
下载掌阅APP,畅读海量书库
立即打开



在计算机中,各种字符需要用若干位的二进制码的组合表示,即字符的二进制编码。由于字节是计算机的基本存储单位,所以常以8个二进制位为单位表达字符。
一个十进制数位在计算机中用4位二进制编码来表示,这就是所谓的二进制编码的十进制数(Binary Coded Decimal,BCD)。常用的BCD码是8421 BCD码,它用4位二进制编码的低10个编码表示0~9这十个数字,参见前面的表2-3。
BCD码很容易实现与十进制真值之间的转换。例如:
BCD码:0100 1001 0111 1000.0001 0100 1001。十进制真值:4978.149
如果将8位二进制(即一个字节)的高4位设置为0,仅用低4位表达一位BCD码,该BCD码称为非压缩(Unpacked)BCD码;如果通常用一个字节表达两位BCD码,该BCD码称为压缩(Packed)BCD码。
BCD码虽然浪费了6个编码,但能够比较直观地表达十进制数,也容易与ASCII码相互转换,便于输入、输出。另外,它还可以比较精确地表达数据。例如,对于一个简单的数据0.2,采用浮点格式(详见9.1节)无法精确表达,而采用BCD码可以只使用4位“0010”表达。最初的计算机支持十进制运算,IA-32整数处理器中使用调整指令实现十进制运算。
字母和各种字符也必须按特定的规则用二进制编码才能在计算机中表示。编码方式有多种,其中最常用的一种编码是ASCII(American Standard Code for Information Interchange,美国标准信息交换码)。现在使用的ASCII码源于20世纪50年代,完成于1967年,由美国标准化组织(ANSI)在ANSI X3.4—1986中定义。
标准ASCII码用7位二进制编码表示,故有128个,如表2-4所示。计算机的存储单位为8位,表达ASCII码时,最高位D 7 位通常为0;通信时,D 7 位通常用作奇偶校验位。
表2-4 标准ASCII码及其字符
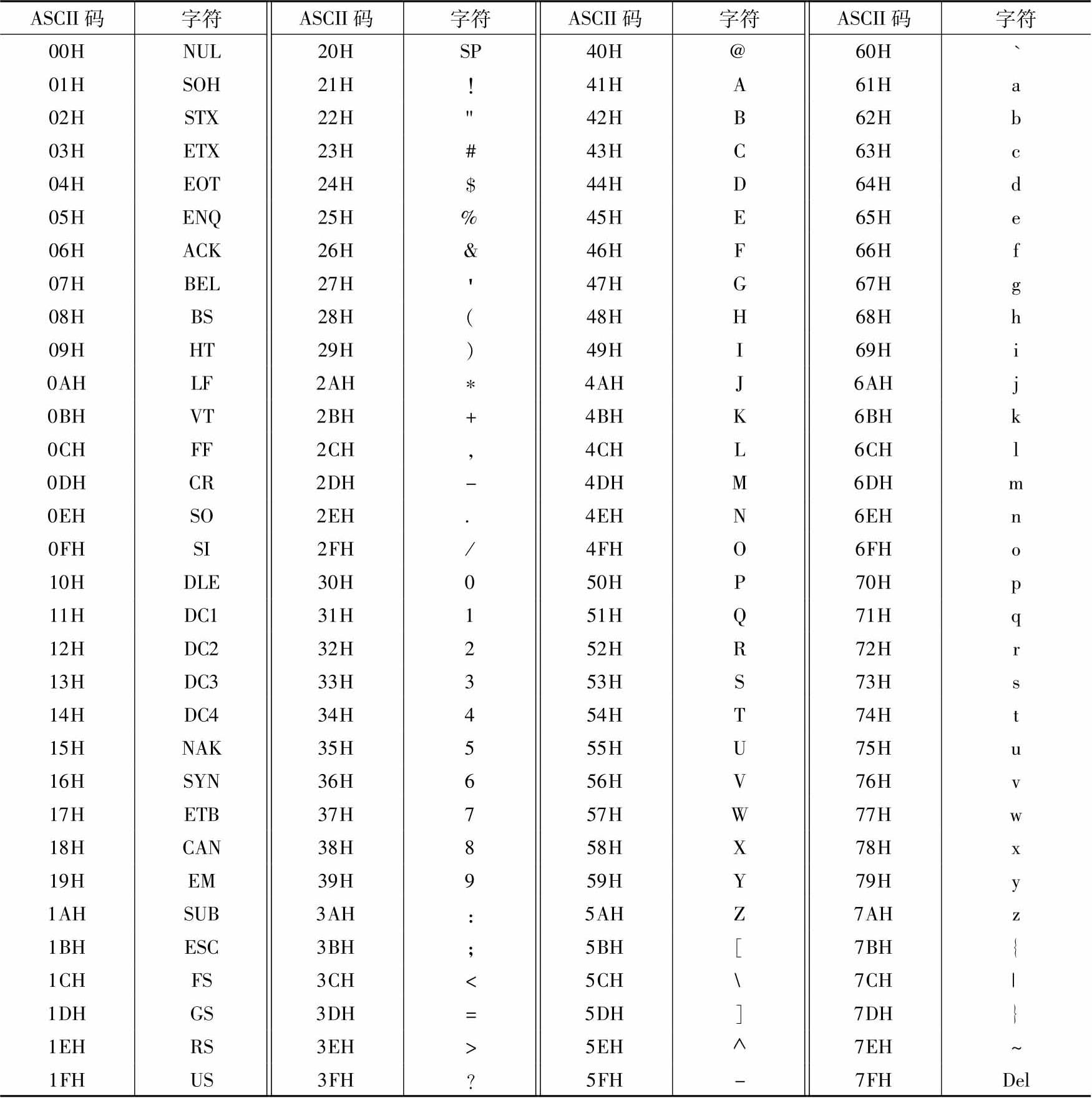
ASCII码表中的前32个和最后一个编码是不可显示的控制字符,用于表示某种操作。并不是所有设备都支持这些控制字符,也不是所有设备都按照同样的功能应用这些控制字符。不过,有些控制字符获得了广泛使用。例如:0DH表示回车CR(Carriage Return),控制屏幕光标时就是使光标回到本行首位;0AH表示换行LF(Line Feed),就是使光标进入下一行,但列位置不变;08H实现退格BS(Backspace);7FH实现删除DEL(Delete)。另外,07H表示响铃BEL(Bell),1BH(ESC)常对应键盘的ESC键(多数人称其为Escape键)。ESC(Extra Services Control)字符常与其他字符一起发送给外设(例如打印机),用于启动一种特殊功能,很多程序中常使用它表示退出操作。
那么,C语言转义符“\n”是哪个字符呢?在C语言中,转义符“\n”设置显示(打印)位置为下一行首列。使用的ASCII控制字符依系统不同而不同:微软的DOS和Windows操作系统使用回车CR和换行LF两个控制字符实现,UNIX(Linux)操作系统使用一个换行LF控制字符实现,而苹果公司的macOS操作系统使用一个回车CR控制字符实现。所以,编写底层应用程序,尤其是跨平台应用时,需要理解这些不同。例如,在不同的操作系统下打开同一个文本文件时,就会遇到换行问题。功能略强的文本类编辑软件都具有处理这个问题的能力,但功能简单的Windows记事本程序就没有处理这个问题的能力,因此会出现文本换行错误的情况。
表示字符串结束时,可以在字符串最后使用特殊的标识符号,即结尾字符。结尾字符可以自行定义,曾使用过回车字符、换行字符等,现在多使用0(例如,C、C++和Java语言)。这个0就是ASCII表的首个字符,称为空字符(ASCII码值为0),编程语言中常用常量NULL(或NUL等)表示。不要把它与字符“0”(ASCII码值为30H)以及空格字符(ASCII码值为20H)混淆。
ASCII码表中从20H开始的95个编码是可显示(打印)的字符,其中包括数字(0~9)、英文字母、标点符号等。从表中可看到,字符'0'~'9'的ASCII码为30H~39H,去掉高4位(或者说减去30H)就是BCD码。大写字母A~Z的ASCII码为41H~5AH,而小写字母a~z的ASCII码为61H~7AH。大写字母和对应的小写字母相差20H(32),所以大小写字母很容易相互转换。ASCII码中,20H表示空格。尽管它显示空白,但要占据一个字符的位置;它也是一个字符,表中用SP(space)表示。熟悉这些字符的ASCII码规律对解决一些应用问题很有帮助,例如,英文字符就是按照其ASCII码大小进行排序的。
处理器只是按照二进制数操作字符编码,并不区别可显示(打印)字符和非显示(控制)字符,只有外部设备才区别对待,产生不同的作用。例如,ASCII字符设备总是以ASCII形式处理数据,要显示(打印)数字“8”,必须将其ASCII码(38H)提供给显示器(打印机)。
另外,PC还采用扩展ASCII码,主要用于表达各种制表用的符号等。扩展ASCII码的最高位D 7 位为1,以与标准ASCII码区别。
ASCII码表达了英文字符,但却无法表达世界上所有语言的字符,尤其是非拉丁语系的语言(如中文、日文、韩文、阿拉伯文等)的字符。因此,各国也都定义了各自的字符集,但相互之间并不兼容。例如,1981年我国制定了《信息交换用汉字编码字符集 基本集》(GB 2312—80)国家标准(简称国标码),规定每个汉字使用16位二进制编码(即两个字节)表达,共计7445个汉字和字符。在实际应用中,为了保持与标准ASCII码兼容,不产生冲突,国标码两个字节的最高位被设置为1,称为汉字的机内码。不过,汉字机内码可能与扩展ASCII码冲突(因它们的最高位都是1),所以一些西文制表符有时会显示为莫名其妙的汉字。
为了解决世界范围的信息交流问题,1991年国际上成立了统一码联盟(Unicode Consortium),制定了国际信息交换码Unicode。在其网站上对“什么是Unicode?”曾给出如下解答:“Unicode给每个字符提供了一个唯一的数字,不论是什么平台,不论是什么程序,不论是什么语言。”Unicode使用16位编码,能够对世界上所有语言的大多数字符进行编码,并提供了扩展能力。Unicode作为ASCII的超集,保持与其兼容。Unicode的前256个字符对应ASCII字符,16位编码的高字节为0、低字节等于ASCII码值。例如,大写字母A的ASCII码值是41H,用Unicode编码是0041H。
现在,Unicode已被大家认同,很多程序设计语言和计算机系统都支持它。例如,Java语言和Windows操作系统的默认字符集就是Unicode。有关Unicode的详情,请访问统一码联盟网站(https://home.unicode.org)。