
下载掌阅APP,畅读海量书库
立即打开



咖哥接着说:当然,在为人工智能走向通用化而心潮澎湃之际,让我们一起回顾一下它的来时路。看看这短短不到百年的时间,人工智能是如何一步步走到今天的。
人工智能这一概念可追溯到20世纪40年代和50年代,但它是在1956年的达特茅斯会议上成为一个独立的学科领域的。在这次会议上,许多计算机科学家、数学家和其他领域的研究者聚集在一起,共同探讨智能机器的发展前景。他们的目标是在计算机上实现人类智能的各个方面的应用,从而开创了现代人工智能研究的道路。从那时起,人工智能领域不断发展,涌现出众多理论、技术和应用。
不过,人工智能的发展并非一帆风顺,其核心技术——深度学习(Deep Learning),以及深度学习的基础——神经网络(Neural Network),曾经历过两次被称为“AI寒冬”的低谷期。下页图就是对以神经网络为主线的AI技术发展史做的一个梳理。
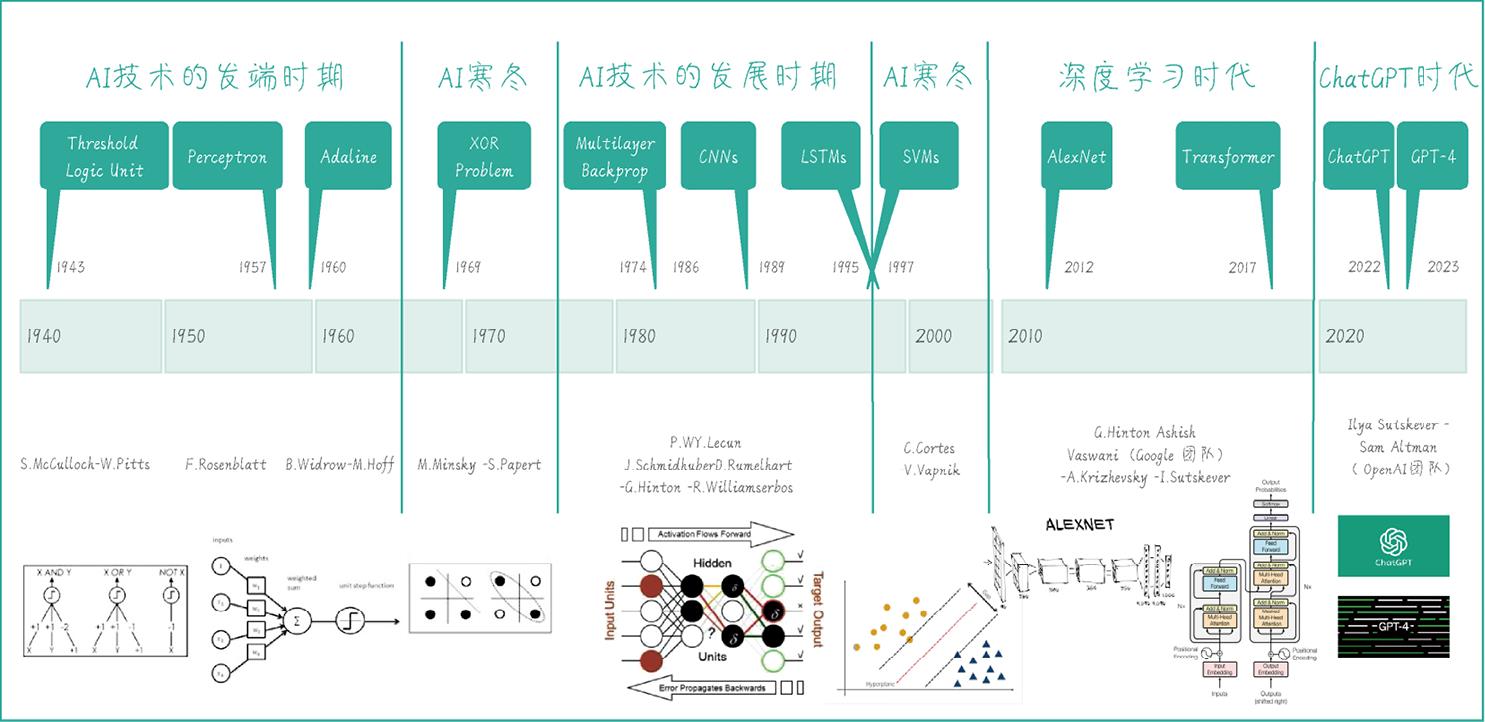
AI技术发展里程碑
小冰:是的,咖哥,这些内容你曾在《零基础学机器学习》中给我介绍过,这些AI技术发展里程碑,我都记忆犹新。
■ 阈值逻辑单元(Threshold Logic Unit): 最早可以追溯到1943年,由美国神经生理学家沃伦·麦克卡洛克(Warren McCulloch)和数学家沃尔特·皮茨(Walter Pitts)共同提出。阈值逻辑单元是一种简单的逻辑门,通过设置阈值来确定输出。它被认为是神经网络和人工智能领域的基石。
■ 感知器(Perceptron): 1952年的霍奇金-赫胥黎模型(Hodgkin-Huxley model)展示了大脑如何利用神经元形成神经网络。该模型通过研究电压和电流如何在神经元中传递,为神经元的动作电位提供了详细的生物物理学描述。基于这个模型带来的启发,弗兰克·罗森布拉特(Frank Rosenblatt)在1957年推出了感知器。它是第一个具有自我学习能力的模型,根据输入与目标值的误差调整权重,而且能进行简单的二分类任务。虽然感知器只是一种线性分类器,但是它具有重要的历史地位,是现代神经网络的雏形和起点。
■ 自适应线性神经元(Adaline): 自适应线性神经元是伯纳德·维德罗(Bernard Widrow)和特德·霍夫(Ted Hoff)在1960年发明的。它的学习规则基于最小均方误差,与感知器相似,但有更好的收敛性能。
■ 第一次AI寒冬——XOR问题(XOR Problem):1969年,马尔温·明斯基(Marvin Minsky)和西摩·佩珀特(Seymour Papert)在《感知器》( Perceptrons )一书中提出,单层感知器具有局限性,无法解决非线性问题(书中的XOR问题,异或问题就是一种非线性问题)。这一发现导致人们对感知器技术失望,相关的资金投入逐渐减少,第一次AI寒冬开始。
■ 多层反向传播算法(Multilayer Backpropagation):多层反向传播算法是一种训练多层神经网络的方法,由保罗·韦尔博斯(Paul Werbos)在1974年提出。这种方法允许梯度通过多层网络反向传播,使得训练深度网络成为可能。 大卫·鲁梅尔哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)在1986年合作发表了一篇具有里程碑意义的论文,题目为《通过反向传播误差进行表示学习》(Learning Representations By Back-propagating Errors)。这篇论文详细介绍了反向传播算法如何用于训练多层神经网络。
■ 卷积神经网络(Convolutional Neural Network,CNN):卷积神经网络是一种特殊的深度学习模型,由杨立昆(Yann LeCun)在1989年提出。它使用卷积层来学习局部特征,被广泛应用于图像识别和计算机视觉领域。
■ 长短期记忆网络(Long Short-Term Memory,LSTM):长短期记忆网络是由谢普·霍赫赖特(Sepp Hochreiter)和于尔根·施米德胡贝(Jürgen Schmidhuber)在1997年提出的一种循环神经网络(Recurrent Neural Network,RNN)结构。LSTM通过引入门控机制缓解了RNN中的梯度消失和梯度爆炸问题,使得模型能够更好地捕捉长距离依赖关系,被广泛应用于自然语言处理和时间序列预测等任务。卷积神经网络和以LSTM为代表的循环神经网络的出现,代表着神经网络重回学术界视野。
■ 第二次AI寒冬——支持向量机(Support Vector Machines,SVM):支持向量机是由弗拉基米尔·瓦普尼克(Vladimir Vapnik)和科琳娜·科尔特斯(Corinna Cortes)于1995年提出的一种有效的分类方法。它通过最大化类别间的间隔来进行分类。SVM只是多种机器学习算法中的一种,然而,它的特殊历史意义在于——SVM在很多任务中表现出的优越性能,以及良好的可解释性,让人们再度开始怀疑神经网络的潜力,导致神经网络再度被打入“冷宫”,从此沉寂多年。
不过好在在这之后,我们进入了深度学习时代。深度学习是一种具有多个隐藏层的神经网络,可以学习复杂的特征表示。随着互联网和计算能力的发展,深度学习使得在更大的数据集和更复杂的模型上进行训练成为可能。而图形处理器(Graphics Processing Unit,GPU)的并行计算能力使得深度学习研究和应用的发展加速。基于深度学习的神经网络在21世纪初开始取得显著的成果。
咖哥:对的,小冰。你刚才总结得非常清晰,在深度学习时代,现象级的理论和技术突破层出不穷。
■ AlexNet:由亚历克斯·克里泽夫斯基(Alex Krizhevsky)、伊利亚·苏茨克维(Ilya Sutskever)和杰弗里·辛顿在2012年提出的深度卷积神经网络。它在ImageNet大规模视觉识别挑战赛中取得了突破性成果,标志着深度学习时代的开始。
■ Transformer:是由阿希什·瓦斯瓦尼(Ashish Vaswani)等人在2017年的论文《你只需要注意力》(Attention Is All You Need)中提出的一种神经网络结构。Transformer 引入了自注意力(Self-Attention)机制,摒弃了传统的循环神经网络和卷积神经网络结构,从而大幅提高了训练速度和处理长序列的能力,成为后续很多先进模型的基础架构。
■ ChatGPT和GPT系列预训练模型: ChatGPT 是基于 GPT(Generative Pre-trained Transformer)架构的一种大规模语言模型,由 OpenAI 开发,其首席科学家正是曾经参与开发AlexNet 的伊利亚·苏茨克维。ChatGPT和GPT-4分别于2022年底和2023年初问世之后,迅速在全球范围刮起了一阵AI风暴,其具有的强大的文本生成能力和理解能力,令世人震惊。不过,与过往的技术突破不同,ChatGPT和GPT系列预训练模型的成功应该归功于OpenAI团队及之前AI技术的积累,而不是某一个(或几个)科学家。
从AlexNet开始,到Transformer,再到今天的ChatGPT,人类一次一次被AI的能力所震撼。
AI技术有两大核心应用:计算机视觉(Computer Vision,CV)和自然语言处理(NLP)。小冰,你有没有注意到,在AI技术发展里程碑中,前期的突破多与CV相关,如CNN和AlexNet;而后期的突破则多与NLP相关,如Transformer和ChatGPT。
下面我们再对自然语言处理技术的发展进行一下类似的梳理。你会发现,自然语言处理技术演进过程包含一些独属于它的微妙细节。而对这个过程的体会,能够让你对自然语言处理技术有更深的领悟。