
下载掌阅APP,畅读海量书库
立即打开



深度神经网络在图像识别领域已经取得了突破性的进展,但在自然语言处理这个重要的领域,却迟迟没有获得巨大突破。从图灵测试到ChatGPT,自然语言处理一直是人工智能最大的试金石,也是公众感知最直接、最深刻的人工智能,无数人工智能从业者都想拿下这颗皇冠上的明珠,但在大语言模型出现以前无不折戟沉沙。人工智能在这个领域无法取得突破主要还是因为数据、算力和算法这三个方面的限制,然而随着技术的快速进步,这些前人看似无法逾越的壁垒正在被锲而不舍的人工智能从业者们逐一攻克。
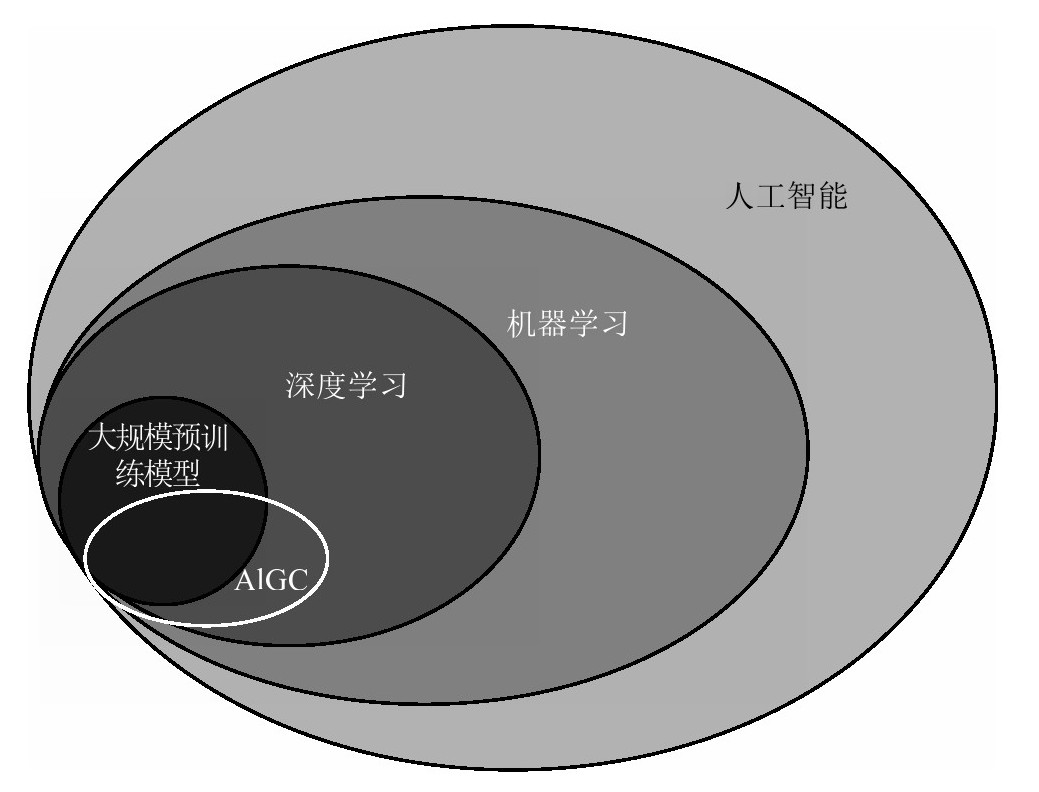
图1-3 大语言模型在人工智能中的定位
在数据方面,与图片的人工标注相比,自然语言的标注工作要复杂得多,需要根据不同的工作场景设定不同的规则指南,确保所有人理解标注的一致性,因此一直没有一个像ImageNet那样高质量的数据集。解决这个问题的方法是无监督学习法,其逐渐发展成熟大大减少了标注数据量的需求。比如后来的GPT和BERT等自然语言模型,其实都是用海量的未经标注的书籍、新闻和文章等进行训练,模型通过阅读大量的文本来学习语言的规律和结构。
比如在一句话中,模型会根据前面的词语来猜测下一个可能出现的词,这个过程类似于填空。通过大量的无监督学习来调整深度神经网络海量的参数,这个过程就是无监督预训练。实际上,动辄包含几百亿参数的大模型的训练也只能依靠这样的方式,因为大模型需要的数据量太大,根本无法通过手动标注完成。所以说,模型的进步解决了数据缺乏的问题,而互联网在过去几十年的发展让大量的人类知识得以数据化,为大模型的出现做好了准备。
在算力方面,则需要感谢云计算、大规模数据中心、分布式算法和显卡等算力硬件和基础设施的飞跃式发展。大语言模型需要的算力已经不是单独的家用级显卡可以处理的了。英伟达推出了Tesla系列显卡,包括我们今天熟知的V100和A100。2024年,英伟达在一年一度的GTC大会上发布了全新一代Blackwell架构人工智能GPU芯片B200。这些显卡的设计都是为了满足云计算中心巨大的算力需求。以大语言模型GPT-3为例,它的预训练就是采用分布式训练方式,通过微软提供的算力,在多个V100显卡上完成的。所以一个业内说法是,大模型天生是长在云上的。
最后也最重要的,是算法的进步。在2010年左右,主流的算法模型是卷积神经网络(convolutional neural networks,简称CNN)和循环神经网络(recurrent neural network,简称RNN)这两种深度神经网络。CNN就像一台专门处理图像的“特征提取器”。它有一系列的“滤镜”,每个滤镜可以检测图像中的不同特征,比如直线、边缘、纹理等。这些滤镜在图像上滑动,从图像中提取出特定的特征,并将这些特征组合起来,帮助我们识别图像中的不同物体或模式。上文提到的AlexNet就是基于CNN设计的。
RNN就像一个可以记住过去信息的“故事讲述者”。它能够处理序列信息,比如句子中的单词或时间序列数据。RNN内部有一种记忆机制,它可以根据之前的信息预测下一个单词或处理下一个时间点的数据。这种记忆能力让它能够更好地理解语言的连贯性或是时间上的依赖关系。
总的来说,CNN擅长从图像中提取特征,而RNN则适用于处理序列信息,能够在自然语言处理中捕捉信息之间的关系。后来CNN也被用来提取语言中的各种特征,因此也用于自然语言处理的不同任务中。但这两种神经网络都有各自的缺陷,CNN主要用于捕获局部特征,难以处理较长的文本序列。RNN存在梯度消失和梯度爆炸的问题,尤其是在处理长序列时。
正因为算法上的不足,各大研究团队都在暗中摩拳擦掌,试图在算法上进行创新,在自然语言处理领域实现突破。
首先取得突破的是鼎鼎大名的谷歌大脑团队,他们在2017年发表了一篇对深度学习产生深远影响的论文,题为“Attention Is All You Need”(《注意力是你所需要的一切》),并发表了以论文为理论基础的Transformer架构。
Transformer最大的创新是一种叫作多头注意力的自注意力机制。相对于传统的RNN, Transformer在自然语言处理中有一些明显的优势。首先是Transformer可以利用多头注意力机制,使每个词同时与其他所有词建立关系,这大幅提升了模型能理解上下文的长度;其次是位置编码让Transformer里的每个token(词元,语言类模型的最小数据单位)可以进行并行计算,而不是像RNN一样必须按照语序进行依次计算,这大幅提升了模型的训练效率,让超大规模参数的语言模型的预训练变得可能。由于这些优势,Transformer一出现就建立了自然语言处理方面机器学习的新范式,此后成功的模型都是基于Transformer开发的。
谷歌种下了一颗神奇的种子,但是没想到第一个收获的却是OpenAI。在伊利亚的带领下,OpenAI在2018年发布了基于Transformer的拥有1.17亿个参数的语言模型GPT-1。GPT-1采用了单向的自注意力机制,即模型只能看到前面的词,而后面的词在训练和生成中是被掩盖起来的。后来证明,用这种方式训练的模型生成的语言更加连贯和自然。
谷歌团队自然不能让OpenAI抢走自家的胜利果实(见图1-4),GPT-1发布仅仅4个月后,他们就发布了基于Transformer架构的BERT模型,其参数增加到了3.4亿个,数倍于GPT-1。BERT模型打破了多项自然语言处理的最好成绩,在能力表现上力压GPT-1一头。
2019年,OpenAI再接再厉,发布了GPT-2,参数达到了15亿个。但GPT-2不仅仅在模型规模上更大,它着重想改进的是模型的泛用性。无论是GPT-1还是BERT,在进行自然语言处理的不同下游任务时都需要单独的数据集来监督学习以进行微调,而GPT-2有了可以处理多种不同任务却不用对模型进行微调的能力。
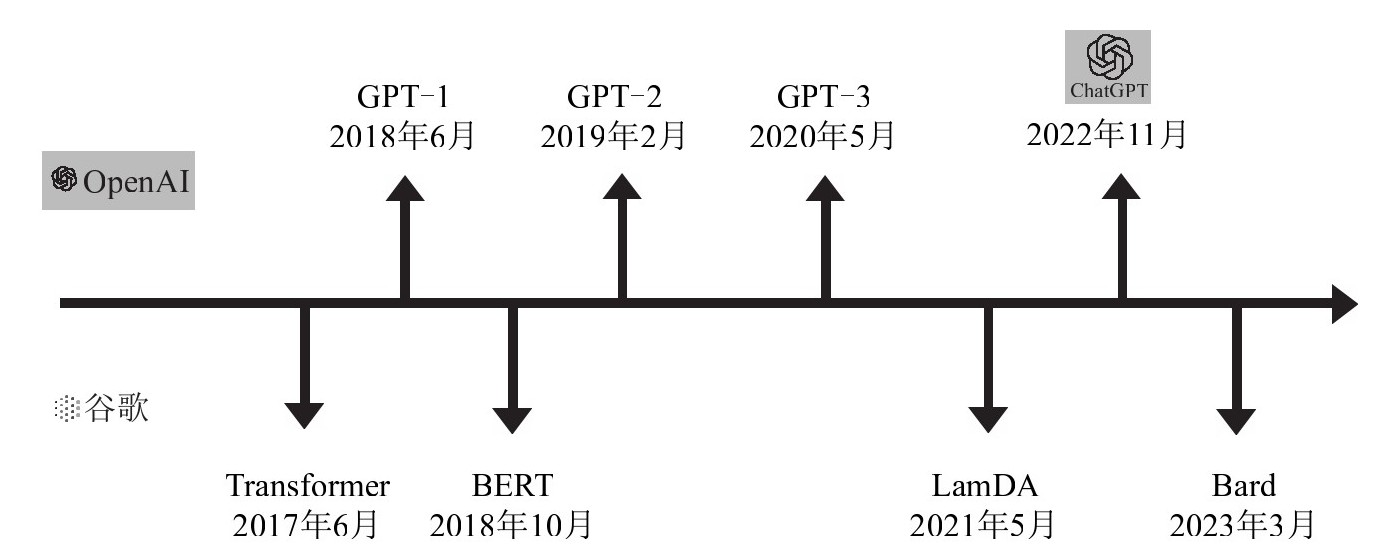
图1-4 OpenAI与谷歌的大模型算法大战
可以看到,从GPT-1到BERT,再到GPT-2,随着参数的增多和模型的变大,模型的能力的确在不断地提升,此外,模型的泛用性也在逐渐增加,需要监督学习的比例在不断下降。但问题是,GPT-2的参数比BERT多了数倍,其表现却只是略胜一筹,并没有出现相应比例的能力提升。这时摆在研究人员面前的问题是:模型的规模是否越大越好?模型规模带来的能力提升是否也有一定的增长极限?
这时资本再次展现了其力量。面对谷歌的紧追不舍,OpenAI必须设计出更大参数量的模型,而这需要的算力和人员成本都要大量的资金作为支撑。而此时,因为理念不同,OpenAI刚刚和马斯克分道扬镳,马斯克直接停止了对公司的资助。眼看大模型正要取得突破性进展,OpenAI却面临“弹尽粮绝”的风险。
在这关键时刻,在创投界驰骋多年的萨姆·奥尔特曼展示出其卓越的商业才华,他首先为身为非营利组织的OpenAI设计了一个限制性的营利机构,并由此吸引到了几位重要的商业投资人。其中最重要的一位就是微软的CEO纳德拉。此前,纳德拉在云计算领域带领微软打了一个漂亮的翻身仗,但在市场份额上始终被老对手亚马逊压制。在方兴未艾的人工智能领域,微软则一直没有形成自己的阵地,位于第二梯队。对于志在进行技术转型的纳德拉来说,OpenAI是一个充满吸引力的标的。而后来的事实也证明,纳德拉是一位对技术潮流走向预判极为精准的决策者。
2019年7月,微软宣布注资10亿美元,成为OpenAI旗下营利机构的有限合作伙伴。正是这笔注资,让公司有了充足的弹药,OpenAI决定“搞个大的”。
2020年5月,GPT-3问世,其参数量达到了惊人的1750亿,也就是说模型规模暴增了100多倍,其预训练用的自然语言资料达到了45T,几乎囊括了整个互联网的知识,并且由几千个英伟达V100显卡形成的云计算矩阵提供算力。GPT-3向世人证明了,在大模型、大算力、大数据的支持下,大力真的可以出奇迹。GPT-3不但在理解语言和生成更连贯的文本方面具有更强大的能力,而且拥有了零样本学习能力,即在未经过特定任务训练的情况下执行多种不同类型的自然语言应用任务。
GPT-3的横空出世震动了整个AI研究领域,这当然也包括中国,多家企业和研究机构开始行动。一直关注自然语言处理的达摩院在2021年发布了全球最大规模的中文文本预训练语言模型PLUG,参数达到了270亿个。此外,达摩院还在同年6月发布了M6多模态模型,参数量达到了万亿级。除了规模巨大,M6模型还有两项与众不同的创新。第一,M6将能耗降低超八成,效率提升近11倍。第二,凭借阿里巴巴丰富的商业场景,M6是国内首个实现商业化落地的多模态大模型,例如作为AI助理设计师上岗阿里巴巴新制造平台犀牛智造。
2019年智谱AI成立之初,张鹏和团队的研究方向之一是以知识图谱为基础的AMiner科技情报平台。简单解释,这个平台可以基于对科研人员、科技文献、学术活动三大类数据的分析挖掘提供科研信息服务,其中一个就是分析技术的成熟度曲线,帮助研究者判断技术研究的走向,从而制定研究投入的决策。比如从图1-5对大模型技术成熟度的预测,可以看到目前我们正处于大语言模型的示范期。
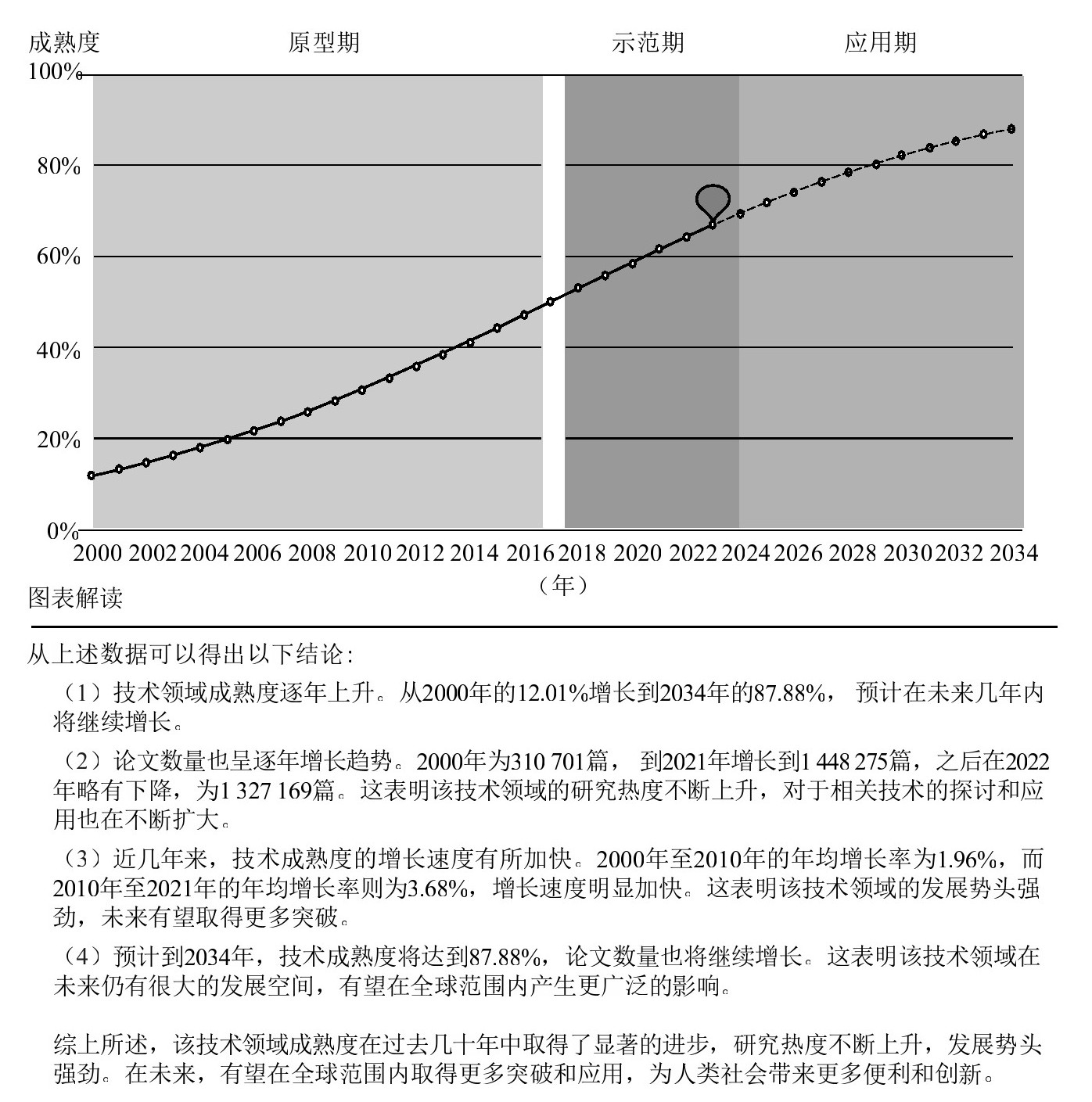
图1-5 在大模型的帮助下,AMiner不仅能判断大模型技术的成熟度曲线,还能对曲线的预测进行解读
近水楼台先得月,长期关注技术发展趋势的智谱AI团队很早就看到了大语言模型的潜力,此后他们也决定转型,全力投入这个领域。公司于2020年底开始研发GLM预训练架构,并训练了百亿参数模型GLM-10B,2021年利用MoE(混合专家)架构成功训练出万亿参数稀疏模型,于2022年合作研发了双语千亿参数超大规模预训练模型GLM-130B。2024年1月,智谱AI推出新一代基座大模型GLM-4,整体性能相比上一代大幅提升,逼近GPT-4。这些先发优势让智谱AI成为中国最受瞩目的大模型创业公司之一。
视线回到美国硅谷,2021—2022年,人工智能领域一个备受关注的话题是,那个一鸣惊人的OpenAI怎么沉寂了一年多?他们会准备怎样的反击?
答案是2022年底ChatGPT的发布。如果说GPT-3震动了人工智能研究领域,那么ChatGPT的出现真正震撼了整个世界。抛开所有标准、竞赛和跑分不谈,即便是普通人也能感受到ChatGPT生成内容的自然顺畅,几乎与人类无异。ChatGPT的惊艳表现迅速提高了社会大众对人工智能商业前景的预期。其推出仅5天,注册用户数就超过了100万,两个月后月活用户数突破1亿,成为有史以来用户增长最快的商业应用。微软的联合创始人比尔·盖茨在自己的博客中写道:“我一生见证过两次最伟大的技术演示。一次是在1980年我看到了图形交互界面,它后来塑造了微软和PC(个人计算机)时代;另一次就是在去年(2022年),ChatGPT的出现宣告了人工智能的时代已经到来。”
GPT-3为何会实现如此大的能力飞跃?我们特别邀请浙江大学人工智能研究所所长吴飞教授为我们梳理了人工智能发展的脉络和核心技术方法,关于这个问题,他认为,大语言模型之所以拥有强大的能力,是因为它展现出一种智能涌现的能力,即GPT-3所呈现的能力不存在于小模型中。在模型参数较小的情况下,模型基本不具备处理任务的能力,其性能与随机选择的效果一样,但当参数规模超过百亿时,模型所表现的能力突然提升。这种现象是机器学习,乃至人工智能领域前所未见的现象。这种涌现能力具有重要的科学意义,它意味着我们有可能掌握了迈向通用人工智能的秘诀。
我们事后回顾谷歌与OpenAI的算法大战,发现了另一个有趣的问题:为何谷歌发明了Transformer这一具有跨时代意义的基础架构,却没能成为大语言模型的开创者?我们认为这还是与企业的愿景,或者说他们想解决的问题相关。谷歌的BERT和Transformer的设计初衷只是想解决自然语言处理的各种子任务问题,比如机器翻译。而OpenAI的几位创始人在成立公司时就是想开发出让所有人类受益的通用人工智能工具。OpenAI的首席科学家伊利亚回忆道:“人工智能研究人员大多出自学术界,他们倾向于从小处思考。由于他们工作的性质,这种小范围思考容易获得认可和奖励(发文章)。但是这种方式让你很难看到人工智能大的发展方向,这也是我离开谷歌加入OpenAI的原因。”
自达特茅斯会议至今,通用人工智能60多年来基本上没有任何实质性的进展,甚至连稍微严肃一点的学术活动都没有。这不仅仅是困难太多的原因,同时还因为人类并没有什么通用人工智能方面的需求。科学界主流的观点也认为基于人类自身安全考虑,不应该往这方面做过多深入探索。因此,谷歌相对更务实的目标在当时也是合理的。
愿景决定高度,OpenAI的创始人团队的确看到了普通人没有看到的未来,也许这就是创业者与科学家的区别。OpenAI的成功再次证明了,只有在伟大的工程师手中,科学技术才能真正改变世界,瓦特如此,乔布斯如此,奥尔特曼和伊利亚亦如此。正如乔布斯曾经说过:只有疯狂到认为可以改变世界的人,才能真正改变世界。
当然,谷歌作为这场大模型竞赛的失意者,其对人工智能发展的贡献也不可磨灭,几十年如一日的大量投入,造就了Transformer这一跨时代的架构,其对GPT的苦苦追赶犹如20世纪60年代美苏之间的登月竞赛,最终逼出了世界上首个千亿参数大语言模型。
那么,大语言模型是我们通往通用人工智能的正确道路吗?至少目前专家们对此还没有达成共识。尽管大模型展现了惊人的能力,但它也有一些明显的限制。首先是不可解释性,大模型生成内容是依靠对上千亿个神经元连接参数的计算,因此难以解释其决策过程和生成结果的具体原因。这种不可解释性导致的黑盒决策模式会造成很多应用上的问题,比如在一些敏感领域,模型的不可解释性可能与监管要求相冲突。人工智能和大数据专家窦德景博士认为,与传统的深度学习模型相比,其实大语言模型的可解释性已经有所提升了。原因是我们可以用提示工程对其进行模型事后解释,从而探索大模型行为的边界。这样可以从完全不可见的黑盒模式,向介于白盒和黑盒之间的状态转变,这种模式又被称为“玻璃盒子”。
其次,人工智能的伦理和安全也是一个必须得到重视的问题,由于我们无法探知其决策的原理,也不可能完全排除其产生安全风险的可能性。很多专家已经建议各国政府行动起来,建立类似于国际原子能机构的跨国组织,用来监管人工智能这一潜在能量巨大的新兴技术。而OpenAI的首席科学家伊利亚则建立了一支超级对齐团队,确保人工智能的行为能对齐人类的价值观,从算法层面保护人类的根本利益。阿里巴巴则尝试从训练数据的角度出发解决问题。天猫精灵和通义大模型团队联合提出了100PoisonMpts(又称“给AI的100瓶毒药”)项目,该项目提供了业内首个大语言模型治理开源中文数据集,由十多位知名专家学者成为首批“给AI的100瓶毒药”的标注工程师。标注人各提出100个诱导偏见、歧视回答的刁钻问题,并对大模型的回答进行标注,完成与AI从“投毒”到“解毒”的攻防。首批领域数据围绕AI反歧视、同理心、商榷式表达等目标,已覆盖法理学、心理学、儿童教育、无障碍、冷知识、亲密关系、环境公平等维度。第一批发起专家包括环境社会学专家范叶超、著名社会学家李银河、心理学家李松蔚、人权法专家刘小楠等。目前,首批数据集已经全部在阿里云魔搭(ModelScope)社区上开源供社会使用。
最后是计算效率问题,训练大模型需要的计算量极大,能耗也惊人。例如,训练GPT-3耗用了1.287吉瓦时电量,大约相当于120个美国家庭一年的用电量。而AI应用所需要的算力可能更大,阿里云计算平台事业部负责人汪军华表示:“好的模型和应用出来后,上亿的用户每天都去用,应用和推理的成本会比训练高一到两个数量级,这对云计算平台提出了更高的要求。”在全球面临气候变化的影响越来越大的今天,如何提升大模型的训练效率以及云计算的效率是各大AI企业和云计算设施提供企业必须面对的问题。
长期关注科技趋势发展的智谱AI的CEO张鹏认为:“回看科技史,技术发展的不同流派都是相互交替和借鉴的。大模型帮助我们向通用人工智能迈了一个重要的台阶,虽然我们还没有看到预训练大模型的增长极限,但也许当它发展到一定极限,我们又需要回过头来借助符号主义的新发展解决大模型的缺陷,比如可解释性和鲁棒性
 的问题。”也许“古老”的符号主义如同神经网络一样,将在未来时机成熟的时刻归来,带领我们进入通用人工智能的新时代。
的问题。”也许“古老”的符号主义如同神经网络一样,将在未来时机成熟的时刻归来,带领我们进入通用人工智能的新时代。
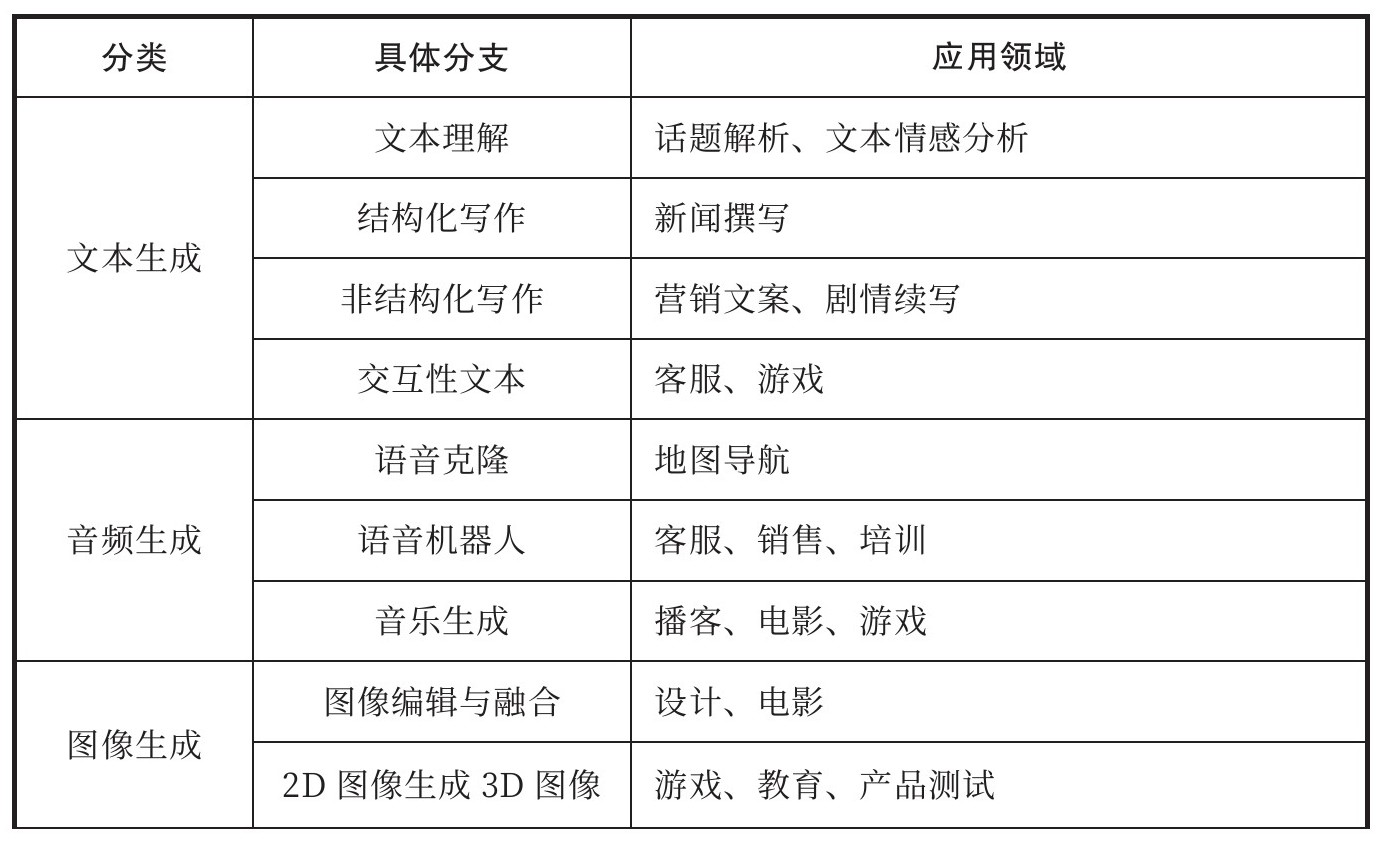
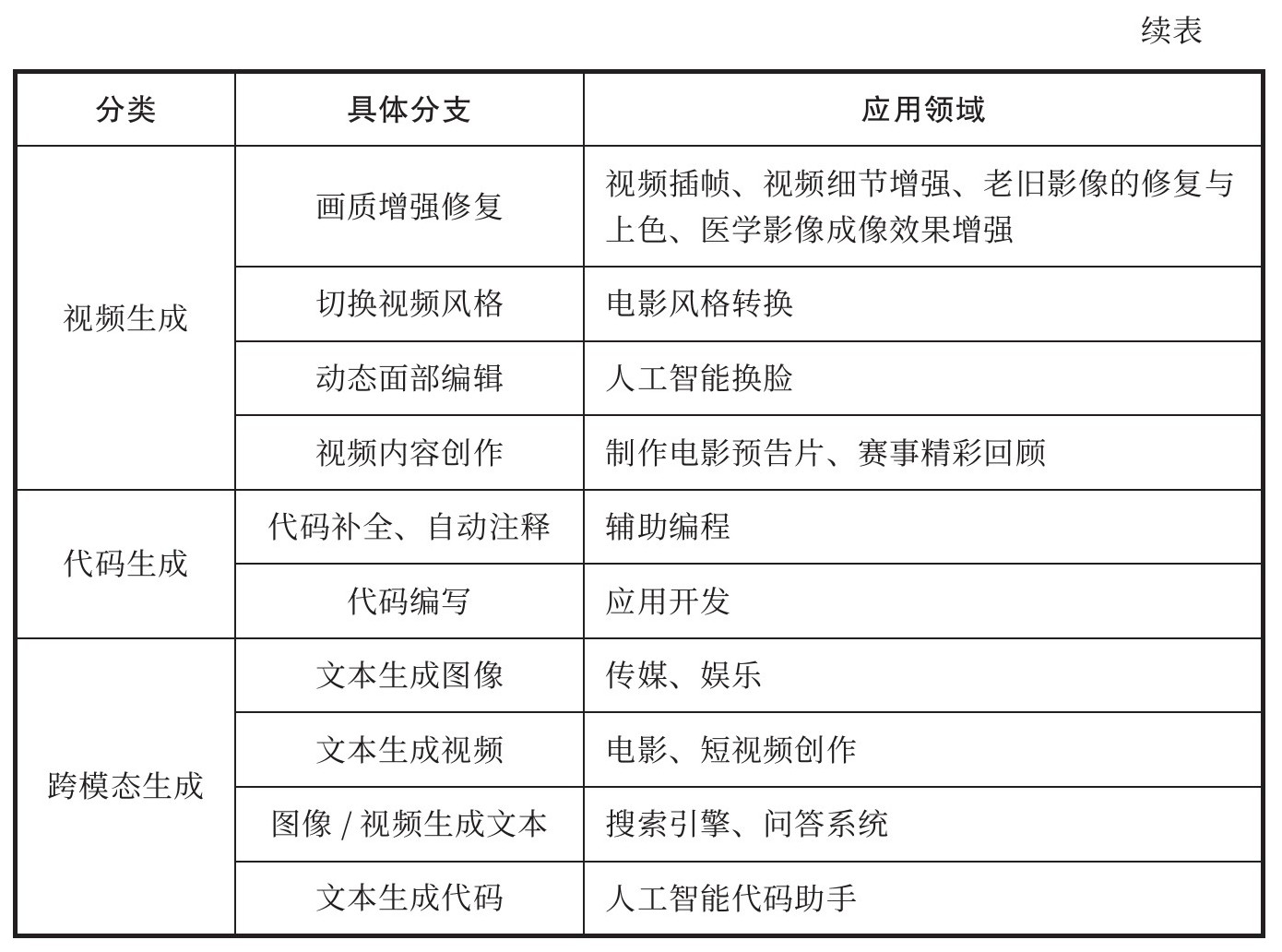
有一点可以肯定,人工智能的大模型新章节才刚刚开始,还远未达到高潮。在ChatGPT席卷世界之后,大模型终于让人工智能回到了世界中心,下一步将凭借强大的智能涌现能力改造商业世界的方方面面。阿里云首席技术官周靖人认为:“大模型的‘大规模’和‘预训练’属性决定了它易于泛化的能力,将作为上层应用技术基础有效支撑众多AI应用落地,解决传统AI应用中壁垒多、部署难的问题,从而有效降低AI技术应用到千行百业的门槛。”在资本的支持下,国内外的创业企业和平台公司正在不断开拓大模型的应用边界,利用现有的文本、音频、图像等数据,通过各种机器学习算法学习其中的要素,从而创造出全新的数字视频、图像、文本、音频、代码等内容。利用人工智能自动生成内容的生产方式被称为AIGC,大模型正在带领我们进入一个全新的生成式AI时代,一个全新的生成式AI竞争格局和商业生态也正在逐步浮现(见表1-2)。
表1-2 AIGC应用全景
在基础大模型领域,OpenAI并非高枕无忧,谷歌在其后推出了自己的大模型对话应用Bard, Meta则选择了一条截然不同的开源之路,Llama 2俨然正在成为开源大模型的领军者。在大洋彼岸的中国市场,“百模大战”正在轰轰烈烈地上演,大模型的竞争格局未来是百花齐放还是强者愈强,现在还未可知。与Meta和OpenAI分别走开源和商业闭源的单一路径不同,阿里云选择了开闭源双路线并进。2023年12月,于国人而言是个激动人心的时刻,通义千问开源720亿参数通用模型Qwen-72B登上全球最大开源大模型社区Hugging Face榜首,这是国产开源大模型首次赶超Llama 2。Llama 2开源可商用5个月后,国产开源大模型终于有一个追上了它,大模型开源领域不再是Llama 2独领风骚,国产大模型也由此进入新时代。同时,在Github、Hugging Face、魔搭等开源社区上,最热门的话题已经从iOS、安卓变为大模型搭建各种应用。独立开发者总是领先大众一步,他们已经进入AI时代;众多创业者终于迎来了一片全新的蓝海,他们的目标是抢占大模型服务的周边服务市场,向量数据库、提示工程、企业大模型落地成为最热门的领域。而作为大模型的基础设施,算力硬件和云计算厂商正在为争霸即将到来的智算时代厉兵秣马。一幅生机勃勃的AI生态画卷正在展开。