
下载掌阅APP,畅读海量书库
立即打开



在尝试学习汇编语言的过程中,许多初学者会在学习二进制和十六进制数制系统时遇到困难。虽然二进制数字、十六进制数字与通常所用的数字之间的确存在一些差异,但它们的优点远远大于缺点。因此,理解二进制和十六进制数制系统非常重要,它们可以简化对许多其他主题的讨论,包括位运算、有符号数字的表示、字符代码和打包数据主题。
本章讨论几个重要概念,具体包括以下内容:
●二进制和十六进制数制系统
●二进制数据的组织形式(位、半字节、字节、字和双字)
●有符号和无符号数制系统
●二进制值的算术、逻辑、移位和循环移位运算
●位字段和打包数据
●浮点数和二进制代码的十进制格式
●字符数据
以上内容都是基本知识,学习本书其余的章节内容离不开读者对这些概念的理解。如果读者已经从其他课程或者研究中熟悉了这些术语,那么至少应该在进入下一章之前浏览一下这些知识。如果读者对本章的知识并不熟悉,或者只是一知半解,那么应在继续之前仔细学习本章内容。本章的所有内容都很重要!请千万不要跳过任何一个知识点。
大多数现代计算机系统都不使用十进制(以10为基数),而是通常采用二进制或者二进制补码(two's complement)的数制系统。
长期以来,人们一直使用十进制数制系统,因此可能会想当然地认为所有数字都是十进制数。现在,当看到像123这样的数字时,不要去考虑数值123,而是在大脑中考虑它总共代表多少项。实际上数字123在十进制数制系统中的表示如下:
(1×10 2 )+(2×10 1 )+(3×10 0 )
或者
100+20+3
在十进制的位置数制系统中,小数点左侧的每一位数字都代表一个数值,它们是0~9之间的数字乘以10的递增次方幂;小数点右侧的每一位数字也都代表一个数值,它们是0~9之间的数字乘以10的递增负次方幂。例如,123.456可以表示为:
(1×10 2 )+(2×10 1 )+(3×10 0 )+(4×10 -1 )+(5×10 -2 )+(6×10 -3 )
或者
100+20+3+0.4+0.05+0.006
在大多数现代的计算机系统中都采用二进制逻辑进行运算。计算机使用两个电平(通常是0V和+2.4~5V)表示数值,这两个电平正好可以表示两个不同的数值。这两个数值可以是任意两个不同的数值,但通常表示二进制数制系统中的两个数值0和1。
二进制数制系统与十进制数制系统的原理类似,不同之处在于二进制数制系统中仅存在0和1(而不是0~9),并且使用的是2的幂(而不是10的幂)。因此,将二进制数字转换为十进制数字非常容易。对于二进制字符串中的每个1,都要乘上2 n ,其中 n 是从0开始计数的1所在的位置。例如,二进制数11001010 2 可以表示为:
(1×2 7 )+(1×2 6 )+(0×2 5 )+(0×2 4 )+(1×2 3 )+(0×2 2 )+(1×2 1 )+(0×2 0 )
=128 10 +64 10 +8 10 +2 10
=202 10
总而言之,首先必须找到所有2的幂,然后将这些幂相加,结果就等于十进制数字。
将十进制数字转换为二进制数字要稍微复杂一些,一种简单方法是“偶/奇—除2”(even/odd—divide-by-two)算法。该算法使用以下的步骤。
(1)如果数字为偶数,则得到一个0。如果数字为奇数,则得到一个1。
(2)将数字除以2,并舍弃小数部分或余数。
(3)如果商为0,则算法完成。
(4)如果商不是0并且是奇数,则在当前二进制串前插入1;如果数字为偶数,则在当前二进制串前面加0。
(5)返回到步骤(2),并重复操作步骤。
虽然在高级计算机程序设计语言中,二进制数不太重要,但它们在汇编语言程序中随处可见。所以读者必须熟悉二进制数。
从最纯粹的意义上讲,每个二进制数都可以包含无限多位的数字,或者称为二进制位(bit,简称位,是binary digit的缩写)。例如,我们可以使用以下任意一种方式来表示数字5:
101 00000101 0000000000101 … 000000000000101
二进制数之前可以包含任意数量的前导0,而不改变其值的大小。由于x86-64通常使用8位的组,所以我们将使用前导0把所有二进制数扩展到4或者8的倍数位。按照这个约定,我们将5表示为01012或000001012。
对于较大的二进制数,为了增加其可读性,我们将每4位分为一组,组之间使用下划线分隔。例如,我们将1010111110110010写成1010_1111_1011_0010的形式。
注意: MASM不允许在二进制数的中间插入下划线。在较大数内部使用下划线分隔只是本书为便于阅读而采用的约定。
我们将按如下方式对每个二进制位进行编号。
(1)二进制数中最右边的位编号为第0位。
(2)从右向左的每一个二进制位连续编号。
一个8位的二进制数使用第0位~第7位的位置编号:
X 7 X 6 X 5 X 4 X 3 X 2 X 1 X 0
一个16位的二进制数使用第0位~第15位的位置编号:
X 15 X 14 X 13 X 12 X 11 X 10 X 9 X 8 X 7 X 6 X 5 X 4 X 3 X 2 X 1 X 0
一个32位的二进制数使用第0位~第31位的位置编号,依此类推。
第0位称为低阶(low-order,LO)位,有些人将其称为最低有效位(least signifcant bit)。最左边的位称为高阶(high-order,HO)位,或者称为最高有效位(most signifcant bit)。我们将通过中间位各自的位置编号来引用这些位。
在MASM中,可以将二进制数指定为以字符b结尾的0或1串。请记住,MASM不允许在二进制数中使用下划线。
不好的是,二进制数非常冗长。例如,202 10 需要8个二进制位来表示,但只需要3个十进制位就可以表示。当处理较大的数时,使用二进制表示很快就会变得非常不适用。然而,计算机是采用二进制进行“思考”的,所以大多数时候使用二进制编码系统会非常方便。虽然我们可以在十进制表示和二进制表示之间进行转换,但这种转换并不是一项简单的任务。
十六进制(基数为16)数制系统解决了二进制系统中固有的许多问题:十六进制数非常紧凑,且向二进制数的转换非常简单,反之亦然。因此,大多数计算机系统工程师使用十六进制数制系统。
十六进制数的基数是16,用十六进制小数点左边的每个位乘以16的递增整数次幂就得到了对应的十进制数。例如,1234 16 等于:
(1×16 3 )+(2×16 2 )+(3×16 1 )+(4×16 0 )
或者
4096+512+48+4=4660 10
每个十六进制位分别对应0~15 10 之间16个数字中的某一个。因为只有10个十进制位,所以我们需要增加六个额外的数字来表示10 10 ~15 10 对应的十六进制位。我们没有为这些数字创建新符号,而是分别使用字母A~F来表示。有效的十六进制数示例如下所示:
1234 16 DEAD 16 BEEF 16 0AFB 16 F001 16 D8B4 16
由于我们经常需要向计算机系统中输入十六进制数,而在大多数计算机系统中,我们不能使用下标来表示相关值的基数,因此需要采用一种不同的机制来表示十六进制数。我们将采用以下MASM约定。
(1)所有十六进制数均以数字字符开头,后缀为h。例如,123A4h和0DEADh。
(2)所有二进制数以b为后缀。例如,10010b。
(3)十进制数没有任何后缀字符。
(4)如果从上下文中可以很清楚地判别出基数,本书可能会省略后缀字符h或者b。
以下是一些使用MASM表示法的有效十六进制数示例:
1234h 0DEADh 0BEEFh 0AFBh 0F001h 0D8B4h
正如所见,十六进制数非常紧凑,并且可读性较好。此外,我们还可以轻松地在十六进制数和二进制数之间进行转换。表2-1提供了将十六进制数转换为二进制数所需的信息,反之亦然。
表 2-1 二进制与十六进制之间的转换
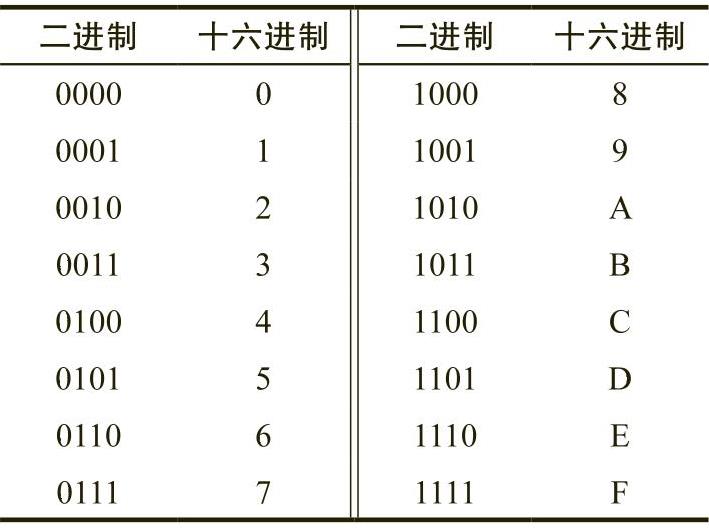
为了将十六进制数转换为二进制数,只需要将数中的每个十六进制数字替换为相应的4位二进制数字。例如,对于0ABCDh,可以根据表2-1对其中每个十六进制数字进行转换,如下所示:

将二进制数转换为十六进制数的方法也非常简单,以下为转换步骤。
(1)使用前导0填充二进制数,以确保该二进制数的位数是4的倍数。例如,给定二进制数1011001010,在该数字的左侧添加2位0,使其包含12位,即001011001010。
(2)将二进制数分成若干组,每组包含4位,例如,0010_1100_1010。
(3)在表2-1中查找这些组,并替换成对应的十六进制数字,因此得到2CAh。
这与十进制数和二进制数之间的转换(或者十进制数和十六进制数之间的转换)复杂度形成了鲜明的对比!
因为十六进制数和二进制数之间的转换是一个需要反复执行的操作,所以建议读者花点时间牢记其转换表(表2-1)。即使可以使用计算器进行转换,我们也会发现,在进行二进制数与十六进制数之间的转换时,手工转换会更快速,也更便捷。
人们常常混淆了数字及其表示的概念。刚刚开始学习汇编语言的学生通常会提出这样一个疑问:“在EAX寄存器中有一个二进制数,如何将其转换为EAX寄存器中的十六进制数呢?”答案是:“不需要转换。”
尽管可以提出一个强有力的论点,即内存或寄存器中的数是用二进制表示的,但最好将内存或寄存器中的值视为抽象的数字量(abstract numeric quantity)。128、80h或10000000b等符号串并不是不同的数字,它们只是同一抽象数字量的不同表示,我们称该量为一百二十八。在计算机内部,数字就是一个数字,与其表示形式无关,仅当以人类可阅读的形式输入或输出值时,才会区分该值的表示形式。
数字量可供人类阅读的形式总是字符串。为了以人类可阅读的形式打印值128,必须将其转换为三字符序列“128”,这将提供数字量的十进制表示形式。如果需要,也可以将值128转换为三字符序列“80h”。这里跟“128”表示的是一个相同的值,但我们将其转换为不同的字符序列,因为(大概)我们希望使用十六进制表示法而不是十进制表示法来查看数值。同样,如果我们希望查看数值对应的二进制表示,就必须将这个数值转换成一个包含1个1和7个0的字符串。
纯汇编语言没有通用的打印或者输出函数,可以调用打印或输出函数在控制台上将数字量显示为字符串。我们可以编写自定义的过程来处理这个显示过程(本书稍后将讨论其中的一些过程)。目前,本书中的MASM代码依赖于C标准库的printf()函数来显示数值。请阅读程序清单2-1中的程序,该程序将各种数值转换为其等价的十六进制数值。
程序清单 2-1 十进制数到十六进制数的转换程序



程序清单2-1使用了第1章中的c.cpp通用程序(以及build.bat通用批处理文件)。在命令行中,可以使用以下命令编译和运行这个程序:
C:\> build listing2-1
C:\> echo off
Assembling:listing2-1.asm
c.cpp
C:\> listing2-1
Calling Listing 2-1:
i=1,converted to hex=1
j=123,converted to hex=7b
k=456789,converted to hex=6f855
Listing 2-1 terminated
单纯从数学的角度而言,一个数的表示可以取任意多位。而从另一个角度看,计算机通常使用特定数量的位来表示数。常见的二进制位组包括:1位一组(bit,位)、4位一组(nibble,半字节)、8位一组(byte,字节)、16位一组(word,字)、32位一组(double words或者dwords,双字)、64位一组(quad words或者qwords,四字)、128位一组(octal words或者oword,八字)等。
在二进制计算机中,最小的数据单位是位。使用单个二进制位,可以表示任意两个不同的数据项。例如,0和1、真和假、对和错。但是,二进制位并不限于表示二进制数据类型,它也可以表示数值723和1245,或者表示红色和蓝色,甚至表示红色和数值3256。可以使用单个二进制位表示任意两个不同的值,但只能表示两个值。
不同的二进制位可以代表不同的对象。例如,可以使用某个二进制位表示值0和1,而用另一个二进制位表示值true和false。那么该如何区分这些二进制位所代表的对象呢?答案是无法区分。这也阐明了计算机数据结构背后的全部思想:数据代表的对象取决于我们的定义。如果使用二进制位表示布尔值,则该位(根据我们的定义)表示true或者false。当然,我们必须保持前后表述的一致性。如果在程序的某一个位置点上使用某个二进制位表示true或者false,那么在后面的代码中就不应使用该位来表示红色或者蓝色。
半字节是由4个二进制位组成的数据类型。对于半字节,最多可以表示16个不同的值,因为4个二进制位最多可以组成16种不同的字符串:
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
半字节是一种有趣的数据结构,因为二进制编码十进制(Binary-coded decimal,BCD)数
 需要4个二进制位来表示,十六进制数中的单个位也需要4个二进制位来表示。在十六进制数的情况下,0、1、2、3、4、5、6、7、8、9、A、B、C、D、E和F都使用4个二进制位来表示。BCD使用10个不同的数字(0、1、2、3、4、5、6、7、8和9),同样需要4个二进制位表示(因为采用3个二进制位只能表示8个不同的值,而采用4个二进制位表示的其他6个值在BCD表示中从未被使用)。事实上,任何16个不同的值都可以用半字节表示,只是十六进制数和BCD数是半字节表示的主要用途。
需要4个二进制位来表示,十六进制数中的单个位也需要4个二进制位来表示。在十六进制数的情况下,0、1、2、3、4、5、6、7、8、9、A、B、C、D、E和F都使用4个二进制位来表示。BCD使用10个不同的数字(0、1、2、3、4、5、6、7、8和9),同样需要4个二进制位表示(因为采用3个二进制位只能表示8个不同的值,而采用4个二进制位表示的其他6个值在BCD表示中从未被使用)。事实上,任何16个不同的值都可以用半字节表示,只是十六进制数和BCD数是半字节表示的主要用途。
毫无疑问,x86-64微处理器所使用的最重要的数据结构是字节。字节由8个二进制位组成。x86-64上的主存和I/O地址都采用字节地址。这就意味着x86-64程序可以单独访问的最小项是由8个二进制位表示的数值。为了访问任何较小的数据,我们需要读取包含该数据的字节,并屏蔽掉不需要的二进制位。字节中的二进制位通常用0~7进行编号,如图2-1所示。
第0位是最低位,第7位是最高位。我们将根据位的编号来引用数值中所有的二进制位。一个字节正好包含两个半字节(参见图2-2)。
第0位~第3位构成低阶半字节,第4位~第7位构成高阶半字节。因为一个字节正好包含两个半字节,所以一个字节需要2个十六进制数来表示。
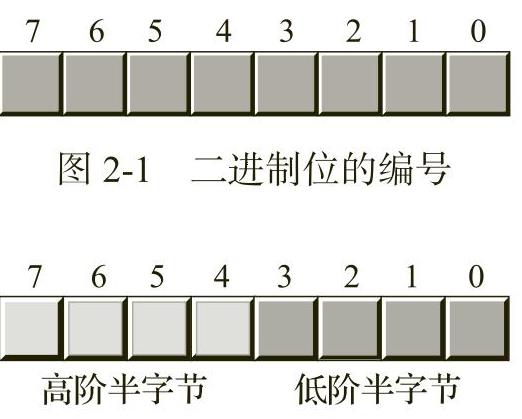
图2-2 一个字节中的两个半字节
因为一个字节包含8个二进制位,所以字节可以表示2 8 (即256)个不同的数值。通常情况下,我们将使用一个字节来表示0~255范围内的数值、-128~+127范围内的有符号数值(具体请见2.7节中的相关内容)、ASCII IBM字符代码,以及其他特殊数据类型(只要这些数据类型的取值不超过256种)。许多数据类型包含的数据项都少于256个,因此8个二进制位通常就足够了。
由于x86-64是按字节寻址的计算机,对整个字节进行操作比对单个二进制位或半字节更为有效,因此使用一个整字节来表示不需要超过256个数据项的数据类型更为有效,甚至用不了8个二进制位就足以表示数据。
对于一个字节而言,其最重要的用途在于保存字符。无论是键盘上键入的字符,还是屏幕上显示的字符,再或者是打印机上打印的字符,它们都对应一个数字值。为了与世界其他地区通信,PC通常使用ASCII字符集或者Unicode字符集的变体。ASCII字符集包含128个有定义的编码。
在MASM程序中,字节也是我们可以创建的最小变量。为了创建一个字节变量,应该使用byte数据类型,如下所示:
.data
byteVar byte?
byte数据类型是半非类型化的数据类型。与字节对象关联的唯一类型信息是字节大小(一个字节)
。可以将任意一个8位的二进制值(较小的有符号整数、较小的无符号整数、字符等)存储到字节变量中。最终由程序来控制存储在字节变量的对象类型。
字是由16个二进制位组成的数据类型。如图2-3所示,我们将一个字中的二进制位用0~15进行编号。与字节一样,第0位是低阶位。对于字而言,第15位是高阶位。当引用字中的其他位时,我们将使用其位置编号。

图2-3 字中的二进制位编号
一个字正好包含2个字节(因此,有4个半字节)。第0位~第7位构成低阶字节,第8位~第15位构成高阶字节(参见图2-4和图2-5)。

图2-4 一个字中的两个字节
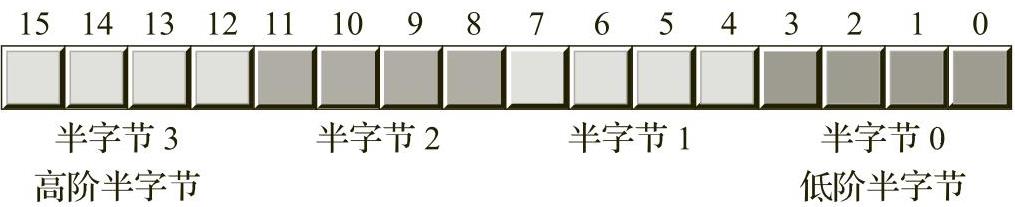
图2-5 一个字中的半字节
使用16个二进制位可以表示2 16 (即65536)个数值。这些数值可以是0~65535之间的值,也可以是通常情况下的有符号数值-32768~+32767,或者是取值不超过65536个的任何其他数据类型。
字主要用于表示“短”有符号整数值、“短”无符号整数值以及Unicode字符。无符号数值由对应于字中各个位的二进制值表示。有符号数值以二进制补码形式来表示数值(具体请参见2.8节中的相关内容)。作为Unicode字符,字最多可以表示65536个字符,允许在计算机程序中使用非罗马字符集。与ASCII一样,Unicode也是一种国际标准,允许计算机处理非罗马字符,例如汉字、希腊字母和俄语字母。
与字节一样,我们也可以在MASM程序中创建字变量。为了创建一个字变量,可以使用word数据类型,如下所示:
.data
w word ?
顾名思义,一个双字由两个字组成。因此,双字的长度为32位,如图2-6所示。

图2-6 双字中的二进制位编号
很显然,1个双字可以分为1个高阶字和1个低阶字、4个字节或者8个不同的半字节(具体请参见图2-7)。
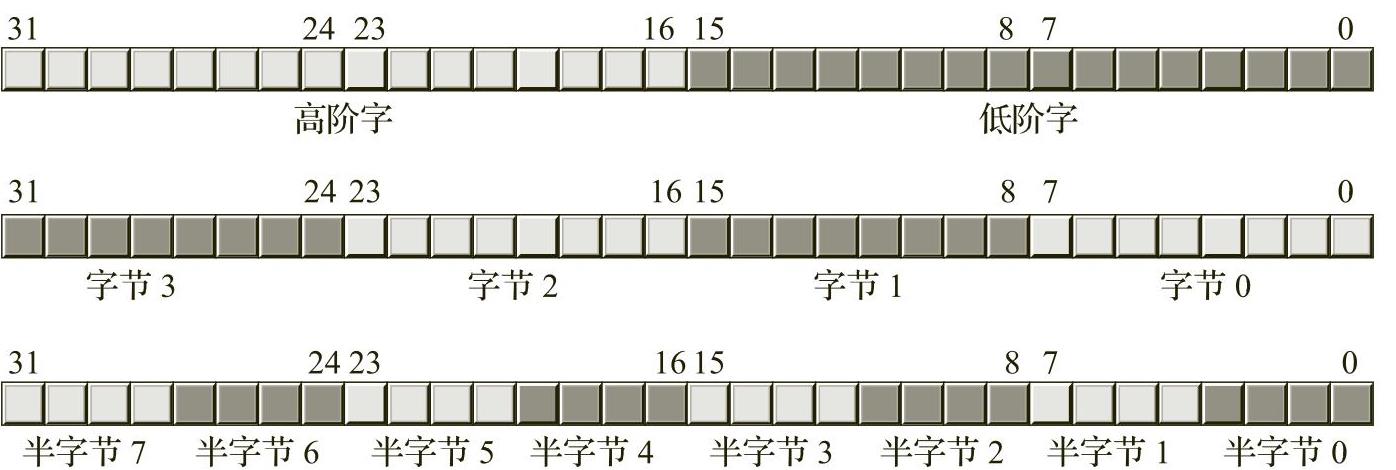
图2-7 双字中的半字节、字节和字
双字可以代表各种不同的对象。一般使用双字来表示32位的整数值(允许0~4294967295范围内的无符号数值,或者-2147483648~2147483647范围内的有符号数值)。32位的浮点数值也可以使用双字来表示。
可以使用dword数据类型创建一个双字变量,如下例所示:
.data
d dword ?
四字(64位)值也非常重要,因为64位整数、指针和某些浮点数据类型需要64个二进制位来表示。同样,现代x86-64处理器的SSE/MMX指令集可以处理64位的数值。当然,八字(128位)数值也非常重要,因为AVX/SSE指令集可以处理128个二进制位所表示的数值。MASM允许使用qword和oword数据类型来声明64位的数值以及128位的数值,如下所示:
.data
o oword ?
q qword ?
但是,不能使用标准指令(例如mov、add和sub)直接操作128位的整数对象,因为标准x86-64整数寄存器一次只能处理64位的数据。在第8章中,我们将讨论如何处理这些扩展精度值,第11章将讨论如何使用SIMD指令直接操作oword值。
我们将使用十六进制数和二进制数,执行四种初级的逻辑运算(布尔函数):AND(与)、OR(或)、XOR(异或)和NOT(非)。
逻辑与运算是一种二元运算(dyadic/binary operation,表示该运算只接受两个操作数)。这些操作数都是单独的二进制位。逻辑与运算的示例如下所示:
0 and 0=0
0 and 1=0
1 and 0=0
1 and 1=1
表示逻辑与运算的紧凑方法是使用真值表。真值表的形式如表2-2所示。
这就像我们在学校里学习的乘法口诀表一样,第一列中的值对应于逻辑与运算的左操作数,第一行中的值对应于逻辑与运算的右操作数。位于行和列相交处的数值(对于特定的一对输入值)是将对应第一行与第一列的两个数值进行逻辑与运算的结果。
表 2-2 逻辑与的真值表
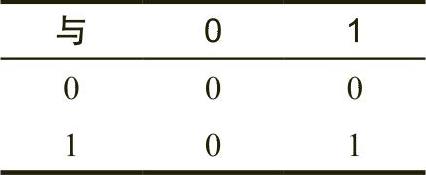
用文字来表述,逻辑与运算的含义是:“如果第一个操作数为1,第二个操作数为1,那么结果为1;否则,结果为0。”我们也可以这样表述:“如果其中一个或两个操作数都是0,那么结果是0。”
可以使用逻辑与运算强制得到一个值为0的结果:如果其中一个操作数为0,则无论其他操作数如何,结果始终为0。例如,在表2-2中,第二行仅包含值0,第二列也仅包含值0。此外,如果一个操作数包含1,则结果恰好是另一个操作数的值。逻辑与运算的这些结果非常重要,特别是当我们想将某些位强制设为0时。我们将在下一节中,对逻辑与运算的这些用法进行深入研究。
逻辑或运算也是一种二元运算。其定义如下所示:
0 or 0=0
0 or 1=1
1 or 0=1
1 or 1=1
逻辑或运算的真值表如表2-3所示。
通俗而言,逻辑或运算的含义是:“如果第一个操作数或者第二个操作数(或两个操作数)为1,那么结果为1;否则,结果为0。”这也称为兼或运算或者同或运算(inclusive-or operation)。
表 2-3 逻辑或的真值表
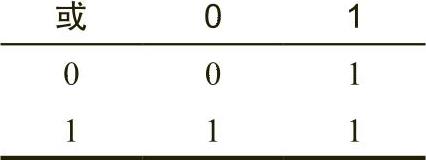
如果逻辑或运算的一个操作数为1,那么无论另一个操作数的值是多少,结果始终为1。如果一个操作数为0,那么结果始终是另一个操作数的值。与逻辑与运算一样,这是逻辑或运算的一个重要附加作用,后面将证实这一点非常有用。
请注意,这种形式的逻辑兼或运算与标准文字“或者”的含义存在差异。考虑这样一个语句:“我将要去商店或者我将要去公园”。这句话意味着说话者将要去商店和公园中的一个地方,而不是两个地方都去。因此,文字中的逻辑或与计算机中的逻辑兼或的运算略有不同。事实上,文字中的或符合的是异或(XOR)运算的定义。
逻辑异或运算也是一种二元运算。其定义如下所示:
0 xor 0=0
0 xor 1=1
1 xor 0=1
1 xor 1=0
逻辑异或运算的真值表如表2-4所示。
采用文字来表述,逻辑异或运算的含义就是:“如果第一个操作数或第二个操作数为1,且不是两者均为1,则结果是1;否则,结果是0。”逻辑异或运算比逻辑或运算更接近文字“或者”的意思。
表 2-4 逻辑异或的真值表
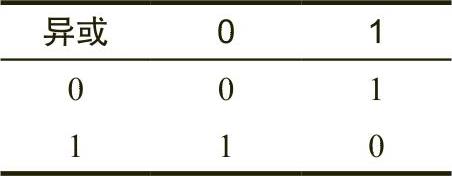
如果逻辑异或运算中的一个操作数是1,则结果总是另一个操作数的相反值。也就是说,假如一个操作数为1,那么如果另一个操作数为1,则结果为0;如果另一个操作数为0,则结果为1。如果第一个操作数为0,那么结果正好是第二个操作数的值。这个功能允许我们有选择地反转一个位串中的某些二进制位。
逻辑非运算是一元运算(monadic operation,意味着这个运算只接受一个操作数):
not 0=1
not 1=0
逻辑非运算的真值表如表2-5所示。
表 2-5 逻辑非的真值表

在上一节中,我们定义了单个位操作数的逻辑函数。由于x86-64使用8、16、32、64位或更多位构成的组
,因此我们需要扩展这些函数的定义,以处理超过两个二进制位的数据。
x86-64上的逻辑函数按位(或逐位)进行运算。给定两个数值,这些函数对这两个值的第0位进行运算,产生结果的第0位;然后,函数对输入值的第1位进行运算,生成结果的第1位,依此类推。例如,要计算以下两个8位数字的逻辑与运算结果,则应单独对每列执行逻辑与运算:
1011_0101b
1110_1110b
----------
1010_0100b
同样,也可以将这种逐位运算的方法应用于其他逻辑函数。
如果要对两个十六进制数执行逻辑运算,那么首先应该将它们转换为二进制数。
在处理位串(例如二进制数)时,使用逻辑与/逻辑或运算强制二进制位为0或1的能力以及使用逻辑异或运算反转二进制位的能力非常重要。这些运算允许我们有选择地操纵位串中的某些位,而不影响其他位的值。
例如,如果有一个8位二进制值 X ,并且我们希望将其第4位~第7位设置为0,那么可以对值 X 与二进制值0000_1111b进行逻辑与运算,这种按位逻辑与运算会将 X 的最高4位强制设置为0,而保持 X 的最低4位的值不变。同样,可以对0000_0001b与 X 进行逻辑或运算,将 X 的低阶位强制设置为1;对0000_0100b与 X 进行逻辑异或运算,从而反转 X 的第2位。
使用逻辑与、逻辑或和逻辑异或运算,以这种方式操纵位串的方法,称为掩蔽(masking,也称为屏蔽)位串。我们之所以使用术语“掩蔽”是因为当我们希望将某些二进制位强制设置为0、1或其将其位取反时,可以使用某些值(1用于逻辑与,0用于逻辑或/异或)对某些位增加或者去除掩蔽。
x86-64 CPU提供了四条指令,用于对操作数执行这些位逻辑运算。这四条指令分别是and、or、xor和not。and、or和xor指令的语法与add和sub指令相同:
and dest , source
or dest , source
xor dest , source
这些操作数与add指令的操作数具有相同的限制。具体而言,source(源操作数)必须是一个常量、内存或寄存器操作数,dest(目标操作数)必须是内存或寄存器操作数。此外,操作数的大小必须相同,并且不能两者都是内存操作数。如果目标操作数为64位,源操作数为常量,且该常量限制为32位(或更少的位数),则CPU将该值有符号扩展至64位(具体请参阅2.8节的相关内容)。
这些指令按位进行逻辑运算,计算等式如下:
dest= dest operator source
x86-64逻辑非指令的语法稍有不同,因为该指令只有一个操作数。逻辑非指令的语法采用以下形式:
not dest
逻辑非指令的计算等式如下:
dest=not( dest )
其中,dest操作数必须是寄存器或内存操作数。逻辑非指令将反转指定目标操作数中的所有的二进制位。
程序清单2-2中的代码读取用户输入的两个十六进制数,并计算它们的逻辑与、逻辑或、逻辑异或和逻辑非的运算结果。
程序清单 2-2 逻辑与、逻辑或、逻辑异或和逻辑非运算的示例



构建和运行此代码的结果如下所示:
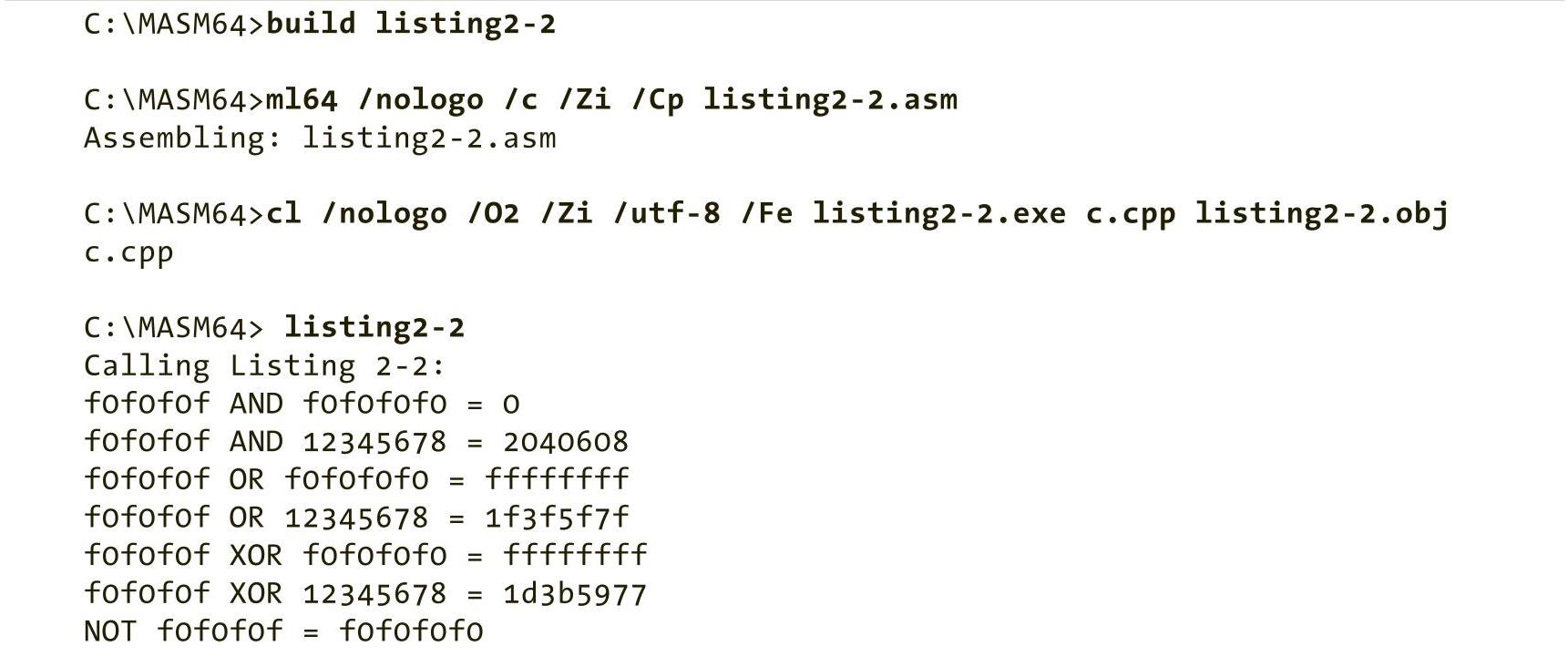

顺便说一下,我们经常会看到以下“魔法”指令:
xor reg , reg
对寄存器与其自身进行逻辑异或运算,会将该寄存器设置为0。除了8位寄存器外,相比将立即数常量转移到寄存器中的操作方式,xor指令通常更高效。请考虑以下代码:
xor eax,eax;机器代码只有2字节长
mov eax,0;机器代码长度根据寄存器的不同,通常为6字节长
在处理64位寄存器时,节省的空间甚至更大(因为立即数常量0的长度本身就是8个字节)。
到目前为止,我们将二进制数均视为无符号数。二进制数…00000表示0、…00001表示1、…00010表示2,依此类推,直到无穷大。 n 个二进制位可以表示2 n 个无符号数。那么应该如何表示负数呢?如果我们将一半可能的组合分配给负值,另一半分配给正值和0,那么用 n 位二进制就可以表示-2 n -1 ~+2 n -1 -1范围内的有符号数。因此,我们使用8位(字节)可以表示负值-128~-1以及非负值0~127;使用16位(字),可以表示-32768~+32767范围内的数值;使用32位(双字),可以表示-2147483648~+2147483647范围内的数值。
在数学以及计算机科学中,补码方法(complement method)将负数和非负数(0和正数)编码成两个相等的集合,这样它们就可以使用相同的算法(或硬件)执行加法运算,并产生正确的结果,因为这其中不需要考虑数值的符号是什么。
x86-64微处理器使用补码表示法来表示有符号数。在补码系统中,一个数的最高位是符号位(正是这个符号位将整数分成两个数量相等的集合)。如果符号位为0,则数为正(或0),并使用标准的二进制格式表示;如果符号位为1,则数为负(采用补码形式,这是一种神奇的格式,支持负数和非负数的加法,无需特殊硬件的支持,稍后将讨论)。下面是一些例子。
对于16位的数:
●8000h为负数,因为最高位为1
●100h为正数,因为最高位为0
●7FFFh为正数
●0FFFFh为负数
●0FFFh为正数
为了将正数转换为负数,可以使用以下算法。
(1)对该数的每一位取反(应用逻辑非函数)。
(2)将取反后的结果加1,并忽略最高位的任何进位。
利用这个算法生成的位模式,满足补码形式的数学定义。特别是,将使用此格式的负数和非负数相加,会产生预期的结果。
例如,计算-5的8位补码的过程如下:
●0000_0101b 5(二进制)
●1111_1010b 对所有二进制位分别取反
●1111_1011b 加1,得到结果
对-5的补码执行补码运算,结果将再次得到原始值0000_0101b:
●1111_1011b -5的补码
●0000_0100b 对所有二进制位分别取反
●0000_0101b 加1,得到结果(+5)
请注意,将+5和-5相加(忽略最高位上的任何进位),将会得到预期的结果0:
1111_1011b -5的补码
+0000_0101b 5
----------
(1)0000_0000b 忽略进位,结果为0
以下示例给出了一些正的16位有符号数和负的16位有符号数的示例:
●7FFFh:+32767,最大的16位正数
●8000h:-32768,最小的16位负数
●4000h:+16384
为了将示例数值转换为自己的负数(即对其取负),可以按照以下方法进行操作:
7FFFh:0111_1111_1111_1111b +32767
1000_0000_0000_0000b 对所有二进制位分别取反(8000h)
1000_0000_0000_0001b 加1(8001h或-32767)
4000h:0100_0000_0000_0000b +16384
1011_1111_1111_1111b 对所有二进制位分别取反(0BFFFh)
1100_0000_0000_0000b 加1(0C000h或-16384)
8000h:1000_0000_0000_0000b -32768
0111_1111_1111_1111b 对所有二进制位分别取反(7FFFh)
1000_0000_0000_0000b 加1(8000h或-32768)
8000h取反以后变成了7FFFh,再加1,就得到8000h!等等,这是怎么回事呢?-(-32768)等于-32768吗?当然不是。只是由于+32768的值不能使用16位有符号数表示,因此我们不能对最小的负数再进行取负运算。
通常情况下,我们不需要手动执行补码运算。x86-64微处理器提供一条指令neg(negate),来执行此操作:
neg dest
该指令完成“dest=-dest;”运算,并且操作数必须是内存位置或者寄存器。neg可以对字节、字、双字和四字大小的对象进行操作。因为这是一个有符号整数运算,所以只对有符号整数值进行运算才有意义。程序清单2-3中的代码演示了补码运算和对有符号8位整数值运行的neg指令。
程序清单 2-3 补码运算的示例



以下命令构建并运行程序清单2-3中的代码:
C:\> build listing2-3
C:\> echo off
Assembling:listing2-3.asm
c.cpp
C:\> listing2-3
Calling Listing 2-3:
Enter an integer between 0 and 127:123
Value in hexadecimal:7b
Invert all the bits(hexadecimal):84
Add 1(hexadecimal):85
Output as signed integer:-123
Using neg instruction:-123
Listing 2-3 terminated
除了补码运算(通过取反加1以及使用neg指令实现),该程序还演示了一个新功能:获取用户的数字输入。从用户处读取输入字符串(使用c.cpp源文件中的readLine()函数),然后调用C标准库中的atoi()函数,就可以完成数字输入。atoi()函数需要单个参数(在RCX寄存器中传递),该参数指向包含整数值的字符串,此函数将该字符串转换为相应的整数并返回RAX中的整数值
。
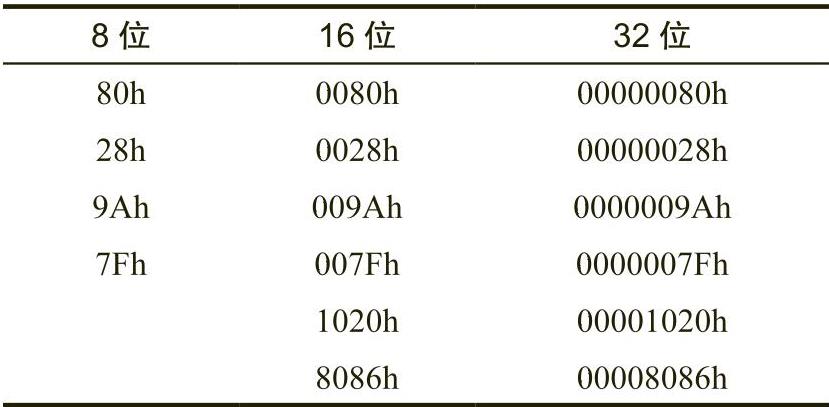
将8位补码值转换为16位,或者将16位补码值转换为8位,可以通过符号扩展(sign extension)和符号缩减(sign contraction)运算来实现。
在将有符号值从一定数量的位扩展到更多数量的位时,只需将符号位复制到新格式的所有附加位中。例如,为了将8位数值符号扩展成16位数值,可以将8位数值的第7位复制到16位数值的第8~15位。为了将16位数值符号扩展成双字,可以将16位数值的第15位复制到双字的第16~31位。
在处理不同长度的有符号值时,必须使用符号扩展。例如,为了将字节数值累加到字数值中,必须先将字节数值符号扩展成字数值,再将两个值相加。其他运算(尤其是乘法和除法)可能需要符号扩展成32位,具体请参见表2-6。
为了将无符号值从一定数量的位扩展到更多数量的位,必须对无符号值进行零扩展,具体请参见表2-7。零扩展(zero extension)非常简单,只需要将0储存到较长操作数的HO字节中。例如,为了将8位值82h零扩展成16位值,可以将0附加到HO字节中,结果为0082h。
表 2-6 符号扩展
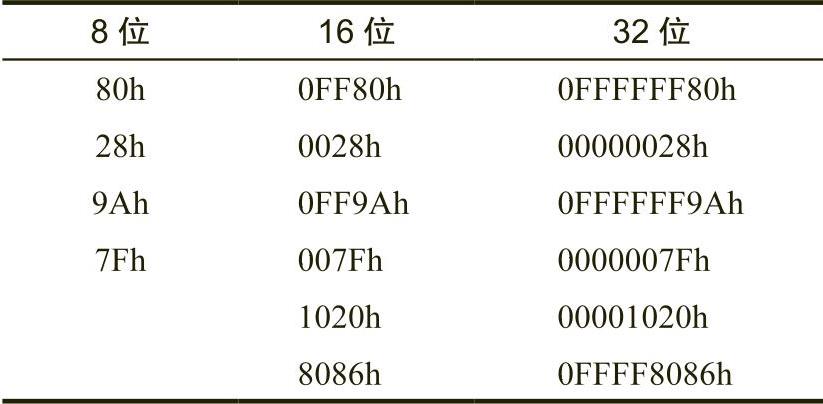
表 2-7 零扩展
符号缩减用于将具有一定二进制位数的值转换为具有较少位数的相同值,这个操作稍微有点麻烦。给定一个 n 位数,如果 m < n ,则不一定可以将其转换成 m 位数。例如,考虑值-448。作为一个16位的有符号数,其十六进制形式表示为0FE40h,这个数的大小超过了8位可表示值的范围,因此无法将其符号缩减为8位(否则会造成溢出)。
为了正确地对一个值进行符号缩减,需要丢弃的高阶字节必须是全部包含0或者0FFh的字节,并且结果值的高阶二进制位必须与从数值中删除的每个位相匹配。以下是将16位数符号缩减成8位数的一些示例:
●0FF80h可以符号缩减到80h
●0040h可以符号缩减到40h
●0FE40h不能符号缩减到8位
●0100h不能符号缩减到8位
如果必须要将较长的对象转换为较短的对象,并且愿意承受可能的精度损失,则可以使用饱和(saturation)操作。在使用饱和操作对数值进行转换时,如果较长对象的值在较短对象的取值范围之内,那么可以将较长对象的值复制到较短的对象中;如果不在,则可以将较长对象的值设置为较短对象取值范围内的最大(或最小)值来剪裁该值。
例如,将一个16位有符号整数转换为8位有符号整数时,如果16位数值在-128~+127范围内,则将16位对象的低阶字节复制到8位对象中即可。如果16位数值大于+127,则将该值剪裁为+127,并将+127存储到8位对象中。同样,如果该数值小于-128,则将最终的8位对象剪裁为-128。
尽管将值剪裁到较短对象的数值界限会导致精度损失,但有时这是可以接受的,因为其他替代方法会引发异常,或者导致无法完成计算。对于许多应用,例如音频或视频处理,剪裁后的结果仍然可以被识别,因此这是一种合理的转换。
到目前为止,我们给出的所有汇编语言示例都在没有使用条件执行(conditional execution)语句(即在执行代码时做出决策)的情况下按顺序运行。事实上,除了call和ret指令外,我们还没有涉及任何影响汇编代码顺序执行方式的方法。
然而,这本书正在迅速接近一个转折点:真正有趣的示例需要具有按照不同条件执行不同代码段的能力。本节将围绕条件执行以及将控制转移到程序其他部分的主题简单展开。
也许最好从讨论x86-64的无条件转移控制指令jmp开始。jmp指令有几种语法形式,一种最常见的形式如下:
jmp statement_label
其中,statement_label(语句标签)是一个标识符,该标识符被附加到“.code”段中的机器指令上。jmp指令立即将控制转移到标签后面的语句。这在语义上等同于高级计算机程序中的goto语句。
以下示例中,mov指令的前面,就有一个语句标签:
stmtLbl:mov eax,55
与所有的MASM符号一样,语句标签具有两个相关联的主要属性:地址(即标签后面的机器指令的内存地址)和类型。类型为label,与proc伪指令的标识符类型相同。
语句标签不必与机器指令位于源代码行的同一物理行上。考虑下面的例子:
anotherLabel:
mov eax,55
这个例子在语义上等同于上一个例子。绑定到anotherLabel的值(地址)是标签后面的机器指令的地址。在这种情况下,即使mov指令出现在下一行,anotherLabel标签后面的指令也仍然是mov指令(anotherLabel标签后紧跟着mov指令,二者之间没有任何由其他MASM语句生成的代码)。
从技术上讲,也可以跳转到proc标签而不是语句标签。但是,jmp指令没有设置返回地址,因此如果该过程执行ret指令,则返回位置可能未定义。第5章将更详细地探讨返回地址。
虽然jmp指令的通用形式在汇编语言程序中是不可或缺的,但该指令不提供按条件执行不同代码段的能力,因此被称为无条件跳转(unconditional jump)
。幸运的是,x86-64 CPU提供了大量条件跳转指令(conditional jump instruction),顾名思义,这些指令允许有条件地执行代码。
这些指令对FLAGS寄存器中的条件码标志位(请参阅1.7节中的相关内容)进行测试,以确定是否存在需要执行的语句分支。这些条件跳转指令对FLAGS寄存器中如下4个条件码标志位进行测试:进位、符号、溢出和零标志位
。
x86-64 CPU提供了8条指令,分别测试这4个标志位(参见表2-8)。条件跳转指令的基本操作是:测试一个标志位,以检查该标志位的状态是设置(1)还是清除(0),如果测试成功,则跳转到目标标签;如果测试失败,程序将继续执行条件跳转指令后的下一条指令。
表 2-8 测试条件码标志位的条件跳转指令

为了使用条件跳转指令,必须先执行一条会影响一个(或多个)条件码标志位的指令。例如,无符号算术溢出将设置进位标志位(同样,如果没有发生溢出,进位标志位将被清除)。因此,可以在add指令之后使用jc指令和jnc指令,以查看计算过程中是否发生(无符号)溢出。例如:
mov eax,int32Var
add eax,anotherVar
jc overflowOccurred
;如果加法运算没有产生溢出,则继续执行后面的代码。
.
.
.
overflowOccurred:
;如果int32Var和anotherVar之和超出了32位的范围,则执行此代码。
并非所有指令都会影响标志位。到目前为止,在我们已经涉及的指令(mov、add、sub、and、or、not、xor和lea)中,只有add、sub、and、or、xor指令会影响标志位。add指令和sub指令影响的标志位如表2-9所示。
表 2-9 执行 add 指令或 sub 指令后的标志位设置

逻辑指令(and、or、xor和not)总是清除进位标志位和溢出标志位。这些指令将结果的最高位复制到符号标志位中,如果产生零或者非零结果,则设置或者清除零标志位。
除了条件跳转指令外,x86-64 CPU系列还提供一组条件移动指令,7.5节将介绍这些指令。
cmp(比较)指令可能是在条件跳转之前执行的最有用的指令。cmp指令与sub指令具有相同的语法,事实上,它还会从第一个操作数中减去第二个操作数,并根据减法的结果,设置条件码标志位
。但是,cmp指令不会将减法的结果存储回第一个(目标)操作数。cmp指令的作用是根据减法的结果设置条件码标志位。
虽然可以在cmp指令之后立即使用jc/jnc、jo/jno、js/jns和jz/jnz指令(用以测试cmp指令如何设置各个标志位),然而标志位的名称在cmp指令的上下文中意义不大。从逻辑上讲,当看到以下指令时(请注意,cmp指令的操作数语法与add、sub和mov指令相同):
cmp left_operand , right_operand
可以将此指令解读为“比较left_operand(左操作数)和right_operand(右操作数)”。在进行比较后,我们通常会提出以下问题:
●左操作数是否等于右操作数?
●左操作数是否不等于右操作数?
●左操作数是否小于右操作数?
●左操作数是否小于或等于右操作数?
●左操作数是否大于右操作数?
●左操作数是否大于或等于右操作数?
到目前为止,我们讨论的条件跳转指令(直觉上)并没有回答上述任何问题。
x86-64 CPU系列提供了一组附加的条件跳转指令,如表2-10所示,允许我们测试这些比较条件。
表 2-10 在 cmp 指令之后使用的条件跳转指令
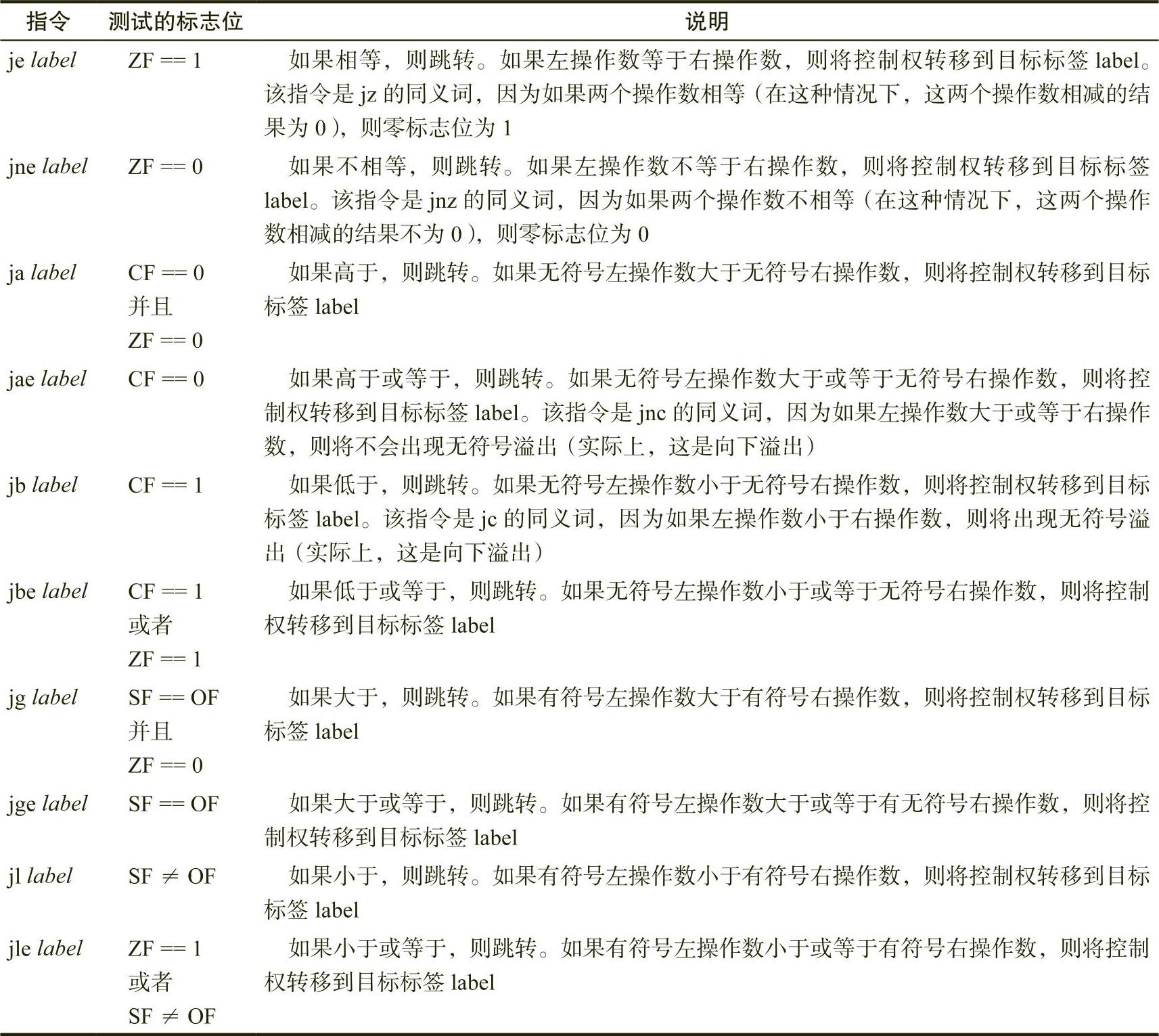
表2-10中可能需要注意的最重要的一点是,分别使用单独的条件跳转指令来测试有符号比较和无符号比较。考虑两个字节值0FFh和01h。从无符号的角度来看,0FFh大于01h。然而,当我们将这些数值视为有符号数时(使用补码编码系统),0FFh实际上是-1,这显然小于1。当将这些值视为有符号或无符号数值时,它们具有相同的位表示形式,但比较结果完全不相同。
有些指令是其他指令的同义词。例如,jb和jc是同一条指令(即这两条指令具有相同的机器码编码)。设置同义词指令是为了方便和可读性。例如,在cmp指令之后,jb比jc指令更有意义。MASM为各种不同的条件分支指令定义了若干同义词,从而使得编码更加容易。表2-11列出了这些同义词指令的一部分。
表 2-11 条件跳转指令的同义词指令

关于cmp指令,需要注意的是:该指令仅为整数比较设置标志位(这也将包含可以用整数编码的字符和其他类型)。具体而言,cmp指令不会比较浮点数值,也不会根据浮点数比较情况设置标志位。为了了解浮点运算(和浮点数比较)的更多信息,请参见6.5节中的相关内容。
应用于位串的另一组逻辑运算是移位(shift)和循环(rotate)移位操作。这两种运算可以进一步细分为左移位(left shift)、循环左(left rotate)移位、右移位(right shift)和循环右(right rotate)移位。
左移位运算将位串中的每个位都向左移动一个位置,如图2-8所示。
第0位移动到第1位所在的位置,第1位中以前的值移动到第2位所在的位置,依此类推。我们将一个0移到第0位,而最高位中以前的值将成为该操作的进位标志位的值。
x86-64提供了一条左移指令shl用于执行该运算。shl指令的语法形式如下所示:
shl dest , count
操作数count(计数)可以是CL寄存器,也可以是0~ n 范围内的常数,其中 n 比目标操作数中的位数少一位(例如,对于8位操作数, n =7;对于16位操作数, n =15;对于32位操作数, n =31;对于64位操作数, n =63)。dest操作数是典型的目标操作数,可以是内存位置,也可以是寄存器。
当操作数count为常数1时,shl指令执行如图2-9所示的运算。

图2-8 左移位运算

图2-9 左移位一位
在图2-9中,C表示进位标志位,也就是说,从操作数中移除的最高位被移入进位标志位中。因此,可以在执行“shl dest,1”指令后,通过立即测试进位标志位(例如,使用jc和jnc指令)来判断“shl dest,1”指令是否会导致溢出。
shl指令会根据移位结果设置零标志位(如果结果为0,则z=1;否则z=0)。如果移位结果的最高位为1,那么shl指令将设置符号标志位为1。如果移位计数为1,则在最高位改变时设置溢出标志位(即当最高位以前为1时将0移入最高位,或者当最高位以前为0时将1移入最高位);如果移位计数不为1,则溢出标志位未定义。
将一个值向左移动一位,与将这个值乘以该值的基数是一样的效果。例如,将十进制数值向左移动一位(在数值的右侧添加一个0)可以有效地将其乘以10(十进制数的基数):
1234 shl 1=12340
“shl 1”指令表示向左移动1位。
因为二进制数的基数是2,所以将某个二进制数值向左移动一位,结果将使其乘以2。如果将一个二进制数值向左移动 n 次,则得到将该值乘以2 n 的结果。
右移位运算的工作方式相同,只是将数据向相反的方向移动。对于一个字节数值,第7位移到第6位,第6位移到第5位,第5位移到第4位,依此类推。在右移位过程中,我们将一个0移到第7位,第0位将作为进位位被移出(具体请参见图2-10)。

图2-10 右移位运算
相应地,x86-64提供了一条shr指令,该指令将目标操作数中的各个位向右移。shr指令的语法与shl指令的语法相类似:
shr dest , count
这条指令将一个0移位到目标操作数的最高位;将其他各个二进制位均向右移动一位(从较高的位编号移动到较低的位编号)。最后,将第0位移入进位标志位。如果指定count为1,那么shr指令将执行如图2-11所示的运算。

图2-11 右移位一位
shr指令将根据移位结果设置零标志位(如果结果为0,则ZF=1;否则ZF=0)。shr指令将清除符号标志位(因为移位结果的最高位始终为0)。如果移位计数为1,那么shl指令将在最高位改变时设置溢出标志位(即当最高位以前为1时将0移入最高位,或当最高位以前为0时将1移入最高位);如果移位计数不为1,则溢出标志位未定义。
因为左移位相当于乘以2,所以右移位大致相当于除以2(或者简而概之,右移位是除以数值的基数)。如果执行 n 次右移,则得到将该数值除以2 n 的结果。
但是,右移位只相当于无符号数除以2。例如,将254(0FEh)的无符号数表示形式向右移动一位,结果将得到127(7Fh),这正好符合预期。然而,如果将用补码表示的-2(0FEh)向右移动一位,结果将得到127(7Fh),这是一个错误的结果。之所以出现这个问题的原因在于,我们将一个0移入第7位。如果第7位之前包含一个1,则意味着将这个数从负数改变成了正数。对于除以2的操作而言,这是一个错误的结果。
为了将右移位用作除法运算,必须定义第三种移位运算,即算术右移位(arithmetic shift right)
。算术右移位与正常的右移位(逻辑右移位)相类似,不同之处在于,算术右移位不是将一个0移入最高位,而是将最高位复制回其自身;也就是说,在移位过程中,不会修改最高位,如图2-12所示。
算术右移位通常会产生预期的结果。例如,在-2(0FEh)上执行算术右移位运算,结果会得到-1(0FFh)。但是,算术右移位会将数值舍入到小于或等于实际结果的最接近整数。例如,如果对-1(0FFh)进行算术右移位,则结果为-1,而不是0。因为-1小于0,所以算术右移位向-1舍入。这不是算术右移位中的错误,只是使用了一个不同(尽管有效)的整数除法定义。
x86-64提供算术右移位指令sar。sar指令的语法与shl和shr指令几乎相同:
sar dest , count
对count操作数和dest操作数的通常限制在这里都适用指令sar。如果count为1,则此指令执行的运算如图2-13所示。
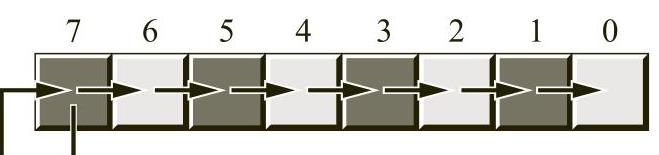
图2-12 算术右移位运算

图2-13“sar dest,1”运算
sar指令将根据移位结果设置零标志位(如果结果为0,则z=1;否则z=0)。sar指令将符号标志位设置为移位结果的最高位。sar指令执行后,溢出标志位始终为0,因为此运算不可能产生有符号溢出。
循环左移位和循环右移位运算的行为类似于左移位和右移位运算,只是从一端移出的位移回了另一端。图2-14演示了这两种运算。
图2-14 循环左移位和循环右移位
x86-64提供rol和ror指令,用于对操作数执行这两种基本运算。这两条指令的语法与移位指令相类似:
rol dest , count
ror dest , count
如果count为1,则这两条指令会将移出目标操作数的位复制到进位标志位中,如图2-15和图2-16所示。
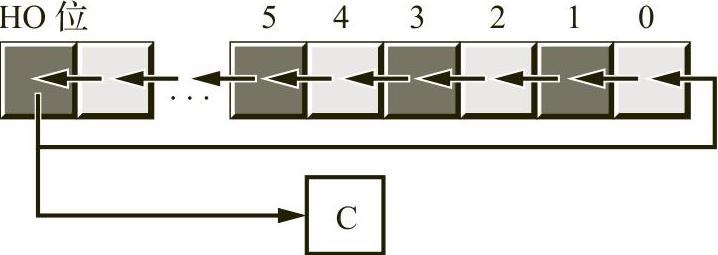
图2-15“rol dest,1”运算
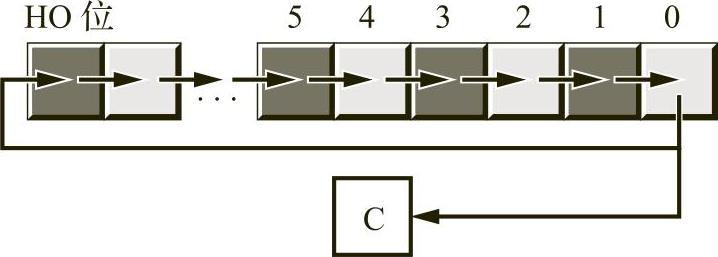
图2-16“ror dest,1”运算
与移位指令不同,循环移位指令不影响符号标志位或者零标志位的设置。仅当进行1位循环移位时,才定义溢出标志位,该标志位在所有其他情况下都是未定义的(仅RCL和RCR指令除外:0位循环移位不起任何作用,也就是说,不影响溢出标志位)。对于循环左移位,溢出标志位被设置为原始高阶两位的异或结果。对于循环右移位,溢出标志位被设置为循环移位后高阶两位的异或结果。
对于循环移位操作来说,可以将输出位移位到进位标志位,并将以前进位标志位的值移回移位操作的输入位,这种做法会更方便一些。x86-64的rcl(rotate through carry left,通过进位标志位循环左移位)和rcr(rotate through carry right,通过进位标志位循环右移位)指令具有这一作用。这两种指令的语法形式如下所示:
rcl dest , count
rcr dest , count
count操作数是常量或者CL寄存器,dest操作数是内存位置或寄存器。count操作数必须小于dest操作数中的位数。如果count为1,则这两条指令实现如图2-17所示的循环移位。
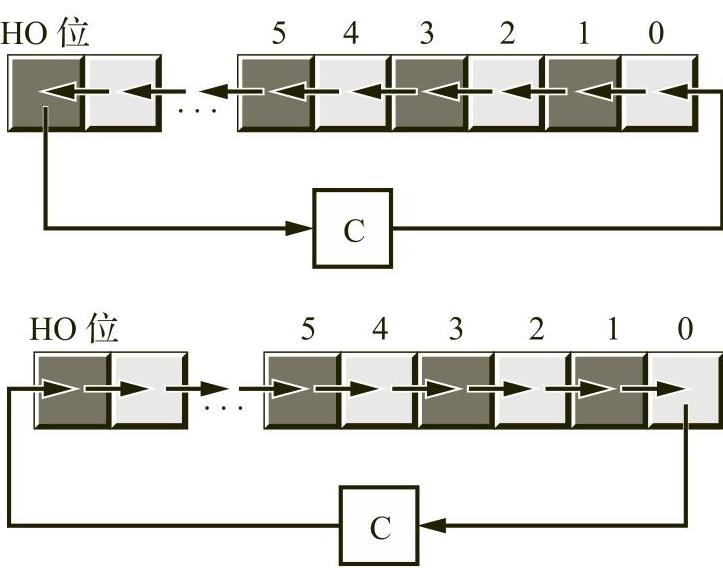
图2-17“rcl dest,1”和“rcr dest,1”运算
与移位指令不同,通过进位标志位进行循环移位的指令不会影响符号标志位或零标志位的设置。仅当进行1位循环移位时,才定义溢出标志位。对于循环左移位,如果原始高阶两位改变,则设置溢出标志位。对于循环右移位,溢出标志位被设置为循环移位后结果的高阶两位的异或结果。
虽然x86-64对于字节、字、双字和四字数据类型运行效率最高,但有时还需要处理不为8位、16位、32位或64位的数据类型。我们也可以对非标准数据进行零扩展,使其大小成为比自己大的第一个2的幂(例如将22位值扩展成32位值)。事实证明,这样的扩展操作可以提高运行速度,但是如果有一个由此类值构成的大数组,则将浪费略多于31%的内存空间(因为每一个32位值中,都有10位被浪费)。假设将这被浪费的10位重新用于其他用途,那么该如何处理呢?答案是将单独的22位值和10位值打包为单个32位值,就可以不浪费任何空间了。
例如,考虑格式为“04/02/01”的日期。表示这种格式的日期需要三个数值,即月、日以及年。当然,月的取值范围为1~12,因此至少需要4位(4位可以表示最多16个不同的值)来表示。日的取值范围为1~31,因此需要5位(5位可以表示最多32个不同的值)来表示。对于年,假设我们使用0~99范围内的值,那么年需要7位(7位可以表示多达128个不同的值)来表示。因此,表示这种格式的日期所需要的位数为4+5+7=16,也就是两个字节。
换句话说,我们可以将日期数据打包成两个字节,而如果我们使用单独的字节来表示每个月、日和年,那么需要三个字节。这样存储每个日期都会节省一个字节的内存空间,在存储大量日期的情况下,可以节省大量的内存空间。使用打包数据表示日期,则各个位的排列如图2-18所示。
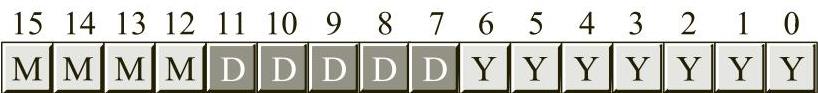
图2-18 短日期打包格式(两个字节)
MMMM表示由4位组成的月,DDDDD表示由5位组成的日,YYYYYYY表示由7位组成的年。每个位集都称为一个位字段(bit field)。例如,2001年4月2日将表示为4101h:
0100 00010 0000001=0100_0001_0000_0001b或4101h
4 2 01
尽管打包值提高了空间利用率(也就是说,打包的方式有效地利用了内存),但打包值的计算效率却非常低(比较慢!)。那么是什么原因导致的呢?其实是将数据解包到不同的位字段中需要额外的指令,这些额外的指令需要额外的执行时间(还需要额外的字节来存储指令),因此必须仔细考虑打包数据字段是否可以节省整体的开销。程序清单2-4中的示例代码演示了打包和解包这种16位的日期格式所需执行的操作。
程序清单 2-4 打包和解包日期数据



构建和运行该程序的结果如下所示:
C:\> build listing2-4
C:\> echo off
Assembling:listing2-4.asm
c.cpp
C:\> listing2-4
Calling Listing 2-4:
Enter current month:2
Enter current day:4
Enter current year(last 2 digits only):68
Packed date is 2244
The date is 02/04/68
Listing 2-4 terminated
当然,经历过“千年虫”(2000年)的问题
之后,我们知道将日期格式限制在100年(或者甚至127年)是一种非常愚蠢的处理方式。为了进一步验证打包日期格式,我们可以将其扩展为四个字节,即打包成一个双字变量,如图2-19所示。(所创建的数据对象的长度应该为2的偶数次幂,即一个字节、两个字节、四个字节、八个字节等,否则程序性能将受到影响。)

图2-19 长日期打包格式(四个字节)
在这种打包数据格式中,月字段和日字段分别由8位组成,因此可以从双字中提取它们作为字节对象。剩下的16位用于表示年,可以表示65536个年。通过重新排列这些位,使得年字段位于高阶位中,月字段位于中间位中,而日字段位于低阶位中。这种长日期格式允许我们轻松地比较两个日期,以查看一个日期是小于、等于还是大于另一个日期。请考虑以下的代码:
mov eax,Date1;假设Date1和Date2是双字变量
cmp eax,Date2;使用长日期打包格式
jna d1LEd2
当Date1>Date2时执行此处的代码
d1LEd2:
如果将不同的日期字段保存在不同的变量中,或者以不同的方式组织字段,那么我们将无法像比较短日期打包数据格式那样轻松地比较Date1和Date2。因此,此示例演示了打包数据的另一个优点,就是即使没有节约任何空间,也可以使某些计算更方便甚至更高效(这正好与使用打包数据时相反)。
在实际应用中,打包数据类型的例子比比皆是。可以将八个布尔值打包成一个字节,也可以将两个BCD数字打包成一个字节,等等。
打包数据的一个典型示例是RFLAGS寄存器,该寄存器将9个重要的布尔对象(以及7个重要的系统标志)打包到一个16位寄存器中。我们经常需要访问其中的某些标志位。可以使用条件跳转指令测试许多条件码标志位,还可以使用表2-12中直接影响某些标志位的指令,来操作标志寄存器中的单个位。
表 2-12 影响某些标志位的指令

lahf和sahf指令提供了一种便捷的方式,可以将标志寄存器的低阶8位作为一个由8位组成的字节(而不是8个单独的1位值)来访问。有关标志寄存器的布局,请参见图2-20。
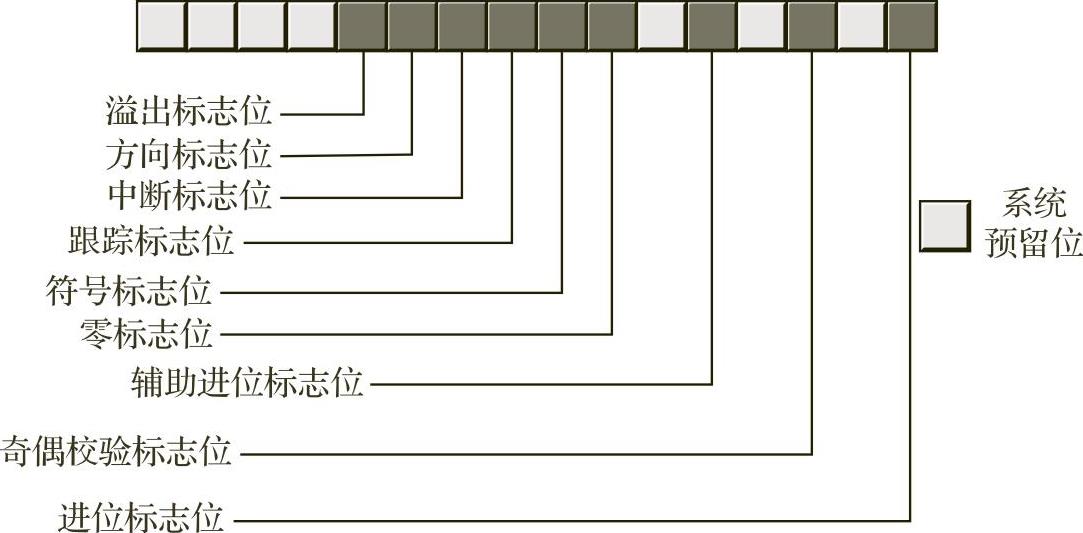
图2-20 作为打包布尔数据的FLAGS寄存器
lahf指令和sahf指令的语法形式如下所示:
lahf
sahf
当英特尔计划为其新推出的8086微处理器引入浮点单元(8087 FPU)时,尽全力聘请了最好的数值分析师来设计浮点格式,该专家随后聘请了该领域的另外两名专家。这三位专家(William Kahan、Jerome Coonen和Harold Stone)设计了英特尔芯片的浮点数格式。他们在设计KCS浮点标准方面做得非常出色,以至于IEEE采用了这种格式作为其浮点数格式
。
为了满足广泛的性能和精度要求,英特尔实际上引入了三种浮点数格式,即单精度、双精度和扩展精度。单精度格式和双精度格式对应于C语言的浮点数和双精度类型,或者FORTRAN语言的实数和双精度类型。扩展精度格式包含16个额外的位,在存储结果的过程中,向下舍入到双精度值之前,长链计算会将这些额外的位用作警戒位。
单精度浮点数格式由三部分组成,分别是由反码表示的24位尾数8位的excess-127格式的指数以及一个符号位。尾数通常表示1.0(包括)~2.0(不包括)之间的值。尾数的高阶位始终假定为1,用于表示二进制小数点
左侧的数值。余下的23个尾数位用于表示二进制小数点右侧的值。因此,尾数表示以下的数值:
1.mmmmmmm mmmmmmmm
mmmm字符表示尾数的23位。请注意,由于尾数的高阶位始终为1,因此单精度格式实际上不会将该位存储在浮点数的32位内。尾数的高阶位被称为隐含位(implied bit)。
因为我们研究的是二进制数,所以二进制小数点右侧的每个位置都表示一个值(0或1)乘以2的一个负数(各位置对应的负数是连续的)次幂。隐含的那1位总是1乘以2
0
,即1。这就是尾数总是大于或等于1的原因。即使其他的尾数位都是0,隐含的1位也会使结果总是数值1
。当然,即使二进制小数点的后面存在几乎无限个1,它们的总和也仍然不会达到2。这就是尾数可以表示介于1(包含)和2(不包含)之间的数值的原因。
虽然在1和2之间存在无限多个数值,但我们只能表示其中的800万个,因为我们使用的是23位的尾数(隐含的第24位始终为1)。这就是浮点算术运算结果不精确的原因所在——在涉及单精度浮点值的计算中,存在固定位数的限制。
尾数使用反码格式而不是补码来表示有符号值。尾数的24位值只是一个无符号二进制数,符号位决定该值是正数还是负数。反码具有一个不寻常的特性,即0有两种表示(符号位分别为1或0)。一般情况下,这种特性仅对设计浮点数软件系统或硬件系统的人员来说很重要。我们将假定0的符号位为0。
为了表示1.0(包含)~2.0(不包含)范围之外的数值,可以利用浮点数格式的指数部分。浮点数格式计算2的指定指数次幂,然后将尾数乘以该数值。指数为8位,以excess-127的格式存储。在excess-127格式中,指数0表示为127(7Fh),负指数是0~126范围内的数值,正指数是128~255范围内的数值。为了将指数转换为excess-127格式,需要将指数值加上127。使用excess-127格式可以更容易地比较浮点数。单精度浮点数格式如图2-21所示。

图2-21 单精度(32位)浮点数格式
使用24位尾数,我们将获得大约六位半(十进制)精度(半位精度意味着前六位数字可以全部在0~9范围内,但第七位数字只能在0~
x
范围内,其中
x
<9且通常接近5)的数据。采用8位excess-127格式的指数,单精度浮点数的动态范围(dynamic range)
大约为2
±127
或10
±38
。
虽然单精度浮点数完全适用于许多实际应用,但其精度和动态范围有限,不适用于金融、科学和其他应用领域。此外,在进行长链计算期间,单精度格式的精度限制可能会引入严重误差。
双精度格式有助于解决单精度浮点数的问题。与单精度格式相比,双精度格式占用了两倍的空间。双精度格式由三部分组成,分别是11位的excess-1023格式的指数、53位的尾数(隐含的高阶位为1)以及一个符号位。这种格式提供了大约10 ±308 的动态范围和14.5位的数据精度,足以满足大多数应用。双精度浮点数的格式如图2-22所示。

图2-22 64位双精度浮点数格式
在涉及双精度浮点数的长链计算过程中,为了确保精度,英特尔设计了扩展精度格式。扩展精度格式占用80位。在额外的16位中,12位附加到尾数末尾,4位附加到指数末尾。与单精度值和双精度值不同的是,扩展精度格式的尾数没有隐含的高阶位。因此,扩展精度格式提供了64位尾数、15位的excess-16383格式的指数和1个符号位。图2-23显示了扩展精度浮点数的格式。

图2-23 80位扩展精度浮点数格式
在x86-64 FPU上,所有计算都使用扩展精度格式完成。无论何时,当加载一个单精度值或双精度值时,FPU都会自动将其转换为扩展精度的数值。同样,在将一个单精度值或双精度值存储到内存中时,在存储之前,FPU会自动将该数值向下舍入到适当的大小。通过使用扩展精度格式,英特尔保证提供大量的警戒位,以确保计算的准确性。
为了在计算过程中维持最大的精度,大多数计算都使用规范化值。规范化浮点值是尾数的高阶位为1的值。几乎任何非规范化的值都可以被规范化:将尾数的各个位向左移位,并减小指数,直到尾数的高阶位为1。
请记住,指数是一个二进制数。每次增加指数时,浮点数都会乘以2。同样,每当减小指数时,浮点值都会除以2。因此,将尾数向左移位一位意味着将浮点值乘以2;同样,将尾数向右移位一位意味着将浮点值除以2。所以,将尾数向左移位一个位置同时将指数减1并不会改变浮点数的值。
使用规范化浮点数具有优势的原因是这种方式可以保证计算的最大精度位数。如果尾数的高阶 n 位都是0,则尾数的计算精度位要少很多。因此,如果仅涉及规范化值,则浮点数的计算将更加准确。
在两种重要情况下,浮点数将无法规范化。第一种特殊情况是数值0。显然,0无法被规范化,因为在0的浮点数表示中,尾数的每一位值都不可能为1。但是,这并不是问题,因为我们可以使用一个位精确地表示数值0。
第二种情况是尾数中有一些高阶位为0,但偏移指数(biased exponent)也为0(我们不能通过减小指数来对尾数进行规范化)。对于尾数的高阶位以及偏移指数都为0(所允许的最大负指数)的那些很小的数,IEEE标准并没有排除它们,而是允许使用特殊的规范化值来表示这些较小的值。
尽管使用非规范化值可以使IEEE浮点数计算产生比向下溢出时更好的结果,但需要注意的是,非规范化值提供的精度位较少。
IEEE浮点标准可以识别三个特殊的非数值数据,即-infinity(负无穷大)、+infinity(正无穷大)和一个特殊的NaN(not-a-number,非数值)。对于这些特殊的数值,其指数字段为全1。
对于某个数值,如果其指数为全1,尾数为全0,则该值为infinity。符号位为0时表示+infinity,符号位为1时表示-infinity。
对于某个数值,如果其指数为全1,尾数不为全0,则该值为无效数值。在IEEE 754术语中,称其为NaN。NaN表示非法操作,例如试图计算负数的平方根。
当任一操作数(或者两个操作数)为NaN时,会发生无序比较。由于NaN的值不确定,因此无法对其进行比较(即它们是不可比较的)。对执行无序比较的任何尝试通常会导致异常或某种错误。另外,有序比较所涉及的两个操作数都不可以是NaN。
MASM提供了几种数据类型,以支持在汇编语言程序中使用浮点数据。MASM的浮点值常量允许以下的语法形式。
●一个可选的“+”或“-”符号,表示尾数的符号(如果没有指定,则MASM假设尾数为正)。
●后面跟一个或多个十进制数字。
●后面跟一个十进制小数点以及零个或多个十进制数字。
●(可选)后面跟e或E,(可选)后面跟符号(“+”或“-”)以及一个或多个十进制数字。
浮点值必须包含小数点或者e/E,以便将该数值与整数或无符号字面常量区分开来。以下是一些合法的字面浮点值常量的示例:
1.234 3.75e2-1.0 1.1e-11.e+4 0.1 -123.456e+789 +25.0e01.e3
浮点值的字面常量必须以十进制数字开头,如在程序中必须使用0.1来表示.1。
为了声明浮点值变量,可以使用数据类型real4、real8或real10。位于这些数据类型声明末尾的数字指定用于每个类型二进制表示的字节数。因此,我们可以使用real4来声明单精度实数值,使用real8来声明双精度浮点值,使用real10来声明扩展精度浮点值。除了使用这些数据类型来声明浮点值而不是整数这一点,这些数据类型的使用方法与byte、word、dword等的几乎相同。以下示例演示了这些声明及语法:
.data
fltVar1 real4?
fltVar1a real42.7
pi real43.14159
DblVar real8?
DblVar2 real81.23456789e+10
XPVar real10?
XPVar2 real10-1.0e-104
和往常一样,本书使用C/C++的printf函数将浮点值打印到控制台。当然,也可以编写汇编语言例程来完成同样的任务,但是C标准库提供了一种便捷的方法,可以避免编写(复杂的)代码,至少目前是这样。
注意: 浮点算术运算不同于整数算术运算,不能使用x86-64的add和sub指令对浮点数进行操作,可参阅第6章。
尽管整数和浮点数格式能够满足一般程序对数值的大多数需求,但在某些特殊情况下,使用其他数值表示形式会更加方便。在本节中,我们将讨论BCD格式,因为x86-64 CPU为这种数据表示提供了少量的硬件支持。
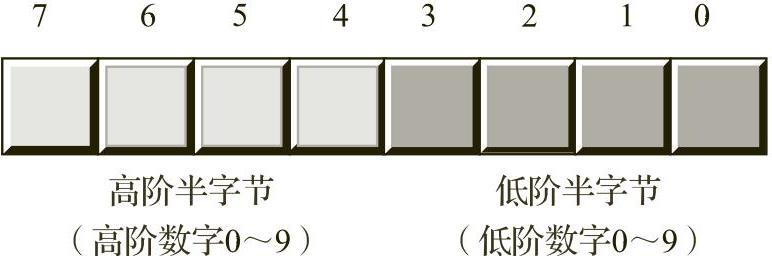
图2-24 内存中的BCD数据表示
BCD值是一个由半字节形成的序列,每个半字节表示0~9范围内的数值。一个字节可以表示包含两个十进制数字的数值,或者0~99之间的数值(具体请参见图2-24)。
可以看出,BCD表示对内存的利用并不是特别高效。例如,一个8位BCD变量可以表示0~99范围内的数值,而在保存二进制数值时,相同的8位可以表示0~255范围内的数值。同样,16位二进制数值可以表示0~65535范围内的数值,而16位BCD数值只能表示0~9999,大约为0~65535的六分之一。
不过,BCD数值可以很容易地在内部数字表示和字符串表示之间转换,而且可以在使用BCD的硬件(例如,旋转控制器或刻度盘)中对多位的十进制数值进行编码。基于上述两个原因,我们发现人们经常在嵌入式系统(例如烤箱、闹钟和核反应堆)中使用BCD,但在通用计算机软件中很少使用。
英特尔x86-64浮点单元支持一对用于加载和存储BCD值的指令。但在内部,FPU将这些BCD数值转换为二进制表示,并采用二进制形式执行所有的计算。英特尔x86-64浮点单元仅将BCD码用作外部数据格式(位于FPU外部)。这种方式通常会产生更加准确的结果,与专门设计一个能够支持十进制算术运算的单独协处理器相比,这种方式节省了所需的硅。
也许个人计算机上最重要的数据类型是字符。术语“字符”是指人或者机器可读的符号,一般是非数字实体。具体而言,字符通常是指可以通过键盘键入的任何符号(包括可能需要多个按键才能生成的某些符号),或者在视频显示器上能够显示的符号。字母、标点符号、数字、空格、制表符、回车符(ENTER)、其他控制字符以及其他的特殊符号都是字符。
注意: 数字字符与数值不同:字符“1”与数值1不同。在计算机中,通常对数字字符(“0”、“1”、…、“9”)与数值(0~9)采用两种不同的内部表示形式。
大多数计算机系统使用一个字节或两个字节的序列将各种字符编码为二进制形式。Windows、MacOS、FreeBSD和Linux使用ASCII或者Unicode编码表示字符。本节将讨论ASCII字符集和Unicode字符集,以及MASM提供的字符声明工具。
ASCII字符集将128个文本字符映射为0~127(0~7Fh)之间的无符号整数值。虽然字符到数值的精确映射可以是任意的并且不重要,但是使用标准化的编码进行映射非常重要,因为当需要与其他程序和外围设备通信时,通信双方需要使用相同的“语言”。ASCII是一种几乎所有人都达成一致的标准化编码:如果使用ASCII编码65表示字符“A”,那么,无论何时向一个外部设备(例如,打印机)传输数据,外部设备都会正确地将该值解释为字符“A”。
尽管存在一些严重不足,但是ASCII数据已经成为跨计算机系统和程序的数据交换标准
。大多数程序可以接受ASCII数据,同样,大多数程序可以生成ASCII数据。因为我们将在汇编语言中处理ASCII字符,所以研究ASCII字符集的布局并记住一些关键的ASCII编码(例如,0、A、a等)是非常必要的。
ASCII字符集可以分为4组,每组32个字符。第一组32个字符[ASCII编码0~1Fh(31)]构成一个特殊的非打印字符集,即控制字符。我们之所以把这些字符称为控制字符,是因为它们执行各种打印/显示的控制操作,而不是显示符号。示例包括回车符,用于将光标定位到当前字符行的左侧
;换行符,将光标在输出设备中向下移动一行;退格符,将光标向左移回一个位置。
遗憾的是,不同的控制字符在不同的输出设备上执行不同的操作,输出设备之间几乎没有统一的标准。为了准确了解控制字符如何影响特定设备,用户需要查阅设备相关的使用手册。
第二组32个ASCII字符编码包含各种标点符号、特殊字符和数字字符。这一组中最著名的字符包括空格字符(ASCII码值为20h)和数字字符(ASCII码值为30h~39h)。
第三组32个ASCII字符包含大写字母字符。大写字母A到Z的ASCII码值为41h~5Ah(65到90)。因为只有26个字母字符,所以剩下的6个编码代表各种特殊符号。
第四组也是最后一组32个ASCII字符编码表示小写字母、5个附加特殊符号和1个控制字符(具于删除功能)。小写字母使用ASCII码值61h~7Ah。将大写字母和小写字母的ASCII编码转换为二进制,就会发现同一字母的大写字符与小写字符仅在一个位上有区别。例如,考虑图2-25中的大写字母E和小写字母e的字符编码。
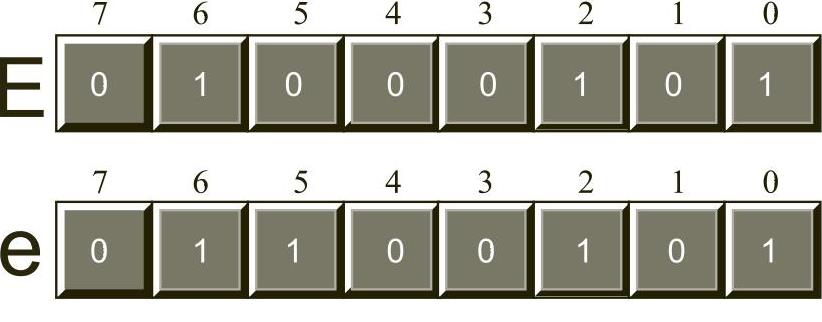
图2-25 大写字母E和小写字母e的ASCII码值
这两个ASCII码值唯一不同的是第5位。所有大写字母第5位的值始终为0,所有小写字母第5位的值始终为1。我们可以使用这个事实实现大写字母和小写字母的快速转换。如果有一个大写字母,则可以将其第5位的值设置为1,从而强制把它转换为小写字母。如果有一个小写字母,则可以将其第5位的值设置为0,从而强制把它转换为大写字母。只需反转第5位,就可以实现字母字符在大写和小写之间的转换。
实际上,如表2-13所示,第5位和第6位决定了字符处于ASCII字符集中的哪一组。
例如,我们可以将第5位和第6位的值设置为0,从而将任何大写、小写(或对应的特殊)字符转换为控制字符。
接下来请考虑表2-14中给出的数字字符的ASCII编码。
对于任意一个数字字符,其ASCII码的低阶半字节恰恰等于该字符等价的二进制值。通过去掉数字字符编码的高阶半字节(即将高阶半字节设置为0),可以将该编码转换为相应的二进制表示形式。相反,只需将高阶半字节设置为3,就可以将0~9范围内的二进制数值转换为相应的ASCII字符。可以使用逻辑与操作将高阶位强制设置为0,也可以使用逻辑或操作将高阶位强制设置为0011b(3)。
表 2-13 ASCII 编码的分组情况

表 2-14 数字字符的 ASCII 编码
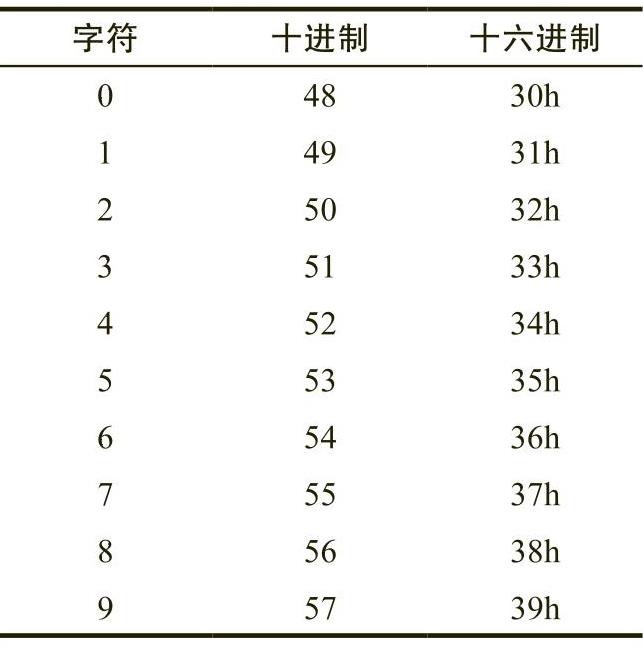
遗憾的是,对于包含数字字符的字符串,我们无法通过简单地从该字符串的每个数字中去掉高阶半字节,来将其转换为等效的二进制值。以这种方式转换123(31h 32h 33h)将产生3个字节——010203h,但123的正确值为7Bh。上一段中描述的转换仅适用于单个数字字符。
MASM为汇编语言程序中的字符变量和字面量提供了支持。MASM中的字符字面常量有以下两种形式:一种是包含在单引号内的单个字符,另一种是包含在双引号内的单个字符,如下所示:
'A'"A"
两种形式代表相同的字符“A”。
如果希望在字符串中包含单引号或双引号,则需要使用另一个字符作为字符串分隔符。例如:
'A"quotation"appears within this string'
"Can't have quotes in this string"
与C/C++语言不同,MASM对单字符对象和字符串对象使用相同的分隔符,并且不使用分单个字符区分字符常量和字符串常量。一个字符字面常量在两个双引号(或单引号)之间只有一个字符,而字符串字面常量在两个双引号(或单引号)之间有多个字符。
在MASM程序中,为了声明字符变量,需要使用byte数据类型。例如,以下示例演示了如何声明一个名为UserInput的变量:
.data
UserInput byte?
上述声明保留一个字节的存储空间,可用于存储任何字符值(包括8位扩展ASCII/ANSI字符)。还可以按如下方式初始化字符变量:
.data
TheCharA byte 'A'
ExtendedChar byte 128;大于7Fh的字符码
因为字符变量是8位对象,所以可以使用8位寄存器对其进行操作。可以将字符变量移动到8位寄存器中,也可以将8位寄存器的值存储到字符变量中。
ASCII码存在的问题是它只支持128个字符的编码。即使将定义扩展到8位(就像IBM在原始PC上所做的那样),我们也只能使用最多256个字符。这对于现代的多国/多语言应用程序而言实在是太少了。早在20世纪90年代,就有几家公司开发了一种ASCII扩展,称为Unicode,它使用两个字节的字符大小进行编码。因此,(原始)Unicode最多支持65536个不同字符的编码。
遗憾的是,尽管最初的Unicode标准是经过深思熟虑的,但系统工程师发现,即使65536个符号也不够用。如今,Unicode定义了1112064个可能的字符,使用可变长度字符格式进行编码。
Unicode码位(code point,又被称为码点)是一个整数值,Unicode将其与特定字符符号相关联。Unicode码位的约定是指定十六进制形式的值,值前面有一个“U+”前缀。例如,U+0041是字符A的Unicode码位(41h是字符A的ASCII码值。U+0000~U+007F范围内的Unicode码位对应于ASCII字符集)。
Unicode标准所定义的码位范围为U+000000到U+10FFFF。10FFFFh为1114111,这是Unicode字符集中1112064个字符的大部分来源,其余2047个码位被保留,用作代理项(surrogate),代理项是Unicode的扩展。
Unicode标准将此范围划分为17个多语言平面(multilingual plane),每个语言平面最多支持65536个码位。6位十六进制码位中的高阶2位用于指定多语言平面,其余4位用于指定平面内的字符。
平面0(U+000000到U+00FFFF)大致对应于原始的16位Unicode定义,Unicode标准将其称为基本多语言平面(Basic Multilingual Plane,BMP)。平面1(U+010000至U+01FFFF)、平面2(U+020000至U+02FFFF)和平面14(U+0E0000至U+0EFFF)为补充(扩展)平面。Unicode为将来的扩展保留了平面3~平面13,将平面15和平面16用于用户自定义的字符集。
很显然,在BMP之外表示Unicode码位需要额外的2个字节。为了减少内存的使用,Unicode在BMP中(特别是UTF-16编码)使用2个字节表示Unicode码位,在BMP外使用4个字节表示码位。在BMP中,Unicode保留代理项码位(U+D800-U+DFFF)以指定BMP后面的16个平面,图2-26显示了其编码。
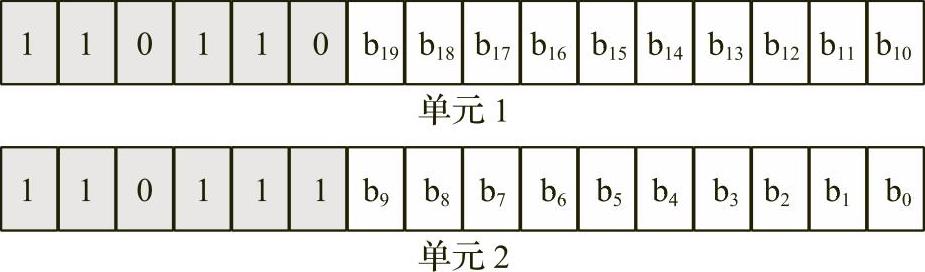
图2-26 Unicode平面1到16的代理项码位编码
请注意,这两个字(单元1和单元2)总是同时出现。单元1的值(高阶位为110110b)指定Unicode标量的高阶10位(b 10 至b 19 ),单元2的值(高阶位为110111b)指定Unicode标量的低阶10位(b 0 至b 9 )。因此,位b 16 到b 19 (加1)指定Unicode平面1到16,位b 0 到b 15 指定平面内的Unicode标量值。
Unicode标准从v2.0版本开始,支持21位字符空间,能够处理超过一百万个字符(尽管大多数码点仍保留供将来使用)。Unicode公司没有采用3字节(或者更糟糕的4字节)编码方式来允许更大的字符集,而是采用不同的编码方案,每种编码都有自己的优点和缺点。
UTF-32使用32位整数来保存Unicode标量
。UTF-32编码方案的优点是32位整数可以表示每个Unicode标量值(只需要21位)。使用UTF-32时,程序可以随机访问字符串中的每个字符(无须搜索代理项对),并且能够以常数时间(大部分情况下)完成操作。UTF
-
32明显的缺点是每个Unicode标量值需要4字节的存储空间(这是原始Unicode定义的2倍,也是ASCII字符的4倍)。
Unicode支持的第二种编码格式是UTF-16。顾名思义,UTF-16使用16位(无符号)整数来表示Unicode值。为了处理大于0FFFFh的标量值,UTF-16使用代理项对的编码方案来表示010000h~10FFFFh范围内的值。因为绝大多数有用的字符可以使用16位,所以大多数UTF-16字符只需要2个字节。对于需要代理项的罕见情况,UTF-16需要两个字(32位)来表示字符。
最后一种编码是UTF-8,毫无疑问,这是最流行的编码方案。UTF-8编码与ASCII字符集向上兼容。特别是,所有ASCII字符都有单字节表示(字符原始的ASCII编码,其中包含字符的字节高阶位为0)。如果UTF-8的高阶位为1,则UTF-8需要额外的字节(1~3个额外的字节)来表示Unicode码位。表2-15给出了UTF-8的编码模式。
表 2-15 UTF-8 编码

表中出现的 xxx …位是Unicode码位所占用的位。对于多字节序列,第一个字节包含高阶位,第2个字节包含下一个高阶位,依此类推。例如,一个由2个字节组成的序列“11011111b,10000001b”对应于Unicode标量0000_0111_1100_0001b(U+07C1)。
遗憾的是,MASM几乎不支持汇编语言源文件采用Unicode文本。幸运的是,MASM的宏工具提供了一种方法,允许我们在MASM中自己创建处理Unicode字符串的方法。有关MASM宏的更多详细信息,请参见第13章。在 The Art of 64-Bit Assembly 的Volume 2中还会重新讨论这个主题,该书花费了大量的篇幅描述如何强制MASM接受和处理源文件与资源文件中的Unicode字符串。
有关数据表示和布尔函数的一般信息,请考虑阅读作者编写的另一本书 Write Great Code 的Volume 1,或者任何一本数据结构和算法方面的教科书(所有的书店都有售)。
ASCII、EBCDIC和Unicode都是国际标准。有关扩展EBCDIC字符集系列的更多信息,请参考IBM的网站(http://www.ibm.com/)。ASCII和Unicode都是国际标准化组织(International Organization for Standardization,ISO)的标准,ISO为这两种字符集提供了相应的报告。通常情况下,获取这些报告需要付费,但读者也可以通过在互联网上按名称搜索ASCII和Unicode字符集,来查找有关这些字符集的大量信息。读者还可以通过Unicode官网(http://www.unicode.org/),阅读有关Unicode的信息。 Write Great Code 还包含有关Unicode字符集的历史、使用和编码这些额外信息。
1.十进制值9384.576代表什么含义(请以10的幂表示)?
2.将以下二进制值转换为十进制值:
a.1010
b.1100
c.0111
d.1001
e.0011
f.1111
3.将以下二进制值转换为十六进制值:
a.1010
b.1110
c.1011
d.1101
e.0010
f.1100
g.1100_1111
h.1001_1000_1101_0001
4.将以下十六进制值转换为二进制值:
a.12AF
b.9BE7
c.4A
d.137F
e.F00D
f.BEAD
g.4938
5.将以下十六进制值转换为十进制值:
a.A
b.B
c.F
d.D
e.E
f.C
6.以下数据类型各包含多少个二进制位?
a.Word
b.Qword
c.Oword
d.Dword
e.BCD数字
f.Byte
g.Nibble
7.以下数据类型各包含多少个字节?
a.Word
b.Dword
c.Qword
d.Oword
8.以下数据类型分别可以表示多少个不同的值?
a.Nibble
b.Byte
c.Word
d.Bit
9.表示一个十六进制数字需要多少个二进制位?
10.一个字节中的位是如何编号的?
11.一个字的低阶位的编号是什么?
12.一个双字的高阶位的编号是什么?
13.计算以下二进制值的逻辑与运算结果:
a.0 and 0
b.0 and 1
c.1 and 0
d.1 and 1
14.计算以下二进制值的逻辑或运算结果:
a.0 or 0
b.0 or 1
c.1 or 0
d.1 or 1
15.计算以下二进制值的逻辑异或运算结果:
a.0 xor 0
b.0 xor 1
c.1 xor 0
d.1 xor 1
16.对于什么值,逻辑非操作与逻辑异或结果相同?
17.可以使用哪个逻辑操作将位串中的位强制设置为0?
18.可以使用哪个逻辑操作将位串中的位强制设置为1?
19.可以使用哪个逻辑操作将位串中的所有位反转?
20.可以使用哪个逻辑操作将位串中的指定位反转?
21.哪一条机器指令可以反转寄存器中的所有位?
22.8位的值5(00000101b)的补码是什么?
23.有符号的8位值-2(11111110)的补码是什么?
24.以下哪些有符号8位值为负值?
a.1111_1111b
b.0111_0001b
c.1000_0000b
d.0000_0000b
e.1000_0001b
f.0000_0001b
25.哪一条机器指令对寄存器或内存位置中的值取补码?
26.以下哪一个16位的值可以正确地符号缩减为8位?
a.1111_1111_1111_1111
b.1000_0000_0000_0000
c.000_0000_0000_0001
d.1111_1111_1111_0000
e.1111_1111_0000_0000
f.0000_1111_0000_1111
g.0000_0000_1111_1111
h.0000_0001_0000_0000
27.哪一条机器指令等价于高级程序设计语言的goto语句?
28.MASM语句标签的语法是什么?
29.条件码有哪些标志位?
30.JE是哪一条用于测试条件码的指令的同义词?
31.JB是哪一条用于测试条件码的指令的同义词?
32.哪些条件跳转指令是基于无符号比较结果实现传输控制的?
33.哪些条件跳转指令是基于有符号比较结果实现传输控制的?
34.SHL指令是如何影响零标志位的?
35.SHL指令是如何影响进位标志位的?
36.SHL指令是如何影响溢出标志位的?
37.SHL指令是如何影响符号标志位的?
38.SHR指令是如何影响零标志位的?
39.SHR指令是如何影响进位标志位的?
40.SHR指令是如何影响溢出标志位的?
41.SHR指令是如何影响符号标志位的?
42.SAR指令是如何影响零标志位的?
43.SAR指令是如何影响进位标志位的?
44.SAR指令是如何影响溢出标志位的?
45.SAR指令是如何影响符号标志位?
46.RCL指令是如何影响进位标志位的?
47.RCL指令是如何影响零标志位的?
48.RCR指令如何影响进位标志位的?
49.RCR指令如何影响符号标志位的?
50.左移位指令等价于哪一个算术运算?
51.右移位指令等价于哪一个算术运算?
52.当执行一系列浮点数的加、减、乘和除运算时,应该首先尝试其中哪个操作?
53.应该如何比较浮点数是否相等?
54.什么是标准化浮点数?
55.一个(标准)ASCII字符占用多少个二进制位?
56.ASCII字符0~9的十六进制表示是什么?
57.MASM使用什么分隔符来定义字符常量?
58.Unicode字符的三种常见编码是什么?
59.什么是Unicode码位?
60.什么是Unicode码平面?