
下载掌阅APP,畅读海量书库
立即打开



客户端又称为用户端,它是安装在用户的电脑上、与服务器连接、为用户提供本地服务的一种程序。网页的客户端主要是指浏览器。
浏览器(Web Browser),全称为网页浏览器,是安装在客户端上的一种软件,比如安装在电脑、平板电脑和手机上,用来访问和浏览网络信息和资源。用户可以在浏览器的地址栏中输入统一资源标志符(URI也就是通俗说的网址)向服务器请求指定的资源文件,服务器在收到请求后会将网页文件发送到客户端的缓存文件夹中,然后浏览器通过渲染引擎解析和排版接收到的网页文件并将最终的内容显示在浏览器的窗口中。浏览器的工作原理如图1.17所示。

图1.17 浏览器访问网页文件的原理
浏览器的主要组件包括:
①用户界面:包括显示网页文件的窗口和操控界面的元件。比如:用来输入URI的地址栏、后退/前进按钮、书签目录等。
②浏览器引擎:用来查询和操作渲染引擎的接口。
③渲染引擎:用来解析从服务器端请求来的网页文件,并将解析后的结果显示在浏览器的窗口中。
④网络:用来调用网络。
⑤UI后端:用来绘制如组合选择框和对话框等基本的组件。
⑥JS解释器:用来解释执行JS代码。
⑦数据存储:用来保存从服务器端请求的各种数据和文件。
浏览器的组件原理图如图1.18所示。
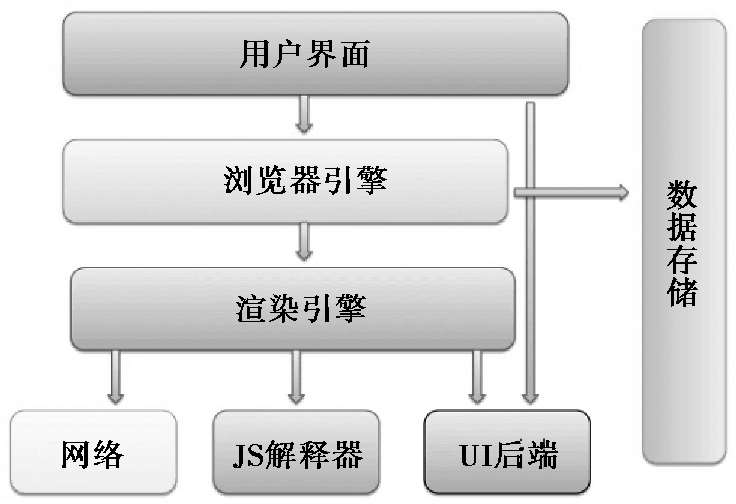
图1.18 浏览器的组件原理图
其中,浏览器的核心组件是渲染引擎,也就是浏览器的内核,它决定了网页文件在浏览器中显示的效果。虽然浏览器的软件产品很多,但浏览器的内核只有4种,它们分别是Trident内核、Geoko内核、webkit内核和Blink内核。
①Trident内核是微软开发的一种渲染引擎,由于Windows系统使用者众多,所以Windows系统自带的IE浏览器也被广泛使用,但是它的使用体验并不好,现在已经被webkit内核的浏览器所取代,浏览器也改名为EDGE。
②Geoko内核是火狐公司开发的渲染引擎,它的特点是可以自由开发,使用体验友好,但是开发后的代码必须完全公开,所以商业价值不高,已逐渐被边缘化。代表产品是Mozilla Firefox。
③webkit内核是KDE小组开发的渲染引擎,它的引擎由WebCore排版引擎和JavaScriptCore解析引擎组成。它也可以自由开发,并且使用体验友好,开发后的代码可以自由选择是否公开,所以被国内外各大厂商广泛改良使用,代表产品有苹果公司Safari、Google公司的Chrome和微软公司的Edge等。
④Blink内核是谷歌公司和欧朋公司一起开发的新一代渲染引擎,它是Webkit内核的一个分支,是目前最新的渲染引擎技术,现已在Chrome和Opera浏览器中使用。
这些内核由于是不同厂家生产的,所以在解析同一个网页文件时会有略微不同的显示效果。为解决这种显示不统一的问题,有些浏览器厂商使用双内核,也就是一个浏览器中有两种渲染引擎,浏览器会根据网页文件的要求判断优先使用哪个内核,当然用户也可以手动切换想要使用的内核。
网址(Website Address)是用来上网的地址,每个网页都对应一个网址或者一个IP地址。用户可以在浏览器中的地址栏内输入网址来访问网页,如图1.19所示。

图1.19 浏览器的地址栏图
URI(Uniform Resource Identifier)是一串采用特定语法规则书写的字符串,用来标识和区分网络中的各种资源。它提供了一种简单的、可扩展的资源标识方式。它标识的资源可以是服务器上的一个文件,也可以是一个邮件地址、新闻消息、图书、人名、Internet主机或者其他任何内容。
URI的书写格式为(其中,方括号[]内为可选项):

它可以分为四个部分,分别为:访问资源的命名机制、存放资源的主机名、资源自身的名称和其他参数。其中,访问资源的命名机制就是访问协议;存放资源的主机名包括登录信息、服务器地址和端口号;资源自身的名称包括文件路径、文件名和文件后缀;其他参数包括查询和信息片断。下面逐一说明。
访问协议项表示使用传输协议的方案,它告诉浏览器如何处理将要打开的文件。访问协议为可选属性,不区分大小写,协议名后要添加英文冒号“:”和双斜杠“//”。常用的协议有:http和https(超文本传输协议)协议,mailto(电子邮件地址)协议,file(当地电脑或者网上分享的文件)协议,ftp(文件传输协议)协议等。
登录信息项用来在登录服务器时认证上网者的身份,方便用户使用网站内的资源。它是可选属性,添加在服务器地址前,并使用“@”符号分隔登录信息项与服务器地址项。登录信息项通常使用用户名和密码作为登录信息,用户名和密码之间使用英文冒号“:”分隔。它的格式为:用户名:密码@服务器地址。例如:liuzhao:123@163.com。
服务器地址项是指存放网页文件空间的域名或者IP地址。
端口号项用来区别同一台计算机内运行的不同程序和服务的接口。它是可选属性,使用英文冒号“:”将服务器地址与端口号分隔。各种传输协议都有自己默认的端口号,当省略端口时,系统会使用默认的端口号。比如:http默认的端口号为80,https默认的端口号为443。有时候出于安全或者其他考虑,可以自定义端口号,即采用非标准端口号,此时端口号就不能省略了。
路径项用来寻找存放在服务器空间中文件的位置,通常为带有层级的、有逻辑的树状结构,层级之间使用英文斜线“/”分隔。它可以分为绝对路径和相对路径两种。
● 绝对路径
绝对路径是文件路径完整的书写形式。绝对路径与它指向的地址有关,也就是绝对路径无论书写在哪,这个书写的地址不会改变。在书写时,要写出URI的全部内容,例如:http://www.example.com/index.html。所以绝对路径的移植性不好,当引用的文件改变地址时,就无法找到了。
● 相对路径
相对路径是绝对路径的省略写法,它与文件存放的位置有关,也就是会随着存储位置的改变而改变。在书写时,只要写出URI的路径项即可,所以相对路径的移植性好,书写简单,当网站文件集体改变存放的空间时,不用修改URI就可以直接使用。
注意:①路径中不要出现中文。②当要访问它的子级资源时,要写出文件的路径结构。例如:page1/img/pic_1.jpg表示访问所在空间中的page1文件夹中的子文件夹img中的page1.html文件。其中,路径中只能使用反斜杠“/”,不要使用正斜杠“\”。这是因为操作系统内的文件路径都是使用正斜杠,使用正斜杠在操作系统上时会引发错误。
文件名项是指网站空间中文件的名称,它由文件名称和文件后缀组成,文件名称和文件后缀之间使用英文点号“.”连接。例如:在http://www. cqucc. com. cn/index. html中,index.html就是文件名。当然,这个文件名是首页文件,它比较特殊,使用时可以省略,省略后计算机会自动打开index.html的文件。
查询项是对数据库的内容进行动态询问时所需要的参数。它是可选属性,用于给使用CGI、ISAPI、PHP、JSP、ASP、ASP.NET等技术制作的动态网页传递参数。参数可以有多个,参数之间使用“&”符号隔开,每个参数的参数名和参数值之间使用等号“=”连接。
信息片断项用于指定网络资源中的片断,它是可选属性,由英文“#”号(读作:sharp)和字符组成。在网页文件中,它还可以用来给网页内设置锚点。例如:百度词条中的名词解释,可以使用信息片段直接定位网页中的名词到它的某一个解释的位置。
例如:http://www.cqucc.com.cn:8004/yssjxy/type1/060140301.html。在这个URI中,访问协议为http,存放资源的主机名为www. cqucc. com. cn:8004,资源的路径为/yssjxy/type1/060140301.html,其他的参数项没有。
URN(Universal Resource Name)用名称定位每个资源,也就是给特定空间的资源命名。URN只告诉我们存放资源的空间和资源的名称,但是不告诉我们资源的访问方式,所以无法定位和找到资源,但是可以在不知道其网络位置或者访问方式的情况下讨论资源。例如:urn:issn:1535-3613(国际标准期刊编号)、urn:isbn:9787115318893(国际标准图书编号)、tel:+86-152-4928-4597(电话号码)、mailto:jijs@ jianshu.com (简单邮件传输协议)等都是URN。
URL(uniform resource locator),俗称网页地址或者网址,它不仅标识了资源的地址,还指定了浏览器应该如何在Internet中寻找资源与获取信息的方式,也就是标明了访问协议,同时还指出了访问机制和网络位置。
URL采用地址定位资源,也就是URL使用字符串的抽象形式来描述资源在Internet上的地址。一个URL标识唯一的互联网资源,通过与之对应的URL即可获得该资源。例如:http://www.jianshu.com/u/1f0067ef、ftp://www.example.com/resource.txt等都是URL。对于网页前端开发人员来说,使用最多的就是URL。
URL的书写格式为(带方括号[]的为可选项):

它由访问协议、存有该资源的主机IP地址、主机资源的具体地址和其他参数四个部分组成。它们的使用方法与URI的这些项类似。
URI用字符串标识某一互联网资源,URL表示资源的地点(资源所处的位置),而URN用特定命名空间的名字标识资源。由此可见URI包含URL和URN,换言之,URL和URN都是URI的子集,但是URI不一定是URL或者URN。URI是一个唯一的字符串,但是这个字符串可以不是网址。URI、URL和URN的关系如图1.20所示。
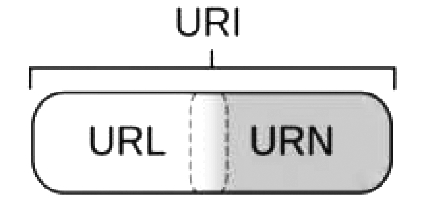
图1.20 URI、URL和URN的关系
例如:

这两个网址既是URI又是URL,它们都是通过寻找某个命名空间中的资源标识找到资源。如果去掉资源的访问方式ftp://和http://,co.za/word/1808. txt和www. example.com/index.html#position就成了URN。
WWW是环球信息网的缩写,中文名字为“万维网”,常被简称为Web。它由欧洲核物理研究中心(CERN)研制,最初的目的是方便全球的科学家利用Internet(因特网)进行通信交流和查询。
WWW以超文本标记语言和超文本传输协议为基础,建立在客户机和服务器模型之上,能够提供面向Internet的服务、界面信息一致的浏览系统。它是一个由许多互相链接的超文本组成的系统。它可以理解为是由无数个网络站点、网页和多媒体等的集合,它们在一起构成了Internet最主要的部分。在这个系统中,每个有用的事物都被称为“资源”,这些资源使用全局统一资源标识符(URI)标识,通过超文本传输协议(Hypertext Transfer Protocol)在互联网中传输,之后用户就可以通过点击超链接或者输入资源地址来获得网络中的资源。
因特网(Internet)是一个把分布于世界各地不同结构的计算机网络用各种传输介质互相连接起来的网络。用户不仅能访问到万维网(WWW)上的信息,还可以使用文件传输(FTP)、电子邮件(E-mail)、远程登录(Telnet)、手机(5GHz)等网络上的服务。因此,它已经成为Internet上应用最广和最有前途的访问工具,并在商业上也发挥着越来越重要的作用。
互联网包含因特网,因特网包含万维网,但是因特网和万维网并不等同于互联网,它们都是依靠互联网运行的一项服务。互联网是一个由许多互相链接的超文本组成的全球性系统,通过超文本传输协议将网络中的资源传送给用户,用户可以通过浏览器来访问互联网上的这些资源。