
下载掌阅APP,畅读海量书库
立即打开



代码生成是编译器后端的统称,在编译器的实现中占据着非常重要的地位,也是非常复杂的模块。以LLVM 15为例,整个项目代码行数超过1000万
 ,其中Clang相关代码超过400万行,LLVM中端优化以及后端代码生成相关代码也有近400万行。其中代码生成相关代码量约为200万行,包含了架构无关的代码和架构相关的代码。其中,架构无关代码约为50万行,架构相关代码约为150万行。架构无关的代码主要包含了指令选择、指令调度、寄存器分配和机器码生成;架构相关代码量是LLVM所有支持的后端的代码总和。目前LLVM支持的后端已超过20种,有些后端的实现非常复杂,如x86后端的代码量超过了20万行,而有些又非常简单,如BPF后端的代码量只有1万行左右。
,其中Clang相关代码超过400万行,LLVM中端优化以及后端代码生成相关代码也有近400万行。其中代码生成相关代码量约为200万行,包含了架构无关的代码和架构相关的代码。其中,架构无关代码约为50万行,架构相关代码约为150万行。架构无关的代码主要包含了指令选择、指令调度、寄存器分配和机器码生成;架构相关代码量是LLVM所有支持的后端的代码总和。目前LLVM支持的后端已超过20种,有些后端的实现非常复杂,如x86后端的代码量超过了20万行,而有些又非常简单,如BPF后端的代码量只有1万行左右。
虽然代码生成模块非常复杂,但LLVM通过模块化的设计,将不同的功能设计为不同的Pass,然后进行组合,以完成代码生成。LLVM代码生成的整体逻辑如下图所示。

每个模块的主要工作简单总结如下。
1)指令选择:为LLVM IR选择合适的机器指令。LLVM实现了3种指令选择算法,分别是FastISel、SelectionDAGISel、GlobalISel。目前LLVM后端默认使用的是基于DAG的SelectionDAGISel指令选择算法,它在指令选择阶段引入了图IR,并使用图匹配的方法为LLVM IR生成MIR。值得注意的是,MIR不完全是目标无关的IR。(虽然MIR结构与后端无关,但是大部分MIR的操作码和具体后端相关,只有少数MIR操作码和后端无关,例如一些伪指令。)
2)指令调度-1:根据MIR中的数据依赖对指令进行调度。目前LLVM实现了几种指令调度策略,如表调度(list scheduling)、循环调度等。此时的优化也称为Pre-RA调度,目的在于减少寄存器分配过程中的压力。注意,在指令选择阶段也有指令调度(图中没有体现)。
3)编译优化-1:基于SSA形式的MIR进行编译优化,例如进行死代码删除、公共表达式消除等优化。
4)寄存器分配:将MIR中使用的逻辑寄存器映射到物理寄存器,目前LLVM中提供了4种寄存器分配算法,分别是Fast、Basic、Greedy和PBQP(划分布尔二次问题),可以通过命令参数regalloc指定。
5)前言/后序代码生成:为函数生成前言和后序代码,例如处理栈帧布局等。
6)编译优化-2:经过寄存器分配后的MIR为非SSA形式,可以再次执行一些编译优化,例如复制传播优化等。需要注意的是,此时执行的编译优化和SSA形式的优化的思路相同,但是因为MIR不再具有SSA的特点,所以导致优化算法实现也有所不同。
7)指令调度-2:再次执行指令调度,此时的优化也称为Post-RA调度,目的在于提高执行效率。
8)其他优化:执行机器码发射前的优化,例如执行基本块重排等优化,此处还允许后端实现自己特殊的优化。
9)机器码发射:寄存器分配完成后就可以进入机器码发射阶段(真正生成目标机器代码)。为了更好地生成目标代码,LLVM引入了MCInst IR(MC),可以更加优雅地处理JIT代码,以及汇编和反汇编代码。
BPF后端的代码生成过程大概涉及45个Pass(不同版本略有不同),上面提到的每个模块都有涉及。而其他一些复杂的后端,例如x86或者AArch64的代码生成过程涉及的Pass通常超过100个(BPF后端的Pass都包含在这100多个Pass中)。和BPF后端相比,这些额外的Pass多数是和后端优化相关的。
当然,要在书中将这45个Pass都详细地介绍也是不可能的事情,故而主要对最重要的一些Pass——指令选择、指令调度、寄存器分配、代码输出进行介绍。除此以外,本书还介绍了一些较为实用的优化Pass,例如If-Conversion(对GPGPU这样的特殊架构效果很好)、公共代码提取(对代码小型化有效果)、代码布局(对提升代码运行性能有较好效果)等。
实际上,对于Pass而言,除了开发更多、更强大的功能外,还有两个研究方向:一个方向是Pass之间的执行顺序对性能的影响,另一个方向是代码生成过程中Pass的重要性,例如关闭JIT中一些不重要的Pass可能获得更好的性能。
对Pass顺序的研究一直以来都是编译优化中较为重要的一个方向,因为编译优化的Pass之间可能相互影响,导致不同Pass执行顺序下产生的机器码质量不同。编译优化是NP难题,无法找到最优解,但是可以根据场景需求,对Pass顺序进行调整生成高质量机器码,这方面有不少论文,读者可以自行查阅。
一些学者通过代码生成过程中不同Pass的耗时进行了量化分析,以研究Pass的重要性,因为Pass的耗时从某种程度上反映了重要程度。例如,在一些基准测试中Top 20的Pass耗时如下表所示:
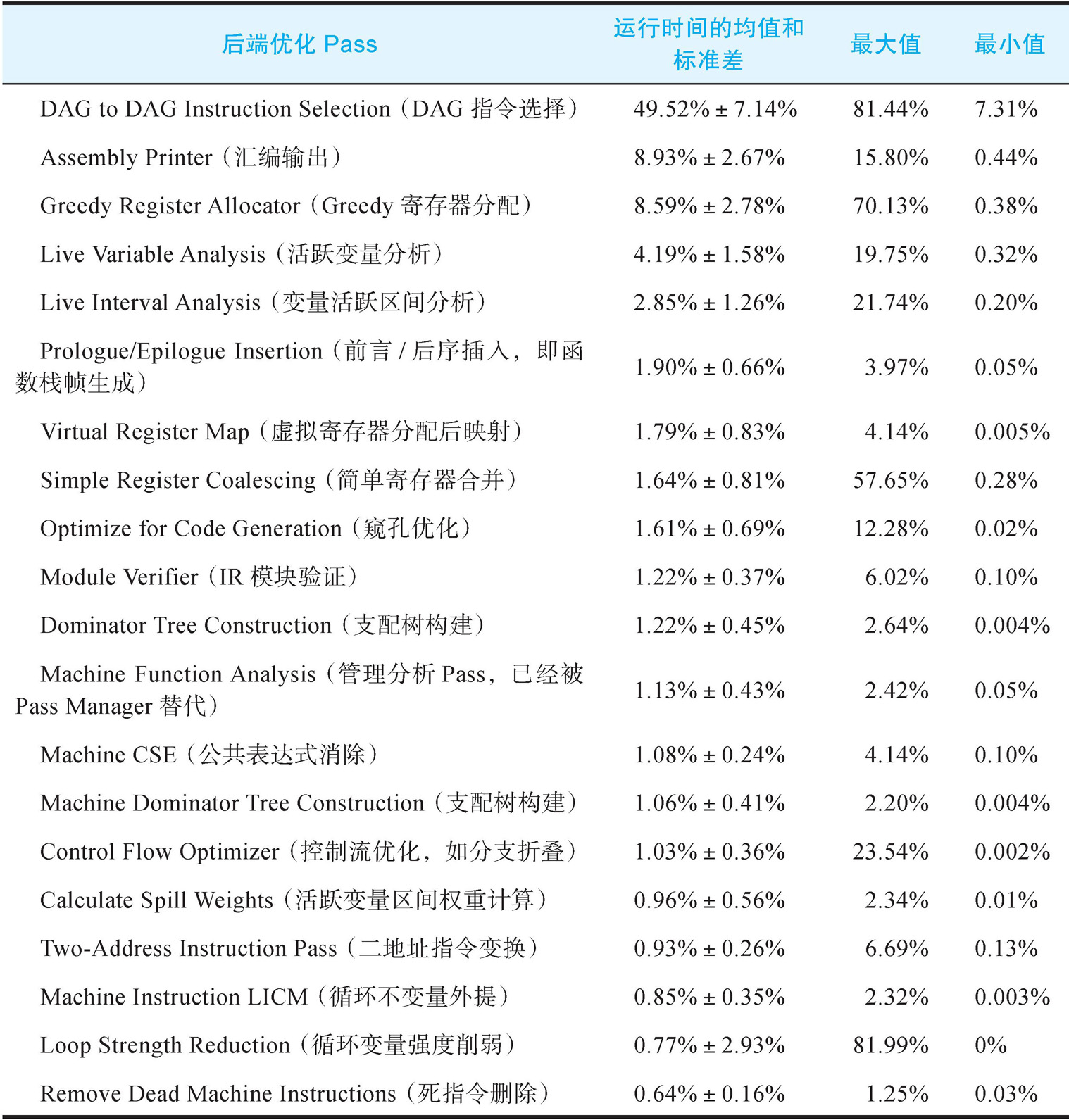
该表的结果是基于LLVM 3.0进行编译的,测试套件为SPEC CPU2006,执行后端优化前经过了充分的中端优化,这一研究的目的是预测JIT等场景中后端编译优化的时间。(由于JIT是运行时进行的编译优化,需要平衡编译质量和编译时间,通过预测编译优化所需的时间可以确定JIT应该使用的编译优化算法。)通过该表可以看到不同的编译优化耗时占比情况,通常来说编译耗时较长,功能越重要。例如,指令选择、寄存器分配、汇编码生成是编译后端必需的功能,其耗时占比接近70%,这也和本书重点介绍的内容一致。
除了重点Pass外,本书对表中其他Pass都有涉猎(个别Pass除外,例如Machine Function Analysis已经被Pass Manager替代),不过详细程度不同,有些仅仅简单介绍了原理(比如支配树),读者可以自行阅读源码或者参考相关资料了解更多细节。通过该表,读者可以对代码生成的功能和重要程度有一个简单的印象,更多信息可以参考论文
。