
下载掌阅APP,畅读海量书库
立即打开



Python软件基金会维护的Python语言代码解释器,可以从Python官方网站https://www.python.org下载。
在Windows下安装Python以后,在控制台输入python命令进入交互式环境。
d:\data>python
Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit
(AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
由于开源软件的迅速发展,可以借助开源软件简化自然语言处理的开发工作。简单地,可以使用Sublime这样的文本编辑器写Python代码,也可以使用Eric(https://ericide.python-projects.org)或者Microsoft Visual Studio这样的集成开发环境。
Scrapy(https://github.com/scrapy/scrapy)是一个流行的爬虫框架。要安装Scrapy,请在终端使用以下命令:
pip install Scrapy
Scrapy shell是一个交互式shell,可以在其中非常快速地尝试和调试爬虫代码。通常,我们通过传递网页的URL来启动一个shell,如下所示:
语法:scrapy shell <url_to_be_scraped>
例如:
scrapy shell http://quotes.toscrape.com/tag/friends/
获得网页标题:
In [1]: response.xpath('//title/text()').get()
Out[1]: 'Quotes to Scrape'
在浏览器中查看网页源代码,可以看到网页标题:

一旦我们学会了启动shell,我们就可以用它来测试爬取代码。在编写任何Python爬虫代码之前,应该使用shell测试网页以进行抓取。Scrapy shell有一些可用的快捷方式,一旦我们启动了shell,它们就可用了。快捷方式介绍如下。
shelp():shelp()命令,显示Scrapy对象列表和有用的快捷方式。可以看到,Request对象代表发送到链接http://quotes.toscrape.com/tag/friends/的GET请求。此外,如果Response对象包含一个200 HTTP代码,表示请求成功,除此之外,它还提到了Crawler和Spider对象的位置。
fetch(URL):“URL”是指向需要抓取的网页的链接。fetch快捷方式接受一个URL,即要抓取的网页,它返回爬虫信息,以及响应是成功还是失败。在下面的示例中,我们有一个有效的URL和一个无效的URL,根据请求的性质,fetch会显示错误或成功代码。

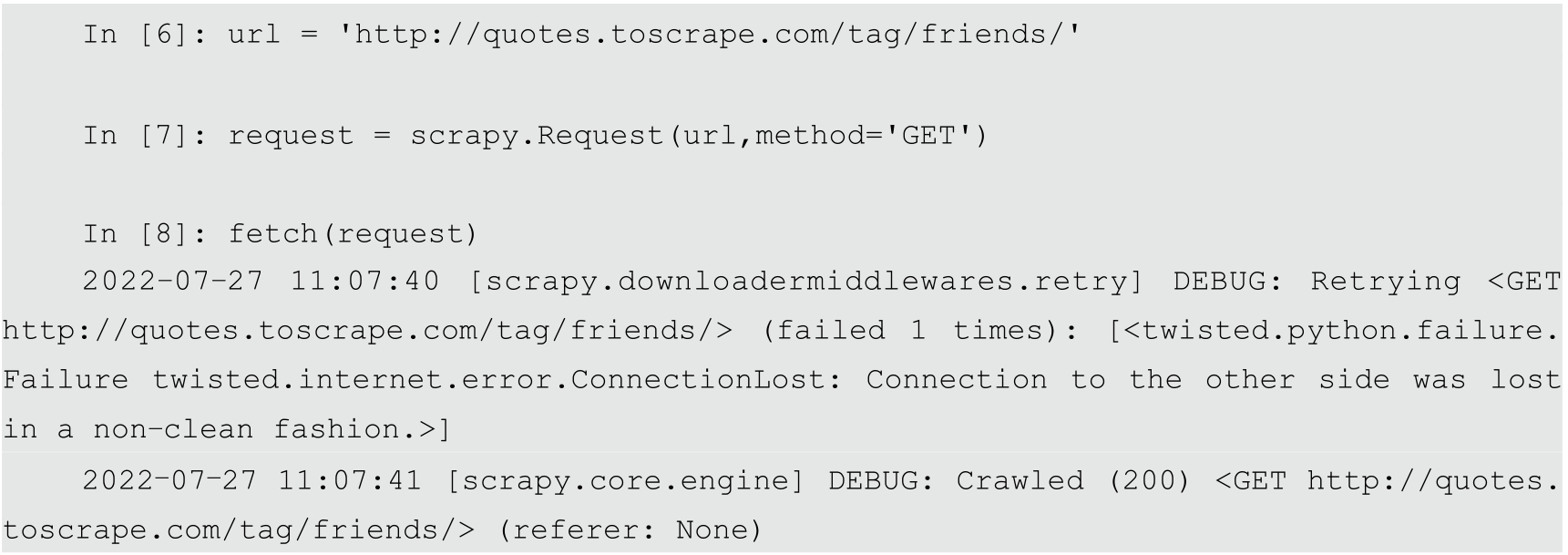
fetch(request):我们可以创建一个Request对象,并将其传递给fetch()方法,为此,需要创建一个Scrapy对象。Request类提及到了所需的HTTP方法、网页的URL、标头(如果有的话)。我们要抓取URL=‘http://quotes.toscrape.com/tag/friends/’的网页,我们需要准备请求对象为:
fetch(request_object)
终端输入输出为:
view(Response):在默认浏览器中打开网页,网页是作为Request对象或fetch()方法中的URL发送的网页。当我们输入view(Response)时,在上述fetch(Request)之后,网页会在默认浏览器中打开。