
下载掌阅APP,畅读海量书库
立即打开



字节是构成数据的基本单位,每个字节由8位(bit)组成,能够表示256种不同的状态。在进行网络I/O或磁盘I/O时,所有数据结构都必须转换为字节序列以便传输。
在Go语言中,字节被定义为一个独立的数据类型,以关键字byte表示。在底层,byte类型是uint8类型的别名,占用1字节的存储空间,其取值范围为0~255,足以表示一个ASCII字符。
本书涉及大量Go源码分析,所使用的Go版本为Go 1.18。
字节的定义如代码清单2-1所示。
代码清单2-1 字节的定义

字节在Go语言中是一个非常基础的类型,它是数据的原始承载形式。序列化和反序列化操作都依赖于字节类型。字节广泛用于存储二进制数据,比如图片、音频和视频文件。在网络编程中,字节数组同样很常见,通常用于传输和描述网络数据包的内容。
在处理数据I/O时,我们操作的是字节类型的序列,并不会去感知业务数据类型。跨组件、进程或网络的数据传输通常涉及序列化与反序列化步骤。本质上,序列可以被视为一维数组。
字节是更高级数据类型的基础,是程序的基石之一。理解字节的定义、初始化及重要性对于编写高效且可靠的I/O程序至关重要,接下来将介绍一些字节与其他类型相互转换的示例。
1.字节和整型
多字节的基本数据类型中,最典型的是整型。以int32类型为例,它占用4字节。若要通过网络发送一个int32类型的数据到另一个进程,首先需要将它转换为一个4字节的序列。这个转变过程会引出字节端序的问题,即将最高有效字节放前面还是后面,其中涉及大端序和小端序两种表现形式。
大端序(Big-endian)是指将高位字节存储在低地址,而低位字节放在高地址。例如,对于十六进制数据0x12345678,大端序的存储方式是0x12,0x34,0x56,0x78。在网络通信中,默认使用大端序,因此大端序也被称为“网络字节序”。
小端序(Little-endian)是指将低位字节存储在低地址,而高位字节存储在高地址。例如,对于0x12345678,小端序的存储方式为0x78,0x56,0x34,0x12。在计算机系统中,通常使用小端序,因此小端序也被称为“主机字节序”。大端序和小端序的区别如图2-1所示。
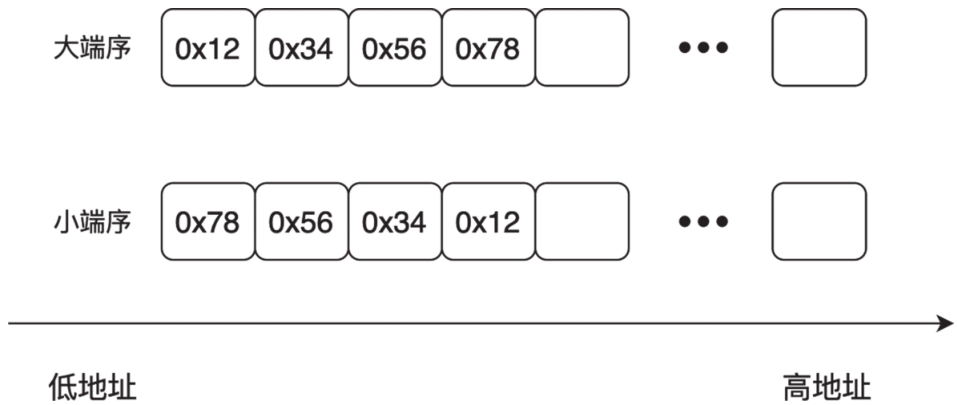
图2-1 大端序和小端序的区别
在Go语言中,标准库binary提供了字节端序的相关功能,可以实现大端序和小端序之间的序列化与反序列化。例如,将一个无符号32位的整型类型序列化,见代码清单2-2。
代码清单2-2 序列化成字节数组

上述代码编译后,可以使用调试工具如dlv查看内存分布,验证存储顺序是否与图2-1一致。以下是使用dlv打印代码清单2-2中变量的示例。

标准库对于大端序和小端序的实现是简单直观的。以大端序为例,它仅需将最高有效字节放置在数组的第一个字节,随后是次高有效字节,以此类推,直至所有字节均被处理。代码清单2-3展示了binary如何实现对uint32类型的大端序转换。
代码清单2-3 binary包的大端序实现

在整型数据序列化为字节序列之后,便可以通过网络I/O或磁盘I/O等方式进行传输。之后,数据可以在合适的时机被读取并反序列化,以重新构建出原始的整型变量。这个过程实现了整型变量在I/O链路上传输的完整周期。
2.字节和复合类型
在Go语言中,通常会根据实际需求自定义复合类型,这通过使用struct关键字来声明。如果我们想要在I/O链路中传输复合结构体的内容,例如将一个结构体通过网络I/O发送到另一个进程,那就必须经过序列化和反序列化的过程。序列化可以采用多种格式,例如JSON或XML等。我们也可以自定义序列化的规则,结构体与字节序列之间的转换如图2-2所示。
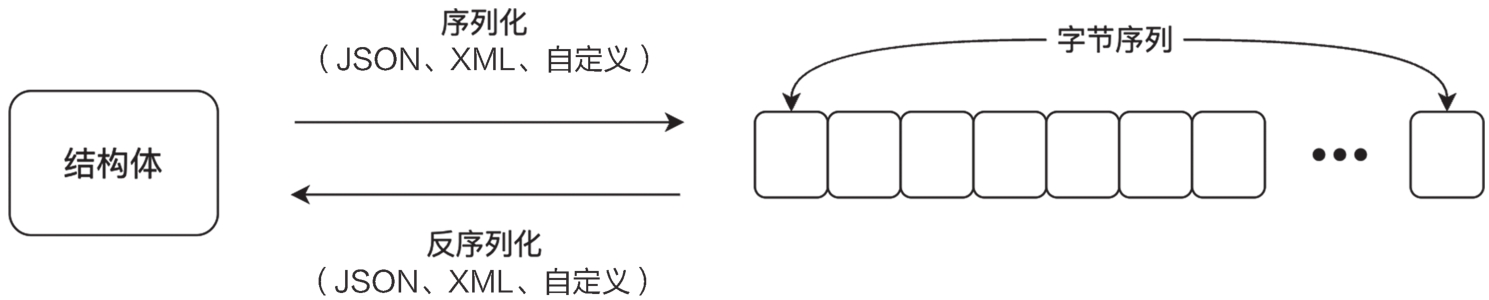
图2-2 结构体和字节序列的转换示意
以一个具体的例子来阐述,我们首先定义一个名为Person的结构体,如代码清单2-4所示。
代码清单2-4 Person结构体定义

(1)JSON序列化规则
接下来使用JSON格式来序列化和反序列化该结构体,从而生成字节序列。这一过程的代码如代码清单2-5所示。
代码清单2-5 Person结构体使用JSON序列化和反序列化

采用通用格式进行序列化和反序列化有显著的优势:只要遵循相同的序列化协议,不同的系统组件就能跨平台和跨语言交换数据。这正是统一标准带来的好处。然而,在某些情况下,我们可能出于对安全性或者性能的考虑,会使用自定义序列化规则来处理数据。
(2)自定义序列化规则
还是以Person结构体为例,我们的目标是将该结构体分解为一维的字节序列,同时确保信息的完整性。对于Person.Name字段,由于其内存长度不固定,在转换为一维序列后,需要用4字节来记录其长度。对于Person.Age字段,用4字节存储即可。对于整数类型的序列化,我们将采用大端序。Person的序列化规则如图2-3所示。
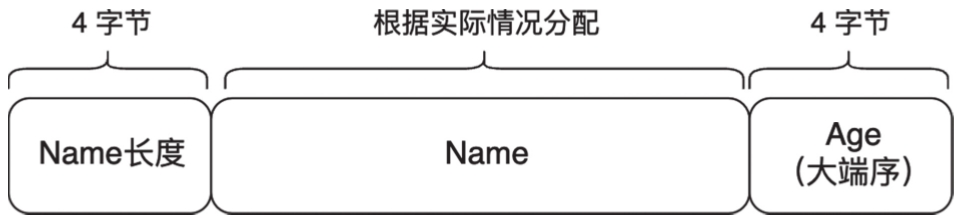
图2-3 Person的序列化规则
代码清单2-6展示了如何实现Person结构体自定义的序列化和反序列化。
代码清单2-6 Person结构体自定义的序列化和反序列化

以上代码展示了一个复杂的、非连续内存的结构体与一维的字节序列相互转换的过程。Person结构体的序列化和反序列化如代码清单2-7所示。
代码清单2-7 Person结构体的序列化和反序列化

序列化的主要目的是将一个复杂的、在内存中非连续存储的结构体转换成一个顺序的字节序列。实现这一目标的关键是分配足够的连续内存空间,并精确地规划如何在这段内存中安置结构体的数据。相对地,反序列化是这个过程的逆操作,它涉及重新构建和恢复结构体的步骤。
通过上述示例,我们可以观察到在不同形式的数据转换过程中,字节类型扮演了承载数字信息的重要角色。在数据传输过程中,数字信息通常以字节序列的形式进行传输。