
下载掌阅APP,畅读海量书库
立即打开



模式识别分类问题是指根据待识别对象所呈现的观察值,将其分到某个类别中去。具体步骤首先是建立特征空间中的训练集,已知训练集里每个点的所属类别,从这些条件出发,寻求某种判别函数或判别准则,设计判别函数模型,然后根据训练集中的样本确定模型中的参数,便可将模型用于判别,利用判别函数或判别准则去判别每个未知类别的点应该属于哪一类。
如何做出合理的判决就是模式识别分类器要讨论的问题。在统计模式识别中,感兴趣的主要问题并不在于决策的正误,而在于如何使由于决策错误造成的分类误差在整个识别过程中的风险代价降到最小。模式识别算法的设计都是强调“最佳”与“最优”,即希望所设计的系统在性能上达到最优。这种最优是针对某一种设计原则来讲的,这种原则称为准则,常用的准则有最小错误率准则、最小风险准则、近邻准则、Fisher准则、均方误差最小准则、感知准则等。设计一个准则,并使该准则达到最优的条件是设计模式识别系统最基本的方法。模式识别中以确定准则函数来实现优化的计算框架设计。分类器设计中使用什么准则是关键,会影响到分类器的效果。不同的决策规则反映了分类器设计者的不同考虑,对决策结果有不同的影响。
一般说来, M 类不同的物体应该具有各不相同的属性值,在 n 维特征空间中,各自有不同的分布。当某一特征向量值 X 只为某一类物体所特有时,对其做出决策是容易的,也不会出什么差错。问题在于当出现模棱两可的情况时,由于属于不同类的待识别对象存在着呈现相同特征值的可能,即所观察到的某一样本的特征向量为 X ,而在 M 类中又有不止一类样本可能呈现这一 X 值。例如癌症病人初期症状与正常人的症状相同,其两类样本分别用“-”与“+”表示。如图1-2所示, A 、 B 直线之间的样本属于不同类别,但是它们具有相同的特征值。从图1-2中可见这两类样本在二维特征空间中相互穿插,很难用简单的分界线将它们完全分开。如果用一直线作为分界线,称为线性分类器,针对图1-2中所示的样本分布情况,无论直线参数如何设计,总会有错分类现象的发生。此时,任何决策都存在判错的可能性。
模式识别的基本计算框架——制订准则函数,实现准则函数极值化,常用的准则有以下6种。
(1)最小错分率准则
完全以减少分类错误为原则,这是一个通用原则,见图1-2,如果以错分类最小为原则分类,则图中 A 直线可能是最佳的分界线,它使错分类的样本数量最小。
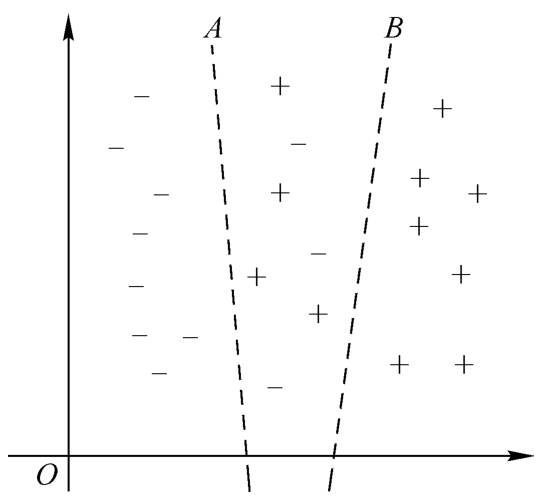
图1-2 分界线示意图(改后)
(2)最小风险准则
当接触到实际问题时,可以发现使错误率最小并不一定是一个普遍适用的最佳选择。有的分类系统将错分率多少看成最重要的指标(如对语音识别、文字识别来说这是最重要的指标),而有的分类系统对于错分率多少并不看重,而是要考虑错分类的不同后果(如对医疗诊断、地震、天气预报等)。例如可能多次将没有发生地震预报成有地震,也有可能已经发生地震但预报为没有地震,这类系统并不看重错分率,而是要考虑错分类引起的严重后果。例如上面讨论过的细胞分类中,如果把正常细胞错分为癌细胞,或发生相反方向的错误,其严重性可想而知。以 B 直线划分,有可能把正常细胞误判为异常细胞,“+”类样本错分成“-”类,给人带来不必要的痛苦,这种方法错分率多;但以 A 直线划分,有可能把癌细胞误判为正常细胞,“-”类样本错分成“+”类,会使病人因失去及早治疗的机会而遭受极大的损失,但这种方法错分率少。为使总的损失为最小,那么 B 直线就可能比 A 直线更适合作为分界线。这是基于最小风险的原理。
由此可见,根据不同性质的错误会引起不同程度的损失这一考虑出发,我们宁可扩大一些总的错误率,也要使总的损失减少。因此引入风险、损失这些概念,以便在决策时兼顾不同后果的影响。在实际问题中计算损失与风险是复杂的,在使用数学式子计算时,往往采用为变量赋予不同权值的方法来表示。在做出决策时,要考虑所承担的风险。基于最小风险的贝叶斯决策规则正是为了体现这一点而产生的。
(3)近邻准则
近邻准则是分段线性判别函数的一种典型方法。这种方法主要依据同类物体在特征空间具有聚类特性的原理。同类物体由于其性质相近,它们在特征空间中应具有聚类的现象,因此可以利用这种性质制订分类决策的规则。例如有两类样本,可以求出每一类的平均值,对于任何一个未知样本,先求出它到各个类的平均值距离,判断距离谁近就属于谁。
(4)Fisher准则
Fisher线性判别原理示意图如图1-3所示。根据两类样本一般类内密集、类间分离的特点,寻找线性分类器最佳的法线向量方向,使两类样本在该方向上的投影满足类内尽可能密集、类间尽可能分开的条件。把样本投影到任意一根直线上,有可能不同类别的样本就混在一起了,无法区分。由图1-3(a)可知,样本投影到 x 1 轴或 x 2 轴无法区分;若把直线绕原点转动一下,就有可能找到一个方向,使得样本投影到这个方向的直线上,各类样本能很好地分开,见图1-3(b)。因此直线方向的选择是很重要的。一般来说,总能够找到一个最好的方向,使样本投影到这个方向的直线上很容易分开。如何找到这个最好的直线方向,以及如何实现向最好方向投影的变换,正是Fisher算法要解决的基本问题。
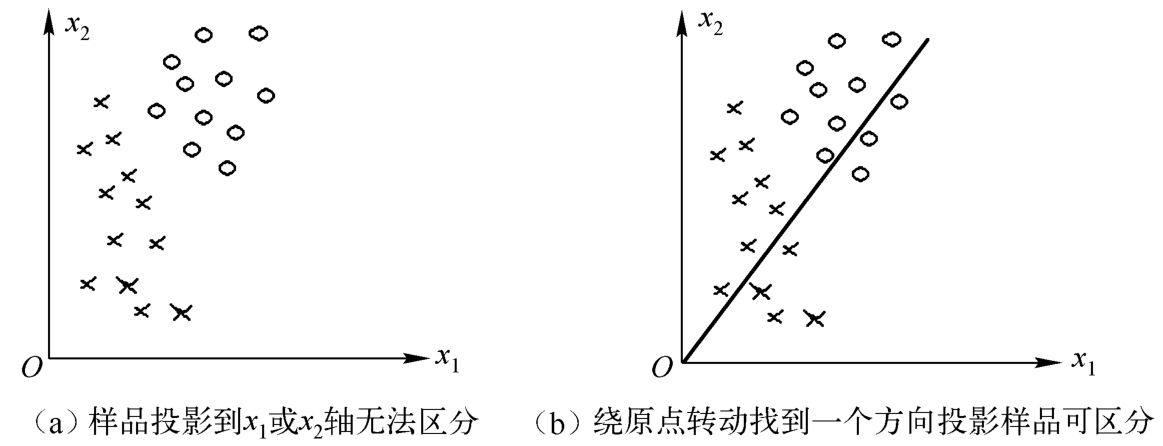
图1-3 Fisher线性判别原理示意图
这说明如果两类分布围绕各自均值的确相近,Fisher准则可使错误率较小,Fisher方法实际上涉及维数压缩的问题。
(5)感知准则
感知准则函数以使错分类样本到分界面距离之和最小为原则。提出利用错误信息实现迭代修正的学习原理,即利用错分类提供的信息修正错误。这种思想对机器学习的发展以及人工神经元网络的发展产生深远影响。其优点是通过错分类样本提供的信息对分类器函数进行修正,这种准则是人工神经元网络多层感知器的基础。
(6)最小均方误差准则
LMSE算法以最小均方误差作为准则。
在讨论了判别函数等概念后,设计分类器的任务就清楚了。根据样本分布情况来确定分类器的类型。在设计分类器时,要有一个样本集,样本集中的样本用一个各分量含义已经确定的向量来描述,也就是说对要分类的样本怎样描述这个问题是已经确定的。在这种条件下研究用贝叶斯分类器、线性分类器与非线性分类器等,以及这些分类器的其他设计问题。
按照基于统计参数的决策分类方法,判别函数及决策面方程的类别确定是由样本分布规律决定的,贝叶斯决策是基于统计分布确定的情况下计算的,如果要按贝叶斯决策方法设计分类器,就必须设法获得必需的统计参数。当有条件得到准确的统计分布知识(这些统计分布知识具体说来包括各类先验概率
P
(
ω
1
)及类条件概率密度函数,从而可以计算出样本的后验概率
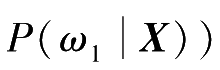 ,并以此作为产生判别函数的必要依据时,可利用贝叶斯决策来实现对样本的分类。但是,在这些参数未知的情况下使用贝叶斯决策方法,就得有一个学习阶段。在这个阶段,应设法获得一定数量的样本,然后从这些样本数据获得对样本概率分布的估计。有了概率分布的估计后,才能对未知的新样本按贝叶斯决策方法进行分类。
,并以此作为产生判别函数的必要依据时,可利用贝叶斯决策来实现对样本的分类。但是,在这些参数未知的情况下使用贝叶斯决策方法,就得有一个学习阶段。在这个阶段,应设法获得一定数量的样本,然后从这些样本数据获得对样本概率分布的估计。有了概率分布的估计后,才能对未知的新样本按贝叶斯决策方法进行分类。
在一般情况下要得到准确的统计分布知识是极其困难的事。当实际问题中并不具备获取准确统计分布的条件时,可使用几何分类器。几何分类器的设计过程主要是判别函数、决策面方程的确定过程。设计几何分类器首先要确定准则函数,然后再利用训练样本集确定该分类器的参数,以使所确定的准则达到最佳。在使用分类器时,样本的分类由其判别函数值决定。判别函数可以是线性函数也可以设计成非线性函数。设特征向量的特征分量数目为 n ,可分类数目为 M ,符合某种条件就可使用线性分类器,正态分布条件下一般适合用二次函数决策面。
①若可分类数目 M =2( n +1)≈2 n ,则几乎无法用一个线性函数分类器将它们分成两类。
②在模式识别中,理论上, M > n +1的线性分类器不能使用,但是如果一个类别的特征向量在空间中密集地聚集在一起,几乎不和其他类别的特征向量混合在一起,则无论 M 多大,线性分类器的效果总是良好的。在字符识别机中,线性函数分类器已经证明能够提供良好的识别效果,它能完成数量很大的字符识别任务。
因此,在手写数字识别中,只要读者规范书写数字,不同数字类别的特征空间就可以看成彼此分离的,而同一类别的数字在特征空间中集群性质较好,应用线性分类器是可行的。相反,如果特征向量的类集群性质不好,则线性分类器的效果总是不理想,此时,必须求助于非线性分类器。
所谓模式识别中的学习与训练是从训练样本提供的数据中找出某种数学式子的最优解,这个最优解使分类器得到一组参数,按这种参数设计的分类器使人们设计的某种准则达到极值。分类决策的具体数学公式是通过分类器设计这个过程确定的。在模式识别学科中一般把这个过程称为训练与学习的过程。
分类的规则是依据训练样本提供的信息确定的。分类器设计在训练过程中完成,利用一批训练样本(包括各种类别的样本),大致勾画出各类样本在特征空间分布的规律性,为确定使用什么样的数学公式及这些公式中的参数提供信息。一般来说,使用什么类型的分类函数是人为决定的。分类器参数的选择以及在学习过程得到的结果取决于设计者选择什么样的准则函数。不同准则函数的最优解对应不同的学习结果,进而得到性能不同的分类器。数学式子中的参数则往往通过学习来确定,分类器有一个学习过程,如果发现当前采用的分类函数会造成分类错误,那么利用错误分类获取纠正信息,就可以使分类函数朝正确的方向前进,这就形成了一个迭代的过程,如果分类函数及其参数使分类出错的情况越来越少,就可以看成逐渐收敛,学习过程就获得了效果,设计也就可以结束了。
训练与学习的过程常常用到以下三个概念。
(1)训练集,是一个已知样本集,在监督学习方法中,用它来开发模式分类器。
在分类实例中,样本库训练集是程序开发人员按照自己的手写数字习惯来书写的数字,因此,会造成对读者手写的数字分类有误的情况,为了尽量避免此类情况的发生,我们把每次添加的手写数字放在样本训练集的首位,读者可以尽量多写一些数字以使程序适应其书写式样。
(2)测试集,在设计识别和分类系统时没有使用过的独立样本集。
在分类实例中,以读者自己手写的数字作为样本进行测试检验,每写一个数字就可以用各种模式识别算法进行检验。这样的好处是在相同的样本特征值下,可以对不同的模式识别算法进行比较,找出最佳适应算法。
(3)系统评价原则,就是判断该模式识别系统能否正确分类。为了更好地对模式识别系统性能进行评价,必须使用一组独立于训练集的测试集对系统进行测试。