
下载掌阅APP,畅读海量书库
立即打开



本章将全面探讨知识图谱的历史、发展以及当前的现状。读者将了解知识图谱的起源和演进,包括早期的知识表示方法和推理系统,以及知识图谱的重要里程碑和发展趋势。此外,本章还将深入探讨当前知识图谱的应用领域和挑战,涵盖领域知识图谱、通用知识图谱等。读者将对知识图谱在各个领域中的应用和潜力有一个全面的了解。
知识图谱(knowledge graph,KG)旨在描述客观世界的概念、实体、事件及其之间的关系,本质是语义网络知识库,可以对现实世界的事物及其相互关系进行形象化的描述,也可以从互联网海量信息中形象化出实体关系进行知识存储。
2012年谷歌(Google)正式推出知识图谱的概念并将其应用在谷歌搜索,其初衷是提高搜索引擎的能力,优化用户体验。有了知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更好地满足用户的查询需求。Google知识图谱 [1] 的宣传语“things not strings”给出了知识图谱的精髓,即不要无意义的字符串,而是获取字符串背后隐含的对象或事物。谷歌搜索“鲁迅”的结果如图1.1所示。
下面以图1.1为例解释知识图谱的概念,谷歌搜索引擎检索关键词时,右边knowledge graph card更直观地展示了人物实体的具体信息。
互联网上拥有丰富的资源。但是,大多数的资源都只能被人理解,却无法被机器理解,如何让机器像人一样理解文本?答案是使用知识图谱技术,即使用知识图谱建立和应用的技术,融合了认知计算、知识表示与推理、信息检索与抽取、自然语言处理与语义Web、数据挖掘与机器学习等方向的交叉研究。知识图谱本质上是一种语义网络,以实体或者概念作为节点,通过语义关系相连接。知识图谱来源于语义搜索、机器问答、情报检索、电子阅读、在线学习等实际应用。以“孔子”为例,知识图谱数据节点的显示如图1.2所示。
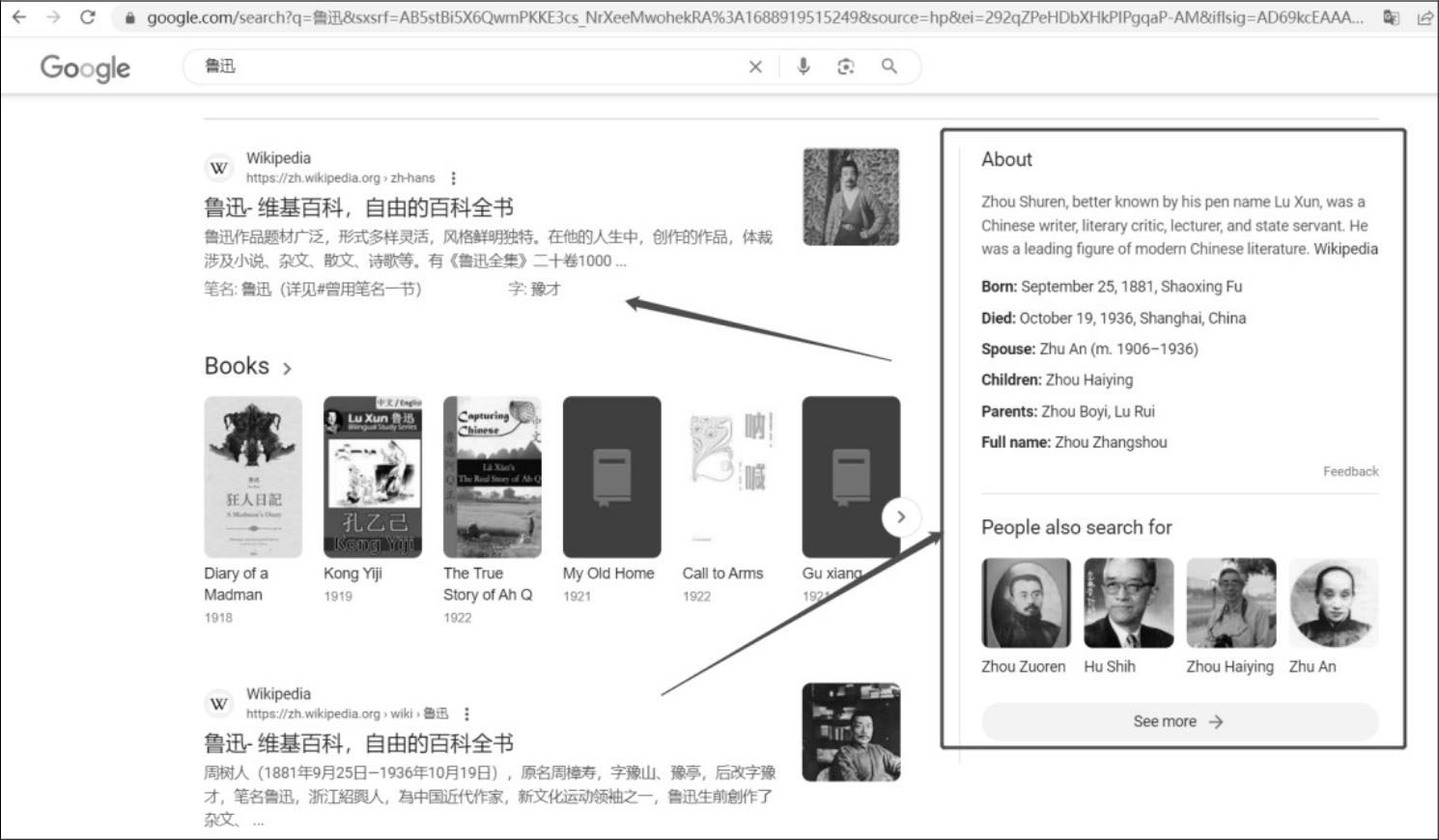
图1.1 谷歌搜索“鲁迅”的结果
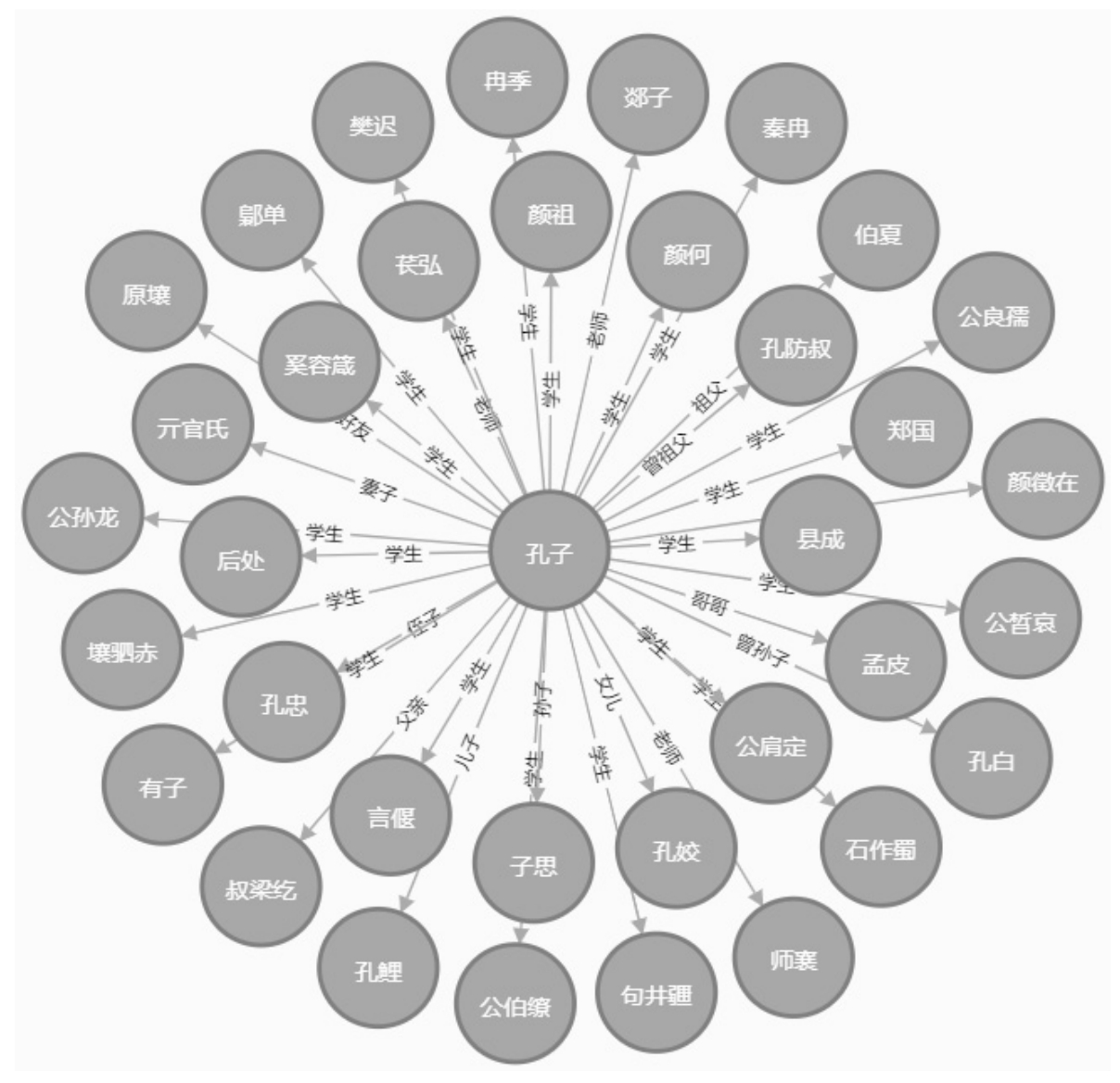
图1.2 知识图谱中的数据节点:“孔子”示例
通过上面的例子我们会有一个大致的认识,那什么是知识图谱?我们分两个方面来看,即知识(knowledge)与图(graph)。什么是知识?知识是人类文明发展以来人类对客观世界探索的结果,如俄罗斯科学家德米特里·伊万诺维奇·门捷列夫发表归纳的元素周期表,或是被我们所熟知的爱因斯坦提出的狭义相对论中的 e = mc 2 公式。知识作为人类对客观世界认识的表达,具备一定的局限性。针对地球的形状,人类文明的不同时期就有着不同的解释,随着人类科技的发展,才确定了地球是一个两极稍扁、赤道略鼓的不规则球体。知识的形成伴随着推理、归纳、实践,当然,在知识的形成中往往也伴随着大量的冲突和辩证。
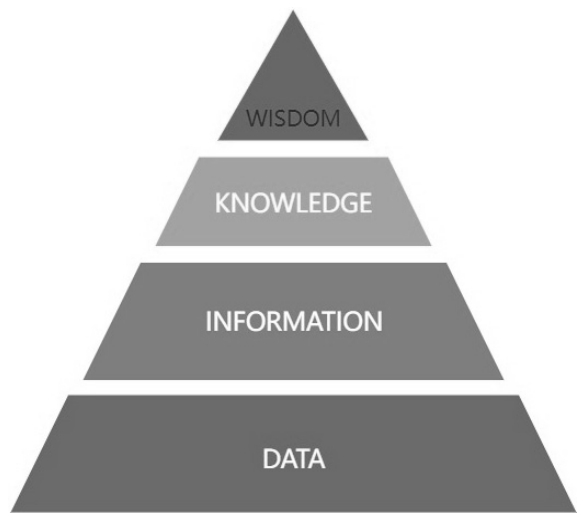
图1.3 DIKW体系示意图
图1.3为DIKW体系,即关于数据、信息、知识及智慧的体系,可以很直观地看出从数据获取到智慧形成的层级关系和流程。该体系可以追溯至托马斯·斯特尔那斯·艾略特所写的诗——《岩石》。在首段,他写道:“我们在哪里丢失了知识中的智慧?又在哪里丢失了信息中的知识?”(Where is the wisdom we have lost in knowledge?/Where is the knowledge we have lost in information?)
上面介绍了知识的概念,下面进一步对图进行阐释,在计算机课程中,图是一种比较松散的数据结构,图往往用来表示和存储具备“多对多的关系”,是一种很重要的数据结构。它有一些节点,节点与节点之间也会存在着联系,一张图往往由一些节点和连接节点的边组成。例如,计算机网络就是由许多节点(例如计算机)和节点之间的边(如网线)构建的。城市的地铁系统也可以理解为图,地铁站可以理解为节点,北京地铁示意图如图1.4所示(图片来源为北京地铁官网https://www.bjsubway.com/)。
图1.4 北京地铁示意图
通过对上面知识和图的了解,可以知道知识图谱与此类似。图1.5是构建的一个人物图谱的片段,可以看出图上有很多节点和边,知识图谱也是由节点和边构成的。节点表示实体或概念,边表示实体的属性或实体间的关系。图1.5中“项羽”与“虞姬”是两个节点,节点的关系是“妻子”。我们将“项羽-妻子-虞姬”这种表达方式称为资源描述框架(resource description framework,RDF),简称为三元组,把实体、属性、属性值归纳为RDF,这是一种常见的表达知识图谱的方式。它属于实体属性,常见的还有实体关系。
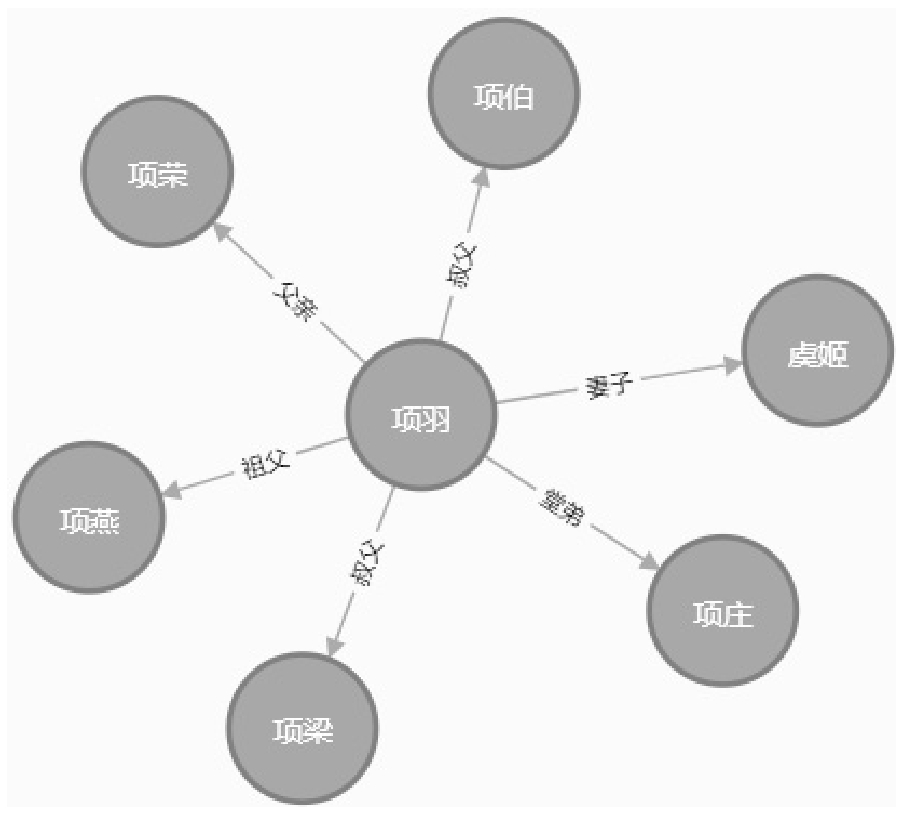
图1.5 知识图谱节点示例
知识图谱中的节点可以分为以下两种。
(1)实体:指具有可区别性且独立存在的某种事物,如一个人、一座城市、一种商品等。某个时刻、某个地点、某个数值也可以作为实体。实体是一个知识图谱中最基本的元素,每个实体可以用一个全局唯一的ID进行标识。
(2)语义类/概念:语义类指具有某种共同属性的实体的集合,如国家、民族、性别等;而概念则反映一组实体的种类或对象类型,如人物、气候、地理等。
知识图谱中的边分为以下两种。
(1)属性(值):指某个实体可能具有的特征、特性、特点以及参数,是从某个实体指向它的属性值的“边”,不同的属性对应不同的边,而属性值是实体在某一个特定属性下的值。例如,“人口”“首都”是不同的属性,“北京”是中国在“首都”这一属性下的属性值。
(2)关系:是连接不同实体的“边”,可以是因果关系、相近关系、推论关系、组成关系等。在知识图谱中,将关系形式化为一个函数。这个函数把若干个节点映射到布尔值,其取值反映实体间是否具有某种关系。
基于以上定义,可以更好地理解三元组。三元组是知识图谱中的一种基本元素,由三个部分组成:主语、谓语和宾语。主语表示一个实体,谓语表示该实体与另一个实体之间的关系,宾语则表示与主语相关的另一个实体或值。三元组用于描述实体之间的关系,是知识图谱中一种直观、简洁的通用表示方式,能够方便计算机对实体关系进行处理,也是实现语义网的基础。
对于上面三元组的构成,我们用三元组 G =( E , R , S )表示知识图谱。其中, E ={ e 1 , e 2 ,…, e E }是知识图谱中的实体集合,包含| E |种不同的实体; R ={ r 1 , r 2 ,…, r E }是知识图谱中的关系集合,共包含| R |种不同的关系; S ⊆ E × R × E 是知识图谱中的三元组集合。三元组的基本形式主要包括(实体1,关系,实体2)以及(概念属性,属性值)等。(实体1,关系,实体2)和(实体,属性,属性值)都是典型的三元组。
虽然知识图谱在2012年才因为谷歌而得名,但是知识图谱的发展历程可以追溯到上个世纪。知识图谱的发展可以从人工智能和语言网两个方向进行追溯。在人工智能方面,人类致力于利用计算机进行推理、分析、预测、决策等高级思维活动。通过运用计算机处理数据的能力并通过设计响应的算法完成机器的智能行为,实现推理、预测等任务。另一方面,随着互联网的高速发展,产生了大量的数据,对海量数据的处理伴随着日益复杂的推理、预测、决策、问题求解等任务。人类希望引入知识来处理原始数据,使其支撑推理、预测等复杂问题,语义网就是在这一背景下诞生的,知识图谱可以看作为语义网的一种简化后的商业实现。知识图谱的发展历程如图1.6所示。
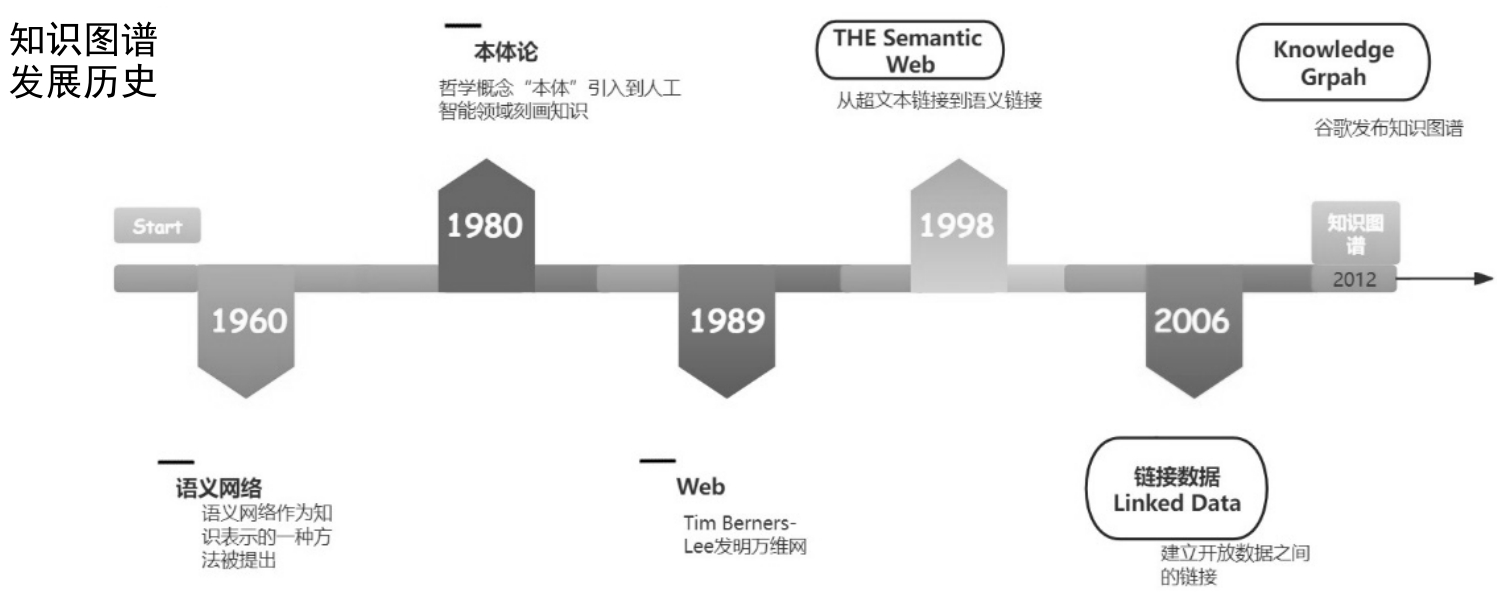
图1.6 知识图谱的发展历程
从学术的观点看,人工智能的主要学派有三家,即符号主义学派、连接主义学派和行为主义学派。在人工智能发展的早期,符号主义学派和连接主义学派贯穿着人工智能的发展,符号主义是一种基于逻辑推理的智能学习方法,又称为逻辑主义。符号派的核心在于知识的表示和推理。
符号主义学派认为人工智能源于数理逻辑。数理逻辑从19世纪末迅速发展,在20世纪30年代开始用于描述智能行为。计算机出现后,又在计算机上实现了逻辑演绎系统。其有代表性的成果为启发式程序LT逻辑理论家,证明了38条数学定理,表明了可以应用计算机研究人的思维过程,模拟人类智能活动。正是这些符号主义者,早在1956年首先采用“人工智能”这个术语。后来又发展了启发式算法→专家系统→知识工程理论与技术,并在20世纪80年代取得很大发展。符号主义曾长期一枝独秀,为人工智能的发展做出重要贡献,尤其是专家系统的成功开发与应用,为人工智能走向工程应用和实现理论联系实际具有特别重要的意义。在人工智能的其他学派出现之后,符号主义仍然是人工智能的主流派别。这个学派的代表人物有纽厄尔(Newell)、西蒙(Simon)和尼尔逊(Nilsson)等。
连接主义学派认为人工智能源于仿生学,特别是对人脑模型的研究。它的代表性成果是1943年由生理学家麦卡洛克(McCulloch)和数理逻辑学家皮茨(Pitts)创立的脑模型,即MP模型,开创了用电子装置模仿人脑结构和功能的新途径。它从神经元开始,进而研究神经网络模型和脑模型,开辟了人工智能的又一发展道路。20世纪60—70年代,连接主义,尤其是对以感知机(perceptron)为代表的脑模型的研究出现过热潮,由于受到当时的理论模型、生物原型和技术条件的限制,脑模型研究在20世纪70年代后期至80年代初期落入低潮。直到Hopfield教授在1982年和1984年发表了两篇重要论文,提出用硬件模拟神经网络,之后连接主义才又重新抬头。1986年,鲁梅尔哈特(Rumelhart)等人提出多层网络中的反向传播算法(BP)。此后,连接主义势头大振,从模型到算法,从理论分析到工程实现,为神经网络计算机走向市场打下基础。现在,对人工神经网络(ANN)的研究热情仍然较高,但研究成果没有预想的那样好。
行为主义学派认为人工智能源于控制论。控制论思想,早在20世纪40—50年代就成为时代思潮的重要部分,影响了早期的人工智能工作者。维纳(Wiener)和麦克洛克(McCulloch)等人提出的控制论和自组织系统以及钱学森等人提出的工程控制论和生物控制论,影响了许多领域。控制论把神经系统的工作原理与信息理论、控制理论、逻辑以及计算机联系起来。早期的研究工作重点是模拟人在控制过程中的智能行为和作用,如对自寻优、自适应、自镇定、自组织和自学习等控制论系统的研究,并进行“控制论动物”的研制。到20世纪60—70年代,上述这些控制论系统的研究取得一定进展,播下智能控制和智能机器人的种子,并在20世纪80年代诞生了智能控制和智能机器人系统。行为主义在20世纪末以人工智能新学派的面孔出现,一出现便引起了许多人的兴趣。这一学派的代表作者首推布鲁克斯(Brooks)的六足行走机器人被看作是新一代的“控制论动物”,是一个基于感知—动作模式模拟昆虫行为的控制系统。
专家系统是符号主义的主要成就,是人工智能领域的一个重要分支。它是一个具备大量专业知识与经验的计算机程序系统,通过知识表示和知识推理来模拟解决那些领域专家才能解决的复杂问题。专家系统通常由人机交互界面、知识库、推理机、解释器、综合数据库、知识获取6个部分构成。专家系统结构图示例如图1.7所示。
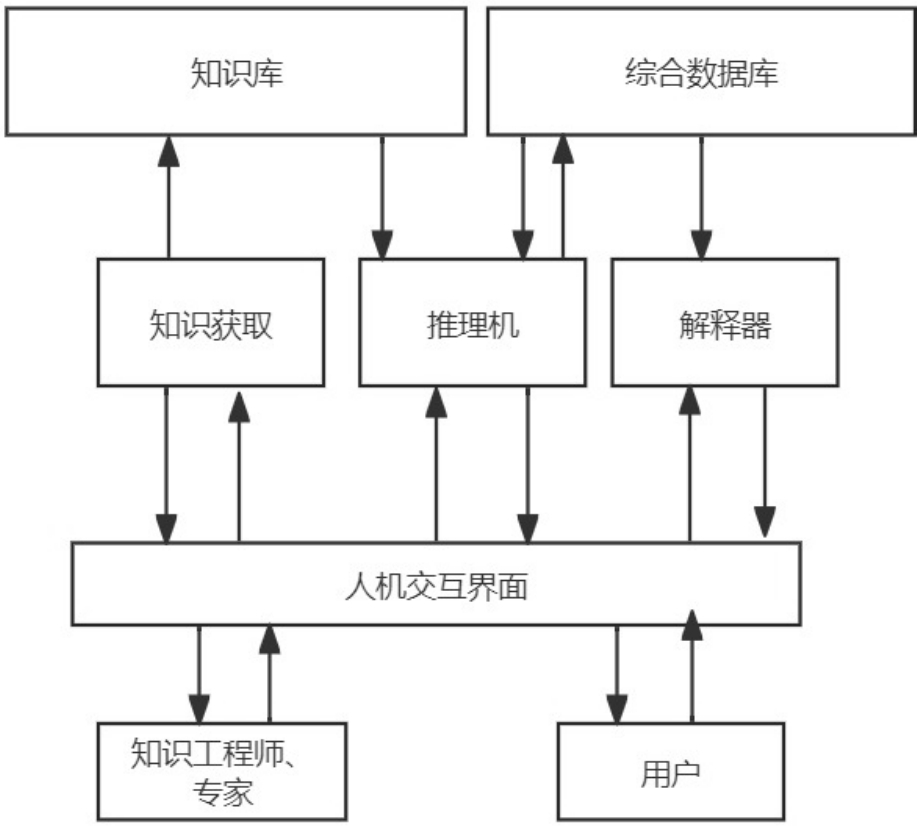
图1.7 专家系统结构图
1965年,费根鲍姆等人在总结通用问题求解系统的成功与失败经验的基础上,结合化学领域的专门知识,研制了世界上第一个专家系统DENDRAL。20世纪70年代,第二代专家系统(mycin、casnet、prospector、hearsay等)属单学科专业型、应用型系统,其体系结构较完整,移植性方面也有所改善,而且在系统的人机接口、解释机制、知识获取技术、不确定推理技术、增强专家系统的知识表示和推理方法的启发性、通用性等方面都有所改进。20世纪70年代,斯坦福大学使用LISP语言研制了MYCIN系统,用于帮助医生对住院的血液感染患者进行诊断和用抗菌素类药物进行治疗。从功能与控制结构上可分成两部分:①以患者的病史、症和化验结果等为原始数据,运用医疗专家的知识进行推理,找出导致感染的细菌。若是多种细菌,则用0~1的数字给出每种细菌的可能性。②在上述基础上,给出针对这些可能的细菌的药方。尽管MYCIN系统并没有被运用于实践中,但是研究报告显示这个系统所给出的治疗方案可接受度约为69%,比大部分使用同一参考标准给出治疗方案要好得多。20世纪80年代初到90年代初,专家系统发展迅速,商业价值被各行各业看好。20世纪80年代初,专家系统主要应用于医疗领域,主要原因是医疗专家系统属于诊断性系统且容易开发。到了20世纪80年代中后期,专家系统在商业上应用越来越广泛。第三代专家系统属多学科综合型系统,采用多种人工智能语言,综合采用各种知识表示方法和多种推理机制及控制策略,并开始运用各种知识工程语言、骨架系统及专家系统开发工具和环境来研制大型综合专家系统。专家系统时代最成功的案例是DEC的专家配置系统XCON。当客户订购DEC的VAX系列计算机时,XCON可以按照需求自动配置零部件。从1980年投入使用到1986年,XCON一共处理了8万个订单 [2] 。
专家系统经过数十年的研究和实践,尽管已经在很多领域具备了AI所拥有的能力,但其知识获取能力仍然存在瓶颈且无法自我学习。随着包括日本第五代计算机计划在内的许多超前概念失败后,人们开始质疑专家系统。一方面,与专家系统一脉相传的这一派自身的逻辑功力不够,他们和定理证明派发生分歧;另一方面,他们的工程实践又略显欠缺。专家系统风口过后,他们变成了暗流,直到万维网支持者之一蒂姆·伯纳斯·李(Tim Berners-Lee)提出了“语义网”(Semantic Web),也就是知识图谱的前身。蒂姆·伯纳斯·李以便捷的HTTP协议和超文本链接标准HTML而闻名,被各种媒体称为万维网的发明人。
“语义网”是以资源描述框架(W3C标准RDF)、OWL(Web ontology language,网络本体语言)和SPARQL为核心,研究知识本体、关联数据和知识图谱的基础和应用的领域。语义网的设计可以理解为使计算机更好地解读万维网。
着手构建一个更“语义的”万维网有多种方式。一种方式是构建一个“巨型Google”,依赖“数据不可思议的效力”来发现诸如词语之间、术语和情境之间的正确关联。我们在过去几年中已经见证了搜索引擎性能的停滞,这似乎暗示了此种方式存在缺陷——没有一个搜索巨头能够超越仅返回分散页面的简单扁平列表的情况。
语义网(近年来被逐渐熟知的数据万维网)遵循了不同的设计原则,可以概括如下。
(1)使结构化和半结构化的数据以标准化的格式在万维网上可用。
(2)不仅制造数据集,还创建万维网上可解读的个体数据元素及其关系。
(3)使用形式化模型来描述这些数据的隐含语义,使这些隐含语义能够被机器处理。
设计原则体现在语义网中的技术如下。
(1)使用带标签的图(labeled graph)作为对象及其关系的数据模型,图中将对象作为节点,对象间的关系表示为边。使用被草草命名为资源描述框架的形式化模型来表示这种图结构。
(2)使用万维网标识符——统一资源标识符(uniform resource identifier,URI)来标识出现在数据集中的单个数据项以及它们之间的关系。这同样反映在RDF的设计中。
(3)使用本体(ontology,简言之:类型和关系的层次化词汇表)作为数据模型来形式化地表达数据的隐含语义。诸如RDF模式(RDF schema)和网络本体语言的形式化模型来描述这些数据的隐含语义,使得这些隐含语义能够被机器处理,同样也使用URI来表示类型和它们的属性。 [3]
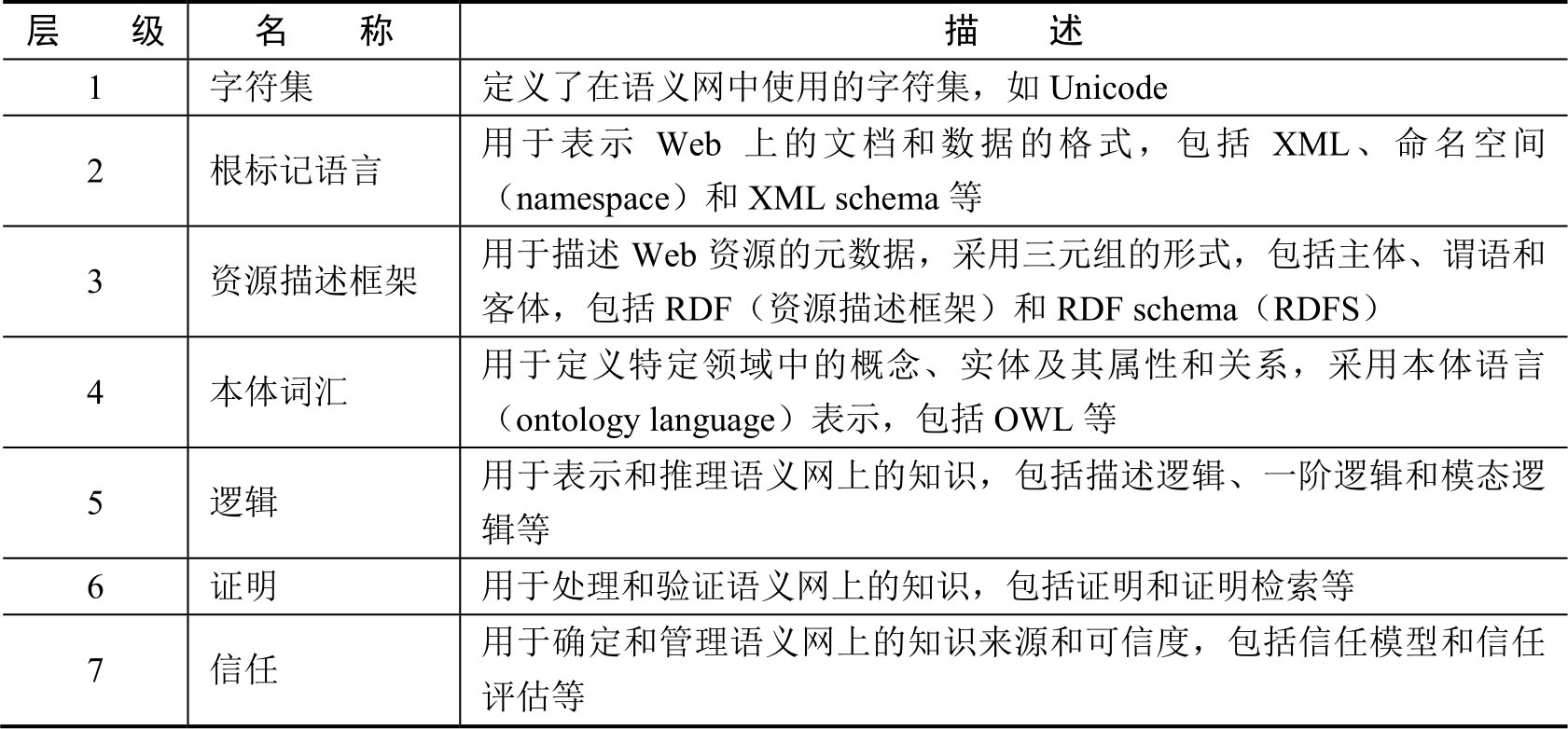
2000年,蒂姆·伯纳斯·李为未来的Web发展提出了语义网的体系结构,其各层表达式的描述如表1.1所示。在语义网模型中,第2、3、4层是语义Web的关键层,用于表示Web信息的语义,也是现在语义Web研究的热点所在。其中XML(eXtensible markup language,可扩展标记语言)层作为语法层,RDF层作为数据层,本体层作为语义层。
表1.1 语义网模型
XML不仅提供对资源内容的表示,还提供资源所具有的结构信息。但仅有XML是不够的。XML页面上还包含大量其他信息,如图像、音频和其他说明性文字等,这些信息难以被智能软件代理处理。需要对所描述对象结构和内容进行规范说明,提供描述XML的元数据。RDF是W3C推荐的用于描述和处理元数据的方案,能为Web上应用程序间的交互提供机器能处理的信息,是处理元数据的基础。XML和RDF都能为所描述的资源提供一定的语义,同时XML标签集和RDF属性集不存在限制 [4] 。
语义网体系结构 [5] 由以下7层组成。
 字符集层:该层使用Unicode作为数据格式,可以表示世界上所有主要语言的字符,并通过URI为资源提供唯一的标识符。Unicode的使用确保了多语言的支持和跨语言的检索能力。
字符集层:该层使用Unicode作为数据格式,可以表示世界上所有主要语言的字符,并通过URI为资源提供唯一的标识符。Unicode的使用确保了多语言的支持和跨语言的检索能力。
根标记语言层:在这一层,使用XML作为标记语言。XML具有灵活的结构和易用性,允许用户自定义文档结构,并通过命名空间避免不同应用之间的命名冲突。此外,XML schema用于定义和验证数据的结构,提供了更多的数据类型和校验机制。
资源描述框架层:RDF是用于表示网络上互连数据的通用框架,用于描述网络上的信息资源。RDF采用三元组(主体-谓词-客体)的形式表示知识,使信息具有机器可理解性。此外,RDFS提供了一种词汇定义语言,用于定义资源之间的关系和属性,进一步丰富了资源描述的语义。
本体词汇层:在这一层,通过使用专门的本体语言(如OWL)定义概念、关系和约束等。本体词汇层提供了更高层次的语义描述,允许用户建立领域特定的知识模型,并进行推理和推断。
逻辑层:逻辑层为语义网提供了推理和推断的能力。通过采用逻辑语言(如规则语言)和推理机制,可以从已知的事实中推导出新的知识,填补信息的缺失并发现隐藏的关联。
证明层:在这一层,使用Proof交换和数字签名技术建立信任关系并验证数据的可靠性。通过证明的交换和验证过程,可以确保数据的真实性和完整性。
信任层:信任层用于评估和确定语义网中资源和信息的可信度。它可以基于证明层提供的证据和其他信任度评估机制,为用户提供对语义网数据和服务的信任度评估,并根据信任度做出决策和使用资源。
实际上,知识图谱在谷歌正式提出知识图谱的前几年就已经有了雏形,Metaweb公司将现实世界中各种实体数据信息存储于系统中,并在数据之间建立关联关系,从而发展出区别于传统关键词搜索的技术。谷歌为了改善其搜索服务于2010年收购了Metaweb。Metaweb的标签数据数据库将有助于让谷歌搜索变得更智能。
Metaweb为Web开发了语义存储基础设施和Freebase,是一个类似维基百科的创作共享类网站,于2007年3月发布。Freebase是一个巨大的,合作编辑的交联(cross-linked)数据知识库,由大量三元组组成。其背后的想法是为语义网建造一个像维基百科系统的产品。Freebase允许任何人提供、组织、查询、复制及利用其数据。这听起来很像维基百科,但是不同于维基百科按作品安排结构,Freebase的结构更像一个人和软件均能读取的数据库。Metaweb已经使用多种技术构建了一个高质量的知识图谱,包括爬取和解析维基百科。所有这些都是由其内部构建的一个图数据库驱动的,这个数据库叫作Graphd,是一个图守护程序(现在已经发布在GitHub上)。Graphd具有一些非常典型的属性,像一般守护进程一样,它在一台服务器上运行,所有数据都放在内存中。整个Freebase网站都基于Graphd。收购完成后,谷歌面临的挑战之一是继续运行Freebase。2012年5月16日,谷歌在Freebase的基础上提出了谷歌知识图谱。截至2012年发布时间,其语义网络包含超过5亿个对象,超过35亿个关于这些不同对象的事实和关系,这些不同的对象之间存在的链接关系用来理解搜索关键词的含义。
知识图谱从三个主要方面增强了Google搜索:(1)找到正确的内容。(2)获得最佳摘要。(3)更深入、更广泛。
谷歌在商品硬件和分布式软件上建立了一个帝国。单个服务器数据库永远无法容纳搜索的爬网、索引和服务。谷歌先是创建了SSTable,然后提出了Bigtable的概念,Bigtable可以横向扩展到数百或数千台服务器,协同运行PB级的数据。谷歌还构建了Borg(K8s的前驱)分配机器,使用Stubby(gRPC的前驱)进行通信,通过Borg的名称服务解析IP地址(BNS,K8s组件之一),数据存储在Google的分布式架构文件系统GFS上(Hadoop FS)。分布式策略有效地避免了系统因为机器崩溃而不稳定的情况。由于Graphd是单机式,无法满足谷歌的需求,特别是Graphd需要消耗大量的内存,于是,如何替换Graphd且以分布式方式工作的想法被提出。一个被命名为Dgraph的真正的图数据库服务系统,不仅可以取代Graphd for Freebase,还可以为将来的所有知识图谱工作服务。Dgraph是一个分布式的图数据库服务系统,Dgraph是一个升级版的Graphd。 [6]
早期的知识图谱一般指Google为了增强其搜索能力所建立的知识库,现在的知识图谱泛指各种各样的知识库。
知识图谱按照功能和应用场景可以分为通用知识图谱和领域知识图谱。其中通用知识图谱面向的是通用领域,强调知识的广度,形态通常为结构化的百科知识,针对的使用者主要为普通用户;领域知识图谱则面向某一特定领域,强调知识的深度,通常需要基于该行业的数据库进行构建,针对的使用者为行业内的从业人员以及潜在的业内人士等。
通用知识图谱和领域知识图谱主要会在知识获取、知识构建和知识应用这几个方面存在明显的差异。通用知识图谱以常识性知识为主,来源广泛,构建过程成熟,应用受众广泛,面向大众。领域知识图谱使用专业领域知识突出知识深度,构建流程尚不成熟,知识获取难以自动化,要求质量,应用受众为相关专业人员。通用知识图谱和领域知识图谱的差异点主要如下。
通用知识图谱的知识获取主要依赖于互联网上的大规模文本数据、百科全书、维基百科等广泛的信息源。通过自动化的知识抽取和知识融合技术,可以从海量的非结构化数据中提取出常识性知识。
领域知识图谱的知识获取相对更具挑战性。它需要依赖于专业领域的文献、专家知识、行业数据库等有限的信息源。由于专业领域的知识通常以非结构化或半结构化的形式存在,知识的提取和整合过程需要更多的人工干预和专业领域的理解。
通用知识图谱的构建过程相对成熟,有较多的自动化技术支持。它可以通过大规模的数据挖掘、实体链接、关系抽取等方法,将抽取到的知识组织成结构化的图谱形式。
领域知识图谱的构建过程相对更复杂和耗时,需要依赖于领域专家的知识输入和人工标注。知识的组织和建模需要深入理解领域的概念、关系和规则,以确保图谱的准确性和完整性。
通用知识图谱的应用面向大众用户,可以用于智能搜索、问答系统、信息推荐等多个领域。它可以为用户提供常识性的知识支持,帮助用户更快地获取所需的信息。
领域知识图谱的应用主要面向相关专业人员,如医生、金融分析师、工程师等。它可以提供专业领域内的深度知识、辅助决策和解决领域特定的问题。领域知识图谱的应用也更加依赖于领域专家的指导和解释。
Google提出的知识图谱就是通用知识图谱,强调广度,面向全领域,主要是应用于面向互联网的搜索、推荐、问答等业务场景。通用知识图谱大体可以分为百科知识图谱(encyclopedia knowledge graph)和常识知识图谱(common sense knowledge graph)。
2001年,全球性多语言百科全书——维基百科的协作计划开启,其宗旨是为全人类提供自由的百科全书,它在短短几年的时间里利用全球用户的协作完成了数十万词条(至今拥有上百万词条)知识。维基百科的出现推动了很多基于维基百科的结构化知识的知识库的构建,DBpedia、YAGO等都属于这一类知识库。
DBpedia始于2007年的早期语义网项目,该项目最初由莱比锡大学和柏林自由大学的学者在OpenLink的支持下启动。DBpedia从维基百科中提取包括摘要、标签、类别等信息构建大规模知识库,另外,本体(即知识库的元数据、schema)的构建是通过社区成员合作完成的。2022年3月发布的DBpedia快照包含超过8.5亿个事实(3倍)。快照统计2022年的快照版本提供了从762万个实体到179个外部资源的超过1.306亿条链接。当前的快照版本总共使用了55000个属性,其中1377个属性由DBpedia本体定义。维基百科中的知识不断快速增长。我们使用DBpedia Ontology Classes来衡量增长:此版本中的总数(在括号中,我们给出①与上一版本相比增长,可能暂时为负;②与Snapshot 2016年10月相比增长)如下。
人:1792308(1.01%,1.13%)。
地方:748372(1.00%,1820.86%),包括但不限于590481(1.00%,5518.51%)人口稠密的地方。
作品:610589(1.00%,619.89%)。包括但不限于:
157566(1.00%,1.38%)音乐专辑;
144415(1.01%,15.94%)电影;
24829(1.01%,12.53%)电子游戏。
机构:345523(1.01%,109.31%)。包括但不限于:
87621(1.01%,2.25%)公司;
64507(1.00%,64507.00%)教育机构。
物种:1933436(1.01%,322239.33%)。
植物:7718(0.82%,1.71%)。
疾病:10591(1.00%,8.54%)。
图1.8所示为DBpedia系统的person类实体数量变化示例,图1.9所示为DBpedia系统的系统架构图。图1.8和图1.9均来自DBpedia系统官网。
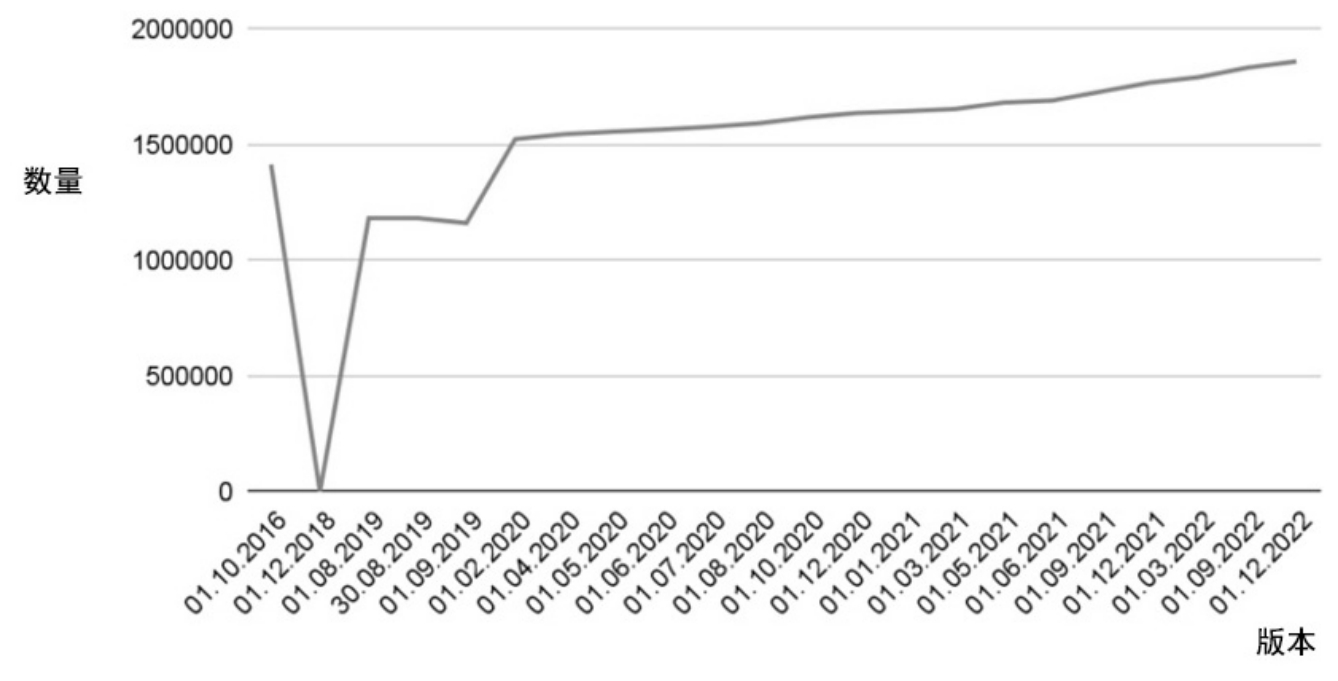
图1.8 DBpedia系统的person类的实体数量变化
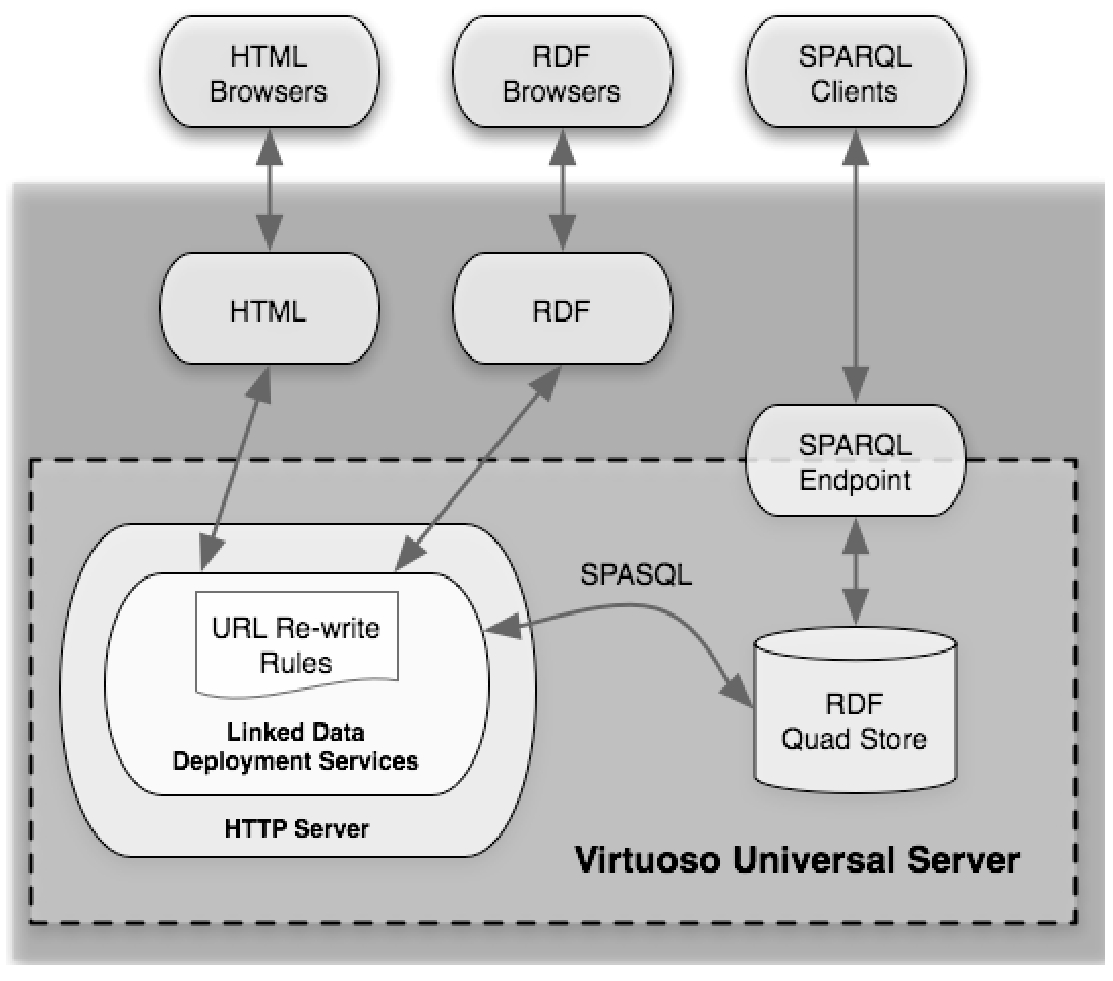
图1.9 DBpedia系统的架构图
YAGO由德国马普研究所于2007年研制,YAGO是一个知识库,即一个包含现实世界知识的数据库,官网为https://yago-knowledge.org/。YAGO既包含实体(如电影、人物、城市、国家等),也包含这些实体之间的关系(谁在哪部电影中演过什么角色,哪个城市位于哪个国家等)。YAGO包含超过5000万个实体和20亿个事实。YAGO存储在标准资源描述框架RDF中。这意味着YAGO是一组事实,每个事实都由一个主语、一个谓词(也称为“关系”或“属性”)和一个宾语组成。
Freebase是Google Knowledge Graph的早期版本,由Metaweb公司在2005年建立,2010年被谷歌收购。谷歌于2016年关闭了Freebase,并把Freebase数据转移到Wikidata。Freebase数据集总共的三元组数量为19亿,gzip压缩后的数据量为22 GB,解压后达250 GB。
Wikidata(维基数据)是维基媒体基金会主持的一个自由的协作式多语言知识库,旨在为维基百科、维基共享资源以及其他的维基媒体项目提供支持。每个实体都有一个唯一的数字标识。截至2022年5月,Wikidata有超过9000万个实体。用户可以在官网下载Wikidata的数据快照,这些数据快照可以用于各种数据分析,包括关系抽取。
Microsoft Concept Graph是微软研究院基于微软先前成立的Probase项目构建的。Probase中的知识来自数十亿个网页和多年的搜索日志,截至2022年5月,该项目有超过540万个概念。
XLORE是一个大型中英文知识图谱,是清华实验室的一个知识库项目,截至2022年5月15日,XLORE已包含26146618个实例,2351701个概念,510404个属性以及丰富的语义关系。
OpenKG是中国中文信息学会语言与知识计算专业委员会于2015年发起和倡导的开放知识图谱社区联盟项目。旨在推动以中文为基础的知识图谱数据的开放、互联与众包,以及知识图谱算法、工具和平台的开源开放工作。OpenKG设立常设工作组和管理委员会,总体协调开展工作,由来自浙江大学、东南大学、同济大学等多个单位的知识图谱专业团队联合提供持久性技术支持和日常管理运营。
CN-DBpedia是由复旦大学知识工场实验室研发并维护的大规模通用领域结构化百科。CN-DBpedia主要从中文百科类网站(如百度百科、互动百科、中文维基百科等)的纯文本页面中提取信息,经过滤、融合、推断等操作后,最终形成高质量的结构化数据,供机器和人使用。CN-DBpedia自2015年12月发布以来已经在问答机器人、智能玩具、智慧医疗、智慧软件等领域产生数亿次API调用。CN-DBpedia提供全套API,并且免费开放使用。对于大规模商务调用,提供由IBM、华为支持的专业且稳定的服务接口。截至2020年5月16日,CN-DBpedia百科实体数为16994589,CN-DBpedia百科关系数为223810811,平台的API调用次数为1359840516。
在领域图谱构建方面,由于通用知识图谱的知识来源于多种结构的数据,其可看成一个面向通用领域的“结构化的百科知识库”,而领域知识图谱又称为行业知识图谱或垂直知识图谱,面向某一特定领域。领域知识图谱基于行业数据构建,通常有严格而丰富的数据模式,对知识的深度、准确性要求较高,亟须解决增强领域知识的表示能力、对领域实体进行识别和关系抽取、隐性关系发现等关键问题。
领域知识图谱的应用研究主要有智能搜索及问答、辅助决策及个性化推荐等方面。
(1)智能搜索及问答:领域知识图谱可以用于构建智能搜索引擎和问答系统,通过将结构化的领域知识与自然语言处理技术相结合,实现更准确、高效的信息检索和问题回答。例如,在电商领域,通过构建电商知识图谱,可以提供更精准的商品搜索结果和个性化的推荐。
(2)辅助决策:领域知识图谱可以为决策者提供实时、全面的领域知识支持,帮助他们做出更准确、科学的决策。在金融领域,知识图谱可以用于风险评估和预测,提供对市场、行业和企业的深度分析,辅助投资决策。
(3)个性化推荐:领域知识图谱可以帮助构建个性化推荐系统,根据用户的兴趣和需求,提供个性化的推荐内容。在电影、音乐、新闻等领域,通过分析用户的偏好和行为,结合领域知识图谱中的相关信息,可以实现更精准的个性化推荐。
领域知识图谱已经在医疗、电商、金融、军工、电力、教育、公安等多个领域开展应用。例如,在金融领域的信用评估、风险控制、反欺诈方面的应用,以及在医疗领域的智能问诊等应用。以下是对几个领域的应用的进一步扩展。
(1)电商领域:领域知识图谱可以用于构建电商平台的智能推荐系统,根据用户的购买历史、浏览行为和个人喜好,提供个性化的商品推荐。同时,知识图谱还可以整合商品属性、品牌关系、用户评价等信息,提供更准确的商品搜索和对比功能。
(2)金融领域:领域知识图谱在金融领域的应用非常广泛。它可以整合金融市场数据、企业财务信息、行业报告等多种数据源,帮助金融机构进行风险评估、信用评级和投资决策。知识图谱可以建立企业之间的关联关系、资金流向等信息,帮助发现潜在的风险和机会。
(3)医疗领域:领域知识图谱在医疗领域的应用非常重要。它可以整合医学文献、疾病数据库、临床指南等多源数据,帮助医生进行疾病诊断、治疗方案选择和患者管理。知识图谱还可以建立疾病与症状、药物与治疗方法之间的关联关系,支持智能问诊系统和个性化医疗服务。
(4)教育领域:领域知识图谱可以应用于教育领域的个性化学习和教育资源推荐。通过分析学生的学习兴趣、学习历史和学习行为,知识图谱可以推荐适合学生的学习材料、课程和教学方法。同时,它还可以帮助教师了解学生的知识点掌握情况,进行针对性的教学辅导。
(5)公安领域:领域知识图谱在公安领域可以用于犯罪分析、情报挖掘和预防。通过整合犯罪数据、嫌疑人关系、案件线索等信息,知识图谱可以帮助警方发现潜在的犯罪模式和犯罪网络,辅助侦破案件和预测犯罪趋势。
AliOpenKG开放的数字商业知识图谱(阿里巴巴)是一款商业知识图谱。截至2022年5月22日,AliOpenKG有超过193万个本体三元组,超过18亿个实体关系,一百多万条概念知识。通过建立一套基于消费者需求场景的知识图谱表示体系来组织商品,并把商业要素知识沉淀到图谱中,以解决业务痛点。
[1]SINGHAL A. Introducing the knowledge graph: things, not strings[EB/OL]. (2012-05-06)[2023-10-5]. https://blog.google/products/search/introducing-knowledge-graph-things-not/.
[2]尼克.人工智能简史著[M].北京:人民邮电出版社,2017.
[3]安东尼乌.语义网基础教程:3版[M].胡伟,程龚,黄智生,译.北京:机械工业出版社,2014.
[4]李洁,丁颖.语义网关键技术概述[J].计算机工程与设计,2007(8):1831-1836.
[5]刘清堂,黄景修,吴林静,等.基于语义网的教育应用研究现状分析[J].现代远距离教育,2015(1):60-65.
[6]JAIN M R. Why Google needed a graph serving system[EB/OL]. (2019-02-13) [2023-10-5]. https://dgraph.io/blog/post/why-google-needed-graph-serving-system/.