
下载掌阅APP,畅读海量书库
立即打开



大家都知道,组成计算机的三大件是CPU、内存和IO。CPU和内存就不用说了,那么IO具体是什么呢?IO就是IN和OUT的简称。顾名思义,CPU需要从内存中提取数据来运算,运算完毕后再放回内存,或者直接将电信号发向一些针脚以操作外部设备。对于CPU来说,从内存提取数据,就叫做IN。运算完后将数据直接发送到某些其他针脚或者放回内存,这个过程就是OUT。对于磁盘来说,IN是指数据写入磁盘的过程,OUT则是指数据从磁盘读出来的过程。IO只是一个过程,那为何要在本书开头就研究它呢?因为我们必须弄清楚计算机系统的数据流动和处理过程。数据在每个部件中不断地进行IO过程,传递给CPU由其进行运算处理之后,再经过IO过程,最终到达输出设备供人使用。
现代计算机中,IO是通过共享一条总线的方式来实现的。如图2-1所示,总线也就是一条或者多条物理上的导线,每个部件都接到这些导线上,导线上的电位每个时刻都是相等的,这样总线上的所有部件都会收到相同的信号。也就是说,这条总线是共享的,同一时刻只能有一个部件在接收或者发送,是半双工的工作模式。
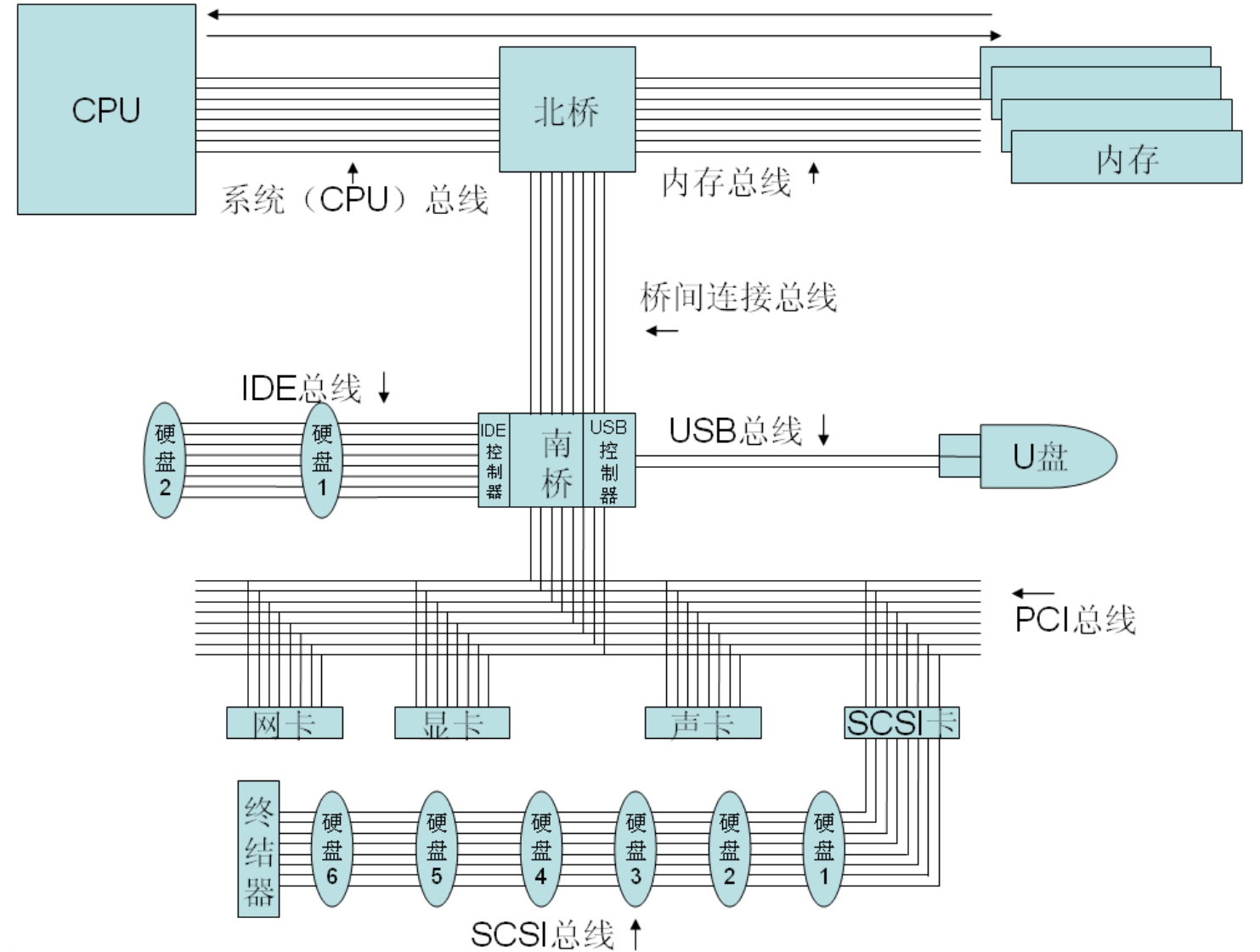
图2-1 计算机总线示意图
所有部件按照另一条总线,也就是仲裁总线或者中断总线上给出的信号来判断这个时刻总线可以由哪个部件来使用。产生仲裁总线或者中断电位的可以是CPU,也可以是总线上的其他设备。如果CPU要向某个设备做输出操作,那么就由CPU主动做中断。如果某个设备请求向CPU发送信号,则由这个设备来主动产生中断信号来通知CPU。CPU运行操作系统内核的设备管理程序,从而产生了这些信号。
如图2-1所示,主板上的每个部件都是通过总线连接起来的。图中只画了8条导线,而实际中,导线的数目远远不止8条,可能是16条、32条、64条甚至128条。这些导线密密麻麻地印刷在电路板上,由于导线之间非常密集,在高频振荡时会产生很大干扰,所以人们将这些导线分组印刷到不同电路板上,然后再将这些电路板压合起来,形成一块板,这就是多层印刷电路板(多层PCB)。这样,每张板上的导线数量降低了,同时板与板之间的信号屏蔽性很好,不会相互干扰。这些导线之中,有一些是部件之间交互数据用的数据总线,有些则是它们互相传递控制信号用的控制总线,有些则是中断与仲裁用的中断总线,还有一些则是地址总线,用来确认通信时的目标设备。一般按照数据总线的条数来确认一个总线或设备的位宽(CPU是按照其内部寄存器到运算单元之间的总线数目来确定位数的)。比如32位PCI总线,则表明这条总线共有32根导线用于传递数据信号。PCI总线可以终结在一个插槽,用于将PCI接口的板卡接入PCI总线,也可以直接与设备连接。后者一般用于集成在主板上的设备,因为它们之间无须使用插槽来连接。
目前最新的主板架构中,高速总线比如PCIE 2.0往往是直接接入北桥,南桥只连接低速总线。
PCI总线是目前台式机与服务器所普遍使用的一种南桥与外设连接的总线技术。
PCI总线的地址总线与数据总线是分时复用的。这样的好处是,一方面可以节省接插件的管脚数,另一方面便于实现突发数据传输。在数据传输时,一个PCI设备作为发起者(主控,Initiator或Master),而另一个PCI设备作为目标(从设备、Target或Slave)。总线上的所有时序的产生与控制,都由Master来发起。PCI总线在同一时刻只能供一对设备完成传输,这就要求有一个仲裁机构(Arbiter),来决定谁有权力拿到总线的主控权。
当PCI总线进行操作时,发起者(Master)先置REQ#信号Master用来请求总线使用权的信号),当得到仲裁器(Arbiter)的许可时(GNT#信号),会将FRAME#信号(传输开始或者结束信号)置低,并在地址总线(也就是数据总线,地址线和数据线是共享的)上放置Slave地址,同时C/BE#(命令信号)放置命令信号,说明接下来的传输类型。
所有PCI总线上的设备都需对此地址译码,被选中的设备要置DEVSEL#(被选中信号)以声明自己被选中。当IRDY#(Master可以发送数据)与TRDY#(Slave可以发送数据)都置低时,可以传输数据。当Master数据传输结束前,将FRAME#置高以标明只剩最后一组数据要传输,并在传完数据后放开IRDY#以释放总线控制权。
PCI总线可以实现中断共享,即不同的设备使用同一个中断而不发生冲突。
硬件上,采用电平触发的办法:中断信号在系统一侧用电阻接高,而要产生中断的板卡上利用三极管的集电极将信号拉低。这样不管有几块板产生中断,中断信号都是低电平;而只有当所有板卡的中断都得到处理后,中断信号才会恢复高电平。
软件上,采用中断链的方法:假设系统启动时,发现板卡A用了中断7,就会将中断7对应的内存区指向A卡对应的中断服务程序入口ISR_A;然后系统发现板卡B也用中断7,这时就会将中断7对应的内存区指向ISR_B,同时将ISR_B的结束指向ISR_A。依此类推,就会形成一个中断链。而当有中断发生时,系统跳转到中断7对应的内存,也就是ISR_B。ISR_B就要检查是不是B卡的中断,如果是则处理,并将板卡上的拉低电路放开;如果不是则呼叫ISR_A。这样就完成了中断的共享。
网络是什么,用一句话来说就是将要通信的所有节点连接起来,然后找到目标,找到后就发送数据。笔者把这种简单模型叫做“连找发”网络三元素模型,听起来非常简单。
网络系统当然首先要都连接起来,不管用什么样的连接方式,比如HUB总线、以太网交换、电话交换、无线、直连、中转等。在这些层面上每个网络点到其他网络点,总有通路,总是可达。
连接起来之后,由于节点太多,怎么来区分呢?所以就需要有个区分机制。当然首先就想到了命名,就像给人起名一样。在目前广泛使用的网络互联协议TCP/IP中,IP这种命名方式占了主导地位,统一了天下。其他的命名方式在IP看来都是“非正统”的,全部被“映射”到了IP。比如MAC地址和IP的映射,Frame Relay中DLCI地址和IP的映射,ATM中ATM地址和IP的映射,最终都映射成IP地址。任何节点,不管所在的环境使用什么命名方式,到了TCP/IP协议的国度里,就都需要有个IP名(IP地址),然后全部用TCP/IP协议来实现节点到节点无障碍的通信。在“连起来”这个层面,就是OSI(本书第7章介绍)模型中链路层实现的功能。
“找目标”这个层面是网络层实现的功能。“发数据”这个层面,就是传输层需要保障的。至于发什么数据,数据是什么格式,这两个层面就不是网络通信所关心的了,它们已经属于OSI模型中上三层的内容了。
IO总线可以接入多个外设,比如键盘、鼠标、网卡、显卡、USB设备、串口设备和并口设备等,最重要的当然要属磁盘设备了。讲到这里,大家的脑海中应该能出现这样一种架构:CPU、内存和各种外设都连接到一个总线上,这不正是以太网HUB的模型么?HUB本身就是一个总线结构而已,所有接口都接在一条总线上,HUB所做的就是避免总线信号衰减,因此需要电源来加强总线上的电信号。
没错!仔细分析之后,发现它确实就是这么一个模型!不过IO总线和以太网HUB模型还是有些区别。CPU和内存因为足够快,它们之间单独用一条总线连接。这个总线和慢速IO总线之间通过一个桥接芯片连接,也就是主板上的北桥芯片。这个芯片连接了CPU、内存和IO总线。
CPU与北桥连接的总线叫做系统总线,也称为前端总线。这个总线的传输频率与CPU的自身频率是两个不同概念,总线频率相当于CPU向外部存取数据时的数据传输速率,而CPU自身的频率则表示CPU运算时电路产生的频率。
提示: 本书写作时,Intel用于PC的CPU前端总线频率已经可以达到2000MHz,而作者用来写作的PC,CPU为Intel赛扬II,前端总线只有100MHz,整整20倍的提升,而CPU自身频率提升不过三四倍而已,但是性能却提升了远超三四倍。
前端总线的条数,比如64条或者128条,就叫做总线的位数。这个位数与CPU内部的位数也是不同的概念,CPU位数指的是寄存器和运算单元之间总线的条数。内存与北桥连接的总线叫做内存总线。由于北桥速度太快,而IO总线速度相对北桥显得太慢,所以北桥和IO总线之间,往往要增加一个网桥,叫做南桥,在南桥上一般集成了众多外设的控制器,比如磁盘控制器、USB控制器等。
思考: 这不正是个不折不扣的“网络”么?而且还是个不折不扣的“网桥”!我们看,CPU和内存是一个冲突域,IO总线是一个冲突域,桥接芯片将这两个冲突域桥接起来,这正是网桥的思想!太好了!我们的思想在这个模型中得到了升华!我们知道了计算机系统原来就是一个网络啊!
下面就来看看,在这个网络上,我们能够干点什么惊天动地的事呢?
提示: IO总线其实不是一条总线,它分成数据总线、地址总线和控制总线。寻址用地址总线,发数据用数据总线,发中断信号用控制总线。而且IO总线是并行而不是串行的,有32位或者64位总线。32位总线也就是说有32根导线来传数据,64位总线用64根导线来并行传数据。
CPU是一个芯片,磁盘是一个有接口的盒子,它们不是一体的而是分开的,而且都连接在这个网桥上。那么CPU向磁盘要数据,也就是两个节点之间的通信,必定要通过一种通路来获取,这个通路当然是电路!
提示: 当然也可以是辐射的电磁波,估计21世纪还应用不到CPU上。
凡是分割的节点之间,需要接触和通信,就可以成为网络。那么就不由得使我们往OSI模型上去靠,这个模型定义得很好。既然通信是通过电路,也就是物理层的东西,那么链路层都有什么内容呢?
大家知道,链路层相当于一个司机,它把货物运输到对端。司机的作用就是驾驶车辆,而且要判断交通规则做出配合。那么在这个计算机总线组成的网络中,是否也需要这样一个角色呢?答案是不需要。因为各个节点之间的路实在是太短、太稳定了!主板上那些电容、电阻和蛇行线,这一切都是为了保障这些电路的稳定和高速。在这样的一条高速、高成本的道路上,是不需要司机的,更不需要押运员!所以,计算机总线网络是一个只有物理层、网络层和上三层的网络!
强调: 所有的网络都可以定义成连起来、找目标和发数据。也就是“连找发”模型,这也是构成一个网络的三元素。任何网络都必须具有这三元素(点对点网络除外)。连,代表物理层。物理层必须要有,如果没有物理层,要达到两点之间通信是不可能的。物理层可以是导线,可以是电磁波,总之必须有物理层。找,突出一个找字,既然要找,那么就要区分方法,也就是编址,比如IP等。发,突出一个发字,即指最上层发出数据。
下面就按照“连找发”三元素理论,去分析一个CPU向磁盘要数据的例子。
CPU与硬盘数据交互的过程如下。
首先看“连”这个元素,这个当然已经具备了,因为总线已经提供了“连”所需的条件。
再看“找”这个元素,前面说了,首先要有区分,才能有所谓“找”,这个区分体现在主机总线中就是设备地址映射。每个IO设备在启动时都要向内存中映射一个或者多个地址,这个地址有8位长,又被称做IO端口。针对这个地址的数据,统统被北桥芯片重定向到总线上实际的设备上。假如,IDE磁盘控制器地址被映射到了地址0xA0,也就是十六进制A0,CPU根据程序机器代码,向这个地址发出多条指令来完成一个读操作,这就是“找”。“找”的条件也具备了。
接下来我们看看“发”这个元素!首先CPU将这个IO地址放到系统总线上,北桥接收到之后,会等待CPU发送第一个针对这个外设的指令。然后CPU发送如下3条指令。
第一条指令:指令中包含了表示当前指令是读还是写的位,而且还包含了其他选项,比如操作完成时是否用中断来通知CPU处理,是否启用磁盘缓存等。
第二条指令:指明应该读取的硬盘逻辑块号(LBA)。这个逻辑块在我们讲磁盘结构时会讲到,总之逻辑块就是对磁盘上存储区域的一种抽象。
第三条指令:给出了读取出来的内容应该存放到内存中哪个地址中。
这3条指令被北桥依次发送给IO总线上的磁盘控制器来执行。磁盘控制器收到第一条指令之后,知道这是读指令,而且知道这个操作的一些选项,比如完成是否发中断,是否启用磁盘缓存等,然后磁盘控制器会继续等待下一条指令,即逻辑块地址(号)。磁盘控制器收到指令之后,会进行磁盘实际扇区和逻辑块的对应查找,可能一个逻辑块会对应多个扇区,查找完成之后,控制器驱动磁头寻道,等盘体旋转到那个扇区后,磁头开始读出数据。在读取数据的同时,磁盘控制器会接收到第三条指令,也就是CPU给出的数据应该存放在内存中的地址。有了这个地址,数据读出之后直接通过DMA技术,也就是磁盘控制器可以直接对内存寻址并执行写操作,而不必先转到CPU,然后再从CPU存到内存中。数据存到内存中之后,CPU就从内存中取数据,进行其他运算。
上面说的过程是“读”,“写”的过程也可以依此类推,而且CPU向磁盘读写数据,和向内存读写数据大同小异,只不过CPU和内存之间有更高速的缓存。缓存对于计算机很重要,对于磁盘阵列同样重要,后面内容将会介绍到。
思考: CPU在对磁盘发送指令的时候,这些指令是怎么定义的?这些指令其实是发给了主板南桥上集成的(或者是通过PCI接入IO总线的)控制器,比如ATA控制器或者SCSI控制器。然后控制器再向磁盘发出一系列的指令,让磁盘读取或者写入某个磁道、某个扇区等。CPU不需要知道这些,CPU只需要知道逻辑块地址是读还是写就可以了。让CPU产生这些信号的是磁盘控制器驱动程序。
那么控制器对磁盘发出的一系列指令是怎么定义的呢?它们形成了两大体系,一个是ATA指令集,一个是SCSI指令集。SCSI指令集比ATA指令集高效,所以广泛用于服务器和磁盘阵列环境中。这些指令集,也可以称为协议,协议就是语言,就是让通信双方知道对方传过来的比特流里面到底包含了什么,怎么由笔划组成字,由字组成词,词组成句子,等等。
通过图2-2可以体会到,计算机的主板上的各个部件本身就形成了一个网络,而且通过网卡,还可以连接到外部网络。
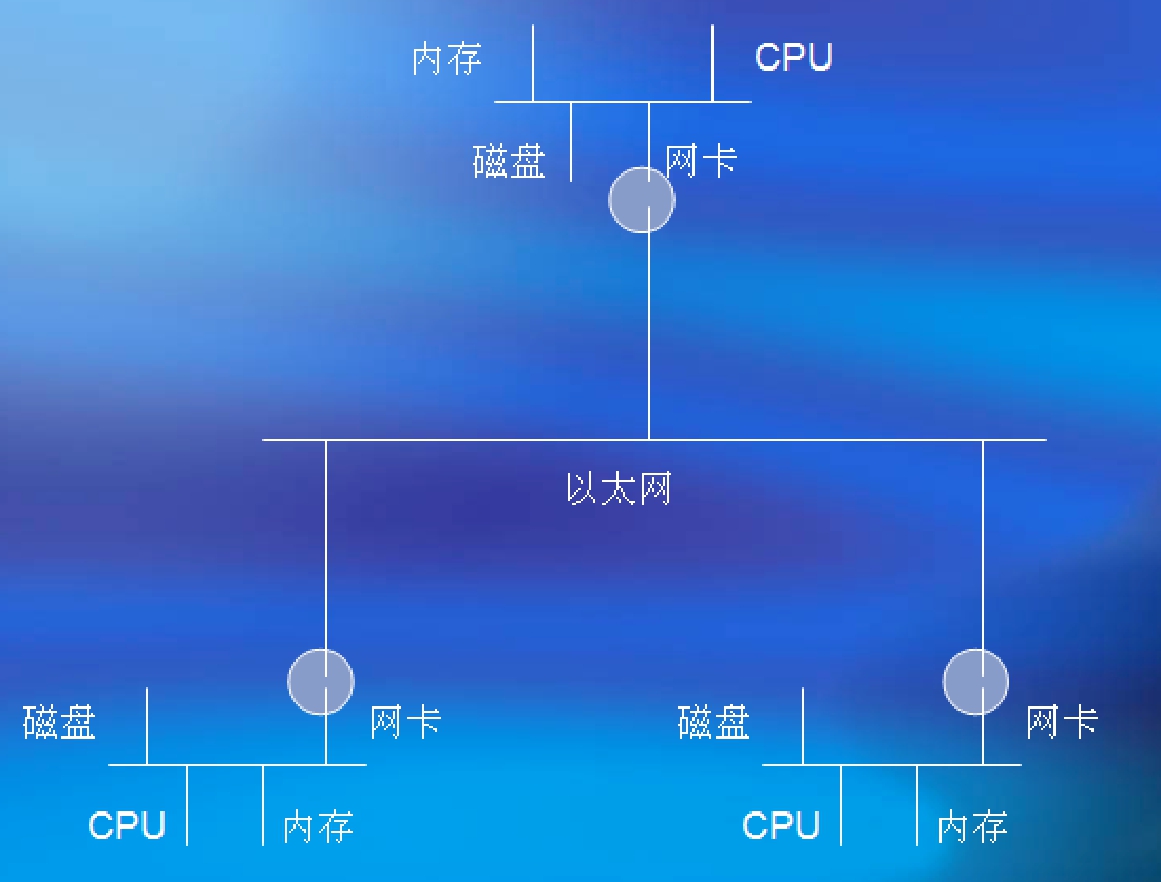
图2-2 网中之网
正所谓:
CPU内存和磁盘,
大家都在线上谈。
待当看破三元素,
网中有网天际来!
