
下载掌阅APP,畅读海量书库
立即打开



静态分析(Static Analysis)是基于词法分析、语法分析、语义分析、控制流分析、数据流分析、污点分析,静态地检查程序的逻辑结构及编码规范,检出程序描述、表示、规格等方面的错误及算法实现、故障处理、安全漏洞等方面的缺陷,是软件测试的基础。定理证明、类型推导、抽象解释、规则检查、模型检测、符号执行奠定了静态分析的理论基础。
定理证明 旨在根据消解原理,构建定理证明器,证明命题的永真性,但消解原理不能处理整数及有理数域上的运算,需借助判定程序,判别公式是否为定理,方能用于程序分析。 类型推导 是按一定规则,将编程语言中的数据划分为不同集合,利用推导算法分析得到程序变量及函数类型,适用于函数式程序设计语言。 抽象解释 是将抽象函数作用于指定抽象域,对程序属性进行检查,抽象域可以通过对具体的精确域模糊化得到,而具体的精确域可以通过求解程序语义的表达函数 F 的最小不动点 x = F ( x )得到,由于抽象函数作用的抽象域使得求解最小不动点的运算规模大幅度减小,利用解集合,能够很好地适用于静态分析。 规则检查 是基于规则检查分析系统,检查程序是否遵循相应规则,检出特定类型的编码规则类缺陷。规则检查分析系统由规则处理器和分析器组成,通过规则处理器将编码规则转换为分析器能够接收的内部表示,应用于程序分析。 模型检测 是通过遍历系统模型,验证系统性质,系统模型包括FSM或EFSM,模型检测的难点在于搜索算法的效率及如何避免状态空间爆炸。 符号执行 是使用符号值代替真实值作为程序输入,将运算过程逐语句或逐指令转换为数学表达式,生成基于控制流图的符号执行树,为每一条路径建立一系列以输入数据为变量的符号表达式,得到一个基于符号值函数输出的静态分析技术。
一般地,将静态分析划分为技术评审、代码走查、代码审查、桌面检查、逻辑覆盖、路径覆盖、符号执行等不同类型,但可以归结为基于模式和基于流的静态分析。基于模式的静态分析主要用于合规性验证及资源泄露、逻辑错误、API滥用、安全漏洞检查分析。基于流的静态分析是基于程序路径,通过控制流和数据流分析,检出诸如内存使用、缓冲区覆盖、空指针引用、静态条件、死锁等缺陷。当然,基于流的静态分析还可以绕过安全关键代码,如身份验证或加密代码路径,实现安全性检测。
不论哪种静态分析方法,通常都包括程序预处理、错误分析、报告生成三个阶段。静态分析技术架构由程序预处理器、错误分析器、报告生成器及数据库构成,如图5-1所示。
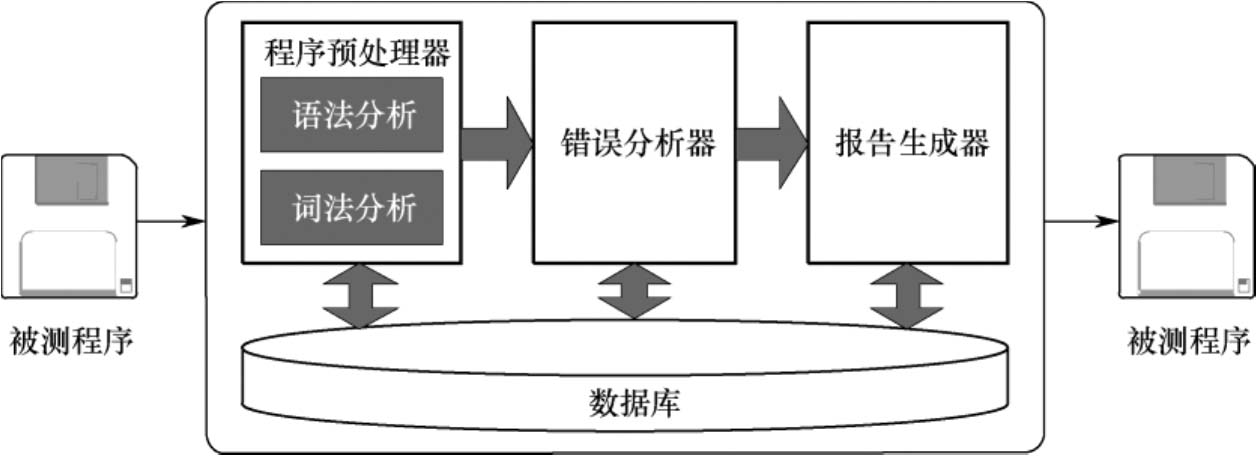
图5-1 静态分析技术架构
程序预处理器根据所采用的分析技术及逻辑覆盖算法,对程序进行词法和语法分析,生成抽象语法树、有限自动机、有向图等,以便程序描述、表示、规格等错误分析;错误分析器是依据规则,对处理结果进行分析,生成错误列表;报告生成器是依据分析结果,以文本或图表等形式输出静态分析报告;数据库以表格形式存储各种语言信息,记录程序变量类型、使用情况、各种标号及控制流、数据流等信息。根据数据库作用范围的不同,将表格分为全局表和局部表。全局表记录程序的全局变量、模块名、函数及过程调用关系等信息;局部表对应于程序的各个模块,记录模块信息,如标号引用、分支索引、变量属性、语句变量引用、数组或记录特性等。
词法及语法分析是静态分析的基础。基于规则段,词法说明文件定义需要识别的符号,规定识别后所需处理的内容。语法说明文件定义所支持的语法结构规则及其所对应的动作,其核心同样也是规则段。规则段定义输入流应满足的语法规则及相应的执行程序,由一条或多条文法规则组成。规则段的左边是正则表达式,右边是对应的动作,规定识别出正则表达式之后需要执行的程序。Lex和Yacc就是一款基于UNIX/Linux的词法和语法分析工具。Lex是一个基于词法分析器的自动生成程序,其输入是一个面向问题的用于字符匹配检查的高级说明文件,其输出是一个用普通语言书写的能够识别正则表达式的程序。
技术评审(Technical Review)是指由测试人员、开发人员、管理人员、用户代表、行业专家及相关方人员组成评审组,依据标准规范,使用编码模板,基于内部和外部质量要求,依据系统规格、需求规格、设计文档及编码规则等,对软件代码进行评审,检出逻辑结构、算法实现及故障处理等错误,然后对检出的缺陷进行分析讨论、定位并确认问题,分析问题产生的原因及其影响域,纠正问题并进行回归验证。技术评审是基于标准规范、领域知识、专家经验,在一致的需求驱动及统一模式下的静态分析过程活动,是保证软件质量的有效手段之一,不仅能够发现程序描述、表示及规格等方面的错误,确保代码与预先定义的开发规范、需求规格、设计文档的一致性,而且有助于正确理解文档的完整性、规范性。但不少人混淆了技术评审与软件测试的区别,加之技术评审过程及结果的不可量化,技术评审的效果常常受到质疑,使得技术评审工作不断弱化,流于形式。
代码走查(Code Walkthrough)是指在软件开发项目组内建立代码标准的集体阐述机制,在由系统分析人员、架构设计人员、编码实现人员、相关方人员对编码实现思路进行充分沟通交流的基础上,进行走查策划,编制走查计划和代码走查单,从开发库中提取代码,根据代码走查单阅读代码,通过模拟运行及集中分析、讨论、辩论等方式审查代码,确定并排除代码错误的过程活动。对于可靠性、安全性攸关的软件系统,在提交代码到版本库即正式测试之前,进行代码走查具有重要意义。
代码走查并非持续集成之前开展的代码规范检查,而是根据需求规格,验证编码实现与需求规格、软件设计的符合性和一致性。代码中的绝大多数错误尤其是编码规范等问题,一般能够通过工具扫描检出,并且在冒烟测试过程中也能够被轻易发现,所以有人认为代码走查是浪费资源。到底是不是如此呢?事实上,有些程序问题尤其是一些恶性缺陷,往往难以通过逻辑覆盖等方式检出。例如,图5-2所示代码,用于调用dubbo服务接口,当连接一个系统时,传入的枚举UNSETTLED_BILL_REPAY表示偿付未出的账单,但这段代码则错误地实现为偿还已出账单的service层。此问题可能是在系统集成时,开发人员疏于沟通、存在理解偏差导致错误调用造成的。
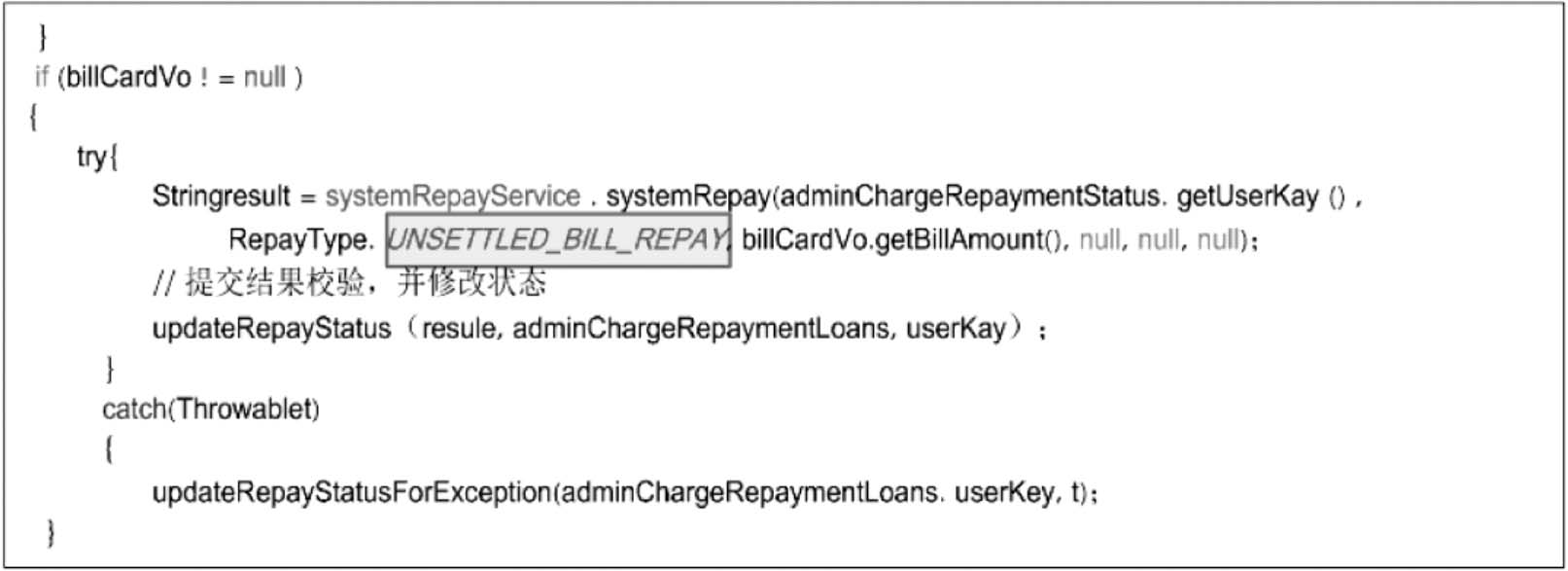
图5-2 用于调用dubbo服务接口的代码
对于图5-2所给出的程序实现所存在的服务接口调用错误,即便能够通过代码审查等方法发现,也必然存在一定的偶然性。显而易见,在开发过程中,通过代码走查,基于相关方的沟通交流,能够有效地发现这类问题。这里,通过图5-3所示代码片段,进一步说明代码走查的效果及意义。

图5-3 代码走查示例
XYZ_TO_BHL(float DX_x,float DY_y,float DZ_z,float *Glon,float *Glat,float *Gh)中,当地心直角坐标X趋于零、Y不等于0时,赋值错误。通常,这种错误往往难以通过代码审查发现。但如果对照设计要求,仔细分析,透彻理解“当
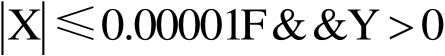 时,
时,
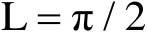 ;且
;且
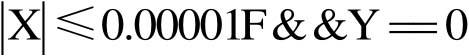 时,
时,
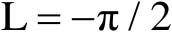 ,地心直角坐标到地理坐标的转换为
,地心直角坐标到地理坐标的转换为
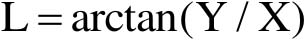 ”这一设计要求时,通过代码走查,就能够非常容易地发现此问题。
”这一设计要求时,通过代码走查,就能够非常容易地发现此问题。
当然,代码走查并非易事。需要测试人员具有丰富的软件开发经验和深厚的领域知识积淀,更需要一丝不苟的工作作风和良好的团队沟通协作精神。
代码审查(Code Review)就是依据编码规则,通过人工、自动或人工与工具相结合,扫描代码,测试代码的逻辑结构、安全问题、脱敏问题、代码冗余、编码风格等是否符合软件设计及编码规则等要求,检出功能实现问题及代码缺陷、格式化字符串攻击、竞争危害、内存泄漏、缓存溢出等安全隐患,同时对编码规范、性能优化等进行评价,有利于改善代码质量及软件的可测试性、可维护性、保障性。代码审查所关注的问题是软件质量的基点,也是团队交流的起点,包括正式代码审查和轻量级代码审查。
正式代码审查是基于正式、规范的流程,由测试人员会同开发人员成立审查组,进行审查策划,编制代码审查单,对代码进行分阶段审查,其审查策划、审查准备及实施过程中需要投入大量资源,专业的代码分析工具或集成开发环境下的测试工具,能显著提升审查效率,为开发过程提供编程规范的兼容反馈。范根检查法是最具代表性的正式代码审查实践之一,它为试图检出代码缺陷提供了一种结构化流程,用于发现编码规范问题和设计缺陷。
轻量级代码审查是与软件开发过程中同步进行的审查方法,可分为瞬时代码审查(结对编程)、同步代码审查(及时代码审查)、异步代码审查(工具支持的代码审查)、偶尔代码审查及基于会议的代码审查。结对编程是广泛使用的轻量级代码审查实践,是极限编程中常见的敏捷开发方法,由两名编码人员在同一开发环境中并行实施,一个编写程序即所谓“驾驶员”,完成战术性的编程任务,另一个即“观察员”或“导航员”,同步进行代码审查,把握战略方向,发现问题并提出改进意见。当然,如果“驾驶员”和“导航员”能够有的放矢地互换角色,进行交叉检查,会呈现意想不到的效果。
代码审查并不验证需求规格等顶层技术文件的正确性和符合性,无法验证业务逻辑的正确性、功能的完整性及代码中遗漏的路径和数据敏感性错误,存在着一定的局限性。
5.1.4.1 审查组织
审查人员、开发人员及相关人员联合组成审查组。开发人员依据设计文档,采用诸如从前端到后台,从Web层到DAO层的方式,基于开发设计重点、可能存在的问题,详述代码实现及相关逻辑。
审查人员进行审查策划,编制代码审查单进行代码审查,发现并记录问题,同开发人员进行沟通确认,修改完毕之后,进行代码复审,确认所发现的缺陷得到有效处置,编制问题报告单及代码审查报告,将审查过程中发现的缺陷更新到《代码规范》等文档中,对于特别重要或典型问题应报告给质保人员及相关人员。通过复审后,更新审查结果,进行代码备份与版本控制。
代码审查通过之后,一般不对代码再行修改。任何通过审查的代码,修改后必须重新组织实施审查。
5.1.4.2 进入条件
(1)代码结构完整、语法正确、注释清晰、符合相关编码规范、通过编译。
(2)日志代码完整,业务日志、系统日志相互分离,已进行脱敏处理,状态变更清晰明确。
(3)项目引用关系明确,依赖关系清晰,配置文件描述准确。
(4)测试代码覆盖全部分支和流程,能够使用相应工具进行覆盖性检查。
5.1.4.3 审查内容
代码审查包括基本规范、程序逻辑、设计实现三个方面。
(1)代码审查的通用方法所关注的是编码风格,如变量、参数等是否声明为final,以及函数变量定义与调用代码或函数开始代码是否太相似。
(2)域、常量、变量、参数、类等名称是否符合命名规则,如命名方式是否符合驼峰规则,命名是否太短等。
(3)被审查代码是否通过覆盖测试。
当然,代码审查需要综合考虑各种因素,优先级分配和持续检查是一个非常烦杂的问题。
1.基本规范审查
整洁、优雅、高效的代码令人心情愉悦。基于人工智能的代码审查让我们充满期待,但能否透彻地理解客户模糊或极具情感的需求尚待时日。代码可能永远需要人来书写,不确定性不可避免。代码规范问题不是洁癖,是软件质量的基本问题,是软件文明的基础。美国软件工程大师Robert C.Martin在《代码整洁之道》一书中提出了一个极具影响力的观点:代码的好名字本身就解释了最重要的信息。干净优雅的代码让人心生敬畏!
代码不规范,亲人两行泪!2018年9月19日,因同事在编码中未遵循驼峰命名规则,使用括号换行、git push-f参数强行覆盖仓库及未进行注释等原因,美国程序员安东尼·汤恼羞成怒,向四名同事开枪射击,致使一名同事重伤,自己被击毙。虽然这是一幕惨剧,但却有人将安东尼·汤誉为“用生命维护代码的程序员”。
现实中,命名不规范、成员变量不能表示其含义、函数名不能反映其功能、大量使用if else逻辑、一个方法包括成百上千行代码、注释缺失或不规范等问题俯拾皆是,从源头埋下质量隐患。编程规范审查就是依据编码规则,审查代码与标准规范的符合性,检出诸如命名不规范、magic Number、System.out等问题。这里,以如下代码为例,讨论基本规范审查的内容。

依据编码规范,对上述这段简短代码进行审查,即可发现上述代码存在如下问题:
(1)成员变量命名不规范。
(2)成员变量访问权限声明方式不一致。
(3)代码之间的空行不符合规范。
(4)部分成员变量只有声明,没有进行初始化。
(5)未进行必要的注释。
关于软件编码规范问题,已有大量标准规范、技术文献进行了详细的定义,在此不赘述。
2.程序逻辑审查
程序逻辑审查是指对代码的循环、递归、线程、事务等逻辑结构的合理性及异常处理、性能、重复代码、可优化代码、无效代码等进行测试的过程活动。在代码级别检查用户界面操作逻辑是否正确、布局是否合理、用户提示是否简洁明了,是否存在重复或无用功能等。现以如下代码为例,说明程序逻辑审查的内容。

对上述代码的程序逻辑进行审查发现:该代码异常捕获后未进行处理,未将异常抛出,存在异常淹没问题。
错误处理和异常捕获是程序中处理错误和异常情况的重要机制。对于不同的编程语言,异常处理的实现方法有所不同。例如,C++使用如下try-catch实现异常处理。

3.设计实现审查
做人要有原则,写代码也要讲原则。否则,脱离原则的播放自由必将在代码中埋下隐患。设计实现审查的目的就是检查代码或项目是否遵循相应的设计原则,如单一职责原则、开闭原则、里氏替换原则、接口隔离原则和依赖倒置原则等,确保代码的可读性、可扩展性、可测试性、可重用性、可维护性。软件设计原则如图5-4所示。
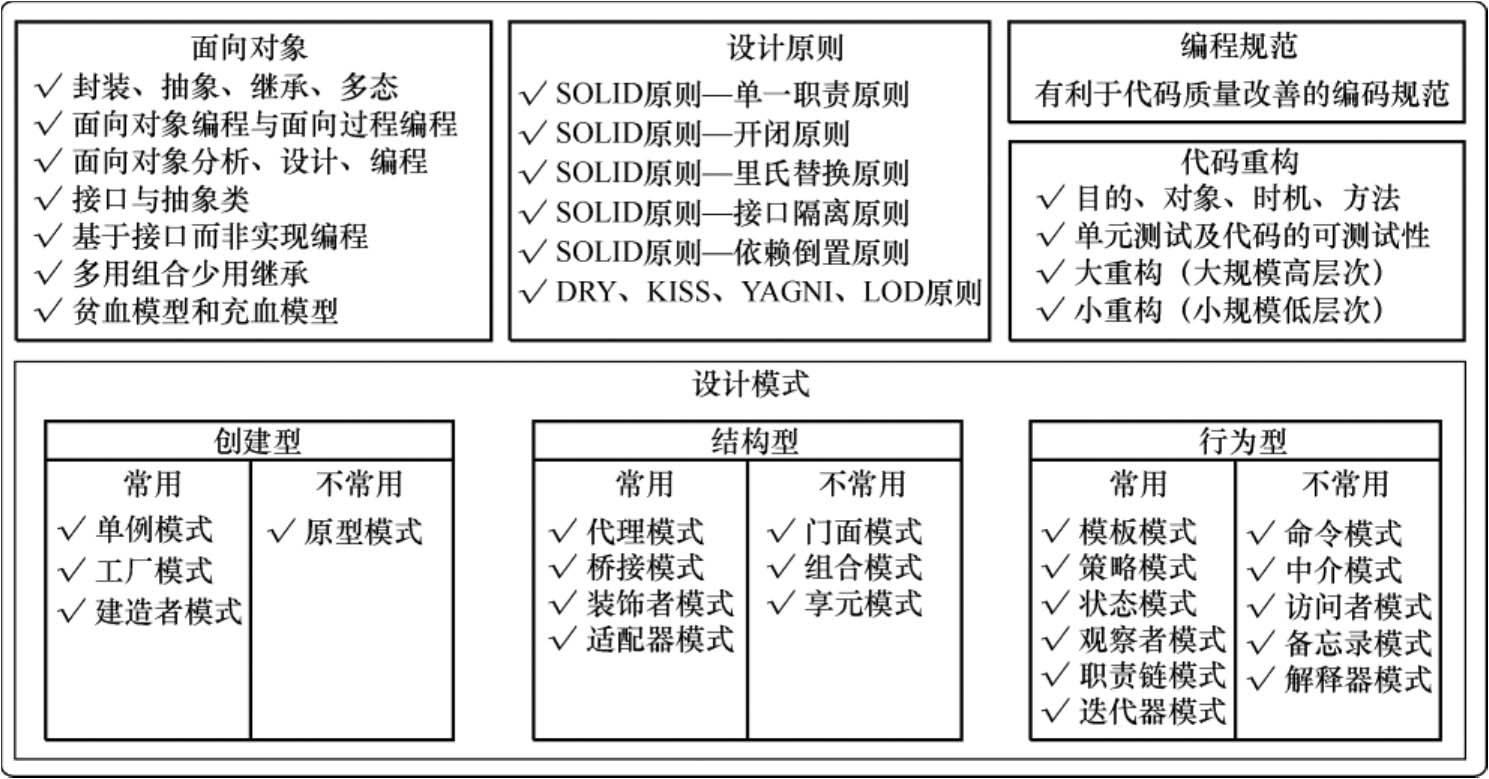
图5-4 软件设计原则
设计实现审查是对软件层次结构划分的合理性,用户界面(User Interface,UI)层、逻辑层、数据层、组件层的清晰性及性能设计、安全性设计、维护性设计、健壮性设计等的合理性进行审查的过程活动。审查内容包括但不限于:
(1)代码是否与整体架构匹配?
(2)设计模式是否合适?是否遵循SOLID原则,即单一职责原则(Single Responsibility Principle)、开闭原则(Open Closed Principle)、里氏替换原则(Liskov Substitution Principle)、接口隔离原则(Interface Segregation Principle)、依赖倒置原则(Dependency Inversion Principle),以及领域驱动或其他设计模式?
(3)若代码库采用混合标准或设计风格,代码是否符合规定的风格?
(4)代码迁移是按正确方向进行还是效仿那些可能被淘汰的旧代码?
(5)代码是否处于正确位置?如果代码执行与顺序相关,是否按顺序执行?
(6)是否重用相关代码?如何根据保持简洁原则(You Ain’t Gonna Need It,YAGNI)权衡重用内容?
(7)是否使用开源代码?开源代码是否遵循开源协议?
(8)如果包含冗余代码,是重构为更加可重用部分还是在此阶段能接受这种冗余?
其中,代码功能审查是设计审查的重点。审查内容包括但不限于:
(1)代码实际工作是否符合预期?
(2)测试代码是否满足约定要求?对于未覆盖的代码,是否引入不可避免的性能问题,如不必要的数据调用或远程服务?
(3)是否包含错误,如使用错误变量进行检查,或将or误用为and?
(4)展示给用户的消息是否通过检查且准确无误?
(5)是否存在潜在的安全问题?
(6)是否需要创建公共文档或修改现有帮助文档?
(7)是否存在导致产品崩溃的明显错误?
(8)代码是否会意外指向测试数据库,是否存在应替换为真正服务的硬编码存根代码?
5.1.4.4 审查范围
1.完整性
(1)是否完整实现软件设计规定的功能、性能、接口、流程等内容?
(2)是否包含业务日志、系统日志、异常日志等所需日志?日志内容是否完整?日志文件配置是否正确?
(3)是否使用缓存?配置信息是否正确且可配置?
(4)是否存在未定义或未引用到的变量、常数或数据类型?
2.一致性
(1)代码逻辑是否符合设计要求?
(2)格式、符号、结构等风格是否保持一致?
3.正确性
(1)软件设计规定的功能、性能、接口、流程等是否准确实现?
(2)变量定义和使用是否准确?
(3)程序调用是否使用正确的参数?
(4)是否符合相关编码规范?
(5)注释是否完整准确?
4.可修改性
(1)常量是否易于修改?如配置、定义为类常量及专门常量类定义等。
(2)是否包含交叉说明或数据字典?
(3)是否存在描述程序对变量和常量的访问?
(4)除严重异常处理外,代码是否只有一个出口和一个入口?
5.可预测性
(1)开发语言是否具有定义良好的语法和语义?
(2)能否避免依赖于开发语言缺省提供的功能?
(3)是否无意中陷入了死循环?
(4)能否避免无穷递归?
6.健壮性
是否采取数组边界溢出、被零除、值越界、堆栈溢出等检测及防护措施?
7.结构性
(1)每个功能是否仅作为一个可辨识的代码块存在?
(2)循环是否只有一个入口?
8.可追溯性
(1)程序标识是否唯一?
(2)是否存在一个交叉引用框架用于代码和开发文档之间的映射和追踪?
(3)是否包括一个修订历史记录,用于代码修改及原因记录?
(4)是否对所有安全功能进行了标识?
9.可理解性
(1)字段、变量、参数、函数、类等命名,能否反映所定义的对象及属性?
(2)是否具有良好的可阅读性?通过阅读代码能否领会或理解设计要求?是否使用统一的格式化技巧,如缩进、空白等增强代码的清晰度?命名规则定义是否采用便于理解、记忆、反映类型等方法?
(3)是否为每个变量定义了合法的取值范围?算法实现是否同数学模型一致?是否存在影响算法精度的约减或取舍?
(4)异常错误消息是否易于理解?
(5)难以理解的代码是否进行了备注、评论或使用易于理解的测试用例覆盖?
(6)注释能否清晰地描述每个子程序,当使用不明确或不必要的复杂代码时,是否进行了清晰、准确的注释?
(7)能否理解测试目的?测试是否覆盖绝大部分情况、常见情况、异常情况以及未考虑到的情况?
10.可验证性
(1)实现技术是否便于测试?
(2)测试代码是否正确且覆盖所有流程?
动态测试就是运行程序,执行测试用例,验证测试输出与预期结果的一致性和符合性,包括功能确认、接口测试、覆盖分析、性能分析、内存缺陷测试等。究其本质,动态测试是一种测试用例设计方法,可以直接使用UML图产生或设计测试用例,将基于经验的测试用例设计方法作为系统化测试的补充。本书将在后续章节对动态测试展开详细论述。这里,仅仅为了与静态分析进行比较而简述之。
功能确认与接口测试包括程序的基本功能、图形用户界面功能、数据一致性、开发环境配置、过渡迁移能力、代码导航等功能验证确认以及函数调用关系、函数接口、编程接口、单元接口、局部数据结构、重要执行路径、错误处理路径覆盖及影响软件功能、接口等边界条件验证确认。覆盖分析是通过扫描或观察软件代码,验证函数调用关系、行、分支、类、方法、语法分析树等的覆盖能力以及软件设计模型验证能力,包括控制流和数据流覆盖。控制流覆盖包括语句、判定、条件、判定−条件组合、条件组合、修正条件判定及路径等覆盖;数据流覆盖是选择一组满足变量的定义与引用间的某种关联关系实体以及一组实体的有限路径,包括Rapps、Weyuker、Ntafos、Ural、Laski、Korel等标准,关注程序中某个变量从声明、赋值到引用的变化情况,是路径覆盖的变种。性能分析是对资源容量、数据处理能力、网络通信传输效率、并发吞吐、文档存取、图形界面操作效率等进行测试,验证其性能指标是否满足规定的要求,改进软件性能瓶颈。内存缺陷测试是通过测试软件的内存使用情况,发现内存分配、非正常使用以及内存泄漏等错误,定位内存缺陷的上下文状况,确定发生错误的原因。
动态测试是在测试平台或目标环境中运行软件。但在单元测试、集成测试等低级别测试阶段,程序尚不能单独运行,需要将其集成到动态测试平台,构成可执行程序后再执行测试。图5-5展示了一个动态测试平台的构成及工作原理。
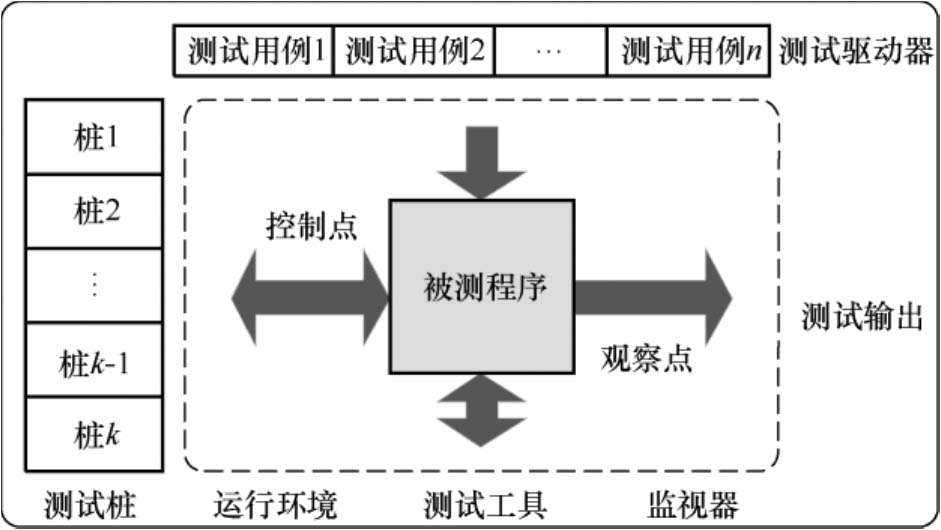
图5-5 动态测试平台的构成及工作原理
测试驱动器和桩的组合构成动态测试平台。桩用于模拟程序中由测试对象调用部分输入/输出的行为,驱动器用于模拟程序中调用被测程序的部分,为测试对象提供输入数据。
至此,读者不禁会问,怎么会有如此之多的静态分析方法呢?它们之间有什么关系?事实上,静态分析方法远不止这些。上述静态分析方法一个比一个正式,参与人员逐渐增多,测试机构也从以内部为主转向第三方测试机构。这里,从参与人员、是否生成测试大纲和报告以及正式程度三个维度,对静态分析方法进行比较,如表5-1所示。
表5-1 静态分析方法比较

在实际工作过程中,不必被概念所左右,无须纠结于如何区分以及到底是代码走查、代码审查还是技术评审,而是应该根据实际情况选择静态分析方法。
软件测试界百花齐放,各种静态分析工具如雨后春笋般地涌现,如语义缺陷检测工具Klockwork、编码规则检测工具LDRA Testbed、通过状态机语言自定义时序规则实现静态分析扩展的Meta-Compilation、安全漏洞检测工具Fortify等得以广泛应用,强有力地支持和促进了静态分析的最佳实践。但无论是基于技术视角还是工程视角,无论是基于工程实用性还是分析结果的可信度,现有静态分析技术及工具尚不足以解决目前所存在的问题。一方面,抽象解释、值依赖分析、符号执行通过数学约束求解,进行路径约减或可达性分析,促进静态分析技术向模拟执行技术方向发展,降低缺陷漏报、误报率。另一方面,在一个开放融合的平台上,集成不同的静态分析工具,实现静态分析集成化以及静态分析与动态测试的综合化,静态测试与综合分析一体化,进一步降低缺陷漏报、误报、误判率,提高静态分析质量和静态分析的可信度。此乃综合测试、一体化测试的重要发展方向。