
下载掌阅APP,畅读海量书库
立即打开



基于卷积神经网络的图像分类算法的起源非常早,最早可追溯到日本学者福岛邦彦在1980年提出的Neocognitron(神经认知机)神经网络模型 [55] 。该模型借鉴了生物的视觉神经系统。但该模型提出之后,在国际上一直不温不火,一直到2012年AlexNet在ImageNet大规模视觉识别比赛(ImageNet Large Scale Visual Recognition Competition,ILSVRC)中大获全胜之后,卷积神经网络的潜力才被广泛认识到,并真正成为业界关注的焦点。

图3.12 conv6和conv9层的神经网络可视化效果 [54]
表3.1 文献[54]中的一种卷积神经网络结构
ImageNet大规模视觉识别比赛是图像分类领域最有影响力的学术竞赛之一。该比赛评测图像分类算法在ImageNet-1k
[56]
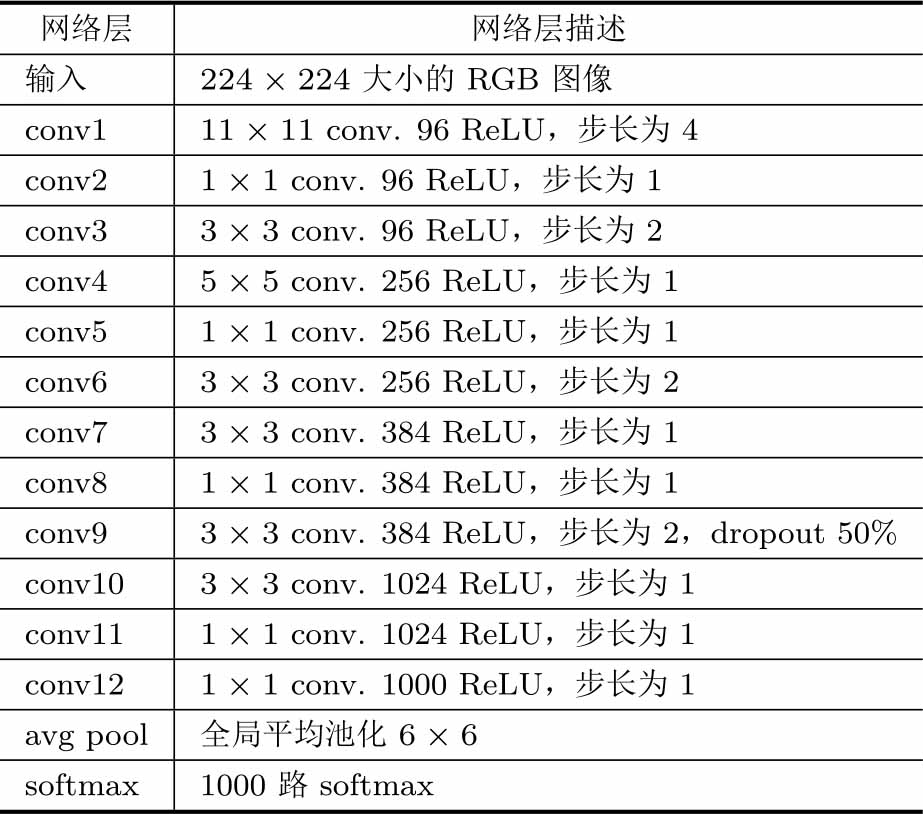
数据集上的Top-1和Top-5分类准确率。ImageNet-1k数据集包含约128万训练数据,分为1000个类。参赛模型需要判断测试集中的图片到底是1000种物体中的哪一种。图3.13是从2010年到2017年期间ImageNet分类的Top-5错误率(Top-5 error)
 。2010年和2011年ILSVRC冠军主要采用传统视觉算法,Top-5错误率分别是28.2%和25.8%。2012年提出的AlexNet
[16]
是一个8层的卷积神经网络,将Top-5错误率从25.8%降到了16.4%。在此之后,深度学习的发展非常迅速,网络深度也在不断地快速增长,从8层的AlexNet
[16]
到19层的VGG
[40]
,再到22层的GoogLeNet
[41]
,以及152层的ResNet
[42]
,甚至252层的SENet
[57]
。对于ImageNet上1000种物体的分类,ResNet的Top-5错误率仅为3.57%,这是非常振奋人心的进展。
。2010年和2011年ILSVRC冠军主要采用传统视觉算法,Top-5错误率分别是28.2%和25.8%。2012年提出的AlexNet
[16]
是一个8层的卷积神经网络,将Top-5错误率从25.8%降到了16.4%。在此之后,深度学习的发展非常迅速,网络深度也在不断地快速增长,从8层的AlexNet
[16]
到19层的VGG
[40]
,再到22层的GoogLeNet
[41]
,以及152层的ResNet
[42]
,甚至252层的SENet
[57]
。对于ImageNet上1000种物体的分类,ResNet的Top-5错误率仅为3.57%,这是非常振奋人心的进展。
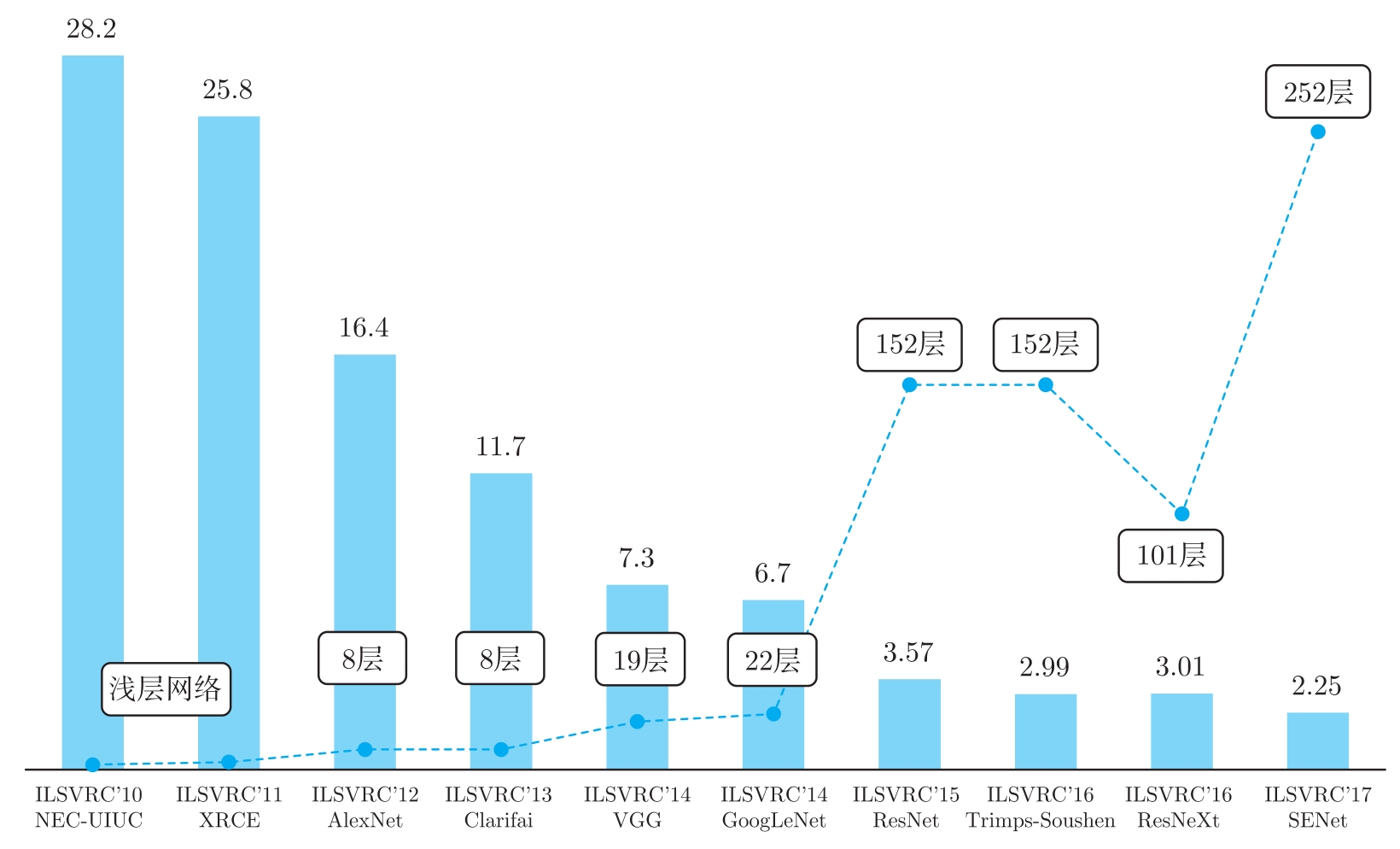
图3.13 ImageNet图像分类大赛中历年的Top-5错误率
上述算法中,性能改进跨度最大的是AlexNet,将ImageNet分类的Top-5错误率从25.8%降到16.4%;其次改进跨度比较大的是ResNet,将Top-5错误率从6.7%降到3.57%,因为越到后面降低错误率越困难。换个角度看,Top-5错误率从6.7%降到3.57%,意味着出错的图片的数量降低了接近一半,这是非常困难的。
下面我们将分别介绍几个在卷积神经网络历史上有里程碑意义的算法,包括AlexNet、VGG、Inception(GoogLeNet是Inception系列中的一员)以及ResNet。
AlexNet是深度学习领域最重要的成果之一,也是G.Hinton的代表作之一。文献[16]中给出的AlexNet网络结构如图3.14所示。
AlexNet的输入是224×224大小的RGB图像。第一层卷积,用48个11×11×3的卷积核计算出48个55×55大小的特征图,用另外48个11×11×3的卷积核计算出另外48个55×55大小的特征图,这两个分支的卷积步长都是4,通过卷积把图像的大小从224×224减小为55×55。第一层卷积之后,做局部响应归一化(Local Response Normalization,LRN)和步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为27×27。第二层卷积,用两组各128个5×5×48的卷积核对两组输入的特征图分别进行卷积处理,输出两组各128个27×27的特征图。第二层卷积之后,做局部响应归一化和步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为13×13。第三层卷积,将两组特征图合为一组,采用192个3×3×256的卷积核对所有输入特征图做卷积运算,再用另外192个3×3×256的卷积核对所有输入特征图做卷积运算,输出两组各192个13×13的特征图。第四层卷积,对两组输入特征图分别用192个3×3×192的卷积核做卷积运算。第五层卷积,对两组输入特征图分别用128个3×3×192的卷积核做卷积运算。第五层卷积之后,做步长为2、池化窗口为3×3的最大池化,池化输出的特征图大小为6×6。第六层和第七层的全连接层都有两组神经元(每组2048个神经元),第八层的全连接层输出1000种特征并送到softmax中,softmax输出分类的概率。
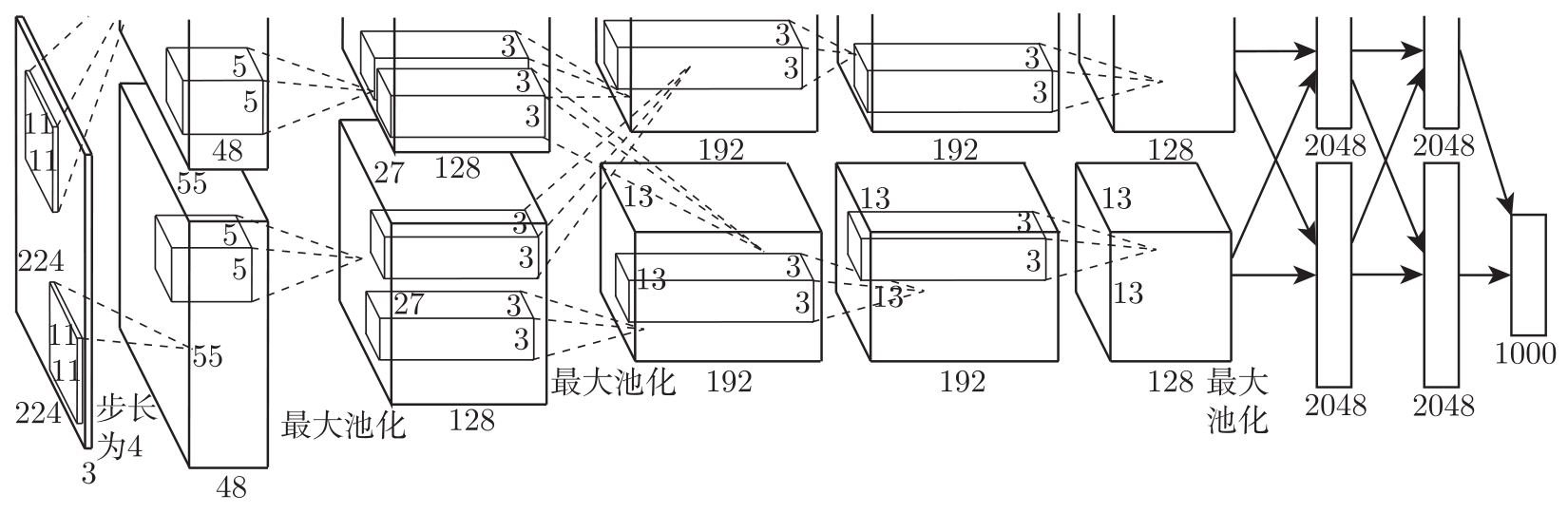
图3.14 AlexNet的网络结构 [16]
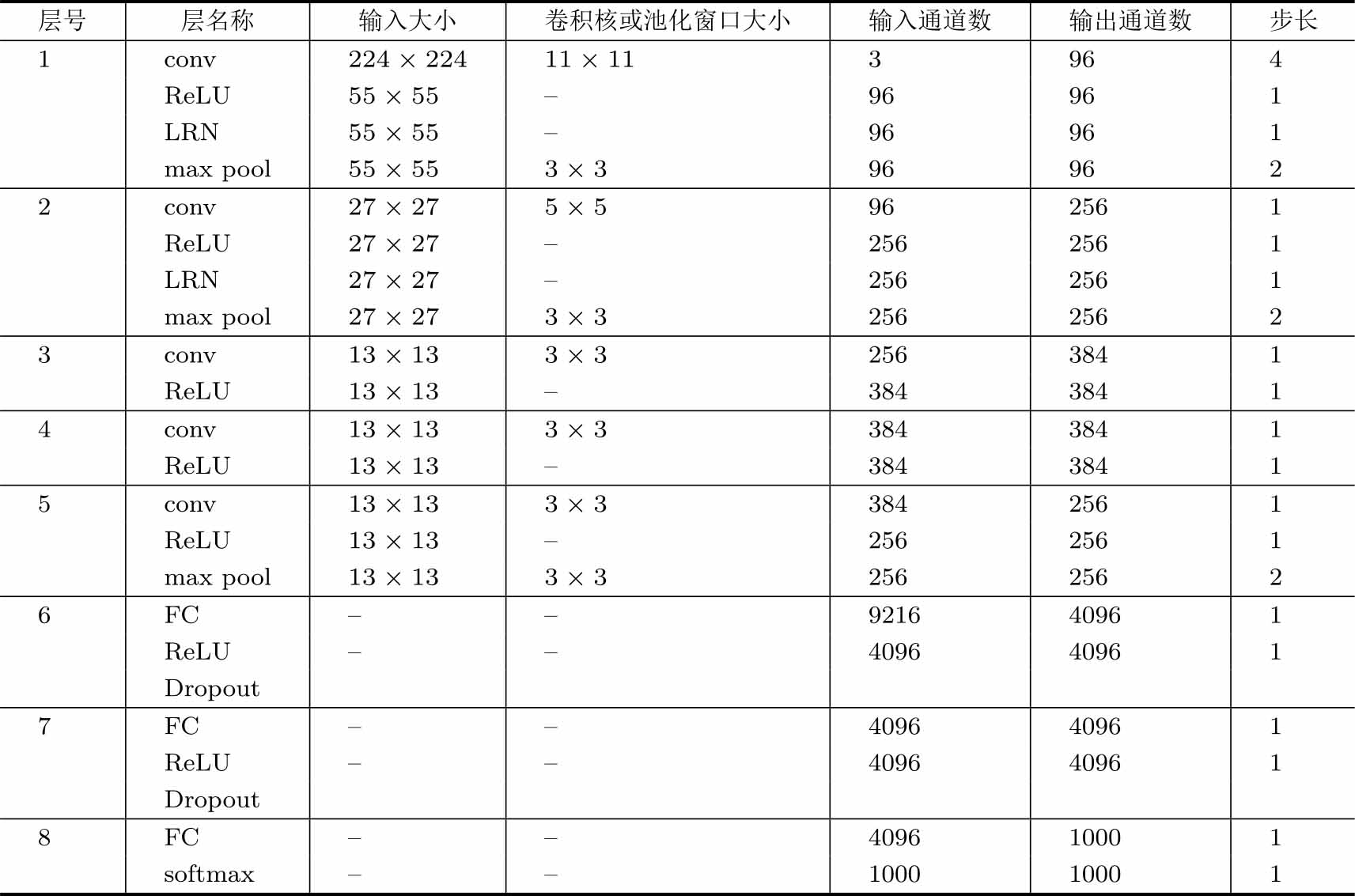
AlexNet的网络配置如表3.2所示。
相对于传统人工神经网络,AlexNet主要有四个技术上的创新:
(1)Dropout(随机失活)。在训练的过程中随机舍弃部分隐层节点,可以避免过拟合。
(2)LRN(局部响应归一化)。LRN可以提升较大响应,抑制较小响应。当然最近几年业界发现LRN层作用不大,所以现在使用LRN的研究者很少。
(3)max pooling(最大池化)。最大池化可以避免特征被平均池化模糊,提高特征的鲁棒性。在AlexNet之前,很多研究用平均池化。从AlexNet开始,业界公认最大池化的效果比较好。
(4)ReLU激活函数。在AlexNet之前,常用的激活函数是sigmoid和tanh。而ReLU函数很简单,输入小于0时输出0,输入大于0时输出等于输入。以前业界认为ReLU函数太简单了,但事实上非常简单的ReLU函数带来了非常好的效果。AlexNet在卷积层和全连接层的输出均使用ReLU激活函数,能有效提高训练时的收敛速度。
AlexNet把这些看上去并不惊人的技术组合起来,取得显著效果,它推动深度学习成为业界主流,具有里程碑意义。之前我们已经介绍过最大池化和ReLU,故不再赘述。下面我们主要介绍一下LRN和Dropout。
表3.2 AlexNet的网络配置
1.LRN
LRN对同一层的多个输入特征图在每个位置上做局部归一化,以提升高响应特征和抑制低响应特征。LRN的输入是卷积层的输出特征图经过ReLU激活函数后的输出。假设LRN的输入是 C 个特征图,LRN要对输入的 c 个相邻特征图上相同位置的点进行归一化处理,得到第 m 个输出特征图上位置( i , j )处的值 [16]
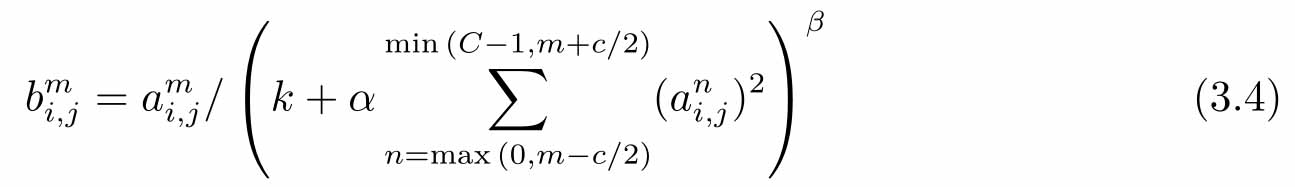
其中,
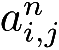 是第
n
个输入特征图上位置(
i
,
j
)处的点。常数
k
、
c
、
α
、
β
的值是人工设定的,在文献[16]中
k
=2、
c
=5、
α
=10
-4
、
β
=0.75。
是第
n
个输入特征图上位置(
i
,
j
)处的点。常数
k
、
c
、
α
、
β
的值是人工设定的,在文献[16]中
k
=2、
c
=5、
α
=10
-4
、
β
=0.75。
举例来讲,LRN的输入是 C 个不同的特征图,包含三角形特征、点特征、线特征、长方形特征、正方形特征等。在同一个位置上,如果既有长方形特征,又有正方形特征、三角形特征,还有菱形特征,就要对该位置上的点进行归一化,以将该位置上最显著的特征找出来。但实际上,一个位置上的点可能既参与到三角形中,又参与到正方形和长方形中,还参与到菱形中,强行抑制一个点参与的低响应特征并不一定合理。因此,LRN在实际中并没有产生明显效果,现在已很少有人使用。
2.Dropout
Dropout是G.Hinton等人 [52] 在2012年提出来的。该方法通过随机舍弃部分隐层节点缓解过拟合,目前已经成为深度学习训练常用的技巧之一。
使用Dropout进行模型训练的过程为:
(1)以一定概率(如0.5)随机地舍弃部分隐层神经元,即将这些神经元的输出置为0。
(2)一小批训练样本经过正向传播后,在反向传播更新权重时,不更新与被舍弃神经元相连的权重。
(3)恢复被删除神经元,输入另一小批训练样本。
(4)重复步骤(1)~(3),直到处理完所有训练样本。
在Dropout训练过程中,并不是真的丢掉部分隐层神经元,只是暂时不更新与其相连的权重。对于这一批样本,可能不用某些隐层神经元,但对于下一批样本,可能又会用到这些隐层神经元,并且需要更新与其相连的权重。训练完成后使用神经网络进行预测时,所有神经元都是要用到的。AlexNet网络的前两个全连接层使用了Dropout。
Dropout可以防止训练数据中复杂的共同适应(co-adaptation),即一个特征检测器需要依赖其他几个特定特征检测器,从而缓解过拟合。
3.小结
AlexNet最大的贡献在于证明了深层的神经网络在代表性问题上的表现可以远远超越其他机器学习方法。AlexNet的成功主要得益于:
(1)使用多个卷积层。过去都是浅层的神经网络,AlexNet真正把深度学习应用到了ImageNet图像分类这种比较复杂的问题上。通过使用多个卷积层,有效地提取了图像的特征,显著地提升了图像识别的准确率。
(2)使用ReLU,提高了训练速度。
(3)使用Dropout、数据增强(data augmentation),缓解过拟合。
8层的AlexNet显著提高了图像识别准确率,更多层的神经网络是否能进一步提升识别准确率?2014年K.Simonyan和A.Zisserman [40] 提出了比AlexNet更深的神经网络VGG,进一步提升了分类准确率。VGG有很多不同的版本,VGG16是最经典的版本之一。
1.网络结构
神经网络层数增多之后会遇到很多问题,包括梯度爆炸、梯度消失等。距离输出层(计算损失函数)很近的一两层,可能很快就可以训练好;但是距离输出层10层、100层时,损失函数的导数可能会非常小,神经网络可能就无法继续训练了。因此,如表3.3所示,K.Simonyan和A.Zisserman设计了一系列不同配置的VGG网络结构 [40] ,在此基础上提出了预训练策略,利用较浅神经网络训练出来的权重参数来初始化更深神经网络的部分层,从而达到逐步加深神经网络层数的效果。
表3.3 VGG的网络结构 [40]
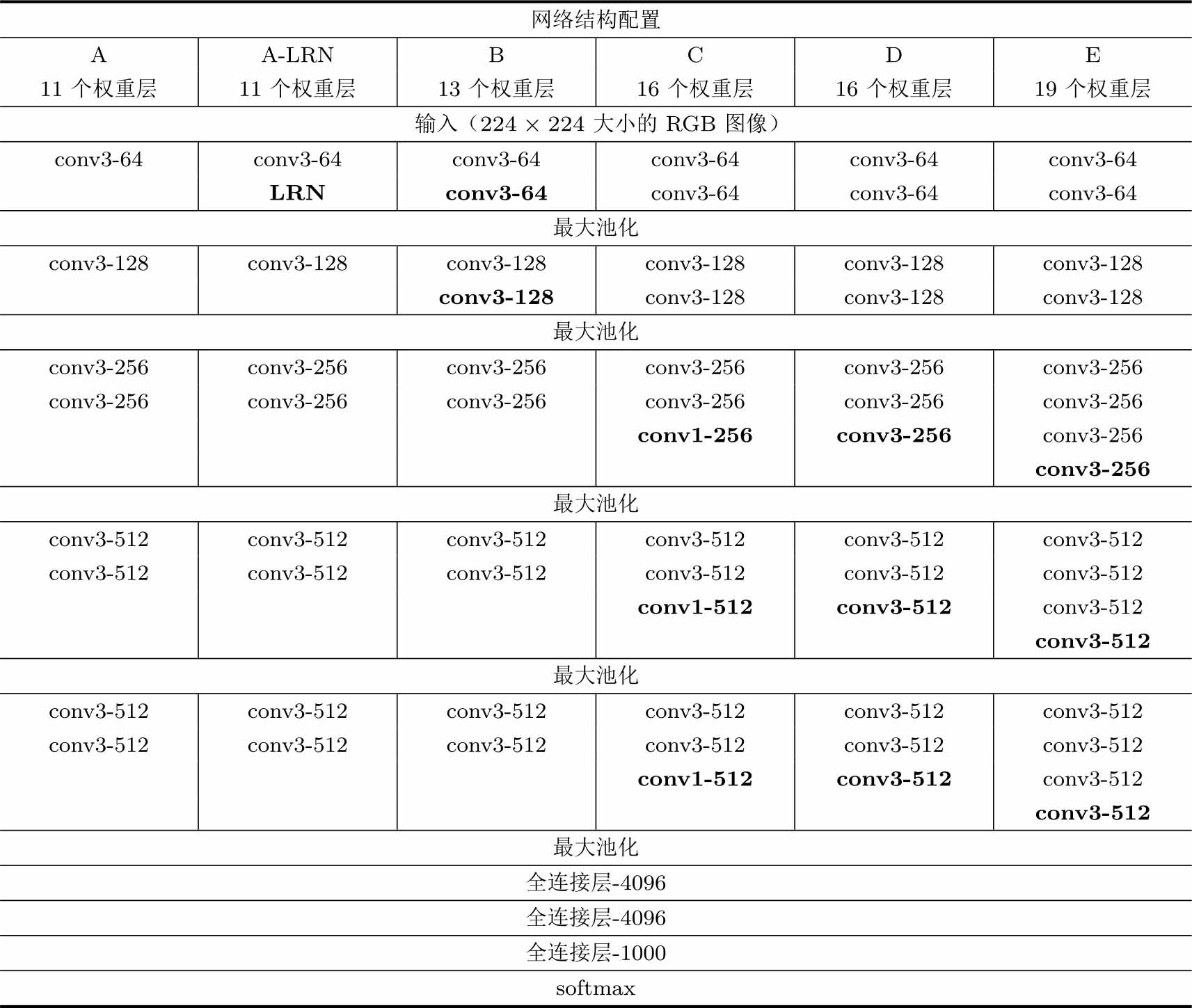
具体来说,VGG首先训练一个配置为A的11层的神经网络,每一个卷积层都是3×3卷积,即卷积核是3×3大小。训练更深的神经网络(如配置为B的13层的神经网络)时,先将B网络的前4个卷积层和后3个全连接层的参数用训练好的A网络的前4个卷积层和后3个全连接层的权重参数进行初始化,B网络其他中间层的参数采用随机初始化;然后对B神经网络进行训练。
配置为A的11层的神经网络(简记为VGG-A),其输入是224×224大小的RGB图像;经过第1层卷积输出64个特征图,再做最大池化;随后做第2层卷积,输出128个特征图,再做最大池化;接着连续做两层卷积,输出均为256个特征图,再做最大池化;然后连续做两层卷积,输出均为512个特征图,再做最大池化;继续做两层卷积,输出均为512个特征图,再做最大池化;然后经过三个全连接层,分别输出4096、4096、1000个特征;通过softmax得到最终输出。在VGG-A的第一层卷积之后增加一个LRN层,就得到了配置为A-LRN的神经网络(VGG-A-LRN)。文献[40]给出的实验表明,LRN不会提升神经网络模型的分类准确率,因此其余的VGG结构中都没有使用LRN层。
神经网络结构从配置A到配置B的变化是,在第1个卷积层和第2个卷积层之后各增加了一个卷积层。在13层的神经网络VGG-B中,在第6、8、10层卷积之后各增加1个卷积层,并通过使用不同大小的卷积核得到两个版本的VGG网络。如果新增的卷积层的卷积核都是1×1大小,就得到了16层的神经网络VGG-C;如果新增的卷积层的卷积核都是3×3大小,就得到了16层的神经网络VGG-D,也就是现在常用的图3.2中的VGG16。在16层的VGG-D的第7、10、13层卷积之后各增加1个卷积层,得到19层的神经网络VGG-E,也就是现在常用的VGG19。不同配置的VGG网络中,所有隐层都使用了非线性激活函数ReLU。
VGG通过逐渐增加层数,训练出了多个不同版本的神经网络。首先增加LRN层,发现LRN层没用。然后发现,随着层数的增多,Top-5错误率基本上是在下降的。但是到了16层的VGG-D和19层的VGG-E,Top-5错误率基本都在8%左右,不再有大的变化。
2.卷积-池化结构
VGG中图像尺寸基本上是通过卷积和池化来调整的。由于VGG的层数很多,为了避免边缘特征被弱化掉,VGG在卷积层做边界扩充以使输出图像和输入图像的尺寸相同。池化窗口为2×2,池化步长为2,因此池化后图像的长和宽均减半。输入为224×224大小的RGB图像,经过第1次池化输出64个112×112的特征图,经过第2次池化输出128个56×56的特征图,经过第3次池化输出256个28×28的特征图,经过第4次池化输出512个14×14的特征图,经过第5次池化输出512个7×7的特征图。
VGG中除了配置C中有3个卷积层使用了1×1的卷积核,其余均使用3×3的卷积核,卷积步长均为1。而AlexNet使用了3种卷积核,包括11×11、5×5和3×3,而且越靠前的层使用的卷积核的尺寸越大。直观上,大卷积核的视野范围(感受野)更大,效果似乎应该更好,而事实恰恰相反。这背后的原因在于,VGG会使用连续的多层卷积,每个卷积核都是3×3的。因此,一个AlexNet中常用的5×5的卷积可以看成是2层连续的3×3的卷积,二者在输入图像上的感受野是一样的,如图3.15所示。以此类推,7×7的卷积与3层连续的3×3的卷积的感受野相同,11×11的卷积与5层连续的3×3的卷积的感受野相同。而11×11的卷积,有121个参数,5层连续的3×3的卷积只有45个参数。因此,VGG通过使用连续的小卷积核,用更少的参数,就能完成AlexNet中大卷积核的任务,训练起来难度也会更小。
此外,VGG在每一层卷积中加入非线性激活函数ReLU,因此多层卷积可以增强决策函数的区分能力,从而提高分类准确率。比如,将配置为B的13层神经网络VGG-B中连续2个3×3卷积层替换为1个5×5卷积层,其Top-1错误率比VGG-B高7% [40] ,见图3.15。
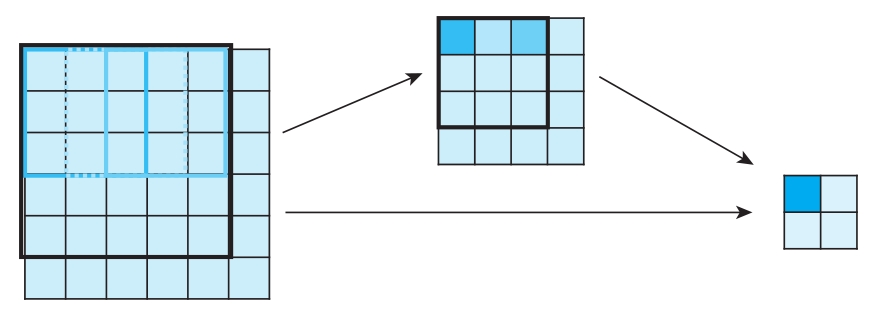
图3.15 一个5×5卷积层和连续2个3×3卷积层的感受野大小相同
3.小结
VGG的成功主要得益于以下几点:
(1)使用规则的多层小卷积替代大卷积。在相同视野下,有效减少了权重参数的数量,提高了训练速度。
(2)使用更深的卷积神经网络。在神经网络中使用更多的卷积层及非线性激活函数,提高了图像分类的准确率。
(3)通过预训练,对部分网络层参数进行初始化,提高了训练收敛速度。
在VGG之后,Inception进一步考虑了能否用更小的卷积核、更多的神经网络层来降低错误率。在Inception系列工作中,最著名的是Inception-v1,即GoogLeNet,它获得了2014年ImageNet比赛的冠军。在GoogLeNet之后,又出现了BN-Inception、Inception-v3、Inception-v4等(见表3.4)。下面将分别介绍它们的具体特点。
1.Inception-v1
AlexNet和VGG的网络结构都比较规整。而Inception-v1(GoogLeNet) [41] 中有很多结构复杂的模块,即Inception模块。这也是GoogLeNet最核心的创新。
表3.4 Inception系列卷积神经网络

Inception模块 。图3.16a是Inception模块的初级版本。该模块对上一层的输出分别做四种处理(即四个分支),包括1×1卷积、3×3卷积、5×5卷积、3×3最大池化。而之前的神经网络,对输入都是用一组相同尺寸的卷积核(比如,3×3或5×5)来提取特征。相对于以往工作,Inception模块中不同尺寸的卷积以及池化可以同时提取到输入图像中小范围的特征以及大范围的特征,因此Inception中的每一层都能够适应不同尺度的图像的特性。在此基础上,Inception模块通过加入1×1卷积,可以做降维(dimensionality reduction),如图3.16b所示。1×1卷积,对多个特征图中同一位置的点进行卷积处理,相当于做全连接处理,其好处是可以对同一位置上的不同特征进行归一化。虽然已经证明LRN用非常复杂的归一化处理是失败的,但对于Inception模块中这种简洁的1×1卷积有比较好的效果。
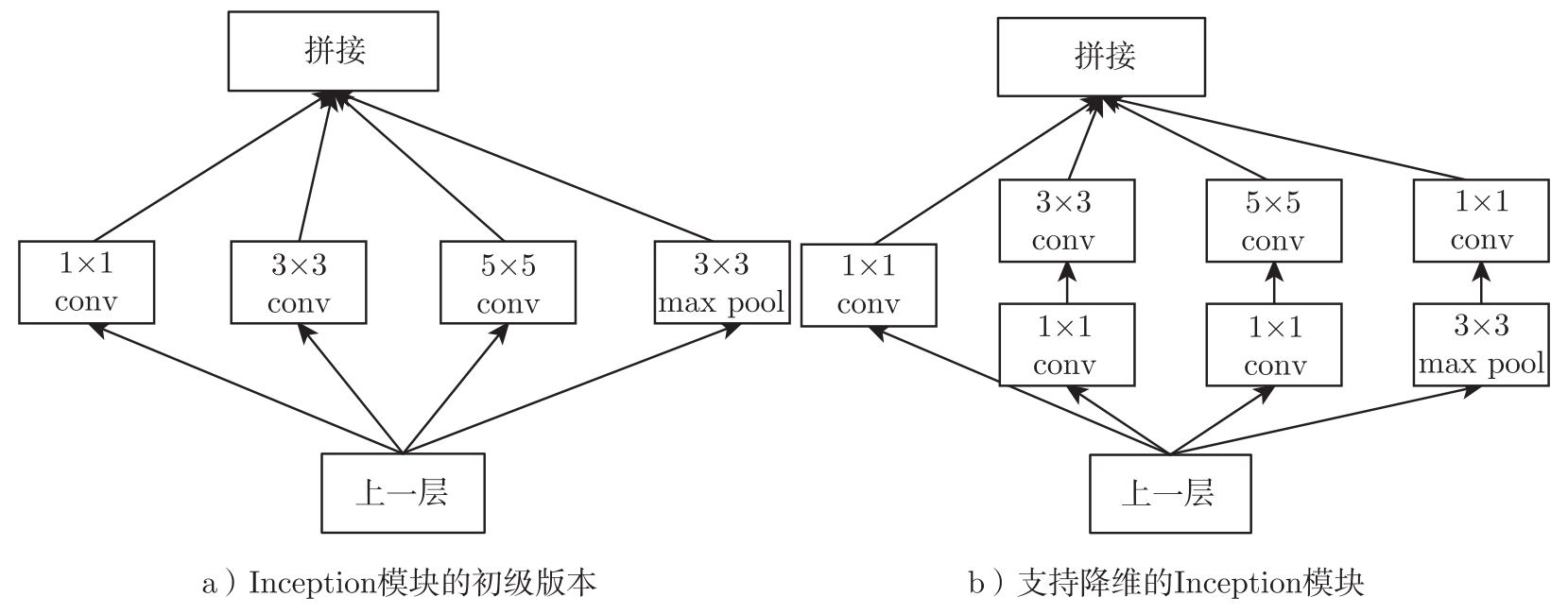
图3.16 Inception模块 [41]
1×1 卷积 。1×1卷积实际上是跨通道的聚合,将多个输入特征图上相同位置的点做全连接处理,计算出输出特征图上对应位置的一个点,因此相当于是输入和输出之间的全连接。同时,每个1×1卷积层都使用ReLU激活函数来提取非线性特征。
如果1×1卷积层的输出特征图的数量比输入特征图少,就可以实现降维,减少神经网络的参数,同时也能减少计算量。以图3.17为例,卷积层的输入是256个28×28大小的特征图,输出是96个28×28大小的特征图,左图是只有一个卷积层且卷积核为5×5的情况,右图是额外加入一层1×1卷积的情况,且1×1卷积层输出32个28×28大小的特征图。
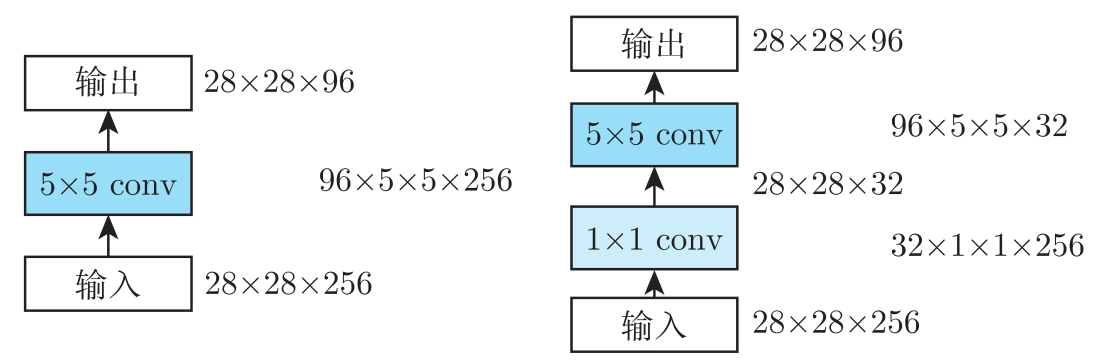
图3.17 1×1卷积参数对比。每个子图中左列数据为特征数量,右列数据为卷积参数数量
只有一个5×5卷积层时,网络参数的数量为96×5×5×256=614 400,乘加运算的数量为28×28×96×5×5×256=481 689 600。
增加1×1卷积层后,网络参数的数量为32×256+96×5×5×32=84992,乘加运算的数量为28×28×32×256+28×28×96×5×5×32=66633728。
增加1×1卷积层后,5×5卷积层的输入维度从256降为32,参数数量减少为原来的1/7.2,计算量也减少为原来的1/7.2。因此,1×1卷积已广泛应用于多种神经网络架构中,包括ResNet。
GoogLeNet网络结构 。GoogLeNet的网络结构如图3.18所示,它由多个Inception模块叠加在一起,看起来非常复杂。GoogLeNet共有22层(仅统计有参数的层,如果算上池化层共27层)。该神经网络的输入是224×224大小的RGB图像;第1层卷积,卷积核为7×7,步长为2,输出64个112×112大小的特征图,再经过步长为2、窗口为3×3的最大池化层,随后做LRN;随后通过一个1×1卷积层输出64个特征图,再通过一个3×3卷积层输出192个特征图,再做LRN和步长为2、窗口为3×3的最大池化;然后是连续9个Inception模块,中间插入两个最大池化层;最后经过1个平均池化层、全连接层,再通过softmax层得到最终输出。GoogLeNet中所有卷积层都使用ReLU激活函数。
GoogLeNet的网络层数比VGG深得多,而且所有网络层一起训练,很容易出现梯度消失现象。为了解决这个问题,GoogLeNet从神经网络中间层旁路出来2个softmax辅助分类网络,以在训练中观察网络的内部情况。每个softmax辅助分类网络,包含一个降低特征图尺寸的平均池化层(池化窗口为5×5,步长为3),一个将输入特征图降维到128的1×1卷积层,一个有1024个输出的全连接层,一个以70%概率Dropout的全连接层,以及一个softmax层
。该辅助分类网络对中间第
l
层的输出进行处理得到分类结果,再将该分类结果按较小的权重(0.3)加到最终的分类层里。利用该辅助分类网络,可以在训练过程中观察到第
l
层的训练结果,如果训练效果不好,可以提前从第
l
层做反向传播,调整权重。这种方式有助于训练一个很多层的神经网络,防止梯度消失。而传统的训练方式从神经网络的最终输出进行反向传播,如果中间某个地方出错了,也得从最终输出反向传播过来,采用梯度下降法寻找最小误差,在该过程中梯度很可能就会消失或爆炸。值得注意的是,softmax辅助分类网络仅用于训练阶段,不用于推理阶段。
相对于VGG,GoogLeNet网络层数更深、参数更少、分类准确率更高,这主要得益于三个方面:一是增加了softmax辅助分类网络(也称为观察网络),可以观察训练的中间结果,提前反向传播;二是增加了很多1×1卷积,可以降低特征图维度,减少参数数量以及计算量;三是引入了非常灵活的Inception模块,能让每一层网络适应不同尺度的图像的特性。
2.BN-Inception
在GoogLeNet基础上,BN-Inception [58] 在训练中引入了批归一化(Batch Normal-ization,BN),取得了非常好的效果。具体来说,BN-Inception在训练时同时考虑一批样本。它在每个卷积层之后、激活函数之前插入一种特殊的跨样本的BN层,用多个样本做归一化,将输入归一化到加了参数的标准正态分布上。这样可以有效避免梯度爆炸或消失,训练出很深的神经网络。
以下是BN背后的原理。随着神经网络层数的增多,在训练过程中,各层的参数都在变化,因此每一层的输入的分布都在变化,其分布会逐渐偏移,即内部协方差偏移(internal covariate shift)。输入分布通常会向非线性激活函数的两端偏移,靠近饱和区域,因此会导致反向传播时梯度消失。此外,为了不断适应新的分布,训练时需要较低的学习率和合适的初始化参数,因此训练速度很慢。在批训练时,如果对多个样本做归一化,把激活函数的输入归一化到标准正态分布(均值为0,方差为1),激活函数的取值就会靠近中间区域,输入很小的变化就能显著地体现到损失函数中,就不容易出现梯度消失。
如果激活函数的输入都简单归一化为标准正态分布,可能会将激活函数的输入限定到线性区域,此时激活函数不能提供非线性特征,神经网络的表达能力会下降。因此,BN需要对归一化后的值进行缩放和偏移。缩放因子 γ 和偏移变量 β 是和模型参数一起训练得到的,相当于对标准正态分布做一个水平偏移并变宽或变窄,等价于将非线性函数的值从中间的线性区域向非线性区域偏移,从而可以保持网络的表达能力。
BN变换的具体计算过程如下。假设某一网络层的输入为 x i , i =1,…, M ,其中 M 为训练集的大小, x i =[ x i 1 ; x i 2 ;…; x id ]为 d 维向量。理论上,首先用所有训练数据对 x i 的每一维度 k 做归一化

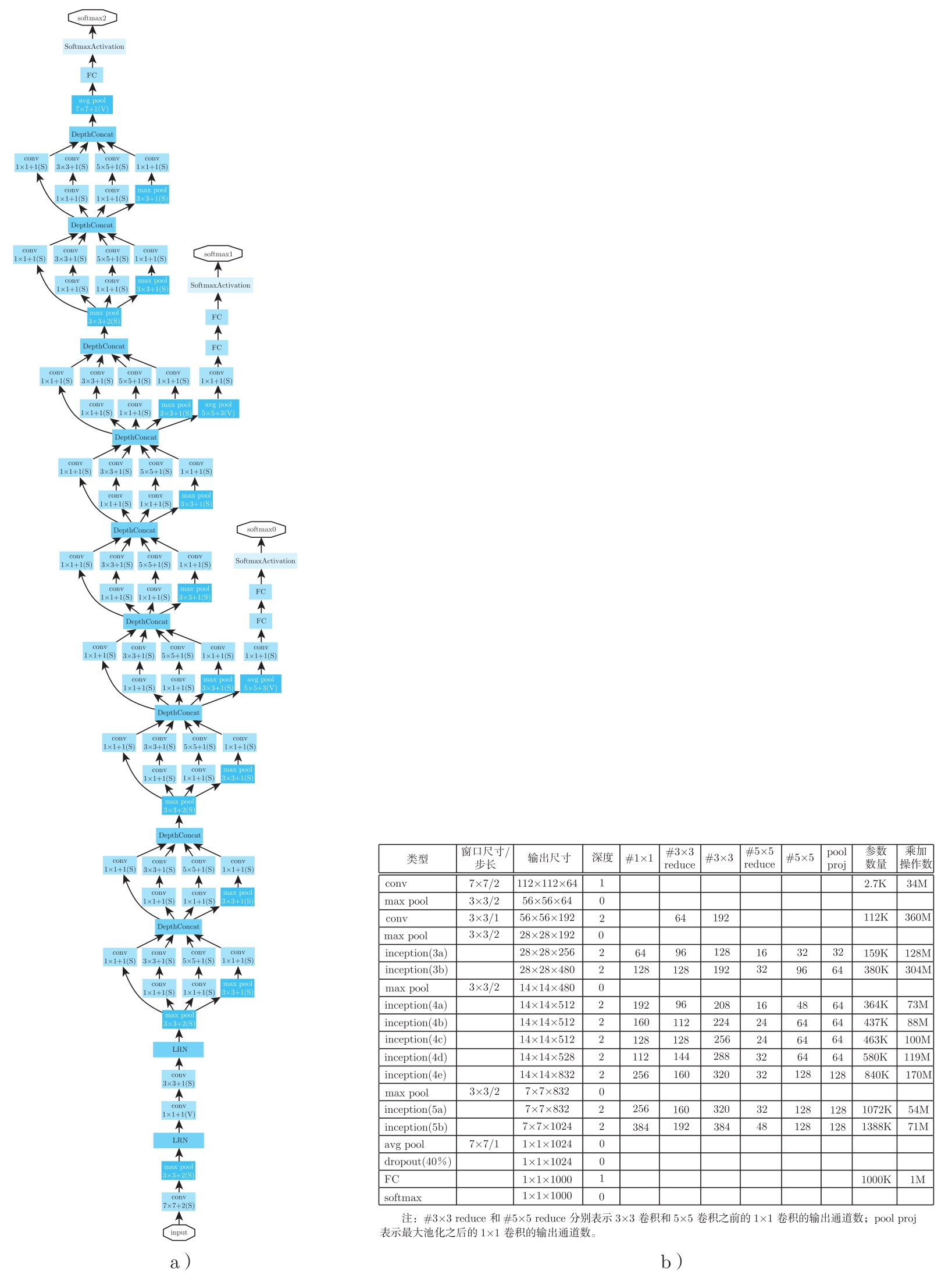
图3.18 GoogLeNet网络结构(左图)及配置(右图) [41]
然后,对归一化后的值做缩放和偏移,得到BN变换后的数据

其中, γ k 和 β k 为每一个维度的缩放和偏移参数。在整个训练集上做上述BN变换是难以实现的;此外随机梯度训练时通常使用小批量数据进行训练。因此实际中,使用随机梯度训练中的小批量数据来估计均值和方差,做BN变换。
BN-Inception借鉴VGG的思想,在Inception模块中用两个3×3的卷积核去替代一个5×5的卷积核,如图3.19所示。
BN很多时候比LRN、Dropout或 L 2 正则化的效果好,而且可以大幅提高神经网络的训练速度。在Inception训练中加上BN,可以把学习率调得非常大,从而加速训练。把学习率调大5倍,BN训练速度比原始Inception快14倍 [58] ,更惊人的是,准确率还可以略有提升(0.8%),可谓是“多快好省”。现在,BN已经不仅用于Inception系列网络,而是已经成为各种当代深度学习神经网络必备的训练技术之一。
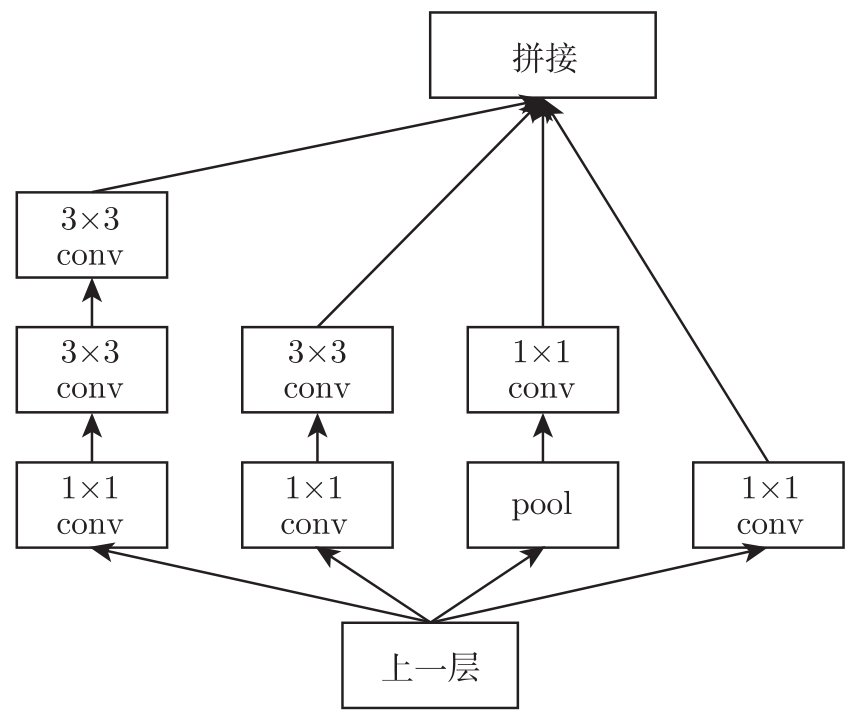
图3.19 BN-Inception模块结构
3.Inception-v3
Inception-v1(GoogLeNet)将部分7×7卷积和5×5卷积拆分为多个连续的3×3卷积。延续这个思想,Inception-v3 [59] 将卷积核进一步变小,将对称的 n × n 卷积拆分为两个非对称的卷积,1× n 卷积和 n ×1卷积。例如,将3×3卷积拆分为1×3卷积和3×1卷积,从而把参数的数量从9个减为6个。这种非对称的拆分方式,可以增加特征的多样性。因此,形成了图3.20中的3种新的Inception模块结构。
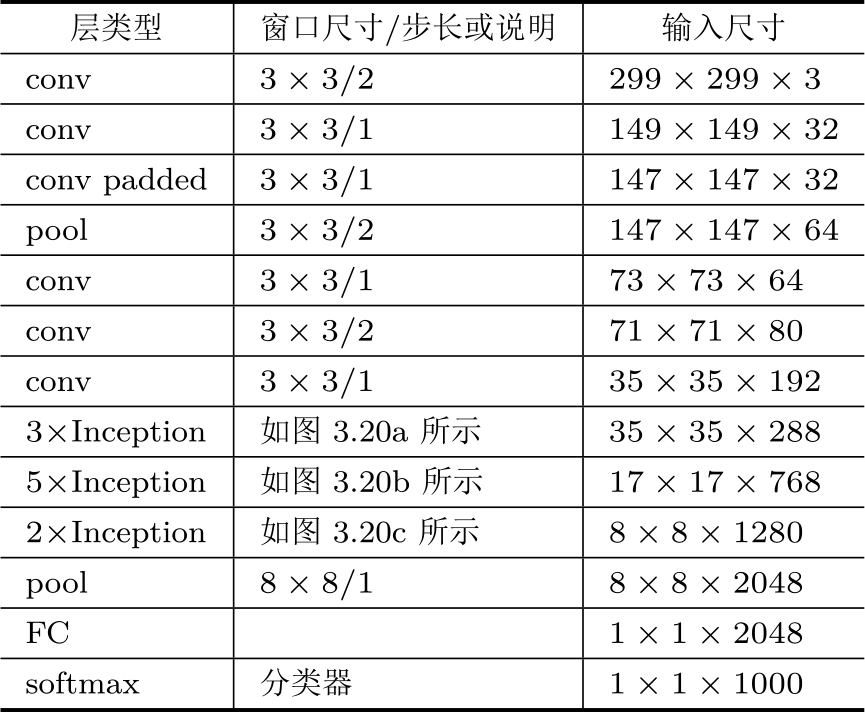
将图3.20中的3种Inception模块组合起来,把GoogLeNet中第一层7×7卷积拆分为3层3×3卷积,对所有卷积层和辅助分类网络的全连接层做BN,就形成了Inception-v3的网络结构,如表3.5所示。该网络进一步提高了分类的准确率。
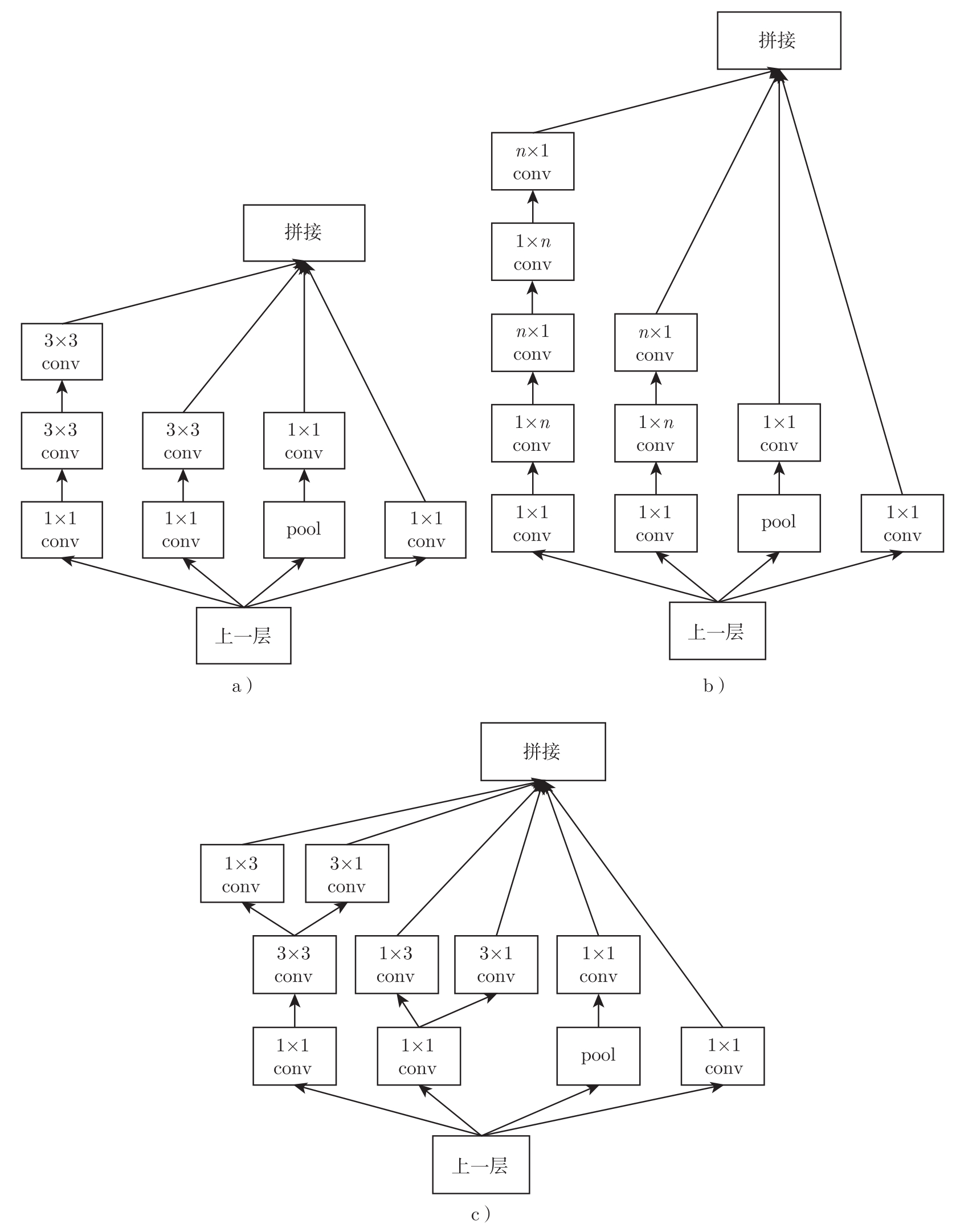
图3.20 Inception-v3中的3种模块结构 [59]
表3.5 Inception-v3网络结构 [59]
Inception系列的主要创新包括:
(1)使用BN,减少梯度消失或爆炸,加速深度神经网络训练。
(2)进一步减小卷积核的大小,减少卷积核的参数数量。从AlexNet的11×11卷积,到VGG的3×3卷积,到Inception-v3的1×3卷积和3×1卷积。
(3)加入辅助分类网络,可以提前反向传播调整参数,减少梯度消失,解决了多层神经网络训练的问题。
沿着AlexNet、VGG和GoogLeNet的脉络发展下来,我们可以看到一个明显的趋势,就是研究者不断尝试各种技术,以加深神经网络的层数。从8层的AlexNet,到19层的VGG,再到22层的GoogLeNet,可以说,技术一直在进步。但是在突破神经网络深度问题上真正最具颠覆性的技术还是来自ResNet(Residual Network,残差网络)。它不仅在2015年的ImageNet比赛中分类准确率远高于其他算法,更重要的是,自ResNet提出之后,神经网络层数就基本没有上限了。今天,虽然已经有一些更新、更深、更准的神经网络出现,但是它们一般都继承了ResNet的思想。
ResNet要解决的问题很简单,继续堆叠卷积层能否形成更深、更准的神经网络?为了回答这个问题,ResNet的作者何恺明等人曾经分别用20层和56层的常规卷积神经网络在CIFAR-10数据集上进行训练和测试。如图3.21所示,实验结果表明56层的CNN的训练和测试误差都高于20层的CNN [42] 。
为什么随着层数增加,误差会变大?有人认为是因为梯度消失。但是,何恺明等人在上述实验中已经使用了BN,可以缓解梯度消失,至少梯度不会完全消失。因此,何恺明等人认为,深层神经网络准确率降低是因为层数增加导致的神经网络的退化 [42] 。也就是说,神经网络层数增加越多,训练时越容易收敛到一些局部最优的极值点上,而不是全局最优点,导致误差比较大。
为了避免神经网络退化,ResNet采用了一种不同于常规卷积神经网络的基础结构。常规的卷积神经网络,对输入做卷积运算得到输出,等同于用多项式拟合输出并使输出与图像识别的结果一致。但ResNet的基本单元如图3.22b所示,增加了从输入到输出的直连(shortcut connection),其卷积拟合的是输出与输入的差(即残差)。由于输入和输出都做了BN,都符合正态分布,因此输入和输出可以做减法,如图3.22b中 F ( x ):= H ( x ) -x 。而且从卷积和BN后得到的每层的输出响应的均方差来看,残差网络的响应小于常规网络 [42] 。残差网络的优点是对数据波动更灵敏,更容易求得最优解,因此能够改善深层网络的训练。
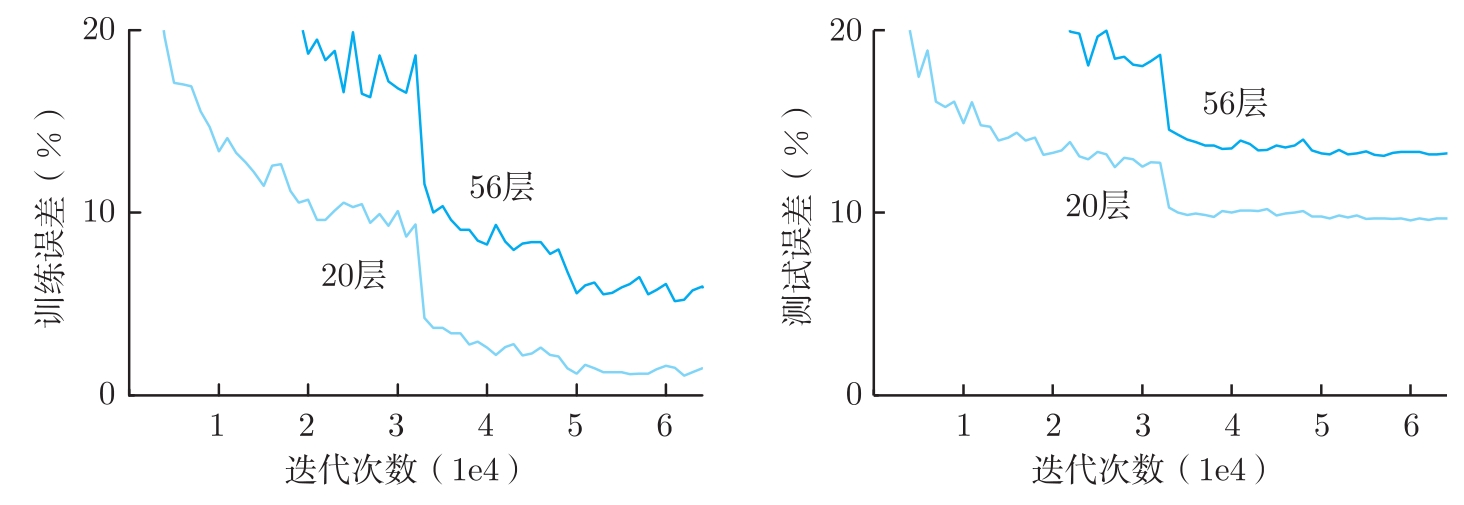
图3.21 20层和56层卷积神经网络在CIFAR-10数据集上的训练和测试准确率 [42]
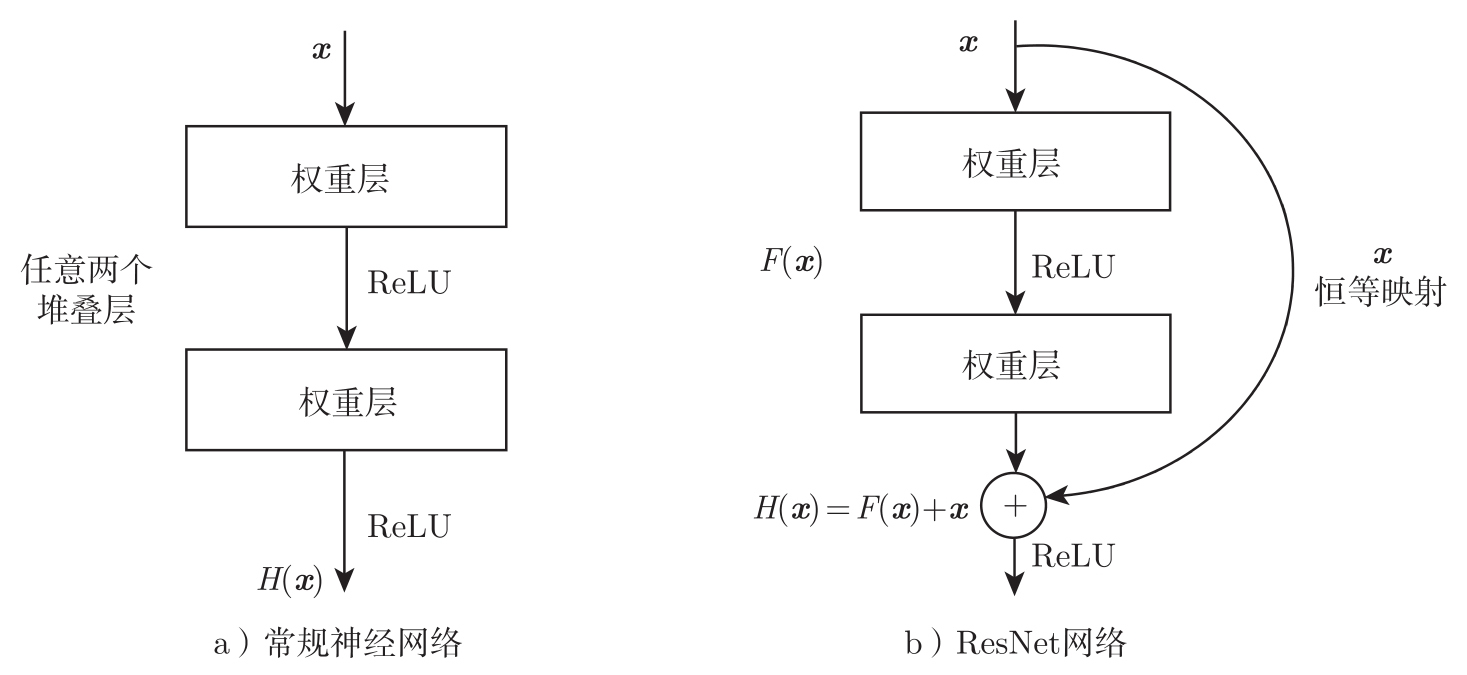
图3.22 网络结构对比
ResNet的基本单元(基本块)的处理过程为:输入 x 经过一个卷积层,再做ReLU,然后经过另一个卷积层得到 F ( x ),再加上 x 得到输出 H ( x )= x + F ( x ),然后做ReLU得到基本块的最终输出 y 。当输入 x 的维度与卷积输出 F ( x )的维度不同时,需要先对 x 做恒等变换使二者维度一致,然后再加和。
如图3.23所示,ResNet网络结构是基于VGG19的网络结构发展而来的。首先,把VGG中对应的3×3卷积层拆出来,变成对应的残差模块,这些残差模块由2个3×3卷积层组成。其次,特征图的缩小用步长为2的卷积层来完成。如果特征图的尺寸减半,则特征图的数量翻倍;如果特征图的尺寸不变,则特征图的数量也不变。再次,增加了跳转层。跳转层中有实线和虚线,实线表示特征图的尺寸和数量不变,虚线表示特征图的尺寸减半而数量翻倍。
当特征图数量翻倍时(虚线连接),对于输入到输出的直连有两种处理方式:一种是做恒定映射,增加的维度的特征填充0;另一种是用1×1卷积进行特征图数量翻倍,该方式会引入额外的卷积参数。这两种方式处理时的步长都为2,以满足特征图尺寸减半。
此外,每层卷积之后、激活函数之前做BN,一方面使得残差模块的输入和输出在同一值域,另一方面缓解梯度消失。
通过上述创新,ResNet在2015年ImageNet大赛中取得了最低的Top-5错误率(3.57%),远低于GoogLeNet的Top-5错误率(6.7%)。在ResNet之后,很多研究者通过提高神经网络层数进一步提高图像分类的准确率,但是这些工作都是建立在ResNet独特的残差网络基础之上。ResNet中提出的残差连接设计可以有效地加深神经网络的深度,不会使较深的神经网络出现难以优化的问题。因此,残差连接的设计也被广泛应用于之后的深度神经网络设计中。例如,3.3.3节介绍的Transformer的结构中也使用了残差连接。
应用于图像分类的卷积神经网络在计算机视觉领域具有非常大的影响力,因为这些网络可以作为对图像进行特征学习的骨干网络(backbone)被应用于多种图像处理任务中,如目标检测、图像语义分割、人体关键点检测、动作识别等。本节中介绍的AlexNet、VGG、Incep-tion系列和ResNet等代表性卷积神经网络都被广泛应用于多种图像处理任务中。在ResNet被提出后,研究人员在其基础上进一步设计了规模更大、层数更深、分类准确率更高的卷积神经网络。例如,DenseNet [61] 将残差连接设计改进为稠密连接,进一步提高分类准确率;ResNeXt [62] 通过结合ResNet和Inception的思想设计了分组卷积(group convolution),可以在与ResNet同等参数量的情况下取得更高的分类准确率;MobileNet系列 [63-65] 通过设计深度可分离卷积(depthwise separable convolution)实现卷积神经网络的轻量化设计;ShuffleNet系列 [66-67] 通过设计通道重排(channel shuffle)增强深度可分离卷积的通道间信息交互,提升轻量级卷积神经网络的性能;EfficientNet [68] 通过同时增加网络的深度、宽度(通道数)和输入网络的分辨率来提升卷积神经网络的性能。在Transformer被提出后,基于Transformer的神经网络(如ViT和Swin Transformer,详见3.3.5节)在图像分类领域也取得了令人瞩目的效果,甚至一度超过了卷积神经网络。之后,ConvNeXt [69] 从ResNet出发,借鉴Swin Transformer的设计思路,通过一系列宏观设计、模块调整、卷积核、微观设计等多种改进提升卷积神经网络的分类准确率,取得超越Swin Transformer的结果。
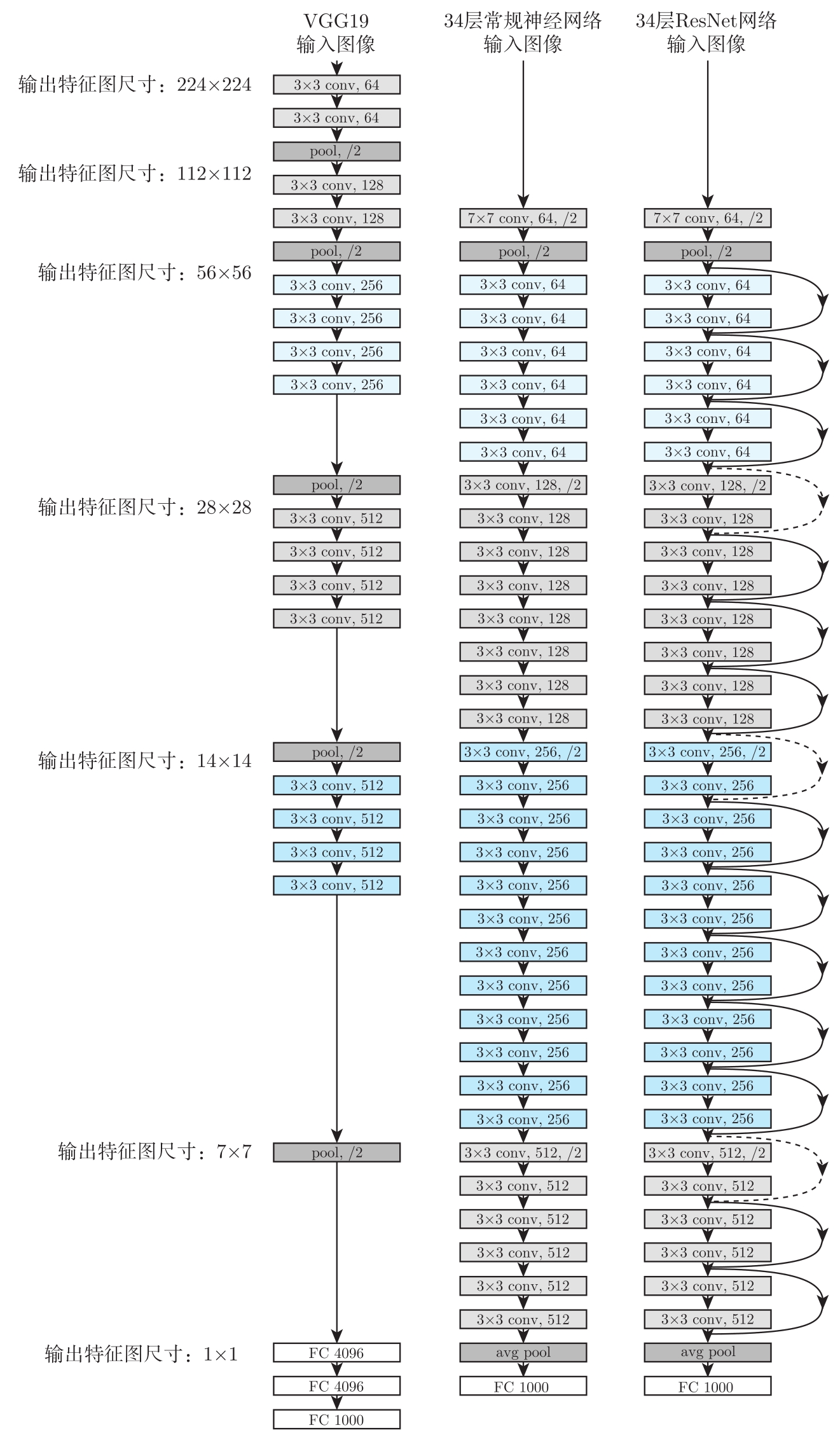
图3.23 ResNet网络结构 [42]