
下载掌阅APP,畅读海量书库
立即打开



前面介绍的分类问题是利用已知类别的样本(训练集)来构造分类器的。其训练集样本是已知类别的,所以又称为有监督学习(或有教师分类)。在已知类别样本的“指导”(监督)下对单个待测样本进行分类。聚类问题则不同,它是指利用样本的特性来构造分类器。这种分类为无监督分类,通常称为聚类或集群。
聚类分析是指事先不了解一批样本中的每一个样本的类别或其他的先验知识,而唯一的分类依据是样本的特征,利用某种相似性度量的方法,把特征相同或相近的样本归为一类,实现聚类划分。
聚类分析是对探测数据进行分类分析的一个工具,许多学科要根据所测得的或感知到的相似性对数据进行分类,把探测数据归到各个聚合类中,且在同一个聚合类中的模式比在不同聚合类中的模式更相似,从而对模式间的相互关系做出估计。聚类分析的结果可以被用来对数据提出初始假设、分类新数据、测试数据的同类型及压缩数据。
聚类算法的重点是寻找特征相似的聚合类。人类是二维的最佳分类器,然而大多数实际问题涉及高维的聚类。对高维空间内的数据的直观解释,其困难是明显的,另外,数据也不会服从规则的理想分布,这就是大量聚类算法出现的原因。在图像中进行聚类分析,当一幅图像中含有多个物体时,需要对不同的物体进行分割标识。
1.聚类的定义
Everttt提出一个聚合类是一些相似的实体的集合,而且不同聚合类的实体是不相似的。在一个聚合类内两个点间的距离小于在这个类内的任一点和不在这个类内的任一点间的距离。聚合类可以被描述成在 n 维空间内存在较高密度点的连续区域和较低密度点的区域,而较低密度点的区域把其他较高密度点的区域分开。
在模式空间 S 若给定 N 个样本 X 1 , X 2 ,…, X N ,聚类的定义则是:按照相互类似的程度找到相应的区域 R 1 , R 2 ,…, R M ,将任意 X i ( i =1,2,…, N )归入其中一类,而且 X i 不会同时属于两类,即
R 1 ∪ R 2 ∪…∪ R M = R
R i ∩ R j =∅( i ≠ j )
这里∪、∩分别为并集、交集。
选择聚类的方法应以一个理想的聚类概念为基础。然而,如果数据不满足聚类技术所做的假设,则算法不是去发现真实的数据结构而是在数据上强加上某一种结构。
2.聚类准则
设有未知类别的 N 个样本,要把它们划分到 M 类中去,可以有多种优劣不同的聚类方法,怎样评价聚类的优劣,这就需要确定一种聚类准则。但客观来说,聚类的优劣是就某一种评价准则而言的,很难有对各种准则均呈优良表现的聚类方法。
聚类准则的确定,基本上有两种方法。一种是试探法,根据所分类的问题,试探性地进行样本的划分,确定一种准则,并用它来判断样本分类是否合理。例如,以距离函数作为相似性的度量,用不断修改的阈值,来探究聚类对此种准则的满足程度,当取得极小值时,就认为得到了最佳划分。另一种是群体智能方法,随着对生物学的深入研究,人们逐渐发现自然界中的某些个体虽然行为简单且能力非常有限,但当它们一起协同工作时,表现出来的并不是简单的个体能力的叠加,而是非常复杂的行为特征,群体智能优化算法在没有集中控制并且不提供全局模型的前提下,利用群体的优势,分布搜索,这种方法一般能够比传统的优化方法更快地发现复杂优化问题的最优解,为寻找复杂问题的最佳方案提供了新的思路和新的方法。
下面给出一种简单而又广泛应用的准则,即误差平方和准则:
设有 N 个样本,分属于 ω 1 , ω 2 ,…, ω M 类,设有 N i 个样本的 ω i 类,其均值为
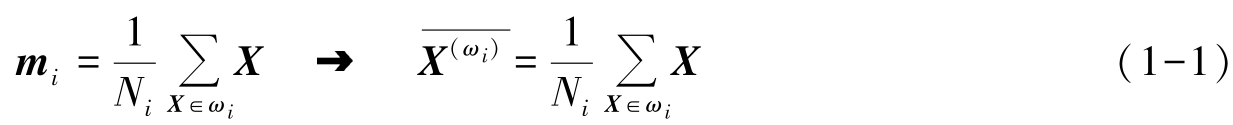
因为有若干种方法可将 N 个样本划分到 M 类中去,因此对应一种划分,可求得一个误差平方和 J ,要找到使 J 值最小的那种划分。定义误差平方和为
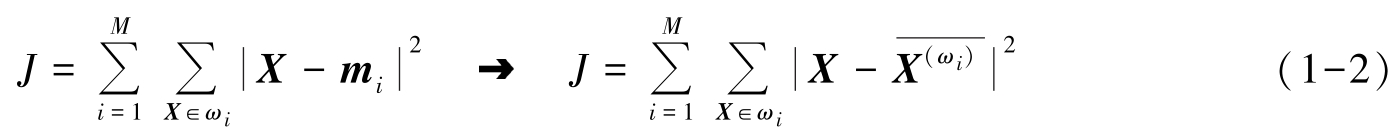
样本分布与误差平方和准则的关系如图1-4所示。经验表明,当各类样本均很密集,各类样本个数相差不大,而类间距离较大时,适合采用误差平方和准则,见图1-4(a)。若各类样本数相差很大,类间距离较小时,就有可能将样本数多的类一分为二,而得到的 J 值却比大类保持完整时得到的小,误以为得到了最优划分,实际上得到了错误的划分,见图1-4(b)。
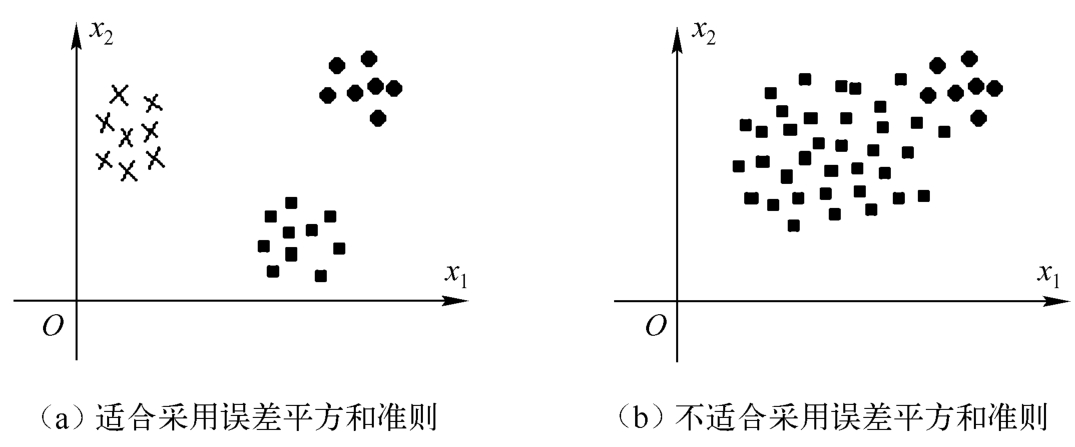
图1-4 样本分布与误差平方和准则的关系
基于试探法的聚类设计首先假设某种分类方案,确定一种聚类准则,然后计算 J 值,找到 J 值最小的那一种分类方案,则认为该种方法为最优分类。基于试探法的未知类别聚类算法,包括最临近规则的试探法、最大最小距离试探法和层次聚类试探法。
1.最临近规则的试探法
假设前 i 个样本已经被分到 k 个类中。则第 i +1个样本应该归入哪一个类中呢?假设归入 ω a 类,要使 J 最小,则应满足第 i +1个样本到 ω a 类的距离小于给定的阈值 T ,若大于给定的阈值 T ,则应为其建立一个新的类 ω k +1 。在未将所有的样本分类前,类数是不能确定的。
这种算法与第一个中心的选取、阈值 T 的大小、样本排列次序及样本分布的几何特性有关。这种方法运算简单,当有关于模式几何分布的先验知识作为指导给出阈值 T 及初始点时,则能较快地获得合理的聚类结果。
2.最大最小距离试探法
最临近规则的试探法受阈值 T 的影响很大,阈值的选取是聚类设计成败的关键之一。最大最小距离试探法充分利用样本内部特性,计算出所有样本间的最大距离作为归类阈值的参考,改善了分类的准确性。例如,当某样本到某一个聚类中心的距离小于最大距离的一半时,则归入该类,否则建立新的聚类中心。
3.层次聚类试探法
层次聚类试探法对给定的数据集进行层次上的分解,直到满足某种条件为止。具体又可分为合并、分裂两种方案。
合并的层次聚类是一种自底向上的策略,首先将每个对象作为一个类,然后根据类间距离的不同,合并距离小于阈值的类,合并一些相似的样本,直到终结条件被满足,合并算法会在每一步均减小聚类中心数量,每一步聚类产生的结果都来自于前一步的两个聚类的合并。绝大多数层次聚类方法属于这一类,它们只是在相似度的定义上有所不同。
分裂的层次聚类与合并的层次聚类相反,采用自顶向下的策略,它首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的样本簇,直到满足某种终止条件。分裂算法与合并算法的原理相反,会在每一步均增加聚类中心数量,每一步聚类产生的结果,都是由前一步的一个聚类中心分裂成两个得到的。
群体智能优化算法的仿生计算一般由初始化种群、个体更新和群体更新三个过程组成。下面分别介绍这三个过程的仿生计算机制。
1.初始化种群
在任何一种群体智能优化算法中,都包含种群的初始化。种群的初始化是指假设群体中的每个样本已经被随机分到某个类中,产生若干个个体,并人为地认为这些群体中的每一个个体为所求问题的解。因此,一般需要对所求问题的解空间进行编码操作,将具体的实际问题以某种解的形式给出,便于对问题进行描述和求解。初始化种群的产生一般有两种方式:一种是完全随机产生的方式,另一种是结合先验知识产生的方式。在没有任何先验知识的情况下往往采用第一种方式,而第二种方式可以使得算法较快收敛到最优解。种群的初始化主要包括问题解形式的确定、算法参数的选取、评估函数的确定等。
2.个体更新
个体的更新是群体智能优化算法中的关键一步,是群体质量提高的驱动力。在自然界中,个体的能力非常有限,行为也比较简单,但是,有时当多个简单的个体组合成一个群体之后,将会有非常强大的功能,能够完成许多复杂的工作。如蚁群能够完成筑巢、觅食,蜂群能够高效完成采蜜、喂养和保卫工作,鱼群能够快速完成寻找食物、躲避攻击等工作。
群体智能优化算法中,采用简单的编码技术来表示一个个体所具有的复杂结构,在寻优搜索过程中,对一群用编码表示的个体进行简单操作,本书将这些操作称作“算子”。个体的更新依靠这些算子实现,不同的群体智能优化算法仿生构造了不同的算子。如进化算法中的交叉算子、重组算子,或者变异算子、选择算子;蚁群算法中的蚂蚁移动算子、信息素更新算子。
个体更新的方式主要分为两种:一种是依靠自身的能力在解空间中寻找新的解;另一种是受到其他解(如当前群体中的最优解或邻域最优解)的影响而更新自身。
3.群体更新
在基于群体概念的仿生智能算法中,群体更新是种群中个体更新的宏观表现,它对于算法的搜索和收敛性能具有重要作用。在不同的仿生群体智能优化算法中,存在着不同的群体更新方式。主要有三种方式:个体更新实现群体更新,子群更新实现群体更新,选择机制实现群体更新。