
下载掌阅APP,畅读海量书库
立即打开



深度学习(deep learning,DL),其核心就是“深”。这个“深”主要体现在模型结构上。对于了解神经网络的读者来说很好理解,就是将神经网络的隐藏层加深。对于不太了解的读者来说,可以简单理解为“三思而后行”。浅层神经网络只包含一层隐藏层,相当于瞬时反应,比如人的条件反射。深度神经网络则是让隐藏层变得更多,相当于深度熟虑以后再做出反应,如图1-1所示。
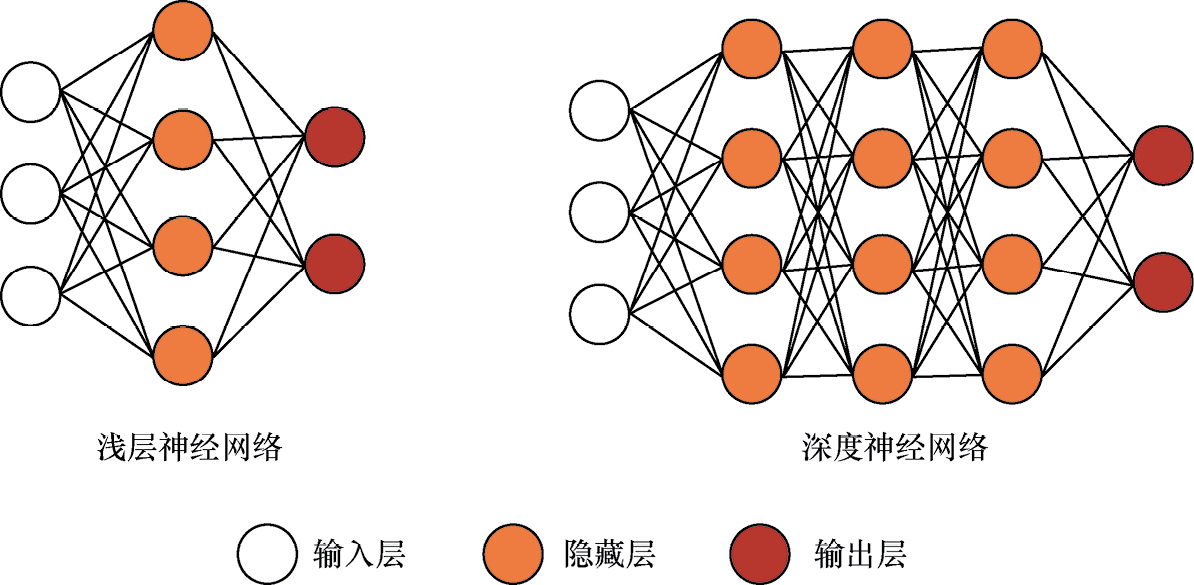
图1-1 神经网络结构示意
在上面这类神经网络的隐藏层中,前一层节点和后一层的每个节点之间都有连接,因此被称为“全连接网络”。它是基础神经网络,除此之外还有很多变体,我们将在后续章节中一一介绍。更深的网络结构意味着更多的参数、更大的模型,也意味着更高的算力需求。近些年深度学习的火热离不开算力的爆发式增长。从GPU到TPU,从单机单卡训练到分布式并行式训练,随着计算机硬件性能的提升,深度学习的效果越来越接近人类水平,甚至在某些领域已经超越了人类的平均水平。
那么,问题来了,深度神经网络的本质是什么?你有没有思考过这个本源问题呢?
理论上可以证明:一个多隐藏层神经网络能以任意精度逼近任意给定的连续函数。这也被称为全局逼近定理(universal approximation theory
 ),其中Universal有人翻译为“万能”,充分表明了它的强大。通过两个不同的视觉表示来说明多层神经网络作为函数逼近器的能力,更加形象化地说明了全局逼近定理的概念,如图1-2所示。
),其中Universal有人翻译为“万能”,充分表明了它的强大。通过两个不同的视觉表示来说明多层神经网络作为函数逼近器的能力,更加形象化地说明了全局逼近定理的概念,如图1-2所示。
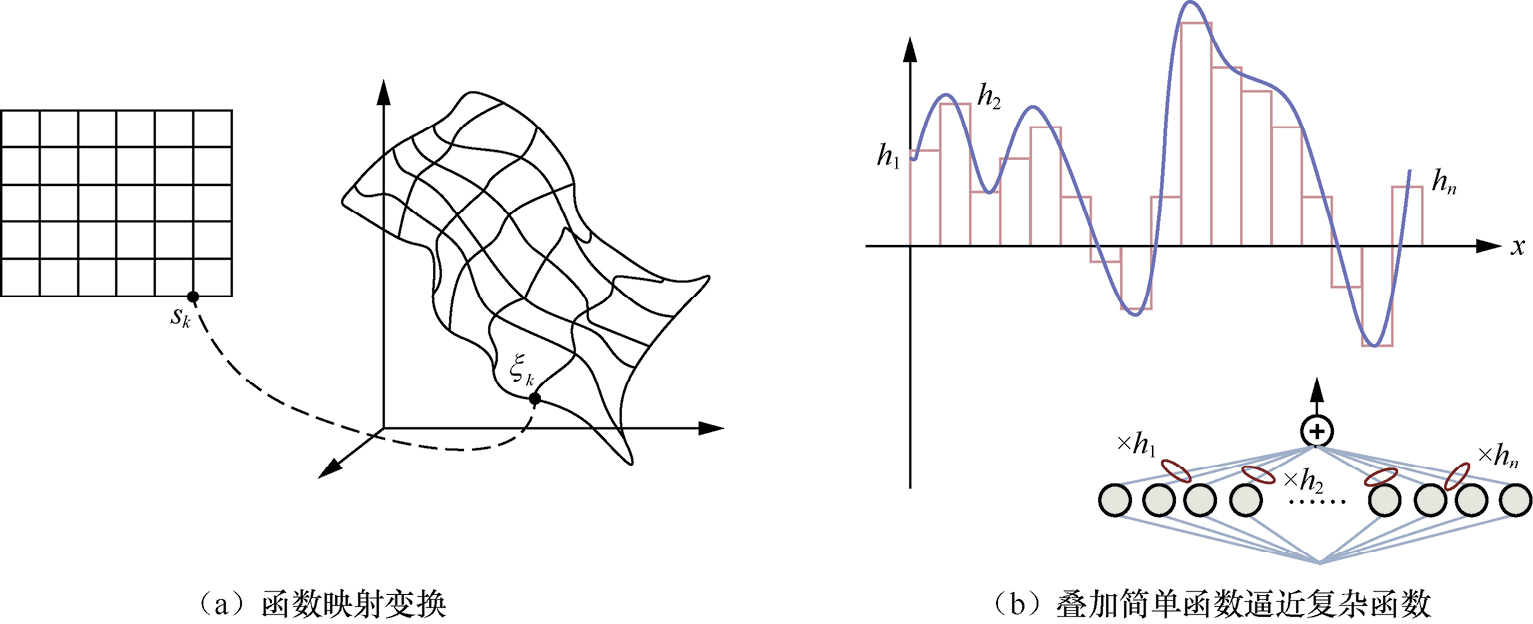
图1-2 函数映射变换和叠加简单函数逼近复杂函数示意
图1-2(a)展示了从输入空间到函数映射空间的变换。左侧的正方形网格表示输入空间,其中每个小方格可以看作输入向量的一个成分。右侧的扭曲网格展示了一个高维空间,原本线性独立的网格被映射成复杂的曲面,代表神经网络通过激活函数和权重的调整所进行的非线性变换。 s k 表示输入层元素或者特征向量的分量。 ξ k 是映射后的空间中与 s k 相对应的点。
图1-2(b)上侧展示了如何通过叠加多个简单函数来逼近一个复杂的连续函数。其中不同高度的矩形条被用来构造出一条近似的曲线。这些矩形条可以看作激活函数的加权输出,神经网络通过调整权重 h n (矩形的宽度和高度)来最小化预测和实际输出之间的差异。下侧的模型是对应的神经网络实现,输入乘以权重 h n 再相加产生输出。
从另一个角度看,深度神经网络强大的本质还在于,它能通过隐藏层神经元的非线性空间变换,使原本非线性不易区分的数据在新的特征空间中变为线性可区分。如图1-3所示,左侧的平面上有两条曲线(蓝色和红色),代表二维空间中的两类数据分布。它们在原始特征空间中是不可区分的,但通过一系列变换被映射到新的特征空间后,两种颜色的数据分布可以通过一个超平面来分隔。而实现这种变换的秘诀就在于激活函数(如Sigmoid函数)的使用。关于这里的数学证明和代码实现,我们在后续章节中都会讲到。
总体来说,全局逼近定理的重要性在于,它为使用神经网络来解决各种各样的非线性和高维问题提供了理论基础,证明了其在各种领域应用的可能性。然而,定理本身并不保证找到这样的近似解是容易的,也不保证学习过程的效率和收敛性,这些都是实际应用中的挑战。
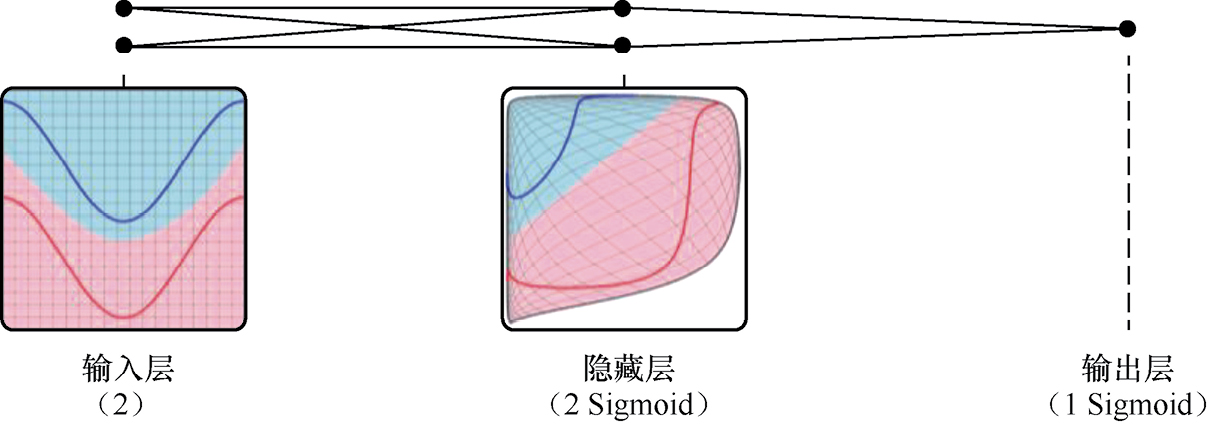
图1-3 非线性空间变换示意
本书第2章将带领大家快速回顾必要的数学知识,第3章介绍动手编程所需的环境搭建。在此基础上,第4章将详细介绍深度神经网络的基本原理,第5章讲述常见的问题和对策,第6章介绍求解模型参数的各种梯度下降算法及其变体。许多初学者常见的疑问是,深度神经网络是如何解决实际问题的?正则化为什么有助于缓解过拟合问题?到底选择哪种优化算法最好?学完这些章节后,你都会找到答案,对深度神经网络的理解也将上升一个层次,不仅能知其然,还能知其所以然。