
下载掌阅APP,畅读海量书库
立即打开



为明确图像非聚焦模糊处理的处理对象以便后续讨论,本节将介绍非聚焦模糊图像的定义及类别。在各类研究中,常将非聚焦模糊图像中的模糊区域称为离焦区域,清晰区域称为聚焦区域。并且,在各类非聚焦模糊检测方法的输出和非聚焦模糊检测训练数据集中,经常将聚焦区域标记为白色(值为1),非聚焦区域标记为黑色(值为0),最终形成一个分割出离焦区域和聚焦区域的二值图掩模,如图1.2.1的第二行所示。
除了较常见的由模糊前景和清晰背景组成的非聚焦模糊图像,在各类场景下还会产生其他种类的非聚焦模糊图像。具体来讲,可以将非聚焦模糊种类分为前景聚焦背景模糊的前景聚焦场景、前景模糊背景聚焦的背景聚焦场景、前景和背景全部模糊的全离焦场景,此外,还有前景和背景全部聚焦的全聚焦场景。各类非聚焦模糊图像请参考图1.2.1。鉴于各类非聚焦模糊的不同特性,图像的非聚焦模糊处理方法往往需要有针对性地做出改变。

图1.2.1 非聚焦模糊图像、非聚焦模糊检测图像及非聚焦模糊图像种类示意图
随着硬件条件和相关技术的发展,深度学习被越来越多的关注,也在诸多场合发挥了相当的应用价值。因此,近年来也有大量基于深度学习的图像非聚焦模糊智能处理方法被提出。为使读者易于理解后续内容,本节将简单介绍图像非聚焦模糊智能处理部分重要的基本概念。
卷积神经网络(CNN)是深度学习领域最重要的组成部分之一。其应用范围包括但不局限于图像识别与检测、自然语言处理、视频数据识别与分析等。在卷积神经网络被大众熟知之前,图像处理一直是难以攻关的难题,一张图片通常有3个维度,分别是高、宽、通道数,通道数在彩色图片中即红、蓝、绿3个通道,在计算机中存储图片时,对应的三维矩阵即高的像素数×宽的像素数×3,当数据量非常大时,通常情况下一般的机器学习方法(如线性回归、随机森林)很难解决这类问题,对图像进行处理时便需要对该矩阵进行大量的计算,费时费力且计算成本极其高。在卷积神经网络出现后,受益于卷积神经网络局部感知和参数共享等特性,极大地降低了图像处理的复杂度和计算成本,为提高图像处理的实时性和准确性做出了巨大贡献 [6] 。
卷积神经网络的基本组成包括卷积层、池化层和全连接层,随着研究人员探索的逐渐深入,还扩展出了非线性激活层、批归一化层等。简单来说,卷积层的工作模式是用卷积核扫描图像,提取特征的。随着卷积次数的增加,图像的特征不断被提取和压缩,最终卷积层提取的特征层次越来越高,也就是说,卷积层对原始特征进行一步又一步地浓缩提取,从而得到能表示整张图像信息的可靠特征。卷积层的重要特点是能实现权值共享,在一个卷积层中,给定一张图像,用一个卷积核扫描图像,这张图像上的所有位置都是被同一个卷积核扫描的,权重相同。在卷积神经网络中,局部连接中隐藏层的每个神经元连接的局部图像权值都会共享给剩余的神经元使用。不管隐藏层包含多少个神经元,网络需要训练的仅是一组权值参数,也就是卷积核的大小,这样就极大地减少了计算参数量。在卷积层中,卷积核以滑窗的形式在其感受野内通过卷积运算进行特征提取,进而将其传输给后面的全连接层作为图像分类的依据。卷积层最重要的作用有两点:首先,卷积层局部感知、参数共享的特点大大降低了网络参数,且保证了网络的稀疏性;其次,通过卷积核的组合及随着网络后续操作的进行,模型靠近底部的卷积层提取的是局部的、高度通用的特征图,而靠近顶部的卷积层提取的是更加抽象的语义特征。
池化层的目的是对特征进行压缩,以减少特征中的冗余信息量,只保留最重要的部分信息,也叫作下采样。通常来说,池化层出现在卷积层之后,可以起到减少卷积层输出特征数量的作用,进而减少计算量,改善过拟合。具体做法是选择某个区域内所有像素的最大值或均值,随后以该值替换区域内的所有像素值,从而压缩特征。几种常见的池化操作有平均池化、最大池化、随机池化等。平均池化即对池化模板做均值化操作,优点是可以保留特征的整体特性,一定程度上可以去除噪声。最大池化即取池化模板内的最大值,优点是能提取特征更多的纹理特征,保留局部细节。随机池化即按照池化模板内值的大小分配选中概率,元素值越大,被选中的概率也越大,模板内各元素选中的概率和为1,但这种池化操作不够稳定。
全连接层的目的是将隐式的特征表示映射到样本标记空间,起到分类的作用,一般全连接层位于卷积神经网络的最后一层。与多层感知机类似,全连接层需要对输入的所有神经元做矩阵计算,从而得到最具代表性的特征信息。在实际应用中,通常使用1×1卷积层作为全连接层,全连接层的输入是上一层输出的所有特征值,对于分类任务来说,输出是一个长度为类别总数的向量,这个向量中的每一个预测值为该张图像属于这个类别的概率值,选择最大的预测值对应的分类结果为最终的图像类别。全连接层在卷积神经网络中大大降低了参数计算量,提高了模型对特征进行压缩提取的能力。
本节将概括性地总结非聚焦模糊智能处理的基本流程及常见分类,作为后续章节介绍具体方法应用的前置知识。
非聚焦模糊检测的一般流程如图1.2.2所示。在一般性的方法中,非聚焦模糊检测都可以抽象凝练为:首先提取高度总结了输入图像关键信息的特征,其次设立相应的评判规则,最后根据所获取的特征判断图像的各部分是否为非聚焦模糊。在传统的非聚焦模糊检测中,特征提取常由手工设计的方法来完成,特征提取方法的设计主要依据频率、梯度等。同时,由特征判断图像是否模糊的判断规则,也基于所提取的特征的性质来人为裁定。而在基于深度学习的非聚焦模糊检测中,特征提取方法则由深度网络来完成,该部分的设计往往是整个流程的核心。后续基于网络提取的特征来判断是否模糊的工作,则交由全连接层等各类深度网络模块通过分类来完成。
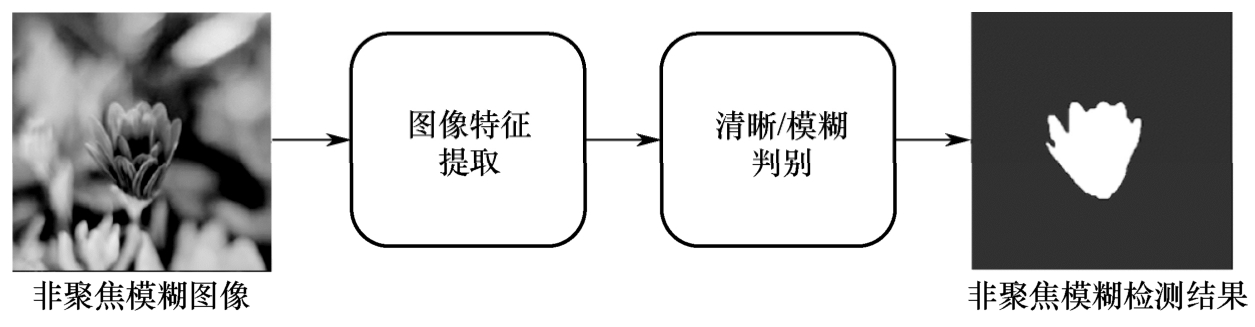
图1.2.2 非聚焦模糊检测的一般流程
非聚焦模糊图像的去模糊任务,需要对图像进行直接处理以去除图像中的非聚焦模糊,相比仅是识别离焦区域的非聚焦模糊检测任务,非聚焦模糊图像的去模糊任务的整体流程则相对更多样化。传统的去模糊方法往往将模糊现象视为一种滤波器,即模糊图像由清晰图像与作为滤波器的模糊核卷积而来,故传统的去模糊方法试图通过已知或估计得来的模糊核,来对模糊图像进行反卷积操作。因此,去模糊可以分为已知模糊核的非盲去模糊和模糊核未知的盲去模糊 [7] ,一般来讲,盲去模糊更契合现实中的多数模糊情景,所以被更多地研究。在基于深度学习的去模糊中,则应用多种多样的深度网络结构来完成去模糊,如利用生成对抗式网络直接端到端地输出去模糊图像,或利用二阶段的网络先估计模糊核,再完成去模糊。