
下载掌阅APP,畅读海量书库
立即打开



习题2.1 教材2.1节介绍了“经验误差”(empirical error)与“泛化误差”(generalization error)的概念,以及机器学习中的“过拟合”(overfitting)现象.请回答以下问题:
1. 图2.1中的黑色圆点表示训练数据,使用曲线拟合.针对图中的3种情况,请说明模型是否发生“欠拟合”(underfitting)或“过拟合”.
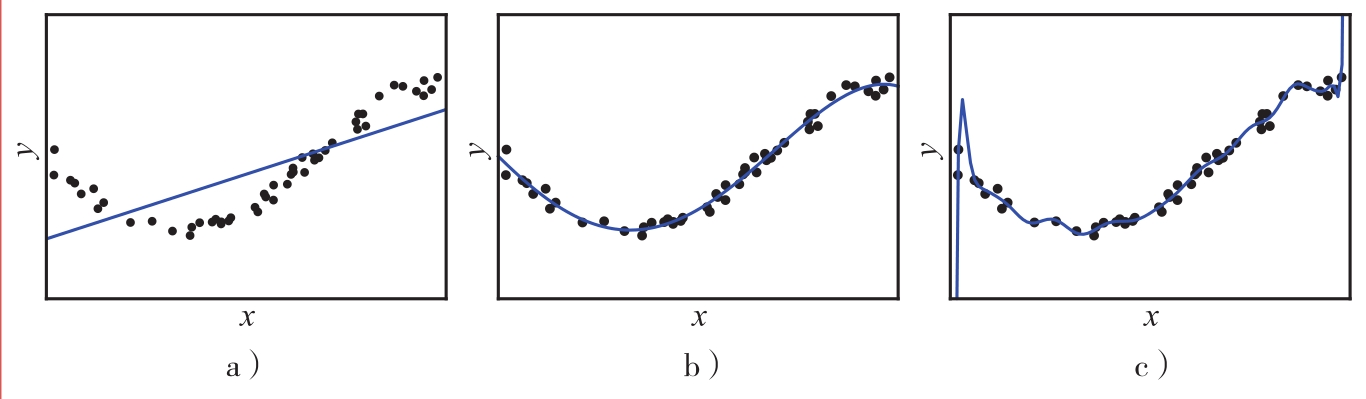
图2.1 针对回归任务构建模型
2. 将经验误差或泛化误差作为纵轴,将模型复杂度作为横轴,绘制曲线图(如图2.2a所示),请判断两条曲线哪条更可能对应经验误差,哪条更可能对应泛化误差.
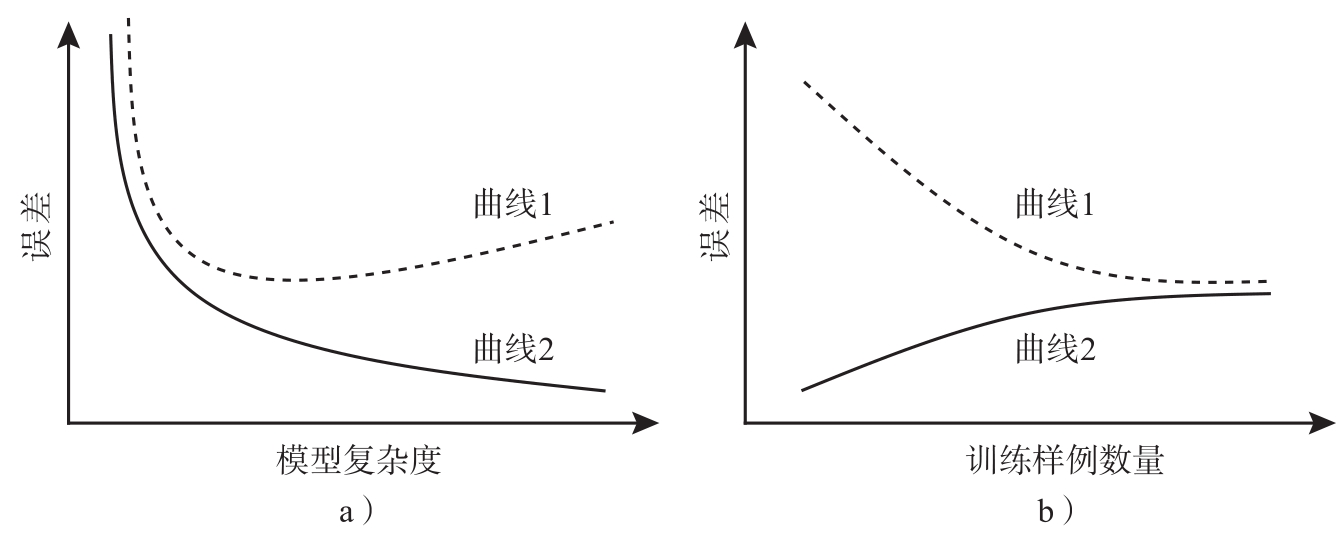
图2.2 模型误差随模型复杂度以及训练样例数量的变化
3. 考虑训练样例数量 m 对模型的影响.针对给定的训练数据训练模型,并使用未见数据计算模型的泛化误差.图2.2b展示了经验误差和泛化误差随着训练样例数量的变化趋势,请判断两条曲线哪条更可能对应经验误差,哪条更可能对应泛化误差.
4. 模型的训练过程一般通过迭代方式进行.随着模型趋于收敛(converge),每一次优化迭代后,利用中间模型计算其经验误差和泛化误差,得到如图2.3所示的两种情况.请说明图2.3a和图2.3b中的模型是否发生“欠拟合”或“过拟合”.
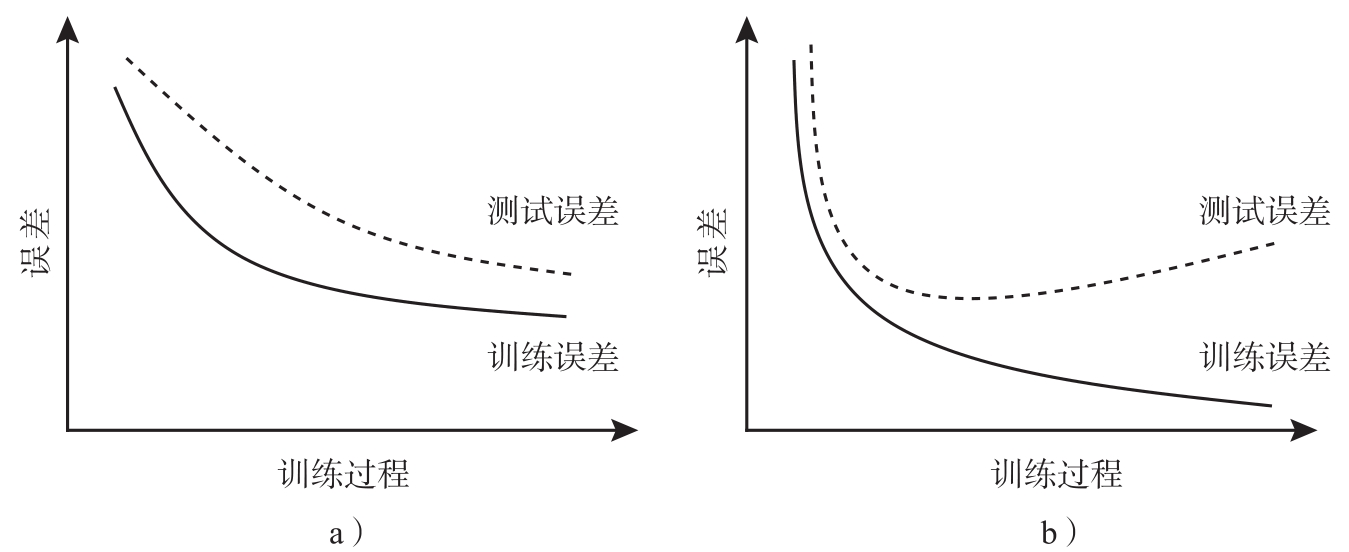
图2.3 模型误差随模型迭代过程的变化
解答
训练误差(training error)或经验误差指模型在训练集上的误差.泛化误差指模型在测试集上的误差.一般地,将模型的实际预测输出与示例的真实标记之间的差异称为“误差”(error).当模型把训练示例学得“太好”时,很可能已经把训练示例自身的一些特点当作了所有潜在示例都会具有的一般性质,这样就会导致泛化性能下降,这一现象称为“过拟合”.与过拟合相对的情况是欠拟合,一般指模型对训练示例的一般性质尚未学好.本题中的几个小题可依此进行判断.
对模型欠拟合和过拟合的判定一般需要同时观察经验误差和泛化误差的关系.对于同一个问题(如某个分类问题),有的模型会造成欠拟合,而有的模型会造成过拟合 [ 1 ] .
1. 图2.1展现了使用不同复杂程度下的曲线拟合数据(圆点)的情况.可以看出,曲线越平滑,则模型越简单,参数越少;曲线越陡峭,则模型越复杂,参数越多.图2.1a中使用直线拟合数据,而数据分布本身呈弯曲趋势,直线无法覆盖大多数数据,模型未能刻画好数据的特性,发生“欠拟合”;图2.1b中的模型较好地穿过了大部分数据,且和数据本身的曲线分布情况一致,此时模型能够较好地反映数据特性,未发生“欠拟合”或“过拟合”;图2.1c中的模型最为复杂,几乎穿过了每一个数据点,且展现出局部抖动特性,但这些突变可能是由于数据收集中的噪声造成的,并不能反映数据本身的性质,模型针对给定的训练数据拟合较好,但不一定能泛化到新数据上,发生“过拟合”.
本小题关于过拟合的讨论可联系习题1.4中关于线性分类器权重大小如何影响模型的讨论.一般而言,图2.1c中的线性模型权重取值较大.
2. 根据图2.1的讨论,模型开始时过于简单,能力较弱,无法刻画数据的特性,发生“欠拟合”,而当模型过于复杂时,充分刻画了训练数据,但过度关注某些细节,导致无法对新样例进行准确预测,发生“过拟合”.在图2.2a中,曲线1对应“泛化误差”,曲线2对应“经验误差”.经验误差随着复杂度增加逐渐降低,而泛化误差会先降低后增加,因此,在构建机器学习模型的过程中,不能一味地以经验误差为标准,需要防止过拟合现象.
3. 图2.2b的纵轴仍表示误差,但横轴表示训练样例的数量.此时曲线2代表了经验误差.一般而言,样例较少时模型更容易将所有样例预测正确,而当有更多的样例时对同一个模型的要求更高.对于同一个模型,训练样例数量增加时经验误差会随之增加,而当经验误差涨幅逐渐缩小时,分类器的泛化性能良好.曲线1对应泛化误差.这是由于随着训练样例数量增加,更容易让模型从数据中发现规律,提升泛化性能,从而降低泛化误差.
4. 图2.3中横轴为训练过程,纵轴为误差.在迭代训练模型的过程中,模型逐步拟合数据,挖掘数据中的规律信息.在图2.3a中训练误差和测试误差都在下降,说明模型在逐步拟合数据,而训练误差在图中仍有下降趋势,说明模型对数据仍未完全拟合,因此发生“欠拟合”.而在图2.3b中,两条曲线的趋势和图2.2a类似,训练误差逐渐降低,而测试误差先降后升,说明随着模型的训练,模型过度描述数据的性质,发生“过拟合”.从本题的分析能够看出,欠拟合比较容易克服,可以进一步训练模型或增加模型复杂度,例如在决策树学习中扩展分支,在神经网络学习中增加训练轮数等.而要克服过拟合相对困难.
习题注释 本题主要考查对过拟合的理解,并通过对模型训练过程不同角度的描述探究模型是否发生过拟合.在实际训练模型时,需要根据经验误差和泛化误差的变化情况进行判断与调试,从而确定是否停止训练或者修改模型复杂度.
如何克服“过拟合”是机器学习中的一项长期难题.不同的机器学习模型都通过各自的模型设计或归纳偏好对过拟合进行预防.而对于过拟合现象本身,近年来也有新的发现 [ 2 ] .
习题2.2 假设在训练集上训练模型直到其收敛,并在与其互斥的测试集上对模型进行测试评估.观察评估结果发现模型的泛化误差很高,然而模型的经验误差却接近于0.下面哪些操作可以帮助缓解模型面临的问题.选出可行的方案,并进行解释.
A.增加训练集样例数量.
B.减少训练集样例数量.
C.增加模型复杂度(例如,当前分类器是支持向量机时,使用一个更加复杂的核函数;或者当前分类器是决策时,增加树的深度).
D.降低模型复杂度.
E.同时使用训练集和测试集样例训练分类器,并在测试集上测试.
解答
A和D是可行的方案.当前情况称为过拟合.常见的过拟合的原因有:①训练集样例未能准确反映数据分布,例如在样例数量过少、样例有噪声、采样错误等情况下;②模型参数过多,使得模型复杂度过高,能够完美地拟合训练集上的样例,但拟合了数据特殊的性质,在未见过的测试集样例上无法很好地预测;③假设条件不存在或者错误.对于选项C,当模型复杂度增加时,会出现过拟合的情况,此时经验误差会下降,然而测试误差会先下降后上升.若模型发生欠拟合,则增加模型复杂度一般能够提升拟合效果.对于选项E,需要注意模型在训练阶段不应该使用任何测试集上的样例,否则无法准确评估模型的泛化能力.
习题注释 本题主要考查对过拟合的理解,题目中提供的只是一般意义上的解决方案,在具体场景下需要具体分析.当样例数量较少时,模型很难从这些样例中学到可泛化的规律.针对这类小样本学习问题,目前有基于度量学习(metric learning) [ 3-4 ] 或基于元学习(meta learning) [ 5-7 ] 等方法.
习题2.3 教材2.2节介绍了多种评估方法.假定学习算法所产生的模型按照类别出现频率进行预测,将新样例预测为训练样例数较多的类别(训练样例数相同时进行随机猜测),考虑在以下两种情况下交叉验证法(cross validation)和留一法(Leave-One-Out,LOO)的差异,并给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果.
1. 假设数据集包含100个样例,其中正负例各一半.
2. 假设数据集包含100个样例,其中正例51个,负例49个.
解答
1. 情况一:10折交叉验证法采取分层抽样,10份数据集中均包含一半正例和一半负例,10次训练中,每次训练集中的正负例样本数相等,进行随机预测,所以错误率期望为50%;留一法每次留出一个样例作为测试集,当留出负例时,训练集由50个正例、49个负例组成,正例样本占多数.模型将所有样本预测为正例,将剩余用于评估的一个负例样本预测错误,而当留出正例时,训练集由49个正例、50个负例组成,将剩余用于评估的一个正例样本预测错误,错误率始终是100%.
2. 对于情况二,10折交叉验证法和留一法得到的错误率均为49%.
习题注释 本题考查对交叉验证法和留一法的理解.在一般情况下,交叉验证法和留一法均能够用于对模型泛化能力的评估,同时用于超参数的选择.本题为展示两种评估方法的不同,构造了两种特殊的情况.这说明并非某种评估方法在所有情况下一定比另一种评估方法有效,且其评估效果依赖于模型的假设空间.
留一法是 k 折交叉验证法在 k 等于样例数 m 时的一种特例.通过对比评估方法在两种情况下的结果可以发现,虽然留一法能够保持训练集的大小和原始训练集几乎一致,但它在评估过程中的计算开销较大,并且采样方式具有确定性(而 k 折交叉验证法中的分层采样具有随机性),每次去除一个样例形成训练集,无法进行分层抽样,在极端情况下,严重破坏了原始数据的分布,导致错误率高达100%.
习题2.4 教材2.2.3节描述了自助法(bootstrapping),下面使用自助法估计统计量,对自助法做进一步分析.考虑 m 个从分布 p ( x )中独立同分布抽取的(互不相等的)观测值 x 1 , x 2 ,…, x m , p ( x )的均值为 μ ,方差为 σ 2 .通过 m 个样例,可估计分布的均值

和方差
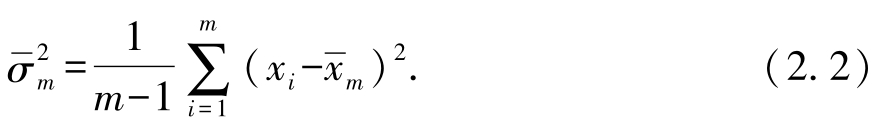
设
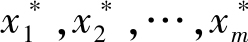 为通过自助法采样得到的结果,且
为通过自助法采样得到的结果,且

1.
证明
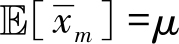 且
且
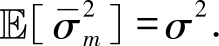
2.
计算
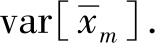
3.
计算
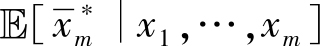 和
和
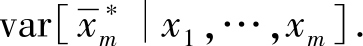
4.
计算
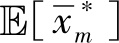 和
和
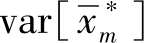 ,可利用如下定理:
,可利用如下定理:
定理2.1(全期望公式(Law of Total Expectation ))
设 X , Y 为同一空间中的随机变量,则

定理2.2(全方差公式(Law of Total Variance ))
设 X , Y 为同一空间中的随机变量,则
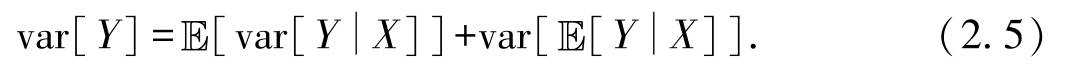
5. 针对上述证明分析自助法和交叉验证法的不同.
解答
1.
通过如下方式证明
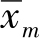 和
和
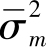 是分布均值和方差的无偏估计.
是分布均值和方差的无偏估计.
证明
针对
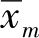 求期望,基于期望的线性性质,得到
求期望,基于期望的线性性质,得到
要计算
 的期望,首先将其展开,得到
的期望,首先将其展开,得到
其中第一项利用方差的性质
 ,得到
,得到
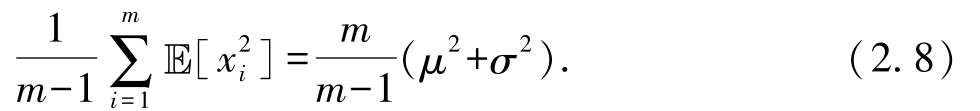
对于第二项,将
 代入,得到
代入,得到
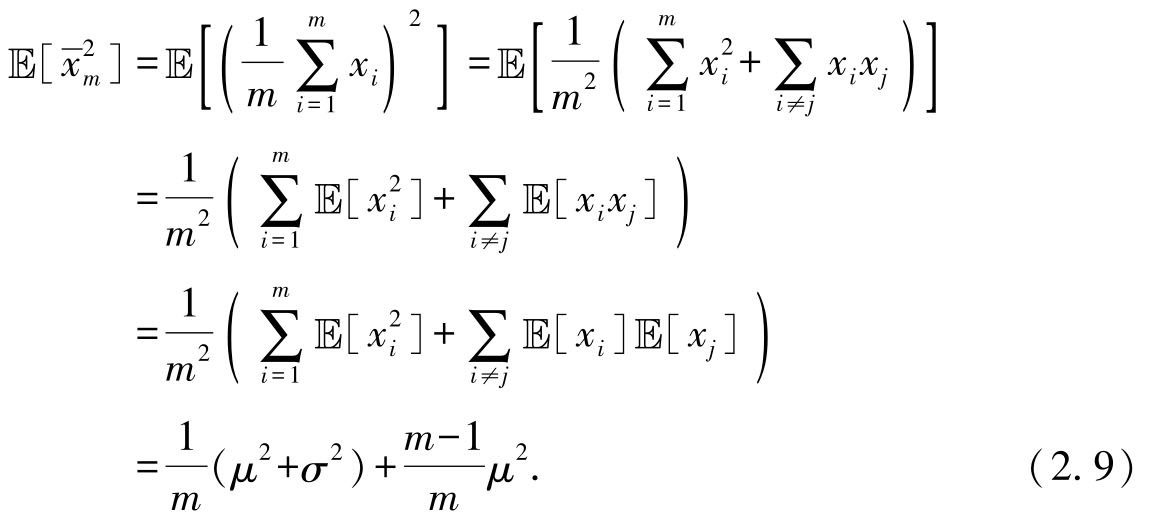
利用 x i 、 x j 的独立性.
最后一个等式利用了在 m 2 组期望的乘积中,符合 i ≠ j 的共有 m ( m -1)组这一性质.式(2.7)中第三项可变化为
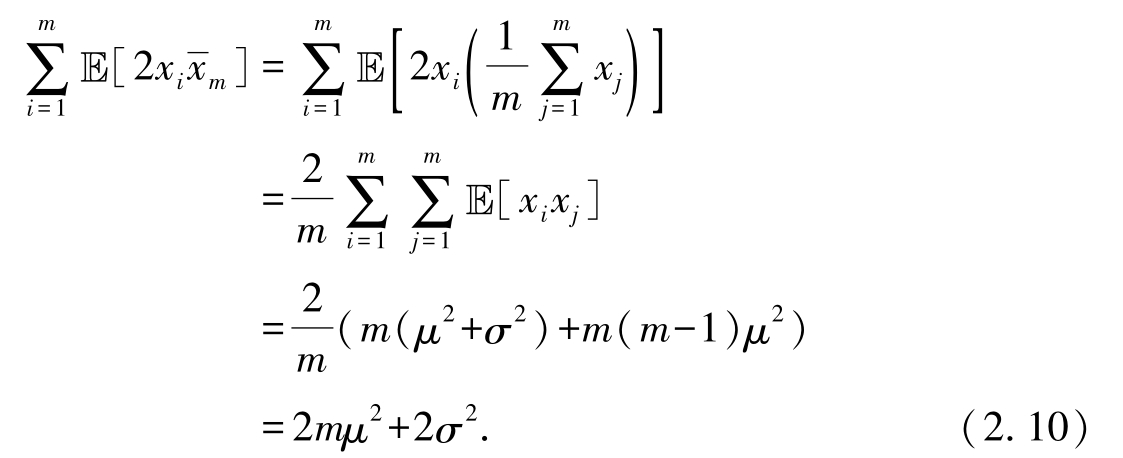
综上,代入式(2.8)、式(2.9)、式(2.10),式(2.7)变化为
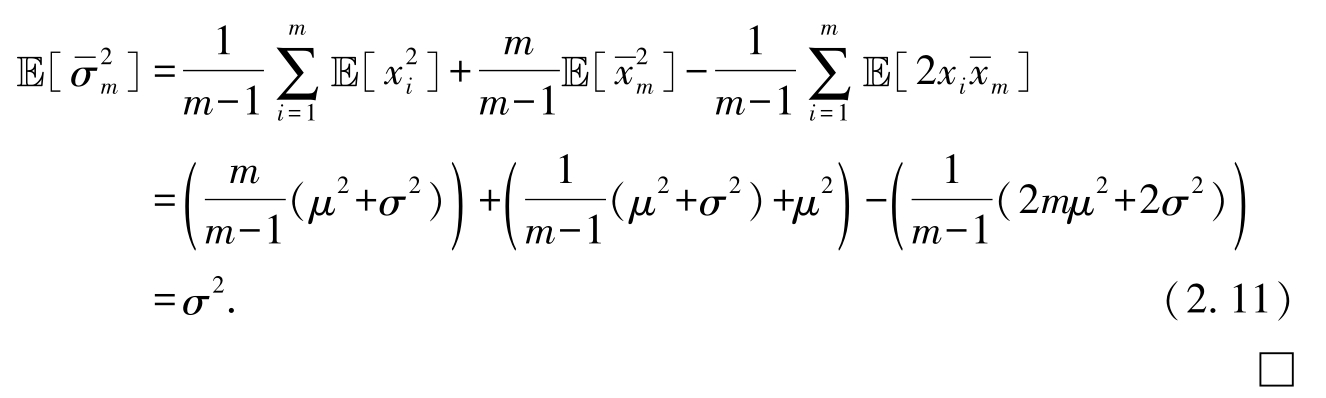
2.
利用方差的性质将
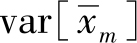 展开,并利用随机变量的独立性,有
展开,并利用随机变量的独立性,有
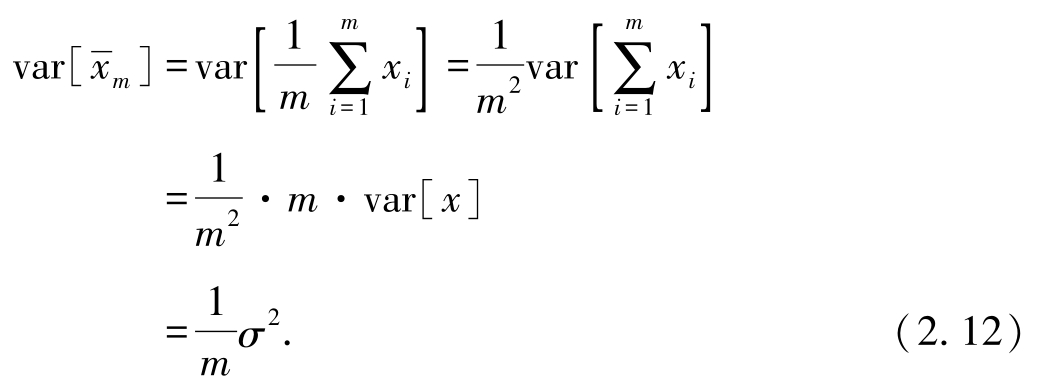
利用样本独立性.
在自助法中,样本 x i 从{ x 1 ,…, x m }中独立同分布重采样,根据bootstrapping性质,计算条件期望时,将{ x 1 ,…, x m }视为定值.
3.
根据
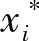 服从分布
服从分布
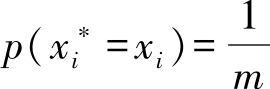 ,得到
,得到
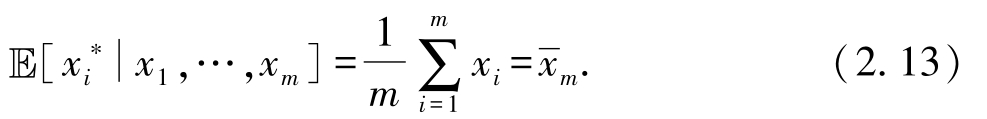
即重采样样本的均值等于所获取的 m 个样本的样本均值.于是
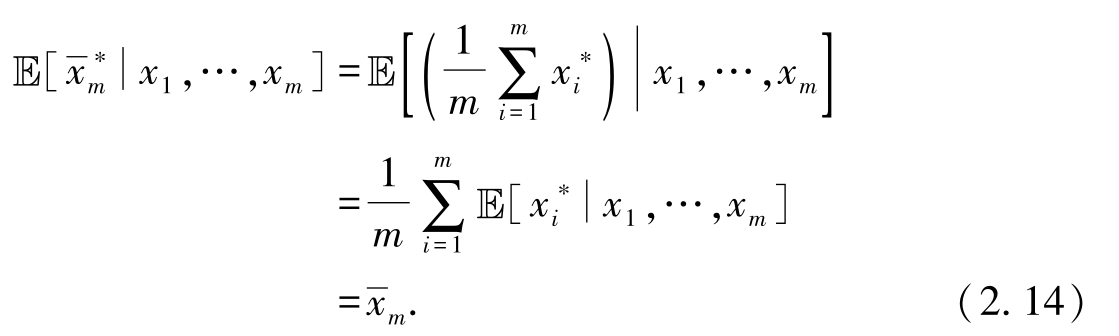
因此,自助法的均值估计是无偏的.为了计算
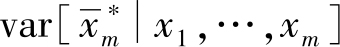 ,首先利用方差定义
,首先利用方差定义
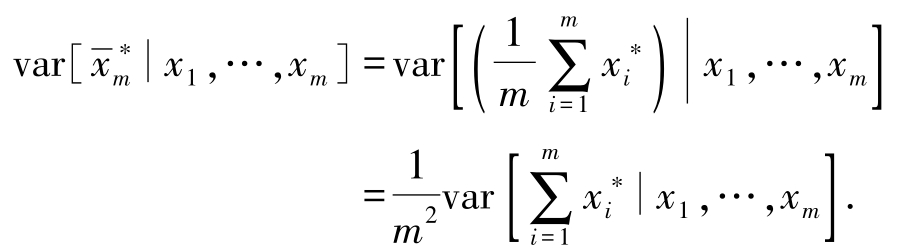
根据自助法采样,
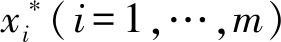 独立同分布,故
独立同分布,故
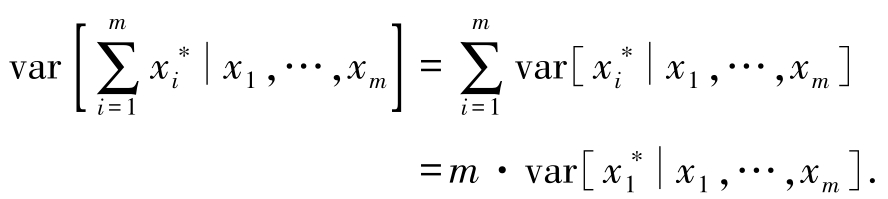
进一步根据方差的定义,以及式(2.2),有
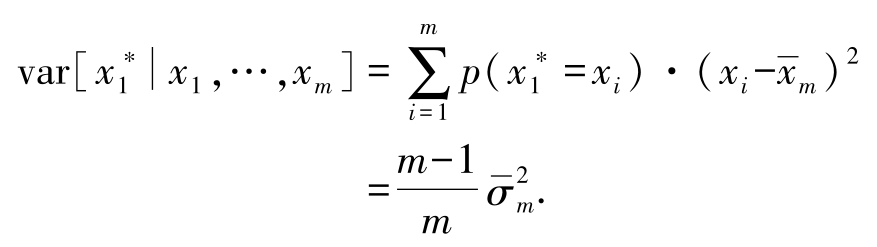
得到
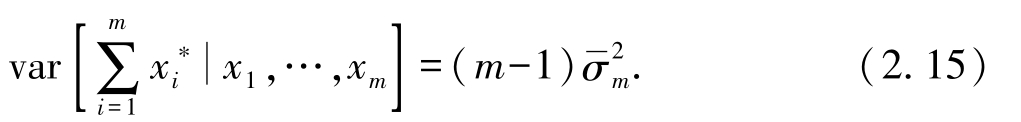
于是
同第2小题,再次利用样本独立性.

即通过自助法抽取的样本计算的样本方差是有偏的.
4. 根据全期望公式(式(2.4)),有
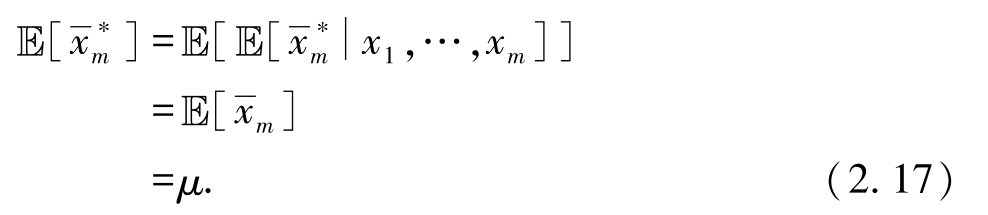
内层期望刻画自助法采样的随机性,而外层期望刻画数据集从原始分布中抽样的随机性.
根据全方差公式(式(2.5)),有
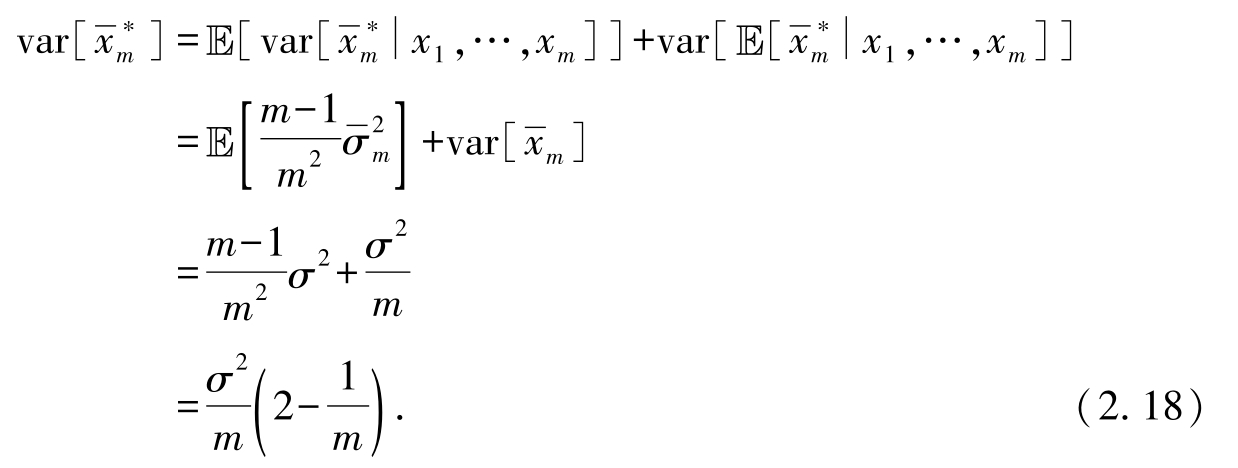
5. 根据上述计算结果,可以发现
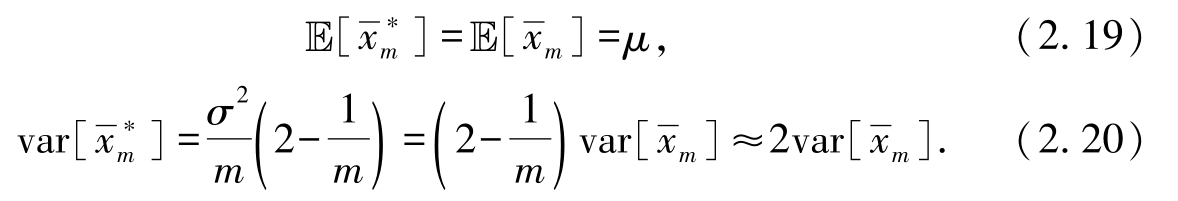
另外,若采用 k 折交叉验证法的方式采样,类似地,有
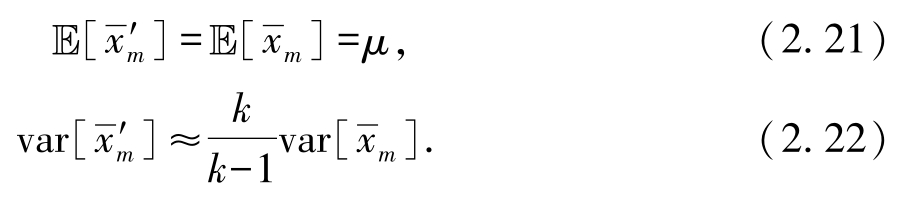
k
折交叉验证法是将
m
个样例均分为
k
份后随机选择
k
-1份,取出的样例约等于
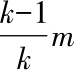 个(“约等于”源于
k
无法整除
m
的情况),等价于从总体分布中随机采样
个(“约等于”源于
k
无法整除
m
的情况),等价于从总体分布中随机采样
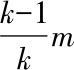 个样例.其方差为
个样例.其方差为
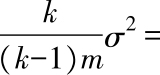
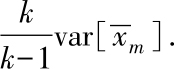
综上所述,虽然通过自助法采样得到的示例均值仍然是总体均值的无偏估计,但是其方差变为原来的近两倍,而这相当于使用2折交叉验证法采样的效果,所以一般而言,自助法采样对数据分布的改变大于交叉验证法.
习题注释 本题考查使用自助法进行参数估计时估计结果期望、方差的变化.更多关于自助法的分析可参考文献[8].
习题2.5 在某个西瓜分类任务的验证集(validation set)中,共有10个样例.其中有3个示例的类别标记为“1”,表示该示例是好瓜;有7个示例的类别标记为“0”,表示该示例不是好瓜.由于学习方法能力有限,只能产生在验证集上精度(accuracy)为0.8的分类器.
1. 如果想要在验证集上得到最佳查准率(precision),该分类器应该做出何种预测?此时的查全率(recall)和 F 1分别是多少?
2. 如果想要在验证集上得到最佳查全率,该分类器应该做出何种预测?此时的查准率和 F 1分别是多少?
精度等指标的计算方式见教材2.3节.
解答
由精度可知,在验证集上,TP+TN=8,FP+FN=2.
1. 要最大化查准率,则此时该分类器应该正确地预测1个好瓜.此时TP=1,FP=0,FN=2,TN=7.混淆矩阵(confusion matrix)见表2.1:
表2.1 最大化查准率时的分类结果混淆矩阵

基于以上结果,有
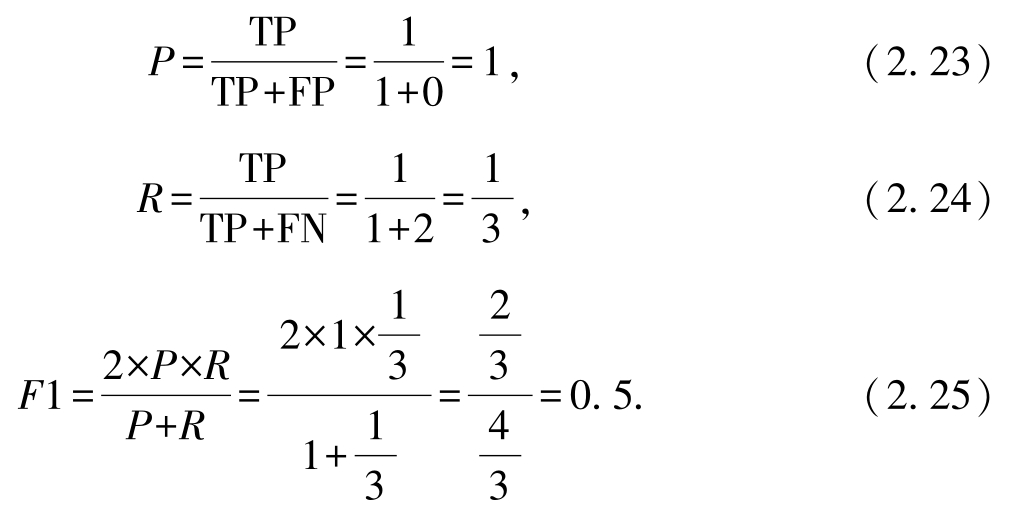
2. 要最大化查全率,则此时该分类器应该预测出5个好瓜.此时TP=3,FP=2,FN=0,TN=5.混淆矩阵见表2.2:
表2.2 最大化查全率时的分类结果混淆矩阵

基于以上结果,有
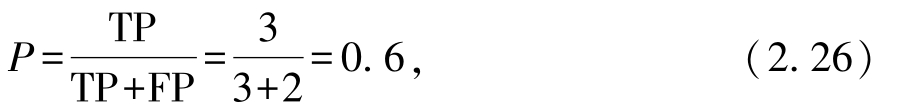
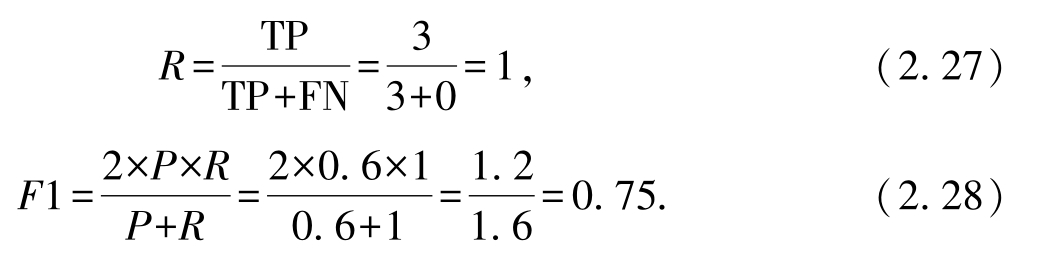
习题2.6 教材2.3节展示了如何计算学习模型的二分类性能度量,下面以多分类为例,探究如何对多分类模型的预测结果进行评估.
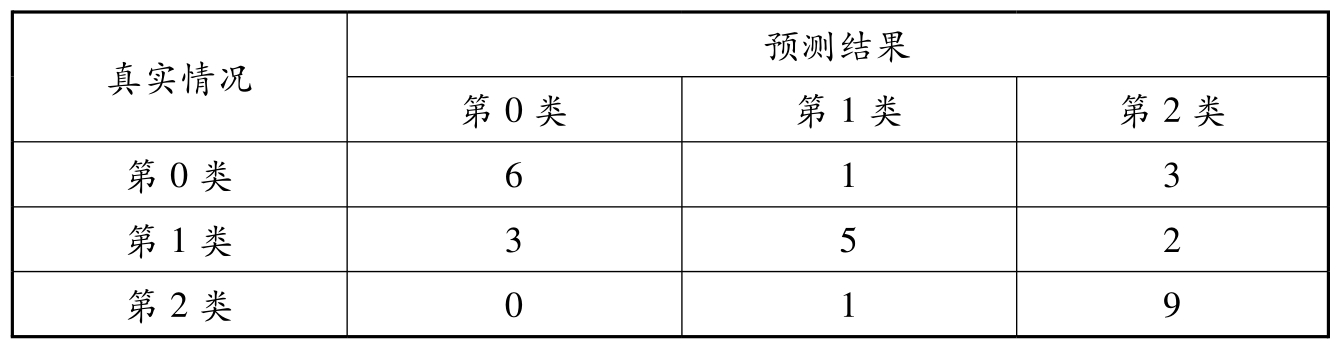
学习器(learner)L在某个多分类任务数据集上的预测混淆矩阵见表2.3,请回答下列问题:
表2.3 学习器L在某个多分类任务数据集上的预测混淆矩阵
1. 该学习器的预测精度是多少?
2. 该学习器的预测查准率、查全率分别是多少?请分别计算微查准率(micro -P )、宏查准率(macro -P )、微查全率(micro -R )和宏查全率(macro -R ),它们的值一样大吗?
3. 该学习器的预测 F 1度量是多少?请分别计算微 F 1(micro -F 1)、宏 F 1(macro -F 1),它们的值一样大吗?
解答
1. 精度是衡量该学习器在所有样例中正确预测的比例.在实际计算中,正确预测的样例是混淆矩阵中对角线上的元素,因此精度等于对角线上的元素和除以矩阵中的总元素和.
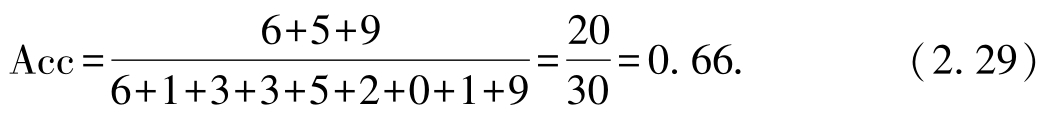
2. 查准率和查全率的计算需要将多分类混淆矩阵改写为二分类混淆矩阵.分别以第0类、第1类、第2类作为正类,以其他类作为负类,可以得到如表2.4所示的3个二分类混淆矩阵:
表2.4 不同类作为正类时的混淆矩阵
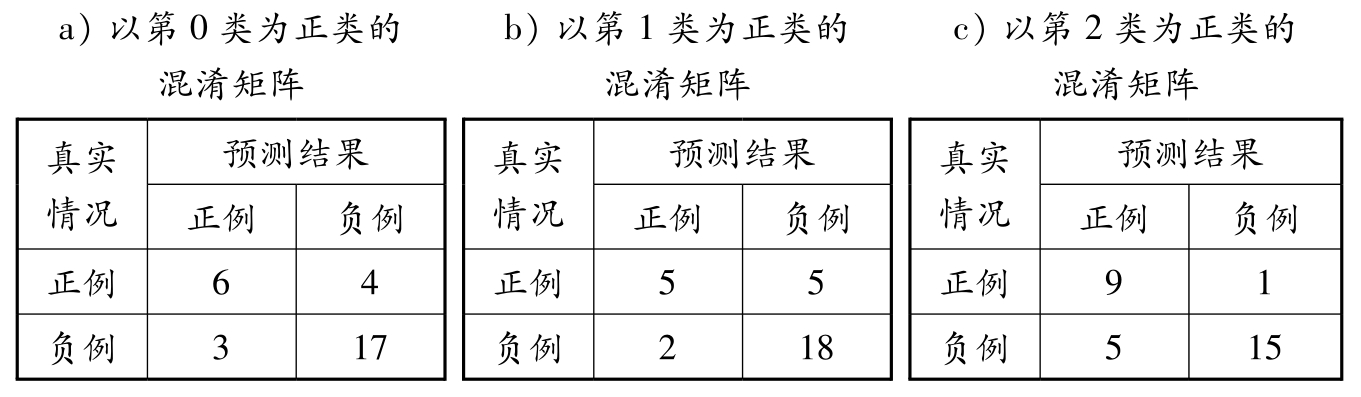
依照教材中的式(2.12)、式(2.13)、式(2.15)、式(2.16),可以计算以下指标:
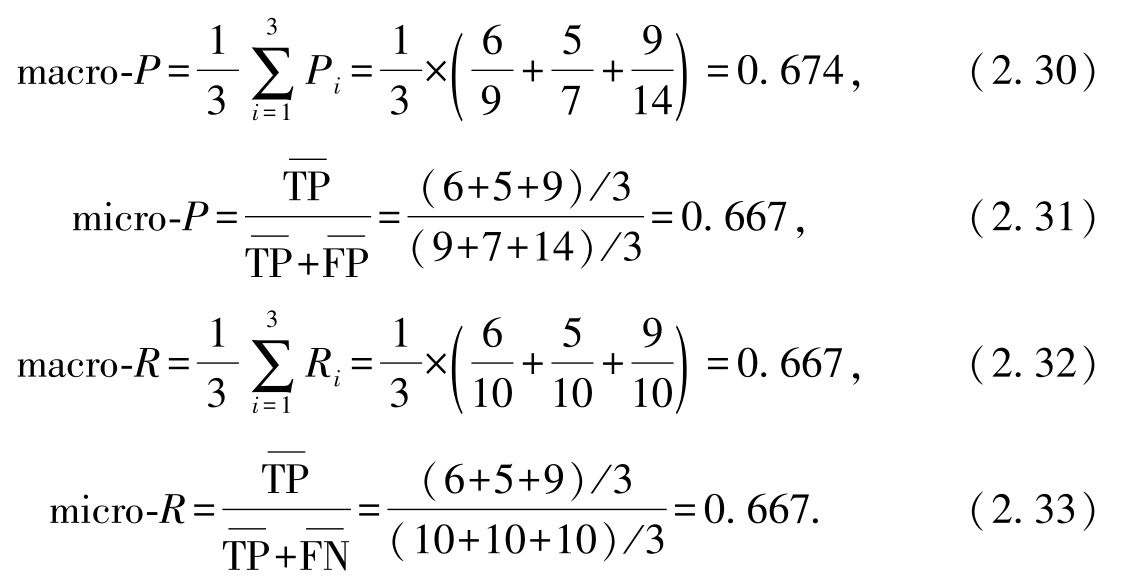
3. 依照教材中的公式,可以计算以下指标:

式(2.34)和式(2.35)分别对应教材中的式(2.14)和式(2.17).
习题注释 本题的目的是帮助理解如何计算多分类的性能度量.scikit-learn等工具包已经集成了已有的多种不同分类指标,由于采取了不同的计算方式,macro -P 和micro -P ,macro -R 和micro -R ,macro -F 1和micro -F 1的值一般不同.本书中的习题12.8讨论了多分类不平衡数据对不同 F 1指标计算方式的影响.
习题2.7 假设某数据集包含8个样例,其对应的标记和学习器的输出值(从大到小排列)见表2.5.该任务是一个二分类任务,标记1或0表示真实标记为正例或负例.学习器的输出值代表学习器对该样例是正例的置信度(认为该样例是正例的概率).
表2.5 样例表

1. 计算P-R曲线中每一个端点的坐标并绘图.
2. 计算ROC曲线中每一个端点的坐标并绘图,计算AUC(Area Under the ROC Curve,ROC曲线下的面积).
解答
基于学习器的输出值(样例预测为正例的概率),可通过划定阈值(threshold)的方法将样例预测为正例或负例,假设输出值大于阈值的预测为正例,反之为负例.例如,若阈值为0.5,则表2.5中{ x 1 , x 2 , x 3 , x 4 }对应的学习器输出值均大于0.5,因此预测 x 1 ~ x 4 为正例,剩下的为负例.对比预测的标记和真实标记,可计算查准率、查全率等指标,从而绘制P-R曲线或ROC曲线.虽然阈值可在[0,1]区间连续取值,但考虑到样例有限,只需要在8个样例构成的9个区间取阈值即可,针对每一个阈值,比较模型的预测结果和标记,从而确定P-R曲线和ROC曲线中各点的坐标.
首先考虑设置阈值在(0.81,1]内,则所有样例均被预测为负例,预测标记与真实标记的对比如表2.6所示.由于没有预测出正例,查准率 P =0,而所有正例均被预测为负例,因此查全率 R =0,得到P-R曲线中的一个坐标(0,0).类似地,可计算出真正例率TPR=0,假正例率FPR=0,得到ROC曲线中的一个坐标(0,0).
表2.6 阈值位于(0.81,1]时样例预测标记与真实标记的对比

其次考虑设置阈值在(0.74,0.81]内,则
x
1
被预测为正例,其余样例均被预测为负例,预测标记与真实标记的对比见表2.7,而对应的类别混淆矩阵见表2.8.可计算出查准率
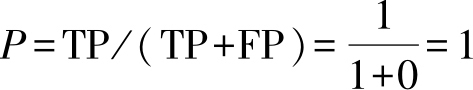 ,查全率
R
=TP/(TP+FN)=0.25,得到P-R曲线中的一个坐标(1,0.25).还可计算出真正例率
,查全率
R
=TP/(TP+FN)=0.25,得到P-R曲线中的一个坐标(1,0.25).还可计算出真正例率
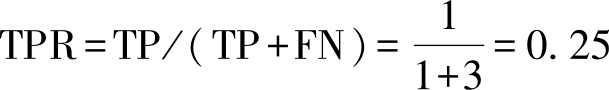 ,假正例率FP R=FP/(TN+
,假正例率FP R=FP/(TN+
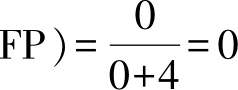 ,得到ROC曲线中的一个坐标(0.25,0).
,得到ROC曲线中的一个坐标(0.25,0).
表2.7 阈值位于(0.74,0.81]时样例预测标记与真实标记的对比

表2.8 阈值位于(0.74,0.81]时的分类结果混淆矩阵

依此类推,可以得到其他阈值下P-R曲线和ROC曲线中各点的坐标.
1. 针对P-R曲线,其横、纵坐标见表2.9(如图2.4a所示).
表2.9 P-R曲线坐标

左侧括号内计算了样本对中有多少负例被排在正例之前,若正负例预测值相同则记为0.5个.
2. 针对ROC曲线,其横、纵坐标见表2.10(如图2.4b所示).AUC为
AUC=0.25×0.5+0.25×0.75+0.25×1+0.25×1=0.8125 . (2.36)
表2.10 ROC曲线坐标

另外,根据教材中式(2.21)和式(2.22),以及表2.5中的数据,有 D + ={ x 1 , x 2 , x 4 , x 6 }, D - ={ x 3 , x 5 , x 7 , x 8 }.于是有
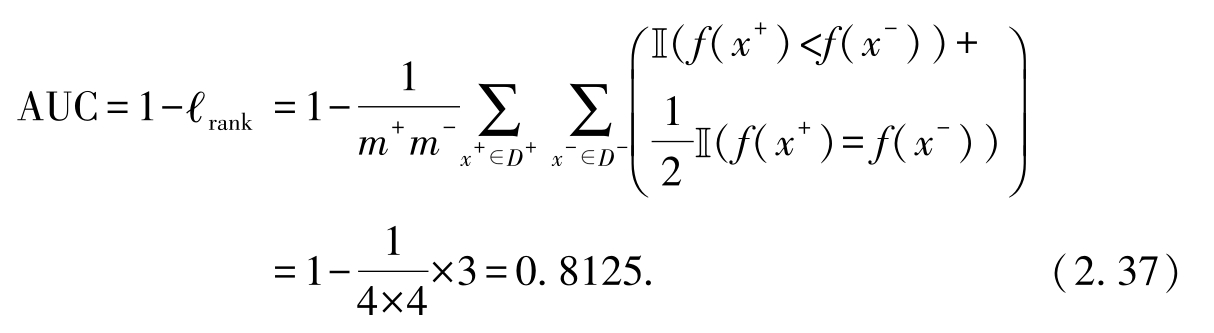
可以看到,通过这两种方式计算的结果相同.
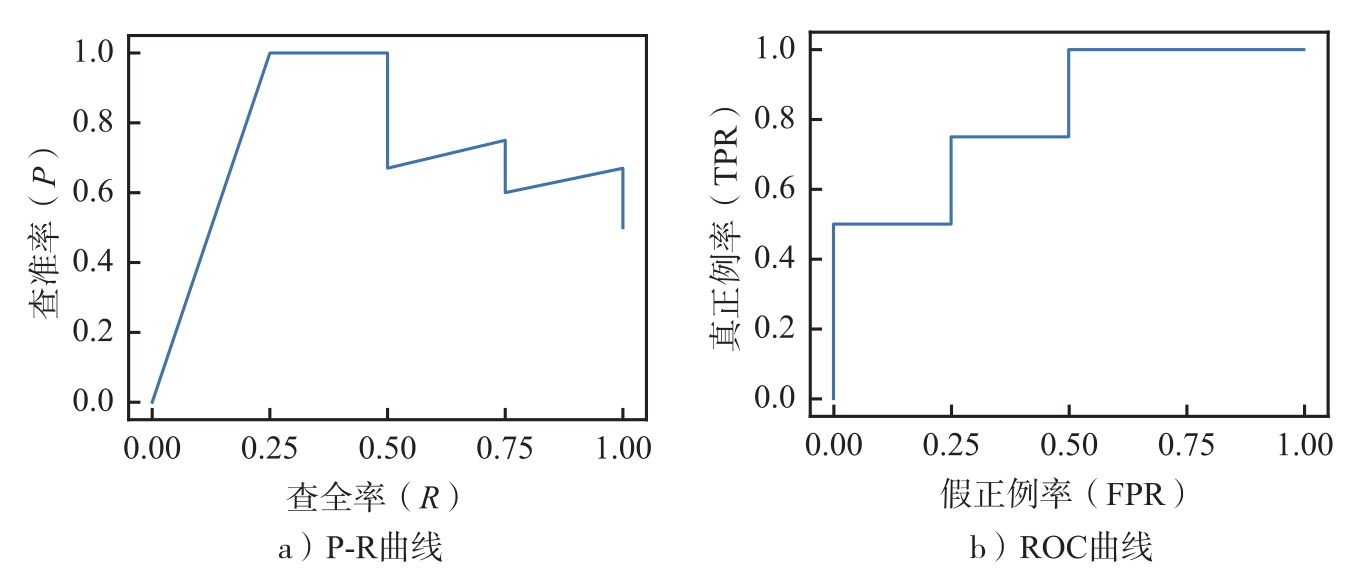
图2.4 P-R曲线与ROC曲线
绘制P-R曲线时,若阈值为0,所有样本均预测为正例,这时 P = m + /m ,其中 m + 为正例样本数, m 为样本总数, m + /m 是正例占所有样本的比例,而 R =1,此时右侧端点为( R =1, P = m + /m );若阈值为1,所有样本均预测为负例,这时 P =0 / 0未定义, R =0,为避免这一情况,可将阈值设置为略低于最大置信度的取值,从而使置信度最大的样本被预测为唯一的正例.在此情况下,若该样本真实标记为正,则 P =1 / 1=1, R =1 /m + 是一个极小值,若 m + 较大,则最左边的点坐标为( R ≈0, P =1),从视觉上来看,P-R曲线从(0,1)开始,到(1, m + /m )结束;但若置信度最大的样本真实标记为负,此时 P =0, R =0,曲线将从(0,0)开始,到(1, m + /m )结束.这一现象也将在习题2.9中进一步验证.
习题注释 本题考查P-R曲线和ROC曲线的理解.两类曲线的绘制方法类似,但需注意其中“点”的含义不同.此外,需注意P-R曲线中的极值点.P-R曲线的左端点的值与置信度最大的样本是正例还是负例有关,如果是正例,那么是从(0,1)开始,否则从(0,0)开始;右端点为(1, m + /m ),其中 m + 为正例样本数, m 为样本总数, m + /m 为正例占所有样本的比例.
习题2.8 教材2.3节介绍了AUC性能度量指标.对于有限样例,请证明
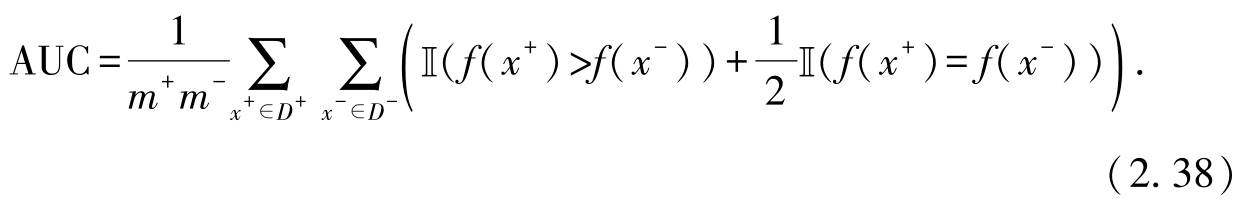
证明 考虑ROC曲线的绘制过程,设前一个样例在ROC曲线上的坐标为( x , y ),
1)若当前样例为真正例,则其在ROC曲线上的对应坐标为
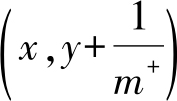 ;
;
2)若当前样例为假正例,则其在ROC曲线上的对应坐标为
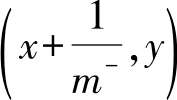 .
.
由此可知,对于任何一对正例和负例,
1)若其中正例预测值小于负例,则 x 值先增加, y 值后增加,曲线下方的面积(即AUC)将不会因此而增加.
2)若其中正例预测值大于负例,则
y
值先增加,
x
值后增加,曲线下方的面积(即AUC)将增加一个矩形格子的大小,其面积为
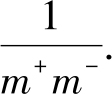
3)若其中正例预测值等于负例,则对应标记点
x
,
y
坐标值同时增加,曲线下方的面积(即AUC)将增加一个三角形的大小,其面积为
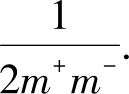
考虑所有正例和负例对,AUC的面积即为曲线下方的面积,根据上述情况进行累加,则有
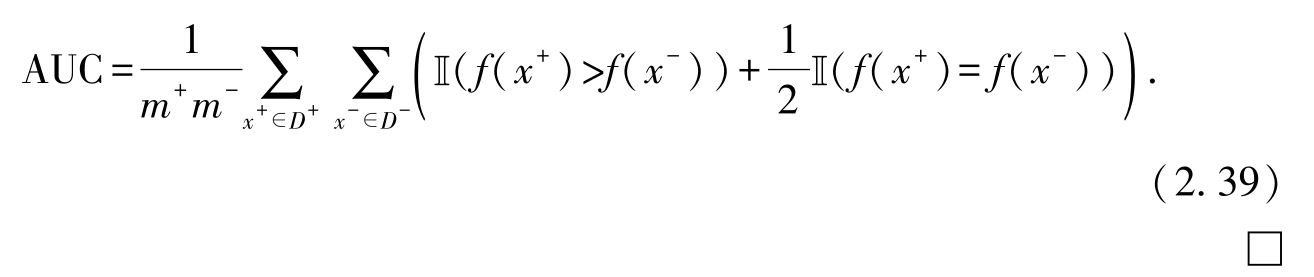
习题注释 本题考查对AUC的理解.AUC的计算有两种方式:一种方式是绘制ROC曲线,计算曲线下的面积;另一种方式是直接比较在模型预测的排序中有多少比例的正例被排在了负例的前面.习题2.7中的AUC结果已验证了这两种计算方式所得的结果一致.
习题2.9 现有500个测试样例,其对应的真实标记和学习器的输出值见表2.11(完整数据见data.csv文件).该任务是一个二分类任务,标记1表示正例,标记0表示负例.学习器的输出值越接近1表明学习器认为该样例越可能是正例(为正例的置信度越高),输出值越接近0表明学习器认为该样例越可能是负例.
表2.11 测试样例表

1. 请编程绘制P-R曲线.
2. 请编程绘制ROC曲线,并计算AUC.
需要注意数据中存在输出值相同的样例.
解答
P-R曲线和ROC曲线的绘制方法见习题2.7.当样例较多时,由于阈值很接近时坐标差异较小,也可以在整个[0,1]区间内均匀取值,计算将每一个临界值作为阈值时的对应坐标值.
1. P-R曲线的绘制.首先对模型预测结果按照输出值进行排序,保证排序后从前到后样例为正例的可能性逐渐降低.然后,选择(0,0.999)间的1000个数作为判为正例的临界阈值,分别计算这些值下的查全率和查准率.最后,根据这1000组数据绘制出P-R曲线,其中,给定阈值 x 时计算P-R曲线的程序如下:

2. ROC曲线的绘制与P-R图类似.首先对模型预测结果按照输出值进行排序,保证排序后从前到后样例为正例的可能性逐渐降低.然后,选择(0,0.999)间的1000个数作为判为正例的临界阈值,分别计算这些值下的真正例率和假正例率.最后,根据这1000组数据绘制出ROC曲线.ROC实现代码如下:

27行使用函数pr_curve可绘制P-R曲线.

所绘制的P-R曲线和ROC曲线如图2.5所示.
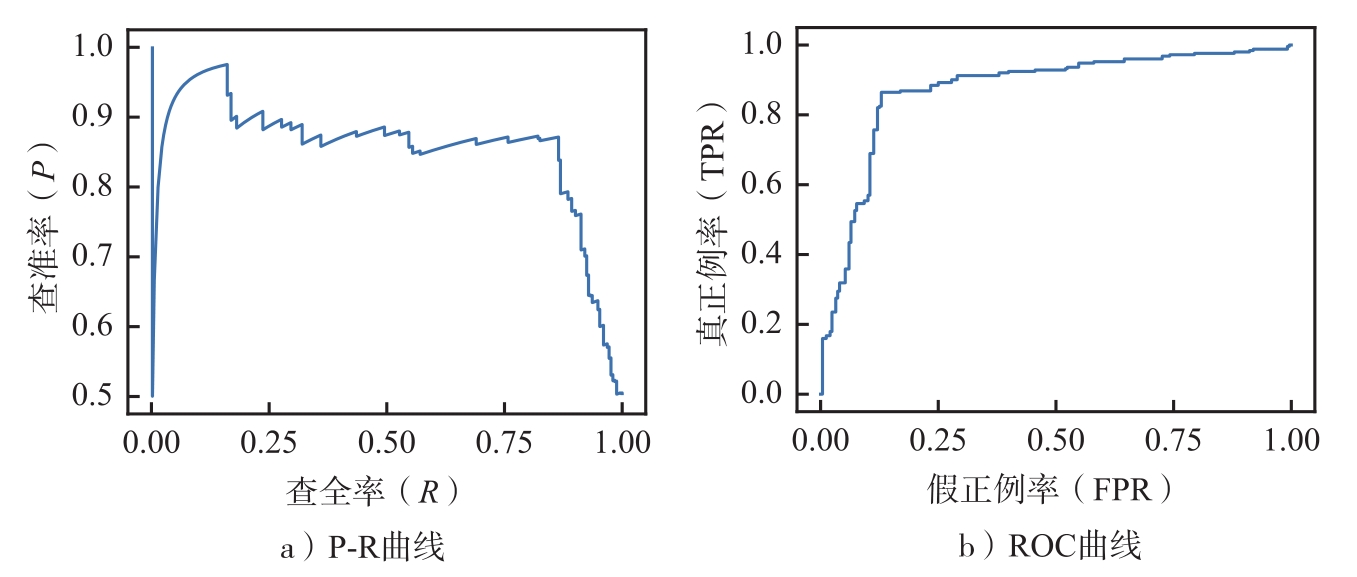
图2.5 P-R曲线和ROC曲线
在绘制P-R曲线和ROC曲线的过程中,需要注意横、纵坐标的值,并给出对应的轴名称.
依照式(2.38)计算得到的AUC值约为0.8737.AUC公式计算的实现代码如下:

dataset.values是模型对500个样本置信度的列表(list).基于式(2.39),AUC的计算查看所有正负样本对的组合,因此使用value1和value2对该列表进行两层循环的遍历.
习题2.10 教材2.4节介绍了机器学习中用于比较检验的方法.在数据集 D 1 , D 2 , D 3 , D 4 , D 5 上运行A,B,C,D,E五种算法,算法比较序值见表2.12:
表2.12 算法比较序值表
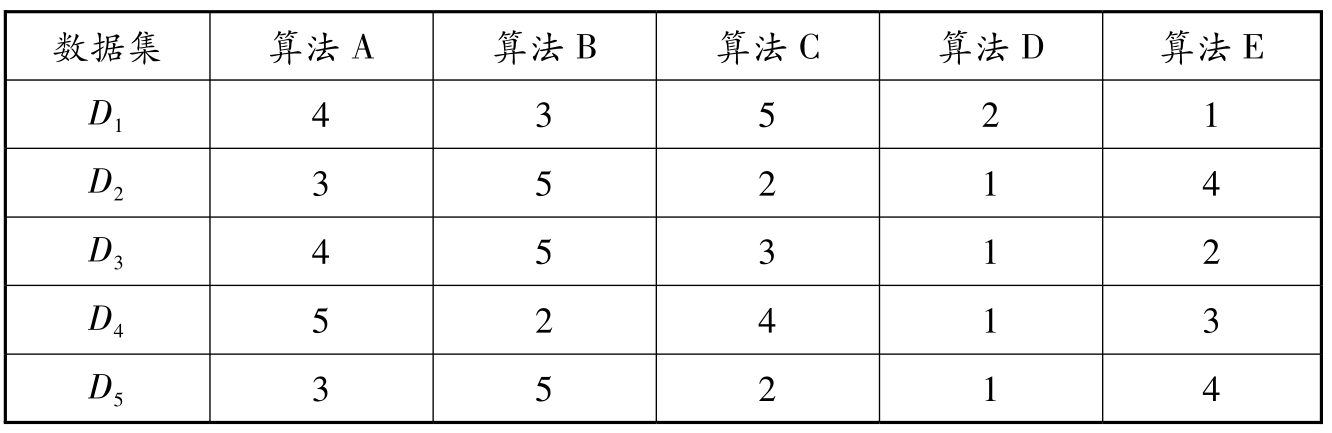
1. 使用Friedman检验( α =0.05)判断这些算法是否性能都相同.
2. 若不相同,进行Nemenyi后续检验( α =0.05),并说明性能最好的算法与哪些算法有显著差别.
3. 基于上述结果,绘制Nemenyi后续检验图.
解答
1. 先给出两个假设.
● H 0 :五种算法的性能无差异.
● H 1 :五种算法的性能有明显差异.
为了验证假设的正确性,需要进行假设检验(hypothesis test).首先,计算不同算法的平均序值(见表2.13),接下来,考虑Friedman检验:
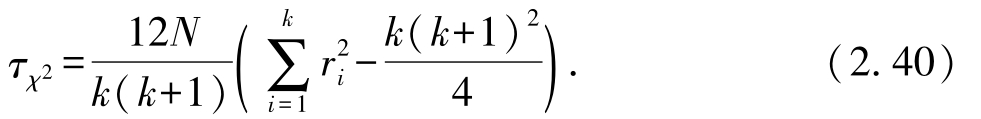
其中, k 表示所比较算法的数量, N 表示数据集的数量.
表2.13 算法平均序值表

变量
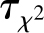 服从自由度为
k
-1=4的
χ
2
分布,其中
N
=5,
k
=5,代入可以求得
服从自由度为
k
-1=4的
χ
2
分布,其中
N
=5,
k
=5,代入可以求得
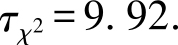 用更常用的
F
分布来进行检验:
用更常用的
F
分布来进行检验:

得到 τ F =3.9365.查表可知 F 检验的临界值为3.007,由于 τ F =3.9365>3.007,因此否定 H 0 假设,认为五种算法的性能有明显差异.
2. 使用Nemenyi后续检验对算法的性能进行进一步分析,其中,

查表可知 q α =2.728,代入数值得到 CD =2.728,因此,算法D和算法B有明显差异,算法D和其他算法之间没有明显差异.
3. 基于上述结果绘制的Nemenyi后续检验图如图2.6所示.首先基于表2.13中的数据绘制每个算法的平均性能.然后以具有最佳平均性能的算法D为起点,以D -CD 为终点,绘制一条临界值域线.可以观察到,这条线与算法A、C、E均有交点,而与算法B无交点.因此可以得出结论,算法D和算法B具有显著差异,而与其他3个算法之间没有显著差异.
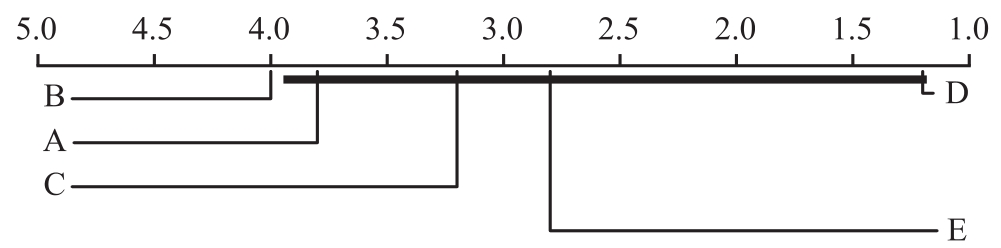
图2.6 Nemenyi后续检验图

习题2.11
教材2.5节介绍了回归任务中的偏差-方差分解(bias-variance decomposition).给定数据集
D
,学习算法的期望预测为
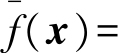
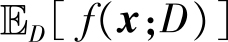 ,使用不同训练集产生的偏差(bias)为
,使用不同训练集产生的偏差(bias)为
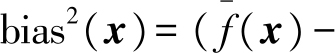 y
)
2
,方差(variance)为
y
)
2
,方差(variance)为
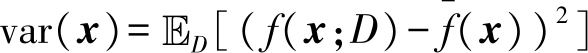 ,噪声为
ε
2
=E
D
[(
y
D
-y
)
2
]
.
本题对偏差-方差分解
,噪声为
ε
2
=E
D
[(
y
D
-y
)
2
]
.
本题对偏差-方差分解
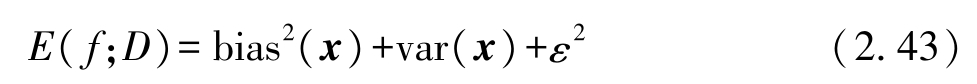
进行验证.考虑如习题2.1中的回归问题,定义真实曲线为

按照如下方式产生数据:

使用测试集衡量泛化误差,在训练集中使用自助法模拟不同数据集并获得多个(200个)模型.使用{1,4,30}阶多项式对数据进行拟合,计算对期望误差、偏差、方差的估计.画出模型拟合结果,并比较使用不同模型时偏差和方差的情况.
题干公式中E D 用自助法模拟.
解答
针对给定的数据,使用如下方式构建多项式回归模型:

为便于从训练集中抽取数据,定义自助法函数:

从而,可通过如下方法估计偏差和方差:

不同阶数的多项式的拟合结果如图2.7所示.对于每一种情况,随机选出3个模型,画出其预测结果.值得注意的是,这3种情况的总误差是不同的.
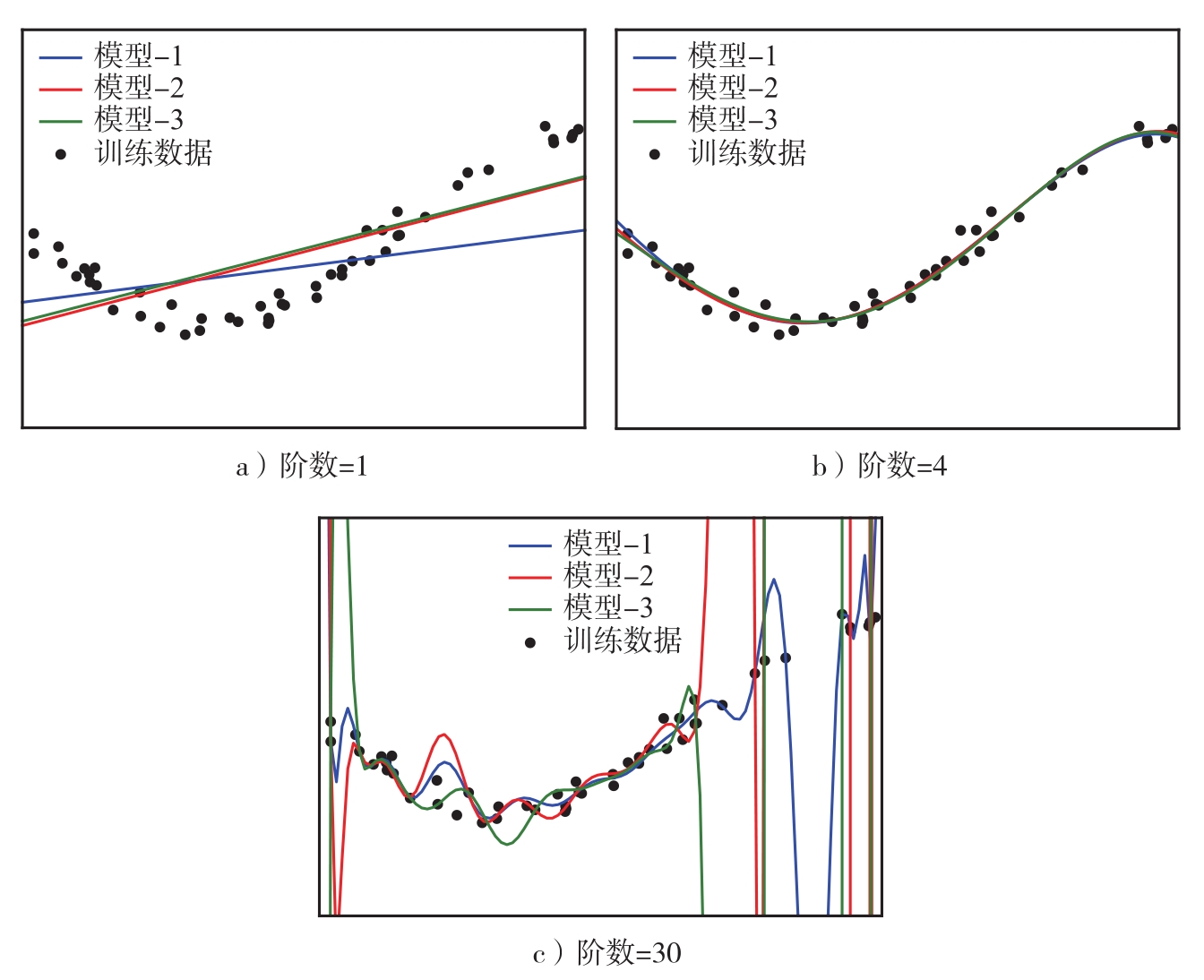
图2.7 不同阶数的多项式的拟合结果
可以看出在图2.7a中,当阶数为1时,使用一条直线拟合数据,此时估计的偏差为0.2,估计的方差为0.01.由于数据本身具有波动趋势,使用线性模型拟合具有较大的偏差,而方差相对较小.当阶数为4时,使用曲线拟合,结果如图2.7b所示,偏差为0.01,方差为0.001.和图2.7a相比,多项式模型更加符合数据本身的趋势,偏差明显减小,方差也有所减小,说明使用当前模型能够获得更好的泛化能力.而在图2.7c中,使用更高阶的多项式拟合数据,发生过拟合,偏差为1.14×10 11 ,方差为1.64×10 14 ,均非常大,说明该模型一方面和真实曲线偏差过大,另一方面不稳定,导致在不同的数据集下产生模型的震荡.
习题2.12 考虑 m 个从分布 p ( x )中独立同分布抽取的(互不相等的)观测值 x 1 , x 2 ,…, x m , p ( x )的均值为 μ ,方差为 σ 2 .
请从偏差、方差的角度分析如下两种均值估计形式的优劣:
1. 基于习题2.4,通过 m 个样例,可采用式(2.1)的方式使用 x m 估计分布的均值.
2. 基于常数 κ 0 和对均值的一个初始估计 μ 0 ,使用如下方式进行均值估计:

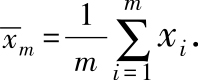
解答
基于给定的估计形式,分析估计量的期望和方差:
1.
根据习题2.4的分析,可知
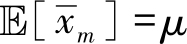 ,是无偏估计,因此偏差为0,而方差
,是无偏估计,因此偏差为0,而方差
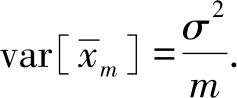
2.
对于第二种估计方式,
κ
0
为常数,记
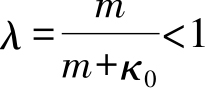 ,则
,则
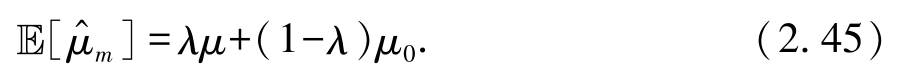
若
μ
0
≠
μ
,则该估计方式不是无偏估计,具有偏差,而其方差
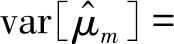
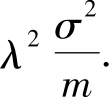 因此,虽然这种估计方式的偏差非0,但其相比于前一种估计方式具有更小的方差,当
μ
0
设置得足够好时,
因此,虽然这种估计方式的偏差非0,但其相比于前一种估计方式具有更小的方差,当
μ
0
设置得足够好时,
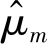 可能具有更低的总误差.
可能具有更低的总误差.
习题注释
本题考查不同统计量估计方式的性质。这两种估计方式
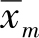 和
和
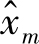 分别对应了机器学习中常用的极大似然估计(Maximum Likelihood Estimation,MLE)和最大后验估计(Maximum A Posterior estimation,MAP)的结果,式(2.44)的估计方式结合了均值的先验
μ
0
,在教材7.2节和本书问题7.3中有更详细的叙述.
分别对应了机器学习中常用的极大似然估计(Maximum Likelihood Estimation,MLE)和最大后验估计(Maximum A Posterior estimation,MAP)的结果,式(2.44)的估计方式结合了均值的先验
μ
0
,在教材7.2节和本书问题7.3中有更详细的叙述.
[1]YE H J, CHEN H Y, ZHAN D C, et al.Identifying and compensating for feature deviation in imbalanced deep learning[J].arXiv preprint, 2020, arXiv:2001.01385.
[2]BELKIN M, HSU D, MA S, et al.Reconciling modern machine-learning practice and the classical bias-variance trade-off[J].Proceedings of the National Academy of Sciences, 2019, 116(32):15849-15854.
[3]VINYALS O, BLUNDELL C, LILLICRAP T, et al.Matching networks for one shot learning[C]//Advances in Neural Information Processing Systems 29(NeurIPS).Red Hook:Curran Associates, Inc., 2016:3630-3638.
[4]SNELL J, SWERSKY K, ZEMEL R S.Prototypical networks for few-shot learning[C]//Advances in Neural Information Processing Systems 30(NeurIPS).Red Hook:Curran Associates, Inc., 2017:4077-4087.
[5]BAXTER J.A model of inductive bias learning[J].Journal of Artifical Intelligence Research, 2000, 12(1):149-198.
[6]MAURER A, PONTIL M, ROMERA-PAREDES B.The benefit of multitask representation learning[J].Journal of Machine Learning Research, 2016, 17(1):2853-2884.
[7]CHAO W L, YE H J, ZHAN D C, et al.Revisiting meta-learning as supervised learning[J].arXiv preprint, 2020, arXiv:2002.00573.
[8]WASSERMAN L.All of statistics[M].New York:Springer, 2004.