
下载掌阅APP,畅读海量书库
立即打开



多核处理器包含CPU内核、高速缓存、内存管理单元、总线接口单元、通用中断控制器、调试与跟踪单元、侦听控制单元、加速器一致性端口等。基于ARMv8-A架构的四核Cortex-A57如图1.2所示。
CPU的计算速度与主频、流水线(Pipeline)和总线等各方面的性能指标有关。主频是CPU内核的工作时钟频率,单位是兆赫(MHz)或吉赫(GHz)。流水线通常是多级的,几乎所有的冯·诺依曼型处理器都基于5个基本操作:取指(Instruction Fetch,IF)、译码(Instruction Decode,ID)、执行(Execute,EXE)、访存(MEMory access,MEM)和写回(Write Back,WB)。高性能CPU还会增加重命名、派发、发射操作,而低功耗CPU会合并某些操作。这些操作可以顺序执行,也可以乱序执行。总线频率影响CPU与外部的数据交换,总线带宽取决于总线频率和传输数据位宽。
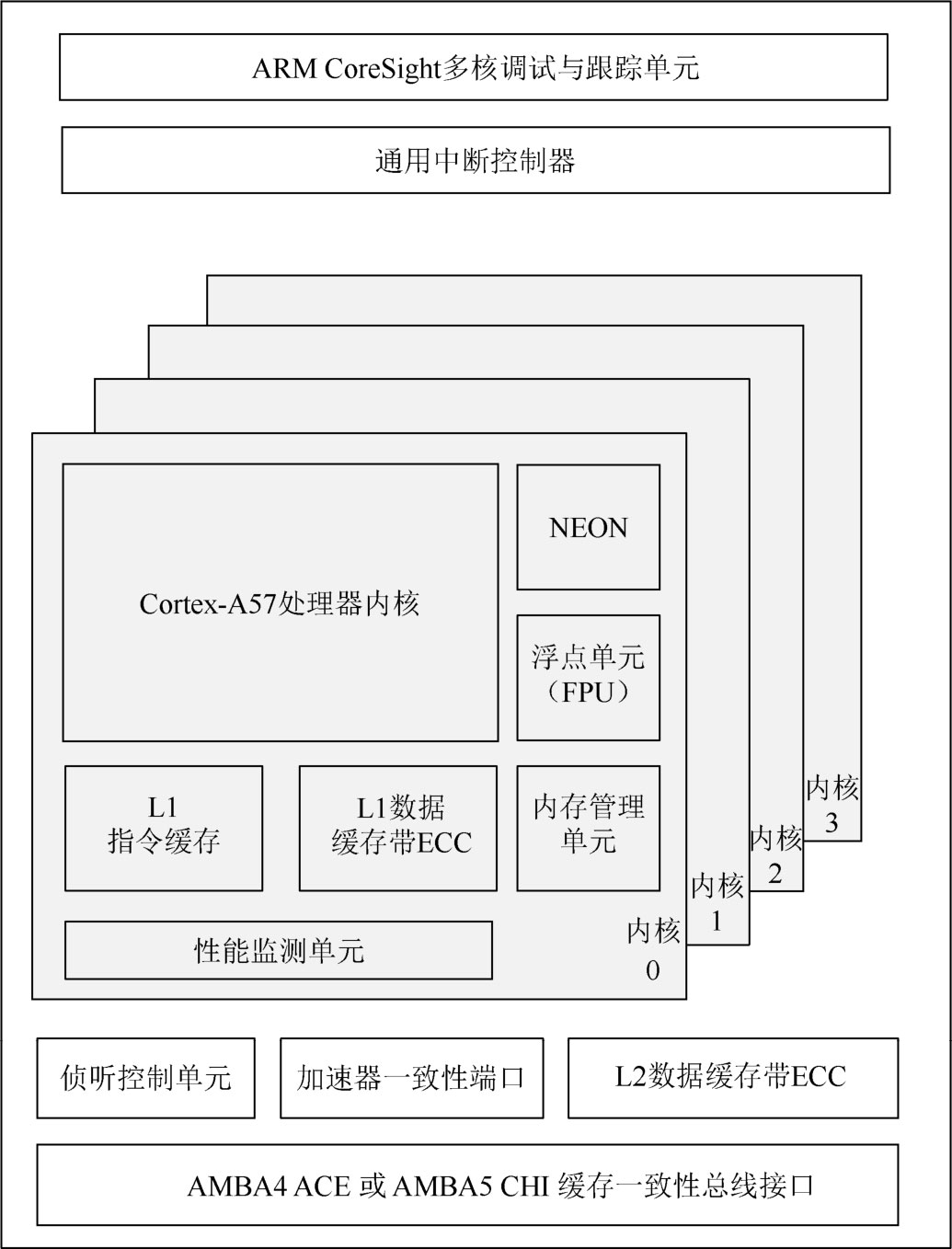
图1.2 基于ARMv8-A架构的四核Cortex-A57
目前,类似ARM处理器的通用处理器均采用片上多级缓存方式来解决处理器与内存之间的速度不匹配问题。
对于多处理器系统来说,如果共享内存,则存在缓存一致性问题,可以由软件或缓存一致性管理硬件来处理。
内存中的每个单元都有一个唯一的编号,此编号即内存地址,或者称为物理地址。内存地址的集合称为内存地址空间或物理地址空间。源程序经过汇编或编译后形成目标程序,目标程序中的地址称为逻辑地址或虚拟地址,并且每个目标程序都是从0地址开始编址的。
内存管理单元(Memory Management Unit,MMU)负责将用户程序中指令或数据的逻辑地址转换为存储空间中的物理地址,这个过程称为内存映射。
总线接口单元(Bus Interface Unit,BIU)负责处理器与外部总线、内存之间的数据传输,以实现高带宽和低延迟。
中断是芯片的重要功能。当产生中断时,处理器的中断处理函数可以打断主程序的执行,并在处理完成后重新交回主程序。
大多数处理器内置中断控制器。如果缺失或中断控制器不足,则可以外接中断控制器。通用中断控制器(Generic Interrupt Controller,GIC)提供了一种强大且灵活的方式,以实现处理器间通信、路由系统中断和优先级确定。
处理器运行时需要实时观测内核状态,片上跟踪功能是指通过专用硬件非入侵地实时记录程序执行路径和数据读写等信息,并将这些信息压缩成跟踪数据流,通过专用数据通道和输出接口传输至调试主机。调试主机中的开发工具解压缩跟踪数据流,恢复程序运行信息以供调试和性能分析。
较早期的处理器采用JTAG标准调试,但现在的ARM处理器统一使用内存映射方式进行调试。
多个处理器的调试与跟踪单元(Debug and Trace Unit)可以分别外连,或者内部以菊花链(Daisy Chain)方式连接后再连出。
侦听控制单元(Snoop Control Unit,SCU)维护多处理器内核与下级共享缓存之间的一致性,降低在各个操作系统驱动程序中维持软件一致性所涉及的软件复杂性。
加速器一致性端口(Accelerator Coherency Port,ACP)是ARM处理器多核架构下定义的一种端口,用于管理不带缓存的外设,从而提高处理器运行效率并与外部数据源达成可靠的高速缓存一致性。
加速器一致性端口可用作标准的辅助端口,它支持所有标准读写事务,并且对连接的组件没有任何其他一致性要求。针对可缓存内存区域的任何读事务,该端口都会与侦听控制单元交互,以测试所需信息是否已存储在处理器高速缓存内。如果已经存储于其中,则将数据直接返回请求组件,否则转入下级缓存或内存。针对可缓存内存区域的任何写事务,在将写数据转发到内存系统之前,侦听控制单元会强制其保持一致性。
处理器子系统拥有两个或多个紧密通信的处理器、共享总线、内存和外设等,主要关注缓存一致性和启动等。
SoC有多个处理器内核或多个处理器,以允许不同进程同时运行,提高系统速度。
具有多个内核的处理器被称为多核处理器(Multi-Core Processor)。一般而言,物理内核越多,性能越强。目前,主流的处理器是四核以上的,有些已经达到十六核。多处理器(Multi-Processor)是指芯片上包含两个或多个同构或异构处理器,分为单芯片多处理器(Chip Multi-Processor,CMP)和片上多处理器系统(Multi-Processor System-on-Chip,MPSoC)两大技术类型。CMP一般见于通用计算类型SoC,如服务器芯片,而MPSoC一般见于复杂计算类型SoC,如多媒体芯片。
一般SoC芯片启动时,会从内部ROM(Internal ROM,IROM)中运行程序。某些芯片提供多种启动方式,当无法从IROM中启动时,可以从其他源启动,从而增强芯片的容错能力;有时基于不同需求而从不同源启动,如Nor Flash提供XIP(eXecute In Place,就地执行)模式,程序可直接运行于其上。芯片在启动和运行时,通常需要使用内部RAM(Internal RAM,IRAM)。
ROM内部的数据是在制造工序中使用特殊方法烧录进去的,其内容只能读不能改,因此一旦烧录进去,用户只能验证写入数据的正确性而不能进行任何修改。
随着5G、AI等新技术不断发展,计算场景变得丰富多样,异构处理器(XPU)的发展成为大势所趋。SoC使用不同类型的处理器或可编程引擎的组合,根据各自的任务,对内存和通信进行优化。不过从处理器的角度来看,XPU中的大部分都非真正的处理器。
图像处理器(Graphics Processing Unit,GPU)采用数量众多的计算单元和超长的流水线,以解决处理器在大规模并行计算中所遭遇的难题,提高数据处理速度。GPU不能单独工作,必须由处理器控制调用才行。当处理器需要处理大量类型统一的数据时,可以调用GPU进行并行计算。GPU在图像处理方面的能力非常强,因为图像上的每一个像素点都有处理需求,而且处理过程和方式十分相似,所以可以并行计算。GPU并不限于图像处理,目前还被广泛应用于科学计算、密码破解、数值分析和海量数据处理等需要大规模并行计算的领域。图1.3所示为CPU和GPU的微架构示意图。
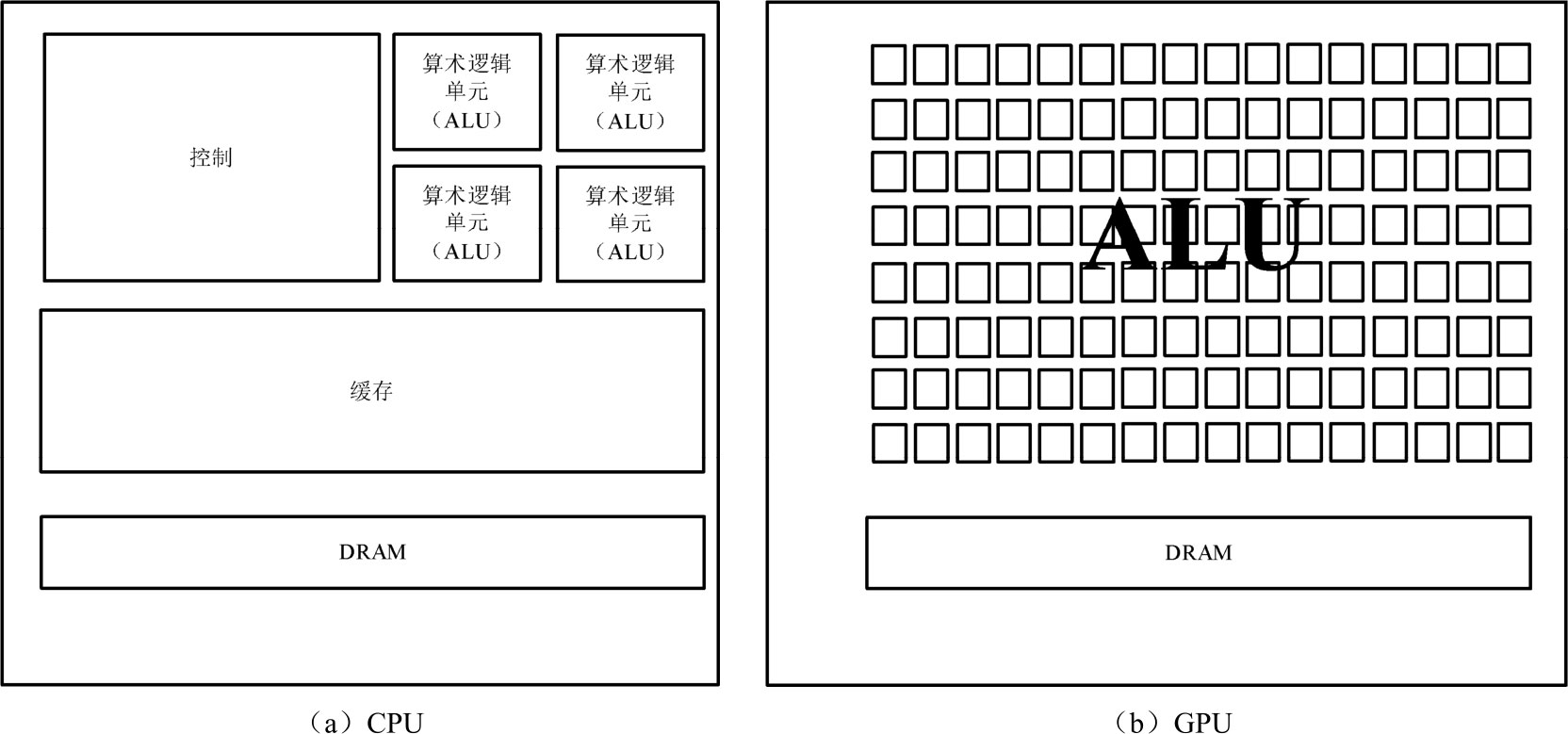
图1.3 CPU和GPU的微架构示意图
数据处理器(Data Processor)是面向数据处理的专用处理器。数据处理器正在取代CPU成为数据中心服务器的中央控制点,从而建立以数据为中心的计算架构。
深度学习处理器是基于深度学习算法的专用处理器,一般用于训练或推理。DLPU可以运行开源的深度学习神经网络模型,这个过程通常需要专门的工具链进行适配,并需要针对不同的网络模型进行优化,以发挥出其最佳性能。
起初机器学习及图像处理算法大部分都在CPU和GPU上运行,它们作为通用型芯片,在效能和功耗上不能紧密适配机器学习算法,而且价格比较贵。张量处理器(Tensor Processing Unit,TPU)是谷歌专门为提高深度学习神经网络计算能力而研发的一款ASIC,最早的TPU就比同期的标准CPU和GPU快15~30倍,效能提升30~80倍。