
下载掌阅APP,畅读海量书库
立即打开



深度学习为何要初始化?传统的机器学习算法很少采用迭代式优化方法,因此初始化的需求不多。但深度学习算法一般采用迭代方法,而且参数多、层数也多,所以很多算法在不同程度上受到初始化的影响。
深度学习使用权重初始化方法是为了减小模型训练时的不确定性和避免训练过程中陷入局部最优解。通过合理的权重初始化方法,可以帮助模型更好地学习和收敛。
初始化对训练有哪些影响?初始化能决定算法是否收敛,如果初始化不适当,初始值过大可能会在正向传播或反向传播中产生爆炸的值;如果初始值太小将导致丢失信息。对收敛的算法适当的初始化能加快收敛速度。初始值选择将影响模型收敛局部最小值还是全局最小值,如图2-51所示,因初始值不同,导致收敛到不同的极值点。另外,初始化也可以影响模型的泛化。
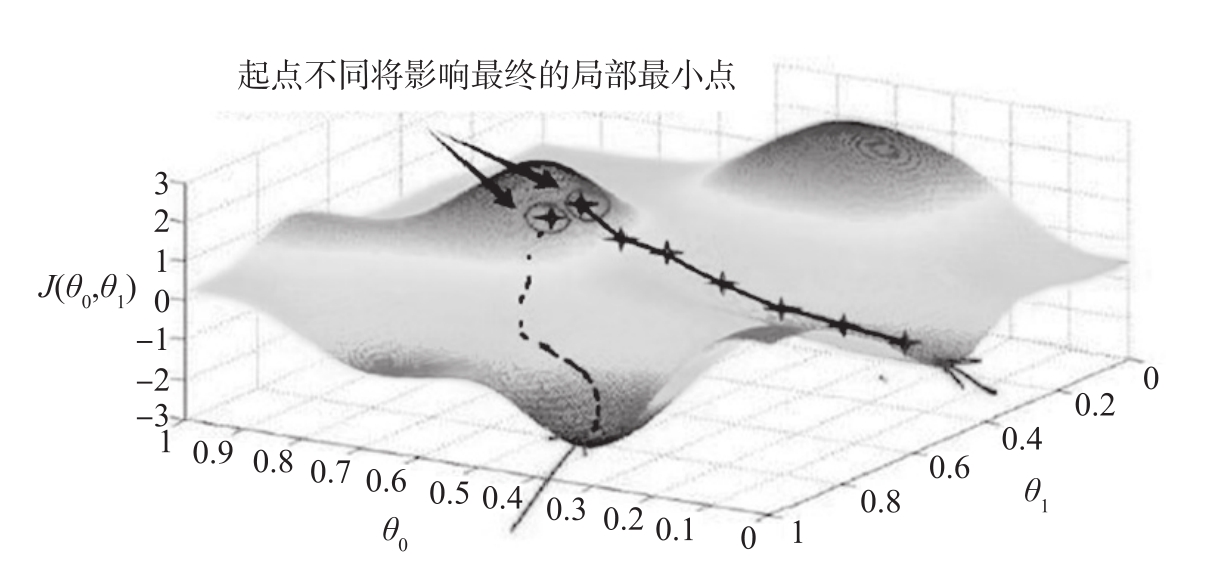
图2-51 初始点的选择影响算法是否陷入局部最小点
如何对权重、偏移量进行初始化?初始化这些参数是否有一般性原则?常见的参数初始化有零值初始化、随机初始化、均匀分布初始化、正态分布初始化和正交分布初始化等。实践表明,正态分布、正交分布、均匀分布的初始值能带来更好的效果。
常见的权重初始化方法如下。
(1)随机初始化
将权重参数随机初始化为一个很小的值或者在某个范围内的随机值。这种方法比较简单,但在一些情况下可能不太稳定,容易导致梯度消失或梯度爆炸的问题。
(2)高斯分布初始化
根据高斯分布随机生成权重参数。一般使用均值为0、标准差为1的高斯分布进行初始化,可以通过加入可学习的偏差项来对中心进行偏移。
(3)Xavier初始化
根据输入和输出的维度来确定权重参数初始化的范围。Xavier初始化可以使得网络在正向传播过程中的方差不变。
(4)Kaiming_He初始化
根据输入的维度来确定权重参数初始化的范围。He初始化可以使得网络在正向传播过程中的方差不变。
常用的权重初始化方法的具体计算如表2-1所示。
表2-1 常用的权重初始化方法
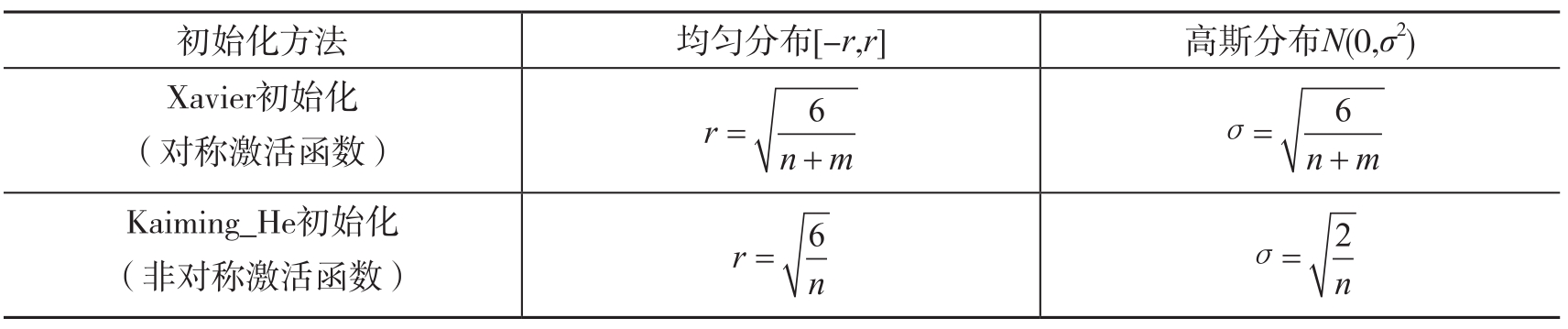
PyTorch提供了nn.init模块,该模块提供了常用的初始化策略,如Xavier、Kaiming_He等经典初始化策略,使用这些初始化策略有利于激活值的分布呈现更有广度或更贴近正态分布。Xavier一般用于激活函数是S型(如sigmoid、tanh)的权重初始化,Kaiming_He更适合于激活函数为ReLU类的权重初始化。
对于激活函数是S型的权重初始化,如果初始化值很小,那么随着层数的传递,方差就会趋于0,此时输入值也变得越来越小,在sigmoid函数上就是在0附近,接近于线性,失去了非线性;如果初始值很大,那么随着层数的传递,方差会迅速增加,此时输入值变得很大,在sigmoid函数中会导致倒数趋近于0,反向传播时会遇到梯度消失的问题。
● PyTorch中权重符合均匀分布的初始化方法:
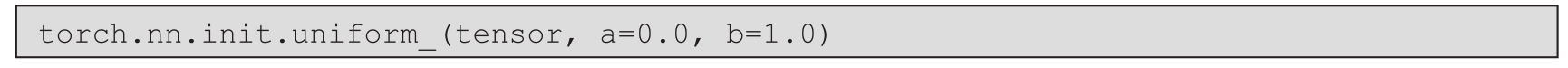
● PyTorch中权重符合正态分布的初始化方法:
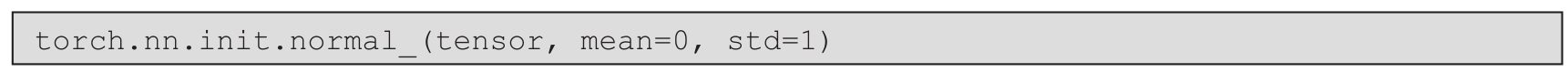
● Xavier初始化:

● Kaiming_He初始化:
