
下载掌阅APP,畅读海量书库
立即打开



在本章中,我将广泛地介绍一些扩展软件系统的基本方法。你可以把本章看成从30000英尺(1英尺约为30.48 cm)的高度鸟瞰第二部分、第三部分和第四部分的内容。我将介绍可扩展系统的主要架构方法,并指出后续将深入探讨相关架构问题的章节。你可以认为本章的内容概述了为什么需要可扩展系统的架构策略,而后续章节的内容将详细解释如何运用这些架构策略。
本书讨论的目标系统类型是我们每天都在使用的、面向互联网的系统。你尽管说出最喜欢的系统!这些系统的特点是:在网页和移动应用程序界面接收用户的请求,根据用户请求或事件(例如,基于GPS的系统)存储和检索数据,并具有一定的 智能 功能,例如根据之前与用户交互的知识来提供建议或通知。
我将从一个简单的系统设计开始,展示如何扩展它。在此过程中,我将引入几个概念,并在本书后续章节更详细地介绍它们。本章只是对这些概念进行全面概述,让你知道它们是如何在系统可扩展性方面发挥作用的——这是一次走马观花之旅!
几乎所有大规模系统都是从小规模开始,在成功路上逐渐发展壮大。从Ruby on Rails、Django或类似的开发框架开始架构系统是常见且明智的做法,它们可以加速开发,使系统得以快速启动并运行。基于一个典型且简单的软件架构来启动你的系统开发,与采用快速开发框架获得的效果相似,如图2-1所示。此架构包括客户端层、应用服务层和数据库层。如果你使用Rails或类似产品,那么可以直接获得以下便利:内置了处理Web应用程序的MVC(模型-视图-控制器)模式和生成SQL查询的ORM(对象-关系映射器)。
使用上述架构,用户从移动应用程序或Web(网页)浏览器向系统提交请求。互联网网络的魔力(参见第3章)将请求传递给运行在企业或商业云数据中心的机器上的应用服务。通信使用标准的应用层网络协议,通常是HTTP。
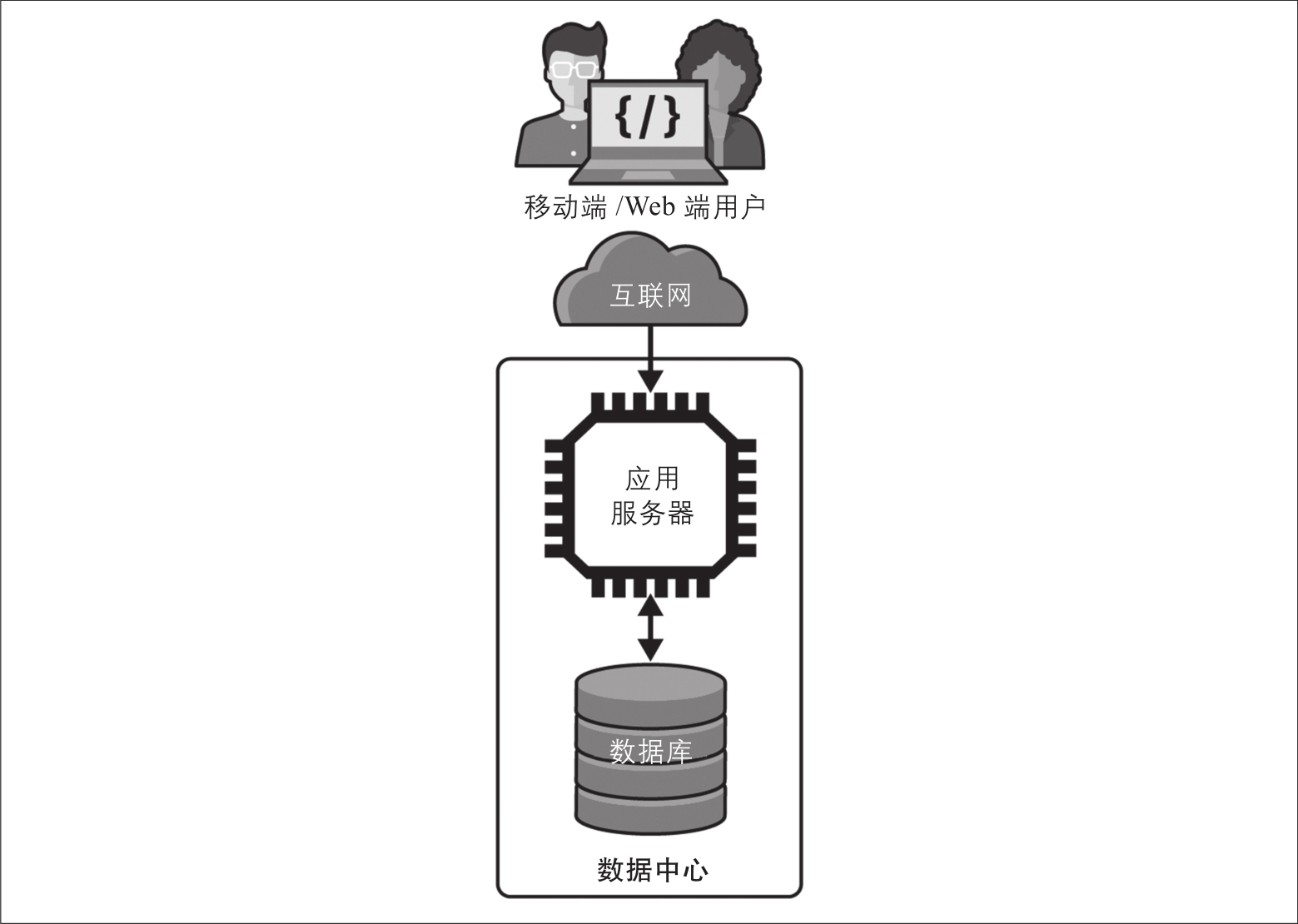
图2-1:简单的多层分布式系统架构
应用服务运行了API的代码,支持客户端发送的HTTP请求。收到请求后,服务会执行与请求的API关联的代码。在此过程中,可能会读取数据库的数据,或写入数据库,或写入其他外部系统,具体取决于API的语义。请求完成后,服务会将结果发送回客户端,结果在客户端应用程序或浏览器中显示。
许多系统在概念上看起来与上述描述一致。应用服务代码利用服务器执行环境,同时处理来自多个用户的多个请求。应用服务器技术有无数种——例如,Java EE和Java的Spring框架,Python的Flask( https://oreil.ly/8FYu5 )——它们在上述场景中被广泛使用。
这种方法通常会产生所说的单体架构 [1] 。随着应用程序的特性变得更加丰富,单体应用程序的复杂性往往会增加。所有API处理程序都内置在同一个服务器代码中,最终会让快速修改和测试变得困难。由于所有API实现都在同一个应用服务中运行,执行足迹可能变得极其繁杂。
尽管如此,如果请求的负载压力保持较低的水平,则此应用程序架构足够了,服务足以处理请求并保持低延迟。如果请求负载持续增长,则意味着延迟增加,因为服务没有足够的CPU和内存来同时处理大量的并发请求,请求将需要等待更长的时间。在这种情况下,单台服务器已经超载,成了性能瓶颈。
对于上述案例,第一个扩展策略通常是“扩展”应用服务的硬件。假设你的应用程序运行在AWS上,你可以将服务器从带有四个CPU(虚拟)和16 GB内存的普通t3.xlarge实例升级到t3.2xlarge实例,为应用程序提供翻倍的CPU和可用内存 [2] 。
扩展很简单,它使现实世界的许多应用程序在支持更大的工作负载方面取得了长足的进步。显然,扩展硬件要花更多的钱,但也物有所值,扩展后的系统满足了你的实际需求。
然而,不可避免的是,对于许多应用程序,无论你拥有多少CPU和多少内存,负载都将增长到超出单个服务器节点所能服务的范围。这时你需要一个新的策略,即第1章提及的,横向扩展或水平扩展
 。
。
水平扩展是指依靠架构复制服务,并在多个服务器节点上运行多个服务副本的能力。来自客户端的请求被分布在不同的副本,理论上讲,如果有 N 个服务副本和 R 个请求,则每个服务器节点处理 R / N 个请求。这种简单的策略增加了应用程序的存储能力和计算能力,从而提升了可扩展性。
要成功扩展应用程序,你的设计中需要具备两个基本元素。如图2-2所示,它们分别是:
负载均衡器
所有用户请求都发送到负载均衡器,由它来决定处理请求的目标服务副本。关于如何选择目标服务副本,有多种策略,所有策略的核心目的都是让不同的资源同等繁忙。负载均衡器还负责将来自服务副本的响应转发回客户端。大多数负载均衡器都属于反向代理的互联网组件( https://oreil.ly/78lLN ),它们控制着客户端请求对服务器资源的访问。负载均衡器扮演着中介的角色,反向代理为请求添加了额外的网络跳跃点,它们需要将延迟控制到极低,才能最大限度地减少引入的开销。有许多现成的负载均衡解决方案以及特定于云提供商的解决方案,我将在第5章中更详细地介绍它们的特征。
无状态服务
为了使负载平衡有效并均匀地分发请求,负载均衡器必须可以自由地将来自同一客户端的连续请求发送到不同的服务实例进行处理。这意味着服务中的API实现不得保留与单个客户端会话相关联的任何知识或状态。当用户访问应用程序时,服务会创建一个用户会话,并在内部管理一个唯一的会话,以识别与该用户交互的顺序并跟踪会话状态。一个典型的会话状态管理例子是购物车。为了有效地使用负载均衡器,代表用户购物车当前内容的数据必须存储在某个地方——通常是数据存储器——任何服务副本接收到请求(作为用户会话的一部分)时都可以访问此状态。如图2-2所示,上述过程的数据存储被标记为“会话存储”。
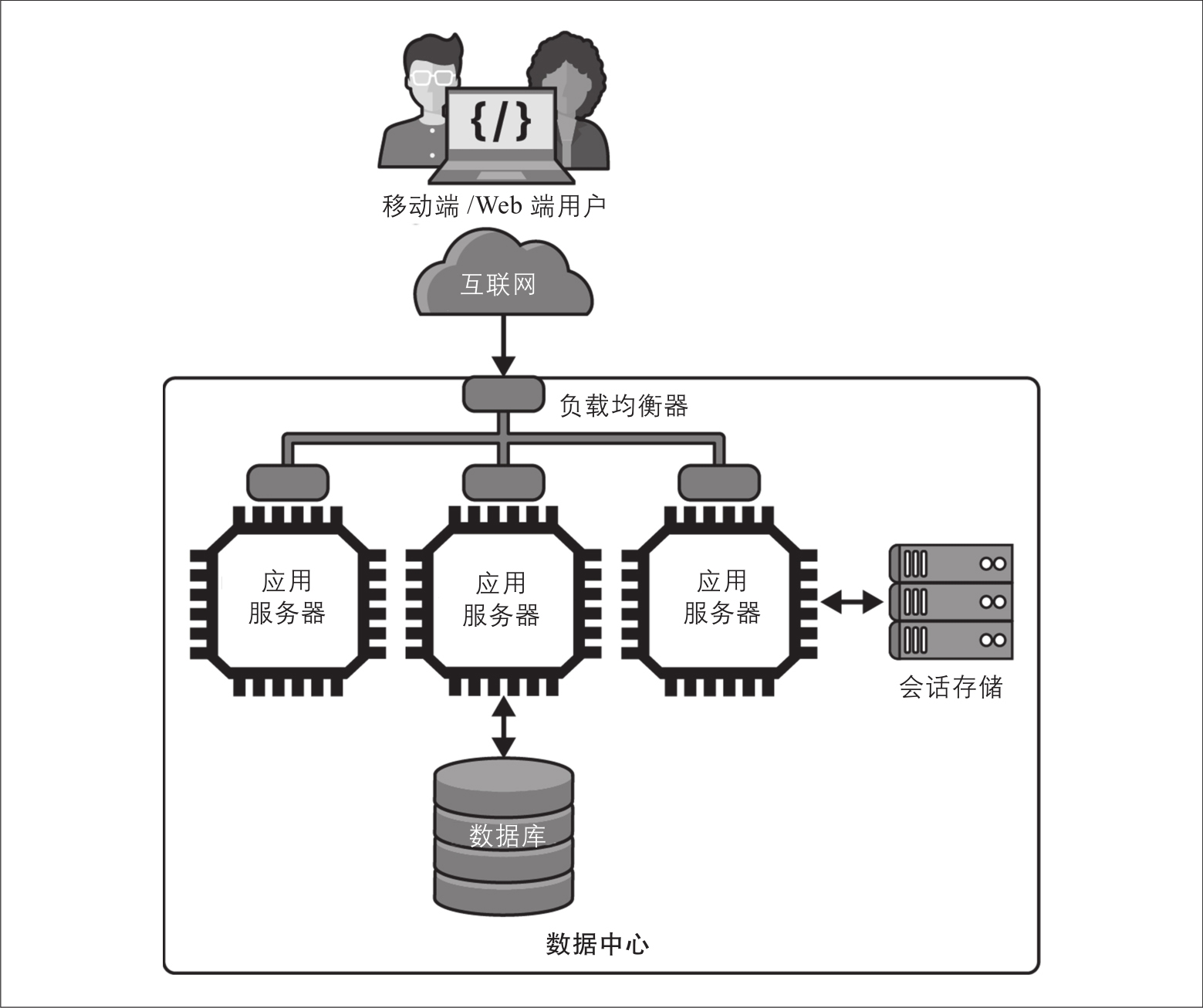
图2-2:水平扩展架构
水平扩展很有意思的地方是,理论上,你可以不断添加新的(虚拟)硬件和服务来处理增加的请求负载,并持续保持低延迟。一旦你看到延迟上升,就部署另一个服务器实例。因为使用的是无状态服务,扩展过程中无须更改代码,你只需要为部署的硬件付费,所以这是一种相对便宜的策略。
水平扩展还有另一个极具吸引力的功能:如果其中一项服务副本宕机,那么它正在处理的请求将丢失,而宕机的服务副本不管理会话状态,请求可以简单地由客户端重新发出,发送到其他服务实例进行处理。应用程序对服务软件和硬件中的故障具有弹性恢复能力,从而提高了应用程序的可用性。
然而,与任何工程解决方案一样,简单的水平扩展也有局限性。随着添加服务实例越来越多,请求处理能力会增长,理论上会无限增长。到了一定阶段,现实会让人清醒,因为单一数据库提供低延迟查询响应的能力将会减弱。缓慢的数据库查询意味着客户端的响应时间变长。如果请求的到达速度比处理速度快,一些系统组件会因为资源耗尽而过载和失败,客户端便会收到异常和请求超时。从本质上讲,数据库成了性能瓶颈,必须对其进行设计才能进一步扩展应用程序。
对于数据库服务器,增加CPU数量以及内存和磁盘的容量有助于扩展系统。例如,在撰写本书时,GCP在db-n1-highmem-96节点上可以配置SQL数据库,该节点具有96个虚拟CPU(vCPU)、624 GB内存和30 TB磁盘,可以支持4000个连接。每年花费6000美元到16000美元,对我来说相当划算!当然,水平扩展对于数据库也是一种常见的扩展策略。
要维持大型数据库高效和快速运行,往往需要技术娴熟的数据库管理员持续地看护和关注。这份工作需要很多非凡的技能,例如,查询调优、磁盘分区、索引和节点缓存等。数据库管理员是宝贵的人才,值得你珍惜,他们可以让你的应用服务保持较快的响应速度。
在扩大规模的同时,一种高效的方法是尽可能低频地从服务中查询数据库,可以在水平扩展的服务层中使用 分布式缓存 来实现。将近期检索和经常访问的数据库结果缓存存储在内存中,既可以快速检索它们,也不会给数据库带来负担。例如,未来一个小时内的天气预报不会改变,但可能会有成百上千的客户查询。天气预报发布后,你可以将其存储到缓存,所有客户端请求都将从缓存读取数据,直至预报内容到期。
对于经常读取且很少更改的数据,可以将处理逻辑改成先检查分布式缓存,例如Redis( https://redis.io )或memcached( https://memcached.org )存储。这些缓存技术本质上是使用非常简单的API进行的分布式键值存储,如图2-3所示。值得注意的是,图2-3使用了通用分布式缓存来存储会话标识符和应用程序数据,图2-2中的会话存储消失了。
你需要在服务中引入远程调用以实现缓存访问。如果你需要的数据在缓存中,那么在快速网络上,数据读取的延迟可以是毫秒级的。这比查询共享数据库实例要便宜许多,而且无须争夺稀缺的数据库连接。
引入缓存层需要你将处理逻辑修改为检查缓存的数据。如果内容不在缓存中,那么代码仍需查询数据库并将结果加载到缓存中,同时将其返回给调用者。你还需要决定何时删除缓存数据或使缓存结果无效——你的行动方案取决于数据的性质(例如,天气预报自然过期),以及你的应用程序对向客户端提供过时(也称为 陈旧 )结果的容忍度。
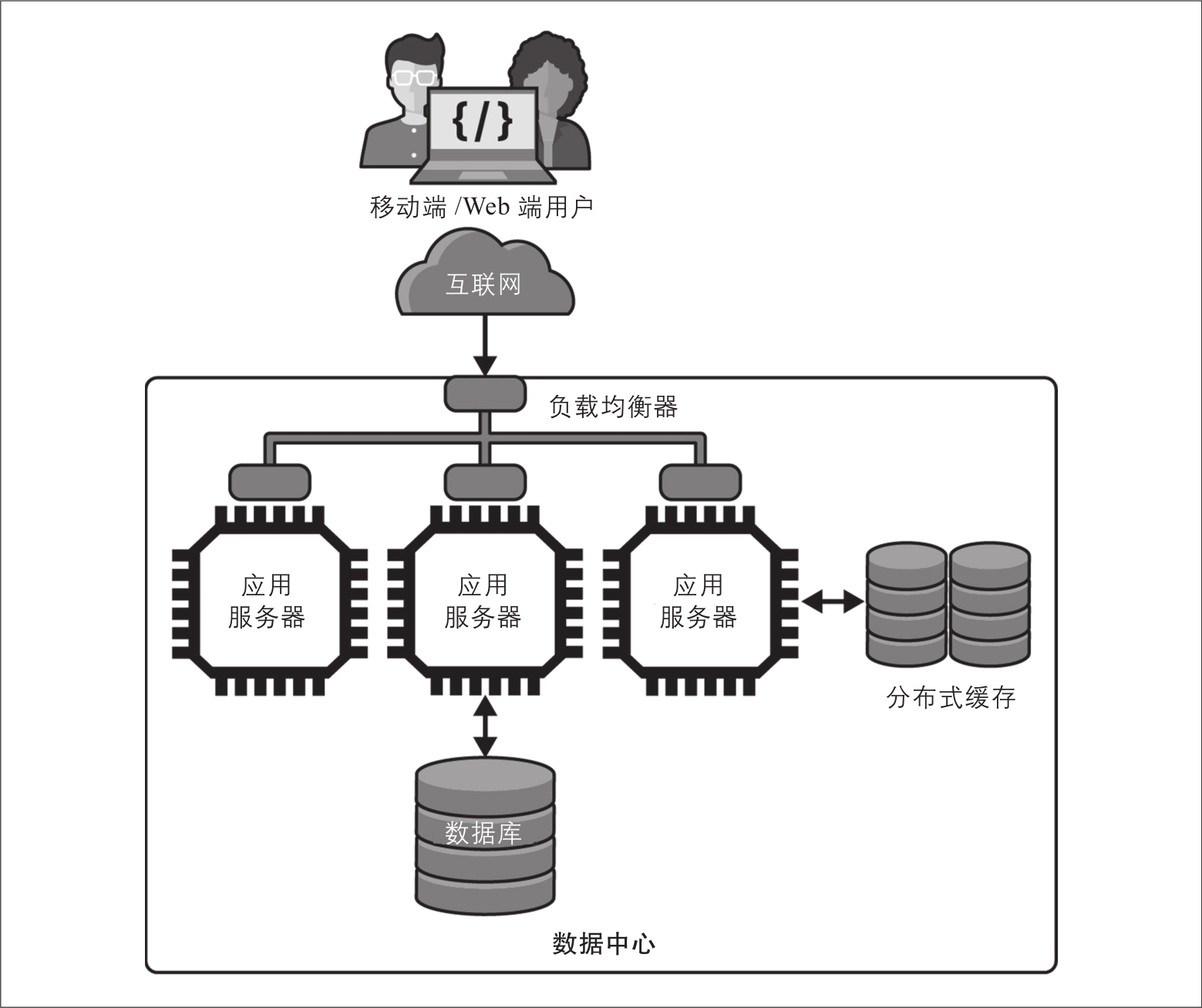
图2-3:分布式缓存
一个设计良好的缓存方案对于扩展系统是无价之宝。缓存非常适用于低频更改且经常访问的数据,例如库存目录、事件信息和联系人数据等。如果你的服务能够通过缓存处理大部分的读取请求,比如说,80%或更多,那么你所购买的额外数据库容量将会被高效使用,因为它们不需要处理这部分请求,从而能更好地支持其他请求。
尽管如此,许多系统仍需要快速访问TB级和更大的数据存储,而单个数据库在实际能力上是令人望而却步的。这样的系统需要一个分布式数据库。
在2022年左右,分布式数据库技术多得超乎你的想象。这是一个复杂的领域,我将在本书第三部分详细介绍。从通用角度来看,分布式数据库技术可以分成两大类:
分布式SQL存储
分布式SQL数据库允许组织机构将数据存储在多个磁盘,由多个数据库引擎副本查询磁盘上的数据,从而实现相对无缝的扩展。多个数据库引擎在逻辑上对应用程序显示为单个数据库,最大限度地减少了代码更改。还有一类“天生”的分布式SQL数据库,通常被称为NewSQL存储,也属于这个分类。
分布式NoSQL存储(来自众多供应商)
这类产品使用不同的数据模型和查询语言在运行数据库引擎的多个节点之间分发数据,每个节点都有自己的本地附加存储。同样,数据的位置对应用程序是透明的,通常由数据模型的设计所控制,在数据库键上使用哈希函数。领先的产品有Cassandra、MongoDB和Neo4j。
图2-4展示了我们的架构如何整合分布式数据库。随着数据量的增长,分布式数据库可以增加存储节点的数量来满足数据存储请求。当添加(或删除)节点时,跨所有节点管理的数据被重新平衡,以确保每个节点的处理能力和存储容量被平等地利用。
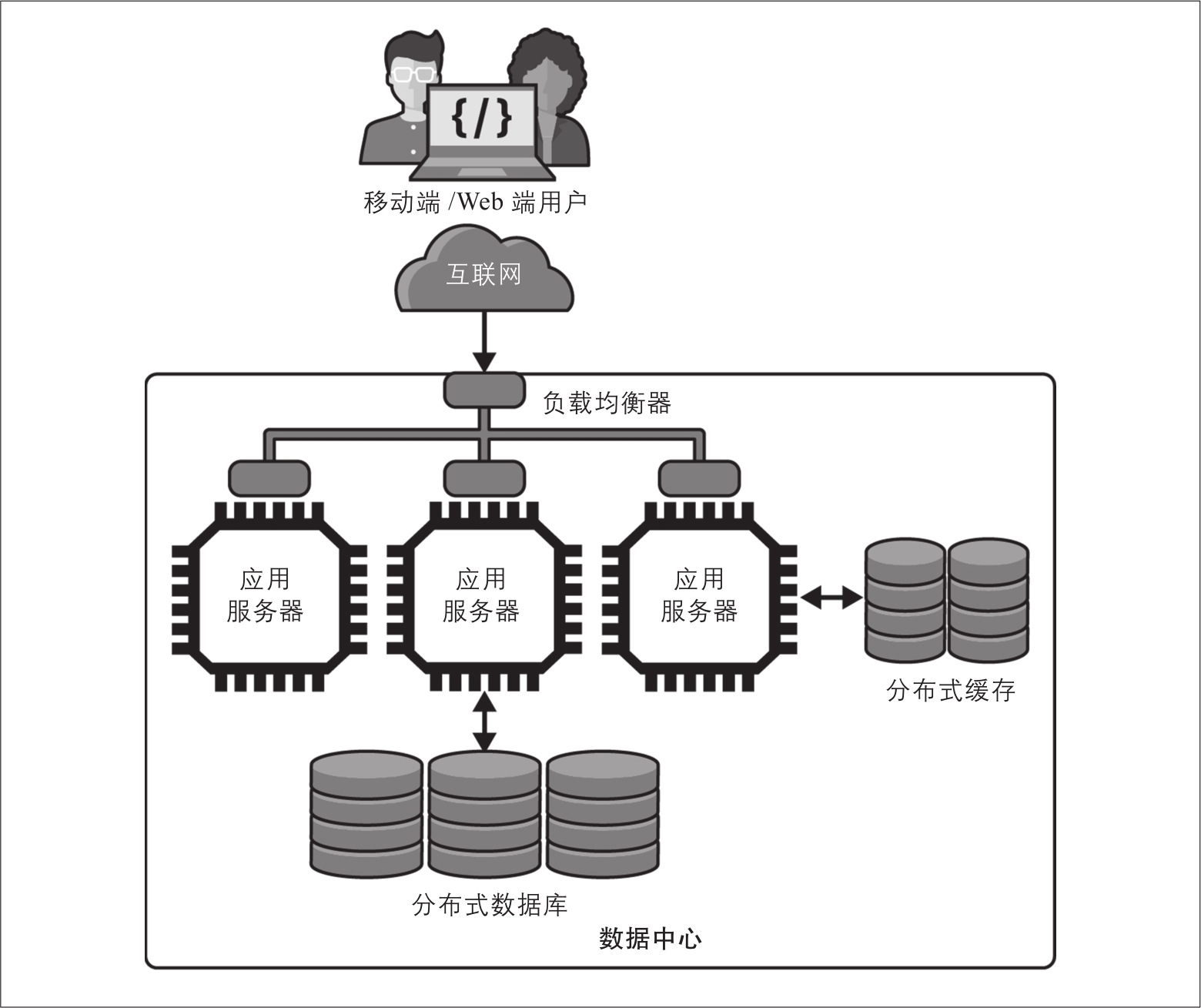
图2-4:使用分布式数据库扩展数据层
分布式数据库也提升了可用性。它们允许复制每个数据存储节点,如果一个节点宕机了或因网络问题而无法访问,那么可以使用另一个数据副本。用于数据复制的模型及其利弊权衡(剧透:一致性)将在后面的章节中介绍。
如果你主要使用云服务提供商的服务,那么你的数据层也有两种部署选择。你可以部署自己的虚拟资源,自行构建、配置和管理分布式数据库服务器。或者,你也可以使用云托管数据库。后者简化了管理、监控和扩展数据库的工作,其中许多任务基本上由你选择的云服务提供商负责。当然,没有免费的午餐,无论选择哪种方法,你总是需要付费。
你需要扩展的任何实际系统都包含许多服务,通过服务间的交互协作来处理请求。例如,访问Amazon.com上的网页可能需要调用超过100种不同的服务,然后才能将响应返回给用户 [3] 。
本章详细阐述的无状态、负载平衡、缓存架构的美妙之处在于它可以扩展核心设计原则并构建多层应用程序。在完成请求时,服务可以调用一个或多个依赖服务,服务已经被不同的副本复制,由负载平衡器调度。图2-5所示的是一个简单示例。在服务如何交互以及应用程序如何确保依赖服务的快速响应方面存在许多细微差别,我将在后面的章节详细介绍。
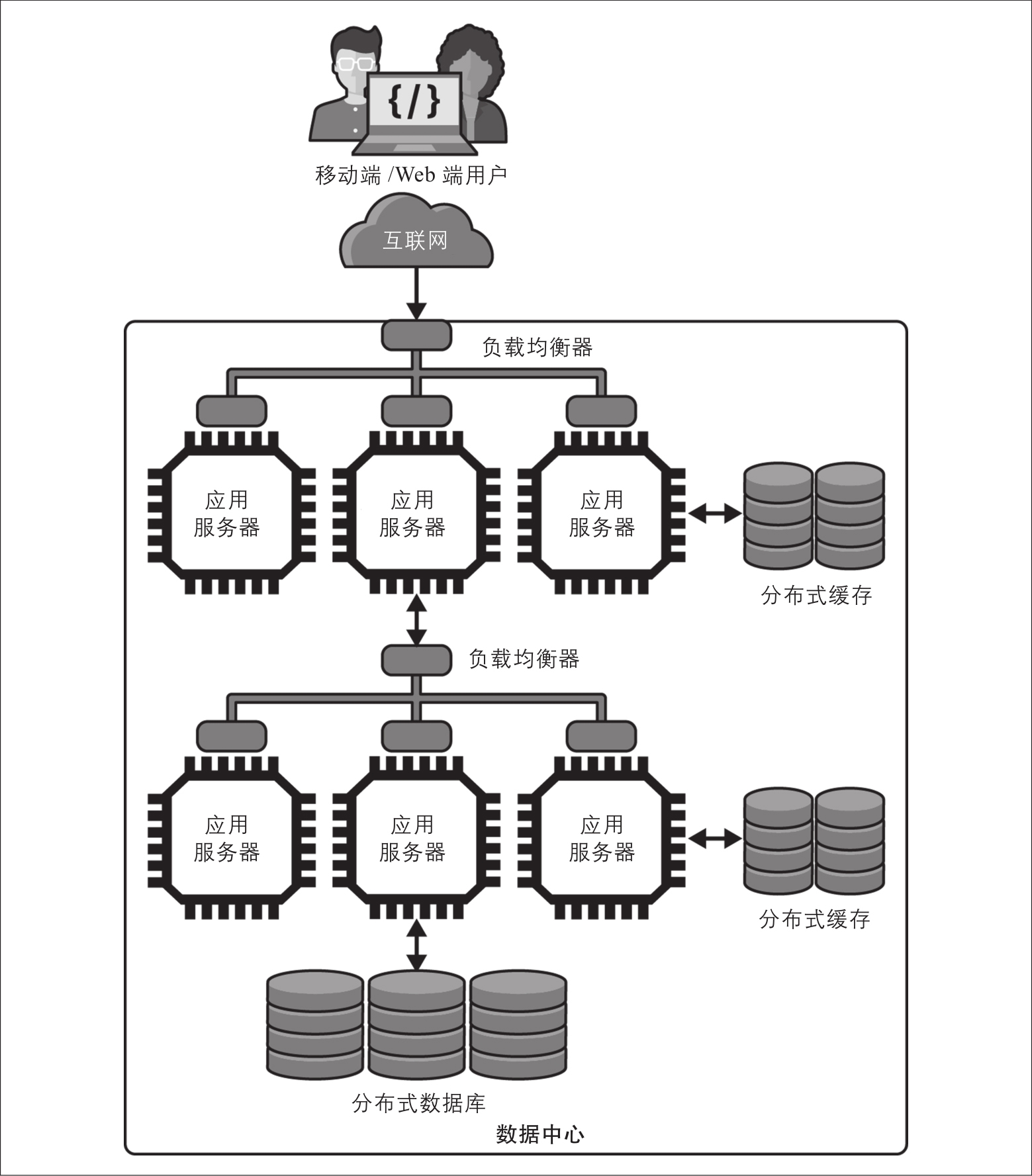
图2-5:使用多个处理层扩展处理能力
上述设计在架构的每一层引入了不同的负载均衡服务。例如,图2-6展示了两个面向互联网的服务,它们各自有多个副本,都调用了提供数据库访问的核心服务。每个服务都是负载平衡的,并且使用缓存来提供高性能和可用性。这种设计通常用于为Web(网页)客户端和移动客户端分别提供服务,每个服务都可以根据所承受的不同负载独立扩展。这就是常说的服务于前端的后端(BFF)模式 [4] 。
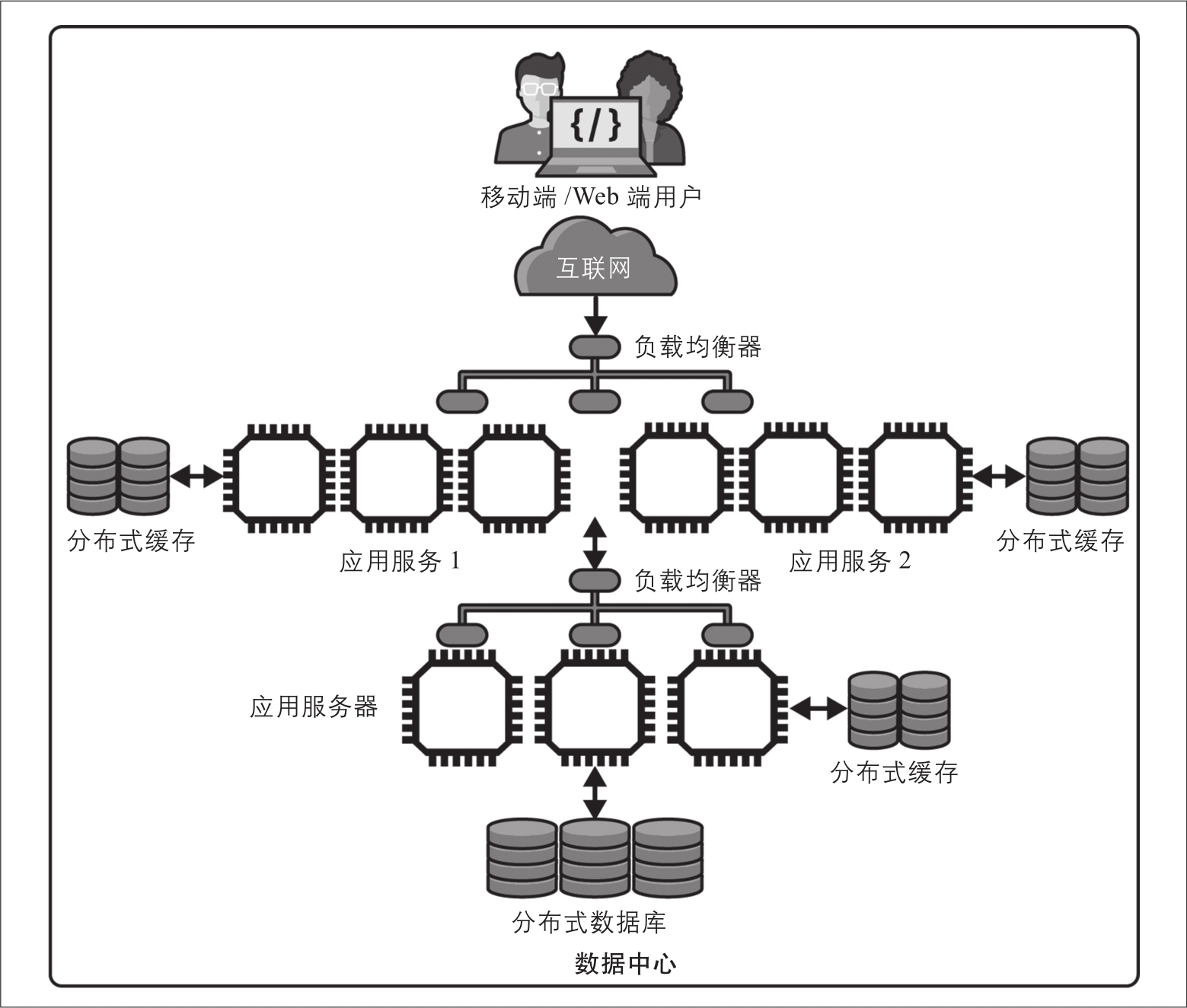
图2-6:具有多种服务的可扩展架构
此外,通过将应用程序分解为多个独立的服务,可以根据服务需求对单个服务进行扩展。例如,如果来自移动用户的请求量在增加,而来自Web用户的请求量在减少,则可以为相应服务提供不同数量的实例来满足需求。这便是将单体应用程序重构为多个独立服务的主要优势,因为不同的服务可以单独构建、测试、部署和扩展。我将在第9章探讨基于这类服务(称为微服务)设计系统的主要问题。
大多数客户端应用程序请求都需要响应。用户可能希望查看特定产品类别的所有拍卖品或查看在特定位置可供出售的房地产。这些示例中,客户端发送请求并等待,直至收到响应。从请求发送到结果接收之间的时间间隔就是请求的响应时间。你可以使用缓存,直接返回预先计算好的响应结果来减少响应时间,但仍然有许多请求会涉及数据库访问。
对于更新应用程序数据的请求,也存在类似的情况。如果用户在下订单前更新了送货地址,那么新的送货地址必须被持久化,以便用户在单击“购买”按钮之前可以确认地址。这种情况下的响应时间包括数据库写入的时间,直至用户收到响应来确定时长。
然而,有部分更新请求无须将数据完全持久化到数据库中便可以成功响应。例如,双板滑雪者和单板滑雪者熟悉的电梯票扫描系统,该系统会检查用户是否持有当天乘坐电梯的有效通行证。系统还会记录用户乘坐的电梯、上车的时间等。然后,双板滑雪者/单板滑雪者可以使用度假村的移动应用程序查看他们一天乘坐了多少次电梯。
当一个人等待电梯时,扫描仪设备使用RFID(射频识别)芯片阅读器验证通行证,有关乘客、电梯和时间的信息通过互联网发送到滑雪胜地运营的数据采集服务。电梯乘客不必等待数据持久化完成,因为响应时间可能会减慢电梯装载速度。电梯乘客也不期望他们可以立即使用应用程序来查看这些数据。他们只是坐上电梯,和朋友闲聊,然后计划下一次滑行。
实现服务时可以充分利用这种类型的场景的特点来提高响应能力。事件的数据被发送到服务后,服务确认接收并同时将数据存储在远程队列中,随后写入数据库。分布式排队平台可以可靠地将数据从一个服务发送到另一个服务,但并非总是以先进先出(FIFO)方式。
将消息写入队列通常比写入数据库快得多,请求能够更快地被成功确认。部署另一个服务从队列中读取消息并将数据写入数据库。当滑雪者检查他们乘坐的电梯时(可能是3小时或3天后),数据已成功保存在数据库中了。
实现这种方法的基本架构如图2-7所示。
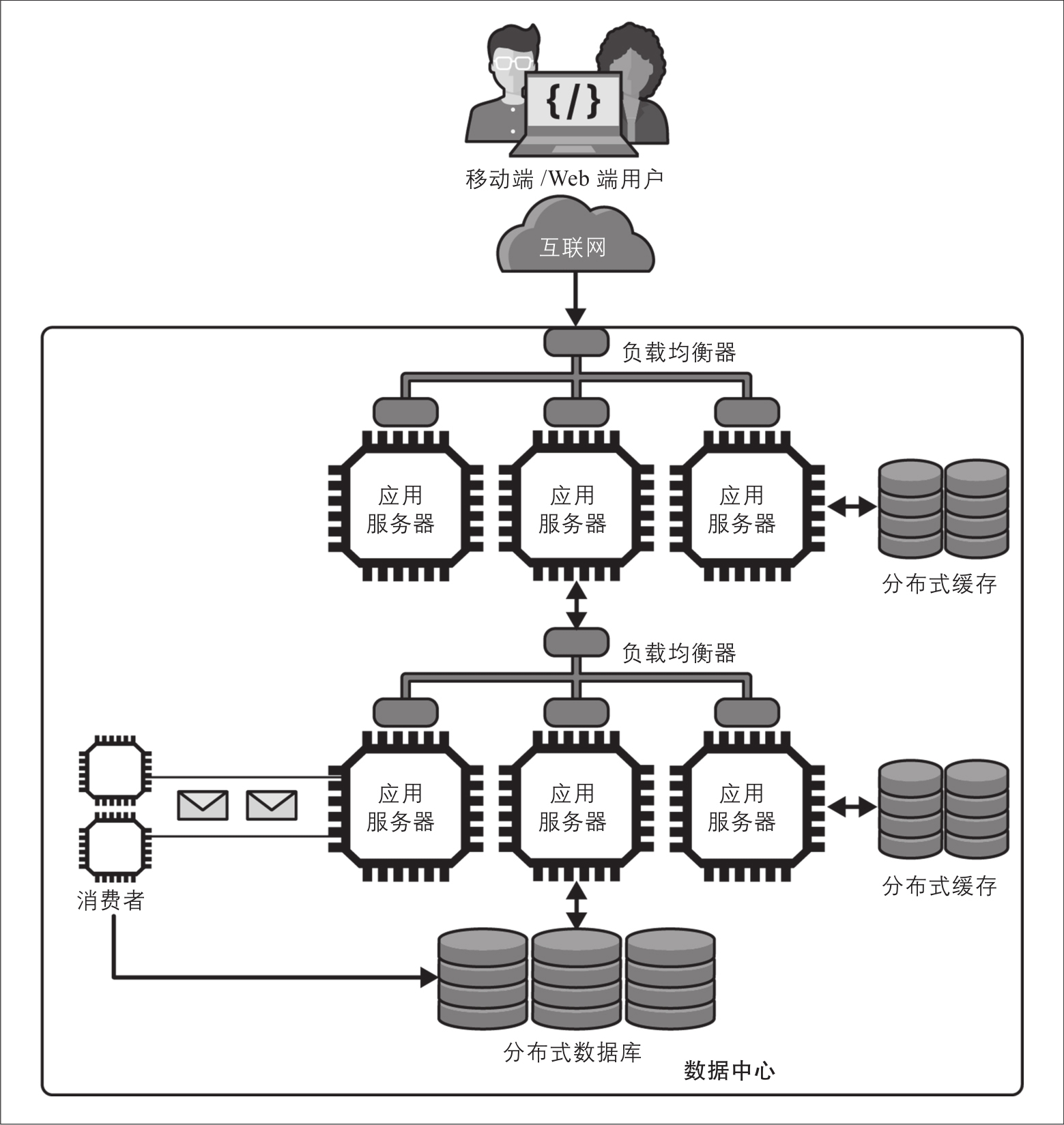
图2-7:通过消息队列提升系统响应能力
对于不需要立即获得写入操作结果的场景,应用程序都可以使用上述方法来提高响应能力,从而提升可扩展性。应用程序可以利用多种排队技术,我将在第7章讨论排队技术是如何运作的。排队平台都提供异步通信。 生产者 服务将消息写入队列后,队列充当临时存储, 消费者 服务从队列中删除消息并对示例中存储滑雪电梯乘坐细节的数据库进行必要的更新。
这个方法的关键是数据最终会被持久化,通常来说用时最多几秒钟,但采用这种设计的用例能够适应更长的延迟而不影响用户体验。
如果服务和数据运行在存储不足的硬件上,那么即使是最精雕细琢的软件架构和代码,其可扩展能力也会受到限制。部署在可扩展系统中的开源软件和商业平台在设计时就要考虑对CPU内核、内存和磁盘等硬件资源的利用,在系统性能和可扩展性之间取得平衡,并且尽可能降低成本。
从另一方面来说,在特定情况下,升级CPU内核数量和可用内存大小并不能提升系统的可扩展性。例如,如果代码是单线程的,即便在更多内核的节点上运行它也不会提高性能,因为它在任何时候都只会使用一个内核,其余的内核根本没用。如果多线程代码包含许多序列化执行的部分,那么一次只能执行一个线程内核以确保结果正确,即阿姆达尔(Amdahl)定律所描述的现象( https://oreil.ly/w8Z5l )。这使得我们可以根据串行执行的代码量来添加更多CPU内核,计算理论上提升的代码速度。
阿姆达尔定律的两个关键数据:
●如果只有5%的代码串行执行,其余的并行执行,那么内核上限为2048个,超过了基本上没有效果。
●如果50%的代码串行执行,其余的并行执行,那么内核上限为8个,超过了基本上没有效果。
这个现象也说明了为什么高效的多线程代码对于实现可扩展性至关重要。如果你的代码没有像线程那样高度独立地运行,即使投入再多金钱也无法带来可扩展性。这就是我在第4章专门讨论多线程主题的原因——它是构建可扩展分布式系统的核心知识。
为了说明升级硬件的效果,图2-8显示了基准系统的吞吐量如何随着数据库部署在更强大(且更昂贵)的硬件上而提高
。基准测试系统使用了Java服务,该服务接受来自客户端(一个生成负载的客户端)的请求,查询数据库并将结果返回给客户端。客户端、服务和数据库运行在AWS云中于相同区域部署的不同硬件资源上。
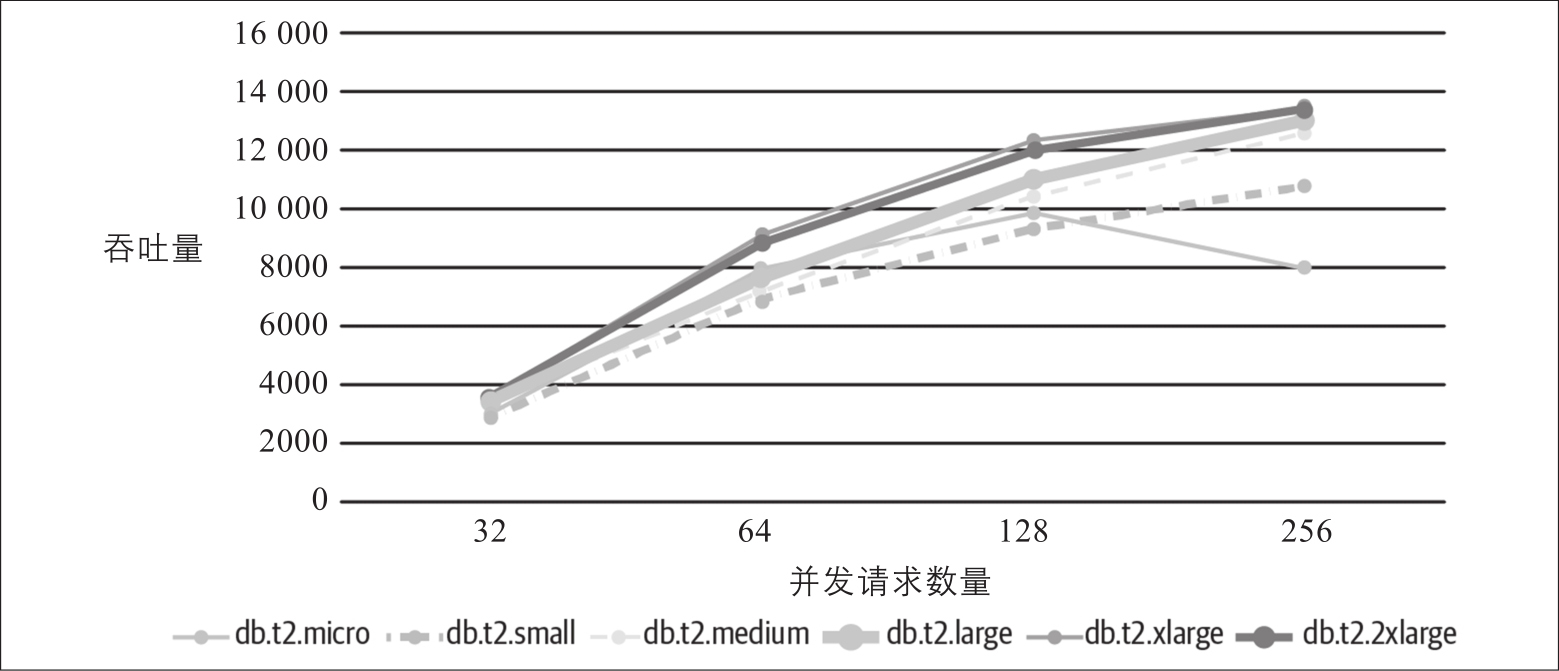
图2-8:一个扩展数据库服务器的示例
在本次测试中, x 轴代表并发请求的数量从32增加到256, y 轴则代表AWS EC2的关系数据库服务(RDS)上不同硬件配置的系统吞吐量。图表底部列出了不同的硬件配置,左边是最弱的,右边是最强大的。每个客户端都通过HTTP同步发送固定数量的请求,在接收到上一个请求的结果和发送下一个请求之间没有停顿,对服务器施加很高的请求负载压力。
从这张图表中,我们可以直观地总结:
●总的来说,数据库选择的硬件越强大,吞吐量就越高。
●db.t2.xlarge和db.t2.2xlarge实例的吞吐量差异较小。这可能是因为服务层成为性能瓶颈,或者数据库模型和查询没有充分利用db.t2.2xlarge RDS实例的额外资源。无论如何,这就是花更多的钱却没有带来收益的案例。
●在请求负载增加到256之前,中间两个较弱的实例(db.t2.medium,db.t2.large)执行得相当好。这两个实例的吞吐量下降表明它们已经超载,如果请求负载增加,结果只会变得更糟糕。
希望这个简单示例已经说明了为什么需要谨慎地升级硬件来实现扩展。添加硬件必然增加成本,但它并不总是能带来性能改进。通过简单的实验来测量和评估硬件升级的效果至关重要,它提供可靠的数据来指导你的设计并向利益相关者证明成本的合理性。
本章简要介绍了可用于将系统扩展为消息服务和分布式数据库的组合的主要方法。中间忽略了很多细节,你肯定也意识到了——在软件系统中,细节就是“魔鬼”。后续章节将逐步开始探索细节,第3章将从每个人都需要了解的分布式系统基本特征开始介绍。
本章还绕开了对软件架构主题的讨论。我在实现应用程序业务逻辑和数据库访问的架构中使用了术语 服务 来表示分布式组件。服务是独立部署的进程,它们使用HTTP等远程通信机制进行通信。在架构领域,服务最接近于面向服务的架构(SOA)模式中的服务,那是一种用于构建分布式系统的著名架构方法,它更现代的演变围绕着微服务展开。微服务往往是更有凝聚力的封装服务,可促进持续开发和部署。
如果你想更深入地讨论服务架构问题和一般的软件架构概念,Mark Richards和Neal Ford的 Fundamentals of Software Architecture:An Engineering Approach ( https://oreil.ly/soft-arch ;O'Reilly,2020年)一书(中文译本为《软件架构:架构模式、特征及实践指南》)是很好的入门书籍。
另外,有一类 大数据 软件架构可以解决在大数据集合中出现的问题,其中最典型的是数据再处理。当代码或业务规则更改而需要重新分析已经存储和分析的数据时,就会发生这种情况。抑或是软件修复或者从原始数据中引入了新算法(新算法能发现更多数据的特性),也可能会触发数据再处理。在O'Reilly Radar博客上,Jay Krepps于2014年发表的文章“Questioning the Lambda Architecture”( https://oreil.ly/zkUBT )讨论了Lambda和Kappa架构,这两个架构在数据再处理领域都很突出。
[1] Mark Richards and Neal Ford. Fundamentals of Software Architecture: An Engineering Approach (O'Reilly Media,2020).
[2] 有关AWS实例的描述,可参阅Amazon EC2实例类型( https://oreil.ly/rtYaJ )。
[3] Werner Vogels,“Modern Applications at AWS,”All Things Distributed,28 Aug. 2019, https://oreil.ly/FXOep .
[4] Sam Newman,“Pattern:Backends For Frontends,”Sam Newman & Associates,November 18,2015. https://oreil.ly/1KR1z .