
下载掌阅APP,畅读海量书库
立即打开



你也许可以猜到,分析型数据和事务型数据在几个关键方面有所不同,这些方面决定了我们要如何管理其可靠性,如图2-1所示。
在数据管道中,事务型数据几乎总是出现在分析型数据的上游。这是因为分析型数据能够(并且)经常包含事务型数据存储的聚合或扩充。某一用户早上5点时在浏览器中的点击率是一个事务型数据,而12月份营销活动的点击率则是相应的分析型数据。
事务型数据与分析型数据的区别很重要,一个关键原因是吞吐量与延迟的权衡。吞吐量-延迟的约束会影响任何具有固定计算能力的系统。传统的吞吐量指的是在某一单位时间内处理的数据量,而延迟指的是数据被处理之前所等待的时间。
想象一家外面正在排队的网红咖啡厅。排队的人要多久才能拿到咖啡呢?这个过程包括排队、下单、付款,然后等待咖啡师制作饮品。这段时间的总和就是该咖啡厅的延迟。相反,单位时间内能够在室内享用咖啡的顾客数量就是该咖啡厅的吞吐量。
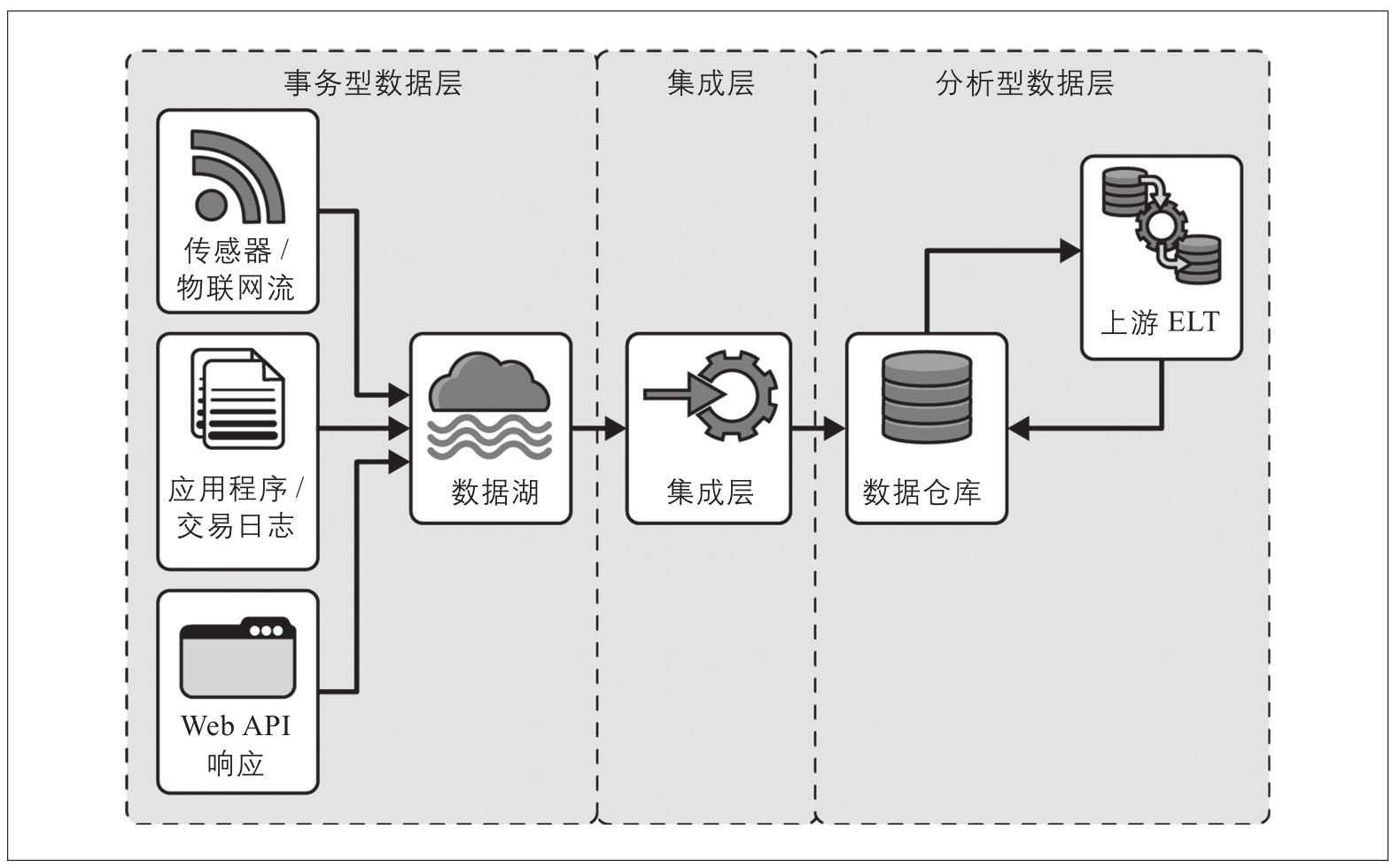
图2-1:数据平台示例,仅说明区分事务型数据和分析型数据的一种方法
不过,这两个度量数据处理效果的指标注定要相互竞争。咖啡厅不能既有高吞吐量又有低延迟。为什么呢?吞吐量和延迟并不是完全相反的呀。这其实与现实中数据处理系统的构建方式有关,具体来说,这与有限数量的请求处理程序有关。
让我们再来想象一下这家咖啡厅。这里有固定数量的员工,而我们订购的机器人serveo-trons由于芯片短缺而出现积压,无法发货。作为经理,我们必须决定应该为浓缩咖啡机和收银台配备多少员工,而又有多少员工应该负责收拾桌子。注意到此处的权衡了吗?假设我们不惜一切代价优化咖啡厅的延迟,那几乎就会把所有员工都配备到收银台和浓缩咖啡机旁,以便顾客能够尽快下单并收到他们的饮品。但如果我们这样做,吞吐量就会大幅降低,因为没人收拾桌子为新来的顾客腾位置。而与此相反,如果我们让大多数员工在餐桌周围服务,在顾客离开的那一刻开始收拾餐桌,那么延迟就会增加,因为没有人操作收银机!
在某些情况下,权衡是显而易见的。事务型数据库需要在页面加载时尽快获取包括订单详细信息在内的某些信息。因此,通过各种设计决策,它们的架构将针对低延迟进行优化。相比之下,分析型数据库则迎合了用户对海量数据集进行大规模聚合的需要,因此它们必须针对高吞吐量进行优化。这种关于使用哪些服务来做什么的启发式建议并不完美,但它至少解释了为什么你通常不会从客户的用户界面(UI)中查询Snowflake或Redshift,或者在MySQL或Postgres实例中运行万亿行的聚合。