
下载掌阅APP,畅读海量书库
立即打开



在深度学习中,表示学习通常采用分布式表示或嵌入方式。分布式表示是指将输入数据转化为高维空间中的向量表示,这些向量捕捉了数据的语义信息。嵌入方式是指通过学习,将高维的离散数据映射到低维的连续向量空间中。
表示学习的逆嵌入(De-Embedding)是指将嵌入向量转化回原始离散数据的过程。在深度学习中,可以使用逆映射函数来实现表示学习的逆过程。逆映射函数通常是一个神经网络模型,将嵌入向量作为输入,输出对应的原始离散数据,如图1-11所示。
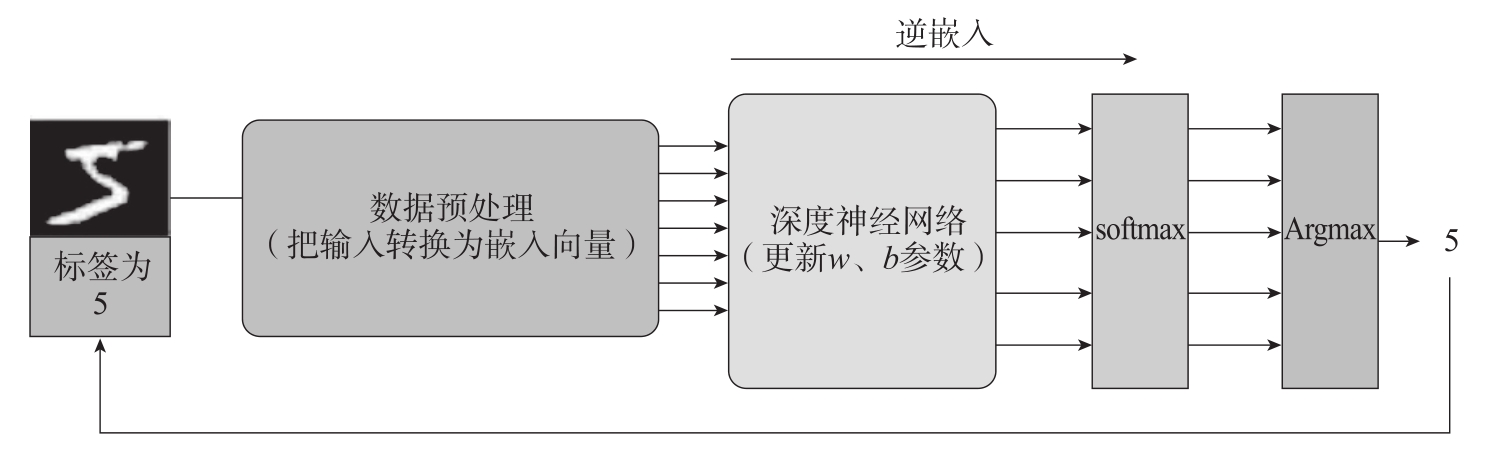
图1-11 分类任务的嵌入与逆嵌入示意
为了实现表示学习的逆过程,需要在训练过程中同时学习嵌入和逆映射函数。具体做法是:使用损失函数等来捕捉原始样本和它的嵌入向量之间的关系,通过优化损失函数,使得嵌入向量在低维空间中聚集到对应的原始数据点附近,从而实现表示学习的逆过程。
需要注意的是,表示学习的逆过程中可能存在信息丢失的问题,因为将低维嵌入向量映射回高维离散数据可能会引入一定的不确定性。因此,在实际应用中,需要权衡维度约减和信息保留之间的平衡,并根据具体任务的需求来采用合适的表示学习方法。
在Transformer模型中,输入通常会经过一个嵌入层进行转换,将输入的离散化符号(如单词、字符或其他离散数据)映射为连续的低维向量表示,这个过程称为嵌入。
而输出的表示学习的逆过程实际上是对网络最后一层输出的操作,将网络输出的连续向量表示映射回原始的离散化符号。在Transformer模型中,输出通常是一系列连续向量,这些向量表示输入序列中各个位置的特征。对于不同的任务,输出的处理方式可能有所不同。
对于常见的序列到序列任务(如机器翻译或文本生成),Transformer模型通常会在输出端引入softmax层。softmax函数可以将连续向量转换成概率分布,使得每个位置的输出可以解释为对应词汇表中不同符号的概率。然后,根据概率分布来生成最终的输出符号序列,详细转换过程如图1-12所示。
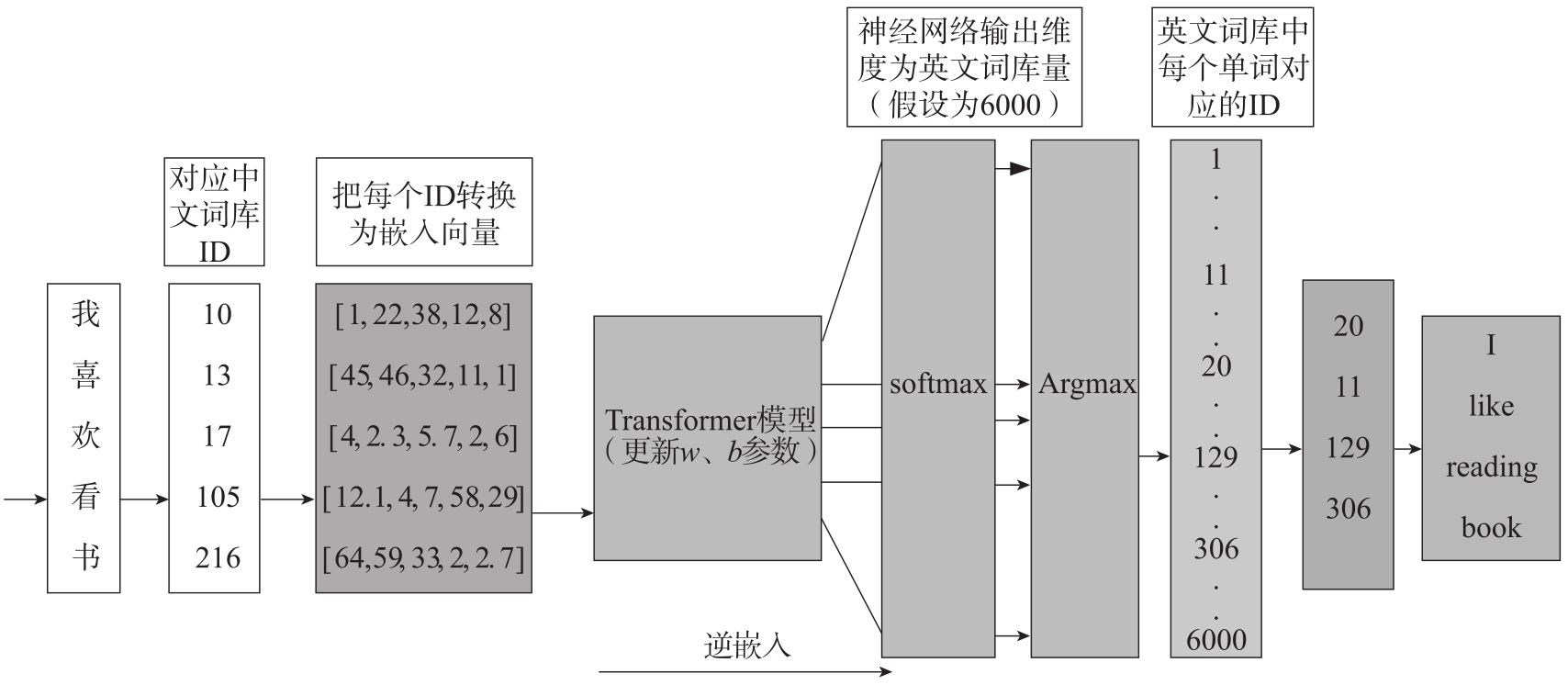
图1-12 利用Transformer模型进行中文翻译成英文的流程
在训练过程中,我们使用真实的目标序列与模型输出之间的差异(通常使用交叉熵损失)来优化模型参数。在预测阶段,我们通常使用贪婪搜索或束搜索等技术来根据模型输出的概率分布选择最可能的符号,从而生成输出序列。需要注意的是,在某些应用中,输出可能不是离散的符号序列,而是连续值的回归问题。在这种情况下,经过逆嵌入过程输出的结果不需要特别处理,直接使用模型输出的连续向量即可。
总之,在Transformer模型中,输入通过嵌入层转换为连续向量表示,输出通过softmax函数等操作将连续向量映射回离散化符号或进行其他任务的处理。这些步骤共同构成了Transformer模型的完整流程,使其在各种序列建模任务中表现出色。
表示学习类似于编码器-解码器中的编码器,但两者不完全一致。编码器是深度学习中的一种常见表示学习方法,它将输入数据转换为高维特征表示。表示学习是一个更广泛的概念,旨在从原始数据中学习有用的表示或特征,这些表示可以用于不同的任务,如分类、聚类、生成等。编码器通常是表示学习的一个组成部分,它可以用于学习数据的表示,但表示学习还包括其他方法和技术,如降维、自编码器、生成对抗网络等。因此,编码器只是表示学习中的一种特定实现方式。
表示学习的逆过程可以简单地理解为从学习到的表示中恢复原始数据,类似于解码器的功能,但两者不完全一致。