
下载掌阅APP,畅读海量书库
立即打开



本书介绍的大语言模型应用主要是指将大型模型部署到本地环境中,而不是直接使用ChatGPT等云端服务。换句话说,这些模型被安装在本地GPU算力服务器上运行,而不依赖其他在线服务资源。通过学习这些完整的大型模型应用案例,读者将全面了解大语言模型的部署方案和开发方法。
构建一个完整的大语言模型应用,需要三大部分组件:第一部分是基础设施,包括搭建算力资源的硬件和操作系统软件;第二部分是基础软件,包括CUDA(Compute Unified Device Architecture、统一计算设备架构)
 、PyTorch、Python虚拟环境Anaconda以及部署客户端应用的Nginx
;第三部分是应用软件,一般由服务端和客户端组成。大语言模型应用的整体架构如图2-1所示。
、PyTorch、Python虚拟环境Anaconda以及部署客户端应用的Nginx
;第三部分是应用软件,一般由服务端和客户端组成。大语言模型应用的整体架构如图2-1所示。
1)基础设施层:由服务器、推理卡、网卡等硬件组成,提供模型应用运行的载体和算力保证,操作系统、推理卡驱动等也被归为基础设施层,为应用提供GPU计算的软件计算服务。
2)基础软件层:由CUDA、PyTorch、Python虚拟环境工具Anaconda和Web服务器Nginx组成,提供程序的运行环境和AI计算服务。
3)应用软件层:服务端由大语言模型文件、Transformers库、基于大语言模型的应用服务程序以及OpenAI兼容API等组成,实现大语言模型的装载、推理和对外服务;客户端使用Python或React.js开发页面服务。其Web页面交互通过在浏览器端调用大模型OpenAI兼容接口实现,主要构成元素是HTML5和JavaScript代码。如果采用React.js编写客户端,则代码被编译成HTML与JavaScript,并被部署到Nginx上,为客户端提供Web服务。
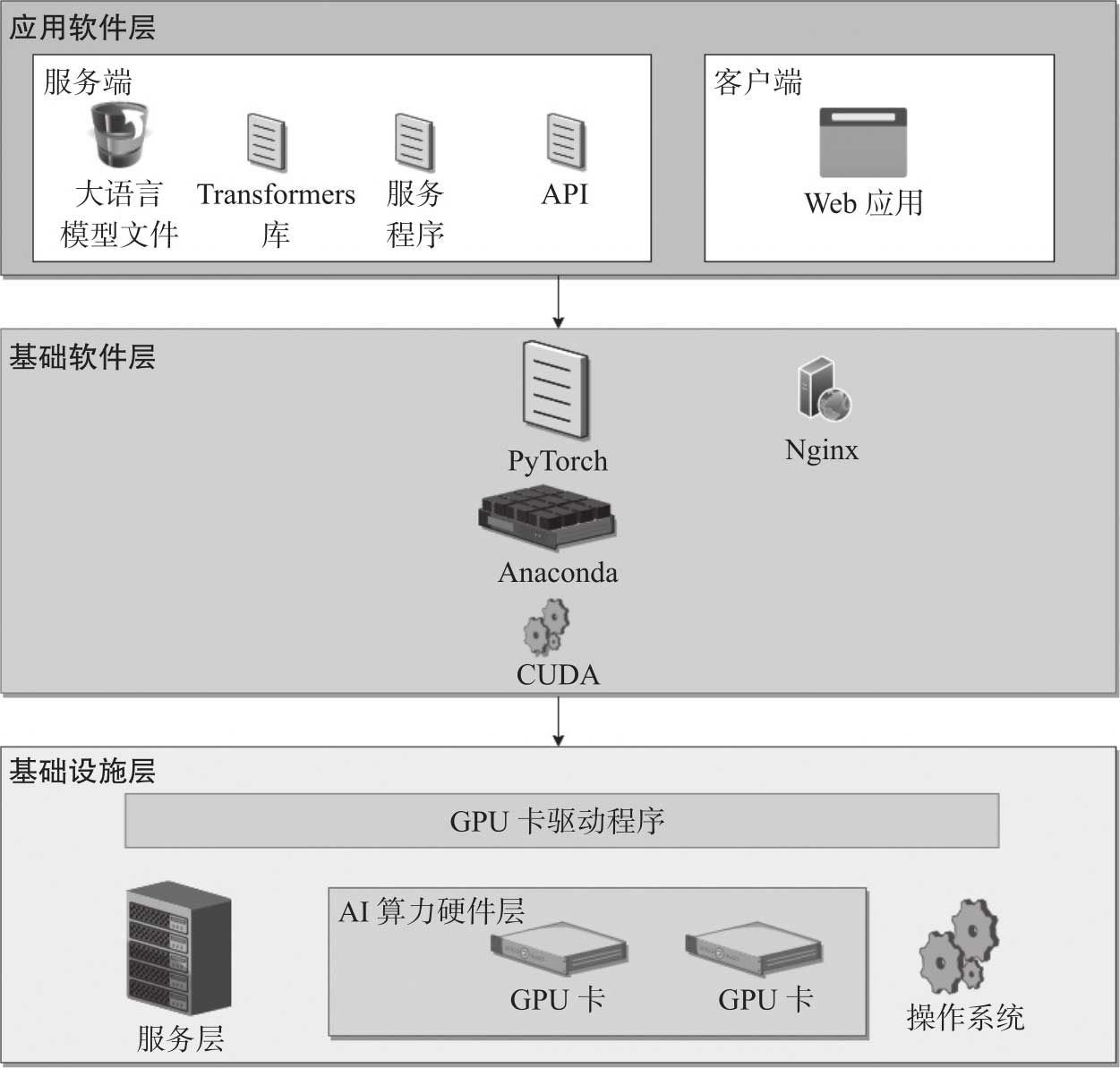
图2-1 大语言模型应用的整体架构
大语言模型的基础设施是指为了支持大规模语言模型训练和应用而建立的计算基础设施,主要包括满足推理卡运行要求的服务器、推理卡和操作系统。基础设施应具备较高的计算性能,以便在运行中处理大量并发的浮点运算。
硬件部分主要包括服务器和推理卡。AI推理卡与消费级显卡有一定的区别。AI推理卡是专门为人工智能应用程序设计的硬件,具有更强大的计算能力和更高的并行处理能力,可以支持深度学习、神经网络等复杂的AI算法,而消费级显卡则更多用于图形处理、游戏等日常应用,两者在计算能力上也有一定的区别。推理卡没有图像输出接口,不能当成显卡使用,一般不内置风扇,需要服务器靠自身硬件配置来解决散热的问题。有代表性的推理卡如A100、A800、A10、P100、V100、T4等,高性能的消费级显卡如RTX4090、RTX3090、RTX2080等。推理卡和显卡都可以用于支撑大语言模型的运算,可根据具体的需求和性价比来选型。
对于服务器来说,需要确认其电源容量是否足够承载推理卡的负荷,主板是否兼容推理卡,以及CPU内存容量等其他组件是否满足大语言模型的运行要求等。一般来说,是否可以运行大模型是由GPU的内存容量决定的,运行的性能如何是由GPU上的计算单元数决定的。
主流的操作系统,如Windows、Linux和macOS,都可运行大语言模型应用,但具体应用所依赖的库在不同的操作系统上是有区别的。比如,通过PyTorch的
k
位量化访问大语言模型的bitsandbytes
库,在Windows上运行就会遇到一些问题,而在Linux上问题较少,所以如果长期训练和使用大语言模型,则建议采用Linux系统,如Ubuntu22.04发行版等。
CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一个并行计算平台和编程模型,利用GPU的并行计算能力来加速通用计算任务。CUDA允许开发者使用一种类似于C语言的编程语言来编写并行计算程序,并在NVIDIA的GPU上运行这些程序。通过CUDA,开发者可以利用GPU的数千个并行处理核心来加速各种计算任务,包括科学计算、深度学习、图形渲染等。CUDA提供了丰富的库和工具,帮助开发者更轻松地利用GPU的计算能力,从而实现更快速和高效的计算。
CUDA需要推理卡驱动的支持。安装完驱动后,可以使用“nvidia-smi”命令查看驱动支持的最高CUDA版本,如11.7、12.1、12.2等。通常要安装与推理卡驱动适配的CUDA版本,以减少兼容性问题。例如,在使用DeepSpeed进行模型微调时,CUDA和PyTorch的版本匹配要求很高,在实际操作中,需要根据具体情况选择合适的版本,而不一定要选择最新版本。
Torch是一个开源的科学计算框架,提供了丰富的数学函数和数据结构,能够进行高效的科学计算和机器学习任务,基于Lua语言实现。PyTorch是Torch的Python语言实现,是一个由Meta的人工智能研究团队开发的开源深度学习框架,包含了一些AI运算的模块,如进行张量计算的torch.Tensor模块、用于CUDA交互的torch.cuda模块、与神经网络相关的torch.nn模块和分布式计算模块torch.distributed等。本书涉及的大语言模型,除将使用C++开发的量化程序移植到CPU运行的情况外,其他的场景都需要PyTorch的支持,PyTorch的版本比较多,在具体项目中,需要按组件依赖、CUDA版本等情况选择合适的版本进行安装。
不同的大语言模型应用,使用的Python版本略有区别,依赖库的区别则更大。如果直接在操作系统上安装Python和依赖库,则会造成只能运行其中一个项目,甚至会出现由于一个项目中不同服务的依赖库冲突而无法运行的情况。为了避免这种情况,需要引入Python环境虚拟化的技术,将不同的项目运行在不同的虚拟环境中。每个虚拟环境有一套独立的文件体系,互不影响,以实现在一个操作系统下运行多个相互隔离的虚拟化环境。
实现Python环境虚拟化,可用Python的venv模块或Python的一个发行版Anaconda。这两个软件都能达到环境隔离的目的,可任选其一。在本书中采用了Anaconda,其架构如图2-2所示。

图2-2 Anaconda虚拟环境
Anaconda是一个开源的Python发行版和库管理器,由Continuum Analytics公司开发和维护,包含了许多常用的Python库和工具,以及用于数据科学、机器学习和科学计算的软件库。Anaconda还提供了一个名为Conda的库管理工具,可以帮助用户轻松地安装、更新和管理Python虚拟环境。经Anaconda管理的虚拟环境,依赖文件默认保存在“~/anaconda3/envs/虚拟环境名”下。
Nginx是一个高性能的HTTP和反向代理Web服务器,同时提供了IMAP/POP3/SMTP服务。Nginx由伊戈尔·赛索耶夫开发,其源代码以类BSD许可证的形式发布,因其稳定性、丰富的功能集、简单的配置文件和低系统资源的消耗而闻名。
在本书中,大部分客户端例程采用React.js开发,在程序调试时,采用npm
运行。在正式部署时,程序被编译成HTML5与JavaScript代码后复制到Nginx的html目录中即可完成部署。程序更新也只需重新更新编译后文件,甚至都不需要重启Nginx。在应对比较高的并发时,可对Nginx的一些参数配置进行优化。Nginx也可以支持负载均衡、配置SSL证书、HTTP代理以及提供文件下载服务,是非常理想的Web服务器。
大语言模型文件主要由模型的权重参数文件、模型的配置文件、词汇表文件和分词标记器的配置文件组成。模型下载到本地服务器后,由Transformers库装载到GPU,提供推理服务。
Transformers库基本统一了大语言模型的调用API。不管是哪一个模型,只要是Hugging Face格式,都统一采用Model.from_pretrained方式进行装载。虽然有的模型使用AutoModel,有的采用诸如LlamaForCausalLM的专用model类,但总体上它们的编程方法是类似的。再比如模型微调,Transformers库也提供了TRL
、PEFT
等统一的编码方式,这样就基本上抹平了各个大语言模型在装载、推理、微调等方面的调用差异。
服务程序一般作为应用软件的后端,装载大语言模型,进行推理服务。得益于Transformers库的封装,最简单的推理服务程序除去注释后,只有短短6行Python代码。有一个网络趣图描述了大语言模型开发的这种现象:程序员在面试时回答了很多关于Transformer的编码器-解码器架构和自注意力机制的技术细节,当他通过面试进行实际工作时发现,编写程序代码只要一行“import transformers”就够了。这个故事虽然夸张,但也在一定程度上反映了大语言模型应用开发的现实特点。


在Chat应用方面,OpenAI提供的API主要有三个,分别是models、completions和embeddings,其请求路径(path)及主要作用见表2-1。
表2-1 OpenAI兼容接口的请求路径及主要作用

㊀Server Sent Event,服务端发送事件,是指客户端与服务端建立连接后,服务端主动向客户端推送数据。
在开发服务程序时,根据这三个标准接口,大部分能够访问OpenAI兼容接口的客户端即可通过设定接口地址接入服务。不过这些只是Chat应用的接口,在实际开发中,对于其他一些应用场景,如检索知识库、语音聊天,也可以变通使用completions接口来调用服务。
对于用来验证模型效果的Demo,往往采用Gradio库
快速实现。Gradio是一个开源的Python库,专门用于快速构建机器学习和数据科学领域的演示应用,广泛应用于大语言模型的Demo开发。在开发过程中,Gradio提供内置的操作和解释工具,可以很方便地调用模型和进行交互。
还有一种更方便的调试大模型的方法,就是使用基于Gradio开发的开源大模型客户端,如text-generation-webui
。这类客户端可直接装载本地的模型文件,进行Chat交互和LoRA微调,功能强大,界面美观。
如果准备开发对外服务的应用,那么使用Gradio或text-generation-webui就不太合适了,需要开发OpenAI兼容接口以及用Gradio或React.js定制客户端。