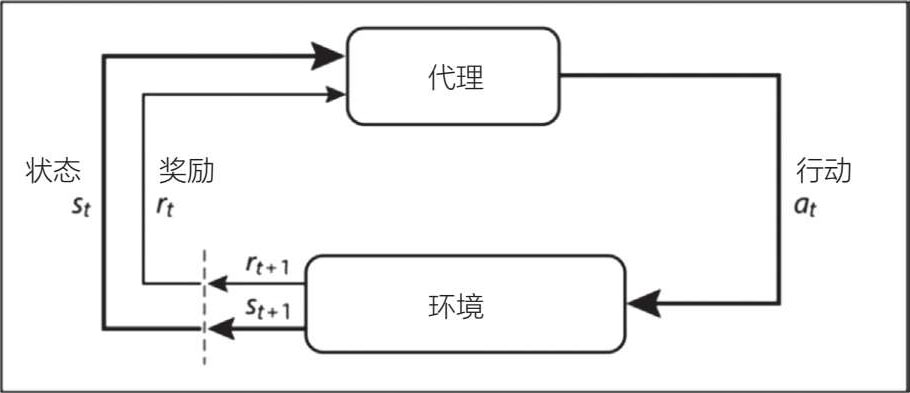
图 5.12 强化学习
智能代理,或在人工智能术语中简称的“代理”,是一个自主实体,可以根据输入(感知)和智能处理产生的输出(行动)来执行任务。这些代理不同于传统的软件程序,它们具有感知、自主、学习和交流的特点。它本质上是一个独立的软件程序,具有包含知识的目标导向,整体上代表某个人。
路易斯·埃韦厄蒙法
数据科学博士路易斯·埃韦厄蒙法撰写的这篇评论,讲述了他作为一个医院的数据科学家对强化学习的看法,以及这种学习方法如何帮助临床医生进行决策并发现新知。
强化学习是人工智能的一个分支,其中包括通过学习算法自主理解数据趋势和预测未来,该学习算法基于对正确决策的激励和对不准确决策的惩罚而进行调整。强化学习是在一系列形式化的基础上发展起来的,其中包括虚拟代理和环境的概念 [1] ,以及行动、奖励和观察 [2] 。虚拟代理通过自主决定行动方案,同时从环境中观察行动的结果来学习。这个结果可能是奖励或惩罚。通过反复试错,虚拟代理学习了最优路径或决策集,以根据其环境的状态获得最高的奖励 [3,4] 。基础理论框架是一个随机过程,称为马尔可夫决策过程 [2,5,6] 。
强化学习在医学上的应用刚刚起步。强化学习已经被应用于预测败血症的问题,这是导致成人死亡的一个主要原因 [7] 。对败血症的应用是通过一个“人工智能临床医生”实现的,该系统是利用重症监护医疗信息市场III(MIMIC III) [8] 和eICU研究机构ICU数据库 [9] 中的ICU数据开发的。强化学习系统建立在来自数据库的多维离散时间序列临床数据上,使得奖励与生存相关,而惩罚与死亡相关。作者表明,人工智能临床医生选择的治疗方案平均优于人类临床医生 [1] ,尽管开发这种“人工智能临床医生”的目标应该是人类和人工智能临床医生合作制定治疗方案。
强化学习在医学上的其他应用包括预测拔管的准备情况 [10] 、肝素的用量 [11] 、ICU中的呼吸机支持 [10] ,以及预测非小细胞肺癌的最佳治疗方案 [12] 。强化学习也被证明适用于优化药物输送,如麻醉的输送 [13] 。多代理深层强化学习模型也可用于发现新的药物和更便宜的替代药物现有替代昂贵或难以管理的现有药物 [14] 。
这些强化学习在医学上的应用实例表明,为医生提供实时人工智能决策支持和互动引擎仍存在很大的机会。人工智能决策支持工具的融合将为临床医生的护理质量提供实质性的改善。与传统的监督和无监督学习相结合,未来的强化学习模型将能够让医生给复杂病情的患者提供多种治疗方案。此外,强化学习模型在医疗提供者难以诊断或难以安全治疗患者病情的情况下,可能会变得非常有价值。想取得成功,很大程度上取决于确定训练强化学习模型的适当奖励机制下临床医生的参与。我们的目标不是取代临床医生,正如最近的深度卷积神经网络研究应用的标题所预示的那样,而是在为患者制定或修改治疗计划的过程中,提供来自强化学习模型的信息作为附加数据点/信息。事实上,数据科学家和机器学习工程师只有通过与医生和注册护士等护理人员的积极合作,才能成功构建安全有效的人工智能系统。因此应增加对医生-数据科学家的培训,他们将在数据科学和医学的高度技术性和广阔的领域之间架起并支撑知识差距/差异的桥梁。
[1] Komorowski M,Celi LA,Badawi O,Gordon AC,Faisal AA. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nat Med. 2018;24(11):1716.
[2] Lapan M. Deep reinforcement learning hands-on: apply modern RL methods,with deep Q-networks,value iteration,policy gradients,TRPO,AlphaGo zero and more. Packt Publishing Ltd; 2018.
[3]Henderson P,Islam R,Bachman P,et al. Deep reinforcement learning that matters. arXiv:1709.06560.aaai.org. ,https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewPaper/16669. [accessed 09.02.19].
[4] Kaelbling LP,Littman ML,Moore AW,et al. Intelligence AM. J Artificial Intelligence Res 1996;4:23785.
[5] Karlin S. A first course in stochastic processes. Academic Press; 2014.
[6] Puterman ML. Markov decision processes. Handbooks Oper Res Manag Sci 1990;2:331434.
[7] Singer M,Deutschman CS,Seymour CW,et al. The third international consensus definitions for sepsis and septic shock (Sepsis-3). JAMA 2016; 315(8): 80110.
[8] Johnson AEW,Pollard TJ,Shen L,et al. MIMIC-III,a freely accessible critical care database. Sci Data 2016;3:160035.
[9] Pollard TJ,Johnson AEW,Raffa JD,Celi LA,Mark RG,Badawi O. The eICU Collaborative Research Database,a freely available multi-center database for critical care research. Sci Data 2018;5:180178.
[10] Prasad N,Cheng L-F,Chivers C,Draugelis M,Engelhardt BE. A reinforcement learning approach to weaning of mechanical ventilation in intensive care units. 2017. arXiv:1704.06300.
[11] Nemati S,Zeng D,Ghassemi MM,Clifford GD. Optimal medication dosing from suboptimal clinical examples: a deep reinforcement learning approach. Conf Proc IEEE Eng Med Biol Soc 2016;2016:297881.
[12] Zhao Y,Zeng D,Socinski MA,Kosorok MR. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics 2011;67(4):142233.
[13] Padmanabhan R,Meskin N,Haddad WM. Closed-loop control of anesthesia and mean arterial pressure using reinforcement learning. Biomed Signal Process Control 2015;22:5464.
[14] Popova M,Isayev O,Tropsha A. Deep reinforcement learning for de novo drug design. Sci Adv 2018;4(7): eaap7885.
强化学习的真正益处在于它与深度学习的有效结合,深度学习使用大型神经网络进行模式识别,其形式为深度强化学习。阿尔法狗将强化学习与深度学习(深度强化学习)结合在一起,是为无数细致入微的类人决策博弈而理想设计的,因为它通过复杂模式的识别、长期规划和“智能”决策的结合来适应一系列更好的决策(见图 5.13) [14] 。阿尔法狗有三个组成部分:(1)策略网络——该要素评估现状,预测下一步;(2)快速走子——该元素提高了决策的速度;(3)估值网络——该元素评估形势,并预测哪一方会赢。
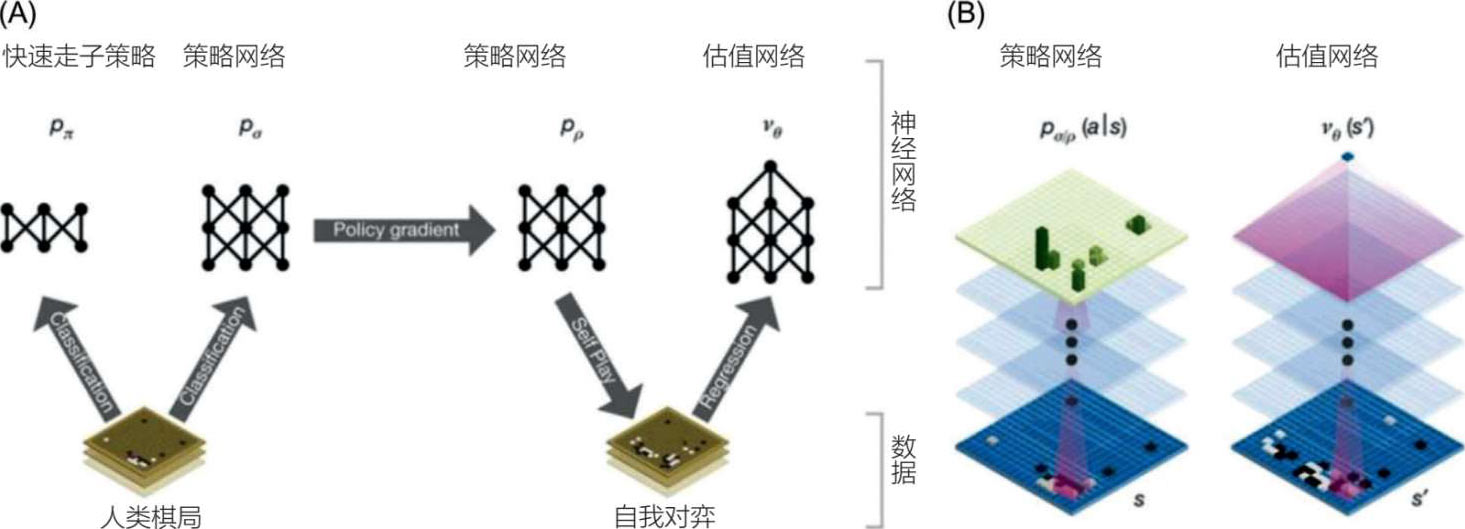
图 5.13 阿尔法狗中的深度强化学习
强化学习和它的人工智能同类深度强化学习对生物医学来说是很有价值的资产,因为这些方法被很好地设计用来在不确定的环境中做出连续的决定,以实现长期的目标,即尽量减少错误(会导致发病率和/或死亡率上升)。在医学和卫生保健领域,强化学习是过程优化和决策序列优化的理想选择。这种强化学习,特别是与深度强化学习相结合,离一些人认为的“真正的”人工智能又近了一步。
表 5.7 中列出了强化学习方法,并简要介绍了深层Q网络(DQN),它是强化学习与深层神经网络的第一个大规模应用 [15] 。在DQN中,强化学习与名为DQN的新型人工代理的协同合作可以使用端到端强化学习,直接从高维感官输入中学习成功的策略。
强化学习的优点是学习类型被认为更加人性化。此外,强化学习不像监督和无监督的学习那样是任务或数据驱动的。强化学习也能够在不断变化的环境中运作。然而,强化学习的一个限制是,一些生物医学问题具有多个同时的相互作用,并且是实时的,没有时间延迟(连续非离散)。此外,强化学习是数据饥渴的且数据不透明,也是狭窄的和脆弱的。最后,强化学习必须平衡探索和开发。
对强化学习和深度强化学习的简要回顾有助于理解强化学习和深度强化学习的基本原理及其在医学中的应用(但在数学上相对深奥) [16] 。在最近的生物医学文献中,有一个例子是使用深度强化学习(以双DQN的形式)在重症监护环境下进行最佳的疼痛管理,比传统的方法更有效 [17] 。
表 5.7 强化学习方法
