
下载掌阅APP,畅读海量书库
立即打开



磁盘分为软盘和硬盘。将布满磁性粒子的一片圆形软片包裹在一个塑料壳中,中间开孔,以便电机夹住这张软片来旋转,这就是软盘。
将软盘插入驱动器,电机便会带动这张磁片旋转,同时磁头也夹住磁片进行数据读写。软盘和录音带是双胞胎,只不过模样不太一样而已。软盘记录的是数字信号,录音带记录的是模拟信号。软盘上的磁性粒子的磁极,不管是N极还是S极,其磁化强度都是一样的,磁头只要探测到N极,便认为是1,探测到S极,便认为是0,反过来也可以,这就是用0和1来记录的数字信号数据。另外,因为软盘被设计为块式的而不是流式的,所以需要进行扇区划分等操作。
所谓块式,就是指数据分成一块块地存放在介质上,可以直接选择读写某一块数据,定位这个块的速度比较快。所谓流式,就是指数据是连续不断地存放在介质上。就像一首歌,不可能让录音机在磁带上定位到这首歌的某处开始播放,只能定位到某首歌曲的前面或者后面。
模拟磁带,也就是录音带,记录是线性连续的,没有扇区的概念,属于流式记录。在每个流之间可以有一段空隙,以便磁头可以通过快进快速定位到这个位置,但是由于设计的原因,磁带定位的速度远比磁盘慢。但是磁带的设计,从一开始就是为了满足大容量数据存储的需要。如果将缠绕紧密的磁带铺展开来,可以想象它的面积比一张磁盘要大得多,所以存储容量必然也就大于磁盘。现在一盘LTO3的数字磁带可以在1平方分米底面、2厘米高的体积中存放400GB的数据,如果使用压缩技术,可以存放约800GB的数据。而它的价格却比同等容量硬盘的一半还低。
但是磁带绝对不可以作为数据实时存储的介质,因为它不可以定位到某个块,这也决定了磁带只能用来做数据备份。Sun公司的顶级磁带库产品可以达到一台磁带库中存放1万盘磁带,最大可以让32台磁带库级联,从而形成32万盘磁带的大规模磁带库阵列。
而作为本章重点介绍的硬盘技术,不仅存取速度比软盘更快,随着技术发展带来的成本下降,更有取代磁带机成为普及型数据存储的趋势。
硬盘大致由盘片、读写头、马达、底座、电路板等几大项组合而成,如图3-1和图3-2所示。

图3-1 磁盘的构成要件
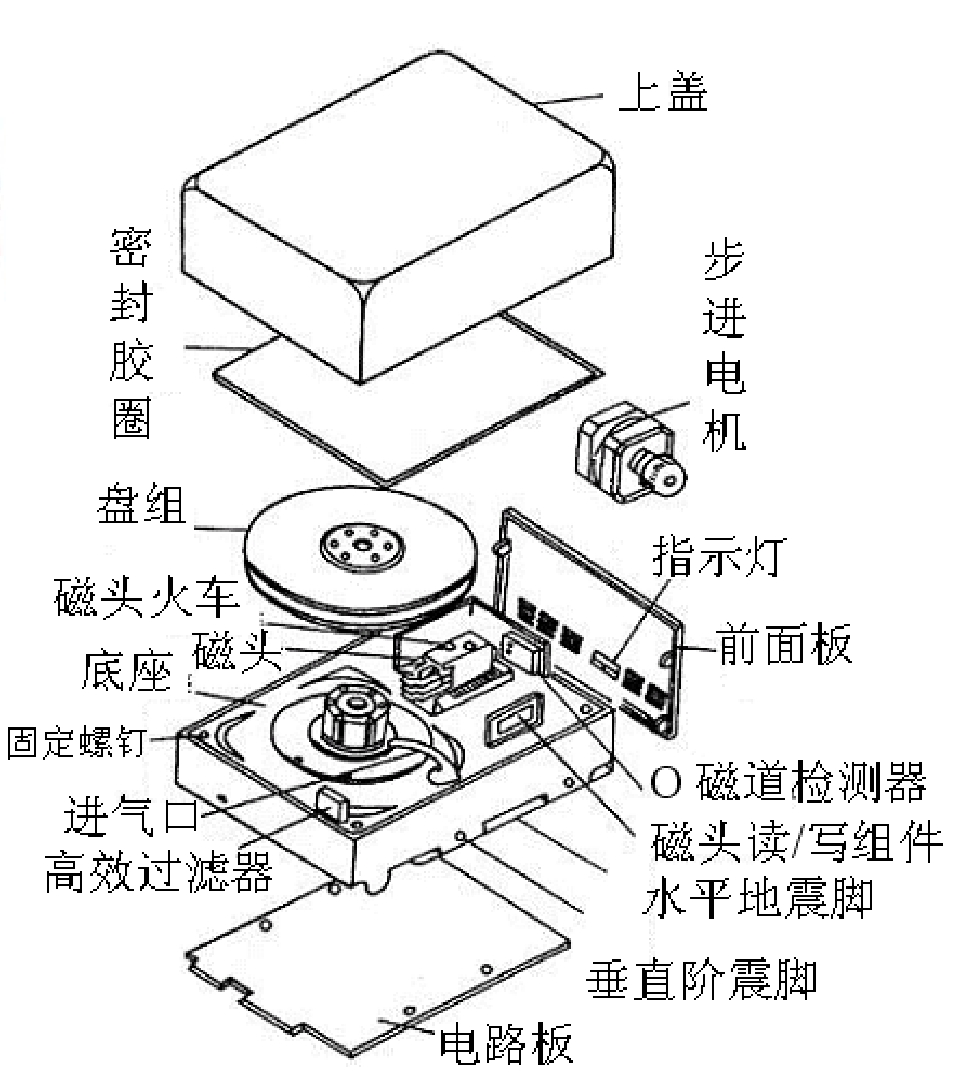
图3-2 磁盘结构图
盘片的基板由金属或玻璃材质制成,为达到高密度、高稳定性的要求,基板要求表面光滑平整,不可有任何瑕疵。然后将磁粉溅镀到基板表面上,最后再涂上保护润滑层。此处要应用两项高科技,一是要制造出不含杂质的极细微的磁粉,二是要将磁粉均匀地溅镀上去。
盘片每面粗计密度为32901120000 b,可见其密度相当高,所以盘片不可有任何污染,全程制造均须在Class 100高洁净度的无尘室内进行,这也是硬盘要求需在无尘室才能拆解维修的原因。因为磁头是利用气流漂浮在盘片上,并没有接触到盘片,因而可以在各轨间高速来回移动,但如果磁头距离盘片太高读取的信号就会太弱,太低又会磨到盘片表面,所以盘片表面必须相当光滑平整,任何异物和尘埃均会使得磁头摩擦到磁面而造成数据永久性损坏。
硬盘的储存原理是将数据用其控制电路通过硬盘读写头(Read Write Head)去改变磁盘表面上极细微的磁性粒子簇的N、S极性来加以储存,所以这几片磁盘相当重要。
磁盘为了储存更多数据,必须将磁性粒子簇溅镀在磁头可定位的范围内,并且磁性粒子制作得越小越好。经过溅镀,磁盘表面上磁粒子密度相当高,而硬盘读写头为了能在磁盘表面高速来回移动读取数据则需漂浮在磁盘表面上,但是不能接触,接触就会造成划伤。磁头如果太高的话读取到的信号就会很弱,无法达到高稳定性的要求,所以要尽可能压低,其飞行高度(Flying Height)非常小(可比喻成要求一架波音747客机,其飞行高度须保持在1米的距离而不可坠毁)。实现这种技术,完全是靠磁盘旋转时,在盘片上空产生气流,利用空气动力学使磁头悬浮于磁片上空。磁头厚度如图3-3所示。

图3-3 磁头厚度示意图
早期的硬盘在每次关机之前需要运行一个被称为Parking的程序,其作用是让磁头回到盘片最内圈的一个不含磁粒子的区域,叫做启停区。硬盘不工作时,磁头停留在启停区,当需要从硬盘读写数据时,磁盘就先开始旋转。旋转速度达到额定速度时,磁头就会因盘片旋转产生的气流抬起来,这时磁头才向盘片中存放数据的区域移动。盘片旋转产生的气流相当强,足以托起磁头,并与盘面保持一个微小的距离。这个距离越小,磁头读写数据的灵敏度就越高,当然对硬盘各部件的要求也就越高。
早期设计的磁盘驱动器可使磁头保持在盘面上方几微米处飞行,稍后的一些设计使磁头在盘面上的飞行高度降到约0.1~0.5mm,现在的水平已经达到0.005~0.01mm,只是人类头发直径的千分之一。气流既能使磁头脱离开盘面,又能使它保持在离盘面足够近的地方,非常紧密地随着磁盘表面呈起伏运动,使磁头飞行处于严格受控状态。磁头必须飞行在盘面上方,而不接触盘面,这种距离可避免擦伤磁性涂层,而更重要的是不让磁性涂层损伤磁头。但是,磁头也不能离盘面太远,否则就不能使盘面达到足够强的磁化,难以读出盘上的数据。
提示: 硬盘驱动器磁头的飞行悬浮高度低、速度快,一旦有小的尘埃进入硬盘密封腔内或者磁头与盘体发生碰撞,就有可能造成数据丢失形成坏块,甚至造成磁头和盘体的损坏。所以,硬盘系统的密封一定要可靠,在非专业条件下绝对不能开启硬盘密封腔,否则灰尘进入后会加速硬盘的损坏。另外,硬盘驱动器磁头的寻道伺服电机多采用音圈式旋转或直线运动步进电机,在伺服跟踪的调节下精确地跟踪盘片的磁道,所以硬盘工作时不要有冲击碰撞,搬动时也要小心轻放。
为了让磁头精确定位到每个磁道,用普通的电机达不到这样的精度,必须用步进电机,利用精确的齿轮组或者音圈,每次旋转可以仅仅使磁头进行微米级的位移。音圈电机则是使用精密缠绕的铜丝,置于磁场之中,通过控制电流的流向和强度,使得磁头臂在磁场作用下作精确的步进。之所以叫做“音圈”,是因为这种方法一开始是用在喇叭的纸盆上的,通过控制电流来控制纸盆的精确振动。
硬盘上的数据是如何组织与管理的呢?硬盘首先在逻辑上被划分为磁道、柱面以及扇区,其结构关系如图3-4所示。
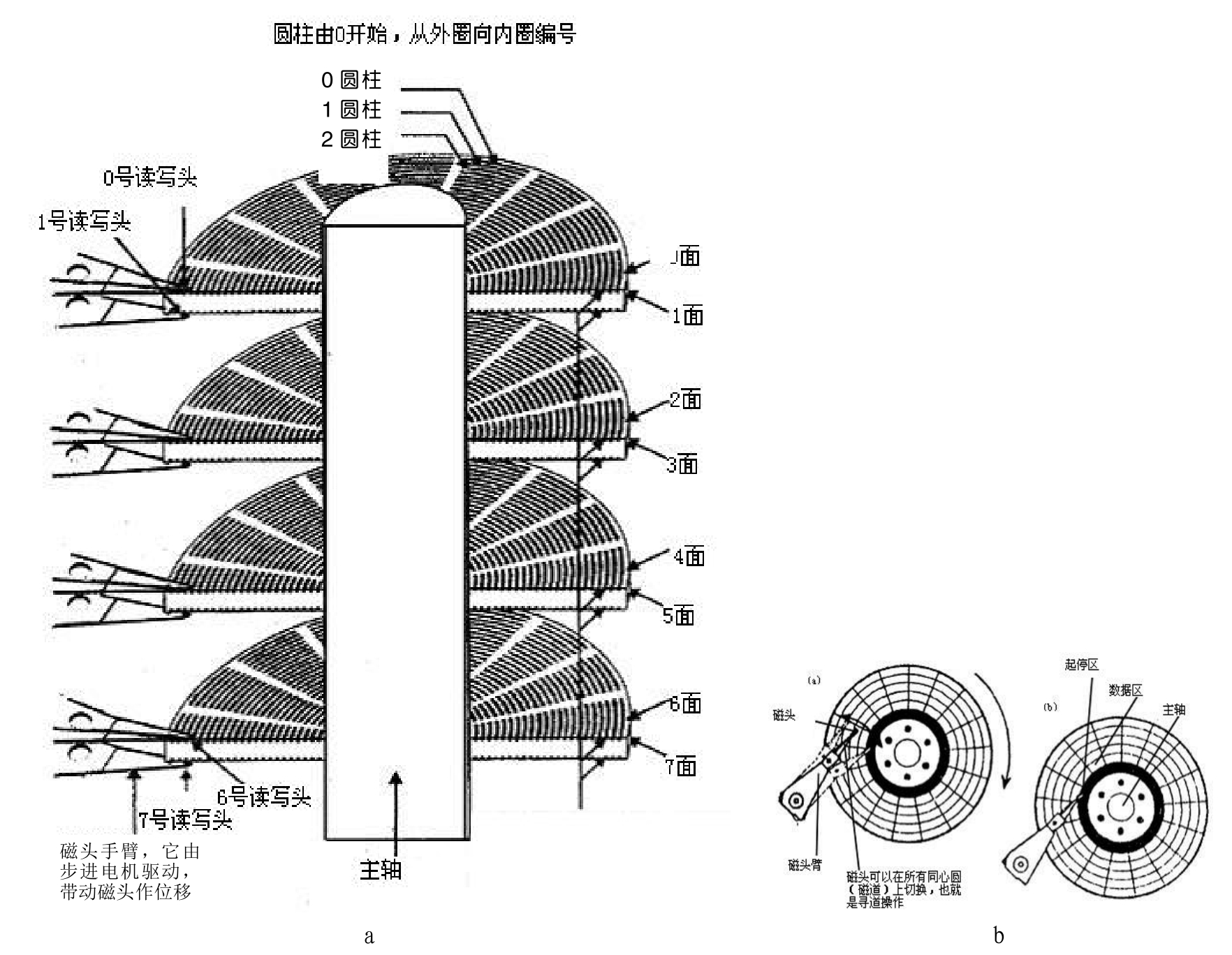
图3-4 柱面和盘片上的磁道
每个盘片的每个面都有一个读写磁头,磁头起初停在盘片的最内圈,即线速度最小的地方。这是一个特殊区域,它不存放任何数据,称为启停区或着陆区(Landing Zone)。启停区外就是数据区。在最外圈,离主轴最远的地方是0磁道,硬盘数据的存放就是从最外圈开始的。
那么,磁头如何找到0磁道的位置呢?从图3.4中可以看到,有一个0磁道检测器,由它来完成硬盘的初始定位。0磁道存放着用于操作系统启动所必需的程序代码,因为PC启动后BIOS程序在加载任何操作系统或其他程序时,总是默认从磁盘的0磁道读取程序代码来运行。
提示: 0磁道是如此重要,以至于很多硬盘仅仅因为0磁道损坏就报废了,这是非常可惜的。
下面对盘面、磁道、柱面和扇区的含义逐一进行介绍。
硬盘的盘片一般用铝合金材料做基片,高速硬盘也有用玻璃做基片的。玻璃基片更容易达到所需的平面度和光洁度,而且有很高的硬度。磁头传动装置是使磁头作径向移动的部件,通常有两种类型的传动装置:一种是齿条传动的步进电机传动装置,另一种是音圈电机传动装置。前者是固定推算的传动定位器,而后者则采用伺服反馈返回到正确的位置上。磁头传动装置以很小的等距离使磁头部件作径向移动,用以变换磁道。
硬盘的每一个盘片都有两个盘面,即上、下盘面。每个盘面都能利用,都可以存储数据,成为有效盘片。每一个这样的有效盘面都有一个盘面号,按从上到下的顺序从0开始依次编号。在硬盘系统中,盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。硬盘的盘片组在2~14片不等,通常有2~3个盘片,故盘面号(磁头号)为0~3或0~5。
磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫做磁道。磁道从最外圈向内圈从0开始顺序编号。硬盘的每一个盘面有300~1024个磁道,新式大容量硬盘每面的磁道数更多。这些同心圆磁道不是连续记录数据,而是被划分成一段段的圆弧,这些圆弧的角速度一样。由于径向长度不一样,所以线速度也不一样,外圈的线速度较内圈的线速度大。在同样的转速下,外圈在相同的时间段里,划过的圆弧长度要比内圈划过的圆弧长度大,因此外圈数据的读写要比内圈快。
每段圆弧叫做一个扇区,扇区从1开始编号,每个扇区中的数据作为一个单元同时读出或写入,是读写的最小单位。不可能发生读写半个或者四分之一个这种小于一个扇区的情况,因为磁头只能定位到某个扇区的开头或者结尾,而不能在扇区内部定位。所以,一个扇区内部的数据,是连续流式记录的。一个标准的3.5英寸硬盘盘面通常有几百到几千条磁道。磁道是肉眼看不见的,只是盘面上以特殊形式磁化了的一些磁化区。划分磁道和扇区的过程,叫做低级格式化,通常在硬盘出厂的时候就已经格式化完毕了。相对于低级格式化来说,高级格式化指的是对磁盘上所存储的数据进行文件系统的标记,而不是对扇区和磁道进行磁化标记。
所有盘面上的同一磁道,在竖直方向上构成一个圆柱,通常称做柱面。每个圆柱上的磁头由上而下从0开始编号。数据的读写按柱面进行,即磁头读写数据时首先在同一柱面内从0磁头开始进行操作,依次向下在同一柱面的不同盘面(即磁头)上进行操作。只有在同一柱面所有的磁头全部读写完毕后磁头才转移到下一柱面,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换,即寻道。
电子切换相当快,比使用机械将磁头向邻近磁道移动要快得多,所以数据的读写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写。一个柱面写满后,才移到下一个柱面开始写数据,这样可以减少寻道的频繁度。读写数据也按照这种方式进行,这样就提高了硬盘的读写效率。
一块硬盘驱动器的圆柱数或每个盘面的磁道数既取决于每条磁道的宽窄(也与磁头的大小有关),也取决于定位机构所决定的磁道间步距的大小。如果能将磁头做得足够精细,定位距离足够小,那么就会获得更高的磁道数和存储容量。如果磁头太大,则磁道数就要降低以容纳这个磁头,这样磁道与磁道之间的磁粉将无法利用,浪费得太多。如果能将磁头做成单个原子的精度,那么存储技术就会发生革命性的质变。
提示: 利用原子探针来移动物质表面的原子成特定形状,这种技术早已实现。如果能将这种技术应用到数据存储领域,则存储容量和速度将会以几何倍数上升。
将每个环形磁道等距离切割,形成等长度的圆弧,每个圆弧就是一个扇区。划分扇区的目的是为了使数据存储更加条理化,就像一个大仓库要划分更多的房间一样。每个扇区可以存放512B的数据和一些其他信息。一个扇区有两个主要部分:存储数据地点的标识符和存储数据的数据段,如图3-5所示。
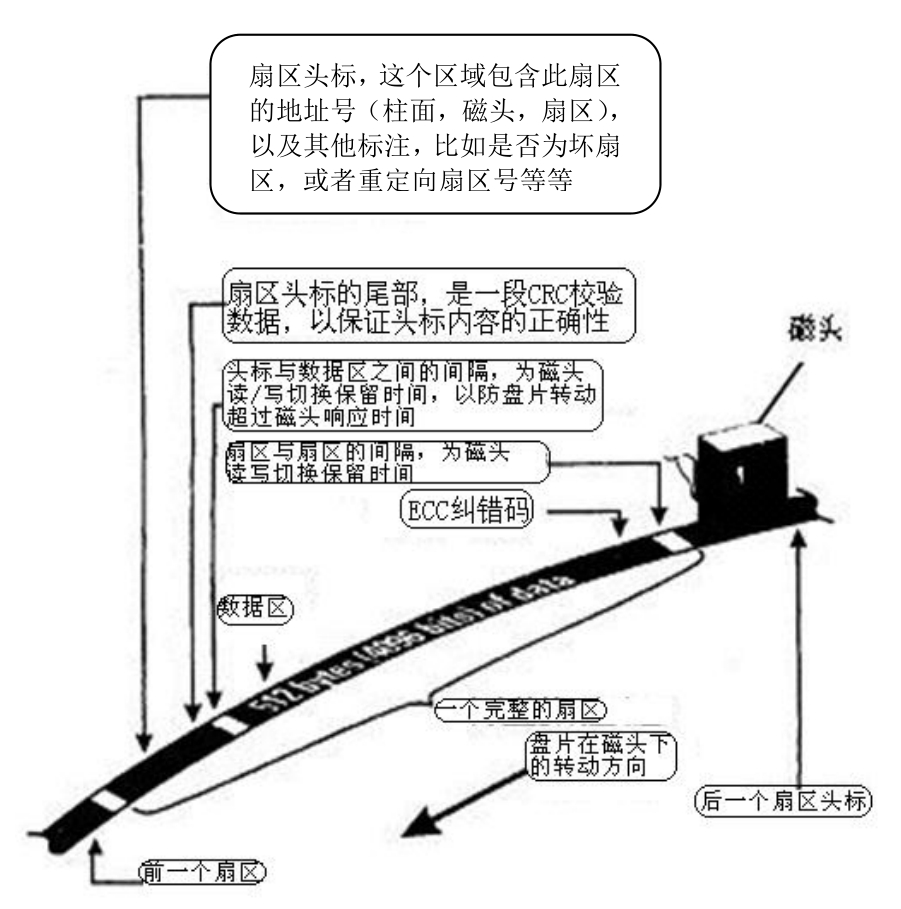
图3-5 扇区示意图
■ 扇区头标包括组成扇区三级地址的三个数字。
■ 扇区所在的柱面(磁道)。
■ 磁头编号。
■ 扇区在磁道上的位置,即扇区号。
■ 柱面(Cylinder)、磁头(Header)和扇区(Sector)三者简称CHS,所以扇区的地址又称为CHS地址。
磁头通过读取当前扇区的头标中的CHS地址,就可以知道当前是处于盘片上的哪个位置,比如是内圈还是外圈,哪个磁头正在读写(同一时刻只能有一个磁头在读写)等。
CHS编址方式在早期的小容量硬盘中非常流行,但是目前的大容量硬盘的设计和低级格式化方式已经有所变化,所以CHS编址方式已经不再使用,而转为LBA编址方式。LBA编址方式不再划分柱面和磁头号,这些数据由硬盘自身保留,而磁盘对外提供的地址全部为线性的地址,即LBA地址。
所谓线性,指的是把磁盘想象成只有一个磁道,这个磁道是无限长的直线,扇区为这条直线上的等长线段,从1开始顺序编号,直到无限远。显然,这种方式屏蔽了柱面、磁头这些复杂的东西,向外提供了简单的方式,所以非常利于编程。然而磁盘中的控制电路依然要找到某个LBA地址到底对应着哪个磁道哪个磁头上的哪个扇区,这种对应关系保存在磁盘控制电路的ROM芯片中,磁盘初始化的时候载入缓存中以便随时查询。
注意: 基于CHS编址方式的磁盘最大容量
磁头数(Heads)表示硬盘总共有几个磁头,也就是有几面盘片,最大为255(用8个二进制位存储)。
柱面数(Cylinders)表示硬盘每一面盘片上有多少条磁道,最大为1023(用10个二进制位存储)。扇区数(Sectors)表示每一条磁道上有多少扇区,最大为63(用6个二进制位存储)。
每个扇区一般是512B,理论上讲这不是必须的。目前很多大型磁盘阵列所使用的硬盘,由于阵列控制器需要做一些诸如校验信息之类的特殊存储,这些磁盘都被格式化为每扇区520B。
如果按照每扇区512B来计算,磁盘最大容量为255×1023×63×512/ 1048576 = 8024 MB(1MB =1048576 B)。这就是所谓的8GB容量限制的原因。但是随着技术的不断发展,CHS地址的位数在不断增加,所以可寻址容量也在不断增加。
提示: 磁盘驱动器内怎样放下255个磁头呢?这是不可能的。目前的硬盘一般可以有1盘片、2盘片或者4盘片,这样就对应着2、4磁头或者8磁头。那么这样算来,硬盘实际容量一定小于8GB了?显然不是这样的。所谓255个磁头,这只是一个逻辑上的说法,实际的磁头、磁道、扇区等信息都保存在硬盘控制电路的ROM芯片中。而每条磁道上真的最多只有64个扇区么?当然也不是,一条磁道上实际的扇区数远远大于64,这样就分摊了磁头数实际少于255个所产生的“容量减小”。所以,这是CHS编址方式沿袭了老的传统,不愿意去作修改导致的。而这种沿袭达到了极限之后,最终导致LBA编址方式替代了CHS编址方式。
头标中还包括一个字段,其中有显示扇区是否能可靠存储数据,或者是已发现某个故障因而不宜使用的标记。有些硬盘控制器在扇区头标中还记录有指示字,可在原扇区出错时指引磁头跳转到替换扇区或磁道。最后,扇区头标以循环冗余校验CRC值作为结束,以供控制器检验扇区头标的读出情况,确保准确无误。
给扇区编号的最简单方法是采用l、2、3、4、5、6等顺序编号。如果扇区按顺序绕着磁道依次编号,那么磁盘控制电路在处理一个扇区的数据期间,可能会因为磁盘旋转太快,没等磁头反应过来,已经超过扇区间的间隔而进入了下一个扇区的头标部分,则此时磁头若想读取这个扇区的记录,就要再等一圈,等到盘片旋转回来之后再次读写,这个等待时间无疑是非常浪费的。
显然,要解决这个问题,靠加大扇区间的间隔是不现实的,那会浪费许多磁盘空间。许多年前,IBM的一位杰出工程师想出了一个绝妙的办法,即对扇区不使用顺序编号,而是使用一个交叉因子(Interleave)进行编号。交叉因子用比值的方法来表示,如3∶1表示磁道上的第1个扇区为1号扇区,跳过两个扇区即第4个扇区为2号扇区,这个过程持续下去直到给每个物理扇区编上逻辑号为止。
例如,每磁道有17个扇区的磁盘按2∶1的交叉因子编号就是l、10、2、11、3、12、4、13、5、14、6、15、7、16、8、17、9;而按3∶1的交叉因子编号就是l、7、13、2、8、14、3、9、15、4、10、16、5、11、17、6、12。当设置1∶1的交叉因子时,如果硬盘控制器处理信息足够快,那么读出磁道上的全部扇区只需要旋转一周。但如果硬盘控制器的处理动作没有这么快,则只有磁盘所转的圈数等于针对这个磁道的交叉因子时,才能读出每个磁道上的全部数据。将交叉因子设定为2∶1时,磁头要读出磁道上的全部数据,磁盘只需转两周。如果2∶1的交叉因子仍不够慢,这时可将交叉因子调整为3∶1,如图3-6所示。
图3-6所示是典型的MFM(Modified Frequency Modulation,改进型调频制编码)硬盘,每磁道有17个扇区,画出了用三种不同的扇区交叉因子编号的情况。最外圈的磁道(0号柱面)上的扇区用简单的顺序连续编号,相当于扇区交叉因子是1∶1。1号磁道(柱面)的扇区按2∶1的交叉因子编号,而2号磁道的扇区按3∶1的交叉因子编号。

图3-6 MFM改进型交叉因子示意图
在早期的硬盘管理工作中,设置交叉因子需要用户自己完成。用BIOS中的低级格式化程序对硬盘进行低级格式化时,就需要指定交叉因子,有时还需要设置几种不同的值来比较其性能,而后确定一个比较好的值。现在的硬盘BIOS已经自己解决了这个问题,所以一般低级格式化程序中就不再提供这一设置选项了。
系统将文件存储到磁盘上时,是按柱面、磁头、扇区方式进行的,即最先是第1磁道的第1磁头下(也就是第1盘面的第一磁道)所有的扇区,然后是同一柱面的下一磁头,直到整个柱面都存满。系统也是以相同的顺序去读出数据。读数据时通过告诉磁盘控制器要读出数据所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行读取(现在都是直接使用LBA地址来告诉磁盘所要读写的扇区)。磁盘控制电路则直接将磁头部件步进到相应的柱面,选中相应磁头,然后立即读取当前磁头下所有的扇区头标地址,然后把这些头标中的地址信息与期待检出的磁头和柱面号做比较。如果不是要读写的扇区号则读取扇区头标地址进行比较,直到相同以后,控制电路知道当前磁头下的扇区就是要读写的扇区,然后立即让磁头读写数据。
如果是读数据,控制电路会计算此数据的ECC码,然后把ECC码与已记录的ECC码相比较;如果是写数据,控制电路会计算出此数据的ECC码,存储到数据部分的末尾。在控制电路对此扇区中的数据进行必要的处理期间,磁盘会继续旋转。由于对信息的后处理需要耗费一定的时间,在这段时间内磁盘可能已旋转了相当的角度。
交叉因子的确定是一个系统级的问题。一个特定的硬盘驱动器的交叉因子取决于磁盘控制器的速度、主板的时钟速度、与控制电路相连的输出总线的操作速度等。如果磁盘的交叉因子值太高,就需要多花一些时间等待数据在磁盘上存入和读出;相反,交叉因子值太低也同样会影响性能。
前面已经说过,系统在磁盘上写入信息时,写满一个磁道后会转到同一柱面的下一个磁头,当柱面写满时,再转向下一柱面。从同一盘面的一个磁道转到另一个磁道,也就是从一个柱面转到下一个柱面,这个动作叫做换道。在换道期间磁盘始终保持旋转,这就会带来一个问题:假定系统刚刚结束了对一个磁道前一个扇区的写入,并且已经设置了最佳交叉因子比值,现在准备在下一磁道的第一扇区写入,这时必须等到磁头换道结束,让磁头部件重新定位在下一道上。如果这种操作占用的时间超过了一点,尽管是交叉存取,磁头仍会延迟到达。这个问题的解决办法是以原先磁道所在位置为基准,把新的磁道上全部扇区号移动约一个或几个扇区位置,这就是磁头扭斜。磁头扭斜可以理解为柱面与柱面之间的交叉因子,已经由生产厂家设置好,一般不用去改变它。磁头扭斜的更改比较困难,但是它们只在文件很长、超过磁道结尾进行读出和写入时才发挥作用,所以扭斜设置不正确所带来的损失比采用不正确的扇区交叉因子值带来的损失要小得多。交叉因子和磁头扭斜可用专用工具软件来测试和更改,更具体的内容这里就不再详述了,毕竟现在很多用户都没有见过这些参数。
提示: 最初,硬盘低级格式化程序只是行使有关磁盘控制器的专门职能来完成设置任务。由于这个过程可能会破坏低级格式化的磁道上的全部数据,现在也极少采用了。
扇区号存储在扇区头标中,扇区交叉因子和磁头扭斜的信息也存放在这里。
扇区交叉因子由写入到扇区头标中的数字设定,所以,每个磁道可以有自己的交叉因子。在大多数驱动器中,所有磁道都有相同的交叉因子。但有时因为操作上的原因,也可能导致各磁道有不同的扇区交叉因子。比如在交叉因子重置程序工作时,由于断电或人为中断就会造成一些磁道的交叉因子发生了改变,而另一些磁道的交叉因子没有改变。这种不一致性对计算机不会产生不利影响,只是有最佳交叉因子的磁道要比其他磁道的工作速度更快。
了解了磁盘的结构之后,知道磁盘是靠磁性子来存放数据的,有人会问:一个磁性子到底是什么概念?是一个磁性分子么?不是,这个“子”的概念是指一个区域,这个区域存在若干磁性分子,这些分子聚集到一起,直到磁头可以感觉到它的磁性为止。所以和磁带一样,磁记录追根到底就是利用线性中的段。根据这一段区域上的一片分子是N极还是S极,然后将其转换成电信号,也就产生了字节,从而记录了数据。当然只有存储介质还远远不够,要让数据可以被读出,被写入,还要有足够的速度和稳定性满足人们的需求,这就需要配套的电路了。
图3-7给出一个完整详细的硬盘电路示意框图。硬盘电路由14个部分组成。

图3-7 硬盘控制电路示意图
■ Buffer Memory:缓冲区存储器。
■ Interface Controller:接口控制器。
■ Micro-processor:微控制器,缩写为MCU。
■ PRML:Partial-Response Maximum-Likelihood Read Channel。
■ Timing ASIC:时间控制专用集成电路。
■ Servo Demodulator:伺服解调器。
■ Digital Signal Processor(DSP):数字信号处理器。
■ Preamp:预放大器。
■ Positioning Driver:定位驱动器。
■ VCM(Voice Coil Motor):音圈电动机。
■ Magnetic Media Disk:磁介质盘片。
■ Spindle Motor:主轴电机。
■ Spindle Driver:主轴驱动器。
■ Read/Write Head:读/写磁头。
实际电路不会有这么多一片一片的独立芯片,硬盘生产厂家在设计电路时都是选取高度集成的IC芯片,这样既减小了体积又提高了可靠性。当然这也正是芯片厂商努力的目标。
大家可以看到图3-7中的Spindle Driver与Positioning Driver这两部分用虚线圈了起来,并且标注了Servo/MSC Controller Combination字样。其中MSC是Motor Speed Control的缩写,意思是伺服/电机速度控制器组合。我们现在能看到的硬盘电路板中就有这样一块合并芯片。
到此,大家应该对磁盘的构造有所理解了。磁盘读写的时候都是以扇区为最小寻址单位的,也就是说不可能往某某扇区的前半部分写入某某数据。一个扇区的大小是512B,每次磁头连续读写的时候,只能以扇区为单位,即使一次只写了一个字节的数据,那么下一次就不能再向这个扇区剩余的部分接着写入,而是要寻找一个空扇区来写。
注意: 对于磁盘来说,一次磁头的连续读或者写叫做一次IO。请注意这里的措辞:“对于磁盘来说”。
提示: 目前4KB大小扇区的硬盘已经发布。因为操作系统的Page、文件系统的Block一般都是4KB大小,所以硬盘扇区512B的容量一直为业界所诟病。将扇区容量与上层的单位匹配,可以大大提高效率。
IO这个概念,充分理解就是输入输出。我们知道从最上层到最下层,层次之间存在着太多的接口,这些接口之间每次交互都可以称做一次IO,也就是广义上的IO。比如卷管理程序对磁盘控制器驱动程序API所作的IO,一次这种IO可能要产生针对磁盘的N个IO,也就是说上层的IO是稀疏的、简单的,越往下层走越密集、越复杂。
除了卷管理程序之外,凌驾于卷管理之上的文件系统对卷的IO,就比卷更稀疏简单了。同样,上层应用对文件系统API的IO更加简单,只需几句代码、几个调用就可以了。比如Open()某个文件,Seek()到某个位置,Write()一段数据,Close()这个文件等,就是一次IO。而就是这一次IO,可能对应文件系统到卷的N个IO,对应卷到控制器驱动的N×N个IO,对应控制器对最终磁盘的N×N×N个IO。总之,磁盘一次IO就是磁头的一次连续读或者写。而一次连续读或者写的过程,不管读写了几个扇区,扇区剩余部分均不能再使用。这无疑是比较浪费的,但是没有办法,总得有个最小单位。
龟在兔子前面100米,兔子的速度是龟的10倍。龟对兔子说:“我们同时起跑,你沿直线追我,你永远也追不上我。”这个结论猛一看,会觉得荒唐至极!可是龟分析了:“兔子跑到100米我当前的位置时,我同时也向前跑了10米。然后兔子跑了10米的时候,而我同时也向前跑了1米。它再追1米,而我又跑了0.1米。依此类推,兔子永远追不上我。大家看到这里就糊涂了,这么一分析确实是追不上,但事实却是能追上。那么问题出在哪里呢?
假如兔子的速度是每秒100米,龟的速度每秒10米。首先兔子追出100米时,用时1秒,此时龟在兔子前方10米处。然后兔子再追出10米,用时0.1秒,此时龟在前方1米处。接着兔子再追出1米,用时0.01秒,学过小学算术的人都能算出来,兔子掉入了一个无限循环小数中,什么时候结束了循环,才能追上龟。那么这就悖论了,小数是无限循环的,这到底是多少秒呢?如果时间可以以无限小的单位延伸,那么兔子确实永远也追不上龟。虽然时间确实是连续的,时间没有理由不连续,时间是一个思想中的概念,时间不是物质,所以时间是唯一能连续的东西,既然时间是无限的、连续的,那么兔子按理说追不上龟了,但是事实确实能追上,但有一个元素我们忽略了,它就是长度的最小单位!仔细分析一下,时间和长度是对应的,时间可以无限小,那么这个无限小的时间也应该对应无限小的长度,这样悖论到这里就解决了!因为存在一个长度的最小单位,而没有无限小!也就是说,当兔子走的长度是最小长度时龟就黔驴技穷了,因为不可能再行走比这长度更小的距离了,那么兔子自然就超过了龟。而这个时间是很短暂的,它发生在有限时间点上。至于这个最小长度,据说有人计算出来了,它可能是一个原子的长度,也可能比这还小。目前看来,我们移动的时候,最小似乎也不可能移动半个原子的距离!
芝诺悖论(龟兔赛跑悖论)证明了,对于我们目前可观察到的世界来说,是有一个最小距离单位的。如果我们以这个结论为前提,就可以推翻芝诺悖论了。假设这个距离最小单位是一块石头的长度。开始,兔子在乌龟后面相隔2块石头的距离,同样兔子的速度是乌龟的2倍,按照量子距离理论,这个2倍速度,不是无限可分的,那么我们表达这个2倍速的时候,应该这么说:兔子每前进2块石头的时间,乌龟只能前进一块石头的距离,而不可能前进半块石头。这样的前提下,连小学生都可以计算兔子何时追赶上乌龟了。
想象一张很大很大的白纸,你要在上面写日记。当你写满这张白纸之后,如果某天想查看某条日记,无疑将是个噩梦,因为白纸上没有任何格子或行分割线等,你只能通过一行一行地读取日记,搜索你要查看的那条记录。如果给白纸打上格子或行分割线,那么不但书写起来不会凌乱,而且还工整。
那么对于一张上面布满磁性介质的盘片来说,想要在它上面记录数据,如果不给它打格子划线的话,无疑就无法达到块级的记录。所以在使用之前,需要将其低级格式化,也就是划分扇区(格子)。我们见过稿纸,上面的格子是方形阵列排布的,原因很简单,因为稿纸是方形的。那么对于圆形来说,格子应该怎么排布呢?答案是同心圆排布,一个同心圆(磁道),就类似于稿纸上的一行,而这一行之内又可以排列上很多格子(扇区)。每个盘片上的行密度、每行中的格子(扇区)密度都有标准来规定,就像稿纸一样。
我们把稿纸放入打印机。打印机的打印头按照格子的距离精确地做着位移,并不停地喷出墨水,将字体打入纸张上的格子里。一旦一行打满,走纸轮精确地将稿纸位移到下一行,打印头在这一行上水平位移打满格子。走纸轮竖直方向位移,打印头水平方向位移,形成了方形扫描阵列,能够定位到整张纸上的每个格子。
同样,把圆形盘片安装到一个电机(走纸轮)上,然后在盘片上方加一个磁头(打印喷头)。但是和打印机不同的是,做换行这个动作不是由走纸轮来完成,而是由磁头来完成,称做径(半径)向扫描,也就是在不同同心圆上作切换(换行)。同样作行内扫描这个动作是由电机(走纸轮)而不是磁头(打印头)来完成,称做线扫描(沿着同心圆的圆周进行扫描)。
形成这种角色倒置的原因,很显然是由圆形的特殊性决定的。作圆周运动毕竟比作水平竖直运动要复杂,如果让磁头沿着同心圆作线扫描,则需要将磁头放在一个可以旋转的部件上,此时磁头动而盘片不动,可以达到相同的目的,但是技术难度就复杂多了。因为磁头上有电路连接着磁头和芯片。如果让磁头高速旋转,磁头动而芯片不动,电路的连通性怎么保证?不如让盘片转动来得干脆利索。
和打印机一样,定位到某个特定的格子之后,磁头开始用磁性来对这个格子中的每个磁粒子区做磁化操作,每个磁极表示一个0或者1状态。每个格子规定可以存放4096位这种状态,也就是512B(很多供大型机使用的磁盘阵列上的磁盘是用520B为一个扇区)。这就像打印机在一个格子再次细分,形成24×24点阵,每个坐标上的一个点都对应一种色彩。只不过对于磁盘来说只有0或者1,而对于打印机来说,可以是各种色彩中的一种(黑白打印机也只有黑或者白两种状态)。
磁盘的扇区中没有点阵,一个扇区可以看作是线性的。它没有宽,只有长,记录是顺序的,不能像打印机那样可以定位到扇区中的某个点。然而,磁盘比打印机有先天的优势。打印机只能从头到尾打印,而且打印之后不能更改。磁盘却可以对任意的格子进行写入、读取和更改等操作。打印机的走纸轮和打印喷头移动起来很慢,而且嘎嘎作响,听了都费劲。而磁盘的转速则快很多,目前可以达到每分钟15000转。磁头的位移动作也非常快,它使用步进电机来精确地换行(换磁道)。但是相对于盘片的转动而言,步进的速度就慢多了,所以制约磁盘性能的主要因素就是这个步进速度(换行或者换道速度),也就是寻道速度。
如果从最内同心圆换到最外同心圆,耗费的时间无疑是最长的。目前磁盘的平均寻道速度最高可以达到5ms多,不同磁盘的寻道速度不同,普通IDE磁盘可能会超过10ms。有了这个磁盘记录模型,我们就该研究怎么将这个模型抽象虚拟化出来,让向磁盘写数据的人感觉使用起来非常方便。就像打印机一样,点一下打印,一会纸就蹭蹭地往外冒。下面还是要一层一层地来做,不能直接就抽象到这么高的层次。
首先,要精确寻址每个格子就一定需要给每个格子一个地址。早期的磁盘都是用“盘片,磁道,扇区”来寻址的,一个磁盘盒子中可能不止一片盘片,就像一沓稿纸中有好几张纸一样。一个盘片上的某一“行”也就是某个磁道,应该可以再区分。一个磁道上的某个扇区也可以区分。到这,就是最终可寻址的最小单位了,而不能再精确定位到一个扇区中的某个点了。磁头只能顺序地写入或者读取出这些点,而不能只更新或者读取其中某个点。也就是说磁头只能一次成批写入或者读取出一个扇区的内容,而不能读写半个或者四分之一个扇区的内容。
后来的扇区寻址体系变了,因为后来的磁盘中每个磁道的扇区数目不同了,外圈由于周长比较长,所以容纳的扇区可以很多,干脆采用了逻辑地址来对每个扇区编址,将具体的盘片、磁道和扇区,抽象成LBA(Logical Block Address,顺序编址)。LBA1表示0号盘片0号磁道的0号扇区,依此类推,LBA地址到实际的盘片、磁道和扇区地址的映射工作由磁盘内部的逻辑电路来查询ROM中的对应表而得到,这样就完成了物理地址到逻辑地址的抽象、虚拟和映射。
寻址问题解决之后,就应该考虑怎么向磁盘发送需要写入的数据了。针对这个问题,人们抽象出一套接口系统,专门用于计算机和其外设交互数据,称为SCSI接口协议,即小型计算机系统接口。
下面举个例子来说明,比如某时刻要向磁盘写入512B的数据,磁盘控制器先向磁盘发一个命令,表明要准备做IO操作了,而且说明了附带参数(是否启用磁盘缓存、完成后是否中断通知CPU等),磁盘应答说可以进行,控制器立即将所要IO的类型(读/写)和扇区的起始地址以及随后扇区的数量(长度)发送给磁盘,如果是写IO,则随后还要将需要写入的数据发送给磁盘,磁盘将这块数据顺序写入先前通告的扇区中。
提示: 新的SCSI标准中有一种促进IO效率的新的方式,即Skip Mask IO模式。如果有两个IO,二者IO的目标扇区段被隔开了一小段,比如第一个写IO的目标为从1000开始的随后128扇区,第二个写IO的目标则为1500开始的随后128扇区,可以合并这两个IO为一个针对1000开始的随后628个扇区的IO。控制器将这条指令下发到磁盘之后,还会立即发送一个Mask帧,这个帧中包含了一串比特流,每一位表示一个扇区,此位为1,则表示进行该扇区的IO,为0,则表示跨过此扇区,不进行IO。这样,多了这串很小的比特流,却能省下一轮额外的IO开销。
SCSI接口完成了访问磁盘过程的虚拟化和抽象,极大的简化了访问磁盘的过程,它屏蔽了磁盘内部结构和逻辑,使得控制器只知道LBA是一个房间,有什么数据就给出地址,然后磁盘就会将数据写入这个地址对应的房间,读取操作也一样。
想象有一个包含10000个同心圆的转盘在旋转,现在有两个人在转盘外面,有一个机械手臂可以将物体放到任何一个同心圆上去。现在,第一个人想到半径最小的同心圆上去,而另外一个人却想到半径最大的同心圆上去,这可让机械手臂犯了难,机械手臂只能按照顺序,先照顾第一个人的要求。它首先寻道到最内侧同心圆,然后转盘旋转到待定位置后将这个人放到轨道上,随后立即驱动磁头臂到最外侧的圆,再将第二个人放上去。这期间的主要时间都用于从内侧到外侧的换道过程了,非常浪费。
这只是两个人的情况,那么如果有多个人,比如3个人先后告诉机械手臂,第一个人说要放到最内侧的圆上,第二个人说要放到最外侧的圆上,第三个人要放到最内侧的圆上。
如果这时候机械手臂还是按照顺序来操作,那么中间就会多了一次无谓的换道操作,极其浪费。所以机械手臂自作主张,在送完第一个人后,它没有立即处理第二个人的请求,而是在脑海中算计,它看第三个人也要求到内侧圆上,而它自己此时也恰好正在内侧圆上,何不趁此捎带第三个人呢?所以磁头跳过第二个人的请求,先把第三个人送到目的地,然后再换道送第二个人。
因为磁头算计用的时间比来回换道快得多,所以这种排队技术大大提高了读写效率。这种例子还有很多,比如电梯就是个很好的例子。实现队列功能的程序控制代码是存放在磁盘控制电路芯片中的,而不是主板上的磁盘控制器上。也就是说,由控制器发给磁盘指令,然后由磁盘自己的DSP固化电路或者由磁盘上的微处理器载入代码从而执行指令排队功能。
但是一个巴掌拍不响,排队必须也要由磁盘控制器来支持,所谓的支持就是说,如果磁盘擅自排队,不按照控制器发送过来的顺序一条一条执行指令,则在读出数据之后,由于步调和控制器期望的不一致,预先读出的数据只能先存放到磁盘驱动器的缓存中,等待控制器主动来取。因为控制器给磁盘发送的读写数据的指令,有可能是有先后顺序的,如果磁盘擅自做了排队,将后来发送的指令首先执行,那么读出的数据就算传送给了磁盘控制器,也会造成错乱。
所以,要实现排队技术,仅仅有磁盘驱动器自身是不够的,还必须在磁盘控制器(指主板上的磁盘控制,而不是磁盘本身的控制电路)电路中固化代码处理排队,和磁盘达成一致。或者不使用固化代码方式,而是修改磁盘控制器驱动程序,加入处理排队的功能从而配合磁盘驱动器。
提示: Intel在WinHEC 2003会议上发布了高级主机控制器接口0.95版规范(Advanced Host Controller Interface,AHCI),为驱动程序和系统软件提供了发现并实施命令队列、热插拔及电源管理等高级SATA功能的标准接口。这个接口就是在新的控制器硬件之上的驱动层面提供一层接口,解决了磁盘控制器不支持硬盘驱动器自身的排队这个问题。
还有一种提高磁盘性能的技术,叫做无序数据传输。也就是说,控制器发出一条指令要求读取某些扇区中的内容,磁盘可以不从数据所在的初始扇区开始读,而是采取就近原则。比如,磁头恰好处于待读取数据的尾部,此时如果等待磁盘旋转到磁头位于这块数据的头部时磁头才开始读,那么就要等一圈时间,也就是所谓的“旋转延迟”,时间就被白白地浪费了。如果磁头按照能读多少先读多少的原则,在尾部时就先读出尾部的数据,然后立即发给控制器,控制器立即通过DMA将数据放到内存,等磁盘转到数据块头部时再读出剩余的部分发给控制器,这样就避免了时间的浪费。然而,这种技术同样也要由磁盘控制器来支持,或是通过控制器硬件,或是通过驱动程序。
通过指令排队和无序传送可以最大化利用磁盘资源。也就是,把麻烦留给控制器,把简单留给磁盘。因为控制器的处理速度永远比磁盘的机械运动快。
假设目前磁盘控制器的队列中存在如下的一些IO,这些IO所需要查找的磁道号码按照先后排列顺序为98、183、37、122、14、124、65和67,而当前磁头处于53号磁道,磁头执行寻道操作有以下几种模式。
在FCFS模式下,磁头完全按照IO进入的先后顺序执行寻道操作,即从53号磁道跳到98号,然后到183号,再回到37号,依此类推。可以算出在这个例子中,此模式下磁头滑过的磁道总数为640。对应的扫描图如图3-8所示。
显然,FCFS模式很不科学,在随机IO的环境中严重影响IO效率。
在SSTF模式下,控制器会优先让磁头跳到离当前磁头位置最近的一个IO磁道去读写,读写完毕后,再次跳到离刚读写完的这个磁道最近的一个IO磁道去读写,依此类推。在SSTF模式下,这个例子呈现的扫描图如图3-9所示。
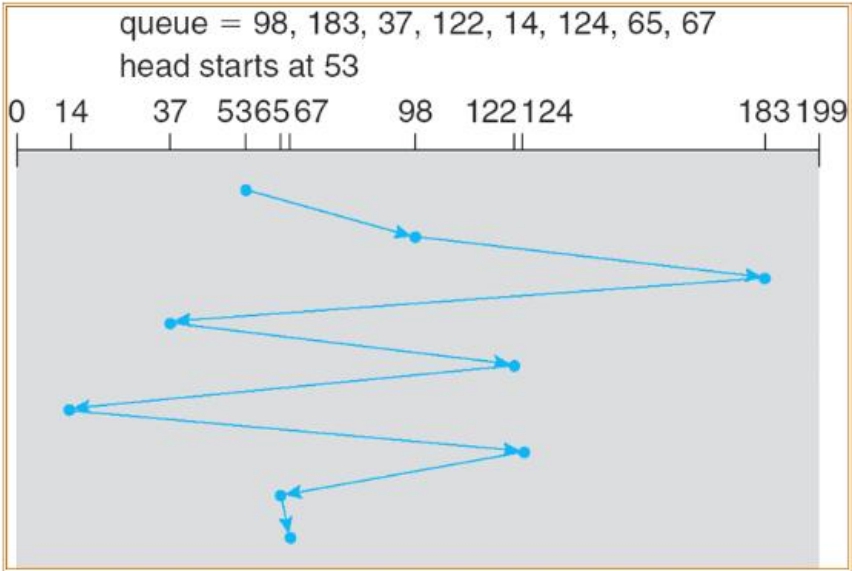
图3-8 FCFS模式扫描图
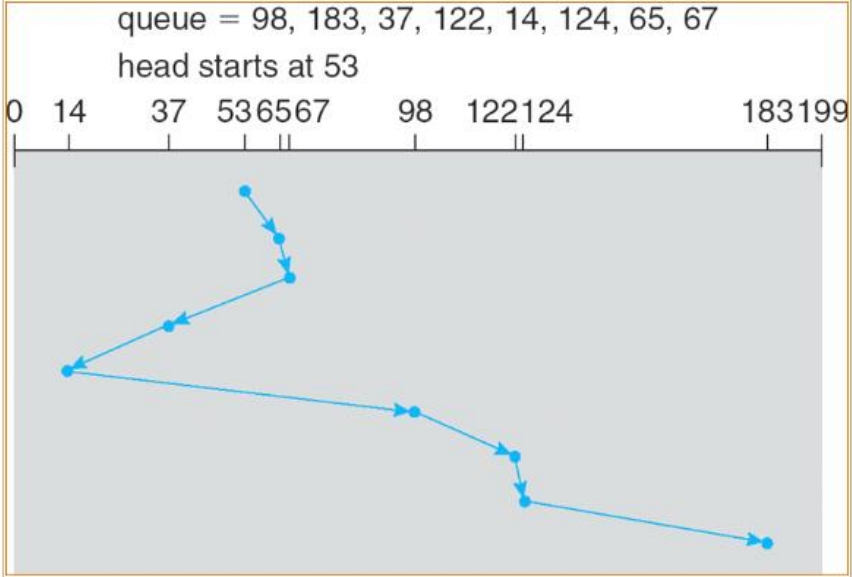
图3-9 SSTF模式扫描图
本例中,磁头初始位置在53号磁道,如果此时IO队列中不断有位于53号磁道周围磁道的IO进入,比如55号、50号、51号磁道等,那么诸如183号这种离53号磁道较远的IO将会被饿死,永远也轮不到183号磁道的IO。所以SSTF模式的限制也是很大的。
这种扫描方式是最传统、最经典的方式了。它类似于电梯模型,从一端到另一端,然后折返,再折返,这样循环下去。磁头从最内侧磁道依次向外圈磁道寻道。然而就像电梯一样,如果这一层没有人等待搭乘,那么磁头就不在本层停止。也就是说如果当前队列中没有某个磁道的IO在等待,那么磁头就不会跳到这个磁道上,而是直接略过去。但是SCAN模型中,即使最外圈或者最内圈的磁道没有IO,磁头也要触及到之后才能折返,这就像50米往返跑一样,必须触及到终点线才能折返回去。SCAN模式的扫描图如图3-10所示。

图3-10 SCAN模式扫描图
SCAN模式不会饿死任何IO,每个IO都有机会搭乘磁头这个电梯。然而,SCAN模式也会带来不必要的开销,因为磁头从来不会在中途折返,而只能触及到终点之后才能折返。如果磁头正从中间磁道向外圈移动,而此时队列中进入一个内圈磁道的IO,那么此时磁头并不会折返,即使队列中只有这一个IO。这个IO只能等待磁头触及最外圈之后折返回来被执行。
在C-SCAN模式中磁头总是从内圈向外圈扫描,达到外圈之后迅速返回内圈,返回途中不接受任何IO,然后再从内圈向外圈扫描。C-SCAN模式的扫描图如图3-11所示。
LOOK模式相对于SCAN模式的区别在于,磁头不必达到终点之后才折返,而只要完成最两端的IO即可折返。同样,C-LOOK也是一样的道理,只不过是单向扫描。图3-12所示的是C-LOOK模式的扫描图。

图3-11 C-SCAN模式扫描图
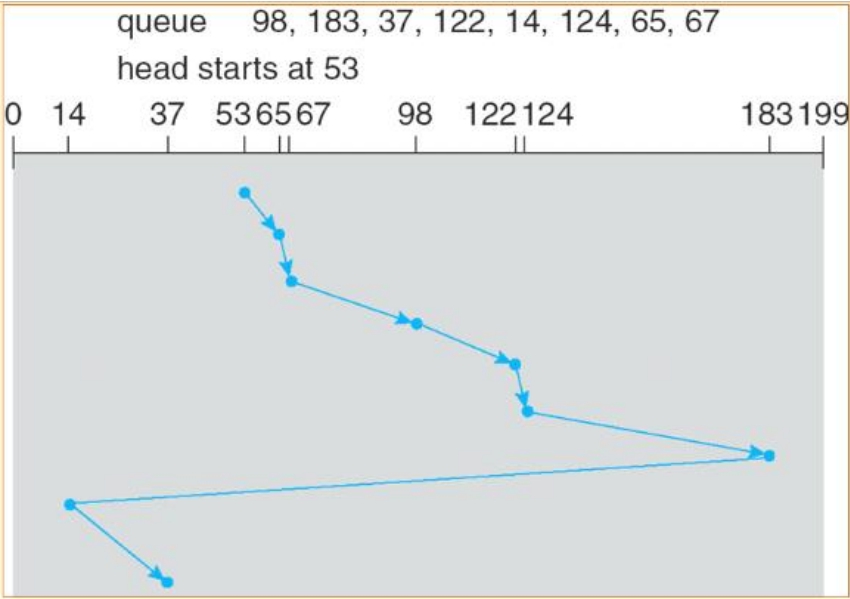
图3-12 C-LOOK模式扫描图
提示: 关于几种扫描模式的选择:总地说来,在负载不高的情况下,SSTF模式可以获得最佳的性能。但是鉴于可能造成某些较远的IO饿死的问题,所以在高负载条件下,SCAN或者C-SCAN、C-LOOK模式更为合适。
在大量随机IO的情况下,磁盘的磁头臂会像蜜蜂翅膀一样振动,当然它们的频率可能相差很大,但是用肉眼观察的话,磁头臂确实会像琴弦一样摆动,频率是比较高的。大家可以去Internet上搜索一下磁盘寻道的一个视频,来增强感观认识。
磁盘上必须有缓存,用来接收指令和数据,还被用来进行预读。磁盘缓存时刻处于打开状态。有很多文档资料上提到某些情况下可以“禁用”磁盘缓存,这是容易造成误解的说法。缓存在磁盘上就表现为一块电路板上的RAM芯片,目前有2MB、8MB、16MB、32MB、64MB等容量规格。所谓“禁用”磁盘缓存指的其实是本书第5章中描述的Write Through模式,即磁盘收到写入指令和数据后,必须先将其写入盘片,然后才向控制器返回成功信号,这样就相当于“禁用”了缓存。但是实际上,指令和数据首先到达的一定是缓存。
SCSI指令中有两个参数可以控制对磁盘缓存的使用。
(1)DPO(Disable Page Out): 这个参数的作用是禁止缓存中的数据页(缓存中的数据以页为单位存在)被换出。不管读还是写,被置了这个参数位的数据在缓存空间不够的时候不能覆盖缓存中的其他数据,也就是不能将其他数据换出。
(2)FUA(Force Unit Access): 这个参数的作用是强制盘片访问。对于写操作,磁盘必须将收到的数据写入盘片才返回成功信号,也就是进行Write Through。对于读操作,磁盘收到指令后,直接去盘片上读取数据,而不搜索缓存。
所以,当某个SCSI指令的DPO和FUA两个参数的值都被设置为1时,便相当于完全不使用缓存的提速功能了,但是指令和数据依然会先到达缓存中,这一点需要分清和理解。
目前基于SCSI指令的磁盘比如SCSI/FC/SAS等都支持FUA和DPO。对于基于ATA指令的IDE/SATA/USB-SATA/USB-IDE等,尚不支持这两个功能位,有另外的函数来绕过缓存。比如在Windows系统中,可以使用下列函数来控制磁盘缓存的行为:
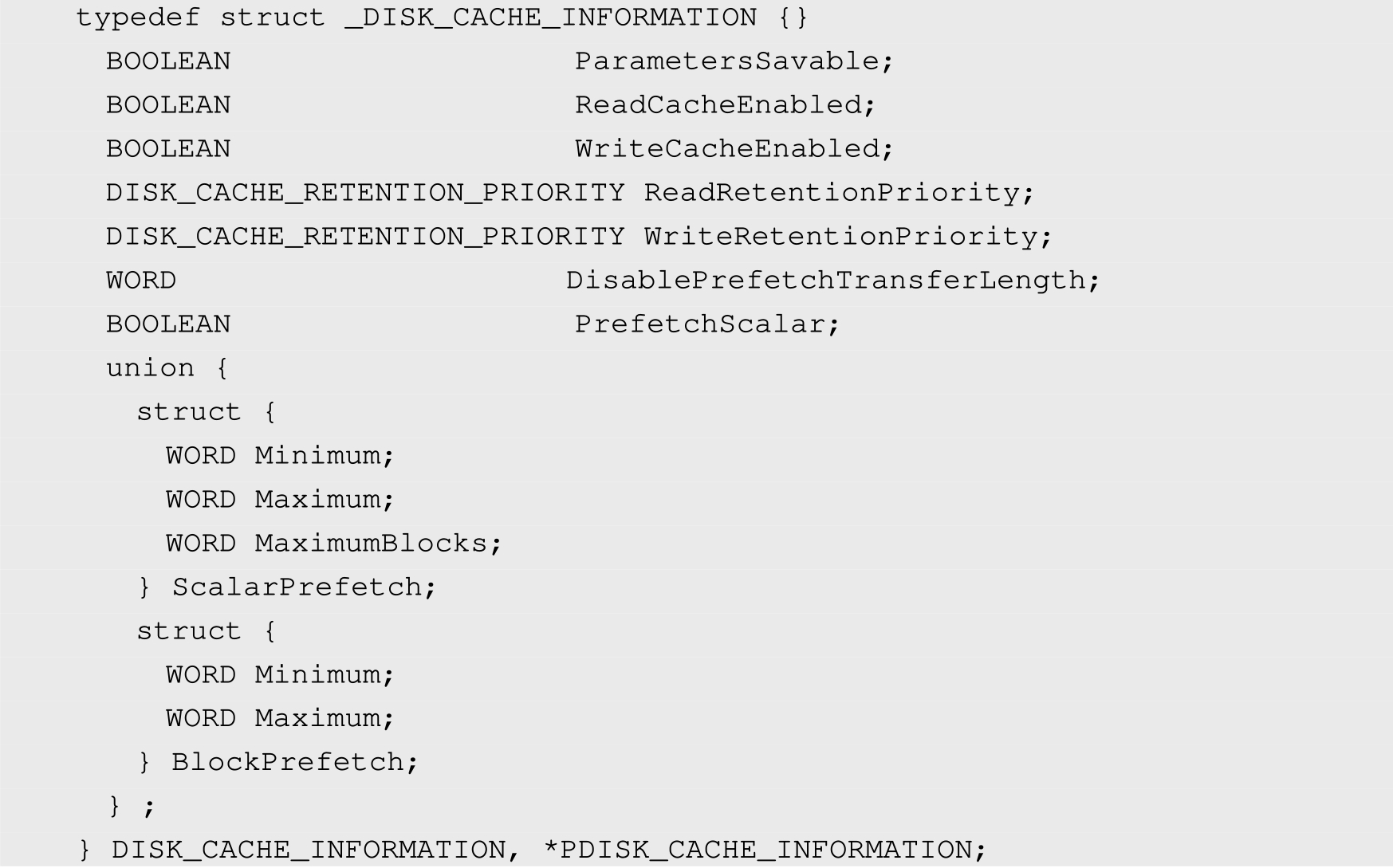
一次性禁用磁盘写缓存也是可以的,通过调用操作系统提供的一些接口即可实现,操作系统会利用对应磁盘的驱动程序来将磁盘的写缓存一次性关闭,直到下次磁盘掉电或者Reset为止,禁用效果一直会保持。对于用于磁盘阵列中的磁盘,写缓存一律禁用。
目前的磁盘可以分为单碟盘和多碟盘,前者在盘体内只有一张盘片,后者则有多张。前面已经讲过,每张盘片的正反两面都可以存放数据,所以每张盘片需要有两个磁头,各读写一面。然而,有一点必须澄清,磁盘每个时刻只允许一个磁头来读写数据。也就是说,不管盘体内盘片和磁头再多,也不可能提高硬盘的吞吐量和IO性能,只能提高容量。然而,已经有很多人致力于改变这个现状,希望能让磁头在盘内实现并发读写,也就相当于盘片和盘片之间相互形成RAID从而提高性能,但是这项工程目前还没有可以应用的产品。
影响硬盘性能的因素包括以下几种。
(1)转速: 转速是影响硬盘连续IO时吞吐量性能的首要因素。读写数据时,磁头不会动,全靠盘片的转动来将对应扇区中的数据感应给磁头,所以盘片转得越快,数据传输时间就越短。在连续IO情况下,磁头臂寻道次数很少,所以要提高吞吐量或者IOPS的值,转速就是首要影响因素了。目前中高端硬盘一般都为10000转每分或者15000转每分。最近也有厂家要实现20000转每分的硬盘,已经有了成形的产品,但是最终是否会被广泛应用,尚待观察。
(2)寻道速度: 寻道速度是影响磁盘随机IO性能的首要因素。随机IO情况下,磁头臂需要频繁更换磁道,用于数据传输的时间相对于换道消耗的时间来说是很少的,根本不在一个数量级上。所以如果磁头臂能够以很高的速度更换磁道,那么就会提升随机IOPS值。目前高端磁盘的平均寻道速度都在10ms以下。
(3)单碟容量: 单碟容量也是影响磁盘性能的一个间接因素。单碟容量越高,证明相同空间内的数据量越大,也就是数据密度越大。在相同的转速和寻道速度条件下,具有高数据密度的硬盘会显示出更高的性能。因为在相同的开销下,单碟容量高的硬盘会读出更多的数据。目前已有厂家研发出单碟容量超过300GB的硬盘,但是还没有投入使用。
(4)接口速度: 接口速度是影响硬盘性能的一个最不重要的因素。目前的接口速度在理论上都已经满足了磁盘所能达到的最高外部传输带宽。在随机IO环境下,接口速度显得更加不重要,因为此时瓶颈几乎全部都在寻道速度上。不过,高端硬盘都用高速接口,这是普遍做法。
硬盘制造是一项复杂的技术,到目前为至也只有欧洲、美国等发达国家和地区掌握了关键技术。但不管硬盘内部多么复杂,它必定要给使用者一个简单的接口,用来对其访问读取数据,而不必关心这串数据到底该什么时候写入,写入到哪个盘片,用哪个磁头,等等。
下面就来看一下硬盘向用户提供的是什么样的接口。注意,这里所说的接口不是物理上的接口,而是包括物理、逻辑在内的抽象出来的接口。也就是说,一个事物面向外部的时候,为达到被人使用的目的而向外提供的一种打开的、抽象的协议,类似于说明书。
目前,硬盘提供的物理接口包括如下几种。
■ 用于ATA指令系统的IDE接口。
■ 用于ATA指令系统的SATA接口。
■ 用于SCSI指令系统的并行SCSI接口。
■ 用于SCSI指令系统的串行SCSI(SAS)接口。
■ 用于SCSI指令系统的IBM专用串行SCSI接口(SSA)。
■ 用于SCSI指令系统的并且承载于FabreChannel协议的串行FC接口(FCP)。
IDE的英文全称为Integrated Drive Electronics,即电子集成驱动器,它的本意是指把控制电路和盘片、磁头等放在一个容器中的硬盘驱动器。把盘体与控制电路放在一起的做法减少了硬盘接口的电缆数目与长度,数据传输的可靠性得到了增强。而且硬盘制造起来更加容易,因为硬盘生产厂商不需要再担心自己的硬盘是否与其他厂商生产的控制器兼容。对用户而言,硬盘安装起来也更为方便了。IDE这一接口技术从诞生至今就一直在不断发展,性能也不断地提高。其拥有价格低廉、兼容性强的特点。IDE接口技术至今仍然有很多用户,但是正在不断减少。
IDE接口,也称为PATA接口,即Parallel ATA(并行传输ATA)。ATA的英文拼写为Advanced Technology Attachment,即高级技术附加,貌似发明ATA接口的人认为这种接口是有高技术含量的。不过在那个年代应该也算是比较有技术含量的了。ATA接口最早是在1986年由Compaq、West Digital等几家公司共同开发的,在20世纪90年代初开始应用于台式机系统。最初,它使用一个40芯电缆与主板上的ATA接口进行连接,只能支持两个硬盘,最大容量也被限制在504MB之内。后来,随着传输速度和位宽的提高,最后一代的ATA规范使用80芯的线缆,其中有一部分是屏蔽线,不传输数据,只是为了屏蔽其他数据线之间的相互干扰。
ATA接口从诞生至今,共推出了7个不同的版本,分别是ATA-1(IDE)、ATA-2(EIDE Enhanced IDE/Fast ATA)、ATA-3(FastATA-2)、ATA-4(ATA33)、ATA-5(ATA66)、ATA-6(ATA100)和ATA-7(ATA 133)。
■ ATA-1:在主板上有一个插口,支持一个主设备和一个从设备,每个设备的最大容量为504MB,支持的PIO-0模式传输速率只有3.3MB/s。ATA-1支持的PIO模式包括PIO-0、PIO-1和PIO-2模式,另外还支持4种DMA模式(没有得到实际应用)。ATA-1接口的硬盘大小为5英寸,而不是现在主流的3.5英寸。
■ ATA-2:是对ATA-1的扩展,习惯上也称为EIDE(Enhanced IDE)或Fast ATA。它在ATA的基础上增加了两种PIO和两种DMA模式(PIO-3),不仅将硬盘的最高传输率提高到16.6MB/s,同时还引进了LBA地址转换方式,突破了固有的504MB的限制,可以支持最高达8.1GB的硬盘。在支持ATA-2的BIOS设置中,一般可以看到LBA(Logical Block Address)和CHS(Cylinder、Head、Sector)设置选项。同时在EIDE接口的主板上一般有两个EIDE插口,也就是由同一个ATA控制器操控的两个IDE通道,每个通道可以分别连接一个主设备和一个从设备,这样一块主板就可以支持4个EIDE设备。这两个EDIE接口一般称为IDE1和IDE2。
■ ATA-3:没有引入更高速度的传输模式,在传输速度上并没有任何的提升,最高速度仍旧为16.6MB/s。只在电源管理方案方面进行了修改,引入了简单的密码保护安全方案。同时还引入了一项划时代的技术,那就是S.M.A.R.T(Self-Monitoring Analysis and Reporting Technology,自监测、分析和报告技术)。这项技术可以对磁头、盘片、电机、电路等硬盘部件进行监测,通过检测电路和主机的监测软件对磁盘进行检测,把其运行状况和历史记录同预设的安全值进行比较分析。当检测到的值超出了安全值的范围时,会自动向用户发出警告,进而对硬盘潜在故障做出有效预测,提高了数据存储的安全性。
■ ATA-4:从ATA-4接口标准开始正式支持Ultra DMA数据传输模式,因此也习惯称ATA-4为Ultra DMA 33或ATA33,33是指数据传输的速率为33.3MB/s。并首次在ATA接口中采用了Double Data Rate(双倍数据传输)技术,让接口在一个时钟周期内传输数据两次,时钟上升期和下降期各有一次数据传输,这样数据传输速率一下子从16.6MB/s提升至33.3MB/s。Ultra DMA 33还引入了冗余校验技术(CRC)。该技术的设计原理是系统与硬盘在进行传输的过程中,随数据一起发送循环的冗余校验码,对方在收取的时候对该校验码进行检验,只有在检验完全正确的情况下才接收并处理得到的数据,这对于高速传输数据的安全性提供了极其有力的保障。
■ ATA-5:ATA-5也就是Ultra DMA 66,也叫ATA66,是建立在Ultra DMA 33硬盘接口的基础上的,同样采用了UDMA技术。Ultra DMA 66将接口传输电路的频率提高为原来的两倍,所以接收/发送数据速率达到66.6 MB/s。它保留了Ultra DMA 33的核心技术——冗余校验技术。在工作频率提升的同时,电磁干扰问题开始出现在ATA接口中。为保障数据传输的准确性,防止电磁干扰,Ultra DMA 66接口开始使用40针脚80芯的电缆。40针脚是为了兼容以往的ATA插槽,减小成本的增加。80芯中新增的都是信号屏蔽线,这40条屏蔽线不与接口相连,所以针脚不需要增加。这种设计可以降低相邻信号线之间的电磁干扰。
■ ATA-6:ATA100接口的数据线与ATA66一样,也是使用40针80芯的数据传输电缆,并且ATA100接口完全向下兼容,支持ATA33和ATA66接口的设备完全可以继续在ATA100接口中使用。ATA100规范将电路的频率又提升了一个等级,可以让硬盘的外部传输率达到100MB/s。它提高了硬盘数据的完整性与数据传输速率,对桌面系统的磁盘子系统性能有较大的提升作用,而CRC技术更有效保证了在高速传输中数据的完整性和可靠性。
■ ATA-7:ATA-7是ATA接口的最后一个版本,也叫ATA133。ATA133接口支持133 MB/s的数据传输速度,这是第一种在接口速度上超过100MB/s的IDE硬盘。迈拓是目前唯一一家推出这种接口标准硬盘的制造商。由于并行传输随着电路频率的提升,传输线缆上的信号干扰越来越难以解决,已经达到了当前技术的极限,所以其他IDE硬盘厂商停止了对IDE接口的开发,转而生产Serial ATA接口标准的硬盘。
图3-13所示为几种ATA接口的总结。
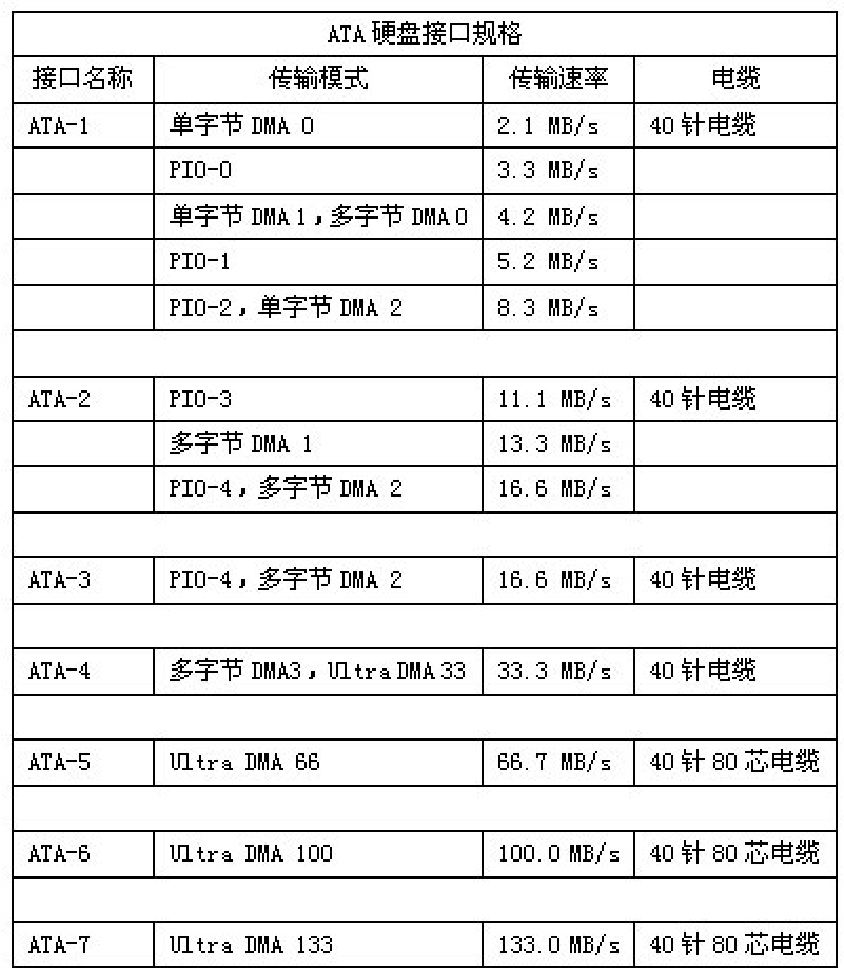
图3-13 几种ATA接口总结
■ PIO模式(Programming Input/Output Model):一种通过CPU执行I/O端口指令来进行数据读写的数据交换模式,是最早的硬盘数据传输模式。这种模式的数据传输速率低下,CPU占有率也很高,传输大量数据时会因为占用过多的CPU资源而导致系统停顿,无法进行其他的操作。在PIO模式下,硬盘控制器接收到硬盘驱动器传来的数据之后,必须由CPU发送信号将这些数据复制到内存中,这就是PIO模式高CPU占用率的原因。PIO数据传输模式又分为PIO mode 0、PIO mode 1、PIO mode 2、PIO mode 3和PIO mode 4几种模式,数据传输速率从3.3MB/s到16.6MB/s不等。受限于传输速率低下和极高的CPU占有率,这种数据传输模式很快就被淘汰了。
■ DMA模式(Direct Memory Access):直译的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式。PIO模式下硬盘和内存之间的数据传输是由CPU来控制的,而在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送。DMA控制器直接将数据复制到内存的相应地址上,数据传送完毕后再把信息反馈给CPU,这样就很大程度上减轻了CPU资源的占用率。DMA模式与PIO模式的区别就在于DMA模式不过分依赖CPU,可以大大节省系统资源。二者在传输速度上的差异并不十分明显,DMA所能达到的最大传输速率也只有16.6MB/s。DMA模式可以分为Single-Word DMA(单字节DMA)和Multi-Word DMA(多字节DMA)两种。
■ Ultra DMA模式(Ultra Direct Memory Access):一般简写为UDMA,含义是高级直接内存访问。UDMA模式采用16-bit Multi-Word DMA(16位多字节DMA)模式为基准,可以理解为是DMA模式的增强版本。它在包含了DMA模式的优点的基础上,又增加了CRC(Cyclic Redundancy Check,循环冗余码校验)技术,提高了数据传输过程中的准确性,使数据传输的安全性得到了保障。在以往的硬盘数据传输模式下,一个时钟周期只传输一次数据,而在UDMA模式中逐渐应用了Double Data Rate(双倍数据传输)技术,因此数据传输速度有了极大的提高。此技术就是在时钟的上升期和下降期各自进行一次数据传输,可以使数据传输速度成倍地增长。
可以在ATA控制器属性中选择使用PIO还是DMA传输模式,如图3-14所示。
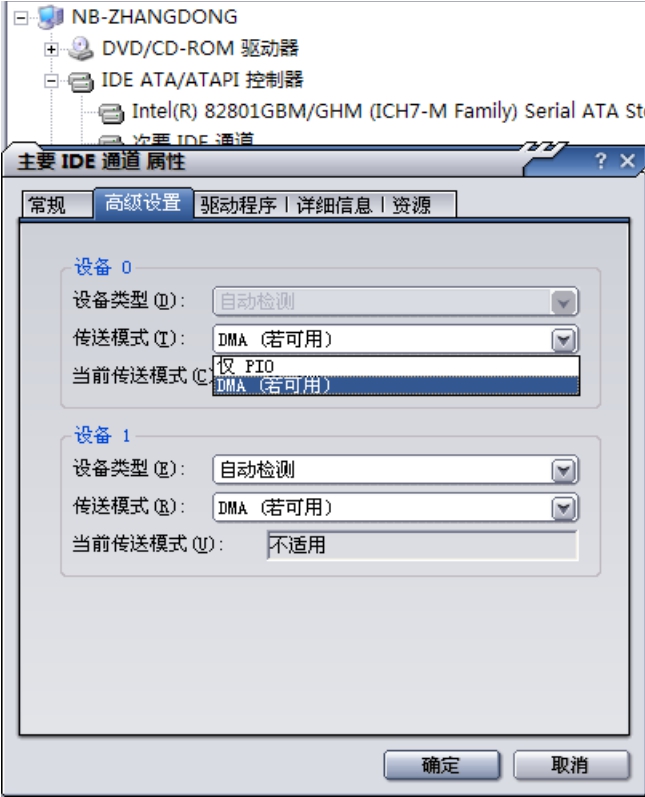
图3-14 DMA模式示意图
在UDMA模式发展到UDMA133之后,受限于IDE接口的技术规范,无论是连接器、连接电缆还是信号协议都表现出了很大的技术瓶颈,而且其支持的最高数据传输率也有限。在IDE接口传输率提高的同时,也就是工作频率提高的同时,IDE接口交叉干扰、地线增多、信号混乱等缺陷也给其发展带来了很大的制约,被新一代的SATA接口取代也就在所难免了。
SATA的全称是Serial ATA,即串行传输ATA。相对于PATA模式的IDE接口来说,SATA是用串行线路传输数据,但是指令集不变,仍然是ATA指令集。
SATA标准是由Intel、IBM、Dell、APT、Maxtor和Seagate公司共同提出的硬盘接口规范。在IDF Fall 2001大会上,Seagate宣布了Serial ATA 1.0标准,正式宣告了SATA规范的确立。自2003年第二季度Intel推出支持SATA 1.5Gbps的南桥芯片(ICH5)后,SATA接口取代传统PATA接口的趋势日渐明显。此外,SATA与现存于PC上的USB、IEEE 1394相比,在性能和功能方面的表现也更加突出。然而经过一年的市场洗礼,原有的SATA 1.0/1.0a(1.5Gb/s)规格遇到了一些问题。2005年SATA硬盘步入了新的发展阶段,性能更强、配置更高的SATA 2.0产品出现在了市场上,这些高性能的SATA 2.0硬盘的到来无疑加速了硬盘市场的转变。
SATA与IDE结构在硬件上有着本质区别,其数据接口、电源接口以及接口实物图如图3-15、图3-16及图3-17所示。

图3-15 IDE线缆和SATA线缆对比

图3-16 SATA硬盘的电源线

图3-17 SATA接口实物图
SATA技术是Intel公司在IDF 2000大会上推出的,其最大的优势是传输速率高。SATA的工作原理非常简单:采用连续串行的方式来实现数据传输从而获得较高的传输速率。2003年发布的SATA 1.0规范提供的传输速率就已经达到了150MB/s,不但高出普通IDE硬盘所提供的100MB/s(ATA100),甚至超过了IDE最高传输速率133MB/s(ATA133)。
SATA在数据可靠性方面也有了大幅度提高。SATA可同时对指令及数据封包进行循环冗余校验(CRC),不仅可检测出所有单比特和双比特的错误,而且根据统计学的原理还能够检测出99.998%可能出现的错误。相比之下,PATA只能对来回传输的数据进行校验,而无法对指令进行校验,加上高频率下干扰甚大,因此数据传输稳定性很差。
除了传输速率更高、传输数据更可靠外,节省空间是SATA最具吸引力的地方。由于线缆相对于80芯的IDE线缆来说瘦了不少,更有利于机箱内部的散热,线缆间的串扰也得到了有效控制。不过SATA 1.0规范存在不少缺点,特别是缺乏对于服务器和网络存储应用所需的一些先进特性的支持。比如在多任务、多请求的典型服务器环境里面,SATA 1.0硬盘的确会有性能大幅度下降,还有可维护性不强、可连接性不好等缺点。这时,SATA 2.0的出现使这方面得到了很好的补充。
与SATA 1.0规范相比,SATA 2.0规范中添加了一些新的特性,具体如下。
■ 3Gb/s的传输速率:在SATA 2.0扩展规范中,3Gb/s的速率是最大的亮点。由于SATA使用8bit/10bit编码,所以3Gb/s等同于300MB/s的接口速率。不过,从性能角度看,3Gb/s并不能带来多大的提升,即便是RAID应用的场合,性能提升也没有想象的那么大。因为硬盘内部传输速率还达不到与接口速率等同的程度。在大多数应用中,硬盘是将更多的时间花在了寻道上,而不是传输上。接口速率的提高直接影响的是从缓存进行读写的操作,所以理论上大缓存的产品会从3Gb/s的传输速率中得到更大的好处。
■ 支持NCQ技术:在SATA 2.0扩展规范所带来的一系列新功能中,NCQ(Native Command Queuing,自身命令队列)功能也非常令人关注。硬盘是机电设备,容易受内部机械部件惯性的影响,其中旋转等待时间和寻道等待时间就大大限制了硬盘对数据访问和检索的效率。前面曾经描述过一个模型,指的就是这种由硬盘驱动器自身实现的排队技术。
如果对磁头寻道这个机械动作的执行过程实施智能化的内部管理,就可以大大地提高整个工作流程的效率。所谓智能化的内部管理就是取出队列中的命令,然后重新排序,以便有效地获取和发送主机请求的数据。在硬盘执行某一命令的同时,队列中可以加入新的命令并排在等待执行的作业中。如果新的命令恰好是处理起来机械效率最高的,那么它就是队列中要处理的下一个命令。但有效的排序算法既要考虑目标数据的线性位置,又要考虑其角度位置,并且还要对线性位置和角度位置进行优化,以使总线的服务时间最小,这个过程也称做“基于寻道和旋转优化的命令重新排序”。
台式SATA硬盘队列一直被严格地限制为深度不得超过32级。如果增加队列深度,可能会起到反作用——增加命令堆积的风险。通常SATA硬盘接收命令时有两种选择,一是立即执行命令,二是延迟执行。对于后一种情况,硬盘必须通过设置注意标志和Service位来通知主机何时开始执行命令。然而硬盘不能主动与主机通信,这就需要主机定期轮回查询,发现Service位后将发出一条Service命令,然后才能从硬盘处获得将执行哪一条待执行命令的信息。而且Service位不包含任何对即将执行命令的识别信息,所必需的命令识别信息是以标记值的形式与数据请求一同传输的,并仅供主机用于设置DMA引擎和接收数据缓冲区。这样主机就不能预先掌握硬盘所设置的辅助位是哪条命令设置的,数据传输周期开始前也无法设置DMA引擎,这最终导致了SATA硬盘效率低下。
NCQ包含如下两部分内容。
一方面,硬盘本身必须有能力针对实体数据的扇区分布对命令缓冲区中的读写命令进行排序。同时硬盘内部队列中的命令可以随着必要的跟踪机制动态地重新调整或排序,其中跟踪机制用于掌握待执行和已完成作业的情况,而命令排队功能还可以使主机在设备对命令进行排队的时候,断开与硬盘间的连接以释放总线。一旦硬盘准备就绪,就重新连接到主机,尽可能以最快的速率传输数据,从而消除占用总线的现象。
另一方面,通信协议的支持也相当重要。因为以前的PATA硬盘在传输数据时很容易造成中断,这会降低主控器的效率,所以NCQ规范中定义了中断聚集机制。相当于一次执行完数个命令后,再对主控器回传执行完毕的信息,改善处理队列命令的效能。
从最早的希捷7200.7系列硬盘开始,NCQ技术应用于桌面产品的时间至今已超过半年,不过目前NCQ对个人桌面应用并没有带来多大的性能提升,在某些情况下还会引起副作用。而且不同硬盘厂商的NCQ方案存在着差异,带来的效果也不同。
■ 端口选择器(Port Selector):目前的SATA 2.0扩展规范还具备了Port Selector(端口选择器)功能。Port Selector是一种数据冗余保护方案,使用Port Selector可增加冗余度,具有Port Selector功能的SATA硬盘,外部有两个SATA接口,同时连接这两个接口到控制器上,一旦某个接口坏掉或者连线故障,则立刻切换到另一个接口和连线上,不会影响数据传输。
■ 端口复用器(Port Multiplier):SATA 1.0的一个缺点就是可连接性不好,即连接多个硬盘的扩展性不好。因为在SATA 1.0规范中,一个SATA接口只能连接一个设备。SATA规范的制定者们显然也意识到了这个问题,于是在SATA 2.0中引入了Port Multiplier的概念。Port Multiplier是一种可以在一个控制器上扩展多个SATA设备的技术,它采用4位(bit)宽度的Port Multiplier端口字段,其中控制端口占用一个地址,因此最多能输出2的四次方减1个,即15个设备连接,这与并行SCSI相当。Port Multiplier的上行端口只有1个,在带宽为150MB/s的时候容易成为瓶颈,但如果上行端口支持300MB/s的带宽,就与Ultra320 SCSI的320MB/s十分接近了。Port Multiplier技术对需要多硬盘的用户很有用,不过目前提供这种功能的芯片组极少。
■ 服务器特性:在SATA 2.0扩展规范中还增加了大量的新功能,比如防止开机时多硬盘同时启动带来太大电流负荷的交错启动功能;强大的温度控制、风扇控制和环境管理;背板互联和热插拔功能等。这些功能更侧重于低端服务器方面的扩展。
■ 接口和连线的强化:作为一个还在不断添加内容的标准集合,SATA 2.0最新的热点是eSATA,即外置设备的SATA接口标准,采用了屏蔽性能更好的两米长连接线,目标是最终取代USB和IEEE 1394。在内部接口方面,Click Connect加强了连接的可靠性,在接上时有提示声,拔下时需要先按下卡口。这些细微的结构变化显示出SATA接口更加成熟和可靠。
下面单独用一节来讲解在存储方面应用最为广泛的SCSI硬盘接口。
SCSI与ATA是目前现行的两大主机与外设通信的协议规范,而且它们各自都有自己的物理接口定义。对于ATA协议,对应的就是IDE接口;对于SCSI协议,对应的就是SCSI接口。凡是作为一个通信协议,就可以按照OSI模型(本书第7章将介绍)来将其划分层次,尽管有些层次可能是合并的或者是缺失的。划分了层次之后,我们就可以把这个协议进行分解,提取每个层次的功能和各个层次之间的接口,从而可以将这个协议融合到其他协议之中,形成一种“杂交”协议来适应各种不同的环境,这个话题将在本书第13章加以阐述。
SCSI的全称是Small Computer System Interface,即小型计算机系统接口,是一种较为特殊的接口总线,具备与多种类型的外设进行通信的能力,比如硬盘、CD-ROM、磁带机和扫描仪等。SCSI采用ASPI(高级SCSI编程接口)的标准软件接口使驱动器和计算机内部安装的SCSI适配器进行通信。SCSI接口是一种广泛应用于小型机上的高速数据传输技术。SCSI接口具有应用范围广、多任务、带宽大、CPU占用率低以及热插拔等优点。
SCSI接口为存储产品提供了强大、灵活的连接方式,还提供了很高的性能,可以有8个或更多(最多16个)的SCSI设备连接在一个SCSI通道上,其缺点是价格过于昂贵。SCSI接口的设备一般需要配合价格不菲的SCSI卡一起使用(如果主板上已经集成了SCSI控制器,则不需要额外的适配器),而且SCSI接口的设备在安装、设置时比较麻烦,所以远远不如IDE设备使用广泛。虽然从2007年开始,IDE硬盘就被SATA硬盘彻底逐出了市场。
在系统中应用SCSI必须要有专门的SCSI控制器,也就是一块SCSI控制卡,才能支持SCSI设备,这与IDE硬盘不同。在SCSI控制器上有一个相当于CPU的芯片,它对SCSI设备进行控制,能处理大部分的工作,减少了CPU的负担(CPU占用率)。在同时期的硬盘中,SCSI硬盘的转速、缓存容量、数据传输速率都要高于IDE硬盘,因此更多是应用于商业领域。
下面简单介绍一下SCSI规范的发展过程。
SCSI最早是1979年由美国的Shugart公司(希捷公司前身)制订的,在1986年获得了ANSI(美国标准协会)的承认,称为SASI(Shugart Associates System Interface),也就是最初版本SCSI-1。
SCSI-1是第一个SCSI标准,支持同步和异步SCSI外围设备;使用8位的通道宽度;最多允许连接7个设备;异步传输时的频率为3MB/s,同步传输时的频率为5MB/s;支持WORM外围设备。它采用25针接口,因此在连接到SCSI卡(SCSI卡上接口为50针)上时,必须要有一个内部的25针对50针的接口电缆。该种接口已基本被淘汰,在相当古老的设备上或个别扫描仪设备上可能还可以看到。
SCSI-2又被称为Fast SCSI,它在SCSI-1的基础上做了很大的改进,增加了可靠性,数据传输率也被提高到了10MB/s;但仍旧使用8位的并行数据传输,还是最多连接7个设备。后来又进行了改进,推出了支持16位并行数据传输的WIDE-SCSI-2(宽带)和FAST-WIDE-SCSI-2(快速宽带)。其中WIDE-SCSI-2的数据传输速率并没有提高,只是改用16位传输;而FAST-WIDE-SCSI-2则是把数据传输速率提高到了20MB/s。
SCSI-3标准版本是在1995年推出的,也习惯称为Ultra SCSI,其同步数据传输速率为20MB/s。若使用16位传输的Wide模式时,数据传输率更可以提高至40MB/s。其允许接口电缆的最大长度为1.5米。
1997年推出了Ultra 2 SCSI(Fast-40)标准版本,其数据通道宽度仍为8位,但其采用了LVD(Low Voltage Differential,低电平微分)传输模式,传输速率为40MB/s,允许接口电缆的最大长度为12米,大大增加了设备的灵活性,且支持同时挂接7个设备。随后推出了Wide Ultra 2 SCSI接口标准,它采用16位数据通道带宽,最高传输速率可达80MB/s,允许接口电缆的最大长度为12米,支持同时挂接15个装置。
LVD可以使用更低的电压,因此可以将差动驱动程序和接收程序集成到硬盘的板载SCSI控制器中。不再需要单独的高成本外部高电压差动组件。而老式SCSI需要使用独立的、耗电的高压器件。
LVD硬盘可进行多模式转换。当所有条件都满足时,硬盘就工作在LVD模式下;反之,如果并非所有条件都满足,硬盘将降为单端工作模式。LVD硬盘带宽的增加对于服务器环境来说意味着更理想的性能。服务器环境都有快速响应、必须能够进行随机访问和大工作量的队列操作等要求。当使用诸如CAD、CAM、数字视频和各种RAID等软件的时候,带宽增加的效果能立竿见影,信息可以迅速而轻松地进行传输。
Ultra 160 SCSI,也称为Ultra 3 SCSI LVD,是一种比较成熟的SCSI接口标准,是在Ultra 2 SCSI的基础上发展起来的,采用了双转换时钟控制、循环冗余码校验和域名确认等新技术。在增强了可靠性和易管理性的同时,Ultra 160 SCSI的传输速率为Ultra 2 SCSI的2倍,达到160MB/s。这是采用了双转换时针控制的结果。双转换时钟控制在不提高接口时钟频率的情况下使数据传输率提高了一倍,这也是Ultra l60 SCSI接口速率大幅提高的关键。
Ultra 320 SCSI,也称为Ultra 4 SCSI LVD,是比较新型的SCSI接口标准。Ultra 320 SCSI是在Ultra 160 SCSI的基础上发展起来的,Ultra 160 SCSI的3项关键技术,即双转换时钟控制、循环冗余码校验和域名确认,都得到了保留。以往的SCSI接口标准中,SCSI接口支持异步和同步两种传输模式。Ultra 320 SCSI引入了调步传输模式,在这种传输模式中简化了数据时钟逻辑,使Ultra 320 SCSI的高传输速率成为可能。Ultra 320 SCSI的传输速率可以达到320MB/s。
图3-18为SCSI总线连接示意图。
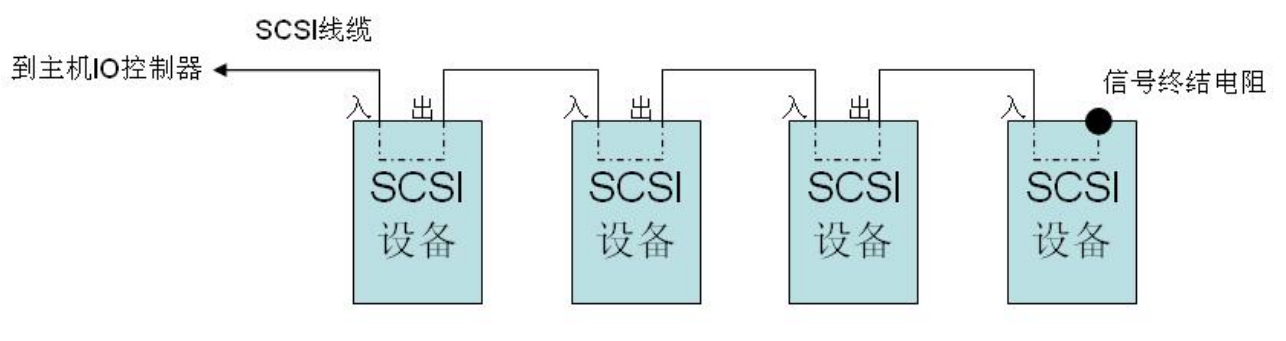
图3-18 SCSI总线连接示意图
下面介绍SCSI协议中的OSI模型。
上面描述的SCSI接口的各个规范,全部限于物理电气层,即描述传输速率、电气技术性能等。SCSI是一套完整的数据传输协议。一个通信协议必然会跨越OSI的所有7个层次,而物理电气参数只是OSI模型中的第一层,那么第二层到第七层,SCSI规范中也包含么?答案当然是肯定的。
OSI模型中链路层的功能就是用来将数据帧成功地传送到这条线路的对端。SCSI协议中,利用CRC校验码来校验每个指令或者数据的帧,如果发现对方发来的校验码与本地计算的不同,则说明这个数据帧在传输过程中受到了比较强的干扰而使其中某个或者某些位发生了翻转,那么就会丢弃这个帧,发送方便会重传这个帧。
OSI模型中网络层的功能就是用来寻址的,那么面对总线或者交换架构下的多个节点,各个节点之间又是如何区分对方呢?只有解决了这个问题,才能继续,否则是没有意义的。SCSI协议利用了一个SCSI ID的概念来区分每个节点。在Ultra 320 SCSI协议中,一条SCSI总线上可以存在16个节点,其中SCSI控制器占用一个节点,SCSI ID被恒定设置为7。其他15个节点的SCSI ID可以随便设置但是不能重复。这16个ID中,7具有最高的优先级。也就是说,如果ID7要发起传输,则其他15个ID都必须乖乖把总线的使用权让给它。图3-19是SCSI总线ID优先级示意图。

图3-19 SCSI总线ID优先级示意图
由于总线是一种共享的线路,总线上的每个节点都会同时感知到这条线路上的电位信号,所以同一时刻只能由一个节点向这条总线上放数据,也就是给这条线路加一个高电位或者低电位。其他所有节点都能感知到这个电位的增降,但是只有接受方节点才会将感知到的电位增降信号保存到自己的缓存中,这些保存下来的信号就是数据。电路上是高电位则接受方会保存为1,低电位则保存成0,反过来保存也可以。图3-20所示的一个只有两条导线的总线网络(实际中的总线远远不止两条导线),其中总线终结电阻的作用是终结导线上的电位信号。

图3-20 SCSI总线ID
图3-21是一个32位数据总线的SCSI ID与其优先级以及导线的对应表。
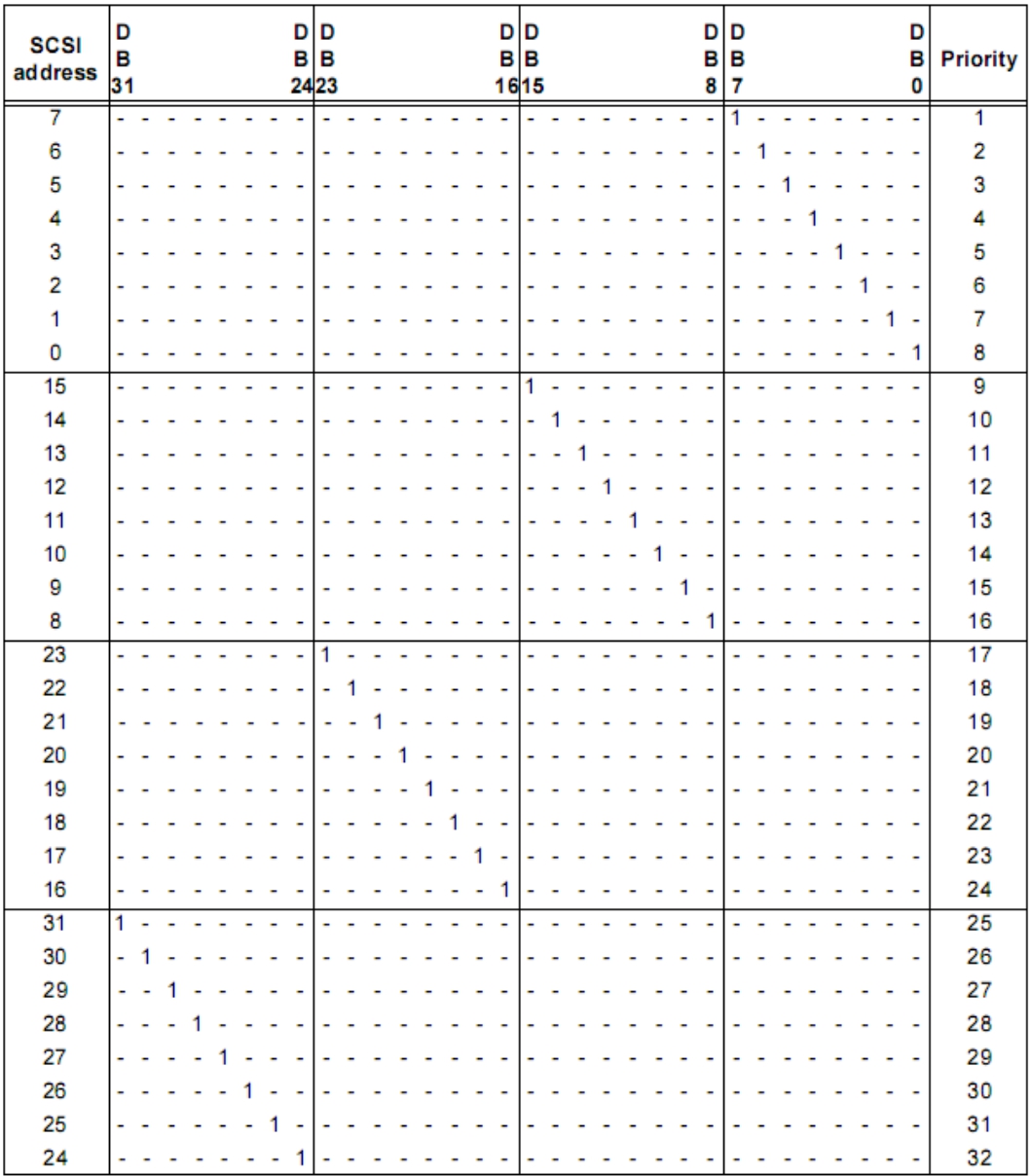
图3-21 SCSI ID与其优先级以及导线的对应表
那么这些节点是如何知道现在正在通信的两个节点之中有没有自己呢?要了解当前线路上是不是自己在通信,或者自己想争夺线路的使用权而通告其他节点,这个过程叫做仲裁。有总线的地方就有仲裁,因为总线是共享的,各个节点都申请使用,所以必须有一个仲裁机制。SCSI接口并不只有8或者16条数据线,还有很多控制信号线。
普通台式机主板一般不集成SCSI控制器,如果想接入SCSI磁盘,则必须增加SCSI卡。SCSI卡一端接入主机的PCI总线,另一端用一个SCSI控制器接入SCSI总线。卡上有自己的CPU(频率很低,一般为RISC架构),通过执行ROM中的代码来控制整个SCSI卡的工作。经过这样的架构,SCSI卡将SCSI总线上的所有设备经过PCI总线传递给内存中运行着的SCSI卡的驱动程序,这样操作系统便会知道SCSI总线上的所有设备了。如果这块卡有不止一个SCSI控制器,则每个控制器都可以单独掌管一条SCSI总线,这就是多通道SCSI卡。通道越多,一张卡可接入的SCSI设备就越多。
图3-22是SCSI总线接入计算机总线的示意图。
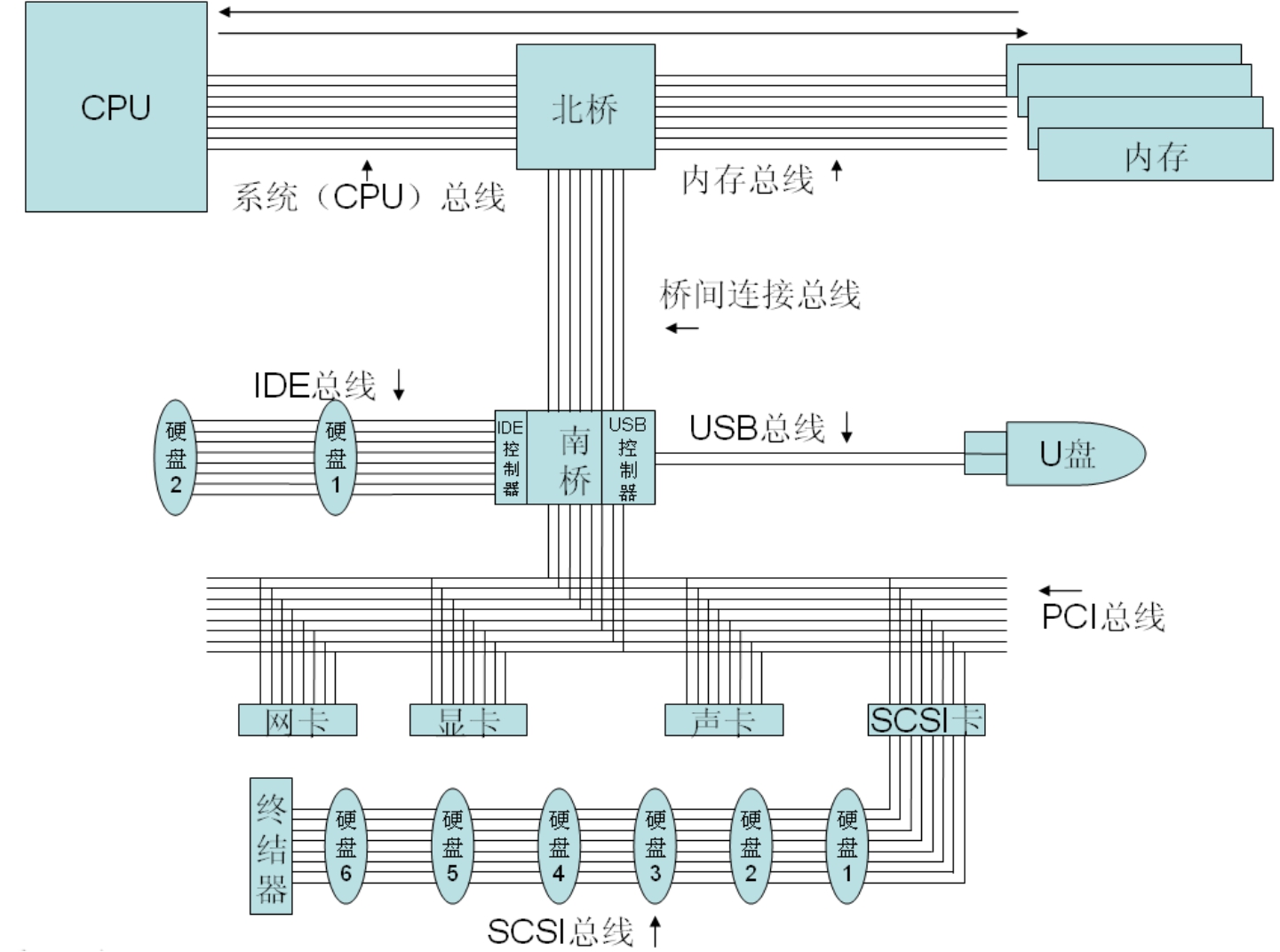
图3-22 SCSI总线与计算机总线
(1)空闲阶段
总线一开始是处于一种空闲状态,没有节点要发起通信。总线空闲的时候,BSY和SEL这两条控制信号线的状态都为False状态(用一个持续的电位表示),此时任何节点都可以发起通信。
(2)仲裁阶段
节点是通过在8条或者16条数据总线上(8位宽SCSI有8条,16位宽SCSI有16条)提升自己对应的那条线路的电位来申请总线使用权的。提升自己ID对应线路的电位的同时,这个节点也提升BSY线路的电位。每个ID号对应这8条或者16条线中的一条。SCSI设备上都有跳线用来设置这个设备的ID号。跳线设置好之后,这个设备每次申请仲裁都只会在SCSI接口的8条或16条数据线中的对应它自身ID的那条线上提升电位。如果同时有多个节点提升了各自线路上的电位,那么所有发起申请的节点均判断总线上的这些信号,如果自己是最高优先级的,那么就持续保留这个信号。而其他低优先级的节点一旦检测到高优先级的ID线路上有信号,则立即撤销自身的信号,回到初始状态等待下轮仲裁,而最高优先级的ID就在这轮仲裁中获胜,取得总线的使用权,同时将SEL信号线提升电位。
SCSI总线的寻址方式,按照控制器-通道-SCSI ID-LUN ID来寻址。LUN是个新名词,全称是Logical Unit Number,后文会对它进行描述。
先看一下控制器一级寻址。控制器就是指SCSI控制器,这个控制器集成在南桥上,或者独立于某个PCI插卡。但不管在哪里,它们都要连接到主机IO总线上。有IO端口,就可以让CPU访问到。一个主机IO总线上不一定只有一个SCSI控制器,可以有多个,比如插入多张SCSI卡到主板,那么就会在Windows系统的设备管理器中发现多个SCSI控制器。系统会区分每个控制器。
每个控制器又可以有多个通道。通道也就是SCSI总线,一条SCSI总线就是一个通道。那么多条SCSI总线(通道)可以被一个控制器管理么?答案是肯定的,这个物理控制器会被逻辑划分为多个虚拟的、可以管理多个通道(SCSI总线)的控制器,称为多通道控制器。目前市场上有的产品可以将4个通道集成到一个单独的SCSI卡上。不仅仅SCSI控制器可以有多通道,IDE控制器也有通道的概念。我们知道,普通台式机主板上一般会有两个IDE插槽,一个IDE插槽可以连接两个IDE设备,但是设备管理器中只有一个IDE控制器,如图3-23所示。也就是说一个控制器掌管着两个通道,每个通道(总线)上都可以接入两个IDE设备。
图3-23 Windows中的IDE控制器
常说的“单通道SCSI卡”和“双通道SCSI卡”,就是指上面可以接几条SCSI总线。当然通道数目越多,能接入的SCSI设备也就越多。
每个通道(总线)上可以接入8或16个SCSI设备,所以必须区分开每个SCSI设备。SCSI ID就是针对每个设备的编号,每个通道上的设备都有自己的ID。不同通道之间的设备ID可以相同,并不影响它们的区分,因为它们的通道号不同。如图3-24所示为多通道控制器示意图。

图3-24 多通道控制器示意图
图3-25中所示的机器安装了一块LSI的SCSI卡,但是显示为两个设备,这两个设备就是两个通道。

图3-25 Windows中的SCSI控制器
其中一个在第3号PCI总线上的第三个设备(第三个PCI插槽)上。功能0指的就是0号通道,如图3-26所示。
另一个也在第3号PCI总线上的第三个设备(第三个PCI插槽)上,表明这个设备也在同一块SCSI卡上。功能1指的是1号通道,如图3-27所示。

图3-26 Windows中的控制器通道号(1)

图3-27 Windows中的控制器通道号(2)
然而,SCSI ID并不是SCSI总线网络中的最后一层地址,还有一个LUN ID。这个是做什么用的呢?难道一个SCSI ID,也就是一个SCSI设备,还可以再划分?是的,可以再分!再分就不是物理上的分割了,总不能把一个SCSI设备掰开两半吧。只能在逻辑上分,每个SCSI ID下面可以再区分出来若干个LUN ID。控制器初始化的时候,会对每个SCSI ID上的设备发出一条Report LUN指令,用来收集每个SCSI ID设备的LUN信息。这样,一条SCSI总线上可接入的最终逻辑存储单元数量就大大增加了。LUN对传统的SCSI总线来说意义不大,因为传统SCSI设备本身已经不可物理上再分了。如果一个物理设备上没有再次划分的逻辑单元,那么这个物理设备必须向控制器报告一个LUN0,代表物理设备本身。对于带RAID功能的SCSI接口磁盘阵列设备来说,由于会产生很多的虚拟磁盘,所以只靠SCSI ID是不够的,这时候就要用到LUN来扩充可寻址的范围,所以习惯上称磁盘阵列生成的虚拟磁盘为LUN。关于RAID和磁盘阵列会分别在本书的第4~6章中介绍。
(3)选择阶段
仲裁阶段之后,获胜的节点会将BSY和SEL信号线置位,然后将8或16条数据总线上对应它自身ID的线路和对应它要通信的目标ID的线路的电位提升,这样目的节点就能感知到它自己的线路上来了信号,开始做接收准备。
提示: SCSI控制器也是总线上的一个节点,它的优先级必须是最高的,即等于7,因为控制器需要掌控整条总线。
总线上最常发生的是控制器向其他节点发送和接收数据,而除控制器之外的其他节点之间交互数据,一般是不会发生的。如果要从总线上的一块硬盘复制数据到另一块硬盘,那也必须先将数据发送到控制器,控制器再复制到内存,经过CPU运算后再次发给控制器,然后控制器再发给另外一块硬盘。经过这么长的路径而不直接让这两块硬盘建立通信,原因就是硬盘本身是不能感知文件这个概念的,硬盘只理解SCSI语言,而SCSI语言是处理硬盘LBA块的,即告诉硬盘读或者写某些LBA地址上的扇区(块),而不可能告诉硬盘读写某个文件。文件这个层次的功能是由运行在主机上的文件系统代码所实现的,所以硬盘必须将数据先传送到主机内存由文件系统处理,然后再发向另外的硬盘。
这就是SCSI的网络层。每个节点都在有条不紊地和控制器交互着数据。
OSI模型中的传输层的功能就是保障此端的数据成功地传送到彼端。与链路层不同的是,链路层只是保障线路两端数据的传送,而且一旦某个帧出错,链路层程序本身不会重新传送这个帧。所以,需要有一个端到端的机制来保障传输,这个机制是运行在通信双方最终的两端的,而不是某个链路的两端。
图3-28显示了SCSI协议是如何保障每个指令都被成功传送到对方的。
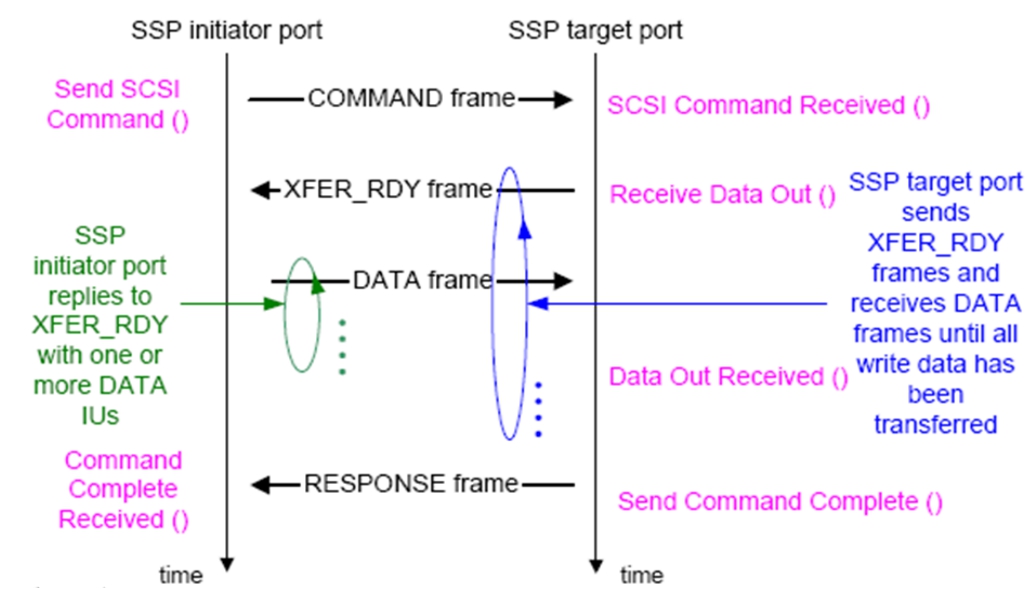
图3-28 控制器向设备发送数据(写入数据)
发起方在获得总线仲裁之后,会发送一个SCSI Command写命令帧,其中包含对应的LUN号以及LBA地址段。接收端接收后,就知道下一步对方就要传输数据了。接收方做好准备后,向发起方发送一个XFER_RDY帧,表示已经做好接收准备,可以随时发送数据。
发起方收到XFER_RDY帧之后,会立即发送数据。每发送一帧数据,接收方就回送一个XFER_RDY帧,表示上一帧成功收到并且无错误,可以立即发送下一帧,直到数据发送结束。
接收方发送一个RESPONSE帧来表示这条SCSI命令执行完毕。
图3-29是一个SCSI读过程的示意图。
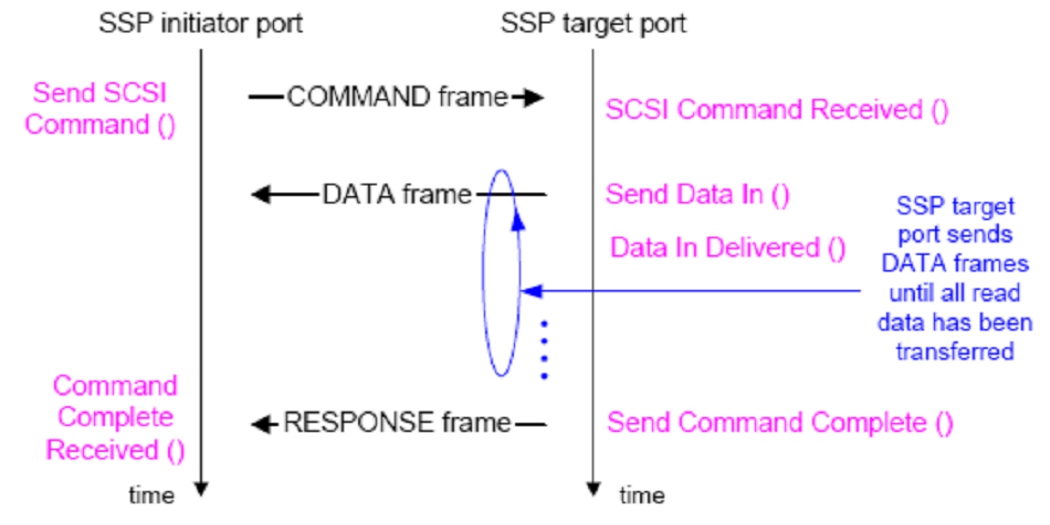
图3-29 控制器向设备读取数据
发起方在获得总线仲裁之后,会发送一个SCSI Command读命令帧。接收端接收后,立即将该命令中给出的LUN以及LBA地址段的所有扇区的数据读出,传送给发起端。
所有数据传输结束后,目标端发送一个RESPONSE帧来表示这条SCSI命令执行完毕。
SCSI协议语言就是利用这种两端节点之间相互传送一些控制帧,来达到保障数据成功传输的目的。
会话层、表示层和应用层是OSI模型中最上面的三层,是与底层网络通信语言无关的,底层语言没有必要了解上层语言的含义。有没有会话层,完全取决于利用这个协议进行通信的应用程序。这里我们就不再详述了。
硬盘的接口包括物理接口,也就是硬盘接入到磁盘控制器上需要用的接口,具体的针数、某个针的作用等。除了物理接口规范之外,还定义了一套指令系统,叫做逻辑接口。磁盘通过物理线缆和接口连接到磁盘控制器之后,若想在磁盘上存放一个字母应该怎么操作?这是需要业界定义的很重要的东西。指令集定义了“怎样向磁盘发送数据和从磁盘读取数据以及怎样控制其他行为”,比如SCSI和ATA指令。其中,逻辑接口,也就是SCSI或者ATA指令集部分,指令实体内容是需要由运行于操作系统内核的驱动程序来生成的,而物理接口的连接,就是磁盘控制器芯片需要负责的,比如ATA控制器或SCSI控制器。磁盘控制器的作用是参与底层的总线初始化、仲裁等过程以及指令传输过程、指令传输状态机、重传、ACK确认等,将这些太过底层的机制过滤掉,从而向驱动程序提供一种简洁的接口。驱动程序只要将要读写的设备号、起始地址等信息,也就是指令描述块(Command Description Block,CDB)传递给控制器即可,控制器接受指令并做相应动作,将执行后的结果信号返回给驱动程序。
应该将磁盘控制器和磁盘驱动器的控制电路区别开来,二者是作用于不同物理位置的。磁盘驱动器控制电路位于磁盘驱动器上,它专门负责直接驱动磁头臂做运动来读写数据:而主板上的磁盘控制器专门用来向磁盘驱动器的控制电路发送指令,从而控制磁盘驱动器读写数据。由磁盘控制器对磁盘驱动器发出指令,进而操作磁盘,CPU做的仅仅是操作控制器就可以了。来梳理一下这个结构,CPU通过主板上的导线发送SCSI或者ATA指令(CDB)给同样处于主板上的磁盘控制器,磁盘控制器继而通过线缆将指令发送给磁盘驱动器并维护底层指令交互状态机,由磁盘驱动器解析收到的指令从而根据指令的要求来控制磁头臂。
SCSI或者ATA指令CDB是由OS内核的磁盘控制器驱动程序生成并发送的。CPU通过执行磁盘控制器驱动程序,生成指令发送给磁盘控制器,控制器收到这些CDB后,会做一定程度的翻译映射工作,生成最底层的磁盘可接受的纯SCSI指令,然后通过底层的物理操作,比如总线仲裁,然后编码,再在线缆上将指令发送给对应的磁盘。
那么机器刚通电,操作系统还没有启动起来并加载磁盘控制器驱动的时候,此时是怎么访问磁盘的呢?CPU必须执行磁盘通道控制器驱动程序才能与控制器交互,才能读写数据。所以,系统BIOS中存放了初始化系统所必需的基本代码。系统BIOS初始化过程中有这么一步,就是去发现并执行磁盘控制器的Optional ROM(该ROM被保存在磁盘通道控制器中或者单独的Flash芯片内),该ROM内包含了该控制器的最原始的、可在主BIOS下执行的驱动程序,主BIOS载入并执行该ROM,从而就加载了其驱动程序,也就可以与控制器进行交互了。最后主BIOS通过执行驱动程序而使得CPU可以发送对应的读指令,提取磁盘的0磁道的第一个扇区中的代码载入内存执行,从而加载OS。
系统BIOS(主BIOS)中是包含常用的磁盘控制器驱动程序的,但是对于一些不太常用的较高端的板载控制器或者PCIE卡形式的控制卡,主BIOS一般不包含其驱动,所以必须主动加载其Optional ROM才能在主BIOS下驱动。如果根本不需要在主BIOS下使用该控制器,那么就不必加载Optional ROM。在OS内核启动过程中,会用高性能的驱动程序来接管BIOS中驻留的驱动程序。当然,BIOS中也要包含键盘驱动,如果支持USB移动设备启动,还要有USB驱动。
图3-30显示了磁盘控制器驱动程序、磁盘控制器和磁盘驱动器控制电路三者之间的关系。控制器驱动程序负责将上层下发的SCSI/ATA指令传递给控制器硬件。

图3-30 磁盘控制器驱动程序、磁盘控制器和磁盘驱动器控制电路三者的关系
安装操作系统时,安装程序要求必须加载完整的磁盘控制器驱动程序之后才可以识别到控制器后面的磁盘从而才可以继续安装。此时虽然系统BIOS里的基本简化驱动已经可以向磁盘进行读写操作,但是其性能是很差的,基本都使用Int13调用方式;而现代操作系统都抛弃了这种方式,所以安装操作系统过程中必须加载完整驱动才可以获得较高的性能。至于系统安装完后的启动过程,一开始必须由BIOS来将磁盘的0磁道代码读出执行以便加载操作系统,使用的是简化驱动,启动过程中,OS的完整驱动会替代掉BIOS的简化驱动被加载。
提示: 本书第9章会详细描述SAN Boot的启动过程以及磁盘控制器驱动程序的详细架构。
磁盘的内部传输速率指的是磁头读写磁盘时的最高速率。这个速率不包括寻道以及等待扇区旋转到磁头下所耗费时间的影响。它是一种理想情况,即假设磁头读写的时候不需要换道,也不专门读取某个扇区,而是只在一个磁道上连续地循环读写这个磁道的所有扇区,此时的速率就叫做硬盘的内部传输速率。
通常,每秒10000转的SCSI硬盘的内部传输速率的数量级大概在1000MB/s左右。但是为何实际使用硬盘的时候,比如复制一个文件,其传输速率充其量只是每秒几十兆字节呢?原因就是磁头需要不断换道。
想象: 闪电侠正在做数学题,假设我们不打断他,他每秒能连续做100道题,此时我们每隔0.1秒,就和他交谈打断他一次,每次交谈的时间是0.5秒。也就是说闪电侠实际上做数学题的时间是每隔0.5秒做一次,每次只能做0.1秒的时间。这样,每0.6秒闪电侠只能做10道题,那么可以计算出闪电侠实际每秒能做的数学题只有区区16道,这和我们不打断他时的每秒100道题相比差了6倍多。
同样,磁盘也是这个道理,我们不断地用换道来打断磁头。磁头滑过盘片一圈,只需要很短的时间,而换道所需的时间远远比盘片旋转一圈耗费的时间多,所以造成磁盘整体外部传输速率显著下降。有人问,必须要换道么?如果要读写的数据仅仅在一条磁道上,那是可以获得极高的传输速率的,但是这并不容易实现。如今,随着硬盘容量的加大,应用程序产生的文件更是在肆无忌惮地加大,动辄几十、几百兆甚至上GB大小,敢问这种文件用一个磁道能放下么?显然不能。
所以,磁头必须不断地被“打断”去进行换道操作,整体传输速率就会大大降低。实际中一块10000转的SCSI硬盘的实际外部传输速率也只有80MB/s左右(最新的15000转的SAS硬盘外部传输率最大已经可以达到200MB/s)。为了避免磁头被不断打断的问题,人们发明了RAID技术,让一个硬盘的磁头在换道时,另一个磁盘的磁头在读写。如果有很多磁盘联合起来,同一时刻总有某块硬盘的磁头在读写状态而不是都在换道状态,这就相当于一个大虚拟磁盘的磁头总是处于读写状态,所以RAID可以显著提升传输速率。不仅如此,如果我们将RAID阵列再次进行联合,就能将速率在RAID提速的基础上,再次成倍地增加。这种工作,就需要大型磁盘阵列设备来做了。
提示: RAID技术的细节在本书第4章详细阐述;磁盘阵列技术将在本书第6章介绍。
磁头从盘片上将数据读出,然后存放到硬盘驱动器电路板上的缓存芯片内,再将数据从缓存内取出,通过外部接口传送给主板上的硬盘控制器。从外部接口传送给硬盘控制器时的传输速率,就是硬盘的外部传输速率。这个动作是由硬盘的接口电路来发起和控制的。接口电路和磁头控制电路是不同的部分,磁头电路部分是超精密高成本的部件,可以保证磁头读写时的高速率。但是因为磁头要被不断地打断,所以外部接口传输速率无须和磁头传输速率一样,只要满足最终的实际速率即可。外部接口的速率通常大于实际使用中磁头读写数据的速率(计入换道的损失)。
来举一个例子,有8个数字从1到8,需要传送给对方。此时我们可以与对方连接8条线,每条线上传输一个字符,这就是并行传输。并行传输要求通信双方之间的距离足够短。因为如果距离很长,那么这8条线上的数字因为导线电阻不均衡以及其他各种原因的影响,最终到达对方的速度就会显现出差距,从而造成接收方必须等8条线上的所有数字都到达之后,才能发起下一轮传送。
并行传输应用到长距离的连接上就无优点可言了。首先,在长距离上使用多条线路要比使用一条单独线路昂贵;其次,长距离的传输要求较粗的导线,以便降低信号的衰减,这时要把它们捆到一条单独电缆里相当困难。IDE硬盘所使用的40或者80芯电缆就是典型的并行传输。40芯中有32芯是数据线,其他8芯是承载其他控制信号用的。所以,这种接口一次可以同时传输32b的数据,也就是4B。
提示: IO延迟与Queue Depth
IO延迟是指控制器将IO指令发出之后,直到IO完成的过程中所耗费的时间。目前业界有不成文的规定;只要IO延迟在20ms以内,此时IO的性能对于应用程序来说都是可以接受的,但是如果延迟大于20ms,应用程序的性能将会受到比较大的影响。
我们可以推算出,存储设备应当满足的最低IOPS要求应该为1000/20=50,即只要存储设备能够提供每秒50次IO,则就能够满足IO延迟小于等于20ms的要求。但是每秒50次,这显然太低估存储设备的能力了。
单块SATA硬盘能够提供最大两倍于这个最低标准的数值,而FC磁盘则可以达到4倍于这个数值。对于大型磁盘阵列设备,由若干磁盘共同接受IO,加上若干个IO通道并行工作,目前中高端设备达到十几万的IOPS已经不成问题。
然而,不能总以最低标准来要求存储设备。当接受IO很少的时候,IO延迟一般会很小,比如1ms甚至小于1ms。此时,每个IO通道的IOPS=1000/1=1000,这个数值显然也不对,上文所述的几十万IOPS,如果每个IO通道仅提供1000的IOPS,那么达到几十万,需要几百路IO通道,这显然不切实际。那么几十万的IOPS是怎么达到的呢?这就引出了另一个概念:Queue Depth。
控制器向存储设备发起的指令,不是一条一条顺序发送的,而是一批一批地发送,存储目标设备批量执行IO,然后将数据和结果返回控制器。也就是说,只要存储设备肚量和消化能力足够,在IO比较少的时候,处理一条指令和同时处理多条指令将会耗费几乎相同的时间。控制器所发出的批量指令的最大条数,由控制器上的Queue Depth决定。如果连接外部独立磁盘阵列,则一般主机控制器端可以将其Queue Depth设置为64、128等值,视情况而定。
如果给出Queue Depth、IOPS、IO延迟三者中的任意两者,则可以推算出第三者,公式为:IOPS=(Queue Depth)/(IO Latency)。实际上,随着Queue Depth的增加,IO延迟也会随即增加,二者是互相促进的关系,所以,随着IO数目的增多,将很快达到存储设备提供的最大IOPS处理能力,此时IO延迟将会陡峭地升高,而IOPS则增加缓慢。好的存储系统,其IO延迟的增加应该是越缓慢越好,也就是说存储设备内部应该具有快速IO消化能力。而对于消化不良的存储设备,其IO延迟将升高得很快,以至于在IOPS较低时,IO延迟已经达到了20ms的可接受值。消化能力再高,也有饱和的时候。图3-31所示为IO延迟与Queue Depth示意图。
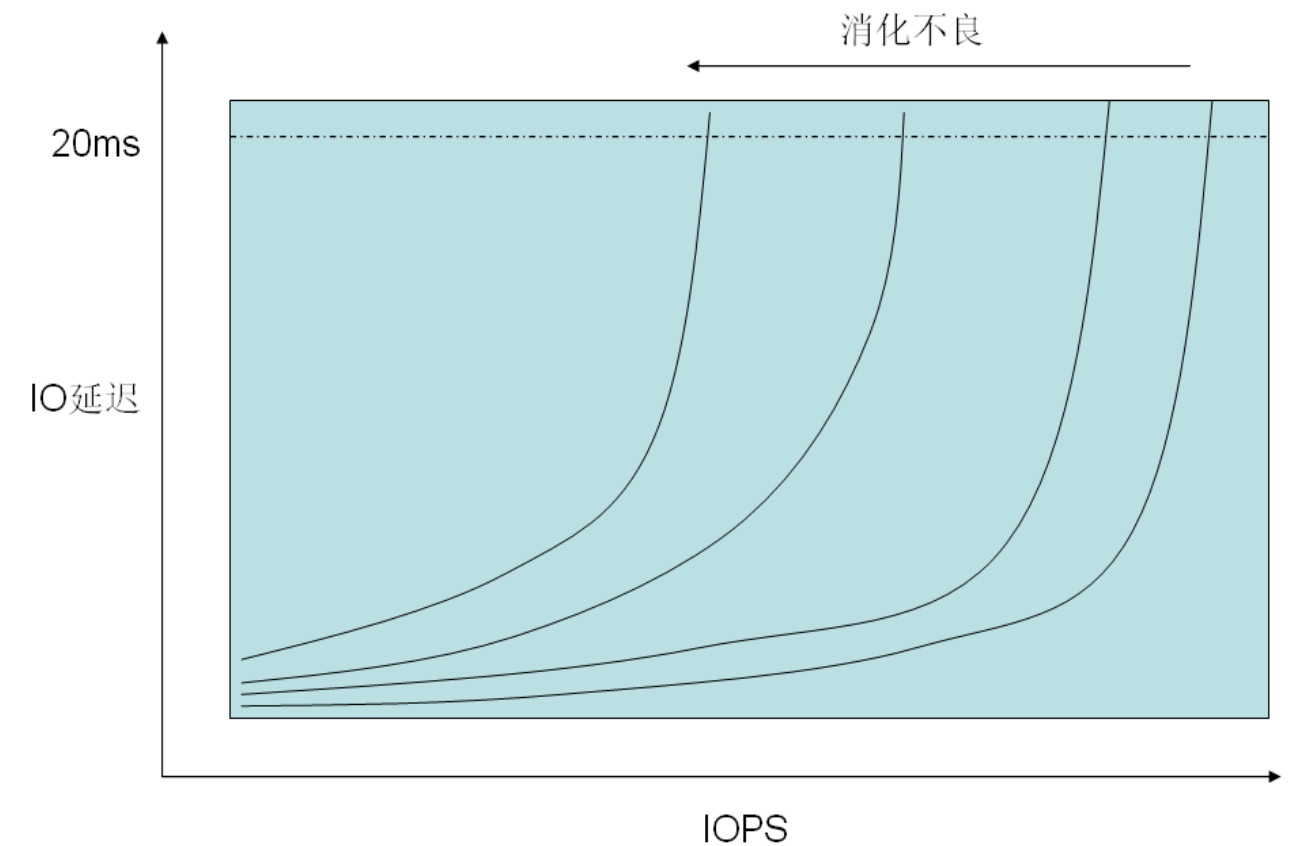
图3-31 IO延迟与Queue Depth示意图
还是上面的例子,如果只用一条连线来连接到对方,则我们依次在这条线上发送这8个数字,需要发送8次才能将数字全部传送到对方。串行传输在效率上,显然比并行传输低得多。但是串行也有串行的优势,就是凭借这种优势使得硬盘的外部接口已经彻底被串行传输所占领。USB接口、IEEE 1394接口和COM接口,这些都是串行传输的计算机外部接口。
并行传输表面上看来比串行传输效率要高很多倍,但是并行传输有不可逾越的技术困难,那就是它的传输频率不可太高。由于在电路高速震荡的时候,数据线之间会产生很大的干扰,造成数据出错,所以必须增加屏蔽线。即使加了屏蔽线,也不能保证屏蔽掉更高的频率干扰。所以并行传输效率高但是速度慢。而串行传输则刚好相反,效率是最低的,每次只传输一位,但是它的速度非常高,现在已经可以达到10Gb/s的传输速率,但传输导线不能太多。
这样算来,串行传输反而比并行传输的总体速率更快。串行传输不仅仅用于远距离通信,现在就连PCI接口都转向了串行传输方式。PCIE接口就是典型的串行传输方式,其单条线路传输速率高达2.5Gb/s,还可以在每个接口上将多条线路并行,从而将速率翻倍,比如4X的PCIE最高可达16X,也就是说将16条2.5Gb/s的线路并行连接到对方。这仿佛又回到了并行时代,但是也只有在短距离传输上,比如主板上的各个部件之间,才能承受如此高速的并行连接,远距离传输是达不到的。
磁盘的IOPS,也就是每秒能进行多少次IO,每次IO根据写入数据的大小,这个值也不是固定的。如果在不频繁换道的情况下,每次IO都写入很大的一块连续数据,则此时每秒所做的IO次数是比较低的;如果磁头频繁换道,每次写入数据还比较大的话,此时IOPS应该是这块硬盘的最低数值了;如果在不频繁换道的条件下,每次写入最小的数据块,比如512B,那么此时的IOPS将是最高值;如果使IO的payload长度为0,不包含开销,这样形成的IOPS则为理论最大极限值。IOPS随着上层应用的不同而有很大变化。
提示: 如何才算一次IO呢?这是很多人都没有弄清楚的问题,也是定义很混乱的一个问题。其根本原因就在于一次IO在系统路径的每个层次上都有自己的定义。整个系统是由一个一个的层次模块组合而成的,每个模块之间都有各自的接口,而在接口间流动的数据就是IO。那么如何才算“一次”IO呢?以下列举了各个层次上的“一次”IO的定义。
应用程序向操作系统请求:“读取C:\read.txt到我的缓冲区”。操作系统读取后返回应用程序一个信号,这次IO就完成了。这就是应用程序做的一次IO。
文件系统向磁盘控制器驱动程序请求:“读取从LBA10000开始的后128个扇区”,然后“请读取从LBA50000开始的后64扇区”,这就是文件系统向下做的两次IO。这两次IO,假设对应了第一步里那个应用程序的请求。
磁盘控制器驱动程序用信号来驱动磁盘控制器向磁盘发送SCSI指令和数据。对于SCSI协议来说,完成一次连续LBA地址扇区的读写就算一次IO。但是为了完成这次读或者写,可能需要发送若干条SCSI指令帧。从最底层来看,每次向磁盘发送一个SCSI帧,就算一次IO,这也是最细粒度的IO。但是通常说磁盘IO都是指完成整个一次SCSI读或者写。
如果在文件系统和磁盘之间再插入一层卷管理层,或在磁盘控制器和磁盘之间再插入一层RAID虚拟化层,那么上层的一次IO就往往会演变成下层的多次IO。
对于磁盘来说,每次IO就是指一次SCSI指令交互回合。一个回合中可能包含了若干SCSI指令,而这一个回合里却只能完成一次IO,比如“读取从LBA10000开始的后128个扇区”。
例如,写入10 000个大小为1KB的文件到硬盘上,耗费的时间要比写入一个10MB大小的文件多得多,虽然数据总量都是10MB。因为写入10 000个文件时,根据文件分布情况和大小情况,可能需要做好几万甚至十几万次IO才能完成。而写入一个10MB的大文件,如果这个文件在磁盘上是连续存放的,那么只需要几十个IO就可以完成。
对于写入10 000个小文件的情况,因为每秒需要的IO非常高,所以此时如果用具有较高IOPS的磁盘,将会提速不少。而写入一个10MB文件的情况,就算用了有较高IOPS的硬盘来做,也不会有提升,因为只需要很少的IO就可以完成了,只有换用具有较大传输带宽的硬盘,才能体现出优势。
同一块磁盘在读写小块数据的时候速度是比较高的;而读写大块数据的时候速度比较低,因为读写花费的时间变长了。15000转的硬盘比10000转的硬盘性能要高。图3-32所示为磁盘IOPS性能与IO SIZE的关系曲线。

图3-32 磁盘IOPS性能与IO SIZE的关系曲线
传输带宽指的是硬盘或设备在传输数据的时候数据流的速度。还是刚才那个例子,如果写入10 000个1KB的文件需要10s,那么此时的传输带宽只能达到每秒1MB,而写入一个10MB的文件用了0.1s,那么此时的传输带宽就是100MB/s。所以,即使同一块硬盘在写入不同大小的数据时,表现出来的带宽也是不同的。具有高带宽规格的硬盘在传输大块连续数据时具有优势,而具有高IOPS的硬盘在传输小块不连续的数据时具有优势。
同样,对于一些磁盘阵列来说,也有这两个规格。一些高端产品同时具备较高的IOPS和带宽,这样就可以保证在任何应用下都能表现出高性能。
固态存储在这几年来开始大行其道,其在性能方面相对机械磁盘来讲有着无与伦比的优势,比如,没有机械寻道时间,对任何地址的访问耗费开销都相等,所以随机IO性能很好。关于SSD的一些性能指标,本节不再列出。
但是SSD也存在一些致命的缺点,现在我们就来了解一下固态存储。
提示: 关于固态硬盘的一些细节标准和操作指南请参考《固态硬盘火力全开——超高速SSD应用详解与技巧》,清华大学出版社。
SSD(Solid State Drive)是一种利用Flash芯片或者DRAM芯片作为数据永久存储的硬盘,这里不可以再说磁盘了,因为Flash Drive不再使用磁技术来存储数据。利用DRAM作为永久存储介质的SSD,又可称为RAM-Dsk,其内部使用SDRAM内存条来存储数据,所以在外部电源断开后,需要使用电池来维持DRAM中的数据。现在比较常见的SSD为基于Flash介质的SSD。所有类型的ROM(比如EPROM、EEPROM)和Flash芯片使用一种叫做“浮动门场效应晶体管”的晶体管来保存数据。每个这样的晶体管叫做一个“Cell”,即单元。有两种类型的Cell:第一种是Single Level Cell(SLC),每个Cell可以保存1bit的数据;第二种为Multi Level Cell(MLC),每个Cell可以保存2bit的数据。MLC容量为SLC的两倍,但是成本却与SLC大致相当,所以相同容量的SSD,MLC芯片成本要比SLC芯片低很多。此外,MLC由于每个Cell可以存储4个状态,其复杂度比较高,所以出错率也很高。不管SLC还是MLC,都需要额外保存ECC校验信息来做数据的错误恢复。
我们来看一下这种场效应晶体管为何可以保存数据。由于计算机的数据只有0和1两种形式,那么只要让某种物质的存在状态只有两种,并且可以随时检测其状态,那么这种物质就可以存储1bit数据。磁盘使用一块磁粒子区域来保存1或者0,那么对于芯片来讲用什么来表示呢?当然非电荷莫属。比如充满电表示0,放电后表示1(这里指电子而不是正电荷)。浮动门场效应晶体管就是利用这种方法。
如图3-33所示,浮动门场效应管由Controler Gate(CG)、Floating Gate(FG)、半导体二氧化硅绝缘层以及输入端源极和输出端汲极触点等逻辑元件组成。浮动门是一块氮氧化物,其四周被二氧化硅绝缘层包裹着,其外部为另一个门电路(即控制门)。在Word Line(字线)上抬高电势,会在S和D之间区域感生出一个电场,从而导通S和D、S和D之间有电流通过,这会使一部分电子穿过绝缘层到达浮动门内的氮氧化物,在这个充电过程中,电子电荷被存储在了浮动门中。随后Word Line恢复电势,控制门断开电场,但是此时电子仍然在被绝缘层包裹的浮动门电路中,所以此时浮动门被充电,并且这些电荷可以在外部电源消失之后依然依然可以保存一段时间。不同规格的Flash其保存时间不同,通常为数个月。这为系统设计带来了复杂性,Flash控制器必须确保每个Cell在电荷逐渐泄露到无法感知之前,恢复其原先的状态,也就是重新充电。而且要逐渐调整感知时间,由于对Cell的读操作是通过预充电然后放电来比对基准电压,进而判断1或0的,如果其中的电荷所剩不多,那么感知基准电压的变化就需要更长的等待时间,控制器需要精确的做预判才可以保证性能。
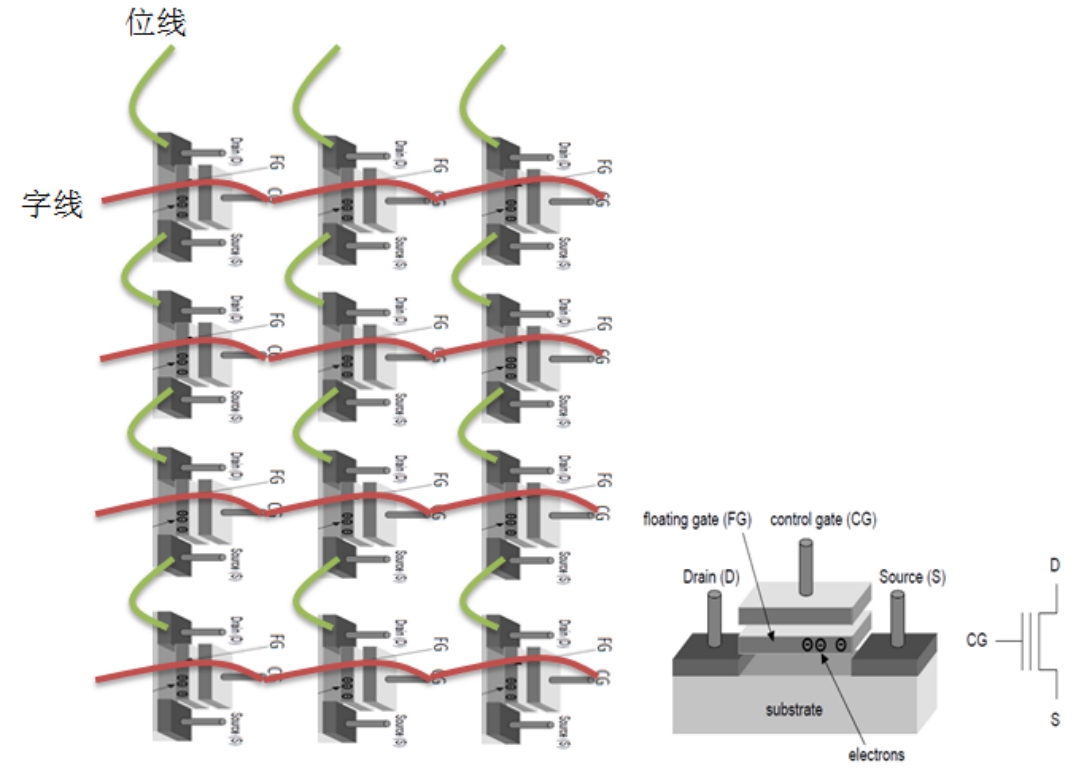
图3-33 浮动门结构
所谓“浮动门”(Floating Gate,FG)的名称也就是由此而来的,即这块氮氧化物是被二氧化硅绝缘层包裹住而浮动在空中的,如图3-33右图所示,电流从Source极进入,从Drain极流出,浮动门一头与S极接触,一头与D极接触,由于被包裹有绝缘层,当电路电压达到一定阀值之后,可以被击穿导电,从而被充电或者放电。被充电到一定电势阀值的Cell的状态被表示为“0”,如果是MLC,可以保存4个电势状态,分别对应00、01、10、11,MLC能够用一个Cell存储两位,也是这个道理,要存哪个数值,就充电到哪个电势档位。FG上方有一片金属,称为控制门(CG),连接着字线,当需要用这个Cell表示“0”的时候,只需要在控制门上加一个足够高的正电压,导通S和D,产生电流,从而电子从Source-Drain电极穿越冲入到FG中。向FG中充电之后,Cell表示0,将FG放电,Cell表示1。
提示: 这有些难以记忆,因为按照常规思维,充电应当表示1而放电表示0,这里恰好相反。
至此我们了解到:Cell是利用FG中的电势值来与阀值对比从而判断其表示1或者0的。那么是否可以让一个Cell有多个阀值,让每一个阀值都表示一种状态呢?答案是可以。MLC类型的Cell就是这样做的。MLC模式的SSD,其每个Cell具有4个电势阀值,每次充电用特定电路掌握住火候,充到一定阀值之上但是低于下一个阀值,这样,利用4个阀值就可以表示4种状态了,4个阀值依次表示00、01、10、11。要向其写入什么值,只需要向其充多少火候的电就可以了。
如图3-33(物理图)和3-34(抽象图)为Cell阵列的有序排列图。我们可以看到每个Cell串是由多个Cell串联而成的,每个Cell串每次只能读写其中一个Cell,多个Cell串并联则可以并行读写多位数据。通常一个Page中的所有位中的每个位均位于一个Cell串相同的位置上,那么对于一个使用2122B(含ECC)/Page的芯片来讲,就需要16896个Cell串,需要16896条串联导线。如图所示,将每个Cell串上所有Cell串联起来的导线称为“位线”,也就是串联每个Cell的S和D极的那根导线,同时也是电源线;将多个并联的Cell串中相同位置的Cell的CG金属片水平贯穿起来(并联)的那根导线组称为“字线”,这样就组成了一个二维Cell矩阵。

图3-34 Cell阵列的有序排布图
将多个这样的Cell排列在一起形成阵列,就可以同时操作多个比特了。NAND就是利用大量这种Cell有序排列而成的一种Flash芯片。如图3-35所示为一片16GB容量的Flash芯片的逻辑方框图。每4314×8=34512个Cell逻辑上形成一个Page,每个Page中可以存放4KB的内容和218B的ECC校验数据,Page也是Flash芯片IO的最小单位。每128个Page组成一个Block,每2048个Block组成一个区域(Plane),一整片Flash芯片由两个区域组成,一个区域存储奇数序号的Block,另一个则存储偶数序号的Block,两个Plane可以并行操作。Flash芯片的Page大小可以为2122B(含ECC)或者4313B(含ECC),一般单片容量较大的Flash其Page Size也大。相应地,Block Size也会根据单片容量的不同而不同,一般有32KB、64KB、128KB、512KB(不含ECC)等规格,视不同设计而定。
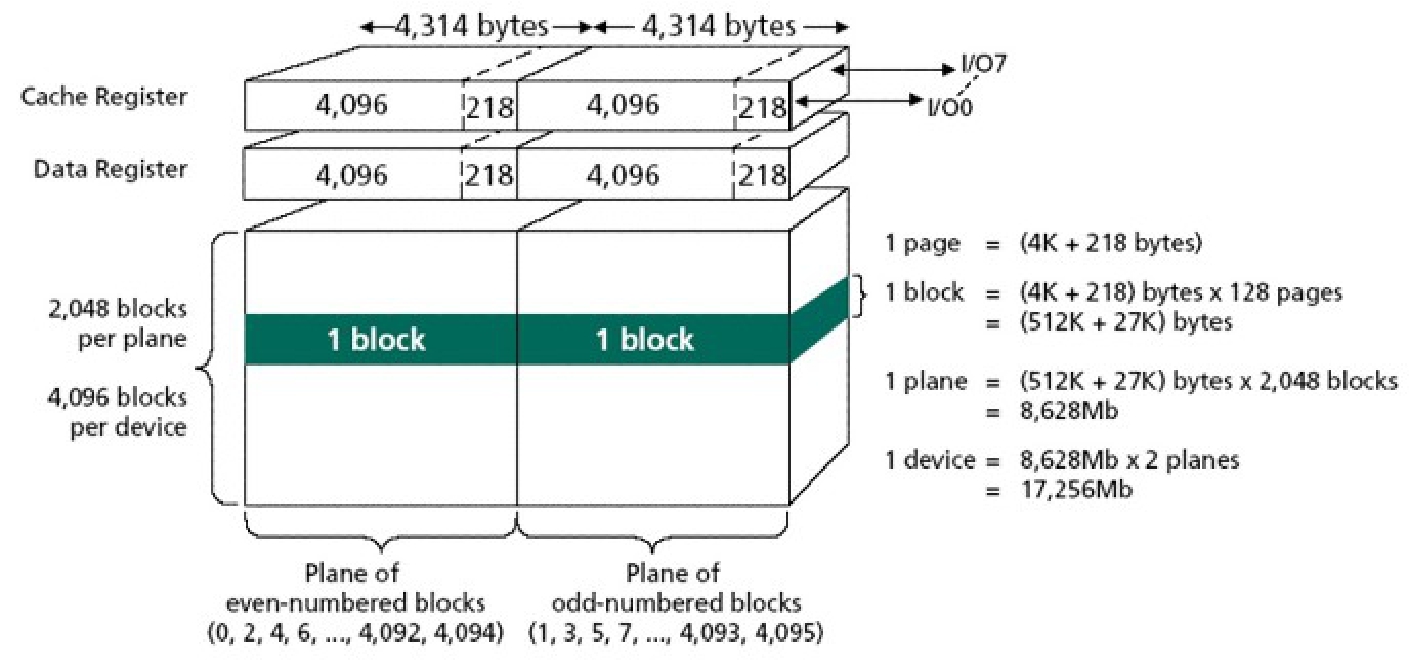
图3-35 Flash芯片逻辑图
如图3-36所示为Intel X-25M固态硬盘的拆机图,可以看到它使用了10片NAND Flash芯片,左上方为SSD控制器,左下方为RAM Buffer。最左侧为SATA物理接口。

图3-36 Cell阵列有序排布图
如图3-37所示为某SSD控制器芯片的方框图。其中包含多个逻辑模块,外围接口部分和底层供电部分我们就不去关心了。这里将目光集中在右半边,其中8051CPU通过将ROM中的Firmware载入IRAM中执行来实现SSD的数据IO和管理功能。Flash Controller负责向所有连接的NAND Flash芯片执行读写任务,每个NAND芯片用8b并行总线与Flash Controller上的每个通道连接,每时钟周期并行传递8b数据。Flash Controller与Flash芯片之间也是通过指令的方式来运作的,地址信息与数据信息都在这8位总线上传送,由于总线位宽太窄,所以一个简单的寻址操作就需要多个时钟周期才能传送完毕。芯片容量越大,那么地址也就越长,寻址时间也就越长,所以,对于小块随机IO,Flash会随着容量的增加而变得越来越低效。新的Flash芯片已经有16b总线的设计了。总线频率目前一般为33MHz,最新也有40MHz的。
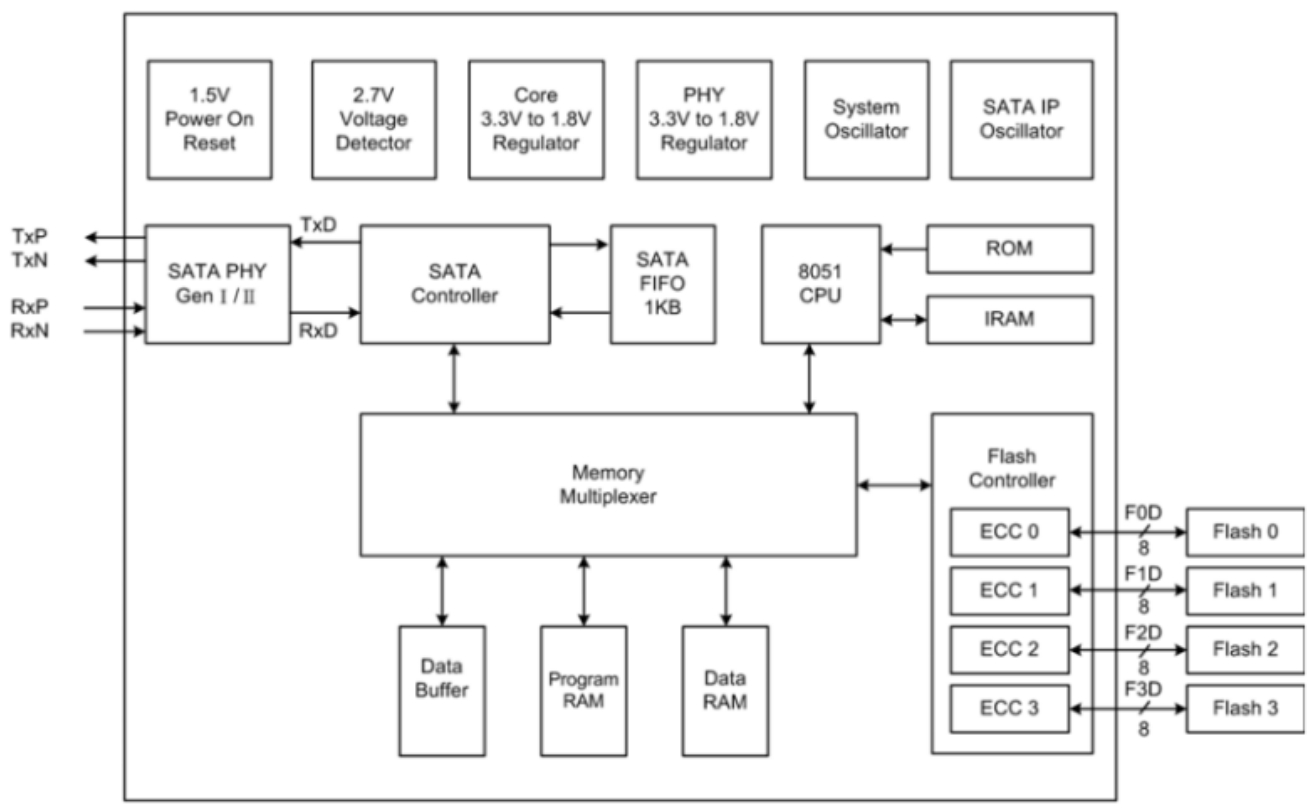
图3-37 Flash控制芯片方框图
对于数据写入来说,待写入的数据必须经过ECC校验之后,将数据和ECC校验信息一并写入芯片;对于数据读取来说,数据会与其对应的ECC信息一起读出并作校验,校验正确后才会通过外部接口发送出去。ECC运算器位于Flash Controller中。整个SSD会有一片很大容量的RAM(相对于机械磁盘来讲),通常是64MB甚至128MB,其原因将在下文讲述。CPU执行的代码相对于机械磁盘来讲也是比较复杂的,关于CPU都需要执行哪些功能,也一并在下文讲述。
MOS的导通并不是非通即断的,就算截止状态,也会有电流漏过,只是非常弱而已。这里还要明确一点,向绝缘层内充电是指充入电子,充入负电荷,栅极电压越负,nMOS就越导不通,也就是说,漏电电流就越弱。如果不充电,反而漏电电流还高一些。
正是在这种前提下,从而可以检测出这种微弱电流的差别,用什么手段?还得SAMP上阵了,老生常谈,首先强制导通未选中的所有Cell的MOS,要读取的MOS栅极不加电压,然后给位线预充电(充正电荷,拉高电平),然后让位线自己漏电,如果对应的Cell里是充了电的(充的是电子负电荷),那么MOS截止性会加强(等效于开启电压升高),漏电很慢(电压相对维持在高位),如果没充电,则漏电很快(电压相对维持在低位),所以最终SAMP比较出这两种差别来,翻译成数字信号就是,充了电=电压下降的慢=电压比放了电的位线高=逻辑1,这么想你就错了。此处你忽略了一点,也就是SAMP不是去比对充了电的Cell位线和没充电的Cell位线,而是把每一根位线与一个参考电压比对,所以,这个参考电压一定要位于两个比对电压之间。具体过程是这样的,假设所有位线预充电结束时瞬间电压为1.0v,然后让位线自然放电(或者主动将位线一端接地放电)一段时间(非常短),在这段时间之后,原先被充了电的Cell其位线压降速度慢,可能到0.8v左右,而原先未被充电的Cell其位线压降速度较快,可能到0.4v左右,每一种Flash颗粒会根据大量测试之后,最终确定一个参考电压,比如0.6v,也就是位于0.4和0.8之间。那么当SAMP比对充电Cell位线时,参考电压小于位线电压,SAMP普遍都是按照参考电压>比对电压则为逻辑,小于则为逻辑0的,所以最终的输出便是,充电Cell反而表示0,放了电的Cell反而表示1。这也正是NAND中的“N”(NOT,非)的来历,AND则是“与”,表示Cell的S和D是串接起来的,相当于串联的开关,它们之间当然是AND逻辑了。
如图3-38所示,当需要读出某个Page时,Flash Controller控制Flash芯片将相应这个Page的字线,也就是串接(实际上属于并联)同一个Page中所有Cell上的CG的那根导线,电势置为0,也就是不加电压,其他所有Page的字线的电势则升高到一个值,也就是加一个电压,而这个值又不至于把FG里的电子吸出来,之所以抬高电势,是为了让其他Page所有的Cell的S和D处于导通状态,而没被加电压的Cell(CG上的电势为0V),也就是我们要读取的那些Cell,其S和D的通断,完全取决于其FG中是否存有电子。
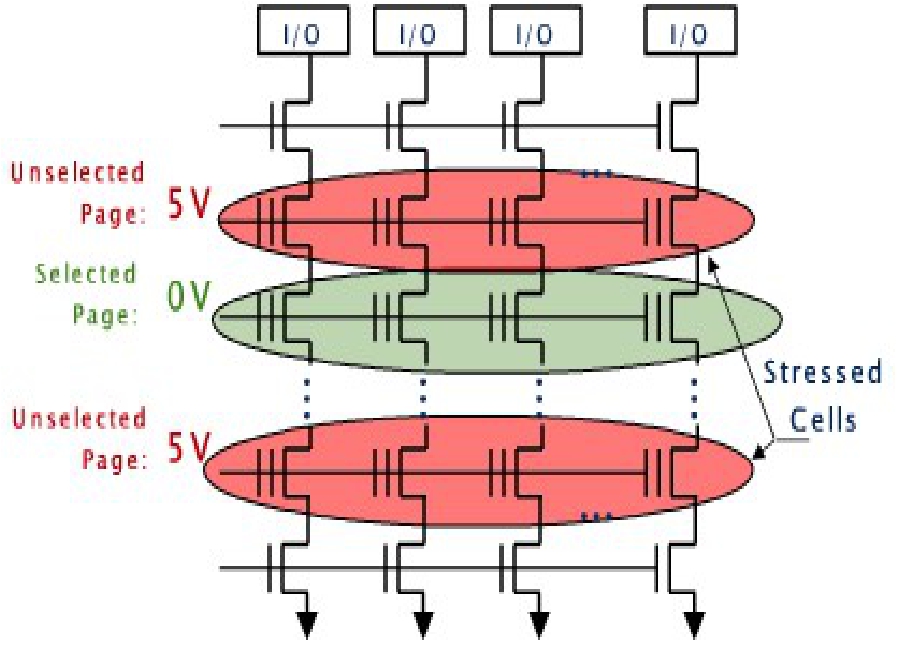
图3-38 读Page时的电压状态
SSD的IO最小单位为1个Page。所以,对于NAND Flash,通过“强行导通所有未被选中的Cell”AND“检测位线的通断状态”=“被选中的Cell的通断状态”,NOT“被选中的Cell的通断状态”=“位线的1/0值”。把这整个Page的1或者0传输到芯片外部,放置于SSD的RAM Buffer中保存,这就完成了一个Page内容的读出。SSD的IO最小单位为1个Page。
对Flash芯片的写入有一些特殊的步骤。Flash芯片要求在修改一个Cell中的位的时候,在修改之前,必须先Erase(即擦除掉)这个Cell。我们暂且先不在此介绍为何要先Erase再修改的原因,先说一说这个“Erase”的意思,这里有点误导之意。我们以机械磁盘为例,机械磁盘上的“数据”是永远都抹不掉的,如果你认为将扇区全部写入0就算抹掉的话,那也是有问题的,你可以说它存放的全是数字0,这也是数据。那么SSD领域却给出了这个概念,是不是SSD中存在一种介于1和0之间的第三种状态呢,比如虚无状态?有人可能会联想一下,Cell“带负电”、“带正电”、“不带电”,这不就正好对应了3种状态么?我们可以将“不带电”规定为“虚无”状态,是否将Cell从带电状态改为不带电状态就是所谓Erase呢?不是的。上文中叙述过,Cell带电表示0,不带电则表示1,Cell只能带负电荷,即电子,而不能带正电荷。所以Cell只有两种状态,而这两种状态都表示数据。
思考: 为何不以“带正电”表示1,“带负电”表示0,“不带电”表示中间状态?如果引入这种机制,那么势必会让电路设计更加复杂,电压值需要横跨正负两个域,对感应电路的设计也将变得复杂,感应电路不但需要感应“有无”还要感应“正负”,这将大大增加设计成本和器件数量。另外,感应电路的状态也只能有两种,即表示为0或者表示为1,如果0表示带负电,1表示带正电,那么就缺少一种用来表示不带电的电路状态,而这第三种状态在感应电路中是无法表示的,也就是说感应电路即使可以感知到三种状态但是也只能表示出两种状态。
其实,这里的Erase动作其实就是将一大片连续的Cell一下子全部放电,这一片连续的Cell就是一个Block。即每次Erase只能一下擦除一整个Block或者多个Block,将其中所有的Cell变为1状态。但是却不能单独擦除某个或者某段Page,或者单个或多个Cell。这一点是造成后面将要叙述的SSD的致命缺点的一个根本原因。Erase完成之后,Cell中全为1,此时可以向其中写入数据,如果遇到待写入某个Cell的数据位恰好为1的时候,那么对应这个Cell的电路不做任何动作,其结果依然是1;如果遇到待写入某个Cell的数据位为0的时候,则电路将对应Cell的字线电压提高到足以让电子穿过绝缘体的高度,这个电压被加到Control Gate上,然后使得FG从电源线(也就是位线上)汲取电子,从而对Cell中的FG进行充电,充电之后,Cell的状态从1变为0,完成了写入,这个写0的动作又叫做Programm,即对这个Cell进行了Programm。
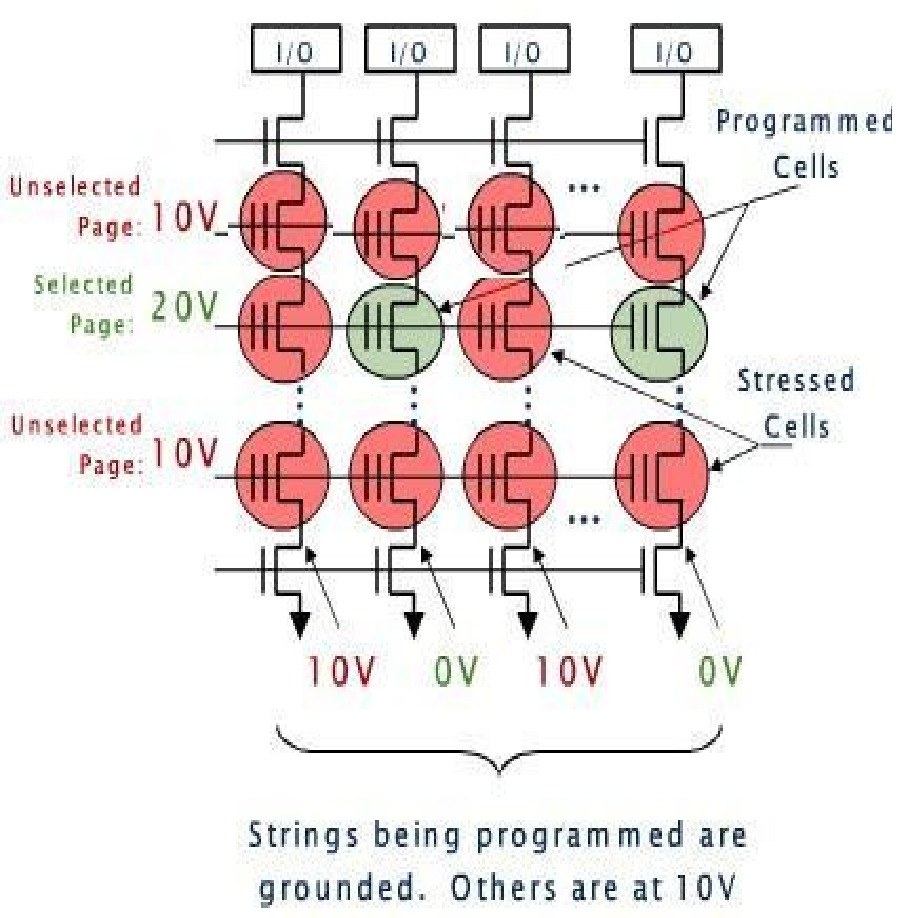
图3-39 写入Cell时的电压状态
如图3-39所示,要写入某个Cell,首先也必须先选中其所在的Page,也就是将这个Page的字线加高电压,对应这个Cell的位线加0V电压,同一个串里的所有其他Page的字线也加一个高电压但是不如待写入Page的高,同时不需要写入操作的那些串对应的位线加一个对应字线相同的电压,结果就是,不需要写入数据的Cell的字线和位线电压抵消,电子不动;需要写入数据的Cell,也就是需要充电的Cell,由电势差将电子从位线中汲取过来充电。仔细看一下这个过程,就会发现,根本无法在这个二维矩阵中做到同时给一个Page里(一横行)的不同Cell既充电又放电,可以自己推演一下对应字线和位线的电压状态,你会发现永远做不到,是个矛盾,这也是Flash挥之不去的痛。我们可以思考一下,虽然不能够同时对一些cell有的写0、有的写1,那么是否可以把一个page的写入分成两个周期来做呢,比如第一个周期先把要写入0的所有Cell写0,第二个周期则要把写入1的所有Cell写1,或者反之?完全可以,但是设计者并没有选择这么做,因为对于Cell来讲,每个Cell都有一定的绝缘体击穿次数,比如MLC一个Cell可击穿一万次,那么就意味着,每个Page被写入1万次就会报废,这显然不能接受,有个办法就是让所有Cell循环写入,不写到原地,每次覆盖写要新写入其他位置,这样就能够保证所有Cell轮流被写入,平衡整体寿命。所以设计者选择了先预先准备好大片已经写满了全1的Cell,每次写入都写到这些预先备好的地方,只写0,如果是覆盖写,就需要把之前的Page地址做一个重定向,所以Flash控制器还需要保存一张地址重定向表。还有一个原因不用两个周期来实现对一个page的写入,那就是如果每次写入都要耗费2个周期,写性能便会骤降,所以设计者不得不采用一下子擦除大片的Block,也就是说不用写IO一次就放电一次,而是类似“批发”,然后写入的时候只需要1个周期即可,所付出的的代价就是后台需要不断地“批发”,一旦断链,那么性能便会骤降。
SSD会以Page为单位进行写入操作,写完一个Page,再写下一个Page。
Flash领域里,写又被称为Programm。由于Flash的最常见表现形式——EPRROM一般是只读的,但是一旦要更改其中的程序,则需要重新写入,即Re-Programm,所以就顺便将写入Flash的过程叫做Programm了。一块崭新的SSD上所有Cell都是已经被Erase好的,也可以使用特殊的程序对整个SSD重新整盘Erase。
提示: 为何字线并联了所有Cell的CG(也就是所有Cell共享CG的控制信号),而不是让每个Cell的CG可以被单独控制呢?这样做实际上还是为了成本和芯片面积考虑,技术上其实都可以实现,关键是钱的问题。
Flash芯片在写入数据的时候有诸多效率低下的地方。包括现在常用的U盘以及SSD中的Flash芯片,或者BIOS常用的EEPROM,它们都不可避免。
对于机械磁盘来说,磁盘可以直接用磁头将对应的区域磁化成任何信号,如果之前保存的数据是1,新数据还是1,则磁头对1磁化,结果还是1;如果新数据是0,则磁头对1磁化,结果就变成了0。而Flash则不然,如果要向某个Block写入数据,则不管原来Block中是1还是0,新写入的数据是1还是0,必须先Erase整个Block为全1,然后才能向Block中写入新数据。这种额外的Erase操作大大增加了覆盖写的开销。
更难办的是,如果仅仅需要更改某个Block中的某个Page,那么此时就需要Erase整个Block,然后再写入这个Page。那么这个Block中除这个Page之外的其他Page中的数据在Erase之后岂不是都变成1了么?是的,所以,在Erase之前,需要将全部Block中的数据读入SSD的RAM Buffer,然后Erase整个Block,再将待写入的新Page中的数据在RAM中覆盖到Block中对应的Page,然后将整个更新后的Block写入Flash芯片中。可以看到,这种机制更加大了写开销,形成了大规模的写惩罚。这也是为何SSD的缓存通常很大的原因。
就像CDRW光盘一样,如果你只需要更改其上的几KB数据,那么就要先复制出全盘700MB的数据,然后擦除所有700MB,然后再写入更改了几KB数据的700MB数据。
SSD的这种写惩罚被称为Write Amplification(写扩大),我们依然使用写惩罚这个词。写惩罚有不同的惩罚倍数,比如,需要修改一个512KB的Block中的一个4KB的Page,此时的写惩罚倍数=512KB/4KB=128。小块随机写IO会产生大倍数的写惩罚。
当SSD当向Flash中的Free Space中写入数据时,并没有写惩罚,因为Free Space自从上次被整盘Erase后是没有发生任何写入动作的。这里又牵渗到一个比较有趣的问题,即存储介质如何知道哪里是Free Space,哪里是Occupied Space呢?本书中多个地方论述过这一点。只有文件系统知道存储介质中哪些数据是没用的,而哪些正在被文件系统所占用,这是绝对无可置疑的,除非文件系统通过某种途径通告存储介质。SSD也不例外,一块刚被全部Erase的SSD,其上所有Block对于文件系统或者SSD本身来讲,都可以认为是Free Space。随着数据不断的写入,SSD会将曾经被写入的块的位置记录下来,记录到一份Bitmap中,每一比特表示Flash中的一个Block。对于文件系统而言,删除文件的过程并不是向这个文件对应的存储介质空间内覆盖写入全0或者1的过程,而只是对元数据的更改,所以只会更改元数据对应的存储介质区域,因此,删除文件的过程并没有为存储介质自身制造Free Space。所以说,对于SSD本身来讲,Free Space只会越来越少,最后导致没有Free Space,导致每个写动作都产生写惩罚,类似Copy On Write,而且Copy和Write很有可能都是一些在文件系统层已经被删除的数据,做了很多无用功,写性能急剧下降。对于一块使用非常久的SSD来讲,就算它在被挂载到文件系统之后,其上没有检测到任何文件,文件系统层剩余空间为100%,这种情况下,对于SSD本身来讲,Free Space的比例很有可能却是0,也就是说只要曾经用到过多少,那么那个水位线就永远被标记在那里。
每个Block中的Page必须被按照一个方向写入,比如每个Block为128个Page,共512KB,则当这个Block被擦除之后,SSD控制器可以先向其中写入前32个Page(或者10个Page,数量不限),一段时间之后,可以再向这个Block中追加写入剩余的Page(或者多次追加一定数量的Page写入)而不需要再次擦除这个Block。SSD控制器会记录每个Block中的大段连续空余空间。但是不能够跳跃的追加,比如先写入0~31这32个Page,然后写入64~127这64个Page,中间空出了32个Page没有追加,控制器是不会使用这种方式写的,Page都是连续排布的。但是一般来讲,控制器都是尽量一次写满整个Block的从而可以避免很多额外开销。
随着FG充放电次数的增多,二氧化硅绝缘层的绝缘能力将遭到损耗,最后逐渐失去绝缘性,无法保证FG中保有足够的电荷。此时,这个Cell就被宣判为损坏,即Wear Off。
损坏的Cell将拖累这个Cell所在的整个Page被标记为损坏,因为SSD寻址和IO的最小单位为Page。损坏的Page对应的逻辑地址将被重定向映射到其他完好的预留Page,SSD将这些重定向表保存在ROM中,每次加电均被载入RAM以供随时查询。
MLC由于器件复杂,其可擦写的寿命比较低,小于10000次。而SLC则高一些,十倍于MLC,小于100000次。这个值是很惊人的,对于某些场合下,有可能一天就可以废掉一大堆Cell/Page,几个月之内当预留的Page都被耗尽后,就会废掉整个SSD。这是绝对不能接受的。
写惩罚会大大加速Wear Off,因为写惩罚做了很多无用功,增加了不必要的擦写,这无疑使本来就很严峻的形势雪上加霜。但是对于读操作,理论上每个Cell可以承受高数量级的次数而不会损耗,所以对于读来说,无须担心。
3.10.2节已经讲过,这里再强调一下,当需要读出某个Page时,Flash Controller控制Flash芯片将相应这个Page的字线【也就是串连(实际上属于并联)同一个Page中所有Cell上的CG的那根导线】电势置为0,也就是不加电压,其他所有Page的字线的电势则升高到一个值,也就是加一个电压,而这个值又不至于把FG里的电子吸出来,之所以抬高电势,是为了让其他Page所有Cell的S和D处于导通状态,而没被加电压的Cell(CG上的电势为0V),也就是我们要读取的那些Cell,其S和D的通断完全取决于其FG中是否存有电子。说白了,未被选中的所有Cell,均强制导通,被选中的Cell的FG里有电,那么串联这一串Cell的位线就会被导通,这是一种AND(也就是与)的关系;被选中Cell的FG里如果没电,那么其所处的Cell串的位线就不能导通(虽然串上的其他Cell均被强制导通),这也是AND的关系。也就是一串Cell必须全导通,其位线才能导通,有一个不导通,整条位线就不通。这就是NAND Flash中的AND的意义。那N表示什么?N表示Not,也就是非,NAND就是“非与”的意思。为什么要加个非?很简单,导通反而表示为0,因为只有FG中有电才导通,上文也说了,FG中有电反而表示为0,所以这就是“非”的意义所在。
还有一类NOR Flash,NOR就是“非或”的意思,大家自然会想到,位线一定不是串联的,而是并联的,才能够产生“或”的逻辑。实际上,在NOR Flash里,同样一串Cell,但是这串Cell中的每个Cell均引出独立的位线,然后并联接到一根总位线上;另外一点很重要的是,每个Cell的S和D之间虽然物理上是串连,但是电路上不再是串联,而是各自有各自的接地端,也就是每个Cell的S和D之间的通断不再取决于其他Cell里S和D的通断了,只取决于自己。以上两点共同组成了“或”的关系,同时每个Cell具有完全的独立性,此时只要通过控制对应的地线端,将未被选中的Cell地线全部断开,这样它们的S和D极之间永远无法导通(逻辑0状态),由于每个Cell的位线并联上联到总位线,总位线的信号只取决于选中的Cell的导通与否,对于被选中的Cell,NOT {(“地线接通”AND“FG是否有电”)OR“未被选中Cell的输出”} =“总位线的1/0值”,这就是NOR非与门的逻辑。
由于NOR Flash多了很多导线,包括独立地线(通过地址译码器与Cell的地线相连)和多余的上联位线,导致面积增大。其优点是Cell独立寻址,可以直接用地址线寻址,读取效率比NAND要高,所以可以直接当做RAM用,但是由于擦除单位较小,擦除效率要比NAND低,所以不利于写频繁的场景。
面对病入膏肓的SSD写入流程设计,是不是无可救药呢?好在SSD开出了五个药方。
为了避免同一个Cell被高频率擦写,SSD有这样一个办法:每次针对某个或者某段逻辑LBA地址的写都写到SSD中的Free Space中,即上一次全盘Erase后从未被写过的Block/Page中,这些Free Space已经被放电,直接写入即可,无须再做Copy On Write的操作了。如果再次遇到针对这个或者这段LBA地址的写操作,那么SSD会再次将待写入的数据重定向写到Free Space中,而将之前这个逻辑地址占用的Page标记为“Garbage”,可以回收再利用。等到Block中一定比例(大部分)的Page都被标记为“Garbage”时,并且存在大批满足条件的Block,SSD会批量回收这些Block,即执行Copy On Write过程,将尚未被标记为“Garbage”的Page复制到RAM Buffer,将所有Page汇集到一起,然后写入一个新Erase的Block,再将所有待回收的Block进行Erase操作,变成了Free Space。SSD这样做就是为了将写操作平衡到所有可能的Block中,降低单位时间内每个Block的擦写次数,从而延长Cell的寿命。
重定向写的设计可谓是一箭双雕,既解决了Wear Off过快问题,又解决了大倍数写惩罚问题(因为每次写都尽量重定向到Free Space中,无须CoW)。但是,正如上文所述,SSD自己认为的纯Free Space只会越来越少,那么重定向写的几率也就会越来越少,最后降至0,此时大倍数写惩罚无可避免。
由于Page的逻辑地址对应的物理地址是不断被重定向的,所以SSD内部需要维护一个地址映射表。可以看到这种设计是比较复杂的,需要SSD上的CPU具有一定的能力运行对应的算法程序。这种避免Wear Off过快的重定向算法称为Wear Leveling,即损耗平衡算法。
Wear Leveling的实现方法随不同厂商而不同,有些以一块大区域为一个平衡范围,有些则完全顺序地写完整个SSD的Free空间,然后再回来顺序地写完整个被回收的Free空间,无限循环直到Free空间为0为止。传统机械硬盘中,逻辑上连续LBA地址同样也是大范围物理连续的,但是对于SSD,逻辑和物理的映射随着使用时间的增长而越来越乱,好在SSD不需要机械寻址,映射关系乱只会影响CPU计算出结果的时间而不会影响数据IO的速度,而CPU运算所耗费的时间与数据IO的时间相比可以忽略不计,所以映射关系再怎么乱也不会对IO的性能有多少影响。
利用这种方式,SSD内部实现了垃圾回收清理以及新陈代谢,使得新擦除的Block源源不断地被准备好从而供应写操作。
有必要一提的是,Flash控制器的这种机制又可以被称为RoW,也就是Redirect On Write,每遇到需要更新的页面,Flash控制器便将其缓存到RAM中,当缓冲的待写入页面达到了一个Block容量的时候,便会直接将这些页面写入到一个已经擦好的Block中。如果待写入的页面未攒够一个Block的容量,必要时也可以写入一个擦好的Block,此时这个Block处于未写满状态,随后可以继续写入页面直到写满为止,当然,要做到这一点,Flash控制器就需要为每个Block记录断点信息了。
每次被更新的页面在更新之前所处的位置,会在该页面被重定向写入到其他Block之后,在映射表中标记为垃圾,可以想象,随着使用时间的加长,Flash中Block里的这种垃圾孔洞越来越多,而且越来越不连续,到处都是,可谓是千疮百孔。垃圾回收程序最喜欢的就是一个Block里全是垃圾的状态,此时最好,但是如果多数Block都处于一种“不尴不尬”的状态,比如50%内容是垃圾,但是另外50%的内容却未被标记为垃圾,那么此时到底是否回收?要回收这50%的垃圾,就需要先把那些非垃圾内容读出到RAM中存放,随后和新数据一起一视同仁地写入到擦好的Block中,此时产生50%不必要的读和50%不必要的写操作,这些都属于惩罚操作,越是不尴不尬,后台的惩罚就越多,性能就会越差。
通过上面的论述我们知道,影响一块SSD寿命和写入性能的最终决定因素就是Free Space,而且是存储介质自身所看到的Free Space而不是文件系统级别的Free Space。但是SSD自身所认识的Free Space永远只会少于文件系统的Free Space,并且只会越来越趋于0。所以,要保持SSD认识到自身更多的Free Space,就必须让文件系统来通知SSD,告诉它哪些逻辑地址现在并未被任何文件或者元数据所占用,可以被擦除。这种思想已经被实现了。所有SSD厂商均会提供一个工具,称为“Wiper”,在操作系统中运行这个工具时,此工具扫描文件系统内不用的逻辑地址,并将这些地址通知给SSD,SSD便可以将对应的Block做擦除并回收到Free Space空间内。如果用户曾经向SSD中写满了文件随后又删除了这些文件,那么请务必运行Wiper来让SSD回收这些垃圾空间,否则就会遭遇到大写惩罚。
Wiper并不是实时通知SSD的,这个工具只是一次性清理垃圾,清理完后可以再次手动清理。所以,这个工具需要手动或者设置成计划任务等每隔一段时间执行一次。
这种垃圾回收与上文中的那种内部垃圾回收不在一个层面上,上文中所讲的是SSD内部自身的重定向管理所产生的垃圾,而本节中所述的则是文件系统层面可感知的垃圾,被映射到SSD内部,也就变成了垃圾。
定期执行垃圾清理确实可以解燃眉之急,但是有没有一种方法,可以让文件系统在删除某个文件之后实时地通知SSD回收对应的空间呢?这种方法是有的。TRIM便是这种方法的一个实现。TRIM是ATA指令标准中的一个功能指令,在Linux Kernal 2.6.28中已经囊括,但是并不完善。Windows 7以及Windows Server 2008R2中已经提供了完善的TRIM支持。一些较早出现的SSD也可以通过升级Firmware来获得对TRIM的支持。
TRIM可以使SSD起死回生,经过实际测试,开启了TRIM支持的SSD,在操作系统TRIM的支持下,可以成功地将性能提高到相对于SSD初始化使用时候的95%以上,写惩罚倍数维持在1.1倍左右。
提示: 台湾闪存厂商PhotoFast银箭已经发布了带有自行回收垃圾空间的SSD,不依赖于Trim指令,在此可以推断其SSD内部一定被植入了可识别NTFS格式数据的代码,所以可以自行识别NTFS文件系统中不被文件占用的空间。
Delay Write是一种存储系统常用的写IO优化措施。比如有先后两个针对同一个地址的IO——Write1、Write2,先后被控制器收到,而在Write1尚未被写入永久存储介质之前,恰好Write2进入,此时控制器就可以直接在内存中将Write2覆盖Write1,在写入硬盘的时候只需要写入一次即可。这种机制为“写命中”的一种情况(其他情况见本书后面章节)。它减少了不必要的写盘过程,对于SSD来讲,这是很划算的。
然而,如果一旦遇到这种IO顺序比如Write1、Read2、Write3,如此时控制器先将Write3覆盖到Write1,然后再处理Read2的话,那么Read2原本是应该读出Write1的内容的,经过Delay Write覆盖之后,却读出了Write3的内容,这就造成了数据不一致。
所以,控制器在处理Delay Write时要非常小心,一定要检测两个针对同一个地址的写IO之间是否插有针对同一个地址的读IO,如果有读IO,首先处理读,然后再覆盖。
Combine Write是另一种存储系统控制器常用的写IO优化方法。对于基于机械硬盘的存储系统,如果控制器在一段时间内收到了多个写IO而这些写IO的地址在逻辑上是连续的,则可以将这些小的写IO合并为针对整体连续地址段的一个大的IO,一次性写入对应的磁盘,节约了很多SCSI指令周期,提高了效率。对于SSD来讲,由于SSD中的逻辑地址本来就是被杂乱地映射到可能不连续的物理地址上的,但是并不影响多少性能,所以,SSD控制器可以整合任何地址的小块写IO成一个大的写IO而不必在乎小块写IO针对的逻辑地址是否连续。整合之后的大写IO被直接写向一个Free的Block中,这样做大大提高了写效率。
为了防止文件系统将数据写满的极端情况,SSD干脆自己预留一部分备用空间用于重定向写。这部分空间并不通告给操作系统,只有SSD自己知道,也就是说文件系统永远也写不满SSD的全部实际物理空间,这样,就有了一个永远不会被占用的一份定额的Free Space用于重定向写。Intel X25-E系列企业级SSD拥有20%的多余空间。其他普通SSD拥有6%~7%的比例。
思考: 为何用普通碎片整理程序在文件系统层整理碎片对于SSD来说是雪上加霜,理解这个问题的关键在于理解对于SSD来讲,逻辑上连续的地址不一定在物理上也连续,如果使用普通碎片整理程序,不但不能达到效果,反而还会因为做了大量无用功而大大减少SSD的寿命。
因为SSD需要对数据进行合并以及其他优化处理以适应Flash的这些劣势,所以SSD自身对接收的写IO数据使用Write Back模式,即接收到主机控制器的数据后立即返回成功,然后异步的后台处理和刷盘。所以,一旦遇到突然掉电,那么这些数据将会丢失,正因如此,SSD需要一种掉电保护机制,一般是使用一个超级电容来维持掉电之后的脏数据刷盘。
关于SSD性能方面的更详细的内容请参考本书第19章中的部分内容。
对于机械硬盘,如果出现被划伤的磁道或者损坏的扇区,也就意味着对应的磁道或者扇区中的磁粉出现问题,不能够被成功地磁化,那么磁头会感知到这个结果,因为磁化成功必定对应着电流的扰动,如果针对某块磁粉区磁化不成功,磁头控制电路迟迟没感知到电流扰动,或者扰动没有达到一定程度,那么就证明这片区域已经损坏。而对于Flash中的Cell,当Cell中的绝缘体被击穿一定次数(SLC 10万次,MLC 1万次)之后,损坏的几率会变得很高,有时候不见得非要到这个门限值,可能出厂就有一定量损坏的Cell,使用一段时间之后也可能时不时出现损坏。那么SSD如何判断某个Cell损坏了呢?我们知道Cell损坏之后的表现是只能表示1而无法再被充电并且屏蔽住电子了,如果某个Cell之前被充了电,为0,某时刻Cell损坏,漏电了,变为1,那么在读取这个Cell的值的时候,电路并不会感知到这个Cell之前的值其实是0,电路依然读出的是1,那么此时问题就出现了。解决这个问题的办法是使用ECC纠错码,每次读出某个Page之后,都需要进行ECC校验来纠错。每种Flash生产厂商都会在其Datasheet中给出一个最低要求,即使用该种颗粒起码需要配合使用何种力度的纠错码,比如8b@512B或者24b@1KB等。8b@512B意味着如果在512字节范围内出现8b的错误,则是可以纠错恢复的,如果超过了8b,那么就无法纠错了,此时只能向上层报“不可恢复错误”;同理,24b@1KB也是一样的意思。厂商给出的纠错码力度越低,就证明这种Flash颗粒的品质越好,损坏率越低。
以上一切缓解SSD效率问题的方法,都是治标不治本。随着Cell的不断损坏,最后的救命稻草——SSD私自保留的空间也将被耗尽,没了救命稻草,加之文件系统空间已满的话,那么SSD效率就会大大降低。
但是,我们在这里讨论的SSD写效率降低,不是与机械硬盘相比的。瘦死的骆驼比马大,SSD比起机械硬盘来讲其优势还是不在一个数量级上的。
可以将多块SSD组成Raid阵列来达到更高的性能。但是可惜的是,Raid卡目前尚未支持TRIM。
为了适应Flash的存储方式,有多种Flash Aware FS被开发出来,这些Flash FS包括TrueFFS、ExtremeFFS等。这些能够感知Flash存储方式的FS,可以将大部分SSD内部所执行的逻辑拿到FS层来实现,这样就可以直接在上层解决很多问题。
SSD看似风光无限,但是其技术壁垒比较大,为了解决所产生的多个问题,设计了多种补救措施,需要靠TRIM维持,而且数据不能占空间太满,否则无药可救。基于目前NAND Flash的SSD很有可能是昙花一现。目前市场上已经出现SRAM、RRAM等更快的永久存储介质,随着科技的发展,更多更优良的存储介质和存储方式必将替代机械硬盘的磁碟,SSD数据存储次世代即将到来。
此外,SSD在使用的时候也比较尴尬,SSD的成本还是太高,比如用户需要一个10TB的存储系统,不可能都用SSD,此时怎么规划?对某个Raid组专门使用SSD来构建,比如8个256GB的SSD组成某Raid组,有效容量1TB,再在其上划分若干LUN。用户使用一段时间后发现原来人工预测的热点数据已经冷了,而原来的冷数据热了,那么此时需要数据迁移,这就要兴师动众了。或者用户发现某个应用所需的数据量庞大,但是又不可能将其分割开一部分放到SSD中一部分放到传统磁盘中。这些尴尬的境况都限制了SSD的应用,也是多个厂商相继开发了Automatically Storage Tiering技术的原因(见后面章节)。
针对传统SSD使用时候的尴尬境况,Seagate等厂商也相继推出了SSD+HDD混合式存储硬盘。这种硬盘其实是将Flash芯片用于磁盘的二级缓存,一级缓存是Ram,二级是Flash,三级则是磁盘片。利用这种多级缓存更大程度地降低了磁头寻道的影响。有人质疑说,传统磁盘自身已经有了多达64MB的RAM缓存,还需要Flash再作为下一级的缓存么?是的,64MB的容量还是太小,虽然速度高,但是很快就被充满,同时没有掉电保护机制,所以盘阵控制器不会让磁盘以WriteBack模式操作,充满了则一定要连续地刷到盘片中,这样就不可避免地直接导致可见的性能骤降;而使用Flash芯片再加入一级缓存,比如用8GB甚至16GB的Flash芯片,数据从RAM缓存出来后先被存入Flash,不用寻道,同时可以掉电保护,Write Back之后,磁盘驱动器再在后台将数据从Flash中写入磁盘片保存并清空Flash中的内容。这样的做法,既比传统纯SSD便宜,还保证了性能,有效屏蔽了磁头寻道带来的高延迟,同时又保证了容量(数据后台被刷入磁盘片),传统SSD在容量方面的问题就这么被解决了。这种磁盘短期内尚无法取代传统纯SSD,因为其读取操作依然需要从磁盘片中读取几乎所有数据而不是从Flash中,无法与纯SSD抗衡,但是其取代传统磁盘的趋势是存在的,今后的磁盘如果都这么做,会大大增加单个磁盘的随机写性能,对磁盘阵列控制器的更新与设计也是一个挑战。
提示: 试想一下,磁盘阵列控制器作为一个嵌在主机与后端物理磁盘之间的角色,其一个本质作用就是提升性能,其性能提升的原理就是让众多磁盘同时工作以屏蔽磁头寻道所浪费的时隙,而现在,每块磁盘自身就能够利用Flash芯片来屏蔽寻道的时隙,如何办?充分地想象吧。
机械磁盘由于其高复杂度的机械部件、芯片及固件,让人望而却步,其技术只被掌握在少数几家巨头手中。因为初期成本非常高,如果没有销量,那就是赔本。而近年来出现越来越多的国产企业级固态存储产品,SSD相对机械磁盘为何会有这么低的门槛?那是必须的。组成SSD的主要是Flash颗粒和控制器,而这些部件,都可以从各种渠道购买,当然,品质和规格也是参差不齐,但是,SSD是对各种部件的集成,只要有足够的集成能力,能快速看懂这些部件提供商的手册,对整个存储系统有基本了解,那么只要具有一定水平和经验的硬件研发者,都可以进入这个领域。
但是,目前各种固态介质充斥市场,从TF卡、U盘到消费级SATA SSD,再到企业级SATA SSD,再到企业级PCIE闪存卡,每个档次要求很不一样。
要做成企业级SSD,不但需要有技术能力,还得有充分的产品定制化能力。我们很欣喜地看到Memblaze同时具有了这两种能力。
评判一个存储团队的技术能力,第一看他们是贴牌还是有自己的特色;第二看其产品设计采用硬加速还是软加速。说到软加速,也就是把原本由硬件芯片实现的功能,上提到由主机CPU运行代码来实现,也就是常说的“软件定义”概念里的一个意思。个人感觉软件定义是个好事情,但是不能过分定义,否则会适得其反。比如一些硬加速DSP、底层特定协议编解码器,这些如果用通用CPU来实现也可以,只要你能忍受性能的极度下降以及几近100%的CPU负荷。曾经有某国外厂商的PCIE闪存卡使用的就是软加速方案。
我们首先得了解一下对于Flash闪存卡,其控制器都需要做哪些工作,然后才能判断到底是软加速就够了,还是必须用硬加速。通过本章前文的描述,我们已经充分了解了对Flash的读写过程,也深知其复杂性,就因为不能够对同一个Page里的不同Cell同时放电和充电,导致了后续一系列严重后果,此外,Flash Cell单元的低寿命和高出错率,也是个令人头疼的事。处理所有这堆烂摊子的角色,其学术名词叫做FTL(Flash Translation Layer),其意思一个是把Flash基于页面为最小IO单元映射成传统的块设备以512B扇区为最小IO单位,另一个是把逻辑IO地址映射为物理IO地址,因为每个Page的实际物理地址都会不断变化。当然,这只是地址方面的映射处理,FTL需要同时掌管映射处理和对Flash的磨损均衡、垃圾回收、纠错等等处理。
我们继续分析这套架构都需要哪些数据结构。首先需要多张超大二维表来存储逻辑地址、物理地址的映射记录,后端挂接的Flash颗粒容量越大,这些表(数组)就越大;其次是为了加速查询所做的索引、位图之类的元数据结构;还有就是存储IO栈里常用的一种数据结构——链表,或者称其为“描述体”,用来追踪分散在多个物理内存处但是逻辑上是一个整体的事物,比如逻辑连续空间,或者某个IO任务等;另外,状态机也非常复杂。
我们分析一下,上面这套数据结构和状态机,如果完全将其运行在主机OS底层的设备驱动层,或者干脆运行在用户态(一般都会是在用户态运行,因为驱动层不适合做复杂的逻辑处理),效率究竟有多高。这一点想想就可以大致推断,比如TCPIP协议栈是个纯软协议栈,其不需要维护太多元数据,多数计算量位于状态机的判断和输出上,即便是这样,一个万兆网口之上承载iSCSI协议的场景,在IOPS跑满之后,CPU利用率基本都超过50%了,何况是需要查表映射的场景。另外,软加速方案需要设备传输更多的信息给驱动程序,这直接导致中断次数激增。还有,软加速方案需要在主机端保存大量的元数据,对内存的占用是不可小视的,通常1GB起步,量多加价,而硬加速方案只有主机端驱动运行耗费一部分内存,通常1MB起步。
如果是使用硬加速方案,所有的元数据、状态机,都在Flash控制器内部维护和计算,就能大大降低主机端CPU的负荷,主机端CPU的负荷只体现在响应外部设备的中断上了。硬加速的好处就是可以将一些专用逻辑直接做成硬逻辑电路,在一个或者几个时钟周期内就可以完成通用CPU需要耗费几百个或者几千个时钟周期才能完成的任务。举个例子,对ECC码的计算,就可以单独拿出来做成硬加速电路。有些逻辑不能完全被翻译成纯数字电路,比如地址映射查表等,一小部分逻辑必须依靠通用CPU来运行对应的固件(或者说微码)来协调完成全部逻辑,当然那些重复运算还是交给数字电路,微码只是负责协调和总控,这一点如果是一些比较复杂的逻辑的话,靠纯数字电路是无法完成的。这里的“通用CPU”并非指主机端CPU,而是指控制器内部的嵌入式CPU核心,一个控制其芯片内部集成的通用CPU核心数量可能在几个到十几个这种级别。
我们可以看到,如果用硬加速方案,对设计者的要求,不仅仅是了解Flash FTL层的全部逻辑,还得有充分的技术实力把这些逻辑梳理成数据结构,然后判断哪些逻辑可以被硬加速,然后还得具备将软件翻译成硬件逻辑的技能,除此之外,还得具有熟练驾驭FPGA的技能,因为不可能让建筑师去烧窑制造砖头,砖头肯定是要买,FPGA也得用现成的。
另外,一款固态存储产品,选择使用什么样的IO协议也是至关重要的。对于基于ATA协议的SATA接口来讲,是无法发挥出Flash最优性能的,直接使用PCIE接口接入主机总线是目前离CPU最近的途径,但是这样就无法使用SATA协议的一切已有软硬件了,包括成熟的SATA控制器硬件,以及主机端OS系统内核对SATA的原生驱动支持。选择PCIE就意味着必须自己开发一套轻量级IO访问协议。
提示: 目前针对PCIE Flash的专用IO协议有NVMe和SCSIe两种,现在看来VNMe似乎已经占了上风,因为SCSI协议簇的庞大臃肿已经完全不适合Flash这种高速介质了。Memblaze在第一代产品中并没有使用NVMe,而是使用了自己的私有协议,下一代产品很有可能会过渡到NVMe标准上来。
Memblaze很显然是充分掌握了这条线上的所有技能。图3-40是Memblaze的Flash控制器框图。其使用了成品FPGA,其中IP硬核部分为PCIE控制器及DDR3控制器;IP软核部分为DMA控制器、嵌入式通用CPU等等,可以任意生成,其他都是需要用户自定义设计的部分。其中纯硬逻辑包含Flash通道控制器、ECC计算电路等;需要嵌入式通用CPU辅助的有:地址映射器、磨损均衡和垃圾回收模块以及整个控制器的中央协调控制逻辑处理部分等。
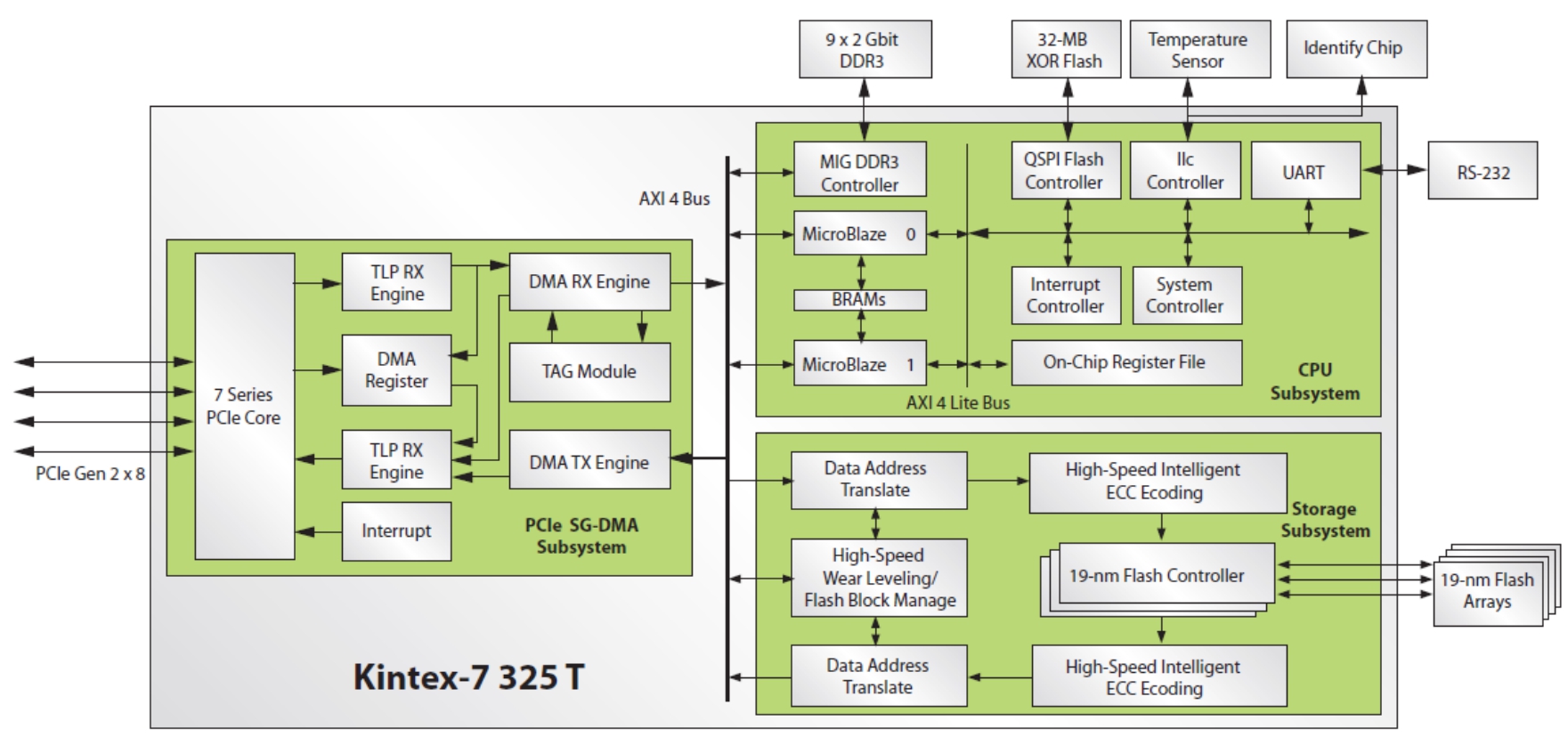
图3-40 Memblaze的Flash控制器框图
除了对硬件的掌控能力之外,Memblaze还拥有IO延时平滑的专利技术,可以针对个别超长延时的IO请求进行削峰滤波处理(类似电容器滤除高电压脉冲的工作原理,对IO延时进行滤波),当运行在较高IOPS情况下,控制器会自动调整垃圾回收算法和内部等待队列深度,并将IO延时进行平滑处理,从而避免产生超长延时的IO,减少对后端系统的影响,使得用户的应用运行得更加平稳顺滑。图3-41为实测结果,可以看到抖动很少,有些场景根本没有抖动。这项技术主要是采用排队论和现代控制理论对SSD的一些指标进行采样,根据采样结果去控制系统通路上的参数,用来优化IO的抖动和延迟。比如,用户发给SSD的请求可能是顺序写入,也可能是随机写入。不同的写入模式对应的写放大倍数是不同的。在这种情况下,后端的处理速度在不同的输入下就会有不同的通道阻塞程度,对于IO来说就会造成抖动和服务质量较低。如果采用通道的阻塞程度作为控制变量,运用自动控制理论,就可以动态地均衡前端的压力,降低整个系统的延迟和抖动。

图3-41 Memblaze的时延平滑技术
最后,对于固态存储厂商来讲,能够驾驭各Flash颗粒厂商的NAND Flash也显得至关重要。不同颗粒使用不同的规格,比如ECC位比例、页面大小、访问协议等等。这些都需要花上足够的时间去测试、调优。
提示: 本文落笔时,Memblaze的最终产品性能已经可以达到70w+的IOPS,已经是目前PCIe闪存卡的最高纪录。
另外,NAND Flash的写放大是导致性能和寿命下降的主要原因,是否能够充分降低写放大效应,也是体现技术实力的地方。如图3-42所示,Memblaze对写放大的压制还有很不错的。
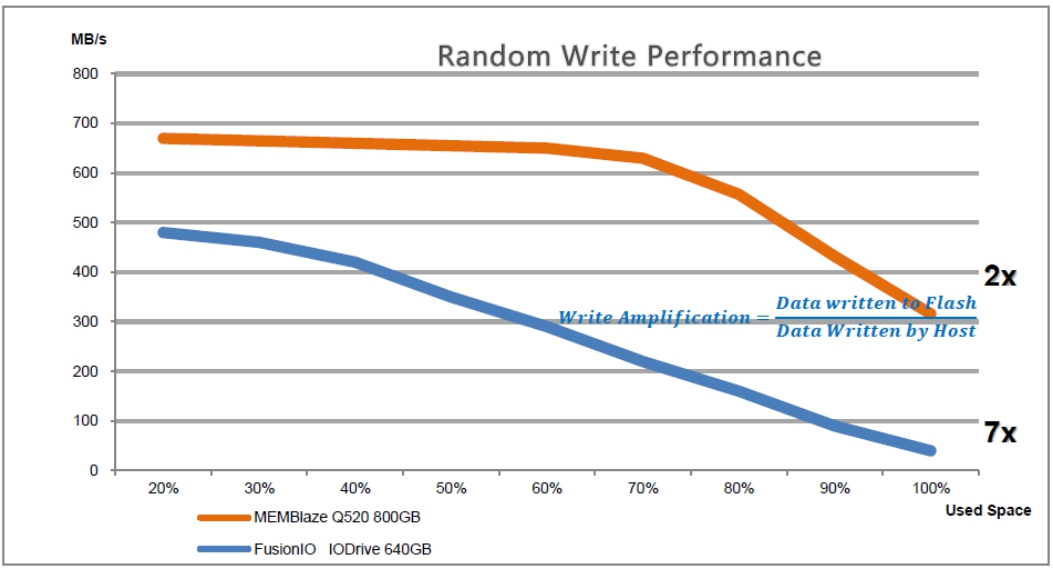
图3-42 Memblaze对写放大的压制
技术是技术,产品是产品,有好技术不一定能出好产品,但是没有好技术一定出不了好产品,当然,忽悠除外。令人眼前一亮的是,Memblaze对产品这个概念还是非常有感觉的,深知“个性”对于一款产品来说是多么重要。
在我们的脑海里,PCIE闪存卡就是一锤子买卖,比如,卡上焊上了多少容量的Flash颗粒,它就是多大容量了,比如1TB容量,如果用户不需要这么大容量,比如只需要500GB容量,那么厂商就不得不再去定制一批只焊了500GB容量颗粒的板子。这个问题谁都清楚,但是Memblaze是第一个提出方案并且成功商用的公司。
“琴键”技术是他们对这个技术的命名,通过将Flash控制器与Flash颗粒之间的连接方式从完全PCB布线转为插槽的形式,然后通过生产不同容量的子卡(琴键)插在插槽上从而生成不同整体容量的闪存卡产品,如图3-43和图3-44所示。Memblaze组合容量和规格如图3-45、图3-46所示。
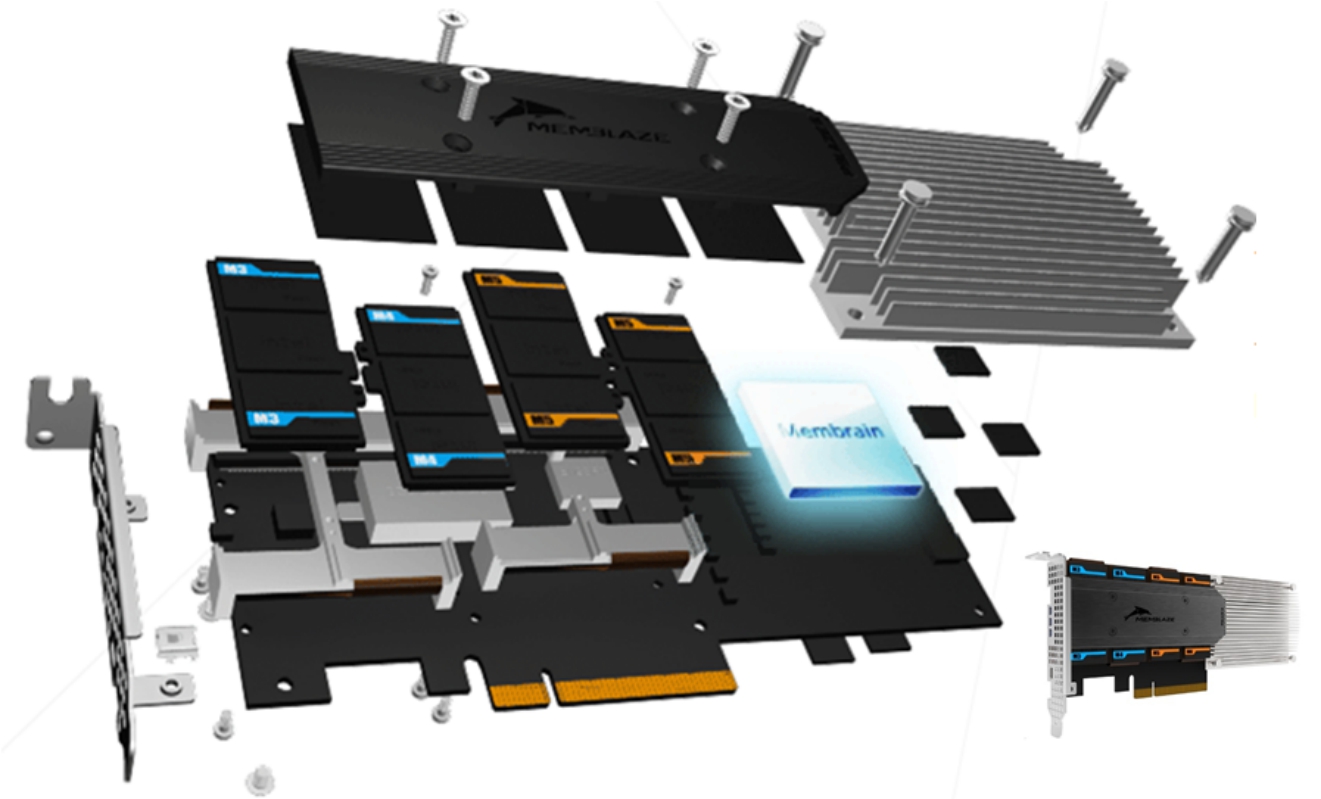
图3-43 Memblaze的琴键技术
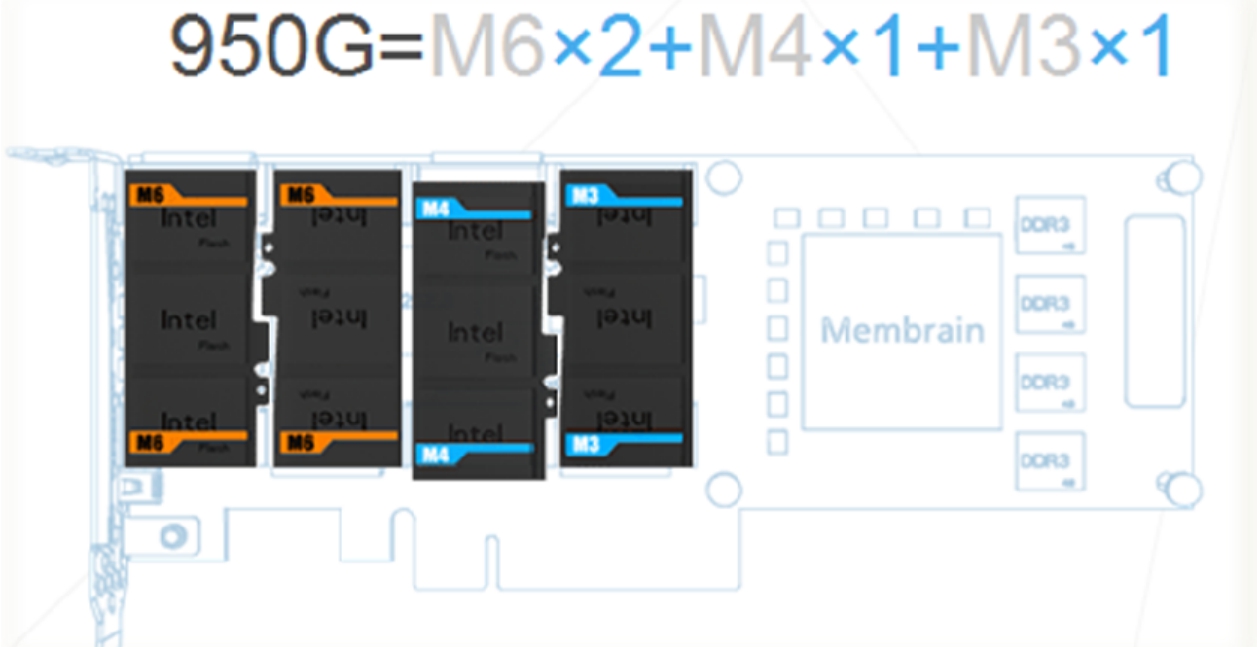
图3-44 Memblaze的琴键技术
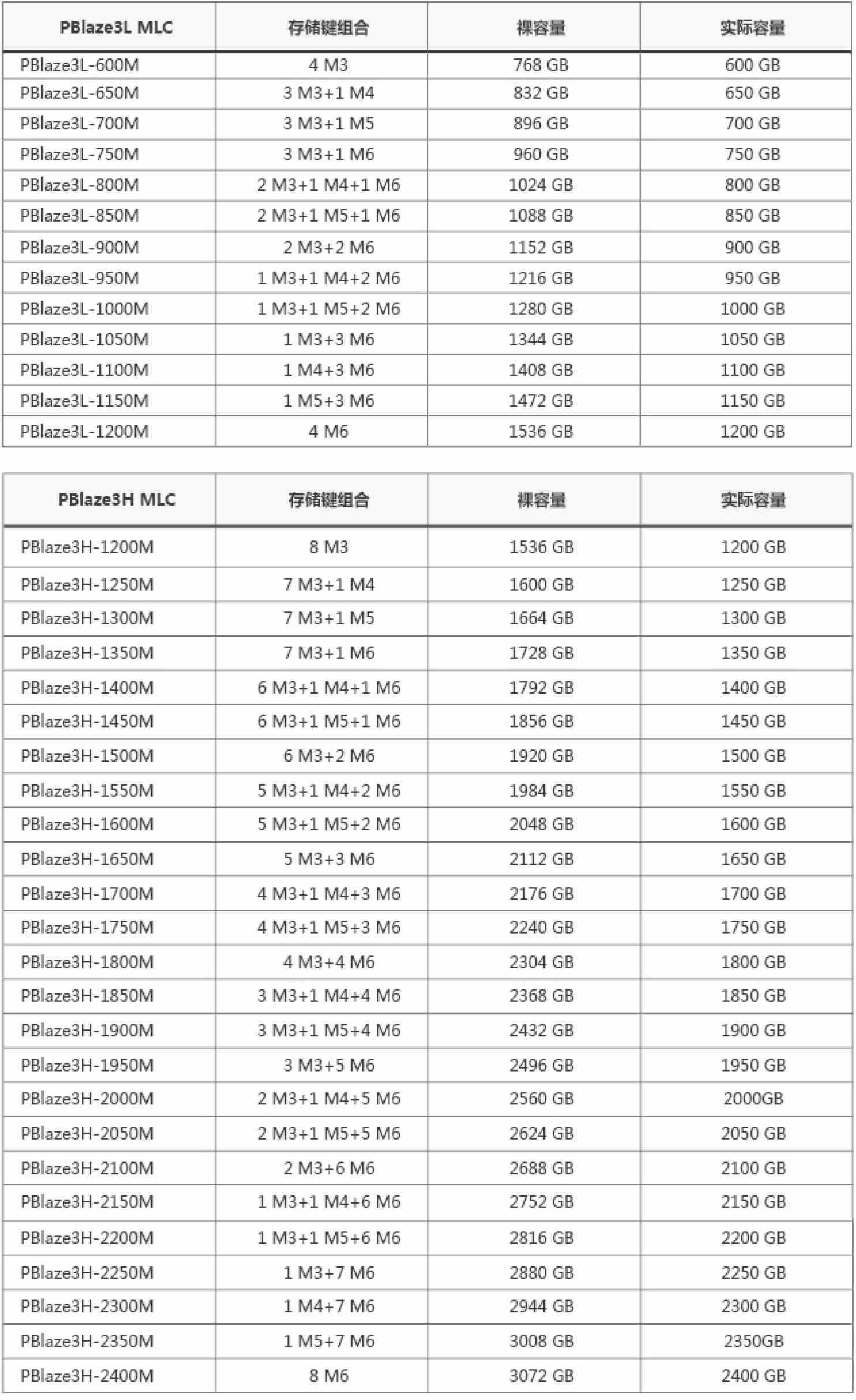
图3-45 Memblaze的琴键技术不同组合容量
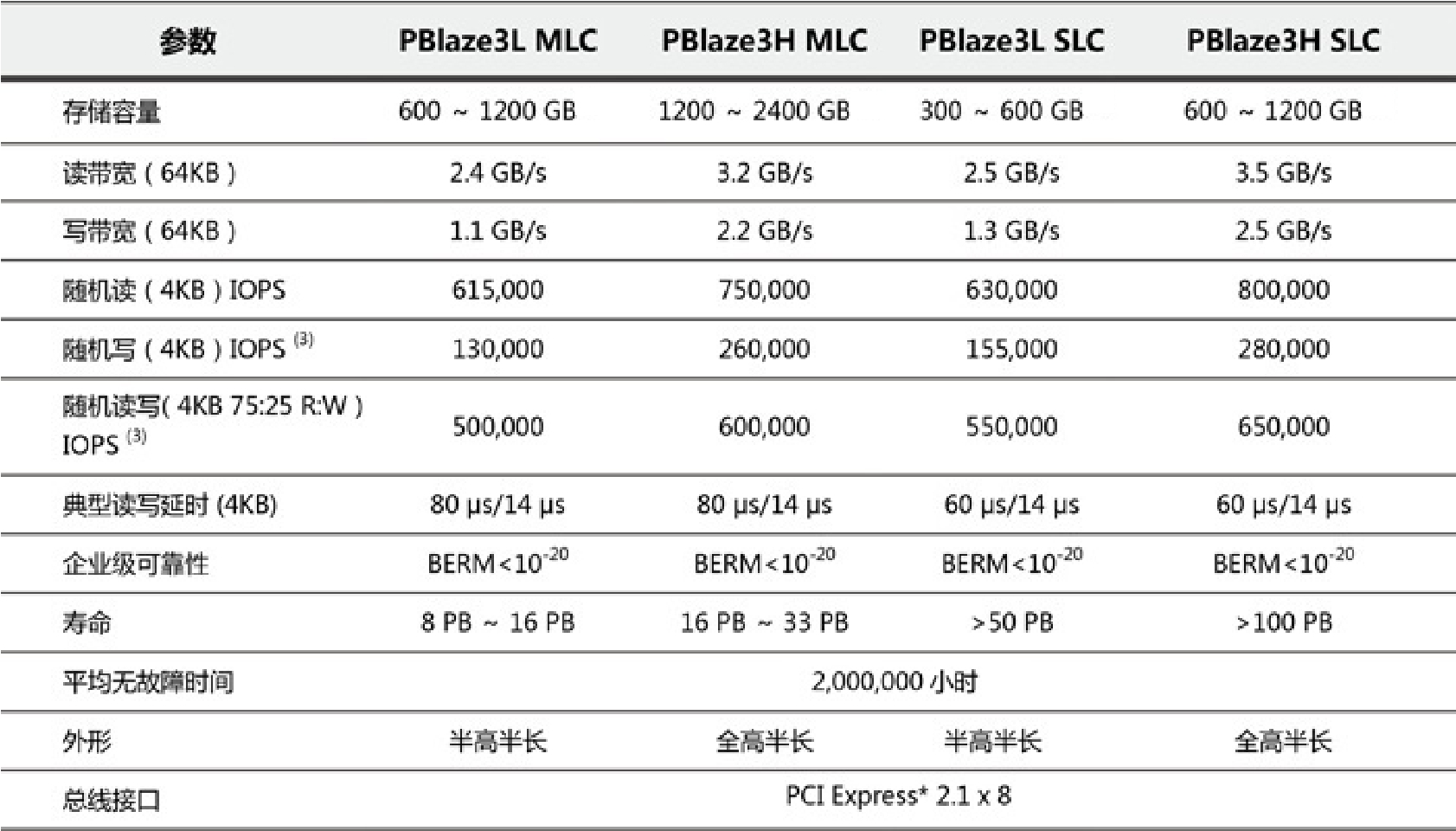
图3-46 Memblaze闪存卡其他规格
说明: Memblaze是一家让人钦佩的初创公司,在此我也得知他们后续有很长远的规划,也非常期待能够早日见到其更有特色的产品。
我们用图3-47来作为本章的结束。
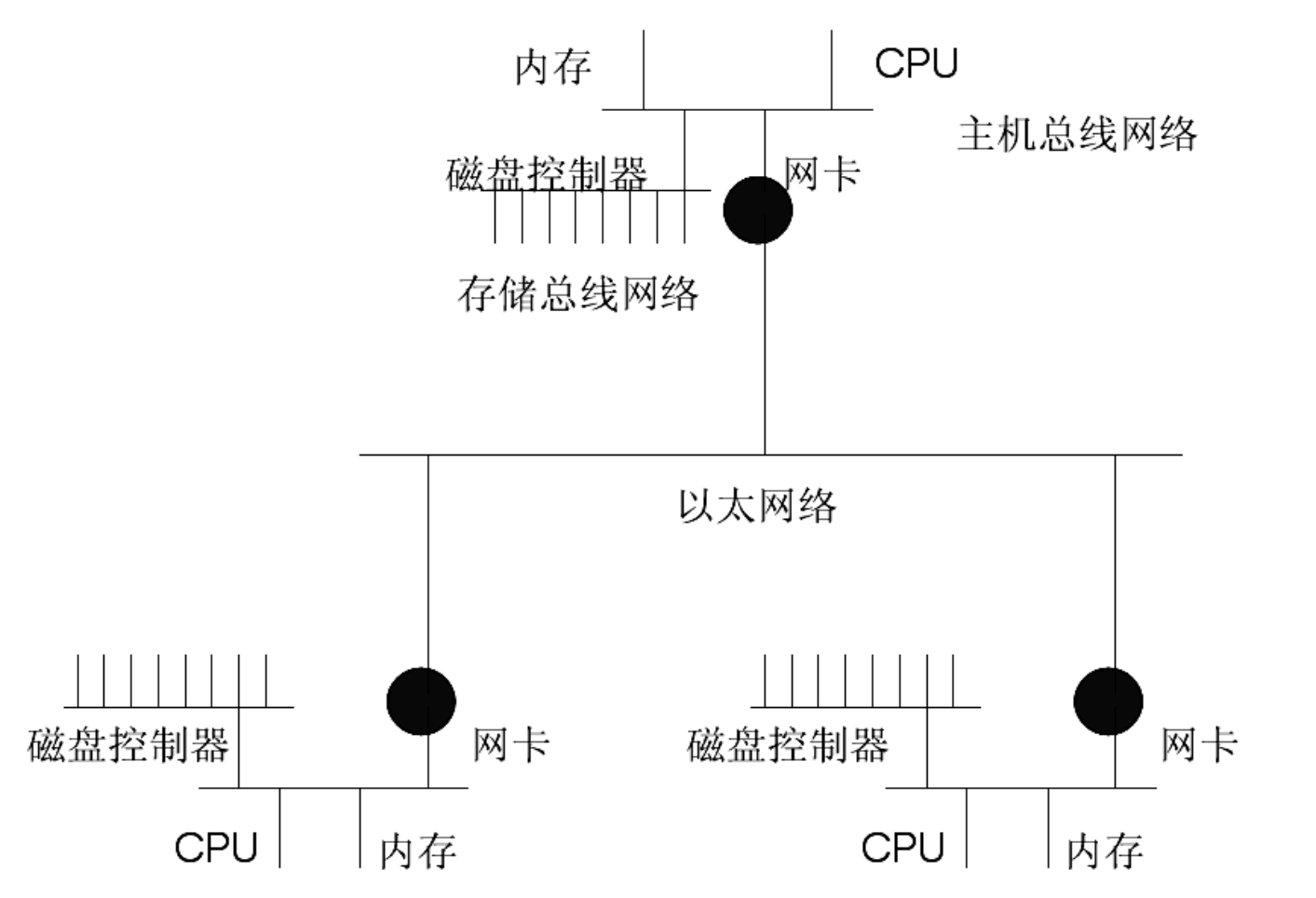
图3-47 三台计算机组成的网——网中有网
