下载掌阅APP,畅读海量书库
立即打开



在MXMACA编程语言中,流(Stream)是一个重要的概念,它描述了在主机端发起并在一个设备上执行的操作序列。流提供了一种机制,使操作的下发和实际执行是异步的。这意味着主机端可以连续地发出多个操作,而不需要等待每个操作完成后再进行下一个操作。流中的操作是按照主机端发起的顺序来执行的,这保证了在同一个流上先发起的操作会被先执行。这种顺序性保证了操作的正确性和一致性,避免了由于并发执行而可能引发的问题。流和并发执行的示意图如图5-11所示。
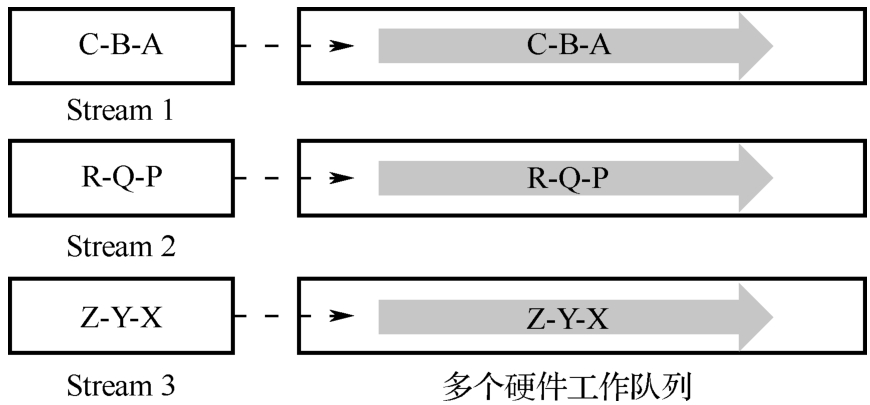
图5-11 流和并发执行的示意图
流是软件设计中根据业务需要进行定义的。在图5-11中,程序员将任务A、任务B和任务C放在Stream 1中,将任务P、任务Q和任务R放在Stream 2中,将任务X、任务Y和任务Z放在Stream 3中,每个流中的三个任务均有依赖关系且需要按相应的顺序被执行。一个流上的任务会被调度到一个硬件工作队列上。在硬件资源充足时,不同流上的任务会被调度到不同的硬件工作队列上以支持GPU任务的并行执行,在硬件资源不足时,可能会被调度到同一个硬件工作队列上串行执行。
按照创建方式分类,流可以被分为默认流和用户自定义流。对于内存复制、内存赋值、核函数启动等操作来说,如果没有显式指定流,MXMACA将把这些操作放入默认流中来执行。
GPU计算的典型流程示意图如图5-12所示。当使用流编程模式时,对于大部分API或者核函数启动来说,发起操作和执行操作是异步的。程序员通过API或者核函数启动发起某个操作(比如内存复制、执行计算等)后,主机线程不会等待这个操作完成,而是继续往下执行,此时主机和设备实现了并行执行。
另外,由于CPU和GPU通过PCIe总线相连,基于PCIe的数据传输与实际计算操作之间可以并行,通过多个流并行执行,这样可以充分利用PCIe总线带宽和计算资源。GPU使用MXMACA流并行提速示意图如图5-13所示,H2D和D2H分别表示将主机端数据复制到设备和将设备端数据复制到主机的操作,K1、K2、K3是三次核函数启动。从图中可以看出,相比使用单个流,使用三个流并行执行可以提升程序的性能。
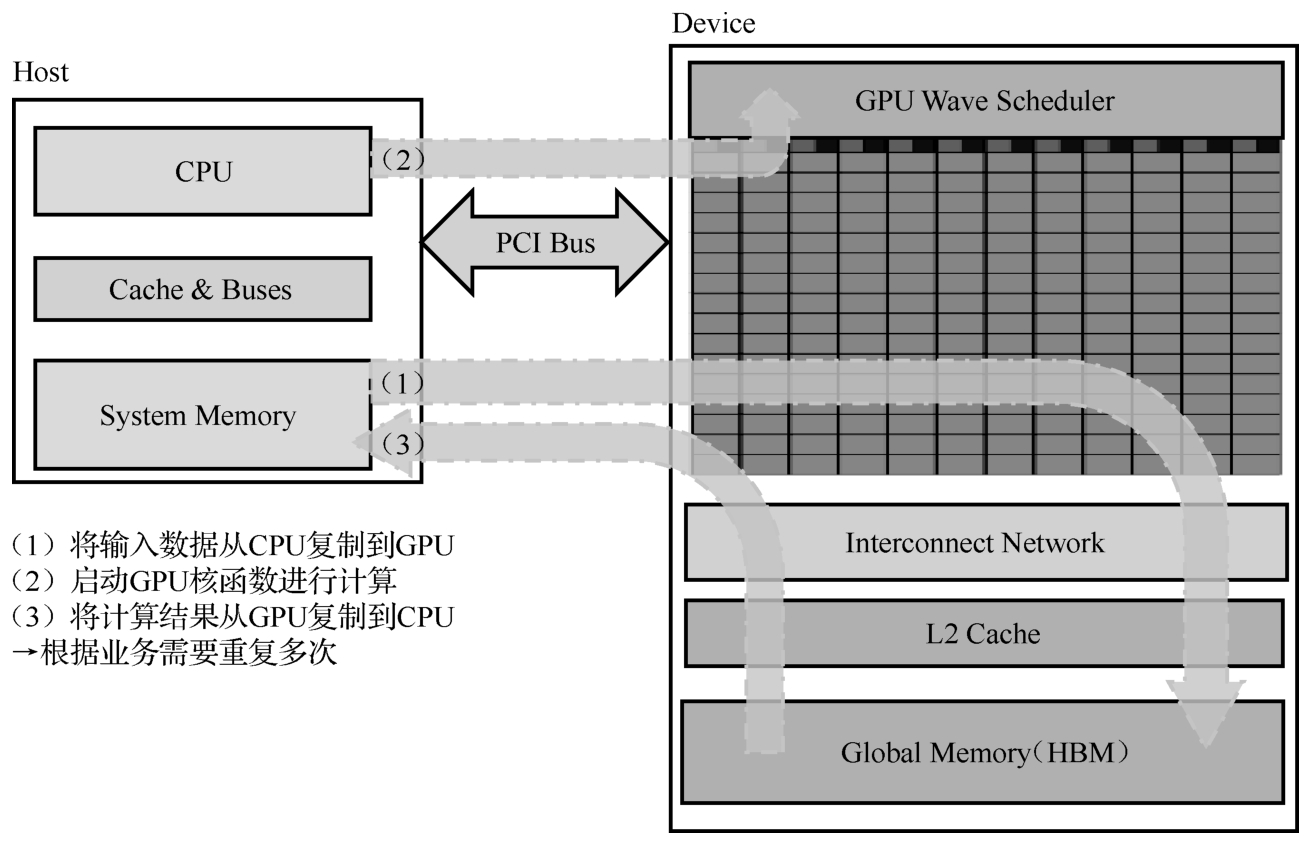
图5-12 GPU计算的典型流程示意图
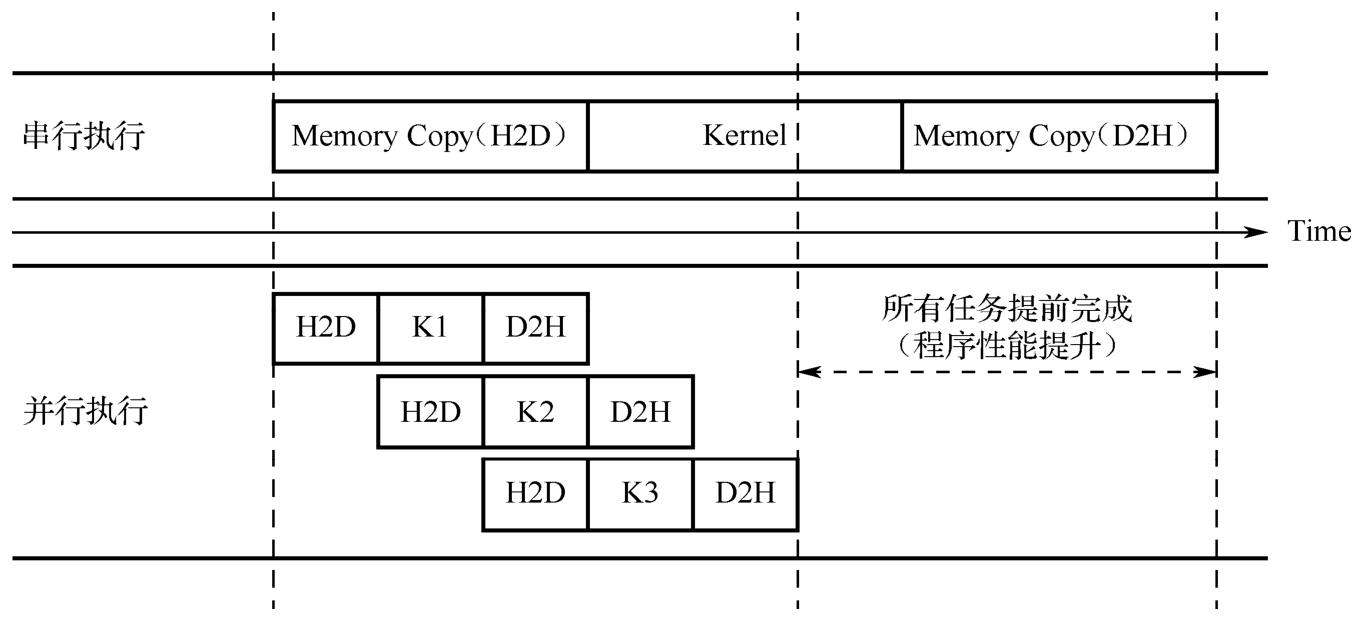
图5-13 GPU使用MXMACA流并行提速示意图
在MXMACA程序中,所有的操作(内存申请、内存复制、核函数启动等)都是运行在某一个流之上的,有些情况下不需要显式指定流,此时MXMACA会将此操作放在默认流上执行。默认流又被称为NULL流。不指定流的核函数启动、内存复制和内存赋值都是在默认流上执行的。
隐式同步是指在发起一个操作时,MXMACA底层驱动程序会主动等待当前的操作及在这个流上尚未完成的操作完成。这样做的目的主要是保证数据的一致性。
对于大部分不显式指定流的函数调用(如调用函数mcMemcpy)来说,调用这些函数时MXMACA底层驱动程序会完成隐式同步。无论是在默认流上还是在用户自定义流上,核函数启动永远都是异步的。
MXMACA运行时库提供了以下函数让程序员创建自定义流。

在MXMACA程序中,用户自定义流可以分为阻塞流(Blocking Stream)和非阻塞流(Nonblocking Stream)两种类型。这两种流的行为略有不同,主要表现在它们对其他流的影响和执行方式上。
(1)阻塞流的特点如下。
● 阻塞流在某些条件下会阻塞其他流的执行。具体来说,当一个阻塞流中的操作正在执行时,其他流中的操作可能会被阻塞,直到该阻塞流中的操作完成为止。
● 阻塞流通常用于需要保证操作顺序执行的场景,或当某个操作需要占用大量资源并且必须先于其他操作完成的场景。
● 阻塞流可以确保操作的顺序性和一致性,但也可能影响并行性和性能,因为它可能会阻塞其他操作的执行。
(2)非阻塞流的特点如下。
● 非阻塞流不会阻塞其他流的执行。即使非阻塞流中的操作正在执行,其他流中的操作也可以同时执行。
● 非阻塞流适用于那些不需要严格保证顺序执行的场景,或当操作可以与其他操作并行执行的场景。
● 非阻塞流能够提高并行性和性能,因为它允许多个流同时执行操作。但它也要求程序员更仔细地处理操作的依赖性和同步,以避免数据不一致或其他的并发问题。
同一个进程内可以创建多个自定义流。由于流与流之间的操作是并行的,多个流并行能够充分地利用GPU的计算资源和通信带宽。使用函数mcStreamCreate创建的流都是阻塞流。如果需要创建非阻塞流,需要使用函数mcStreamCreateWithFlags来创建,并设置函数入参flags为mcStreamNonBlocking。
通过创建多个流,并使这些流上的操作并行执行,可以提升GPU的吞吐量。GPU的并行执行方式既可以是基于任务的,也可以是基于数据的(见图5-14),这由GPU程序员结合业务需要来进行设计。
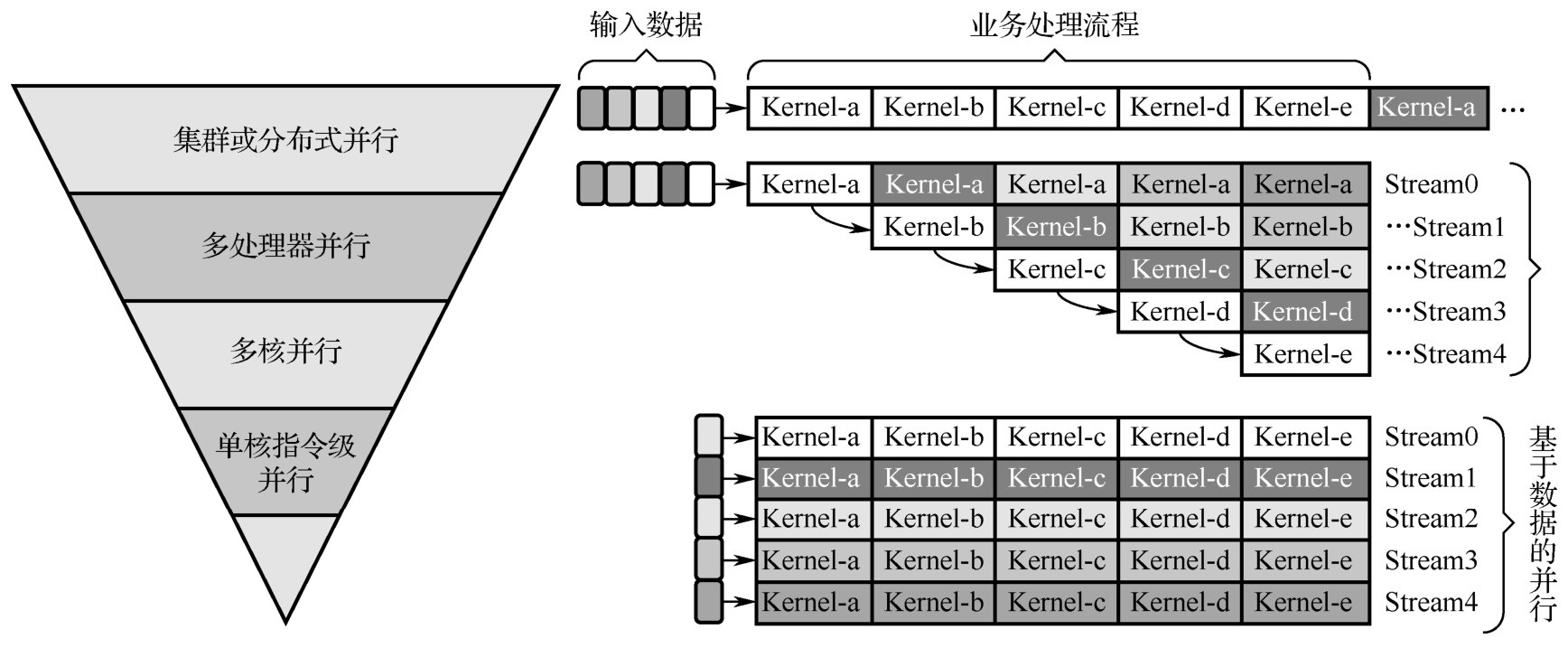
图5-14 GPU并行执行方式:基于任务或基于数据
MXMACA提供了一套同步API和一套异步API,大部分不需要指定流的API(如函数mcMemcpy)都是同步API,使用这些API,所有的操作都会在默认流上执行,并且会执行隐式同步。另一类API需要在调用时显式指定流,这些API的名称都带有后缀Async,如函数mcMemcpyAsync、mcMemsetAsync等。如果程序员创建自定义流,异步的内存申请、核函数启动等操作将会使用这类API来完成。
基于同步API和异步API的编程示例见示例代码5-5。

到目前为止,我们都是采用<<<>>>语法来启动核函数的API的。事实上,这个语法在编译时会被替换为MXMACA运行时库的函数mcLaunchKernel,该函数的原型如下。

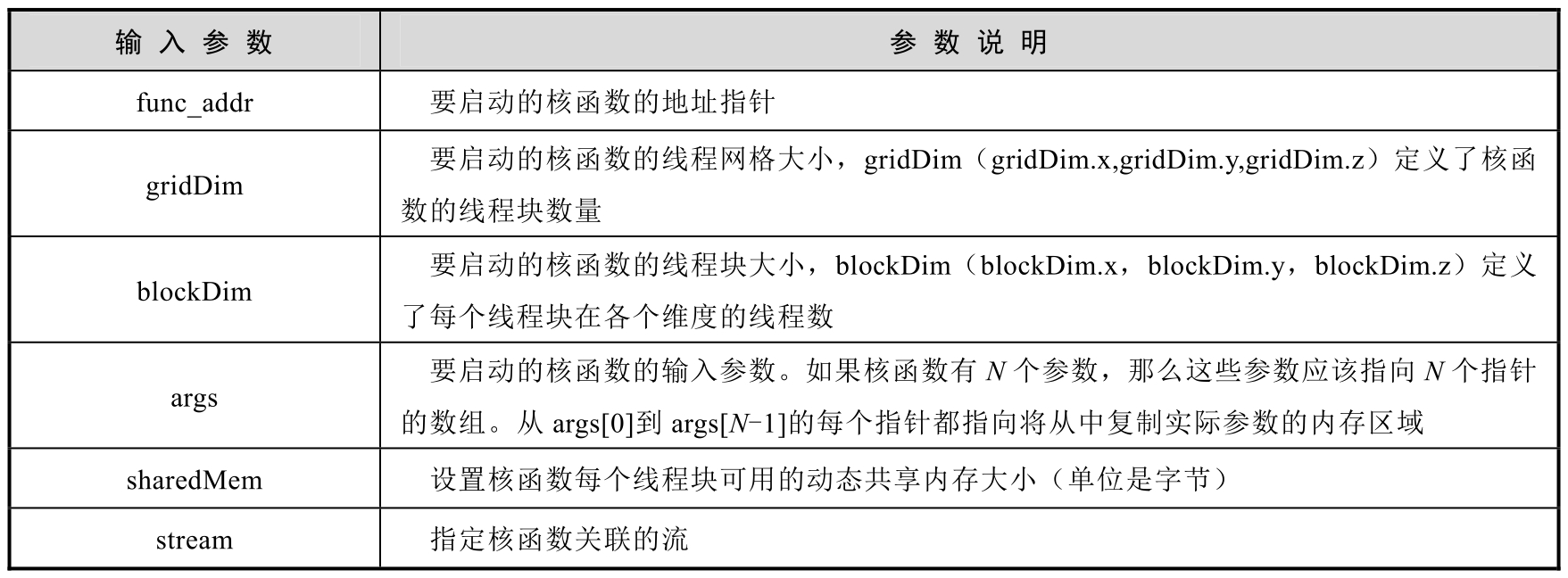
函数mcLaunchKernel的输入参数及参数说明见表5-2。
表5-2 函数mcLaunchKernel的输入参数及参数说明
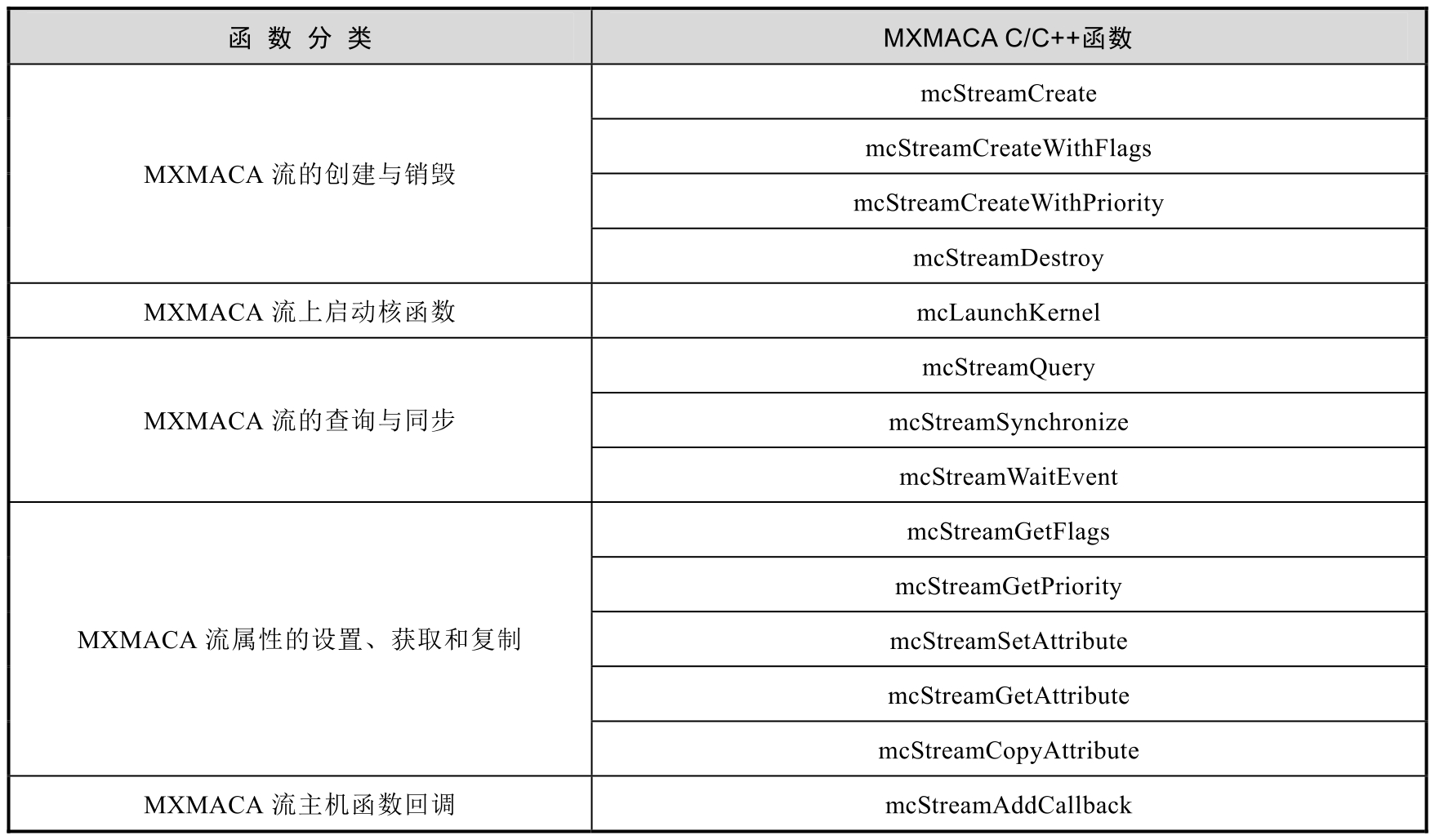
MXMACA流管理函数分类见表5-3。可以在MXMACA编程环境的头文件mc_runtime_api.h中或在沐曦官网发布的MXMACA运行时库编程指南文档中,查阅这些函数的详细定义。
表5-3 MXMACA流管理函数分类