
下载掌阅APP,畅读海量书库
立即打开



函数式编程是一种编程范式,范式是指一种我们可以遵循的代码编写风格。当我们说“我们在进行函数式编程”时,我们必须遵循一些简单的规则,这些规则定义了函数式编程。
函数式编程范式的核心元素是纯函数和不可变对象。我们将在下一节中解释这些概念。
并非所有的编程语言都能很好地支持函数式编程。例如,C语言就没有很好地支持它。另一方面,有一些语言,比如Haskell,是纯函数式的,这意味着你只能编写函数式风格的代码。Python并没有设计成一种函数式语言,但它确实支持函数式编程。
让我们来学习一下纯函数。
让我们快速复习一下Python函数的语法:

函数的定义从关键字def开始,后面是函数的名称和括号内的输入参数。冒号(:)标记函数头的结束。函数的主体代码需要缩进一级。
在函数式编程范式中,函数与其数学定义相似:输入到输出的映射。一个函数是纯函数,当且仅当:
❍输入相同时,输出始终相同;
❍没有副作用。
当该函数修改函数体以外的数据,或者修改函数的输入时,就会产生副作用。纯函数永远不会修改其输入参数。例如,以下函数是纯函数:

给定相同的输入点p和q,输出的向量总是相同,并且在函数体之外的任何东西都没有被修改。相比之下,以下代码是make_vector的“不纯”版本:

这个代码使用last_point的共享状态,该状态在每次调用make_vector时都会改变。这种改变是该函数的一个副作用。函数返回的向量依赖于last_point的共享状态,因此对相同的输入点,该函数不会返回相同的向量。
正如前面的例子所示,函数式编程的一个关键特性是不可变性。如果某样东西不随时间变化,那么它就是不可变的。如果决定以函数式编程的方式编写代码,我们必须避免可变数据,使用纯函数对程序进行建模。
让我们来看一个例子。假设,我们使用字典在平面上定义了一个点和向量:

如果想计算用向量移动该点后所生成的点,我们可以用函数式编程的方式,用函数创建一个新点。示例如下:

这个函数是纯函数:给定相同的点和向量作为输入,得到的位移点总是相同,而且函数处理的数据没有任何改变,也包括函数参数。
运行这个函数,将之前定义的point和vector传入,结果如下:

与之相反,非函数式编程的解决方法可能需要使用如下函数来改变原来的点:

这个函数修改了作为参数输入的point,违反了函数式编程的关键规则。
请注意,函数名称中使用了in_place,这是一种常用的命名约定,它意味着原对象将被修改。我们将在全书中遵循这种命名约定。
现在,让我们看看使用displace_point_in_place函数会发生什么:

如你所见,函数没有返回任何东西,这是非纯函数的标志,因为函数发挥作用时,必然在某个地方改变了某些东西。在本例中,“某些东西”是点,其坐标已被更新。
函数式风格的一个重要优点是,通过恪守数据结构的不可变性,我们可以避免意料之外的副作用。当修改某个对象时,你可能并不知道代码中引用该对象的所有位置。如果有其他部分代码依赖于该对象的状态,就可能出现难以预料的副作用。因此,在对象发生改变之后,程序的行为可能与预期的不同。这类错误非常难发现,甚至可能需要数小时的调试。
在项目中尽量减少可变对象的数量,可以使其更可靠,更不容易出错。
现在让我们来看看一类特殊的函数——lambda函数,它在函数式编程中起着关键作用。
早在20世纪30年代,一位名叫阿隆佐·邱奇(Alonzo Church)的数学家发明了lambda演算——一种关于函数及其如何应用于参数的理论。lambda演算是函数式编程的核心。
在Python中,lambda函数是一种匿名的、通常只有一行代码的短函数。当把函数作为参数传递给其他函数时,lambda函数非常有用。
在Python中定义lambda函数需要使用关键字lambda,后面跟着参数(用逗号分隔)、冒号和函数的表达式:

表达式的结果就是返回值。
一个对两个数字进行求和的lambda函数可以写成如下:

这相当于如下的常规Python函数:

lambda函数将在接下来的章节中出现;我们将看到它是如何在几种场景中被使用的。最常使用lambda的地方是将其作为filter、map和reduce函数的参数,我们将在2.1.6节中对此进行探讨。
高阶函数是指输入参数为一个(或一组)函数或返回值为函数的函数。
让我们分别看看这两种情况的例子。
假设我们想写一个函数,它可以多次执行另一个函数。我们可以这样实现:

如你所见,repeat_fn函数的第一个参数是另一个函数,它被重复执行,执行次数由第二个参数给出。然后,我们定义了另一个函数say_hi,它会在屏幕上输出字符串“Hi there!”。调用repeat_fn函数并传入say_hi的结果是屏幕上的五个问候语。
我们可以使用一个匿名的lambda函数来重写这个例子:

lambda函数使我们不必再定义一个函数来输出信息。
让我们来看看一个返回另一个函数的函数。假设我们想要定义一个验证函数,以验证一个字符串是否包含某些字符序列。我们可以编写一个名为make_contains_validator的函数,它接受一个序列并返回一个函数,来验证字符串是否包含该序列:

我们可以使用这个函数来生成验证函数,如下所示,

可以用这个函数来检查输入的字符串是否包含符号@:

高阶函数非常有用,之后会用到。
本书中用到的另一个技巧是在函数内部定义函数。这样做有两个很好的理由:一是,它允许内部函数访问外部函数的所有信息,而不需要将这些信息作为参数传递;二是,内部函数可以定义一些对外部世界不可见的逻辑。
使用常规语法即可在函数中定义函数。让我们看一个例子:

这里,inner_fn函数是在outer_fn函数内部定义的,因此,它不能从主函数的外部访问,只能从其内部访问。inner_fn函数可以访问outer_fn中定义的所有内容,包括函数参数。
当函数的逻辑变得复杂,且可以被分解时,在函数内部定义子函数很有用。当然,我们也可以将函数分解成同一级别的简单函数。在这种情况下,为了表明这些子函数不从模块外部导入和使用,我们需要遵循Python的标准,将函数名称写成两个下划线开头的形式:

注意,Python没有访问修饰符(公共、专用……),因此,在模块顶层(即Python文件)编写的所有代码都可以被导入和使用。
记住,这两个下划线只是表示一个我们应该遵守的约定。实际上并没有阻止我们导入和使用这些代码。在导入以两个下划线开头的函数时,我们必须明白,该函数的作者并不希望其被外部引用;如果调用该函数,结果可能在意料之外。通过在被调用的函数内部定义子函数,我们可以避免这种行为。
在函数式编程中,我们从不修改集合中的元素,而是创建一个新的集合来反映对该集合的操作的更改。有三个操作构成了函数式编程的基石,而且可以实现对集合的、我们能想到的任何修改:filter、map和reduce。
filter函数接收一个集合,过滤掉某些元素并生成一个新集合。元素的过滤是根据判定函数进行,判定函数会接受参数,根据该参数是否通过给定的测试来返回True或False。
图2-1说明了过滤器的操作。
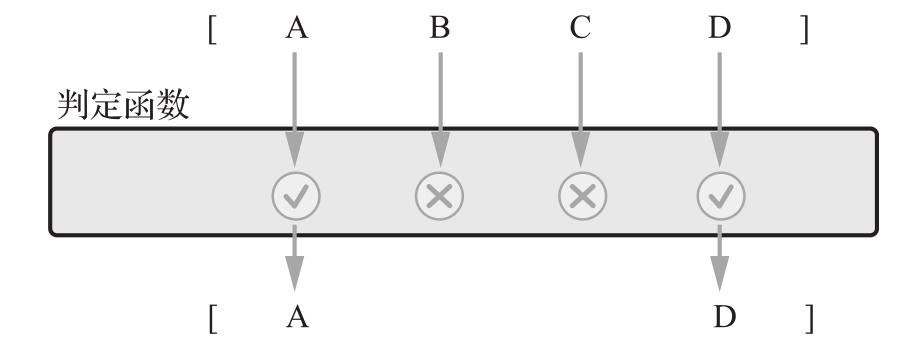
图2-1 过滤一个元素集
图2-1显示了由A、B、C和D四个元素组成的元素集。元素集下面是一个代表判定函数的框,它决定哪些元素被保留,哪些元素被丢弃。元素集中的每个元素都被传递给该函数,只有通过测试的元素才会出现在结果集合中。
Python有两种方法可以过滤集合:一,使用全局函数filter;二,如果集合是一个列表,使用列表推导式。这里我们主要关注filter函数,下一节会介绍列表推导式。filter函数的输入参数是一个函数(判定)和一个集合:

让我们写一个lambda判定函数来测试一个数字是否为偶数:

现在让我们使用lambda函数来过滤一个数字列表,并获得一个只有偶数的新集合:

需要注意的是,filter函数并不会返回列表,而是返回迭代器。迭代器允许对一组元素进行依次迭代。如果你想了解更多关于Python迭代器及其底层原理,请参阅https://docs.python.org/3/library/stdtypes.xhtml#typeiter和https://docs.python.org/3/glossary.xhtml#termiterator上的文档。
我们可以使用前面看到的list函数使用所有迭代器的值,并将它们放入一个列表中,也可以使用for循环来使用迭代器:

map函数对原集合中的每个元素进行函数运算,并将结果存储到一个新的元素集中。两个元素集的大小相同。
图2-2描绘了映射操作。
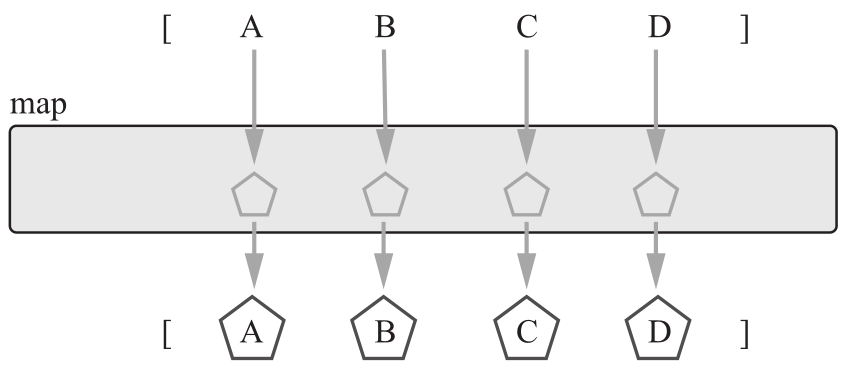
图2-2 映射一个元素集
我们通过一个映射函数,对元素A、B、C和D组成的源集合进行运算,如图2-2中的五边形所示,运算的结果存储在一个新的元素集中。
我们可以使用全局函数map来映射一个元素集,对于列表,还可以使用列表推导式。我们稍后将讨论列表推导式,现在,让我们研究如何使用map函数来映射元素集。
全局函数map接收两个参数,即一个映射函数和一个源集合:

以下代码将一个名称列表与它们的长度进行映射:

与filter函数一样,map返回一个迭代器,可以使用list函数生成列表。在上面的示例中,结果列表包含了名称列表中每个名称的字符数:Angel对应5个字符,Alvaro对应6个字符,以此类推。这样就把每个名称映射成了表示其长度的数字。
reduce函数是三个函数中最复杂,但同时用途最广泛的。它可以创建一个少于、多于或等于原集合的元素数量的元素集。为构造这个新的元素集,它首先对第一和第二个元素应用reduce函数;然后,对第三个元素和第一次操作的结果再次应用reduce函数;接着,对第四个元素和第二次操作的结果再次应用reduce函数。这样一来,结果就会累积起来。一个图在这里会有所帮助。请看图2-3。
本例中的reduce函数将元素集中的每个元素(A、B、C和D)累积为单个元素:ABCD。
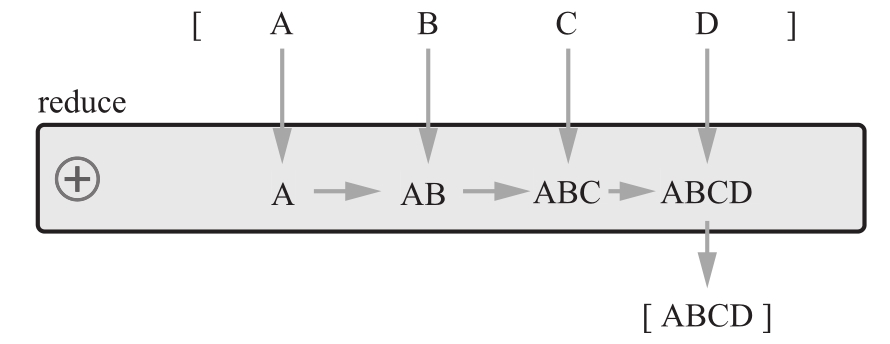
图2-3 将reduce函数用于一个元素集
reduce函数接收两个参数,即累积结果和元素集中的一个元素:

该函数在处理完新元素后返回累积结果。
Python没有提供全局函数reduce,但是有一个叫functools的包,里面有一些处理高阶函数的有用操作,包括reduce函数。这个函数不返回迭代器,而是直接返回生成的元素集或元素。函数的语法如下:

让我们看一个例子:

在这个示例中,reduce函数返回元素“ABCD”,即元素集中的所有字母连接起来的结果。reduce过程开始时,先接收前两个字母A和B,并将它们连接成AB。对于第一步而言,Python使用集合的第一个元素(A)作为累积结果,并将它和第二个元素上应用reduce函数。然后,它移动到第三个字母C,并将其与当前的累积结果AB连接起来,从而生成新的结果:ABC。最后一步,对D字母同样操作,生成最终结果ABCD。
当累积结果和元素集的元素类型不同时会发生什么?在这种情况下,我们不能将第一个元素作为累积结果,因此reduce函数需要我们提供第三个参数作为初始累积结果:
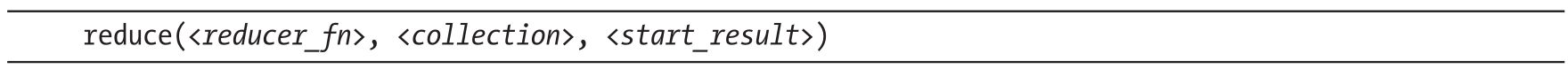
例如,假设我们想将前面用到的名称集合进行缩减,以获得这些名称长度的总和。在这种情况下,累积结果是数字,而集合中的元素是字符串,我们不能使用第一项作为累积的长度。如果我们忘记给reduce函数提供初始结果,Python会弹出一个错误来提醒我们:

这种情况,我们应该传递0作为初始累积长度:

一个有趣的点在于,如果累积结果和集合元素的类型不同,我们总可以用map函数连接reduce函数以获得相同的结果。例如,在前面的练习中,我们也可以这么做:

在这段代码中,我们首先将列表names映射到一个名称长度的列表lengths中。然后,我们缩减列表lengths来求和所有的值,而不需要提供起始值。
当使用一个常规操作来缩减元素——如两个数字求和或两个字符串的连接——我们不需要编写lambda函数;可以直接将现有的Python函数传递给reduce函数。例如,在缩减数字时,Python提供了一个有用的模块,名为operator.py。这个模块定义了对数字进行操作的函数。使用这个模块,我们可以简化之前的代码如下:

这个代码更短,更易读,因此我们在本书中会倾向于使用这种形式。
operator.add函数由Python定义如下:

如你所见,这个函数等价于我们之前定义的两个数字求和的lambda函数。后面我们会看到更多由Python定义的,可以和reduce函数一起使用的函数。
到目前为止,我们所有的示例都将元素集合缩减到一个值,但reduce函数可以做得更多。事实上,filter和map函数都是reduce函数的特例。我们可以使用reduce函数来过滤和映射一个元素集。但我们并不会在这里停下来分析它;如果你有兴趣,可以试着自己弄清楚。
让我们看一个例子,我们希望基于列表names创建一个新的集合,其中的每个元素都是前面所有的名称与当前名称的组合,由连接符(-)进行分隔。结果类似如下:

我们可以使用以下代码来做到这一点:

这里,我们使用compute_next_name来确定列表中的下一个项。reduce函数内部的lambda函数将累积结果连接起来,生成由组合名称形成的列表,和一个由新元素组成的新列表。需要提供空列表作为初始结果,因为列表中的每个元素的类型(字符串)与结果的类型(字符串组成的列表)不同。
如你所见,reduce函数用途非常广泛。
如前所述,在Python中我们可以使用列表推导式过滤和映射列表。在处理列表时,这种形式通常比filter和map函数更好,因为它的语法更简洁和易读。
列表推导式映射列表的语法结构如下:

它分为两个部分:
❍for<item>in<list>是一个for循环,负责迭代<list>中的元素;
❍<expression>是一个映射表达式,负责将<item>映射到其他东西上。
让我们重复之前做过的练习,将一个名称列表映射到每个名称的长度列表,这次使用列表推导式:

或许你已经明白,为什么Python程序员倾向于使用列表推导式而非map函数;上面的例子读起来就像日常英语:“name列表中(每个)名称的名称长度。”在本例中,for name in names遍历原始列表中的名称,然后将每个名称的长度(len(name))作为结果输出。
使用列表推导式过滤列表,可以在推导式的末尾添加一个if子句:
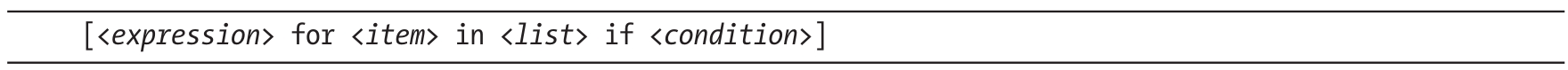
例如,如果我们想过滤一个名称列表,只保留以A开头的名称,列表推导式可以这么写:

本例中有两点需要注意:映射表达式是name自身(恒等映射,映射后的对象不变),过滤操作使用了字符串的startswith方法。只有当字符串以给定的参数作为前缀时,此方法才会返回True。
我们可以在同一个列表推导式中进行过滤和映射操作。例如,假设我们想过滤名称列表中超过5个字母的名称,然后构造一个新的列表,其元素是原名称及其长度组成的元组。我们可以很容易地做到这一点:

为了便于比较,让我们看看如果使用filter和map函数,会是什么样子:

如你所见,结果相同,但列表推导式的版本更简单易读。越容易阅读的东西也越容易维护,因此列表推导式将是我们过滤和映射列表的首选方式。
现在让我们将注意力转向第二个范式:面向对象编程。