
下载掌阅APP,畅读海量书库
立即打开



当我们遇到一个机器学习任务的时候,首先要对其任务类型进行判别,然后才能选择正确的方法来解决问题。总的来说,机器学习可以根据其有无明确的响应变量(也称因变量)分为三大类,即有监督学习(有响应变量)、无监督学习(无响应变量)和半监督学习(部分包含响应变量),如图1—3所示。例如我们要分辨一个邮件是否为垃圾邮件,如果我们已经有标注好的邮件信息(即已经知道哪些邮件是垃圾邮件,哪些是非垃圾邮件),那么这就是一个有监督的问题。如果我们单纯要根据邮件的内容长短(但没有预知信息)来给邮件分类,例如分为长文本邮件和短文本邮件,那么这就是一个无监督问题。一种特殊的情况是半监督学习,它是在标注信息有限的情况下,人工先对部分样本进行标注,然后利用已经标注好的样本进行训练,得到一个有监督学习的模型。然后利用这个模型对未知样本进行预测,从而自动化获得标注信息,最后依赖所有的样本及其标注信息,再次训练样本获得一个新的模型。
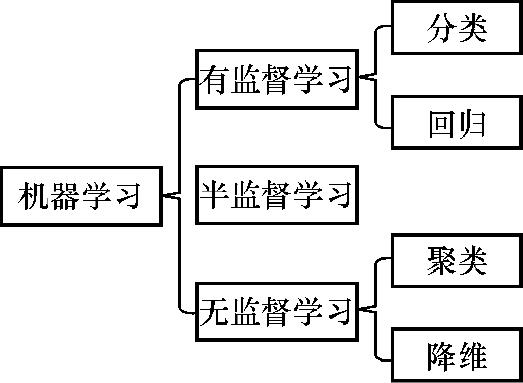
图1—3 机器学习的种类
至于有监督学习和无监督学习,又可以继续细分。在有监督学习中,根据响应变量是连续变量还是离散变量,可以分为分类和回归两种。当响应变量为离散变量时,称为分类任务。例如银行会根据客户的一些基本材料判断其是否违约,那么是违约还是不违约,共计两种情况,就是典型的分类任务。当响应变量为连续变量时,我们称之为回归任务(这是广义的概念,不同于狭义的基于最小二乘法的回归模型)。例如我们想要预测每一天的气温,而气温是一个离散型随机变量,有无数种可能,因此它属于回归任务。无监督学习可以分为聚类和降维两类任务。其中,聚类是指在没有先验知识的情况下,基于一定的标准对样本进行划分。例如商业领域分析用户画像的时候,就可以根据用户的消费频次、消费金额和最近消费时间给用户进行聚类,从而筛选出具有价值的重要客户,并对他们予以更多的关注。另外,降维任务是指在高维数据中把冗余信息剔除,把重要的变量筛选出来或利用较少变量来对数据进行表征。例如特征中可能存在严重的共线性(变量之间存在较强的相关性),那么就可以剔除一些常数变量(在所有样本中都是同一数值的变量)。其他常用的降维方法还有PCA、SVD等。