
下载掌阅APP,畅读海量书库
立即打开



七星大侠将七星北斗阵式永传于世,虽然其思想博大精深,但是并没有给出如何去具体地实现这七种阵式。但没有关系,有了正确的思想才能更好地指导实践。人们根据七星北斗的思想,发明了各种各样的RAID实现方式。
然而,实现了各种RAID,许多问题也随之而来,且看人们是怎么运用各种手段来解决这些问题的。
有人直接在主机上编写程序,运行于操作系统底层,将从主机SCSI或者IDE控制器提交上来的物理磁盘,运用七星北斗的思想,虚拟成各种模式的虚拟磁盘,然后再提交给上层程序接口,如卷管理程序。这些软件通过一个配置工具,让使用者自行选择将哪些磁盘组合起来并形成哪种类型的RAID。
比如,某台机器上安装了两块IDE磁盘和4块SCSI磁盘,IDE硬盘直接连接到主板集成的IDE接口上,SCSI磁盘则是连接到一块PCI接口的SCSI卡上。在没有RAID程序参与的条件下,系统可以识别到6块磁盘,并且经过文件系统格式化之后,挂载到某个盘符或者目录下,供应用程序读写。
安装了RAID程序之后,用户通过配置界面,先将两块IDE磁盘做成了一个RAID 0系统。如果原来每块IDE磁盘是80GB容量,做成RAID 0之后就变成了一块160GB容量的“虚拟”磁盘。然后用户又将4块SCSI盘做了一个RAID 5系统,如果原来每块SCSI磁盘是73GB容量,4块盘做成RAID 5之后虚拟磁盘的容量将约为3块盘的容量,即216GB。
当然,因为RAID程序需要使用磁盘上的部分空间来存放一些RAID信息,所以实际容量将会变小。经过RAID程序的处理之后,这6块磁盘最终变成了两块虚拟磁盘。如果是在Windows系统中,打开磁盘管理器只能看到两块硬盘,一块容量为160GB(硬盘1),另一块容量为219GB(硬盘2)。之后,可以对这两块盘进行格式化,比如格式化为NTFS文件系统。格式化程序丝毫不会感觉到有多块物理硬盘正在写入数据。
比如,格式化程序某时刻发出命令,向硬盘1(由两块IDE磁盘组成的RAID 0虚拟盘)的LBA起始地址10000,长度128,写入内存起始地址某某的数据。RAID程序会截获这个命令并做分析,硬盘1是一个RAID 0系统,那么这块从LBA10000开始算起的128个扇区的数据,会被RAID引擎计算,将逻辑LBA对应成物理磁盘的物理LBA,将对应的数据写入物理磁盘。写入之后,格式化程序会收到成功写入的信号,然后接着做下一次IO。经过这样的处理,上层程序完全不会知道底层物理磁盘的细节。其他RAID形式也都是相同的道理,只不过算法更加复杂而已。但是即使再复杂的算法,经过CPU运算,也要比磁盘读写速度快几千几万倍。
提示: 为了保证性能,同一个磁盘组只能用相同类型的磁盘,虽然也可以设计成将IDE磁盘和SCSI磁盘组合成虚拟磁盘,不过除非特殊需要,否则没有这样设计的。
下面以Windows Server 2003企业版操作系统为例,示例一下Windows是如何在操作系统上用软件来实现RAID功能的。
每个例子的环境都是一个具有5块物理磁盘的PC,每块磁盘容量为100MB。
(1)新磁盘插入机箱并启动操作系统之后,打开磁盘管理器,Windows会自动弹出一个配置新磁盘的向导,如图5-1所示。
(2)单击“下一步”按钮,出现图5-2所示的对话框。
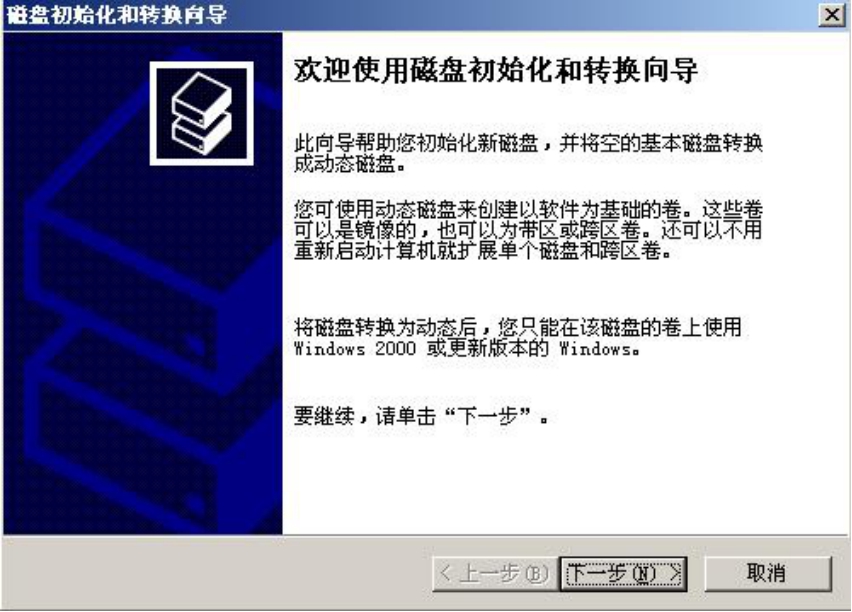
图5-1 初始界面
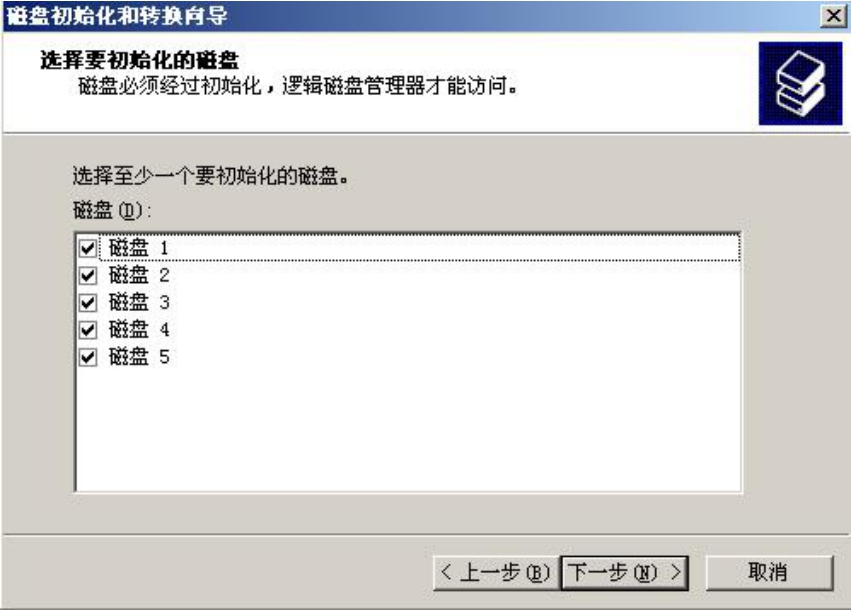
图5-2 选择要初始化的磁盘
(3)单击“下一步”按钮,初始化所有新磁盘,如图5-3所示。
(4)单击“下一步”按钮,将所有磁盘转换为动态磁盘,如图5-4所示。所谓的动态磁盘就是可以用来做RAID以及卷管理的磁盘。
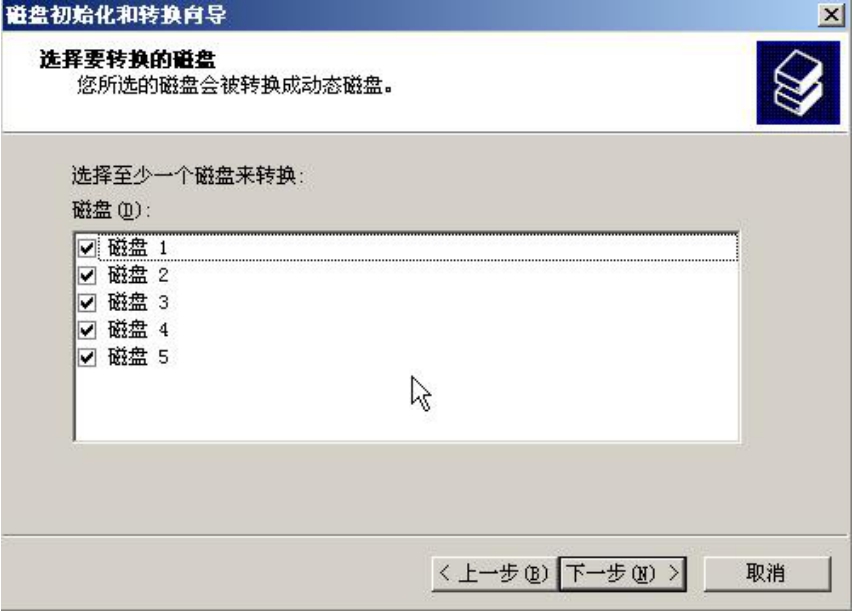
图5-3 选择要转换的磁盘
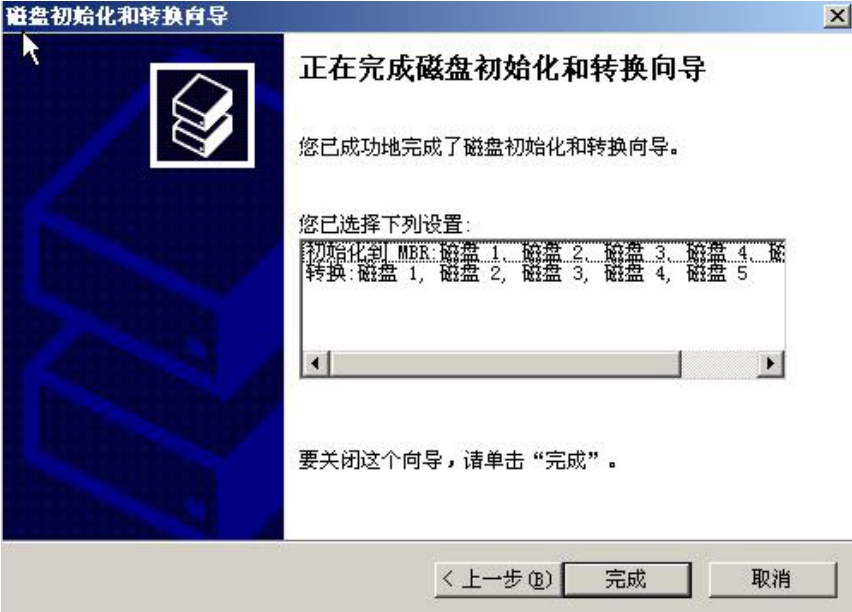
图5-4 初始化磁盘
(5)单击“完成”按钮。查看磁盘管理器中的状态,如图5-5所示。
我们从图5-5中可以看到,磁盘0为基本磁盘,同时也是系统所在的磁盘以及启动磁盘。这个磁盘不能对其进行软RAID或卷管理操作。
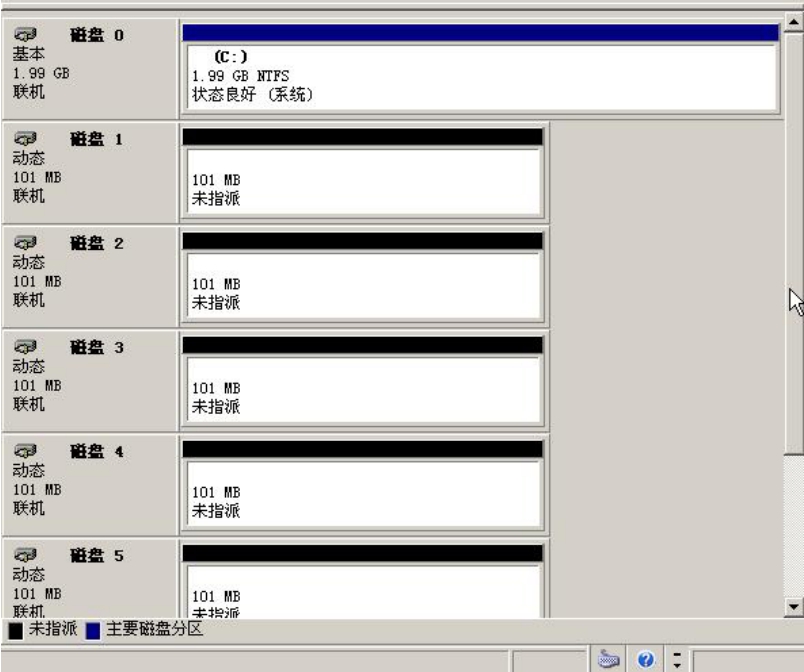
图5-5 磁盘状态
在“磁盘1”上右击,在弹出的快捷菜单中选择“新建卷”命令,如图5-6所示,系统弹出“新建卷向导”对话框,以选择要创建的卷的类型,如图5-7所示。
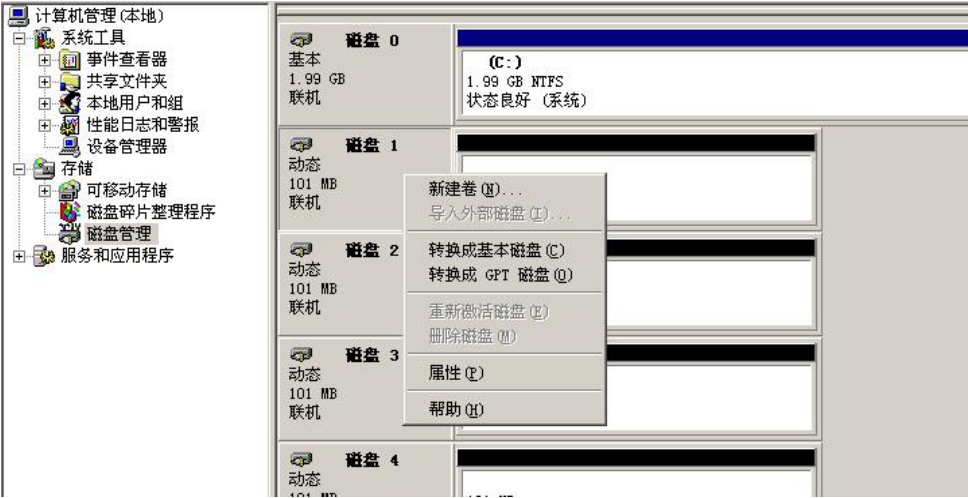
图5-6 选择“新建卷”命令
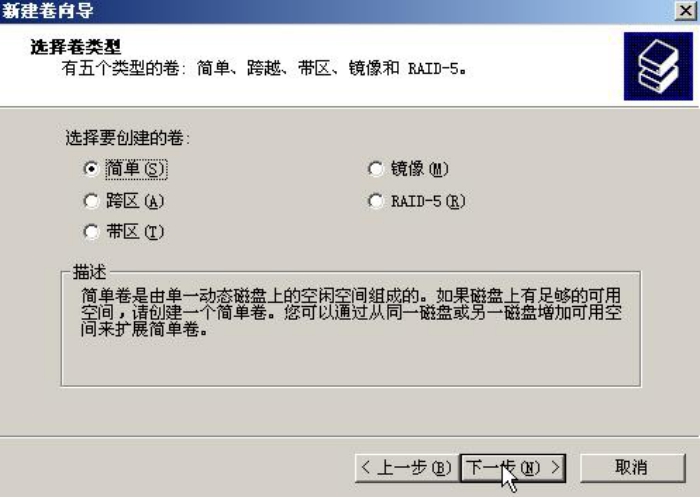
图5-7 选择卷类型
这里有5个选项,下面分别介绍。
■ 简单卷:指卷将按照磁盘的顺序依次分配空间。简单卷与磁盘分区功能类似,卷空间只能在一块磁盘上分配,并且不能交叉或者乱序。
■ 跨区卷:跨区卷在简单卷的基础上,可以让一个卷的空间跨越多块物理磁盘。相当于不做条带化的RAID 0系统。
■ 带区卷:带区卷相当于条带化的RAID 0系统。
■ 镜像卷:镜像卷相当于RAID 1系统。
■ RAID-5卷:毫无疑问,这种方式就是实现一个RAID 5卷。
图5-8做的是一个大小为101MB的简单卷,也就是将物理磁盘1全部容量划分给这个卷。可以发现,简单卷只能在一块物理磁盘上划分,图中“添加”按钮是灰色的,证明不能跨越多块磁盘。
我们再来看看跨区卷,如图5-9所示。
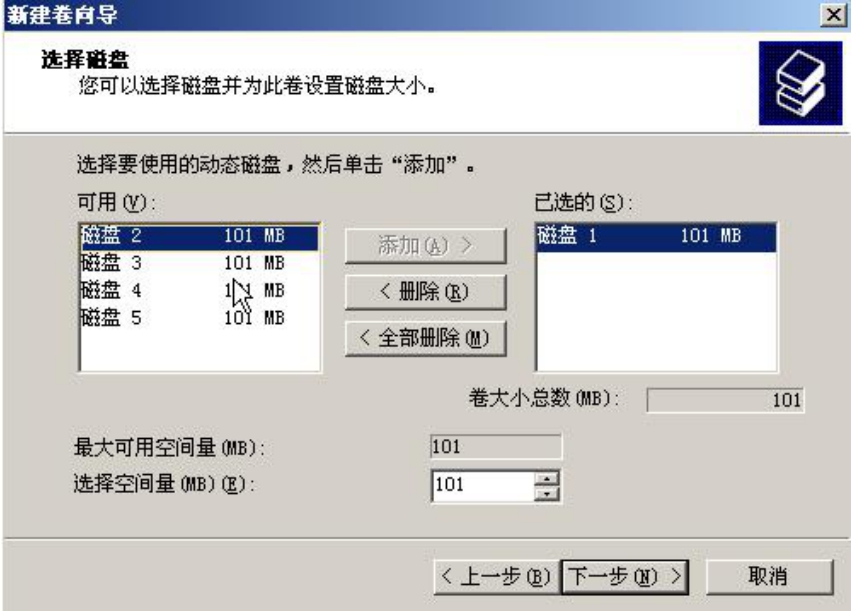
图5-8 划分大小
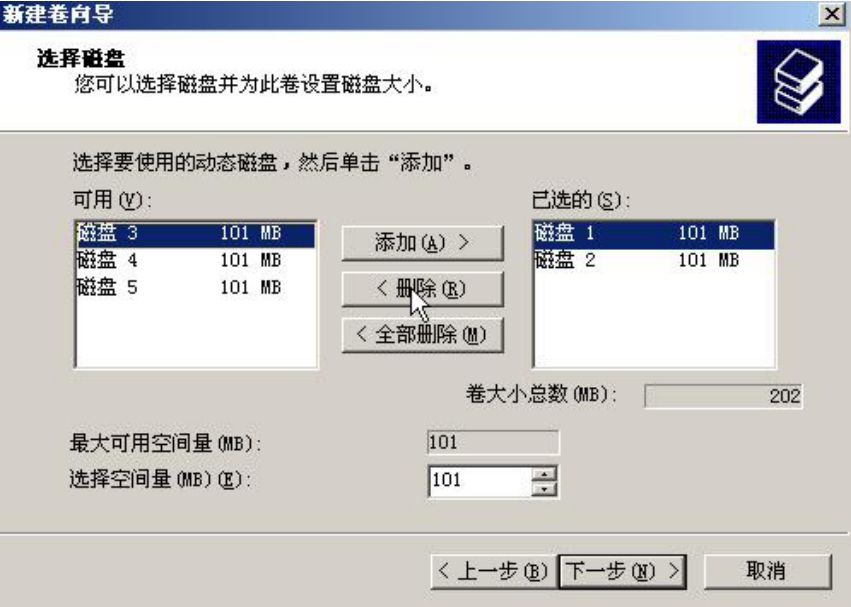
图5-9 跨区卷
跨区卷允许卷容量来自多个硬盘,并且可以在每个硬盘上选择部分容量而不一定非要选择全部容量。在此,我们将全部容量划分给这个卷,卷总容量为200MB,如图5-10所示。
建好的跨区卷,将用紫色来表示。此外,还可以灵活地扩展这个卷的容量,如图5-11所示。
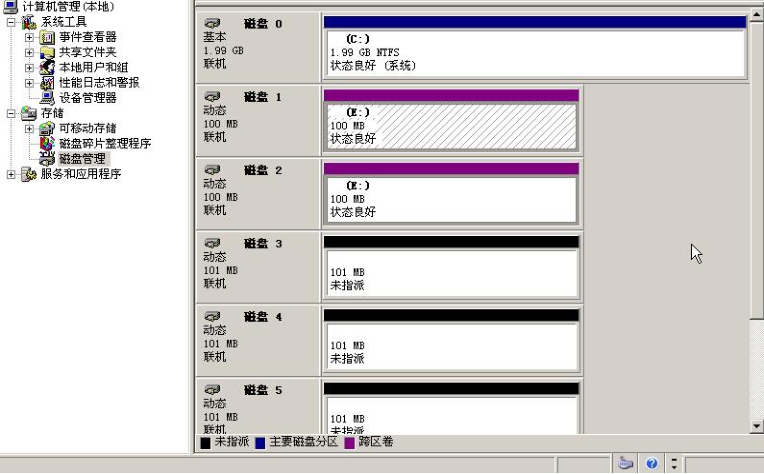
图5-10 跨区卷状态
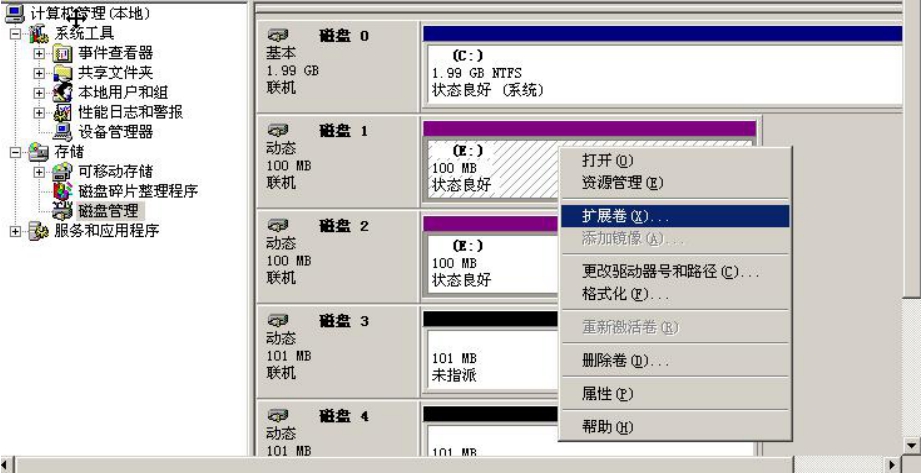
图5-11 扩展容量
向这个卷中再添加一块磁盘“磁盘3”,如图5-12所示。
加完之后这个卷的容量就被扩充到了300MB,如图5-13所示。
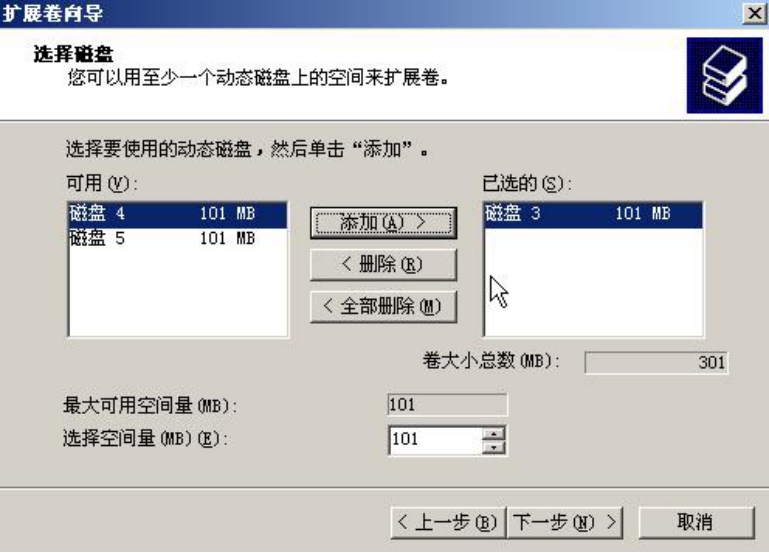
图5-12 增加一块物理磁盘
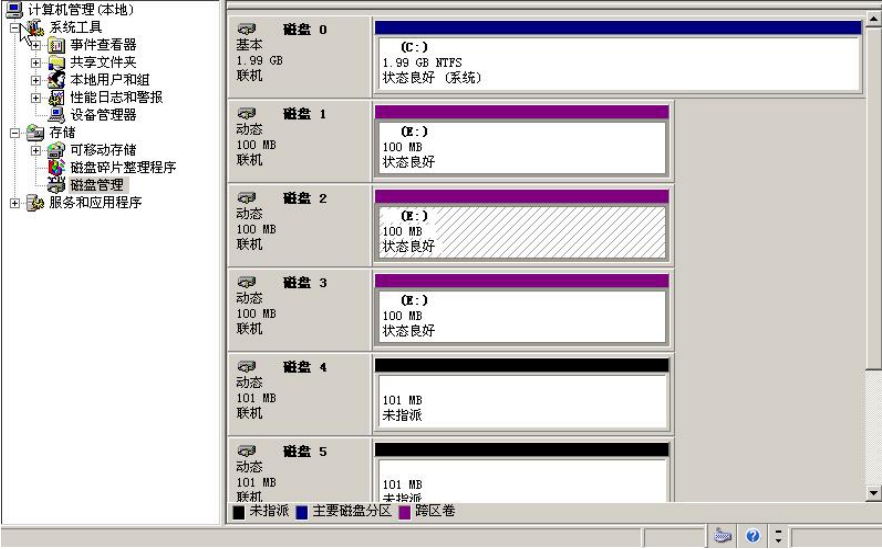
图5-13 扩容后的卷
如图5-14所示,可以任意删除卷。
下面用磁盘1的前50MB的容量和磁盘2的全部容量来做一个跨区卷,如图5-15所示。
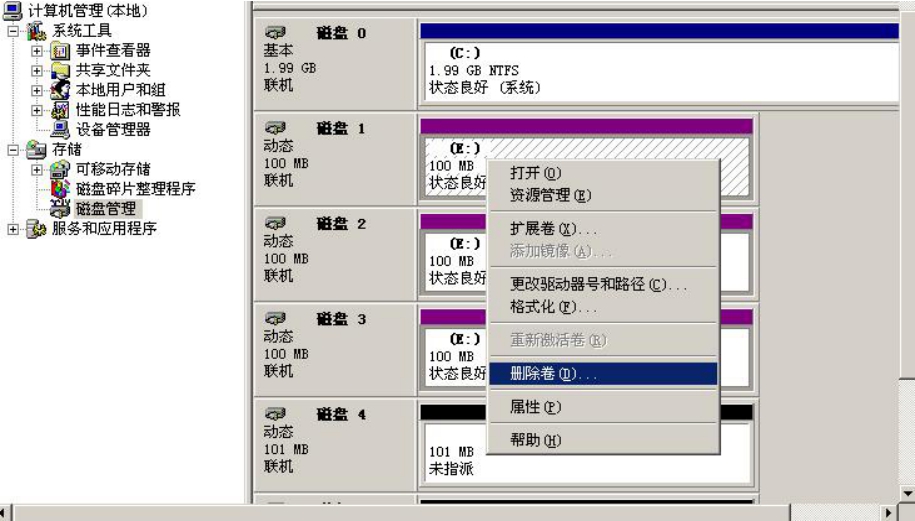
图5-14 删除卷
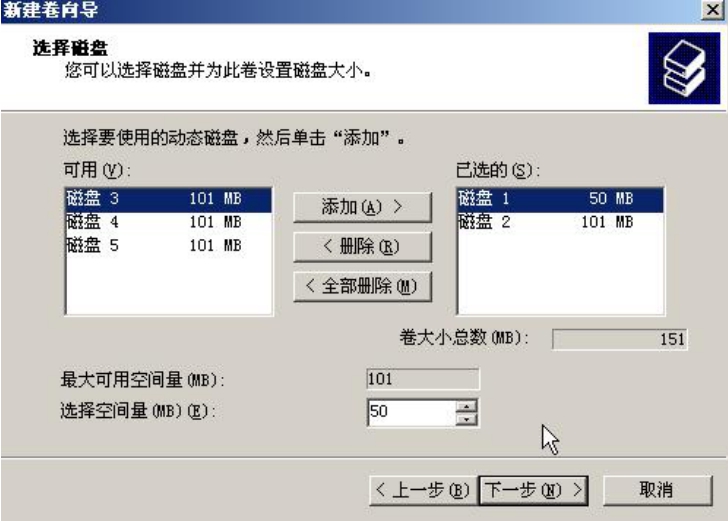
图5-15 灵活地划分尺寸
做好后的卷如图5-16所示。此外,磁盘1剩余的51MB容量还可以再新建卷,如图5-16所示。
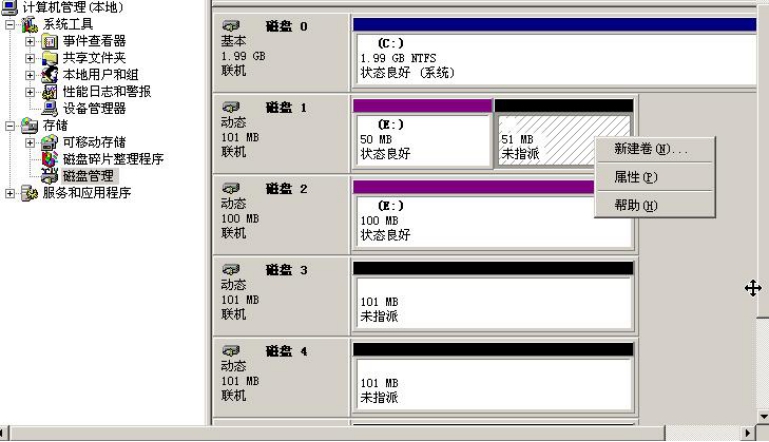
图5-16 剩余空间可以新建卷
下面我们来做一个带区卷,即条带化的RAID 0卷,选择用磁盘1和磁盘2中各30MB的容量来做一个60MB的卷,如图5-17和图5-18所示。
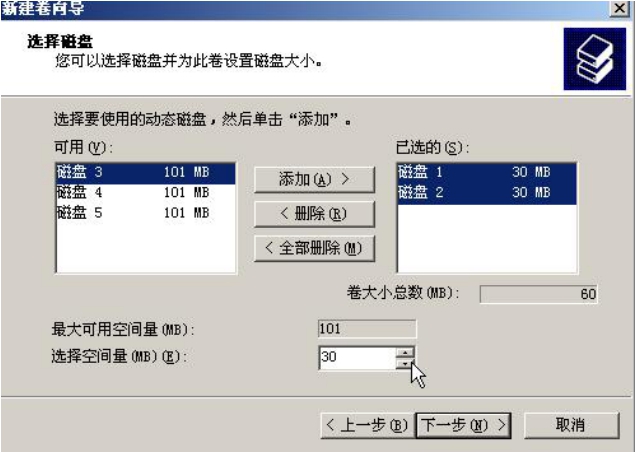
图5-17 带区卷
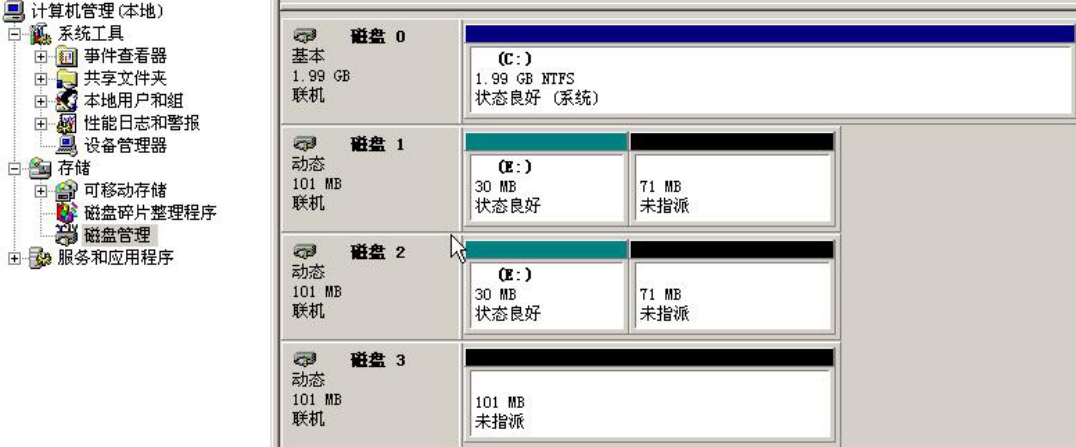
图5-18 带区卷的状态
做好之后的带区卷会用绿色标识。
我们再来做一个镜像卷,即RAID 1卷,选择用磁盘1和磁盘2中各40MB的容量来做一个40MB的卷,如图5-19和图5-20所示。
做好后的镜像卷会用棕色标识。
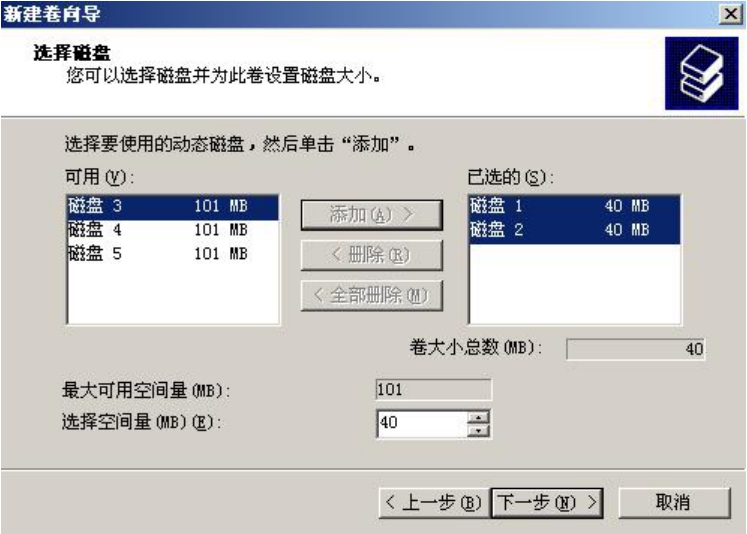
图5-19 镜像卷
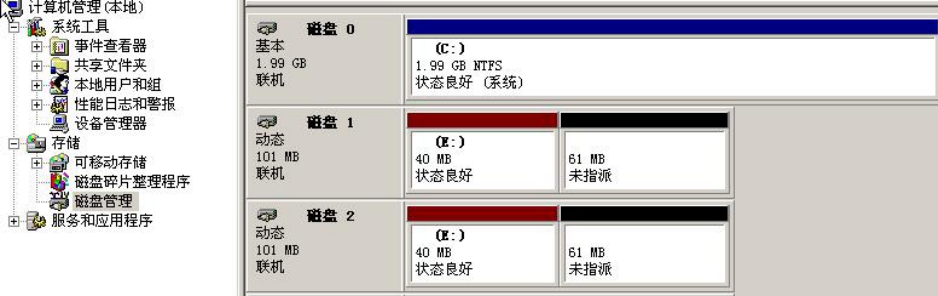
图5-20 镜像卷的状态
最后,我们来做一个RAID 5类型的卷,可将所有磁盘的各50MB空间做一个卷,如图5-21所示;然后再用所有硬盘的20MB空间做一个卷,形成两个RAID 5卷。
做好后的RAID 5卷会用亮绿色标识,如图5-22所示。
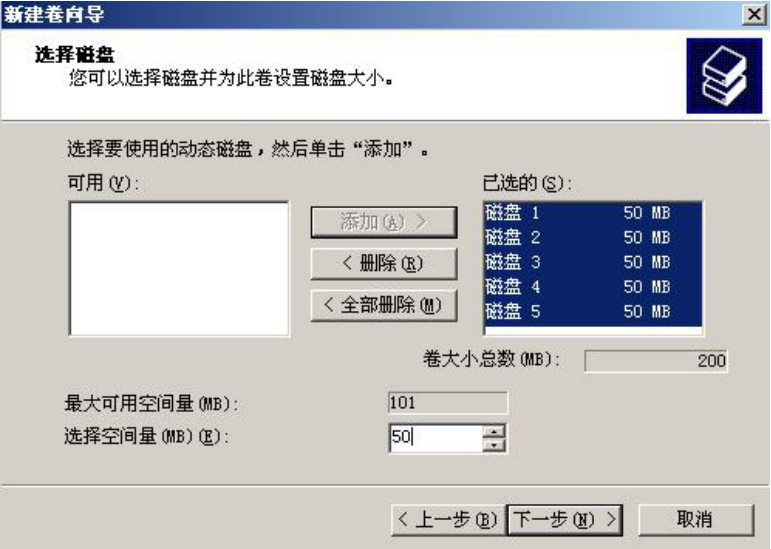
图5-21 创建RAID 5卷
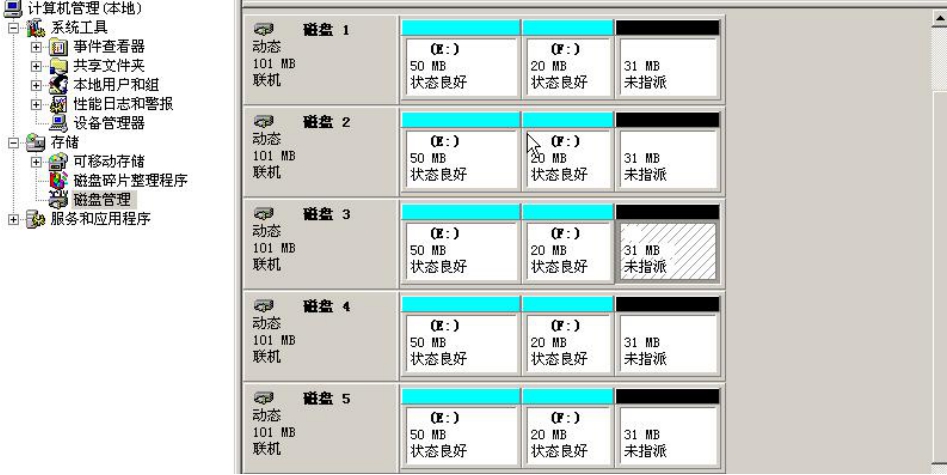
图5-22 RAID 5卷的状态
提示: 做好的任何卷均可随意被删除,如图5-23所示。
说明: Windows的动态磁盘管理实际上应该算是一个带有RAID功能的卷管理软件,而不仅仅是RAID软件。卷管理的概念我们在下文会解释。
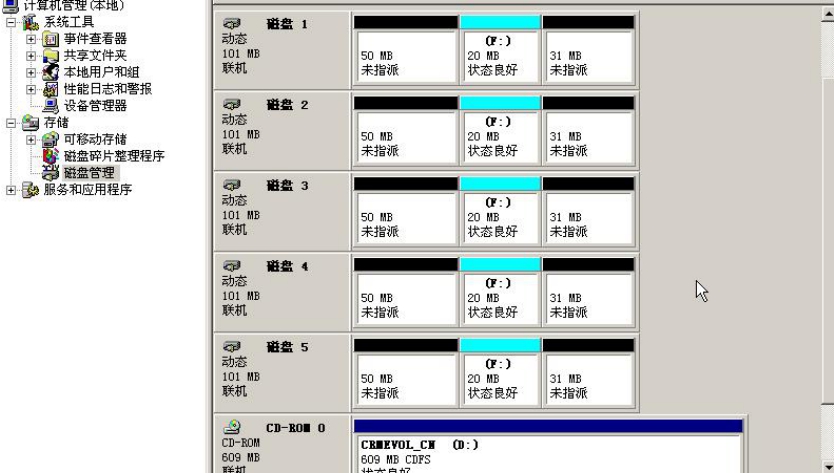
图5-23 删除了一个RAID 5卷
下面在一台装有8块物理磁盘的机器上安装RedHat Enterprise Linux Server 4 Update 5操作系统,具体操作过程如下
(1)选择手动配置磁盘界面,如图5-24所示。
(2)可以看到系统识别到了8块物理磁盘,如图5-25所示。
(3)必须划分一个/boot分区用来启动基本的操作系统内核。用第一块磁盘sda的前100MB容量来创建这个分区,如图5-26所示。
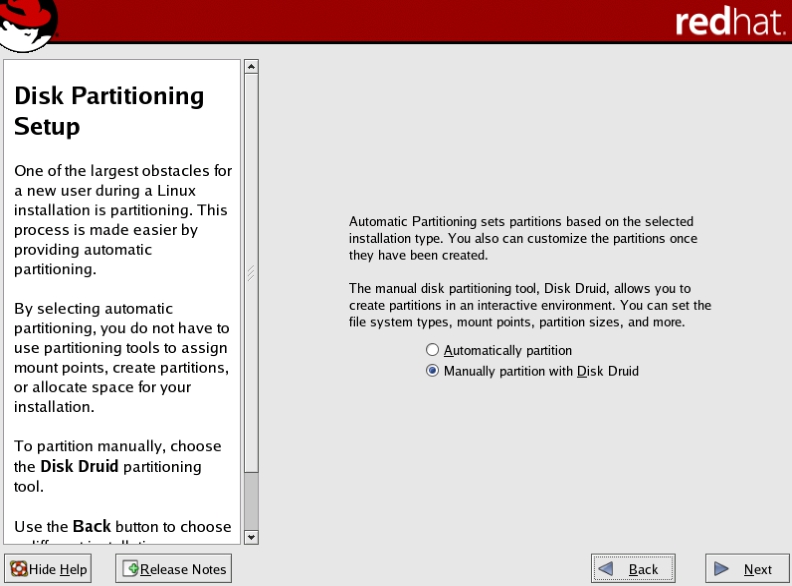
图5-24 选择手动配置
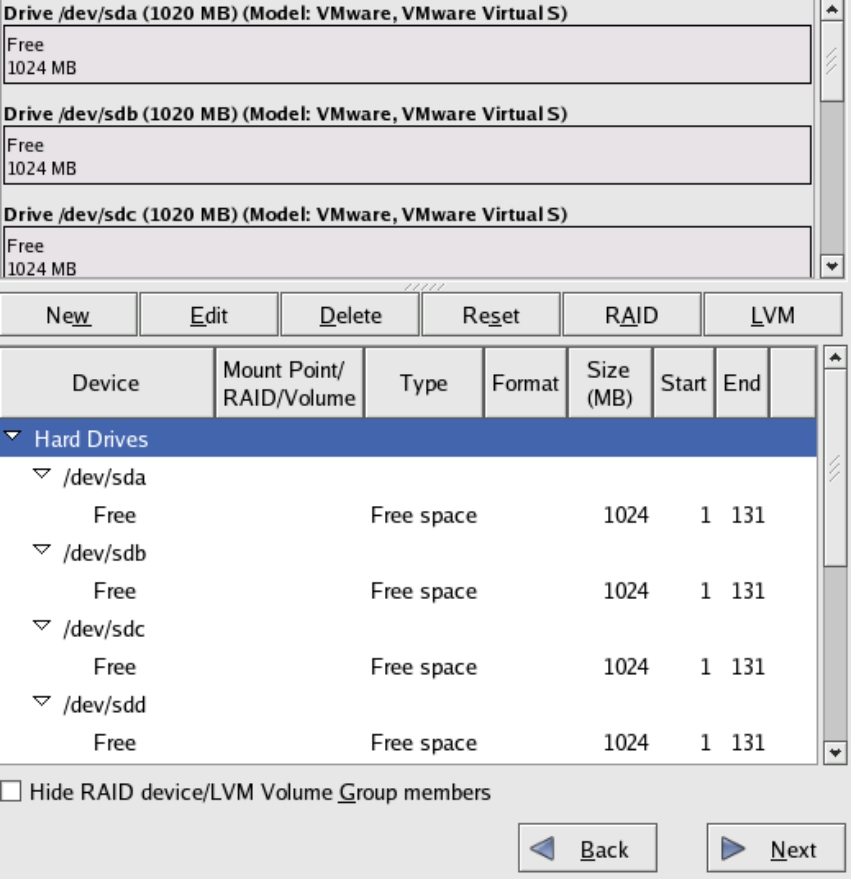
图5-25 识别到的磁盘列表
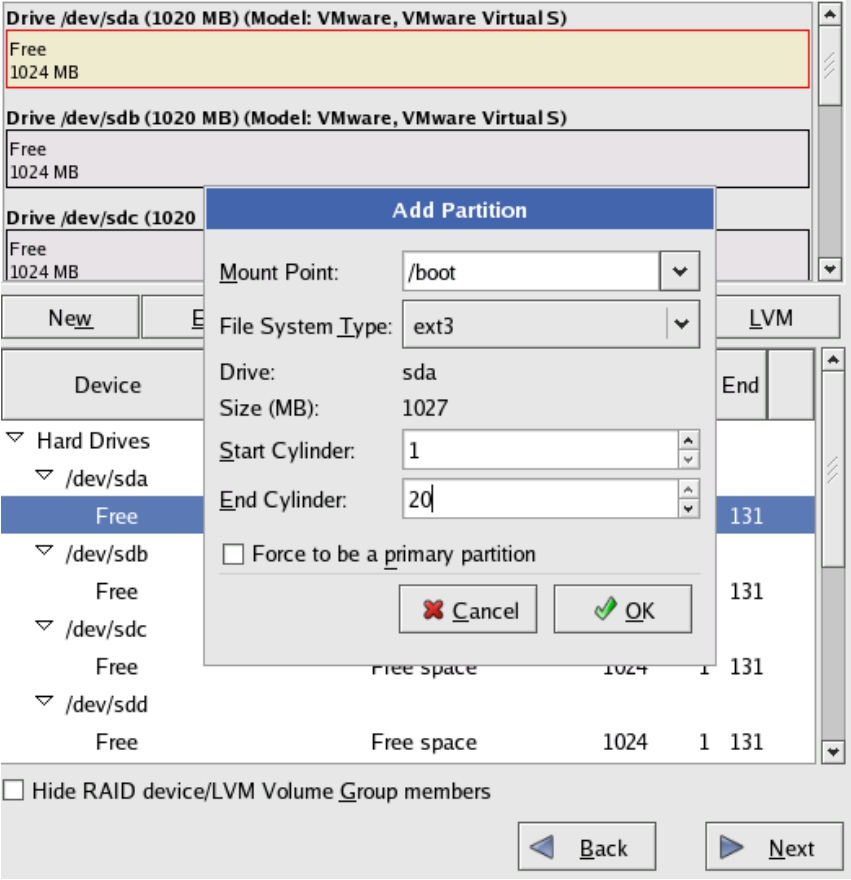
图5-26 创建/boot分区
(4)在创建/boot分区之后,将SDA磁盘剩余的分区以及所有剩余的物理磁盘,均配置为software RAID类型,如图5-27所示。
(5)在将所有磁盘都配置成software RAID类型之后,单击Next按钮,会打开RAID Options对话框询问想要进行什么样的操作,如图5-28所示。
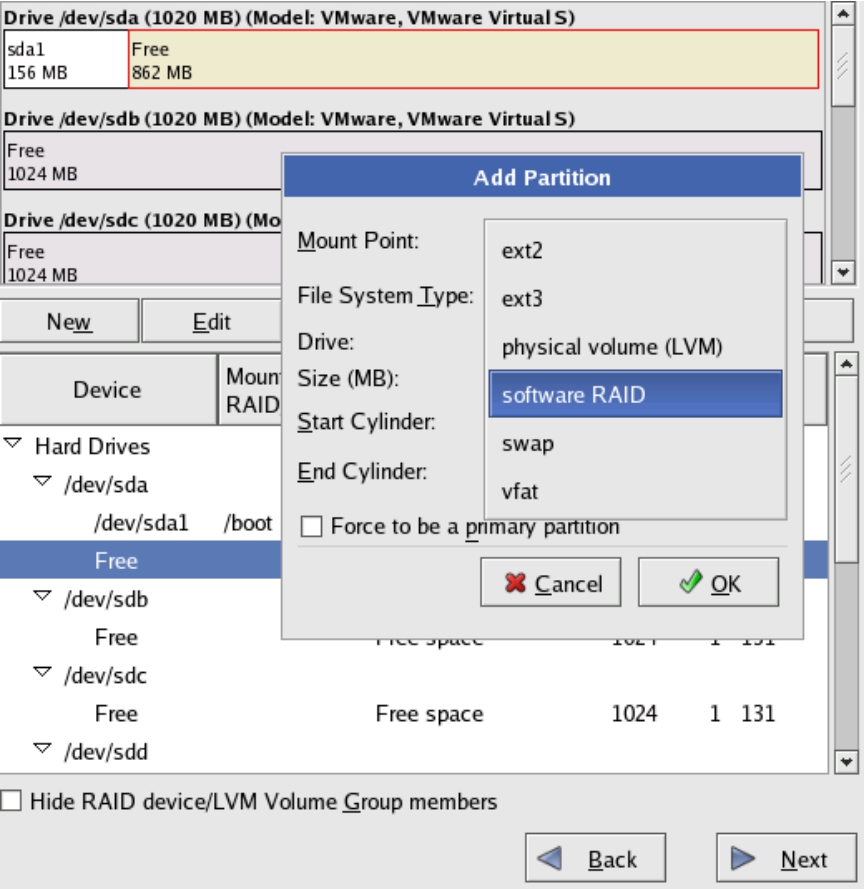
图5-27 配置磁盘类型
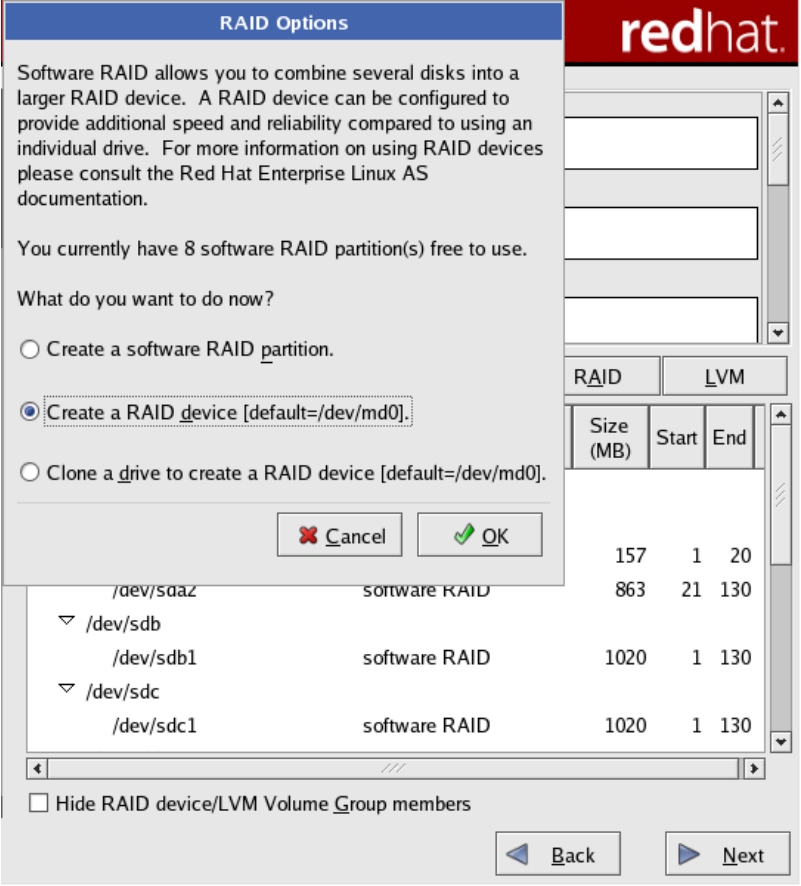
图5-28 设置为RAID设备
(6)选中Create a RAID device [default=/dev/md0]单选按钮后单击OK按钮,系统弹出Make RAID Device对话框。在对话框的RAID Device下拉列表框中,可以选择相应的RAID组在操作系统中对应的设备名。在RAID Level下拉列表框中,可以选择需要配置的RAID类型。在RAID Members列表框中,可以选择RAID组中包含的物理磁盘。用相同的方法可以做多个不同类型的RAID组,如图5-29所示。
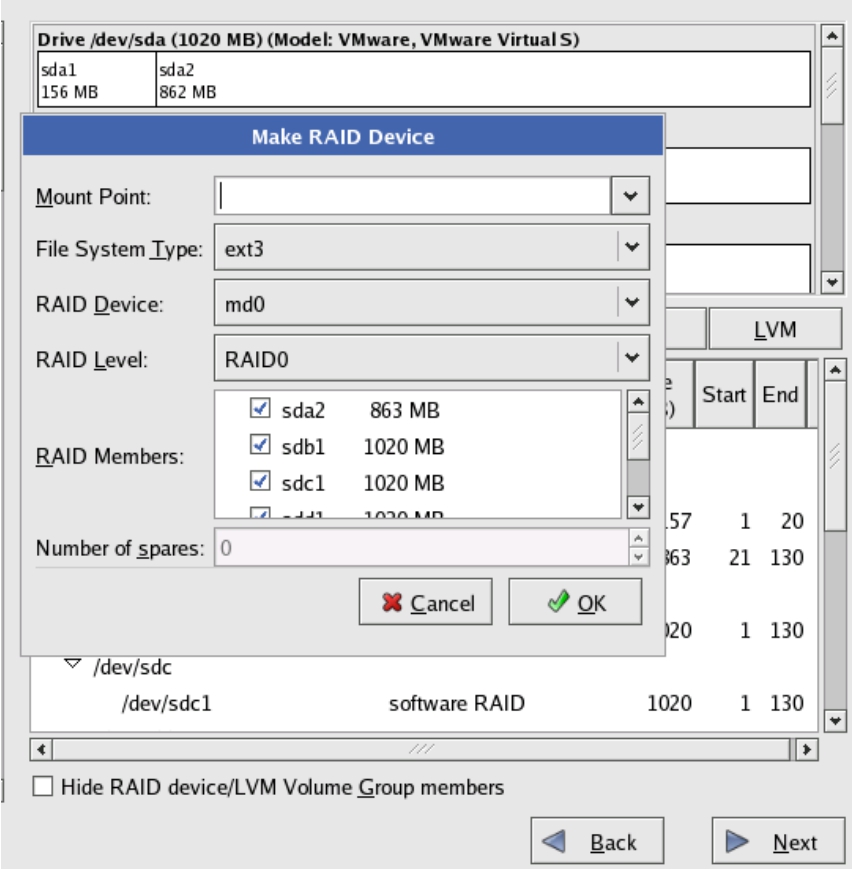
图5-29 创建对应的Mount点
思考: 软件RAID有三个缺点:①占用内存空间;②占用CPU资源;③软件RAID程序无法将安装有操作系统的那个磁盘分区做成RAID模式。因为RAID程序是运行在操作系统之上的,所以在启动操作系统之前,是无法实现RAID功能的。也就是说,如果操作系统损坏了,RAID程序也就无法运行,磁盘上的数据就成了一堆无用的东西。因为RAID磁盘上的数据只有实现相应RAID算法的程序才能识别并且正确读写。如果没有相应的RAID程序,则物理磁盘上的数据仅仅是一些碎片而已,只有RAID程序才能组合这些碎片。幸好,目前大多数的RAID程序都会在磁盘上存储自己的算法信息,一旦操作系统出现了问题,或者主机硬件出现了问题,就可以将这些磁盘连接到其他机器上,再安装相同的RAID软件。RAID软件读取了存储在硬盘上固定区域的RAID信息后,便可以继续使用。
软件RAID的缺点如此之多,使人们不断地思考更多实现RAID的方法。既然软件缺点太多,那么用硬件实现如何呢?
RAID卡就是一种利用独立硬件来实现RAID功能的方法。要在硬件上实现RAID功能,必须找一个物理硬件作为载体,SCSI卡或者主板上的南桥无疑就是这个载体了。人们在SCSI卡上增加了额外的芯片用于实现RAID功能。这些芯片是专门用来执行RAID算法的,可以是ASIC这样的高成本高速度运算芯片,也可以是通用指令CPU这样的通用代码执行芯片,可以从ROM中加载代码直接执行,也可以先载入RAM后执行,从而实现RAID功能。
实现了RAID功能的板卡(SCSI卡或者IDE扩展卡)就叫做RAID卡。同样,在主板南桥芯片上也可实现RAID功能。由于南桥中的芯片不能靠CPU来完成它们的功能,所以这些芯片完全靠电路逻辑来自己运算,尽管速度很快,但是功能相对插卡式的RAID卡要弱。从某些主板的宣传广告中就可以看到,如所谓“板载”RAID芯片就是指南桥中有实现RAID功能的芯片。
这样,操作系统不需要作任何改动,除了RAID卡驱动程序之外不用安装任何额外的软件,就可以直接识别到已经过RAID处理而生成的虚拟磁盘。
对于软件RAID,至少操作系统最底层还是能感知到实际物理磁盘的,但是对于硬件RAID来说,操作系统根本无法感知底层的物理磁盘,而只能通过厂家提供的RAID卡的管理软件来查看卡上所连接的物理磁盘。而且,配置RAID卡的时候,也不能在操作系统下完成,而必须进入这个硬件来完成(或者在操作系统下通过RAID卡配置工具来设置)。一般的RAID卡都是在开机自检的时候,进入它的ROM配置程序来配置各种RAID功能。
RAID卡克服了软件RAID的缺点,使操作系统本身可以安装在RAID虚拟磁盘之上,而这是软件RAID所做不到的。
带CPU的RAID卡俨然就是一个小的计算机系统,有自己的CPU、内存、ROM、总线和IO接口,只不过这个小计算机是为大计算机服务的。
图5-30为一个RAID卡的架构示意图。
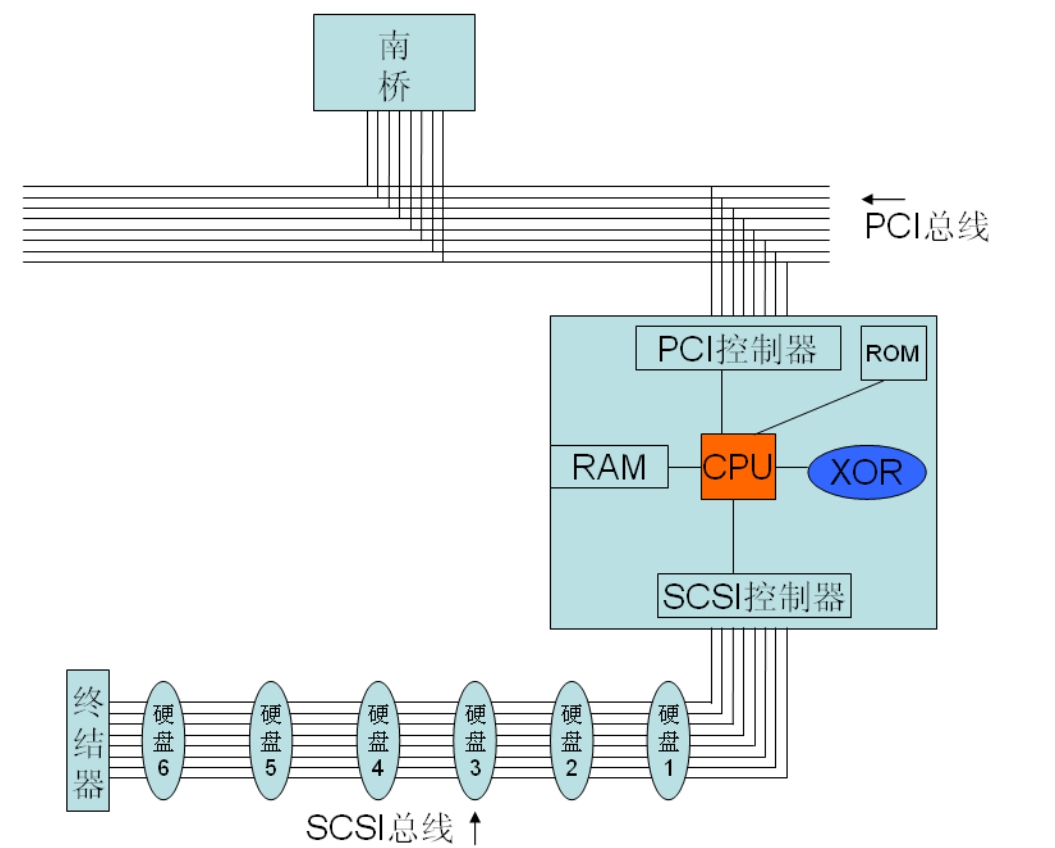
图5-30 RAID卡结构示意图
SCSI RAID卡上一定要包含SCSI控制器,因为其后端连接的依然是SCSI物理磁盘。其前端连接到主机的PCI总线上,所以一定要有一个PCI总线控制器来维护PCI总线的仲裁、数据发送接收等功能。还需要有一个ROM,一般都是用Flash芯片作为ROM,其中存放着初始化RAID卡必须的代码以及实现RAID功能所需的代码。
RAM的作用,首先是作为数据缓存,提高性能;其次作为RAID卡上的CPU执行RAID运算所需要的内存空间。XOR芯片是专门用来做RAID 3、5、6等这类校验型RAID的校验数据计算用的。如果让CPU来做校验计算,需要执行代码,将耗费很多周期。而如果直接使用专用的数字电路,一进一出就立即得到结果。所以为了解脱CPU,增加了这块专门用于XOR运算的电路模块,大大增加了数据校验计算的速度。
RAID卡与SCSI卡的区别就在于RAID功能,其他没有太大区别。如果RAID卡上有多个SCSI通道,那么就称为多通道RAID卡。目前SCSI RAID卡最高有4通道的,其后端可以接入4条SCSI总线,所以最多可连接64个SCSI设备(16位总线)。
增加了RAID功能之后,SCSI控制器就成了RAID程序代码的傀儡,RAID让它干什么,它就干什么。SCSI控制器对它下面掌管的磁盘情况完全明了,它和RAID程序代码之间进行通信。RAID程序代码知道SCSI控制器掌管的磁盘情况之后,就按照ROM中所设置的选项,比如RAID类型、条带大小等,对RAID程序代码做相应的调整,操控它的傀儡SCSI控制器向主机报告“虚拟”的逻辑盘,而不是所有物理磁盘了。
提示: RAID思想中有个条带化的概念。所谓的条带化,并不是真正的像低级格式化一样将磁盘划分成条和带。这个条带化完全就是在“心中”,也就是体现在程序代码上。因为条带的位置、大小一旦设置之后,就是固定的。一个虚拟盘上的某个LBA地址块,就对应了真正物理磁盘上的一个或者多个LBA块,这些映射关系都是预先通过配置界面设定好的。而且某种RAID算法往往体现为一些复杂公式,而不是去用一张表来记录每个虚拟磁盘LBA和物理磁盘LBA的对应,这样效率会很差。因为每个IO到来之后,RAID都要查询这个表来获取对应物理磁盘的LBA,而查询速度是非常慢的,更何况面对如此大的一张表。如果用一个逻辑LBA与物理LBA之间的函数关系公式来做运算,则速度是非常快的。
正是因为映射完全通过公式来进行,所以物理磁盘上根本不用写入什么标志,以标注所谓的条带。条带的概念只是逻辑上的,物理上并不存在。所以,条带等概念只需“记忆”在RAID程序代码之中就可以了,要改变也是改变程序代码即可。唯一要向磁盘上写入的就是一些RAID信息,这样即使将这些磁盘拿下来,放到同型号的另一块RAID卡上,也能无误地认出以前做好的RAID信息。SNIA协会定义了一种DDF RAID信息标准格式,要求所有RAID卡厂家都按照这个标准来存放RAID信息,这样,所有RAID卡就都通用了。
条带化之后,RAID程序代码就操控SCSI控制器向OS层驱动程序代码提交一个虚拟化之后的所谓“虚拟盘”或者“逻辑盘”,也有人干脆称为LUN。
所谓初始化就是说在系统加电之后,CPU执行系统总线特定地址上的第一句指令,这个地址便是主板BIOS芯片的地址。BIOS芯片中包含着让CPU执行的第一条指令,CPU将逐条执行这些指令,执行到一定阶段的时候,有一条指令会让CPU寻址总线上其他设备的ROM地址(如果有)。也就是说,系统加电之后,CPU总会执行SCSI卡这个设备上ROM中的程序代码来初始化这块卡。初始化的内容包括检测卡型号、生产商以及扫描卡上的所有SCSI总线以找出每个设备并显示在显示器上。在初始化的过程中,可以像进入主板BIOS一样,进入SCSI卡自身的BIOS中进行设置,设置内容包括查看各个连接到SCSI总线上的设备的容量、生产商、状态、SCSI ID和LUN ID等。
0通道RAID卡又称为RAID子卡,0通道的意思是说这块卡的后端没有SCSI通道。将这块子卡插入主机的PCI插槽之后,它就可以利用主板上已经集成的或者已经插在PCI上的SCSI卡,来操控它们的通道,从而实现RAID。这个0通道子卡,也是插到PCI上的一块卡,只不过它需要利用主板上为0通道子卡专门设计的逻辑电路,对外和SCSI控制器组成一块RAID卡来用,只不过这块卡在物理上被分割到了两个PCI插槽中而已。
图5-31展示了0通道RAID子卡的架构。在主板的一个特定PCI插槽上,有一个ICR逻辑电路,用来截获CPU发送的地址信号和发给CPU的中断信号。CPU发送到这里原本用来操控SCSI控制器的地址信号,现在全部被这个ICR电路重定向到了RAID子卡处,包括主板BIOS初始载入ROM,也不是载入SCSI卡的ROM了,而是载入了RAID子卡的ROM。RAID卡完全接替了SCSI卡来面对主机系统。RAID卡和SCSI控制器的通信,包括地址信息和数据信息,需要占用PCI总线,这造成了一定的性能损失。RAID子卡和SCSI卡之间的通信,不会被ICR电路重定向。
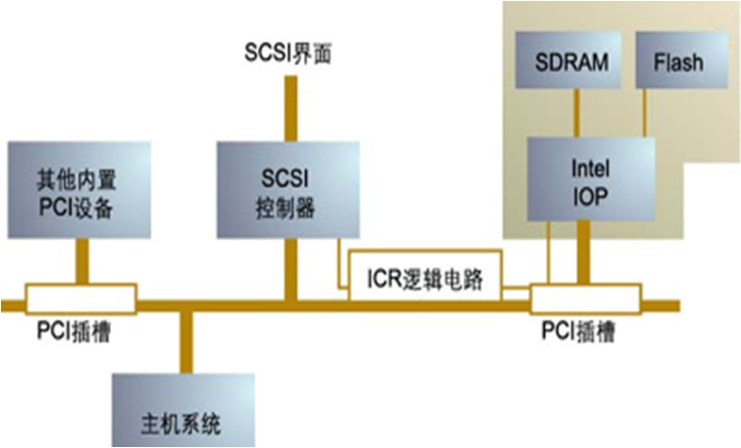
图5-31 0通道RAID子卡示意图
PhotoFast所设计的一款RAID卡可谓是比较创新。传统的RAID卡都是使用PCIX或者PCIE总线来连接到计算机上的,但是PhotoFast这款RAID卡却是使用SATA接口来连接到计算机的,也就是说,这块RAID卡将其上连接的多块物理磁盘虚拟成若干的虚拟磁盘,并将这些磁盘通过SATA接口连接到计算机,计算机就认为它自身所连接的是多块SATA物理磁盘。这样的话,这块Raid卡就不需要任何驱动程序便可被大多数操作系统使用(多数操作系统都自带SATA控制器驱动程序)。
ROC技术是由Adaptec公司推出的一种廉价RAID技术,它利用SCSI卡上的CPU处理芯片,通过在SCSI卡的ROM中加入RAID代码而实现。
2001年,Adaptec展示了它的iROC技术,在2003年这一技术以HOStRAID的形象推出。iROC也就是RAID on Chip,实质上就是利用SCSI控制芯片内部的RISC处理器完成一些简单的RAID类型(RAID 0、1、0+1)。由于RAID 0、1和0+1需要的运算量不大,利用SCSI控制器内部的RISC处理器也能够实现。在ROM代码的配合下,通过iROC实现的RAID 0、1或0+1具备引导能力,并且可以支持热备盘。
在入门级塔式服务器和1U高度的机架式服务器中,主板上通常会集成SCSI控制芯片,但不标配独立的RAID卡。iROC的出发点就是让这些系统具有基本的硬件数据保护,当需要更为复杂的RAID 5时再购买独立的RAID卡。iROC的出现给低端服务器产品的数据保护方案增加了一个简易的选择。iROC或HOStRAID的主要缺点是操作系统兼容性和性能差,由于没有专门的RAID计算处理器,因此使用这种配置的RAID会在一定程度上降低服务器系统的性能,而且它只支持RAID 0、1、0+1,只能支持几块SCSI盘做RAID,相比IDE RAID 0、1、0+1来说特性相近而成本上却高了很多,此外,HOStRAID技术在低端还必然要面对更新、性能更好的S-ATA RAID的竞争。
RAID卡上的内存,有数据缓存和代码执行内存两种作用。
RAID卡上的CPU执行代码,当然需要RAM的参与了。如果直接从ROM中读取代码,速度会受到很大影响。所以RAID卡的RAM中有固定的地址段用于存放CPU执行的代码。而大部分空间都是用作了下文介绍的数据缓存。
缓存,也就是缓冲内存,只要在通信的双方之间能起到缓冲作用就可以了。我们知道CPU和内存之间是L2 Cache,它比内存RAM速度还要高,但是没有CPU速度高。同样,RAID控制器和磁盘通道控制器之间也要有一个缓存来适配,因为RAID控制器的处理速度远远快于通道控制器收集通道上所连接的磁盘传出的数据速度。这个缓存没有必要用L2 Cache那样高速的电路,而用RAM足矣。因为RAM的速度就足够适配二者了。
缓存RAM除了适配不同速率的芯片通信之外,还有一个作用就是缓冲数据IO。比如上层发起一个IO请求,RAID控制器可以先将这个请求放到缓存中排队,然后一条一条地执行,或者优化这些IO,能合并的合并,能并发的并发。
对于上层的写IO,RAID控制器有两种手段来处理,内容如下。
(1)WriteBack模式: 上层发过来的数据,RAID控制器将其保存到缓存中之后,立即通知主机IO已经完成,从而主机可以不加等待地执行下一个IO,而此时数据正在RAID卡的缓存中,而没有真正写入磁盘,起到了一个缓冲作用。RAID控制器等待空闲时,或者一条一条地写入磁盘,或者批量写入磁盘,或者对这些IO进行排队(类似磁盘上的队列技术)等一些优化算法,以便高效写入磁盘。由于写盘速度比较慢,所以这种情况下RAID控制器欺骗了主机,但是获得了高速度,这就是“把简单留给上层,把麻烦留给自己”。这样做有一个致命缺点,就是一旦意外掉电,RAID卡上缓存中的数据将全部丢失,而此时主机认为IO已经完成,这样上下层就产生了不一致,后果将非常严重。所以一些关键应用(比如数据库)都有自己的检测一致性的措施。也正因为如此,中高端的RAID卡都需要用电池来保护缓存,从而在意外掉电的情况下,电池可以持续对缓存进行供电,保证数据不丢失。再次加电的时候,RAID卡会首先将缓存中的未完成的IO写入磁盘。
(2)WriteThrough模式: 也就是写透模式,即上层的IO。只有数据切切实实被RAID控制器写入磁盘之后,才会通知主机IO完成,这样做保证了高可靠性。此时,缓存的提速作用就没有优势了,但是其缓冲作用依然有效。
除了作为写缓存之外,读缓存也是非常重要的。缓存算法是门很复杂的学问,有一套复杂的机制,其中一种算法叫做PreFetch,即预取,也就是对磁盘上接下来“有可能”被主机访问到的数据,在主机还没有发出读IO请求的时候,就“擅自”先读入到缓存。这个“有可能”是怎么来算的呢?
其实就是认为主机下一次IO,有很大几率会读取到这一次所读取的数据所在磁盘位置相邻位置的数据。这个假设,对于连续IO顺序读取情况非常适用,比如读取逻辑上连续存放的数据,这种应用如FTP大文件传输服务、视频点播服务等,都是读大文件的应用。而如果很多碎小文件也是被连续存放在磁盘上相邻位置的,缓存会大大提升性能,因为读取小文件需要的IOPS很高,如果没有缓存,全靠磁头寻道来完成每次IO,耗费时间是比较长的。
还有一种缓存算法,它的思想不是预取了,它是假设:主机下一次IO,可能还会读取上一次或者上几次(最近)读取过的数据。这种假设和预取完全不一样了,RAID控制器读取出一段数据到缓存之后,如果这些数据被主机的写IO更改了,控制器不会立即将它们写入磁盘保存,而是继续留在缓存中,因为它假设主机最近可能还要读取这些数据,既然假设这样,那么就没有必要写入磁盘并删除缓存,然后等主机读取的时候,再从磁盘读出来到缓存,还不如以静制动,干脆就留在缓存中,等主机“折腾”的频率不高了,再写入磁盘。
提示: 中高端的RAID卡一般具有256MB以上的RAM作为缓存。
对于校验型RAID,在RAID卡上设置完RAID参数并且应用RAID设置之后,RAID阵列中的所有磁盘需要进行一个初始化过程,所需要的时间与磁盘数量、大小有关。磁盘越大,数量越多,需要的时间就越长。
思考: RAID卡都向磁盘上写了什么东西呢?大家可以想一下,一块刚刚出厂的新磁盘,上面有没有数据?
有。具体什么数据呢?要么全是0,要么全是1。这里所说的全0是指实际数据部分,扇区头标等一些特殊位置除外。因为磁盘上的磁性区域就有两种状态,不是N极,就是S极。那么也就是说不是0就是1,而不可能有第三种状态。那么这些0或者1,算不算数据呢?当然要算了,这些磁区不会存在一种介于0和1之间的混沌状态。如果此时用几块磁盘做了RAID 5,但磁盘上任何数据都不做改动,我们看一下此时会处于一种什么状态,比如5块磁盘,4块数据盘空间,1块校验盘空间,同一个条带上,4块数据块,1块校验块,所有块上的数据都是全0,那么此时如果按照RAID 5来算,是正确的,因为0 XOR 0 XOR 0 XOR 0 XOR 0 = 0,对。
如果一开始磁盘全是1,那么同样地1 XOR 1 XOR 1 XOR 1 XOR 1 = 1,也对。但是如果用6块盘做RAID 5,而且初始全为1,情况就矛盾了。1 XOR 1 XOR 1XOR 1 XOR 1 XOR 1 =0,此时正确结果应该是校验块为0,但是初始磁盘全部为1,校验块的数据也为1,这就和计算结果相矛盾了。
如果初始化过程不对磁盘数据进行任何更改,直接拿来写数据,比如此时就向第二个extend上写了一块数据,将1变为0,然后控制器根据公式:新数据的校验数据=(老数据EOR新数据)EOR来校验数据。(1EOR 0)EOR 1 = 0,新校验数据为0,所以最终数据变成了这样:1 XOR 0 XOR 1 XOR 1 XOR 1 XOR 1。我们算出它的正确数据应该等于1,而由RAID控制器算的却成了0,所以就矛盾了。
为什么会犯这个错误呢?那是因为一开始RAID控制器就没有从一个正确的数据关系开始算,校验块的校验数据一开始就与数据块不一致,导致越算越错。所以RAID控制器在做完设置,并启用之后,在初始化的过程中需要将磁盘每个扇区都写成0或者1,然后计算出正确的校验位,或者不更改数据块的数据,直接用这些已经存在的数据,重新计算所有条带的校验块数据。在这个基础上,新到来的数据才不会被以讹传讹。
思考: NetApp等产品,其RAID组做好之后不需要初始化,立即可用。甚至向已经有数据的RAID组中添加磁盘,也不会造成任何额外的IO。因为其会将所有Spare磁盘清零,也就是向磁盘发送一个Zero Unit的SCSI指令,磁盘会自动执行清零。用这些磁盘做的RAID组,不需要校验纠正,所以也不需要初始化过程,或者说初始化过程就是等待磁盘清零的过程。
关于Raid初始化过程的更详细的分析可参考本书附录1中的问与答。
双通道160M部门级,性能强悍,BIOS选项极为人性化,在BIOS内可以检测SCSI硬盘的出厂坏道及成长坏道,而不需借助软件。并且允许手动打开/关闭硬盘设备自身的Read cache/Write cache。还带有电池。
详细信息如下。
支持RAID级别:RAID 0、1、0+1、3、5、10、30、50、JBOD。
■ 处理芯片:Intel i960RN。
■ 总线类型:PCI 64b,兼容32b。
■ 外置接口:Ultra 160 SCSI。
■ 数据传输速率:最高160MB/s。
■ 外接设备数:最多30个SCSI外设。
■ 内部接口:双68针高密。
■ 外部接口:双68针超高密。
■ 适用的操作系统:Windows NT 4.0;Windows 2K;NetWare 4.2、5.1;SCO OpenServer 5.05、5.0.6;SCO UnixWare 7.1;DOS 6.x and above;Solaris 7(x86);Linux 2.2 kernel distributions。
■ 包括软件:Storager Manager、Storager Manager Pro和CLI(命令分界面)。
■ 主要RAID特性:在线扩容、瞬时阵列可用性(后台初始化)、支持S.M.A.R.T、支持SES/SAF-TE。
图5-32和图5-33为Mylex AcceleRAID 352卡实物图。

图5-32 Mylex AcceleRAID 352卡(1)

图5-33 Mylex AcceleRAID 352卡(2)
4通道160MB企业/部门级,160MB最为顶级豪华的SCSI RAID,强大的BIOS选项(LSI独有的Web BIOS)。卡上系统缓存可详细调节(除大部分SCSI RAID可以调节的主要功能Write back(回写外),增加Read ahead(预读),Cache I/O等可调选项,满足RAID的用途需要,体现各种RAID的最高性能,带电池。
详细信息如下。
■ 支持RAID级别:RAID 0、1、0+1、3、5、10、30、50、JBOD。
■ 处理芯片:Intel i960RN。
■ 插槽类型:PCI 64b、兼容32b。
■ 总线速度:66MHz。
■ 总线宽度:64b。
■ 外置接口:Ultra 160 SCSI。
■ 数据传输率:160MB/s。
■ 最多连接设备:32。
■ 内部接口:双68针高密。
■ 外部接口:四68针超高密。
■ 系统平台:Windows 95/98/Me/4.0/2000/XP,Linux(Red Hat、SuSE、Turbo、Caldera和FreeBSD)。
图5-34为LSI MegaRAID Enterprise 1600卡实物图。
可以看到RAID卡使用的内存就是台式机的SDRAM内存,有些使用DDR SDRAM内存。

图5-34 LSI MegaRAID Enterprise 1600卡
在一张Rocket RAID卡上,安装了8块IDE磁盘。开机之后,在启动界面按照相应提示进入RAID卡的设置界面,如图5-35所示。
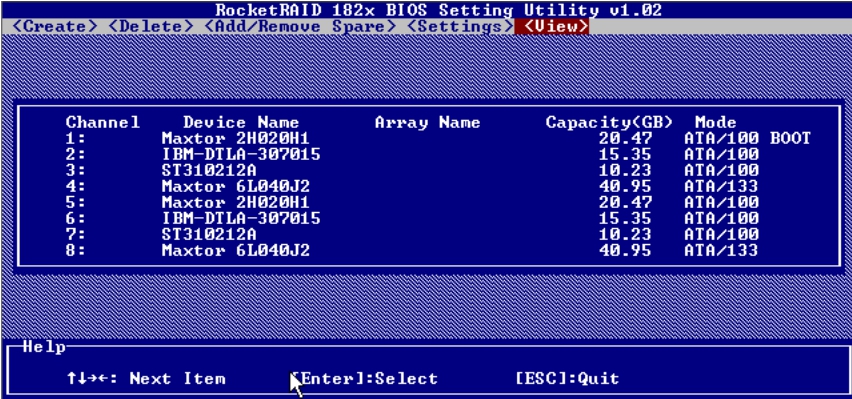
图5-35 磁盘列表
可以看到,这8块硬盘有着不同的品牌、容量以及参数,但它们都是IDE接口的ATA硬盘。
(1)选择RAID 0:Striping,如图5-36所示。
(2)给新RAID 0组起名为“RAID 0”,如图5-37所示。
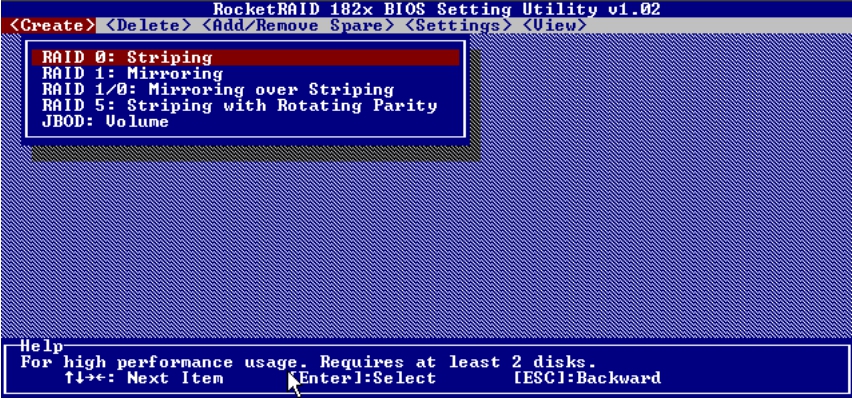
图5-36 选择RAID 0模式
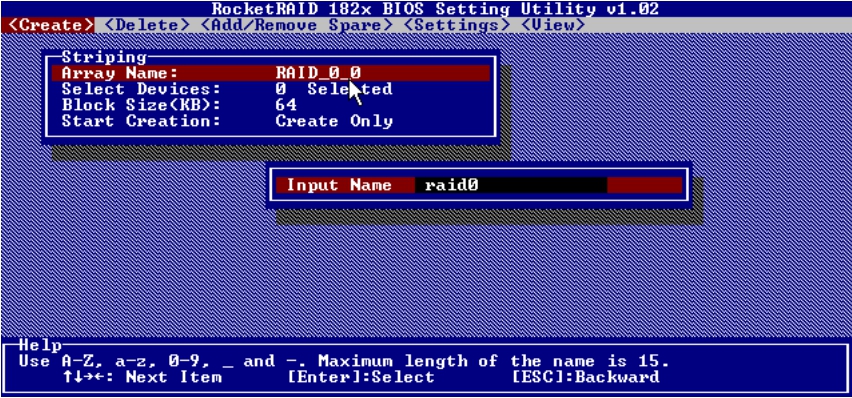
图5-37 起名“RAID 0”
(3)在Select Devices菜单下,选择RAID 0组所包含的磁盘,如图5-38和图5-39所示。
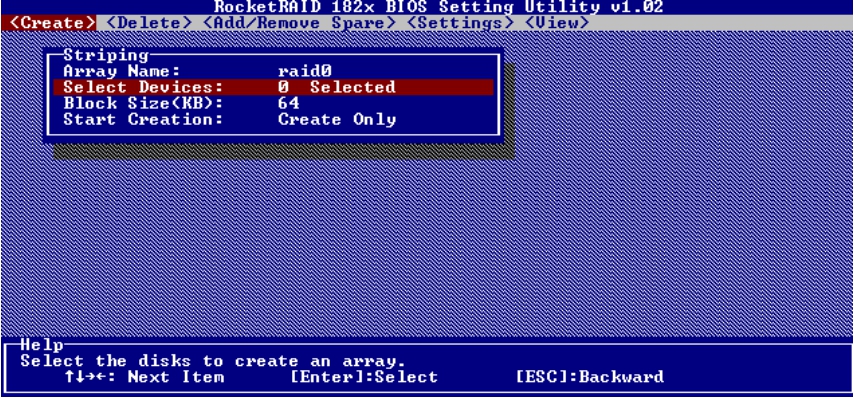
图5-38 选择磁盘(1)
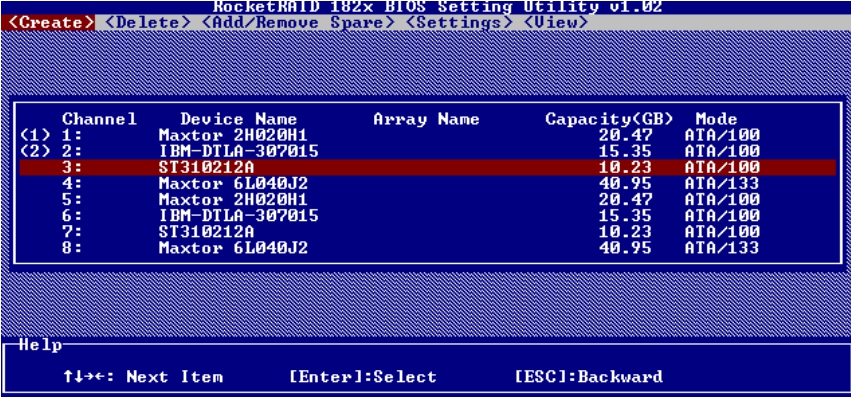
图5-39 选择磁盘(2)
(4)接下来,在Block Size菜单下可以为这个RAID 0组选择条块大小,如图5-40所示。至于Block Size参数是指整个条带的大小,还是指条带Segment的大小,要看厂家自己的定义。
(5)选择Start Creation,确定创建RAID组,如图5-41所示。
(6)创建完毕后,主界面中即显示出RAID信息,如图5-42所示。
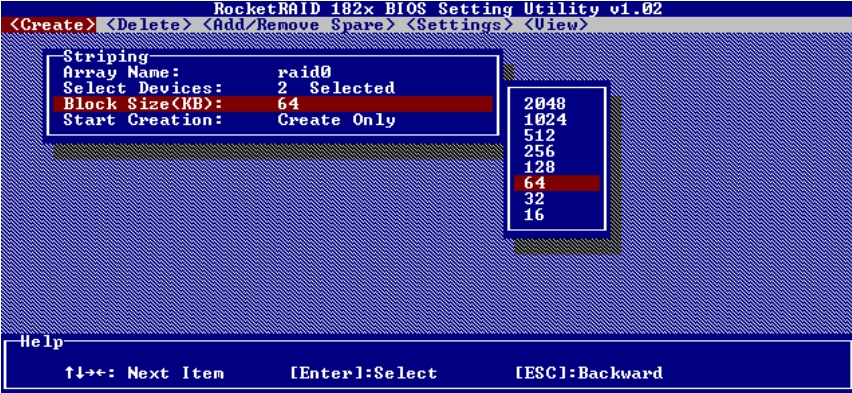
图5-40 设置Block Size
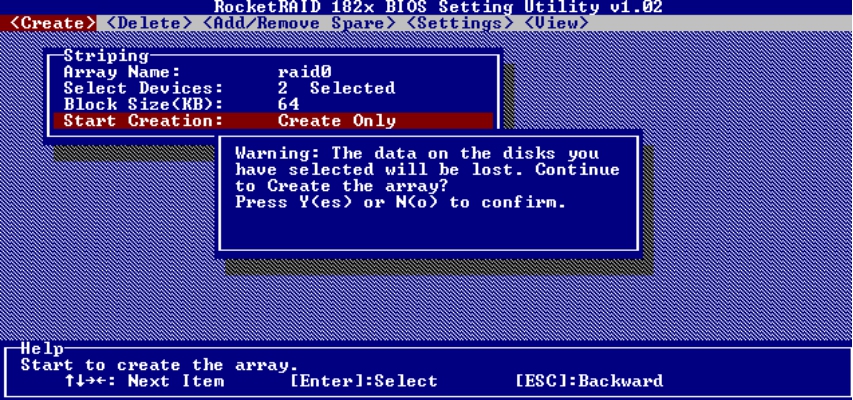
图5-41 开始创建RAID组
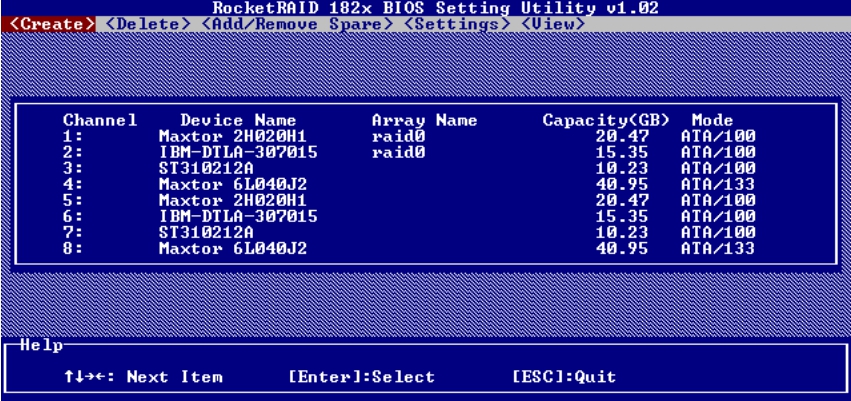
图5-42 RAID组的信息
接下来我们继续用以上方法创建其他类型的RAID组。
图5-43所示是RAID 1组的创建过程,可以发现Start Creation中有一个Duplication选项,这个选项的作用是将源盘数据复制到镜像盘,而不破坏源盘数据。如果选择了Create Only,则会破坏源盘的数据,重新创建干净的RAID 1组。
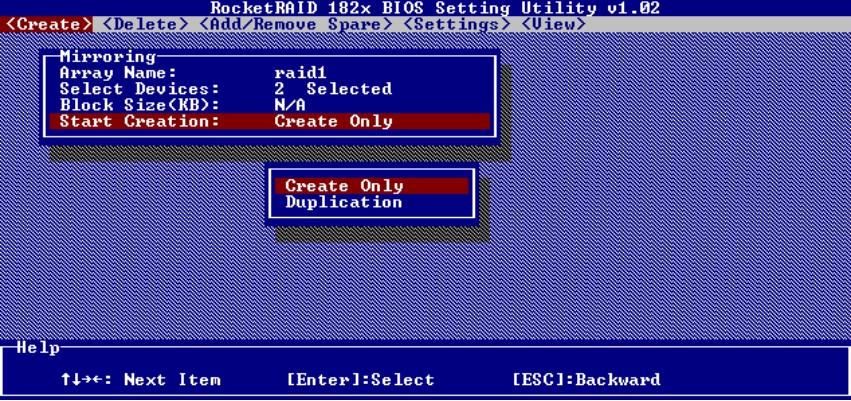
图5-43 创建RAID 1组
提示: 在Start Creation菜单中有两个选项,一个为Zero Build,另一个为No Build,如图5-44所示。Zero Build指将所有数据作废,从零开始生成数据的校验值。No Build指不计算数据校验值,如果用户能保证RAID 5组中的磁盘原来是处于一致性状态的,则可以用这个选项来节约时间,否则不要选择这个选项。
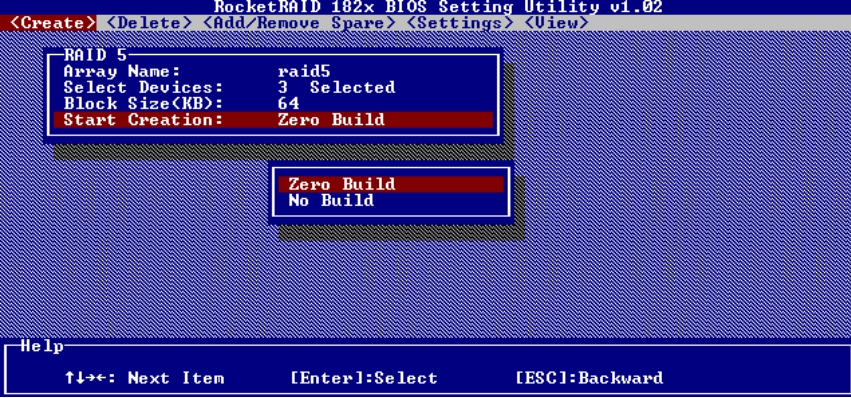
图5-44 两个选项
如果选择No Build选项,则会显示警告信息,如图5-45所示。
按Y键即可完成RAID 5组的创建。
至此,我们创建了RAID 0、RAID 1和RAID 5三个RAID组,如图5-46所示。
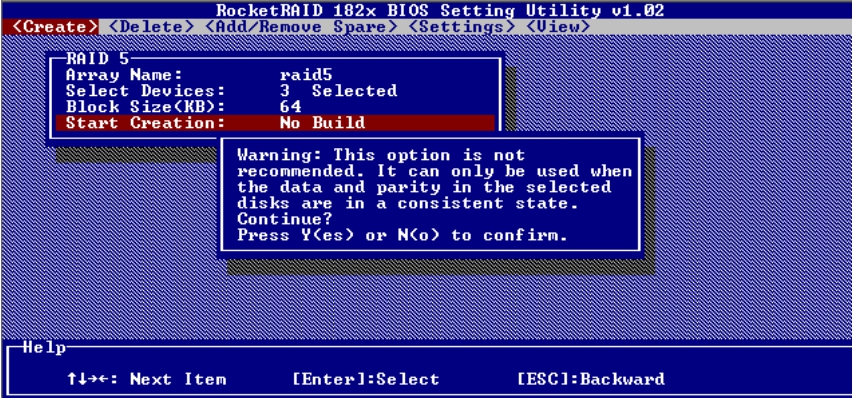
图5-45 警告信息
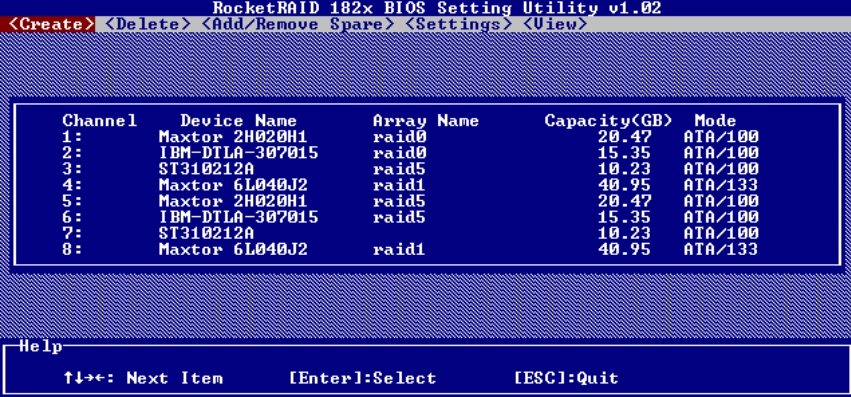
图5-46 三个RAID组的信息
如果对创建的RAID组不满意,可以删除重建,具体操作如图5-47和图5-48所示。
图5-47 删除RAID组
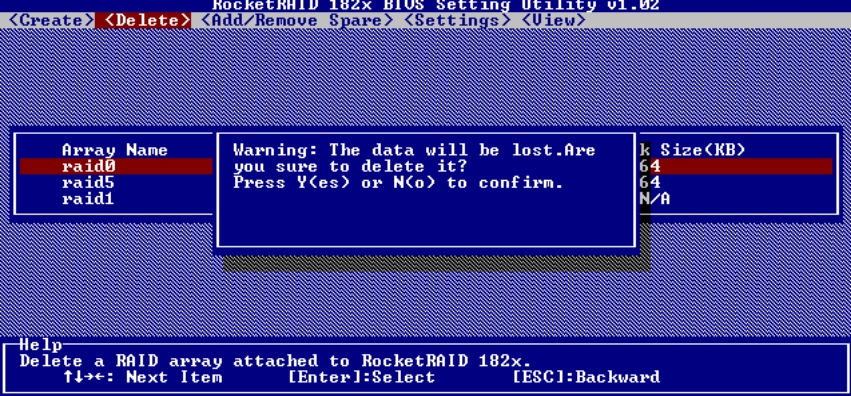
图5-48 确认信息
此外,还可以添加全局热备磁盘。切换到Add/Remove Spare菜单,如图5-49所示。
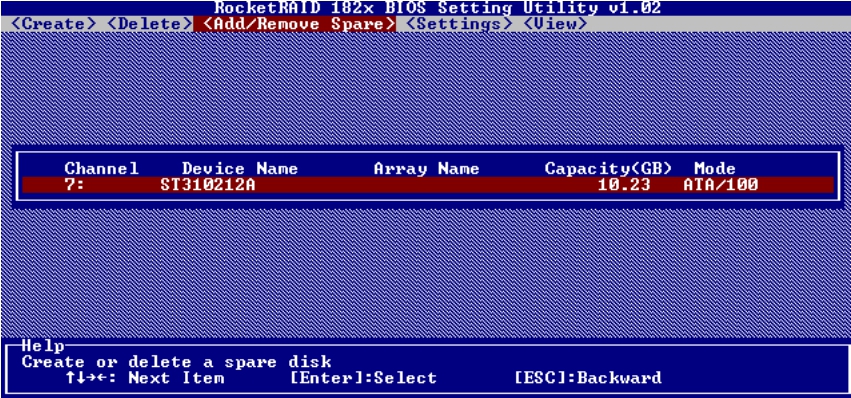
图5-49 添加全局热备盘
由于当前系统中只有一块空闲磁盘,所以我们就将这块磁盘作为全局热备磁盘,操作如图5-50和图5-51所示。如果任何RAID组中有磁盘损坏的话,RAID卡将利用这块热备磁盘来顶替损坏的磁盘,将数据重新同步到这块磁盘上。
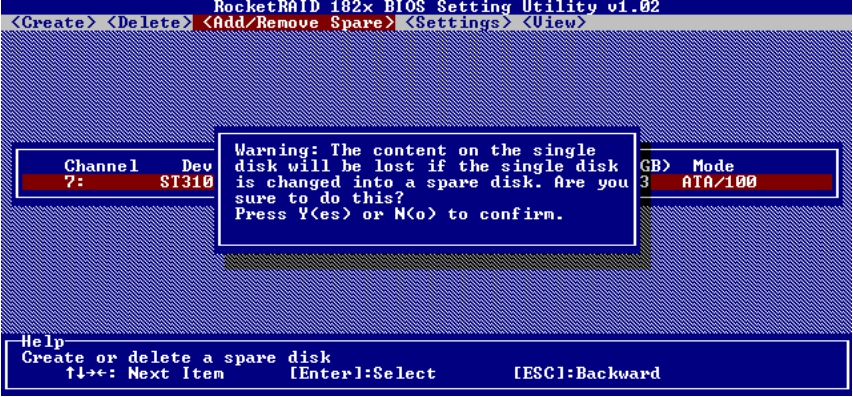
图5-50 确认信息
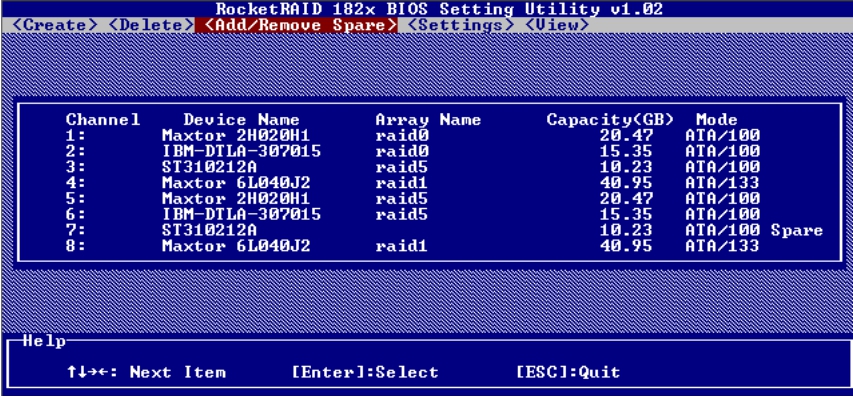
图5-51 磁盘状态
由于系统要从安装有操作系统的磁盘上启动,所以必须让RAID卡知道哪个逻辑磁盘是启动磁盘。具体设置如图5-52~图5-54所示。
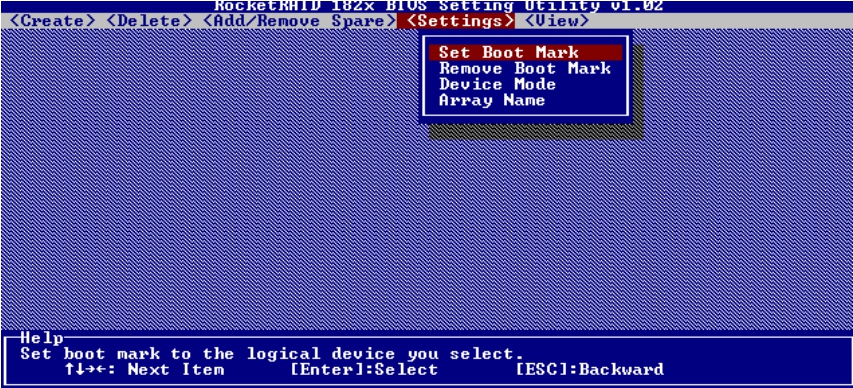
图5-52 设置启动盘(1)
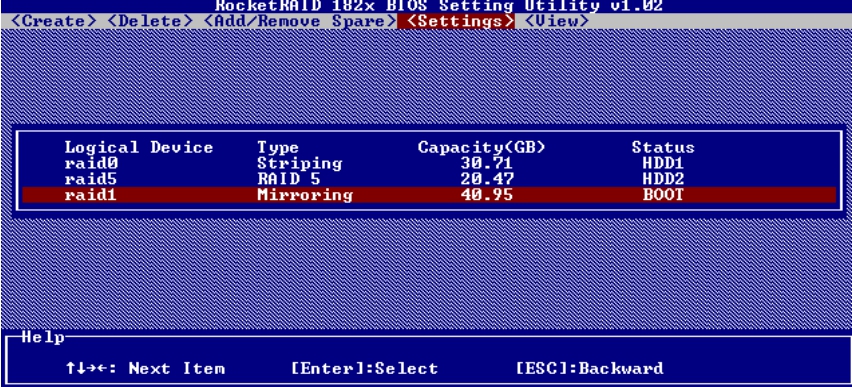
图5-53 设置启动盘(2)
在将RAID 1组形成的逻辑磁盘作为启动磁盘后,可以看见右边的“BOOT”标志。
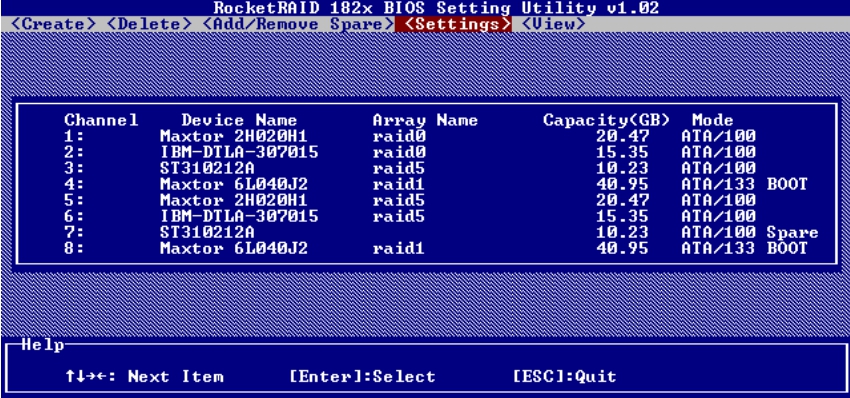
图5-54 设置启动盘(3)
在Device Mode菜单下,可以设置访问各个磁盘的模式参数,如图5-55和图5-56所示。
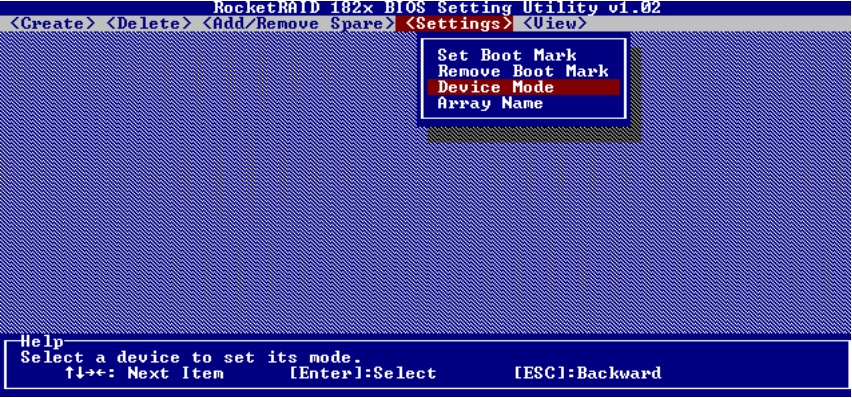
图5-55 设置磁盘参数(1)
图5-56 设置磁盘参数(2)
在View菜单下,可以查看所有设备、所有RAID组和所有逻辑磁盘(由于这块卡不具有在RAID组中再次划分逻辑磁盘的功能,所以每个逻辑组只能作为一个逻辑磁盘),如图5-57和图5-58所示。
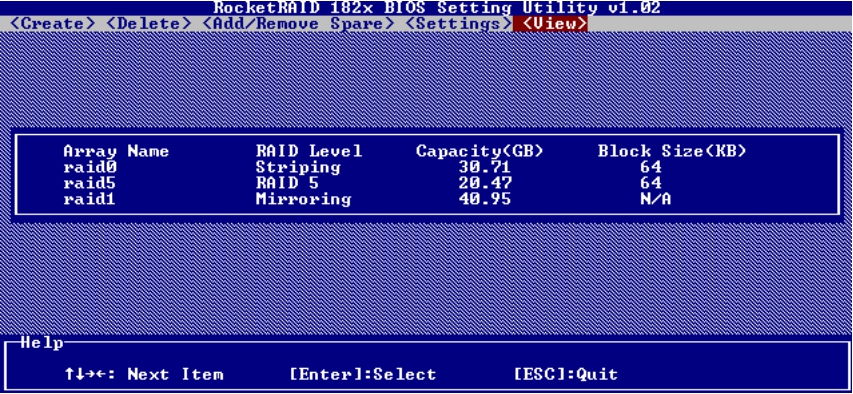
图5-57 RAID组状态(1)
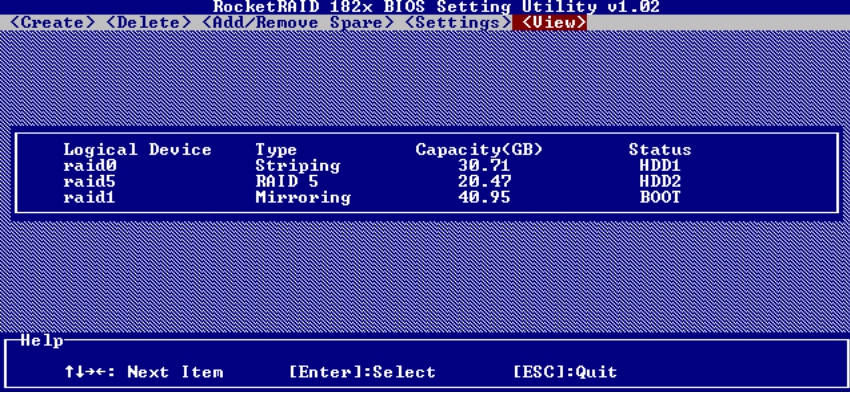
图5-58 RAID组状态(2)
RAID卡的出现着实让存储领域变得红火起来,几乎每台服务器都标配RAID卡或者集成的RAID芯片。一直到现在,虽然磁盘阵列技术高度发展,各种盘阵产品层出不穷,但RAID卡依然是服务器不可缺少的一个部件。
然而,RAID卡所能接入的通道毕竟有限,因此人们迫切希望创造一种可以接入众多磁盘、可以实现RAID功能并且可以作为集中存储的大规模独立设备。最终,磁盘阵列在这种需求中诞生了。
磁盘阵列的出现是存储领域的一个里程碑。关于磁盘阵列的描述,我们将在本书第6章中详细介绍。
在7种RAID形式的基础上,还可以进行扩展,以实现更高级的RAID。由于RAID 0无疑是所有RAID系统中最快的,所以将其他RAID形式与RAID 0杂交,将会生成更多新奇的品种。将RAID 0与RAID 1结合,生成了RAID 10;将RAID 3与RAID 0结合,生成了RAID 30;将RAID 5与RAID 0结合,生成了RAID 50。
图5-59是一个RAID 50的模型,RAID 30与其类似。控制器接收到主机发来的数据之后,按照RAID 0的映射关系将数据分块,一部分存放于左边的RAID 5系统,另一部分存放在右边的RAID 5系统。左边的RAID 5系统再次按照RAID 5的映射关系将这一部分数据存放于5块磁盘中的若干块,另一边也进行相同的过程。
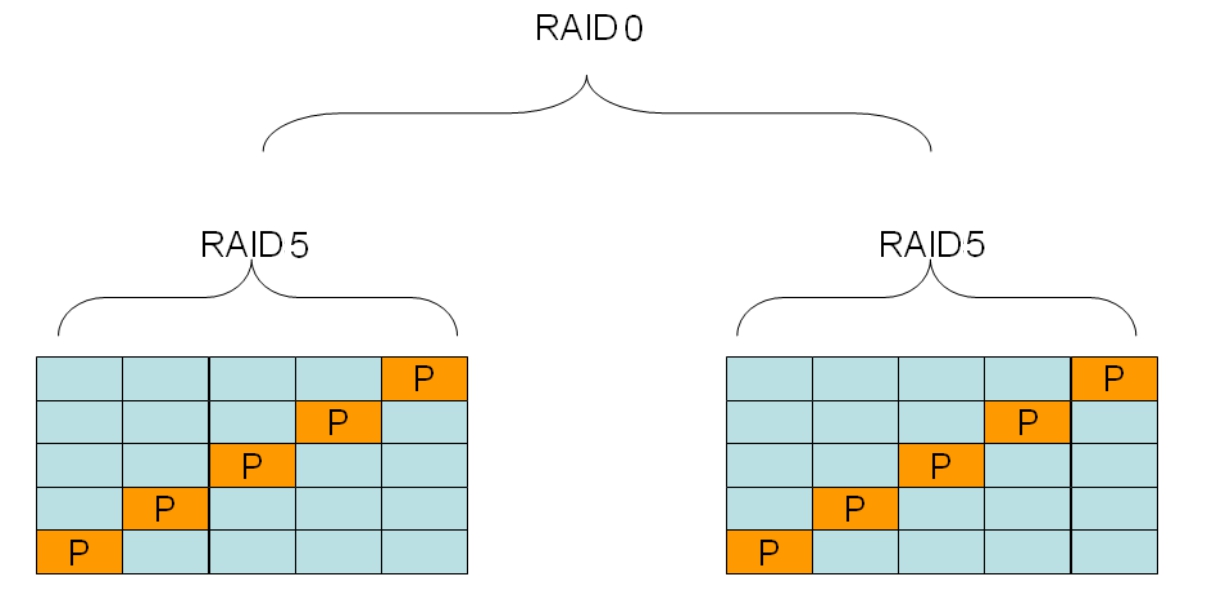
图5-59 RAID 50模型
实际中,控制器不可能物理地进行两次运算和写IO,这样效率很低。控制器可以将RAID 0和RAID 5的映射关系方程组合成一个函数关系方程,这样直接代入逻辑盘的LBA,便可得出整个RAID 50系统中所有物理磁盘将要写入或者读取的相应LBA地址,然后统一向磁盘发送指令。左边的RAID 5系统和右边的RAID 5系统分别允许损坏一块磁盘而不影响数据。但是如果在任何一边的RAID系统同时或者先后损坏了两块或者更多的盘,则整个系统的数据将无法使用。
RAID 10和RAID 01看起来差不多,但是本质上有一定区别。图5-60是一个RAID 10的模型。
如果某时刻,左边的RAID 1系统中有一块磁盘损坏,此时允许再次损坏的磁盘就剩下两块,也就是右边的RAID 1系统中还可以再损坏任意一块磁盘,而整体数据仍然是可用的。我们暂且说这个系统的冗余度变成了2。
图5-61是一个RAID 01的模型。
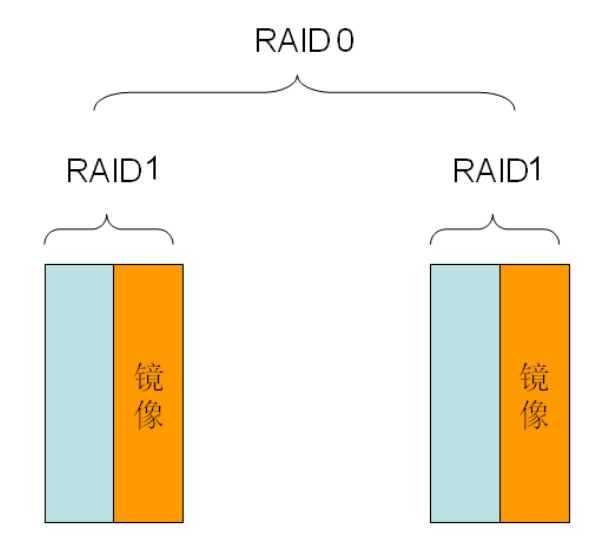
图5-60 RAID 10模型
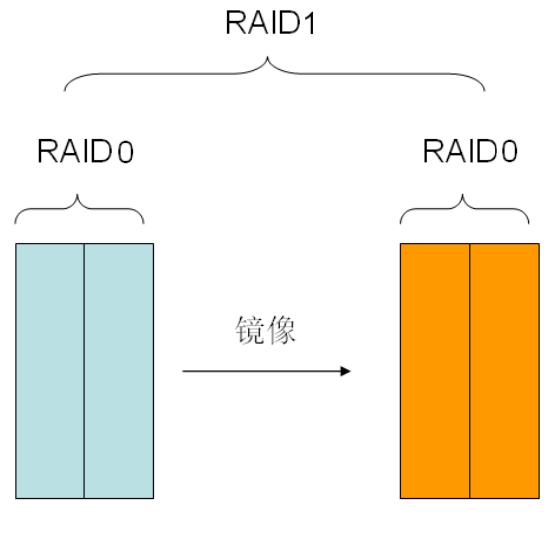
图5-61 RAID 01模型
如果某时刻,左边的RAID 0系统中有一块磁盘损坏,此时左边的RAID 0系统便没有丝毫作用了。所有的IO均转向右边的RAID 0系统。而此时,仅仅允许左边剩余的那块磁盘损坏。如果右边任何一块磁盘损坏,则整体数据将不可用。所以这个系统的冗余度变成了1,即只允许损坏特定的一块磁盘(左边RAID 0系统剩余的磁盘)。
综上所述,RAID 10系统要比RAID 01系统冗余度高,安全性高。
话说张真人送走了七星大侠之后,面对江湖上的浮躁,有苦难言。这江湖还能出一个像七星这样的豪侠吗?难啊!七星北斗阵,多么完美的一个阵式!七星老前辈用尽毕生心血,创立了7种阵式,将单个磁盘组成盘阵,提高整体性能!可是很少有人能体会到这个阵式的精髓,包括创建他的七星,都不一定。张真人自从七星走后,一直处于深度悲痛之中,悔恨当初为什么没有抽时间向七星拜师学艺!如今只能守着一本老侠留下来的《七星北斗阵式》天天仔细研读,以求找到什么灵感,来继续发扬老侠的这门绝技。
……
就这样过去了20年。张真人已经由年轻小伙变成了稳重善思的中年人。他凭借优秀的武艺和才华,来到武当山创立了道观,并收下了7位徒弟,以纪念七星北斗之豪情!张真人每晚休息之前,都要对着七星北斗拜三拜。20多年过去了,北斗的光芒依然是那么耀眼,依然看着世间纷争,昼夜交替。
这20年是科技飞速发展的20年。铁匠们的技艺提高很快,新技术不断被创造出来。大容量、高速度的磁盘在地摊卖10文钱一斤。
某天张老道下山溜达,发现地摊上的磁盘品质还不错,比20年前的货强太多了,顺手就买了50斤回去。点了点,足足50块。他让他的7位徒弟,分别按照七星阵摆上各种阵形,来捣鼓这50块硬盘。7位徒弟早就对七星阵烂熟于心,把这50块磁盘捣鼓得非常顺。张老道频频点头,心里想着:“嗯,真应了那句话啊。长江后浪推前浪,一代新人换旧人!”摆弄了一阵之后,徒弟们都累了。这次格外地累,不禁都坐在地上休息。老道把眼一瞪,“嗯忒!!!年轻人,不好好练功!不准偷懒!”徒弟们上前道:“师父,不是我们偷懒,这次您买的磁盘和以前的不一样。我们在出招的时候,就是在‘化龙’这一招的时候特别吃力。这条龙太大,不好操控。”老道一看,果然,这50块磁盘每块足有1TB大,50块就是50TB。“嚯嚯,20年前一块磁盘最多也就是50MB,没想到啊!”
这天晚上,老道用完粗茶淡饭之后,遥望北斗,心想:七星老侠在天上不知道看见此情此景,会给我什么启示呢?20年前,用此阵式生成的虚拟磁盘,大小也不过几GB,而如今已经达到了TB级别,也难怪我那些徒儿们会吃不消。怎么办呢?需要把这以TB论的虚拟磁盘再次划分开来,划分成多条“小龙”,这样就可以灵活操控了。而且针对目前的磁盘超大的容量,完全可以在一个阵中同时应用多种阵式。比如让我7位徒弟,其中3人摆出RAID 0阵式,另外4人同时摆出RAID 5阵式,共同出招。对每个阵式生成虚拟“龙盘”,把它划分成众多小的“龙盘”,这样对外不但我们的威力没有减少,而且可以灵活运用,让敌人不知道我们到底有几个人。
张老道决定将大龙盘划分成小龙盘,这事十分好办,只需体现在“心中”就可以了。只要你心中有数,那些物理磁盘的哪部分区域属于哪个小龙盘,就完全可以对外通告了。老道称这种技术为逻辑盘技术。
实际中,比如用5块100GB的磁盘做了一个RAID 5,那么实际数据空间可以到400GB,剩余100GB空间是校验空间。如果将这400GB虚拟成一块盘,不够灵活。且如果OS不需要这么大的磁盘,就没法办了。所以要再次划分这400GB的空间,比如划分成4块100GB的逻辑磁盘。而这逻辑盘虽然也是100GB,但是并不同于物理盘,向逻辑盘写一个数据会被RAID计算,而有可能写向多块物理盘,这样就提升了性能,同时也得到了保护。纵使RAID组中坏掉一块盘,操作系统也不会感知到,它看到的仍然是100GB的磁盘。
不仅如此,老道还想到了在一个阵式中同时使用多种阵法的方式。
实际中,假设总线上连接有8块100GB的磁盘,我们可以利用其中的5块磁盘来做一个RAID 5,而后再利用剩余的3块磁盘来做一个RAID 0,这样,RAID 5的可用数据空间为400GB,校验空间为100GB,RAID 0的可用数据空间为300GB。而后,RAID 5和RAID 0各自的可用空间,又可以根据上层OS的需求,再次划分为更小的逻辑磁盘。这样就将七星北斗阵灵活地运用了起来,经过实践的检验,这种应用方法得到了巨大的推广和成功。
张老道给划分逻辑盘的方法取名为巧化神龙,将同一个阵中同时使用多种阵式的方法叫做神龙七变。
目前各种RAID卡都可以划分逻辑盘,逻辑盘大小任意设置。每个逻辑盘对于OS来说都认成一块单独的物理磁盘。这里不要和分区搞混,分区是OS在一块物理磁盘上做的再次划分。而RAID卡提供给OS的,任何时候,都是一块或者几块逻辑盘,也就是OS认成的物理磁盘。而OS在这个磁盘上,还可以进行分区、格式化等操作。
下面说一下RAID卡对逻辑磁盘进行再次划分的具体细节。既然要划分,就要心中有数,比如某块磁盘的某个区域,划分给哪个逻辑盘用,对应逻辑盘的LBA地址是多少,这块磁盘的RAID类型是什么等。而这些东西不像RAID映射那样根据几个简单的参数就能确定,而且对应关系是可以随时变化的,比如扩大和缩小、移动等。所以有必要在每块磁盘上保留一个区域,专门记录这种逻辑盘划分信息、RAID类型以及组内的其他磁盘信息等,这些信息统称为RAID信息。不同厂家、不同品牌的产品实现起来不一样,SNIA委员会为了统一RAID信息的格式,专门定义了一种叫做DDF的标准,如图5-62所示。
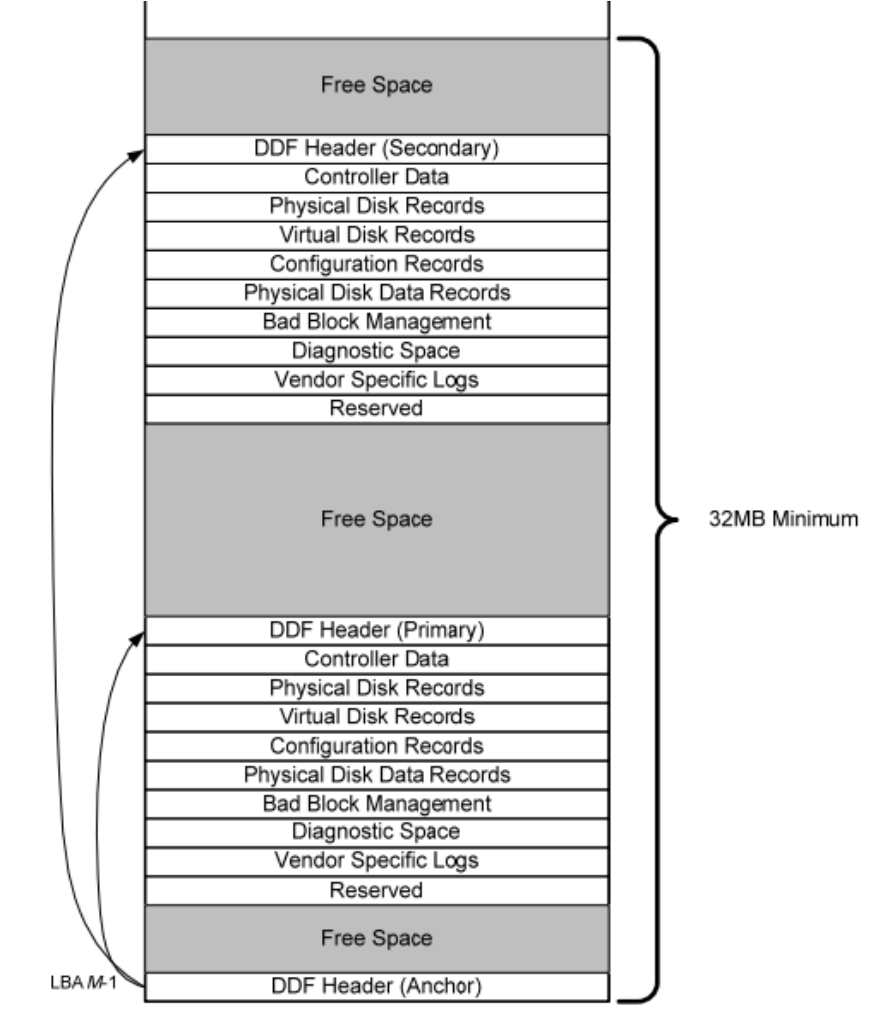
图5-62 DDF布局图
图5-63所示的是微软和Veritas公司合作开发的软RAID在磁盘最末1MB空间创建的数据结构。有了这个记录,RAID模块只要读取同一个RAID子系统中每块盘上的这个记录,就能够了解RAID信息。即使将这些磁盘打乱顺序,或者拿到其他支持这个标准的控制器上,也照样能够认到所划分好的逻辑盘等所有需要的信息。
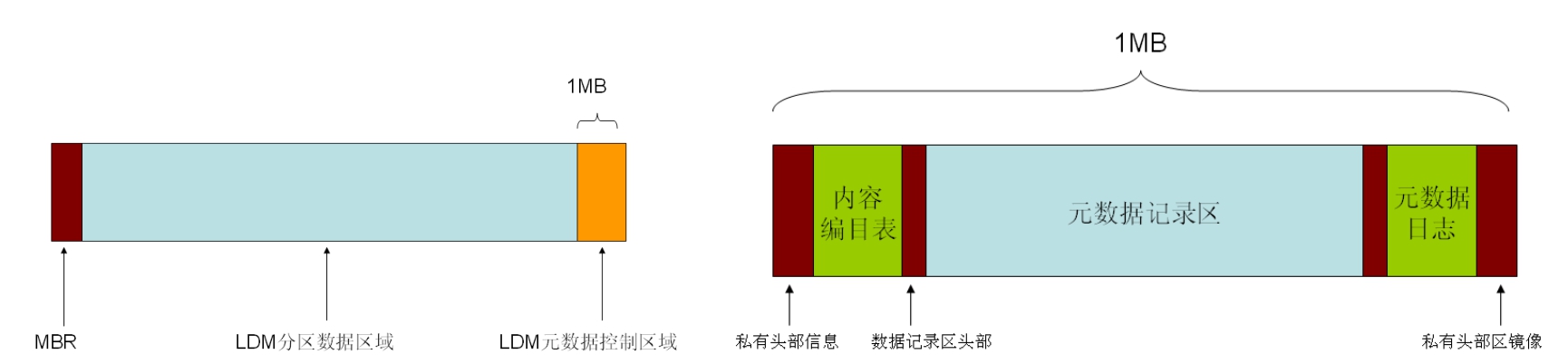
图5-63 Windows系统中的动态磁盘信息
RAID卡可以针对总线上的某几块磁盘做一种RAID类型,然后针对另外的几块磁盘做另一种RAID类型。一种RAID类型中包含的磁盘共同组成一个RAID Group,简称RG。逻辑盘就是从这个RG中划分出来的,原则上逻辑盘不能跨RG来划分,就是说不能让一个逻辑盘的一部分处于一个RG,另一部分处于另一个RG。因为RG的RAID类型不一样,其性能也就不一样,如果同一块逻辑盘中出现两种性能,对上层应用来说不是件好事,比如速度可能会忽快忽慢等。
张真人推出了这两门绝技之后,在江湖上引起了轩然大波。大家争相修炼,并取得了良好的效果。一时间,江湖上几乎人人都练了张真人这两门功夫。而且各大门派已经将七星北斗阵以及张真人的功夫作为各派弟子必须掌握的基本功。
近水楼台先得月。武当七子当然已经把功夫练到了炉火纯青的地步。老道非常欣慰。他相信七星侠在天之灵倘若看到了这阵式被拓展,一定也会感到欣慰的。
老道创立这两门功夫的兴奋,很快就被一个不大不小的问题给吹得烟消云散。这个问题就是一旦逻辑盘划分好之后就无法改变,要改变也行,上面的数据就得全部抹掉,这是让人无法容忍的。比如已经做好了一个100GB的逻辑盘,但是用了两年以后,发现数据越来越多,已经盛不下了。但又不能放到别的磁盘,因为受上层文件系统的限制,一个文件不可能跨越多个分区来存放,更别提跨越多个磁盘了。如果有一个文件已经超过了100GB,那么谁也无力回天,只能重新划分逻辑盘。数据怎么办?这问题遇不到则已,遇到了就是死路一条。江湖上已经有不少生意人因为这个问题而倾家荡产,他们无奈之余,准备联合起来到武当恳求张老道想一个办法,以克服这个难关,好让他们东山再起。张老道对他们的遭遇深感同情,同时也责怪自己当初疏忽了这个问题。于是他当众许下承诺:3个月之后,来武当取解决办法。
其实张真人许下3个月的时间,他自己也毫无把握。但是为了平息众怒,也只能冒险赌一次了!送走众人之后,张老道就开始天天思考解决这个问题的办法。他想:到底怎么样才能让使用者运用自如呢?如果一开始就给它划分一个100GB的逻辑盘,如果数据盛不下了,此时把其他磁盘上未使用的空间挪一部分到这个逻辑盘,岂不是就可以了么?
可以是可以,但从RAID卡设置里增加或减少逻辑盘容量很费功夫。在RAID卡里增加这种代码,修炼成本很高,而且即使实现了,主机也不能立即感应到容量变化。即使感应到了,也不能立即变更。对于Windows系统来说,必须将其创建为新的分区。想要合并到现有分区,必须用第三方分区表调整工具在不启动操作系统的情况下来修改分区表才行。再者,其上的文件系统不一定会跟着扩大,NTFS这种文件系统不能动态张缩,也必须在不启动操作系统的条件下用第三方工具调整。这种方法对一些要求不间断服务的应用服务器并不适用。
老道想到这里,觉得至少已经找到了一种解决办法,虽然不是很方便,需要重启主机,之后再在RAID卡中更改配置。更改完毕后,可能还要重启一次,然后进入系统,系统才能认出新容量的磁盘。而OS就算正确认出了新增的磁盘容量,由于分区表没有改变,新增容量不属于任何一个分区,还是不能被使用,所以还需要手动修改分区表。太复杂、太麻烦了,能否找一种方便快捷的方法呢?
话说冬至这天,天上飘着雪花。武当山张灯结彩,喜气洋洋!这天是张真人的70大寿!江湖各大门派及各路英雄纷纷前来拜寿。武当上下忙得是不亦乐乎!就说包饺子吧,一会儿面不够了去和面,一会儿水不够了去挑水。张真人是往来作揖,笑迎来宾。厨房则加紧和面,由于厨房空间太小,所以和好的面被运往各个分理点处,那里有小道士负责擀皮、包饺子。张真人看着眼前这小老道跑来跑去的多少回了,就纳闷了,所以跟着去看看怎么回事。一看才知道,弄了半天是往各处运面团呢!觉得挺好笑的,也没当回事。等大家都差不多到齐了,共同给老道祝了寿,然后就上饺子了。张老道看着碗里一个个的饺子,再想想刚才那面团的事,心里突然一动!于是当众宣布,一个月前自己承诺的约定过不了几天就会实现了!众豪杰都鼓起掌来!
提示: 张老道到底想到了什么呢?原来,他想起了小道包饺子和面的情形。厨房和了一大团面,下面随用随取。不够了,割一块揉进去就行了,或者掰下一块来放着下次用。这不正解决了一个月前大家所头疼的问题吗?RAID控制器和好了几团面(逻辑盘),放那由自己看着用,哪不够了就掰块补上。必须实现这样一种像掰面团一样灵活的管理层,才能最终解决使用中出现的问题。是啊,说得简单,可是具体要做却不是那么容易的。
当天晚上,老道睡觉的时候就一个劲地想,在RAID控制器上掰面,以前也分析过了,不合适,那么在哪里掰呢?RAID控制器给你和了几斤面,你就得收着,不要也不行。但是面收着了,你可以自己掰呀,是啊,自己掰。那么就是说,RAID控制器提交给OS的逻辑磁盘。应该可以掰开,或者揉搓到一块儿去,可以想怎么揉搓就怎么揉搓。这功能如果能通过在操作系统上运行一层软件来实现的话,不但灵活,而且管理方便!想到这,老道心里有了底。
第二天,老道就让徒弟们按照他写的口诀来实现他这个想法,大获成功!RAID控制器是硬件底层实现RAID,实现逻辑盘,所以操作起来不灵活。如果在OS层再把RAID控制器提交上来的逻辑盘(OS会认成不折不扣的物理磁盘)加以组织、再分配,就会非常灵活。因为OS层上运行的都是软件,完全靠CPU来执行,而不用考虑太多的细节。张老道立即将这种新的掌法公布天下,称作神仙驾龙!
实际中,有很多基于这种思想的产品,这些产品都有一个通用的名称,叫做卷管理器(Volume Manager,VM)。比如微软在Win2000中引入的动态磁盘,就是和Veritas公司合作开发的一种VM,称为LDM(逻辑磁盘管理)。Veritas自己的产品Veritas Volume Manager(VxVM)和广泛用于Linux、AIX、HPUX系统的LVM(Logical Volume Manager),以及用于Sun Solaris系统的Disk Suite,都是基于这种在OS层面,将OS识别到的物理磁盘(可以是真正的物理磁盘,也可以是经过RAID卡虚拟化的逻辑磁盘)进行组合,并再分配的软件。它们的实现方法大同小异,只不过细节方面有些差异罢了。
这里需要重点讲一下LVM,因为它的应用非常普遍。LVM开始是在Linux系统中的一种实现,后来被广泛应用到了AIX和HPUX等系统上。
■ PV:LVM将操作系统识别到的物理磁盘(或者RAID控制器提交的逻辑磁盘)改了个叫法,叫做Physical Volume,即物理卷(一块面团)。
■ VG:多个PV可以被逻辑地放到一个VG中,也就是Volume Group卷组。VG是一个虚拟的大存储空间,逻辑上是连续的,尽管它可以由多块PV组成,但是VG会将所有的PV首尾相连,组成一个逻辑上连续编址的大存储池,这就是VG。
■ PP:也就是Physical Partition(物理区块)。它是在逻辑上再将一个VG分割成连续的小块(把一大盆面掰成大小相等的无数块小面团块)。注意,是逻辑上的分割,而不是物理上的分割,也就是说LVM会记录PP的大小(由几个扇区组成)和PP序号的偏移。这样就相当于在VG这个大池中顺序切割,如果设定一个PP大小为4MB,那么这个PP就会包含8192个实际物理磁盘上的扇区。如果PV是实际的一块物理磁盘,那么这些扇区就是连续的。如果PV本身是已经经过RAID控制器虚拟化而成的一个LUN,那么这些扇区很有可能位于若干条带中,也就是说这8192个扇区物理上不一定连续。
■ LP:PP可以再次组成LP,即Logical Partition(逻辑区块)。逻辑区块是比较难理解的,一个LP可以对应一个PP,也可以对应多个PP。前者对应前后没什么区别。后者又分两种情况:一种为多个PP组成一个大LP,像RAID 0一样;另一种是一个LP对应几份PP,这几份PP每一份内容都一样,类似于RAID 1,多个PP内容互为镜像,然后用一个LP来代表它们,往这个LP写数据,也就同时写入了这个LP对应的几份PP中。
■ LV:若干LP再经过连续组合组成LV(Logical VoLUNme,逻辑卷),也就是LVM所提供的最终可用来存储数据的单位。生成的逻辑卷,在主机看来还是和普通磁盘一样,可以对其进行分区、格式化等。
思考: 有人问了,一堆面团揉来揉去,最终又变成一堆面团了,你这是揉面还是做存储呢?
确实,面团最终还是面团。但是此面团非彼面团。最终形成的这个LV,它的大小可以随时变更,也不用重启OS,你想给扩多大就扩多大,前提是面盆里面还有被掰开备用的PP。而且,只要盆里面有PP,你就可以再创建一个LV,也就是再和一团面,LV数量足够用的。如果不增加卷管理这个功能,那么RAID卡提交上来多少磁盘,容量多大就是多大,不能在OS层想改就改、为所欲为。而卷管理就提供了这个为所欲为的机会,让你随便和面团。
LVM看起来很复杂,其实操作起来很简单。创建PV,将PV加入VG,在VG中再创建LV,然后格式化这个LV,就可以当成一块普通硬盘使用了。容量不够了,还可以随便扩展,岂不快哉?LVM一个最大的好处就是生成的LV可以跨越RAID卡提交给OS的物理磁盘(逻辑盘)。这是理所当然的,因为LVM将所有物理盘都搅和到一个大面盆中了,当然就可以跨越物理盘了。
下面以RedHat Enterprise Linux Server 4 Update 5操作系统为例,给大家示例一下LVM的配置过程。
(1)在操作系统安装过程中,选择手动配置磁盘管理,如图5-64所示。
(2)可以看到,这台机器共有8块物理磁盘,每块的容量为1GB,如图5-65所示。
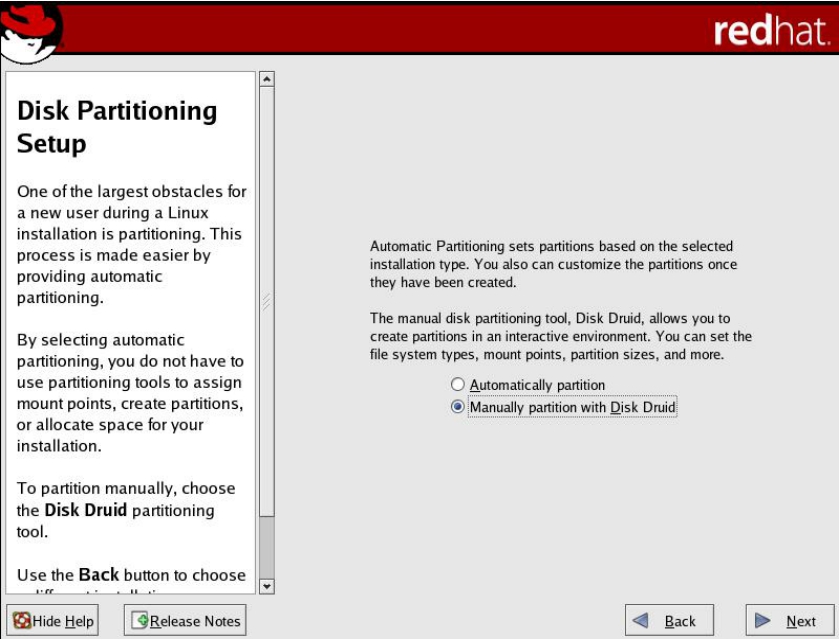
图5-64 选择手动管理
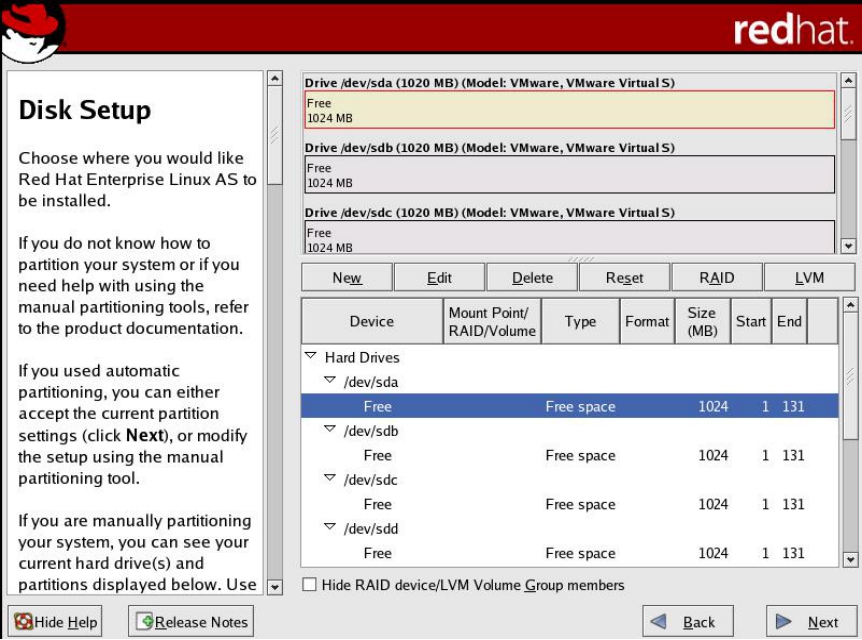
图5-65 磁盘列表
(3)首先,需要定义一个/boot分区,这个分区是用来启动基本操作系统内核的,所以这块空间不能参与LVM。我们选择从第一块硬盘(sda)划分出20个磁道的空间用来作为/boot分区。这块空间也就成了sda1设备,如图5-66所示。
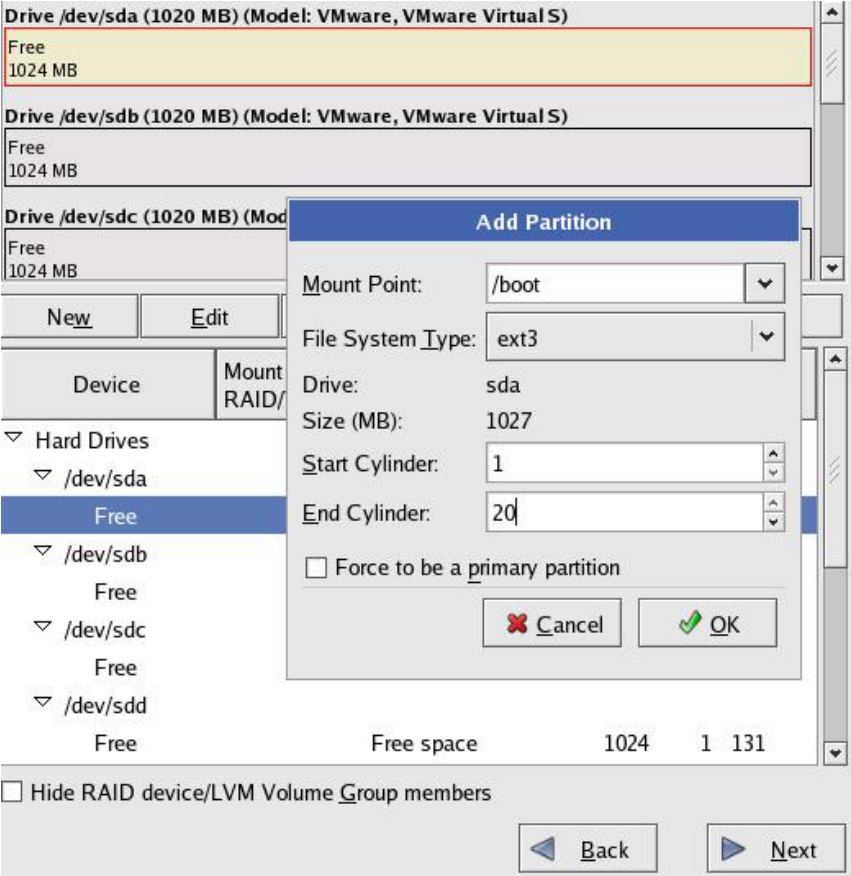
图5-66 创建/boot分区
(4)接下来,对于sda2、sdb、sdc、sdd、sde、sdf、sdg、sdh所有这些剩余的磁盘或者分区,就可以将它们配置成LVM的PV(物理卷)。选中每个磁盘或者分区,单击Edit按钮。在File System Type下拉列表框中,选择physical volume(LVM)选项,表示将这个硬盘或者分区配置成LVM的PV。PV可以任意设定大小,只要编辑End Cylinder文本框中的值即可。剩余空间可以继续作为PV再次分配。对每个磁盘都进行上述操作,如图5-67所示。
(5)操作完成后,信息栏中显示所有磁盘和sda2分区都已被配置成为PV,如图5-68所示。
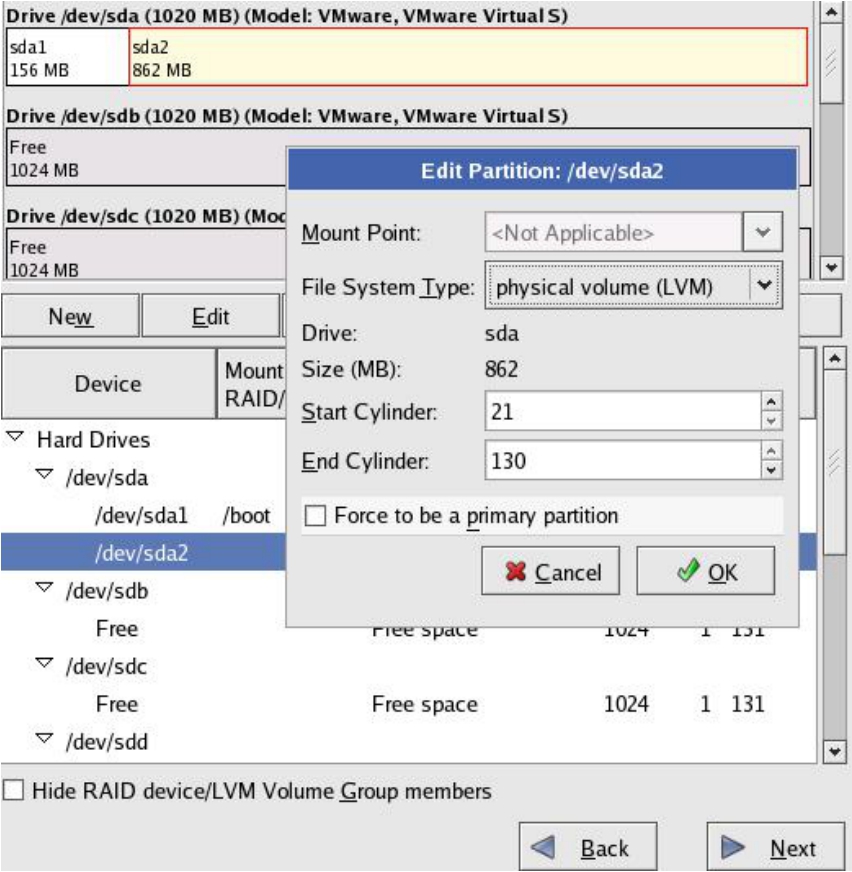
图5-67 设置磁盘类型为LVM管理状态
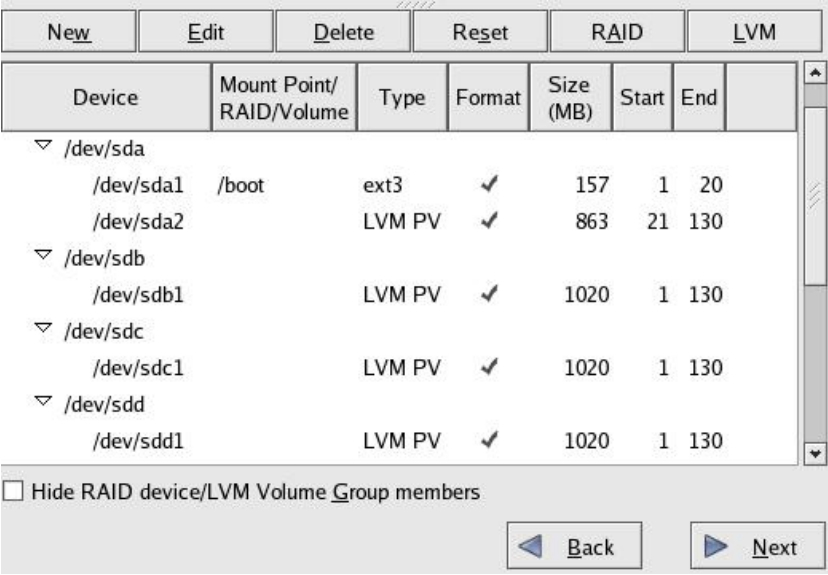
图5-68 磁盘状态
(6)单击LVM按钮会出现如图5-69所示的对话框。这一步就是创建VG(Volume Group,卷组)的过程。可以将PV进行任意组合,组合后的PV就形成了VG。
(7)这里我们做一个名为“VolGroup00”的卷组,其包含sda2和sdb1两个PV。在Physical Extent下拉列表框中,可以选择这个卷组对应的磁盘空间的最小分配单位(在AIX的LVM中,这个最小单位称为Physical Partition,即PP)。然后单击下方的Add按钮,从这个大的卷组空间中再次划分逻辑卷,即LV。下面创建一个大小为1000MB的逻辑卷LogVol00,并且用ext3文件系统将这个卷格式化,并挂载到/home目录下,如图5-70所示。
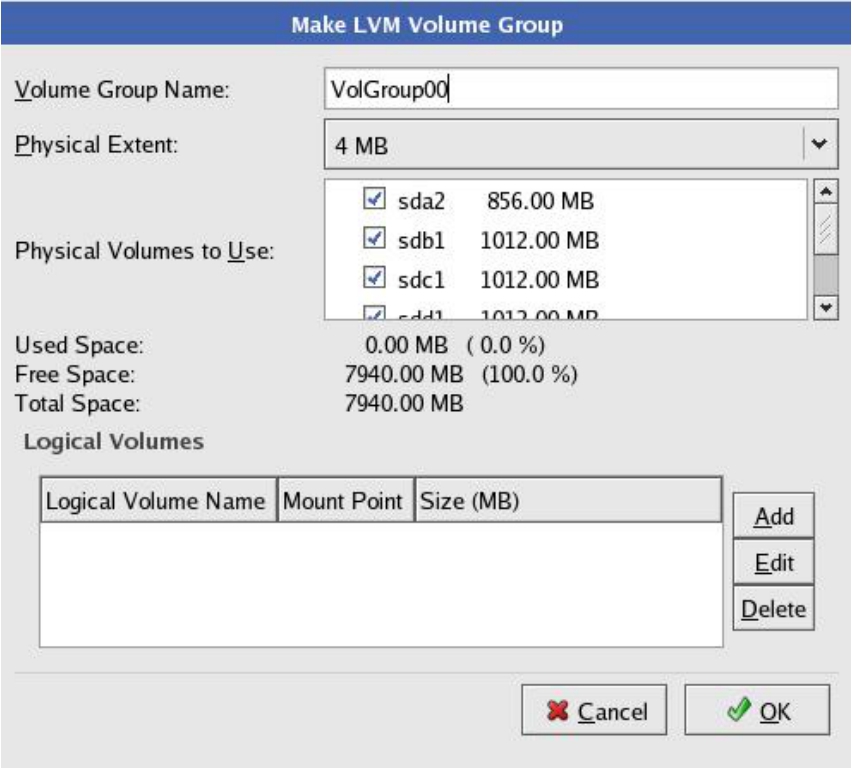
图5-69 创建卷组
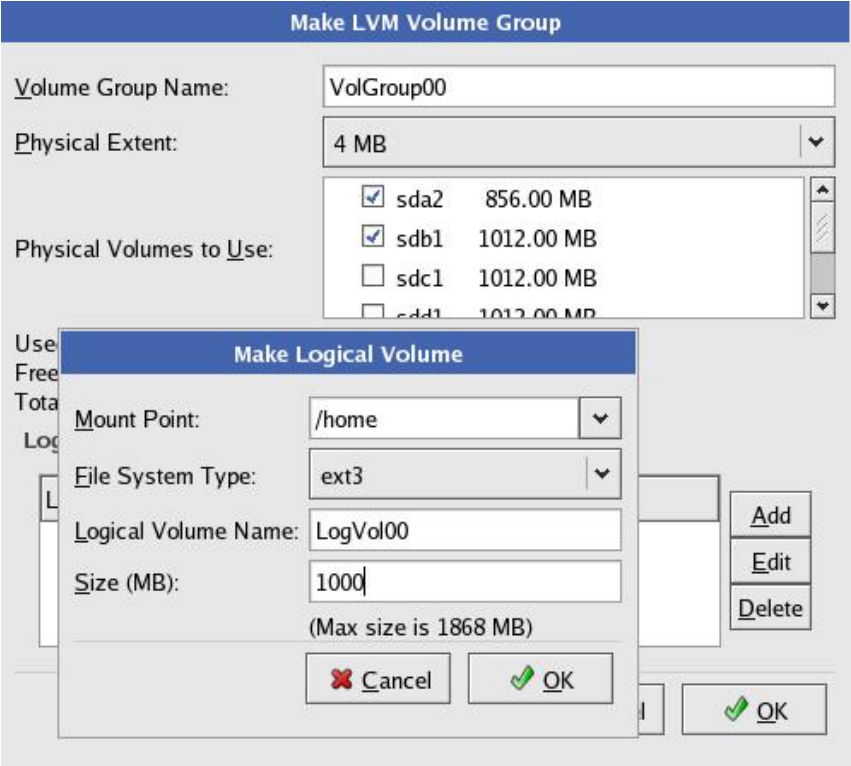
图5-70 创建LV并挂载
(8)然后将VolGroup00卷组中剩余的空间,全部分配给一个新的LV,即LogVol01,用ext3文件系统格式化,并挂载到/tmp目录下,如图5-71所示。
(9)将剩余的sdc1、sdd1、sde1、sdf1、sdg1、sdh1这几块PV全部分配给一个新的卷组VolGroup01,并且在卷组中创建一个逻辑卷LogVol00,大小为整个卷组的大小,用ext3文件系统格式化,并挂载到/目录下,如图5-72所示。
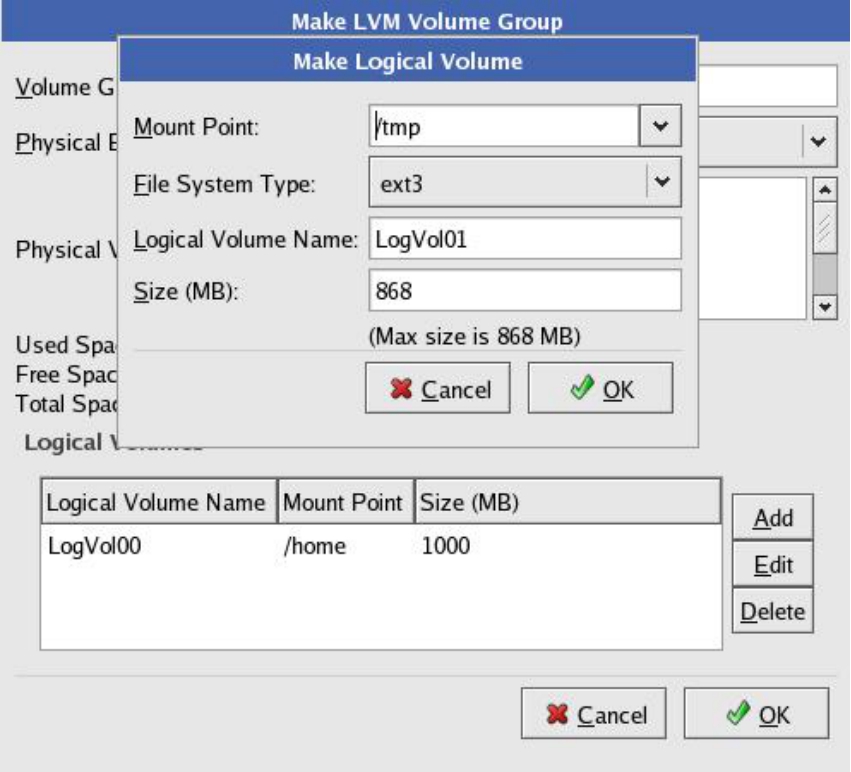
图5-71 创建LV并挂载
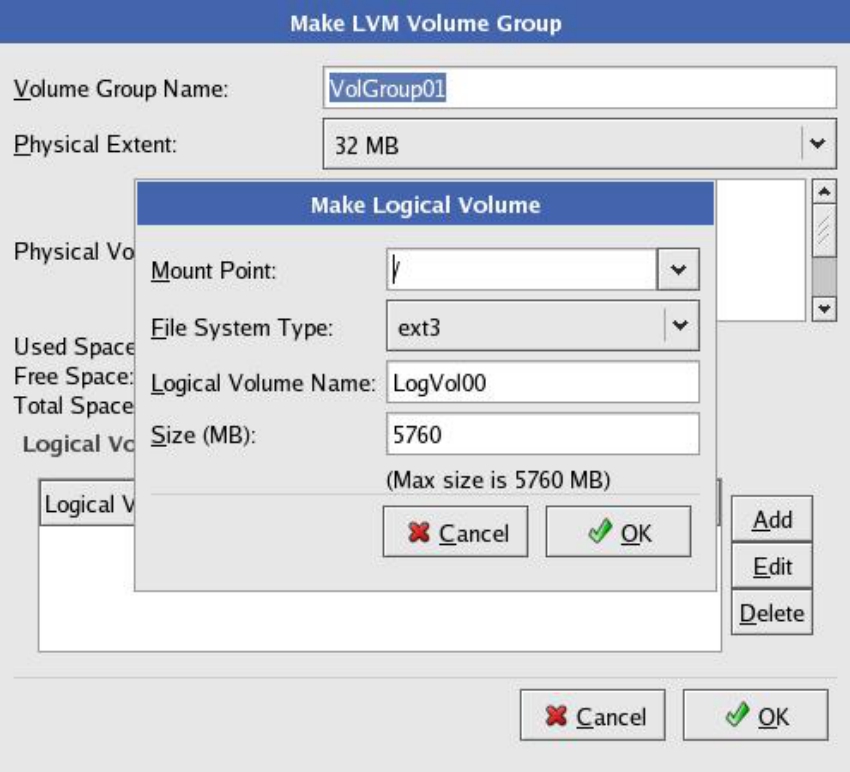
图5-72 创建LV并挂载
(10)配置完成后的状态如图5-73所示。

图5-73 配置完成后的状态
说到这里,别以为LVM就只会像疯子一样,拿来面团就揉到一起,掰来掰去,什么都不管,那样岂不真成了马大哈了。它是需要在心里暗自记录的,比如某块物理盘的名称和容量。表面上是和其他物理盘融合到一起,但还是要记住谁是谁,从哪里到哪里属于这块盘,从哪里到哪里属于那块盘,地址多少,等等。
这些信息记录在磁盘上的某个区域,LVM中这个区域叫做VGDA。LVM就是通过读取每块物理磁盘上的这个区域来获取LVM的配置信息,比如PP大小、初始偏移、PV的数量和信息、排列顺序及映射关系等。LVM初始化的时候会读取这些信息,然后在缓存中生成对应的映射公式,从而完成LV的挂载。挂载之后,就可以接受IO了。比如上层访问某个LV的LBA 0xFF地址,那么LVM就需要通过缓存中的映射关系判断这个地址对应到实际物理磁盘是哪个或哪几个实际地址。假设这个地址实际对应了磁盘a的LBA 0xAA地址,那么就会通过磁盘控制器驱动直接给这个地址发数据,而这个地址被RAID控制器收到后,可能还要做一次转换。因为OS层的“物理磁盘”可能对应真正的存储总线上的多块物理磁盘,这个映射就需要RAID控制器来做了,原理都是一样的。
卷管理软件对待由RAID卡提交的逻辑盘(OS识别成物理磁盘)和切切实实的物理盘的方法是一模一样的。也就是说,不管最底层到底是单物理盘,还是由RAID控制器提交的逻辑物理盘,只要OS认成它是一块物理磁盘,那么卷管理器就可以对它进行卷管理。只不过对于RAID提交的逻辑盘,最终还是要通过RAID控制器来和最底层的物理磁盘打交道。
Linux下的LVM甚至可以对物理磁盘上的一个分区进行卷管理,将这个分区做成一个PV。
卷管理软件就是运行在OS操作系统磁盘控制器驱动程序之上的一层软件程序,它的作用就是实现RAID卡硬件管理磁盘空间所实现不了的灵活功能,比如随时扩容。
为什么卷管理软件就可以随时在线扩容,灵活性这么强呢?首先我们要熟悉一个知识,也就是OS会自带一个卷管理软件层,这个卷管理软件非常简单,它只能管理单个磁盘,而不能将它们组合虚拟成卷,不具有高级卷管理软件的一些灵活功能。OS自带的一些简单VM(卷管理)软件,只会调用总线驱动(一种监视IO总线Plug And Play,即PNP,即插即用),发现硬件之后再挂接对应这个硬件的驱动,然后查询出这个硬件的信息,其中就包括容量,所以我们才会在磁盘管理器中看到一块块的磁盘设备。即从底层向上依次是物理磁盘、磁盘控制器、IO总线、总线驱动、磁盘控制器驱动、卷管理软件程序、OS磁盘管理器中看见的磁盘设备。
而高级卷管理软件是将原本OS自带的简陋的卷管理功能进行了扩展,比如可以对多个磁盘进行组合、再分等。不管是OS单一VM还是高级VM,磁盘在VM这一层处理之后,应该称为卷比较恰当,就算卷只由一块磁盘抽象而成,也不应该再称作磁盘了。因为磁盘这个概念只有对磁盘控制器来说才有意义。
磁盘控制器看待磁盘,真的就是由盘片和磁头组成。而卷管理软件看待磁盘,会认为它是一个线性存储的大仓库,而不管这个仓库用的是什么存储方式,仓库每个房间都有一个地址(LBA逻辑块地址),VM必须知道这些地址一共有多少。它让库管员(磁盘控制器驱动软件)从某一段地址(LBA地址段)存取某些货物(数据),那么库管员就得立即操控他的机器(磁盘控制器)来到各个房间存取货物(数据)。这就是VM的作用。
在底层磁盘扩容之后,磁盘控制器驱动程序会和VM打个招呼:我已经增大了多少容量了,你看着办吧。卷说:“好,你不用管了,专心在那干活吧,我告诉你读写哪个LBA地址的数据你就照我的话办。”这样之后,VM就会直接将等待扩容的卷的容量立即扩大,放入池中备用,对上层应用没有丝毫影响。所以VM可以屏蔽底层的变化。
至于扩容和收缩逻辑卷,对VM来说是小事一桩。但是对于其上的文件系统来说,处理起来就复杂了。所以扩大和收缩卷,需要其上的文件系统来配合,才能不影响应用系统。
分区管理可以看作是一种最简单的卷管理方式,它比LVM等要低级。分区就是将一块磁盘抽象成一个仓库,然后将这个仓库划分成具体的一库区、二库区等。因为一个仓库太大的话,对用户来说很不方便。比如一块100GB的磁盘,如果只分一个区,就显得很不便于管理。有两种方法解决这个问题:
(1)可以用低级VM管理软件,比如Windows自带的磁盘管理器,对这个磁盘进行分区;
(2)用高级VM管理软件,将这个盘做成卷,然后灵活地进行划分逻辑卷。
这两种方法可以达到将一个仓库逻辑划分成多个仓库的效果。所不同的是分区管理这种低级卷管理方式,只能针对单个磁盘进行再划分,而不能将磁盘合并再划分。
思考: 对于低级VM的分区管理来说,必须有一个东西来记录分区信息,如第一仓库区是整个仓库的哪些房间,从第几个房间开始到第几个结束是第二仓库区等这些信息。这样,每次OS启动的时候,VM通过读取这些信息就可以判断这个仓库一共有几个逻辑区域,从而在“我的电脑”中显示出逻辑磁盘列表。那么怎么保存这个分区信息呢?
毫无疑问,它不能保存在内存里,更不能保存在CPU里,它只能保存在磁盘上。分区信息被保存在分区表中,分区表位于磁盘0磁道0磁头的0号扇区上,也就是LBA1这个地址的扇区上。这个扇区又叫做MBR,即主引导记录。MBR扇区不仅仅保存分区表,它还保存了BIOS跳转时所需要执行的第一句指令代码,所以才叫做主引导记录。
BIOS代码都是固定的,它每次必定要执行LBA1扇区上的代码。如果修改BIOS,让它执行LBA100扇区的代码,也可以,完全可以。但是现在的BIOS都是执行LBA1处的代码,没人去改变。而新出的规范EFI将要取代BIOS,并且在安腾机上已经使用了,一些苹果笔记本也开始使用EFI作为BIOS的替代。在EFI中可以灵活定制这些选项,比如从哪里启动,不仅可以选择设备,还可以选择设备上的具体地址。
MBR中除了包含启动指令代码,还包含分区表。通常启动时,程序都会跳转到活动分区去读取代码做OS的启动,所以必须有一个活动分区。这在分区工具中可以设置。
高级卷管理软件在划分了逻辑卷之后,一定要记录逻辑卷是怎么划分的,比如LVM就需要记录PV的数量和信息、PP的大小、起始位置及LV的数量和信息等。这些信息都要保存在磁盘上,所以也要有一个数据结构来存储。这个数据结构,LVM使用VGDA(Volume Group Descriptor Area)。每次启动系统,VM就是通过读取这些数据来判断目前的卷情况并挂载LV的。VGDA的大致结构示意图如图5-74所示。

图5-74 VGDA示意图
不管是MBR中的分区表,还是VGDA9数据结构,一旦这些信息丢失,逻辑卷信息就会丢失,整个系统的数据就不能被访问。
低级VM在给磁盘分区的时候,会更新MBR中的分区表;高级VM做逻辑卷的时候,同样也会更新VGDA中的数据。其实高级VM初始化一组新磁盘的时候,并没有抛弃MBR。因为它们除了写入VGDA信息之外,也要更新MBR扇区中的分区表,将用于启动基本操作系统的代码单独存放到一个小分区中,并标明分区类型为bootable类型,证明这个分区是用于在卷管理模块还没有加载之前启动操作系统的。并将磁盘所有剩余容量划分到一个分区中,并标明这个分区的类型,如AIX类型。
在安装Linux的时候,必须单独划分一个/boot分区,这个分区就是用于启动基本操作系统用的,100MB大小足矣。启动操作系统所必需的代码都放在这个分区。同样AIX系统也要保留一个分区用来启动最基本的操作系统代码。这也是AIX在进行了Mirrorvg镜像操作之后,需要执行BOSboot命令来写入boot分区的内容的原因,因为boot分区没有参与VM管理。这个启动分区是不能做到VM中的,因为VM代码不是在BIOS将控制交给OS的时候一开始就执行的。
总之,高级VM没有抛弃MBR分区的解决方案,而是在MBR基础上,又增加了类似VGDA这种更加灵活的数据结构来动态管理磁盘。
高级VM软件一般均带有软RAID功能,可以实现逻辑卷之间的镜像。更有甚者,有些VM甚至实现了类似RAID 0的条带化。在卷的级别条带化,达到在物理盘级别条带化同样的目的。但是如果磁盘已经被硬件RAID控制器条带化过了,并且这些LUN是在一个RAID Group中,那么VM再来条带化一下子不但没有必要,而且可能二次条带化会将效果抵消。
Windows的动态磁盘VM还可以以纯软件方式实现RAID 5,所有计算都靠CPU,所以也就注定了它比硬件RAID更灵活,但在高系统负载的情况下,它相比硬件RAID来说速度和性能稍差。
VxVM是Veritas公司开发的一个高级卷管理软件,支持RAID 0、RAID 1、RAID 01和RAID 5四种软RAID模式,支持动态扩大和缩小卷容量。
下面的例子是在一个UNIX系统中对4块磁盘做卷管理的案例。所有命令均在UNIX的Shell下执行。
磁盘组就是将所有磁盘作为一个大的资源池,卷将在这个池中产生。
首先,初始化硬盘。
■ vxdisksetup –i disk1
■ vxdisksetup –i disk2
■ vxdisksetup –i disk3
■ vxdisksetup –i disk4
然后创建一个名为“DataDG”的磁盘组,该磁盘组包含了disk1、disk2、disk3和disk4四个磁盘。
■ vxdg init DataDG disk1 disk2 disk3 disk4
除了这种方法,用户还可以用以下方法来创建磁盘组。
■ vxdg init DataDG DataDG01=disk1(创建一个只包含disk1的磁盘组)
■ vxdg –g DataDG adddisk DataDG02=disk2(将disk2加入到该磁盘组)
■ vxdg –g DataDG adddisk DataDG03=disk3(将disk3加入到该磁盘组)
■ vxdg –g DataDG adddisk DataDG03=disk4(将disk4加入到该磁盘组)
如果用户在所需磁盘空间不足,需要扩容的时候,利用添加磁盘到磁盘组的方法,就可以在不破坏现有环境的情况下扩大系统的容量。
创建卷必须指明在哪个磁盘组下面创建,最常用的方法如下:
■ vxassist –g DataDG make DataVolA 5g
该命令将在DataDG磁盘组上创建名为“DataVolA”的卷,卷的大小是5GB。
如果用户希望该卷只创建在disk1和disk2上面,不占用disk3和disk4的空间,那么可以执行下列命令。
■ vxassist –g DataDG make DataVolA 5g disk1 disk2
创建一个5GB大小的条带卷(RAID 0)。
■ vxassist –g DataDG make DataVolB 5g layout=stripe
这样就在DataDG磁盘组上面建立了一个名为“DataVolB”的5GB大小的条带卷。
提示: 4块物理磁盘中,只有5GB的空间是条带化的,剩余的空间还是常规的磁盘空间。为什么呢?条带化RAID 0不是需要至少两块物理硬盘么?这就是卷管理软件的优越性了。我们上文提过,卷管理软件将物理磁盘划分为PP和LV,所以有了更加细粒度的存储单位,条带化可以在这些LV之间进行,而其他LV不受影响。
创建RAID 5格式的卷。
■ vxassist –g DataDG make DataVolC 5g layout=RAID 5
注意: RAID 5至少需要3块盘,否则不能成功。因为两块盘的RAID 5,还不如做RAID 1。但是3块盘的RAID 5不能获得并发IO性能。
创建镜像卷(RAID 1)。
■ vxassist –g DataDG make DataVolD 5g layout=mirror
创建RAID 10卷。
■ vxdg init RAID 10dg disk1 disk2 disk3 disk4
创建磁盘组
■ vxassist –g RAID 10dg RAID 10vol 5g layout=mirror-stripe
创建RAID 01卷。
■ vxdg init RAID 01dg disk1 disk2 disk3 disk4
创建磁盘组。
■ vxassist –g RAID 01dg RAID 01vol 5g layout= stripe-mirror
■ mkfs –F vxfs /dev/vx/rdsk/DataDG/DataVolA
■ mount –F vxfs /dev/vx/dsk/DataDG/DataVolA /mnt
以上例子将卷DataVolA格式化成VxFS(Veritas公司的文件系统)格式,然后挂载于/mnt目录下,执行命令cd /mnt之后,就可以读写这个卷的内容了。
将卷空间增加到10GB。
■ vxassist -g DataDG growto DataVolA 10G
更改之后,卷的容量将会变成10GB。或者用vxresize命令。
■ vxresize -g DataDG DatavolA 10G
将卷容量增加10GB。
■ vxassist -g DataDG growby DataVolA 10G
或者用vxresize命令:
■ vxresize -g DataDG DatavolA +10G
这样,更新之后卷的容量将在原来的基础上增加10GB大小。
卷扩容之后,只是在卷的末尾增加了一块多余空间。这块空间如果没有文件系统的管理就无法存放文件,所以必须让文件系统将这块多余的空间利用起来。
■ fsadm -F vxfs -b 10240000 –r dev/vx/rdsk/DataDG/DataVolA /mnt
如果决定将某个卷缩小以省出更多空间,则在缩小卷空间之前,必须缩小文件系统的空间。也就是说,被裁掉的卷空间上存放的数据,需要转移到卷剩余的空间上存放,所以剩余空间必须足够,以便容纳被裁掉空间中的数据。
■ fsadm -F vxfs -b 5120000 –r dev/vx/rdsk/DataDG/DataVolA /mnt
以上命令将这个卷上的文件系统缩小至5GB大小。剩余的5GB没有数据,可以被裁剪掉。
在缩小了文件系统之后,卷容量方可缩小。
■ vxassist -g DataDG shrinkto DataVolA 5G
■ vxresize -g DataDG DataVolA 5G
上面的两个命令均可以使DataVolA卷的容量变为5GB。
■ vxassist -g DataDG shrinkby DataVolA 5G
■ vxresize -g DataDG DataVolA -5G
上面的两个命令均可以使DataVolA卷的容量在原来的基础上缩减5GB。
若想从磁盘组中移除一块或者几块物理磁盘,则必须先将待移除物理磁盘上的数据转移到磁盘组中的其他物理磁盘的剩余空间中,这个动作通过下面的命令完成。
■ vxevac -g DataDG DataDG04 DataDG03
上面的命令将disk4中的数据转移到disk3上。除了容量改变之外,不会影响卷的其他信息。
■ vxdg -g DataDG rmdisk disk4
上面的命令将已经没有数据的disk4物理磁盘从磁盘组DataDG中移除(逻辑移除)。
■ vxdiskunsetup -C Disk4
上面的命令将disk4物理磁盘从整个VxVM管理模块中注销。
话说这一天,老道闲来无事,在后山溜达。他走到了武当的粮库门口,发现这里堵了一大帮人。老道上前一问,原来这些人都是各个院来领取粮食的。只见他们一拥而上,进入仓库就各自找自己的房间去搬粮食。老道一看,怎么这么乱呢?就不能有个顺序么?
他向其中一个小道打听了一下,这才知道,造成这种乱七八糟进入粮库搬粮食局面的原因,是因为当初没有好好规划仓库。上个月,各个院从山下各自运了粮食上来,当时的政策是大家各自进入仓库,自己找房间放自己的粮食,自己找了哪些房间放粮食,自己记住了。到取粮食的时候,大家根据自己记录的房间来进入取粮。这个政策看似没什么可非议的,实则不然。如今山下粮食供应紧张,造成大家各顾各的,没有顺序,岂能不乱?老道进入粮仓一看,眼前一片狼藉!土豆、西红柿洒落得满地都是。这间房放这样,那间房放那样,就不能顺序地堆放粮食蔬菜?成何体统!!
提示: 在早期的计算机系统中,每个程序都必须自己管理磁盘,在磁盘中放自己的数据,程序需要直接和磁盘控制器打交道。有多少个程序要利用磁盘,就有多少个和磁盘交互的驱动接口。
老道摇了摇头,得想个办法彻底解决这个问题。老道回到了书房,闭目思索。首先大家不能都堵在门口,那么必须让他们排起队来。其次,每个人各顾各,自己记录自己用了哪间房子,一个是浪费,另一个是容易造成冲突。一旦某个人记错了,就会影响其他人。那么就应该只让一个人记录所有人的信息,他自己不会和自己冲突。同样这个人也要充当一个门卫的作用,接待来取粮或者送粮的人,让他们按一定的顺序来运作。
最终决定就应该是这样的:找一个人,这个人的职责就是接待来取粮或者送粮的人,把要取的或者要送的粮食的名称和数量等信息先登记在这个人的一个本子上,然后由这个人来合理地选择仓库中的房间,存放或提取登记在案的粮食,而且提取或放入粮食之后要将本子上的记录更新,以便下次备查。嗯,这么做就好多了,哈哈哈哈!这天晚上的北斗七星,光芒格外耀眼。
第二天,老道亲自挑选了一位才思敏捷、内向稳重、善于思考的道士来担任这个重要的角色。让他和库管员一起完成管理粮库的工作,给他起了一个职称,叫做理货员。并且将自己的想法告诉了这位道士,让他当晚就考虑出一套符合这个思想的方法,还可以做出改进意见。
就这样,又过了一晚。第三天,这位道士上任了。一大早,张老道就在暗中观察。这时候,一个送粮食的人来了,他带了1024斤土豆和512斤白菜。这人还是按老习惯,上来就往仓库闯。小道士截住了他:“道长且慢!请问您送的是什么蔬菜?”那人道:“土豆和白菜!”小道士又道:“土豆多少斤?”答曰:“土豆1024斤。”(上面这个过程就是应用程序和FS的API交互的过程)。小道士笑道:“道长尽可放心将土豆交于我,我自当为您找房间存放。”然后小道士到仓库中找了两个空房间,每个房间放了512斤土豆。并在本子上记录:“土豆1024斤房间1-2。”接着他就命令库管员来搬运货物到相应的房间。
道士给每个库区都预备了一个记录本。小道士不关心具体房间到底在仓库哪里,怎么走才能达到,这些事情统统由库管员来协调。小道士同样也不关心来送货物的人到底送的是什么货物。如果送粮的人告诉他,请给我存放rubbish 1000斤,道士眼都不眨照样给他存放。一旦仓库的房间都满了,小道长再次命令库管员搬运货物的时候,库管员就会告诉他,已经没有房间了。那么道长就告诉来存放货物的人:“对不起,空间不足。”
用同样的方法,小道士将那人的白菜,也放到了一间房中,记录下:“白菜512斤 房间3”。然后向那人说到:“这位道长,您下次来取的时候,直接向我说要某厨房存放的土豆多少斤就可以了,我会帮您找到并取出。”那人非常满意地离去了。接着又有很多人也来送取冬瓜、南瓜、西瓜、大米、面粉等粮食蔬菜,小道士一一对应,有条有理。小道士也专门给自己在每个库区中预留了几间房,用于存放他那一本本厚厚的记录。老道一旁看了,频频点头,“嗯,前途无量,前途无量啊,啊哈哈哈哈哈!!!”
过了几天,张真人又来探查。此时只见有个人一下送来10 000斤大米。小道长开始只是表示吃惊,并没有多想,仍旧按照老办法,记录:“大米10 000斤,房间4-4096”。接着又来了一位要存放65 535斤小麦的。这下可苦了小道士了,把他累得够呛。随着全国粮食大丰收,存粮数量动辄上万斤。这让小道士苦不堪言,他决定思考一种解决方法。第二天,小道长将每8个房间划分为一个逻辑房间,称作“簇”。第一簇对应房间1、2、3、4、5、6、7、8,第二簇对应房间9、10、11、12、13、14、15、16,依此类推。这样道士记录的数字量就是原来的八分之一了。比如4000斤粮食,只需记录“簇1”就可以了。老道心中暗想,“嗯,不错,我没看错人!”这一年,因为大丰收,粮食降价了。农民丰产不丰收,很多农民打算第二年不种粮了,改做其他小生意。
第二年,果然不出张老道所料,全国粮食大减产,价格飞涨,全面进入恐慌阶段。张真人悬壶济世,开仓放粮,平息物价。这一举动受到了老百姓的称赞和感激,但也招致了一小部分奸商的忌恨。
放粮消息宣布之后,山下老百姓都排队来武当买粮。这可忙坏了理货员道士,连续几天没休息,给老百姓取粮食。一个月之后,武当粮库存粮已经所剩无几,张老道和众院道士每天省吃俭用,为的是给老百姓多留点存粮。
大恐慌的一年,终于熬过去了。农民一看粮食价格那么高,第三年又都准备种粮了。不出意料,这一年粮食又得丰收!张老道提前考虑他的粮库在这一年的使用问题了,他叫来理货员道士,让他回去考虑一个问题:经过了去年的折腾,仓库中的存货是零零散散,乱七八糟,为了准备这一年大量粮食涌入仓库,必须解决这个问题,让他回去考虑解决办法。其实张老道早就在心里盘算出了解决办法了。
第二天,理货员趁人少的时候,就命令库管员:“请帮我把房间XXXX的货物移动到房间XXXX处,请帮我把房间XXX的货物移动到房间XXX处……。”
这可累坏了库管员。但是经过几个时辰的整理之后,仓库里的货物重新变得连续,井井有条。老道称赞说:“不错!继续努力!”
这天晚上,小道长也没闲着,他继续思考,今天是有时间整理货物,如果一旦遇到忙的时候,没有时间整理货物,那麻烦就大了,得想一种一劳永逸的办法。有些人来送完粮食之后,第二天就来取了,这个真是头疼了。因为我都按照顺序将每个人的粮食连续存放到各个簇中,他一下取走了,对应的簇就空了。如果再有人来,他带的货物数量如果这个空簇能存下还好,可以接着用。如果存不下呢?还得找新的连续空簇来存放。如果这种情况出现太多,那么整个仓库就是千疮百孔,大的放不下,小的放下了又浪费空间……真头疼。他冥思苦想,最后终于想出一个办法。
一早仓库还没有开门的时候,小道长就来了,他把所有记录本都拿了出来,进行修改。他原本对每个来送货的人,都只用一条简单记录来描述它,描述中包含3个字段:名称、大小和存放位置。比如冬瓜10 000斤 簇1-3。此时仓库中,虽然总空余空间远远大于10 000斤的量,但是已经没有能连续地放入10 000斤大小的簇空间,那么这个货物就不能被放入仓库,而这是不能容忍的一种浪费。有一个办法,就是上面说过的,找空闲时间来整理仓库,整理出连续的空间来。这次小道长想出了另一个方法,就是将货物分开存放,并不一定非要连续存放在仓库。因为仓库已经被逻辑分割成一簇(8个房间)为最小单位存放货物。那么就可以存在类似这样的描述方式:冬瓜10 000斤 簇2、6、19。也就是说这10 000斤的冬瓜是分别被按顺序存放在仓库的2号簇、6号簇和19号簇中的。取出的时候,需要先去2号取出货物,再跨过3个簇去6号,再跨过13个簇去19号。都取出后再交给提货人。这样确实慢了点,但是完美地解决了空间浪费的问题。
粮食大丰收果然又被张老道猜中了,这次小道长是应对自如,一丝不乱。老道啧啧称赞!但是老道却从小道士的记录中,又看出了一些问题,他告诉小道士,要继续思考更好的解决办法。小道士心很灵,他知道这个方法确实解决了问题,但是有缺陷,会有后患,只不过现在的环境并没有显示出来。这天晚上,小道在仓库睡觉,没有回去。
提示: 看着他那些记录,只见上面一条一条、一行一行的,却也比较有条理。但是仔细一看发现,每一条记录的最后一个字段,也就是描述货物存放在哪些簇的那个字段,非常凌乱,因为每个人送来的货物数量不一样,那么就注定这个字段长短不一,显得非常乱。现在记录不是很多,但记录一旦增多,每次查询的时候就很不好办。而且要找一个未被占用的簇,需要把所有已经被占用的全找出来,然后才去选择一个未被占用的簇,分配给新的货物存放。这个过程是非常耗时间的,货物少了还可以,货物一多,那可就费劲了。“嗯,张真人让我继续思考,确实是有道理的,这两个隐患,确实是致命的,尤其是第二个。得继续找新方法。”
提示: 小道士继续思考。第一个问题,要想解决长短不一的毛病,最简单的就是给他一个定长的描述字,这仿佛是不可能的,有的需要1个簇就够了,有的却需要10个甚至100个,如果把这需要10个簇的和需要1个簇的,都用1个簇来描述,那么确实非常漂亮了,记录会非常工整。
想到这里,小道士累了,想出去走走。他溜达到一个路口,看见路口上有路标牌,上面写着:“去会客厅请走左边,去习武观请走右边。”小道士顺着路标指向,走了右边,然后又遇到一个路标:“去习武观请走左边,下山请走右边。”道士走了左边,最终来到了习武观。他看着习武观正中央的那个醒目的“道”字,忽然眼前一亮!
他迅速原路返回到粮库,拿出记录本,将其中一条记录改为:“冬瓜10 000斤 首簇1”。每条记录都改成这种形式,也就是只描述这个货物占用的第一个簇的号码,这样完美解决了记录长短不一的问题,那么后续的簇呢?只知道首簇,剩余的不知道,一样不能全部把货物取出。
所以小道士参照路标的形式,既然知道了首簇号,那么如果找到首簇,再在首簇处作一个标记,写明下一个簇是多少号,然后找到下一个簇取货,然后再参照这个簇处的路标,到下下个簇处接着取货,依此类推,如果本簇就是这批货物的最后一簇,那么就标识:“结束,无下一簇”。比如:“冬瓜10 000斤 首簇1”这个例子,先把4096斤冬瓜放到簇1中,然后在簇1的门上贴上一个标签:“簇10”,这就表明下一簇是10号簇。继续向10号簇中存入4096斤冬瓜,此时还剩808斤冬瓜没放入,还需要一个路标,于是在10号簇的门上再贴一个标签:“90号”。然后去90号簇放入剩下的808斤冬瓜。
第二天,张老道继续来视察。老道一看他的记录,不由地一惊!“一个晚上就想到了这种绝妙方法。嗯,此人大有前途!”老道频频点头称赞。然后老道进仓库查看,一看有些簇的门上,贴着标签,老道立即明白了小道长的做法,对小道说:“孩子,不错,但是还需要再改进!”
小道心里盘算,“嗯,这个方法是解决了第一个问题,但是每个簇门上都贴一个标签,这样是不太像样。而且寻找未被占用的簇的效率还是那么低,还是需要把所有已经占用的簇找出来,再比对选出没有使用的空簇。而且我这么一弄,找空簇的效率比原来还差了,因为原来已经使用的簇都会被记录在货物描述中的字段中,现在把这个字段缩减成一个字了,这样每次找寻的时候,还得去仓库中实际一个门一个门地去抄下已经使用的簇,还不如直接在本子上找来得快。这个问题得解决!”
思考: 既然要拿掉贴在门上的标签,那么就必须找另外一个地方存放标签,所以只能存放到我的记录本上。可是各个簇的路标我都记录在本子上,用一个什么数据结构好呢?货物描述那三个字段肯定不能再修改了,那样已经很完美了,不能破坏它。那么就需要再自己定义一个结构来存放这些路标之间的关系,而且每个货物的路标还不能混淆,混了就惨了。他在纸上写写画画,不知不觉把整个仓库的簇画出来了,从第一个簇,到最后一个簇,都用一个方格标识,然后他参照“冬瓜,10000斤,首簇1”这个例子,下一簇是簇10,那么他在簇1的格子上写上了“簇10”,然后他找到第10个格子,也就是代表簇10的格子,在簇10格子里面写上“簇90”,也就是10号簇的下一簇路标。然后继续找到90号簇,此时他在这个格子里写上“结束”。接着他又举了几个例子,分别画了上去。就这么逐渐睡着了。
第二天早晨,小道士迷迷糊糊地起来了,只见张道长已经在他的面前,带着赞许的笑容。“孩子,你累了,不错不错,你终于把所有问题都解决了啊!”张老道摸着小道士的头,称赞地说道。小道士还不知道是怎么回事呢,他告诉张老道说,他还没想出来呢。老道大笑说:“哈哈哈哈,你看看你画在纸上的图,这不是已经解决了么?哈哈哈哈哈。”说完老道扬长而去。
小道士一头雾水,看着那张画,这才想起了昨晚的思考。“对啊,这张图不就行了么?这就是我所要找的数据结构啊!”接着,小道士把图重新画了一张,工工整整地夹在了记录本里面。这时,来了一个取货的人,他告诉小道士说:“二库区,南瓜,10000斤。”道士说:“稍等。”然后立即查询二库区的记录本,找到南瓜的记录,发现首簇是128。然后立即到那张图上找到第128号簇所在的格子,发现上面写的是“簇168”。继续找到第168号格子,上面写的是“簇2006”。立即找到第2006个格子,只见上面写的是“结束”。然后他通知库管员:“请将第128、168、2006三个簇的货物提取出来给我。”不一会儿,货物到了,交货签字。小道士恍然大悟,“太完美了!!”
紧接着,又来了一个存货的人,他有西瓜500斤要存放到1库区。小道士立即查看那张图,一目了然。只要格子上没有写字的就是空簇,就可以用来存放货物。所以道士立即找到一个空着的50号簇来存放这500斤西瓜。存放完毕之后,在对应的这个格子上写上“结束”,因为500斤的数量一个房间就够了,更不用说一个簇了(最多8个房间)。接着也在1库区的记录本上增加一条记录“西瓜500斤 首簇50”。
道士发现,第二个问题也就是查找未被使用的簇的问题,自从有了这张图,就自然解决了。道士非常兴奋,同时也佩服张真人,是他引导着自己一步一步解决问题的。
随着仓库业务的不断成熟,小道士的技能越来越熟练,他开始考虑描述货物的三个字段:名称、数量、存放的第一个簇。随着国民生产力水平不断提高,各种层出不穷的产品被生产出来,它们有些具有一些奇特的属性。所以小道士准备增加字段来表述一件货物更多的属性,比如送货时间、只读、隐藏等各种花哨属性。同时,那张图也不能满足要求了,因为随着生产力发展,仓库每平方米造价越来越低,武当决定扩大仓库容量。这样仓库中所包含的簇数量就大大增加了,甚至成几何数量级增长,所以簇号码越来越大,甚至超过了亿。要记录这么多位的数字,本来那个小格子就写不开了,所以需要增大格子的宽度,以便能写下更多的数字位数。以前每个格子是2字节(16位)长度,现在扩展到了4字节(32位)。而据传江湖上另一位大侠已经将格子的宽度扩展到了128位。
这位小道长姓字名谁?因为当时张真人收留他的时候,发现他身板有点软,不适合练武。但思维敏捷,适合练心法,所以给他一个道号叫做微软。
就这样,仓库又运作了两年。
仓库存储容量不断增加,仓库管理技术方面却并没有什么进步,还是沿袭两年前那一套运作模式。这显然已经不适应现代仓库了,所以造成入库等待、处理速度逐渐变慢等一系列的问题。张真人决定跟上时代,要研究出一套新的仓库运作模式,并且定义出一个规范,让全天下的仓库都沿袭这个规范来运作。张老道先仔细考察了微软道士的运作模式,然后根据现代仓库管理的特点,提出了一系列的解决方案。
现代仓库管理要求入库出库速度快,由于在仓库硬件方面提高很快,有了更加新式的传送带和机器人等机器,所以大大提高了操作简化度,减轻了库管员的负担。库管员只需要阅读机器的随机手册(驱动程序)便可以轻松地完成操作。与此同时,对于理货员这块技术并没有什么新的突破,因为理货这块主要靠好的算法,并不需要硬件支持,除了那些记录本之外。而从仓库中取出记录本的速度,由于库管员操作迅速,所以也不在话下。关键就看理货算法了。这是任何硬件都不能解决的问题。
首先张老道通过观察、记录,发现一般货物就算是存放到不连续的簇中,这些簇往往也是局部连续的,比如1、2、3、5、6、7、100、101、102,其中1、2、3就是局部连续,5、6、7也是,100、101、102也是。而不太可能出现一个货物占用了1、56、168、2008簇这种情况。如果此时不是一个簇一个簇地去找路标,而是一段一段地去找,这样会节约很多时间和精力。比如簇段1~3,簇段5~7,簇段100~102。这样就大大简化了路标。还有其他的一些改进方式,如直接将一些小货物存放到它们的描述记录中(驻留文件)。只有描述记录中放不下时,才到仓库其他区域找一些簇来存放,然后记录这些簇段。
微软道士将他的记录本上的信息,称为Metadata,即元数据,也就是用来描述其他数据是怎么组织存放的一种数据。如果记录本丢失,那么纵然仓库中货物完好无损,也无法取出。因为已经不知道货物的组织结构了。
张真人最后把微软道士实现的一共三种仓库运作管理模式,分别叫做FAT16、FAT32和NTFS,并取名为小道藏龙。
后来张老道把这套管理模式移植到了磁盘管理上,这就是轰动武林的所谓“文件系统”。对应仓库来说,送货人送来的每一件货物都称作“文件”。取货时,只要告诉理货员文件名称、所要取出的长度及其他一些选项,那么理货员就可以从仓库中取出这些数据。
在一个没有文件系统的计算机上,如果一个程序要向磁盘上存储一些自己的数据,那么这个程序只能自己调用磁盘控制器驱动(无VM的情况下),或者调用VM提供的接口,对磁盘写数据。而写完数据后,很有可能被其他程序的数据覆盖掉。引入文件系统之后,各个程序之间都通过文件系统接口访问磁盘,所有被写入的数据都称为一个文件,有着自己的名字,是一个实体。而且其他程序写入的数据,不会将其他人的文件数据覆盖掉,因为文件系统会计算并保障这一点。
除此之外,不仅张真人的NTFS文件系统取得了巨大的成功,适应了现代的要求。与此同时,少林的雷牛方丈也创造出了其他的文件系统,比如EXT一代、二代、三代和JFS等文件系统。一时间文件系统思想的光环是照耀江湖!!
那么,有了文件系统之后,整个系统是个什么架构?
图5-75为Windows系统的IO简化流程图。
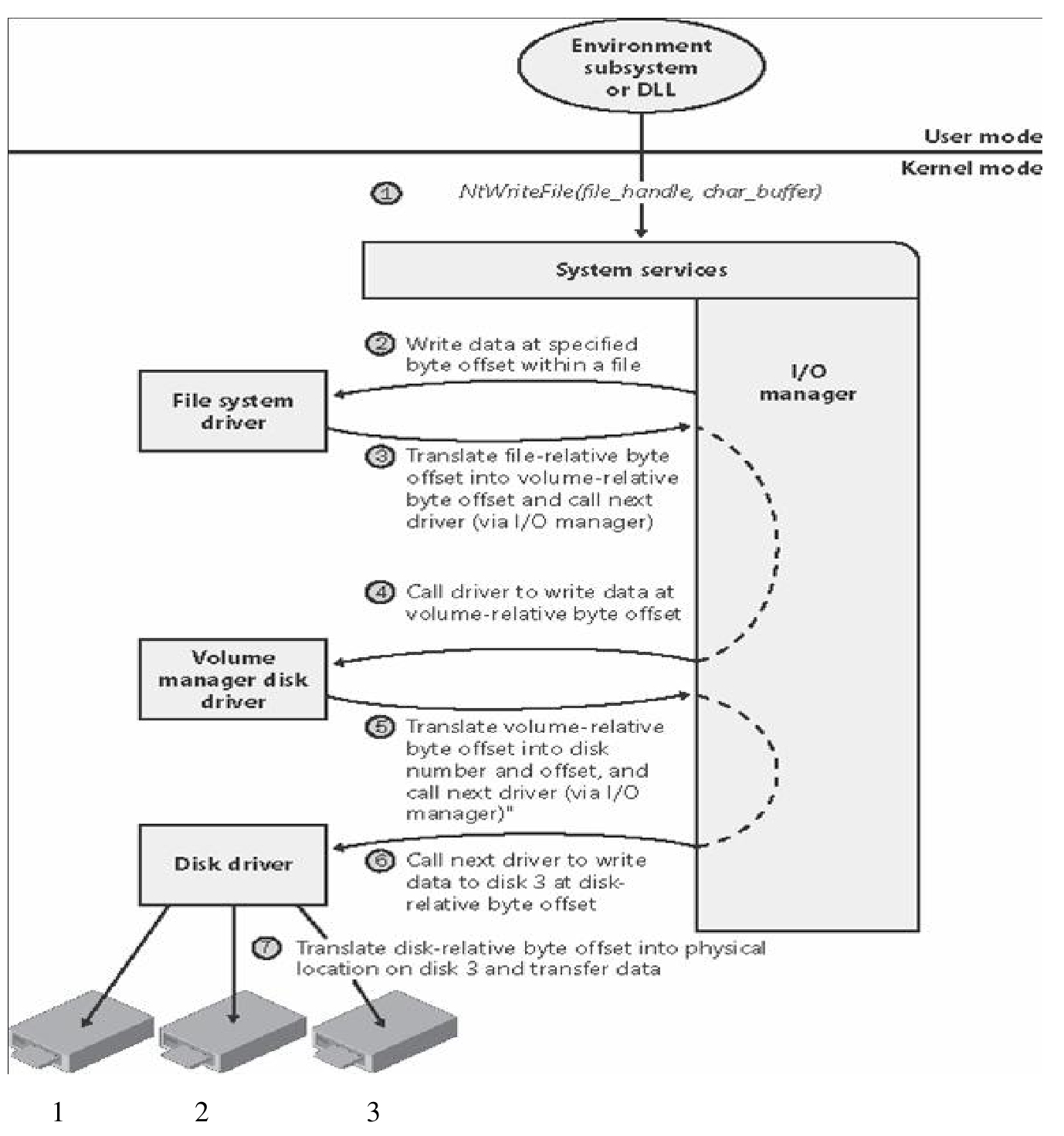
图5-75 Windows系统的IO流程图
图中的IO Manager是操作系统内核的一个模块,专门用来管理IO,并协调文件系统、卷、磁盘驱动程序各个模块之间的运作。整个流程解释如下。
■ 某时刻,某应用程序调用文件系统接口,准备写入某文件从某个字节开始的若干字节。
■ IO Manager最终将这个请求发送给文件系统模块。
■ 文件系统将某个文件对应的逻辑偏移映射成卷的LBA地址偏移。
■ 文件系统向IO Manager请求调用卷管理软件模块的接口。
卷管理软件将卷对应的LBA地址偏移翻译映射成实际物理磁盘对应的LBA地址偏移,并请求调用磁盘控制器驱动程序。
■ IO Manager向磁盘控制器驱动程序请求将对应LBA地址段的数据从内存写入某块物理磁盘。
文件系统的IO包括同步IO、异步IO、阻塞/非阻塞IO和Direct IO。
(1)同步IO: 同步IO是指程序的某一个进程或者线程,如果某时刻调用了同步IO接口,则IO请求发出后,这个进程或者线程必须等待IO路径上的下位程序返回的信号(不管是成功收到数据的信号还是失败的信号)。如果不能立刻收到下位的信号;则一直处于等待状态,不继续执行后续的代码,被操作系统挂起,操作系统继续执行其他的进程或者线程。
而如果在这期间,倘若IO的下位程序尚未得到上位程序请求的数据,此时IO路径上的下位程序又可以选择两种动作方式:第一是如果暂时没有得到上位程序请求的数据,则返回通知通告上位程序数据未收到,而上位程序此时便可以继续执行;第二种动作则是下位程序也等待它自己的下位程序来返回数据,直到数据成功返回,才将数据送给上位程序。前者就是非阻塞IO,后者就是阻塞IO方式。
同步+阻塞IO是彻底的堵死状态,这种情况下,除非这个程序是多线程程序,否则程序就此挂死,失去响应。同理,异步+非阻塞的IO方式则是最松耦合的IO方式。
(2)异步IO: 异步IO请求发出后,操作系统会继续执行本线程或者进程中后续的代码,直到时间片到时或者因其他原因被挂起。异步IO模式下,应用程序的响应速度不会受IO瓶颈的影响,即使这个IO很长时间没有完成。虽然应用程序得不到它要的数据,但不会影响其他功能的执行。
基于这个结果,很多数据库在异步IO的情况下,都会将负责把缓存Flush到磁盘的进程(Oracle中这个进程为DBWR进程)数量设置成比较低的数值,甚至为1。因为在异步IO的情况下,Flush进程不必挂起以等待IO完成,所以即使使用很多的Flush进程,也与使用1个进程效果差不多。
异步IO和非阻塞IO的另一个好处是文件系统不必立刻返回数据,所以可以对上层请求的IO进行优化排队处理,或者批量向下层请求IO,这样就大大提升了系统性能。
(3)Direct IO: 文件系统都有自己的缓存机制,增加缓存就是为了使性能得到优化。而有些应用程序,比如数据库程序,它们有自己的缓存,IO在发出之前已经经过自己的缓存算法优化过了,如果请求IO到达文件系统之后,又被缓存起来进行额外的优化,就是多此一举了,既浪费了时间,又降低了性能。对于文件系统返回的数据,同样也有这个多余的动作。所以文件系统提供了另外的一种接口,就是Direct IO接口。调用这种接口的程序,其IO请求、数据请求以及回送的数据将都不被文件系统缓存,而是直接进入应用程序的缓存,这样就提升了性能。此外,在系统路径上任何一处引入缓存,如果是Write Back模式,都将带来数据一致性的问题。Direct IO绕过了文件系统的缓存,所以降低了数据不一致的风险。
提示: 关于更详尽的系统IO论述,请参考本书后面的章节。