
下载掌阅APP,畅读海量书库
立即打开



Apache Iceberg是一款开源的数据湖项目,Iceberg的出现进一步推动了数据湖和湖仓一体架构的发展,并且让数据湖技术变得更加丰富。通过访问网址https://iceberg.incubator.apache.org/,可进入其官方首页,如图2-25所示。
图2-25
Iceberg的主要特点如下:
· 支持Apache Spark、Flink、Presto、Trino、Hive、Impala等众多的SQL查询引擎。
· 支持更加灵活的SQL语句对数据湖中的数据进行Merge、Update、Delete操作。
· 可以很好地支持对数据Schema的变更,比如添加新的列、重命名列等。
· 支持快速的数据查询。在数据查询时,可以快速跳过不必要的分区和文件,以快速查找到符合指定条件的数据。在Iceberg中,单个表可以支持PB级别数据的快速查询。
· 数据存储支持按照时间序列的版本控制以及回滚。可以按照时间序列或者版本来查询数据的快照。
· 数据在存储时,压缩支持开箱即用。可以有效地节省数据存储的成本。
由于Hive数据仓库中表的状态是直接通过列出底层的数据文件来查看的,表的数据修改无法做到原子性,无法支持事务以及回滚,其一旦写入出错,可能就会产生不准确的结果。因此,Iceberg在底层通过架构设计时增加了元数据层这一设计,以规避Hive数据仓库的不足,如图2-26所示。从图中可以看到,Iceberg使用了两层设计来持久化数据:一层是元数据层,另一层是数据层。在数据层中存储的是Apache Parquet、Avro或ORC等格式的实际数据,在元数据层中可以有效地跟踪在进行数据操作时删除了哪些文件和文件夹,然后在扫描数据文件统计数据时就可以确定在进行特定查询时是否需要读取该文件以便提高查询速度。元数据层通常包括如下内容。
· 元数据文件:元数据文件通常存储表的Schema、分区信息和表快照的详细信息等数据信息。
· 清单列表文件:将所有清单文件信息存储为快照中清单文件的索引,并且通常会包含一些其他详细信息,如添加、删除了多少数据文件以及分区的边界情况等。
· 清单文件:存储数据文件列表(比如以Parquet/ORC/AVRO格式存储的数据),以及用于文件被修改后的列级度量和统计数据。
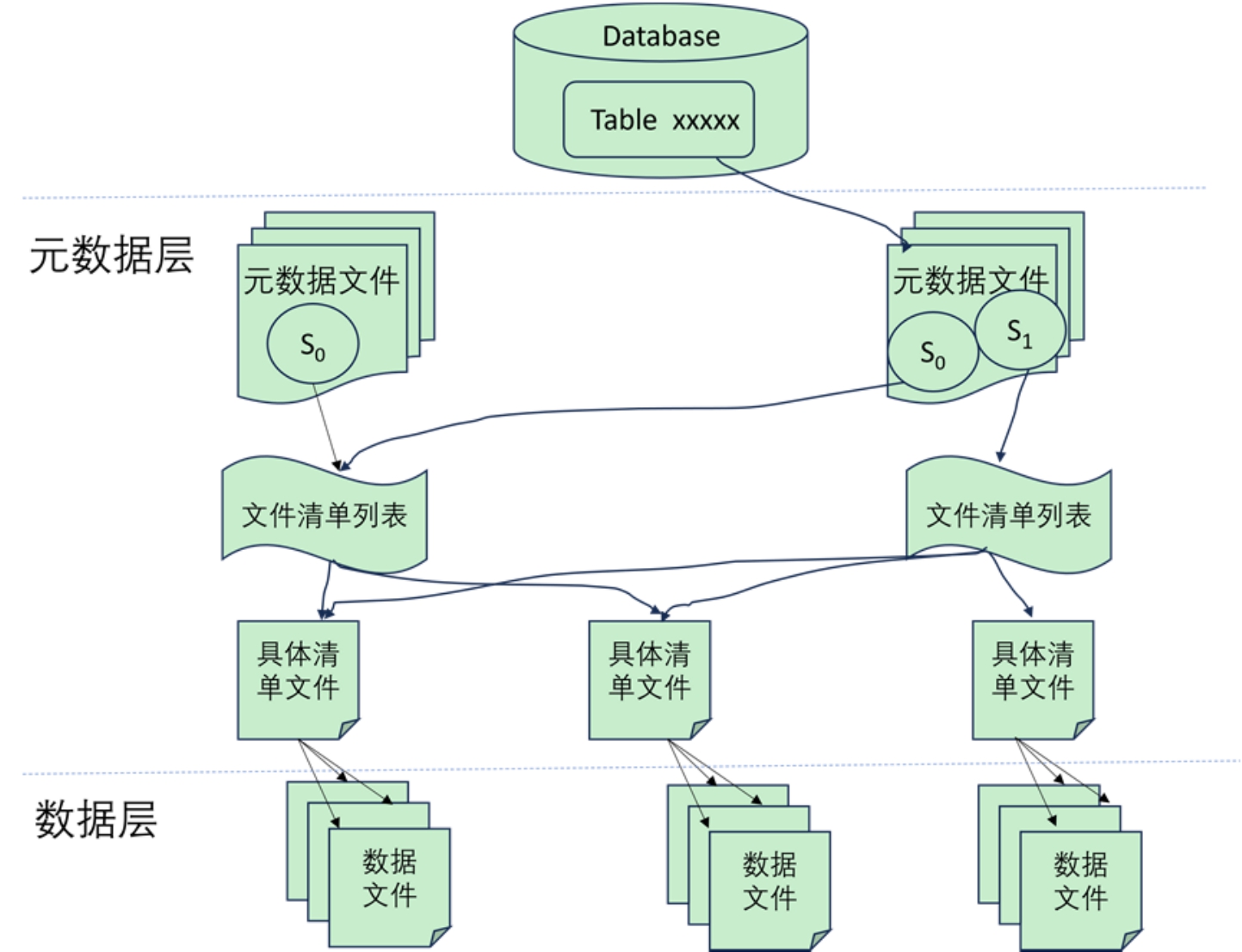
图2-26
在Iceberg的元数据层有一个树状结构,用于存储Iceberg表上每个DML/DDL操作创建的数据快照,如图2-27所示。从图中可以看到,这个元数据文件夹中已经有多个metadata.json文件来存储元数据。每当元数据发生变更时,metadata.json会按照版本号重新生成一个最新的metadata.json文件(例如v1.metadata.json、v2.metada.json),通过版本号的递增来识别最新的元数据文件。当然也可以通过打开version-hint.text文件来查看最新的metadata.json文件的名字。
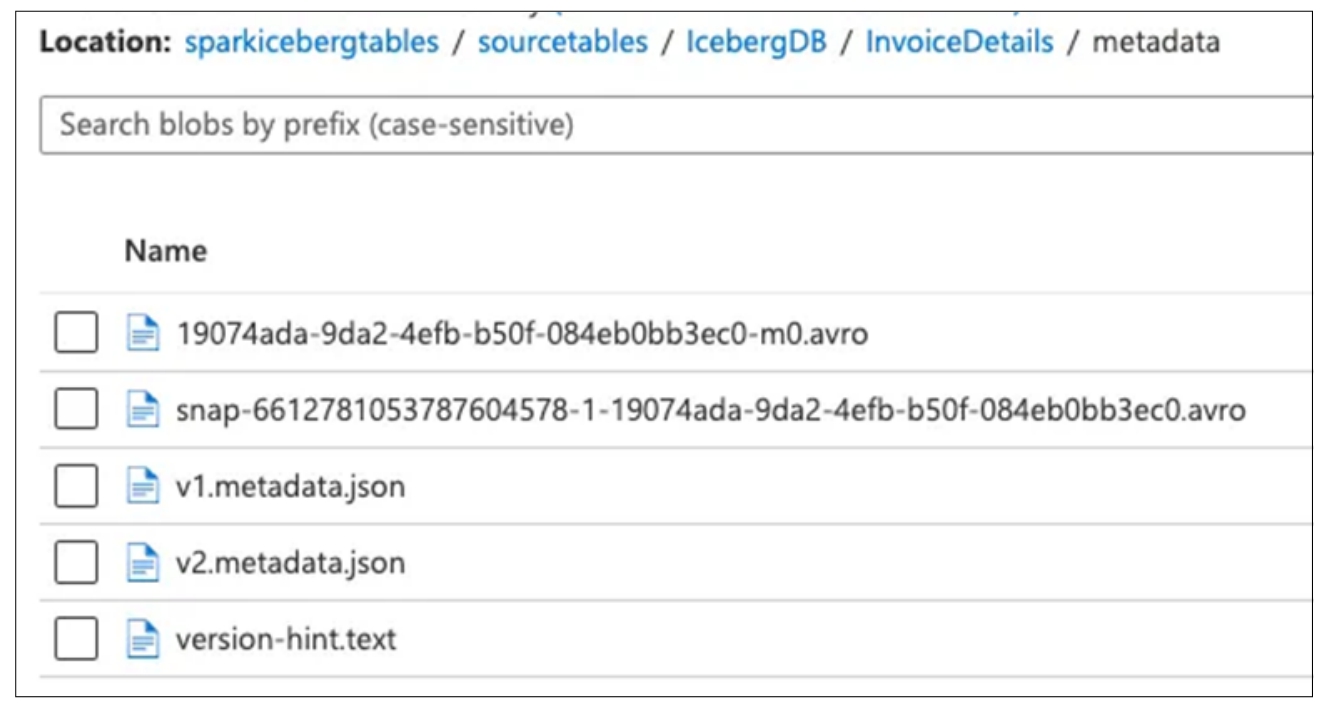
图2-27
一个metada.json文件示例如下:



metada.json文件中包括的核心内容如图2-28所示。

图2-28
从图中可以看到,元数据文件中包含一张数据表的版本号、存储路径、修改时间、表的Schema信息、字段信息、分区信息、属性信息、快照信息等,详细说明如下:
· format-version:以整型数字表示的当前数据表的版本号,当前Iceberg支持的格式版本只有1或者2。如果数据表的版本高于支持的版本,则会抛出异常。
· location:数据表的存储位置。在数据写入时,通过location来确定数据文件、清单文件和表元数据文件的具体存储位置。
· schema:表示表的当前schema。在未来新版本的Iceberg中将会弃用该字段,后续新版本的Iceberg会通过schemas来代替。
· schemas:schema的列表。用于记录schema的变更记录,通过current-schema-id能够查询到最新的schema是哪一个。
· properties:数据表的属性描述。比如commit.retry.num-retries这个属性配置用于控制数据写入时提交重试的次数。
· partition-specs:数据表的分区规范列表的描述,通常会存储为完整的分区规范对象。
· partition-spec:表的当前分区规范,仅存储为字段。该字段不推荐使用,而推荐使用partition-specs这个字段来查看分区的信息。
· snapshots:数据表的有效快照列表。有效快照是数据文件系统中存储所有数据文件的快照,在最后一个列出数据文件的快照被垃圾回收之前,通常不能从数据文件系统中删除该数据文件。
与Hudi和Delta Lake一样,由于Iceberg也支持使用Spark来读取和写入数据,因此在Iceberg的底层设计时也实现了Spark提供的CatalogPlugin接口,通过Spark Catalog的方式即可直接获取Iceberg的元数据信息。通过Spark的方式获取Iceberg的元数据信息时,需要添加如下Spark Config的配置:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("xxx")
.master("xxxx")
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSp
arkSessionExtensions")
.config("spark.sql.catalog.spark_catalog",
"org.apache.iceberg.spark.SparkCatalog")
.getOrCreate()
上述代码中需要通过Maven引入Spark的相关依赖包:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark3</artifactId>
</dependency>
在Iceberg中提供了Java API来获取表的元数据,通过访问官方网址https://iceberg.incubator.apache.org/docs/nightly/api/#tables,即可获取Java API的详细介绍,如图2-29所示。
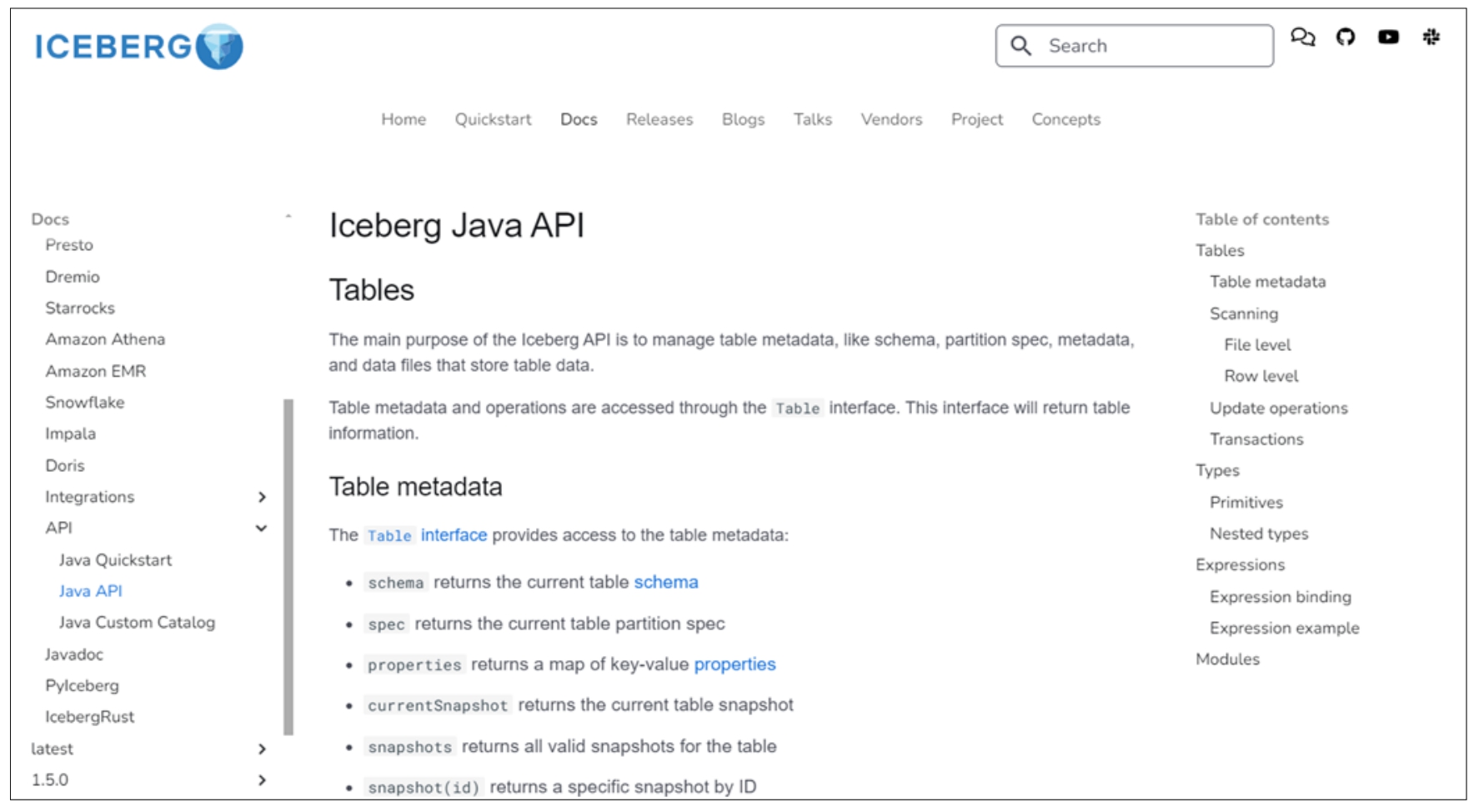
图2-29
从图中可以看到,通过Java API可以获取到Iceberg数据表的schema、spec、属性、当前快照、快照等众多元数据信息。在实际使用Java API做开发时,可以通过如下Maven的方式来引入其Java API的JAR包。
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-api</artifactId>
</dependency>