
下载掌阅APP,畅读海量书库
立即打开



本节首先介绍几个易混淆的概念:人工智能、机器学习、神经网络、深度学习。然后通过线性回归来介绍机器学习的基本思想。
我们在媒体、论文和小说中经常看到人工智能、机器学习、神经网络、深度学习这些热门词汇。很多时候,这些词汇被非专业人士错误地混用了。因此,有必要搞清楚它们之间的准确关系。图2.1中给出了人工智能、机器学习、神经网络、深度学习之间的包含关系。人工智能是最大的范畴,包括机器学习、计算机视觉、符号逻辑等不同分支。机器学习里面又有许多子分支,比如人工神经网络、贝叶斯网络、决策树、线性回归等。目前最主流的机器学习方法是人工神经网络。而人工神经网络中最先进的技术是深度学习。
机器学习有很多定义,T.Mitchell认为机器学习是对能通过经验自动改进的计算机算法的研究 [30] ,E.Alpaydin认为机器学习是利用数据或以往的经验来提升计算机程序的能力的方法 [31] ,周志华认为机器学习是研究如何通过计算的手段以及经验来改善系统自身性能的一门学科 [32] 。这些定义中的共性之处是,计算机通过不断地从经验或数据中学习来逐步提升智能处理能力。
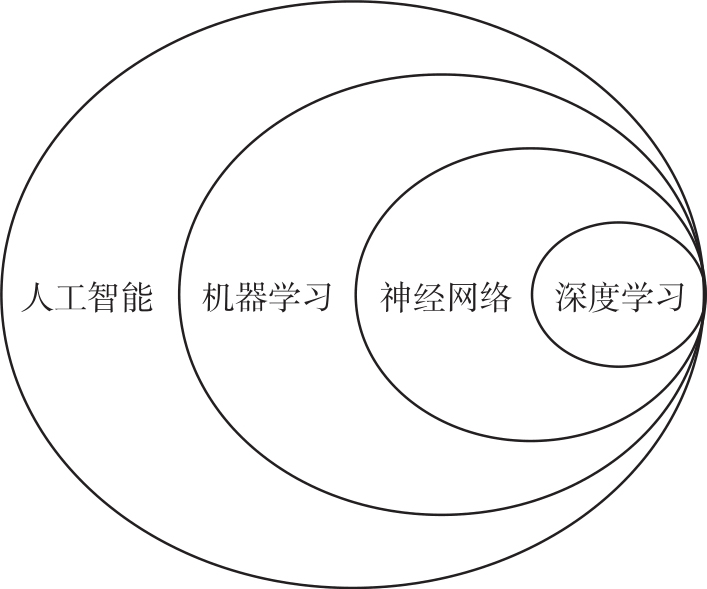
图2.1 人工智能、机器学习、神经网络、深度学习之间的关系
机器学习根据训练数据有无标签可以大致分为监督学习和无监督学习两大类。监督学习通过对有标签的训练数据的学习,建立一个模型函数来预测新数据的标签。无监督学习通过对无标签的训练数据的学习,揭示数据的内在性质及规律。
图2.2展示了一种常见的监督学习的流程。其训练(学习)过程为:首先,要有训练数据
x
及其标签
y
;其次,针对训练数据选择机器学习方法,包括贝叶斯网络、神经网络等;最后,经过训练建立模型函数
H
(
x
)。监督学习的预测过程(测试,也称为推理)是将新的数据送到模型
H
(
x
)中得到一个预测值
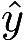 。通常用损失函数
L
(
x
)来衡量预测值与真实值之间的差,损失函数值越小表示预测越准。
。通常用损失函数
L
(
x
)来衡量预测值与真实值之间的差,损失函数值越小表示预测越准。
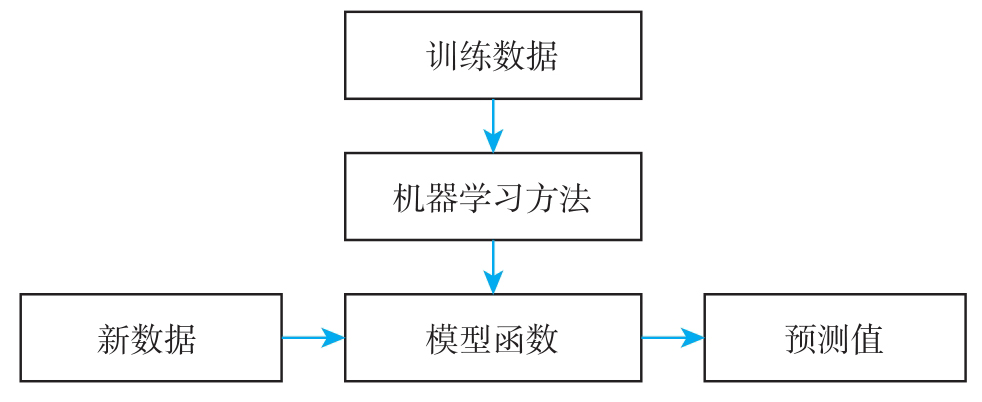
图2.2 典型的机器学习过程
为了便于读者理解,表2.1列出了本书常用的符号。