
下载掌阅APP,畅读海量书库
立即打开



归根结底,批处理和流处理之间的主要区别在于每个批处理所包含的数据量和处理速度。批处理关注的是尽可能多地收集数据,即使这会带来滞后。而流处理关注的是尽可能快地收集数据,尽管这会导致一些损失。正因为如此,批量流系统的数据质量(也就是数据管道中给定阶段的数据健康状况)往往更高,但是当数据在进行实时流传输时,产生错误的空间和数据质量降低的情况都会增加。
例如,市场营销团队会根据用户行为来确定广告投放的位置,营销人员会使用在某一品牌的产品、客户关系管理平台和广告平台之间实时流动的数据。API中一个小的模式更改可能会导致错误的数据,从而让公司超支、错失潜在的收入,或者为用户提供了不相关的广告从而带来糟糕的用户体验。
这个场景和前面的信用卡欺诈监控的示例只揭示了不良数据在你异常优秀的数据管道中作祟时可能发生的事情中的冰山一角。那么,我们该如何为流处理解决数据质量方面的问题呢?
传统来说,数据质量是通过测试来强制执行的:你分批接收数据,并希望数据按照你认为必要的时间间隔到达(例如,每12h或每24h)。你的团队会根据其对数据的假设编写测试,但其实不太可能通过编写测试来解释所有可能的结果。
数据质量往往会出现新的错误,而工程师会急于在问题影响下游表格和用户前进行根因分析。数据工程师最终会解决问题并编写一个测试以防止该问题再次发生。
简而言之,测试很难扩展,正如我们在与数百个数据团队交谈后发现,测试仅仅涵盖了潜在数据质量问题的20%——这些问题对你来说属于“已知的未知”。随着当前现代数据生态系统的日益复杂,公司可以从任何地方的数十到上百个内部和外部数据源中获取数据,而传统的处理和测试方法已经开始过时。
即便如此,在20世纪10年代中期,当组织开始使用Amazon Kinesis、Apache Kafka、Spark Streaming和其他工具接收实时数据时,也采用了同样的方法。虽然向实时洞察的转变对企业来说是件好事,但它也为处理数据质量带来了新的麻烦。
如果确保批处理数据的可靠性都很困难的话,你可以想象一下对每分每秒都在演变的数据运行和扩展测试会多么难以实现!字段的缺失、不准确或滞后都可能会对下游系统产生不利影响,而且如果无法实时捕获数据问题,这些影响就可能会扩散到整个业务中。
虽然单元测试、功能测试和集成测试等传统数据质量框架可能包含了一些基础功能,但它们无法在难以进行预测和实时演变的数据集中进行扩展。为了确保提供给这些实时用例的数据是可靠的,数据团队在处理流处理时需要重新考虑所使用的数据质量方法。
现在,我们知道了这些挑战。所以在下一节中,我们将分享如何管理流处理系统中的数据质量,特别是利用AWS Kinesis和Apache Kafka进行管理。
AWS Kinesis
如图3-1所示,亚马逊的Kinesis服务是一种流行的无服务器流处理工具,适用于依赖实时数据的应用程序。Kinesis的容量可“按需”扩展,从而减少了在数据量增加前预置和扩展资源的需要。
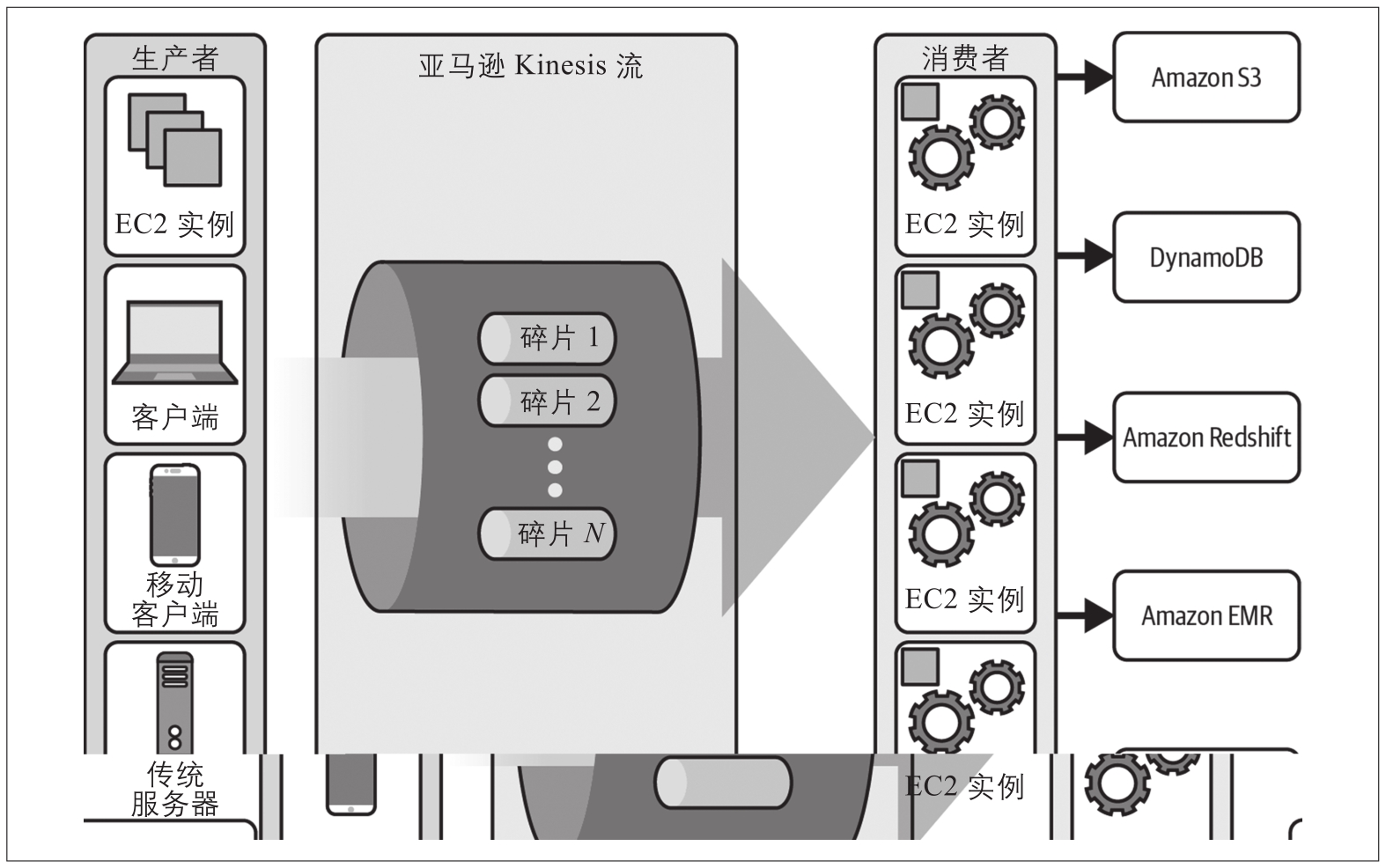
图3-1:AWS Kinesis将数据流式传输到各种结构化消费者中,包括数据仓库、数据库和定制的大数据平台
Kinesis(和其他流式服务)可以被配置为从其他AWS服务、微服务、应用程序日志、移动数据和传感器数据等来源捕获数据。该服务可以扩展到每秒流式传输千兆字节(GB级)的数据。
使用Amazon Kinesis有以下几个优势:
按需可用性
AW S为按需预置设定了行业标准,这意味着资源组可以在负载增加时进行扩展。这使得该服务在数据量出现意外峰值时更加可靠和稳定,并且不需要有经验的数据工程师来处理集群和分区管理。
成本效益
Kinesis的付费方案与资源使用量成正比。这对其他类型的无服务器架构来说是一个常见优势,但对于流式服务来说却有着特殊的意义,因为流式服务的数据吞吐量可能会随着时间的推移而急剧变化。
完善的软件开发工具包(Software Development Kit , SDK)
Kinesis支持Java、Android、.NET和Go等多种编程语言的开发,比一些竞争对手能够支持的语言数量要多得多。例如,相比之下,Kafka仅支持Java。
与AWS基础设施的集成
选择Kinesis而不是其他替代方案的一个关键原因在于,你是否已有现成的集成方案在AW S栈中。处于霸主地位的亚马逊自有其优势,例如,与第三方或开源替代方案相比,Kinesis与Amazon S3、Amazon Redshift和其他亚马逊数据服务的集成要容易得多。
Apache Kafka
Apache Kafka是一个开源事件的流式平台。具体来说,Kafka Streams是支持流式数据进出Kafka集群的客户端库。该服务提供数据流和集成层以及流式分析。Kafka流式服务针对低延迟进行了优化,该服务宣称其延迟低至2ms,但会受限于网络吞吐量。
Kafka Streams提供了以下几个优点:
开源社区
Kafka是一个开源软件,这意味着该工具可以免费使用。此外,它还有一个活跃的在线社区,用户可以通过论坛、聚会和在线参考资料来分享最佳实践和学习成果。
增加可定制性
虽然Kafka比Kinesis等集成度更高的流式解决方案具有更陡的学习曲线,但用户具有更强的可配置性,包括手动指定数据的保留期限(Kinesis将其固定为7天)。
高吞吐量
在测试中,Kafka已被证明支持高达每秒30000条记录的吞吐量,而Kinesis仅支持每秒数千条记录。
AWS Kinesis和Apache Kafka等流式解决方案可以将数据直接实时传输到分析系统中或传输到数据仓库进行存储、处理和转换。有时,数据团队会选择将这些输入直接“流式传输”到下游系统,例如在拼车应用程序或实时欺诈检测工具中。然而,鉴于流式系统的高延迟,这种类型的分析型数据通常容易出现更多错误,而让实时或近乎实时地弄清这些数据的用途变得更加困难。这也是为什么批处理通常成为分析型用例的首选方法。
当你在AWS Kinesis和Apache Kafka之间进行选择时,实际上还是要取决于数据团队的需求。鉴于AWS Kinesis等托管解决方案易于设置,寻求快速实现价值的小型数据团队将受益于这种软件即服务(SaaS)的产品,而拥有更具体需求的大型数据团队可能会发现Apache Kafka更符合要求。
无论你选择以批处理还是流处理的方式来收集数据,都需要通过转换来弄清数据的用途。在管理数据质量方面,这一过程的第一步通常是数据标准化。