
下载掌阅APP,畅读海量书库
立即打开



回顾人工智能的发展历史,有三个主要的人工智能学派,分别是机器模拟人类心智(mind)的符号主义、机器模拟人类大脑(brain)的联结主义以及机器模拟人类行动(action)的行为主义(见表1-1)。由于行为主义的研究主要和机器人学高度相关,往往被视为相对独立的分支,且其主要观点已经融入联结主义的方法论,因此本书主要介绍符号主义与联结主义这两个观点相对的人工智能学派。
表1-1 人工智能学派主要思想和典型应用
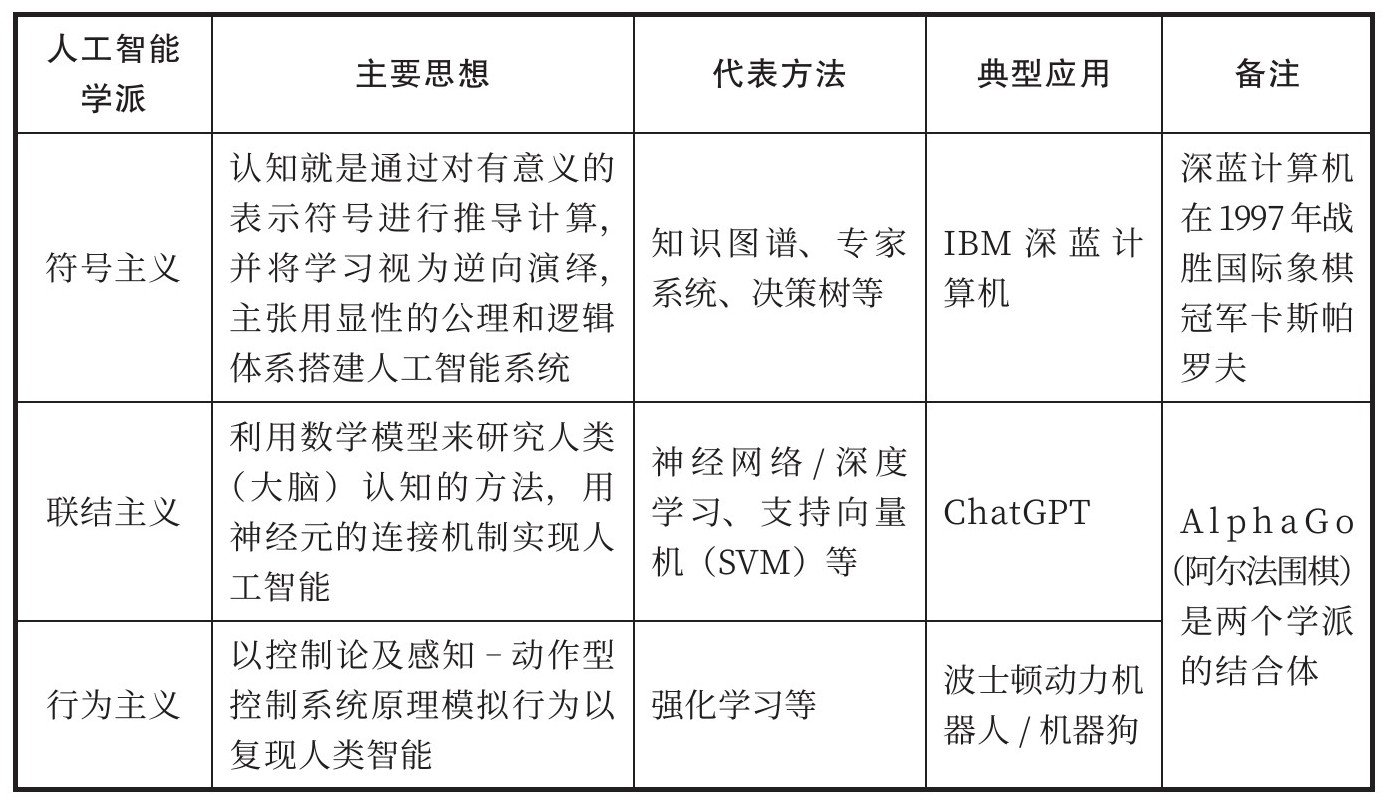
从1956年达特茅斯会议第一次提出“人工智能”一词到20世纪90年代末,符号主义统治了早期的人工智能。如果用一句话来描述符号主义的思想,那就是将现实世界抽象为可被机器识别和计算的符号,利用运算模仿人脑思考,通过逻辑推理来认知世界。简言之,符号主义认为智能就是计算。由于逻辑和计算是人类典型的心智活动,因此符号主义也常常被称为心智派。
追根溯源,符号主义直接脱胎于艾伦·麦席森·图灵的思想。图灵定义了什么是人工智能,以及人工智能应该具备什么样的能力。20世纪40年代,二战带来的计算科学和半导体技术的大爆发,让人们越来越多地在现实层面讨论机器智能的可能。但在那个约翰·冯·诺依曼还没提出计算机架构的年代,学术界根本无法对人工智能的定义达成一致,更不用说形成一门严谨的学科了。
此时图灵的天才尽显无遗,他另辟蹊径,先假定机器可以具有类似人类的智能,然后给出一个判断方法:人与一台机器和另一人进行对话,通过提问与回答,分辨与之对话的是机器还是人类。如果人无法区分机器和人类,则代表机器通过了测试,是具备智能的。
这就是大名鼎鼎的“图灵测试”,起初它只是在论文中的一个思维实验。图灵没有想到的是,图灵测试会成为判断人工智能水平的重要标准。到2024年的今天,每隔几年就会有研究团队带着自己的人工智能向图灵测试发起挑战,但还没有一个可以成功,即便是今天最强大的生成式AI模型也没有完成图灵的愿景。
1950年,图灵发表了题为《计算机器与智能》的重要论文,探讨“机器能否思考”这一问题。图灵的明智之处,是他没有纠结于机器如何思考的问题,而是开创性地提出用计算和推理达到智能的效果,并提出了用图灵机的计算架构去实现这种智能,以及用图灵测试来验证智能效果。可以说他一个人定义了什么是人工智能(计算)、如何实现智能(图灵机)以及人工智能的标准(图灵测试),因此被公认为“人工智能之父”。
回看历史,如果我们承认图灵是人工智能的奠基人,那我们可以说早期的人工智能就是符号主义的。顾名思义,符号主义得名于符号,其思想主要继承于图灵,认为智能等同于计算。为了实现智能,就要用各种方法将现实世界的各种物体抽象成符号,然后利用逻辑和计算替代人类大脑的思考。
在图灵、马文·明斯基和赫伯特·西蒙等代表人物的引领下,符号主义学说在人工智能领域的统治地位维持了半个多世纪,直到杰弗里·辛顿等学者引领的机器学习潮流出现。然而由于时代和相关技术的局限性,符号主义AI取得的两大主要成就是符号表达和专家系统。
将知识符号化的过程又被称为符号表达,也是实现符号主义AI的基础步骤,其中应用最广的一个系统就是语义网络。语义网络可以直观地呈现信息,并且能进行复杂的语义推理。进入互联网时代,谷歌在2012年提出了知识图谱的概念,语义网络的相关研究和应用又迎来了一个小高潮。在知识图谱的帮助下,搜索引擎能够确定Apple(品牌)和apple(水果)之间的区别。语义网络在自然语言处理(NLP)和知识图谱等领域至今仍广泛应用,是符号主义在今天仍然在发挥作用的为数不多的重要遗产。
符号主义的另一个主要成就是专家系统。顾名思义,专家系统是一套回答人们特定问题的计算机系统。20世纪70年代,计算机的硬件发展让大规模的知识存储成为可能,专家系统应运而生,这些系统基于特定行业的知识收集存储,并利用编程规则解决特定的专业问题,如医疗诊断、金融分析等。专家系统的概念,第一次让社会看到了人工智能在商业应用中的前景。
人们对人工智能首次在商业世界中的大规模应用充满期待。然而后来的历史证明,符号主义正在走入一条没有出路的死胡同。符号主义相信,逻辑是认知世界的唯一途径,因为这是人类认知世界的方式,因此他们不辞辛劳地为计算机所做的每一个决定进行编程。然而问题是,现实世界往往充满了定义不清和难以描述规则的事件,一个由工程师精心打造、像钟表一样精密的专家系统根本无法应对这样的情况。
专家系统未能达到预期,让人们对人工智能产业再次失望,直接引发了人工智能第二个冬天的到来(见图1-1)。尽管深蓝计算机应用最新的统计学方法战胜了人类,但这种胜利也展现了符号主义的局限性——IBM花费了多年时间和数百万美元开发一台能下国际象棋的计算机,但仅此而已,深蓝在其他领域毫无建树。
到此为止,符号主义AI看似已经进入瓶颈,无法解决通用性和随机性问题的弊端让AI难以实现可观的商业价值。由于发展没有达到外界预期,符号主义AI两次陷入低谷,外部投资、政府支持和相关学术研究大量减少,史称AI寒冬。浙江大学人工智能研究所所长吴飞认为:“将人类所有知识收集起来且形式化的任务根本无法完成。人工智能需要模拟大脑而非追求严密的推导功能,即对推理的严格约束进行松绑。”看来人工智能要实现破局,需要我们拥有一种完全不同的思维方式。
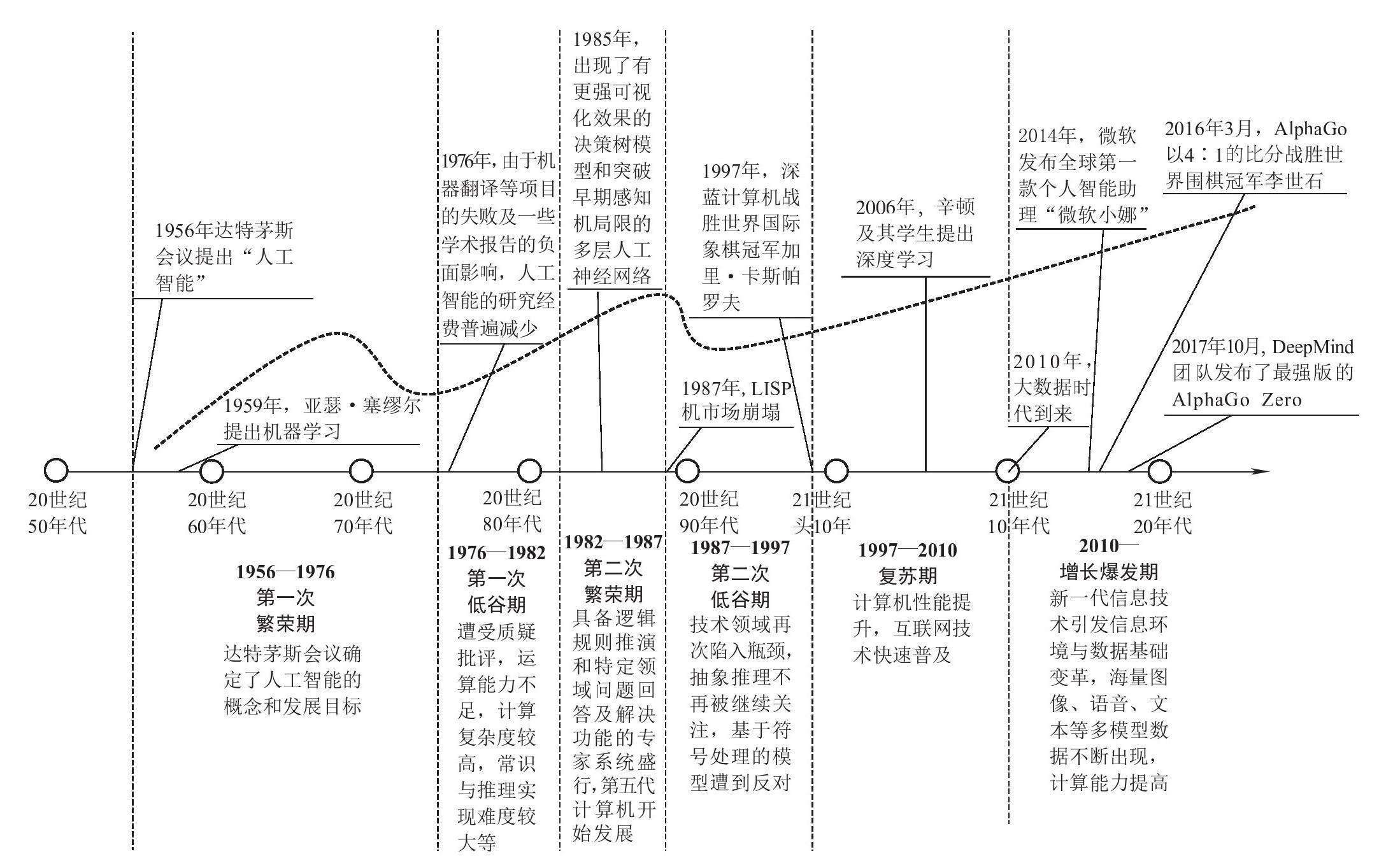
图1-1 生成式A I爆发之前,人工智能的发展时间轴
如果说符号主义试图模拟人类的心智,那么联结主义则试图模拟人类的大脑。与称霸主流的符号主义相比,联结主义的发展更加一波三折,甚至有点像武侠小说的情节——主人公遭遇重大打击却矢志不渝,后来的一番奇遇让他修得神功,最终一统江湖。联结主义的主要思想——模拟人脑的神经网络理论,在人工智能发展早期就已经出现,和符号主义分庭抗礼,但却因为种种限制长期被压制,并没有得到长足发展。神经网络的创始人沃尔特·皮茨(Walter Pitts)英年早逝,第一个将神经网络投入应用的学者弗兰克·罗森布拉特(Frank Rosenblatt)甚至被很多人认为是间接死于学派理论之争,直到辛顿携深度学习出世,神经网络才成为人工智能研究的主流。
符号主义称霸了早期人工智能领域,以神经网络为基础的联结主义则统治了今天的人工智能领域。1943年,神经学家沃伦·麦卡洛克(Warren McCulloch)和数学家皮茨提出了首个人工神经网络模型,从而开创了人工神经网络模拟人类大脑研究的时代,这就是联结主义的起源。后来人们根据麦卡洛克和皮茨的名字将神经元模型命名为“M-P神经元模型”。神经元模型的发布并没有造成太大的影响力,因为它实在太简单,人们不知道它能做什么。直到1957年,罗森布拉特在一台IBM 704计算机上模拟实现了一个叫作“感知机”(perceptron)的神经网络模型“Mark Ⅰ”(见图1-2),号称可以对手写数字进行视觉识别和分类。
简单来说,最初的神经网络就像一个超级大的参数方程,每个参数对应手写数字的一个像素。通过研究大量的手写体数字,研究人员就可以设定每个参数的赋值——在今天的大语言模型中称之为权重,神经网络就可以分辨数字了。

图1-2 罗森布拉特和他的感知机“MarkⅠ”
图片来源:https://transbordeur.ch/en/2019/conversations/
尽管感知机的功能简单,却有着重大意义。这是人类第一次只需要通过预先的参数调整,不依靠编程,仅靠机器学习以完成某项智能任务,这就展现了一条独立于图灵机和符号主义的实现人工智能的全新道路。至今所有以神经网络为基础的人工智能模型在最基本的工作原理上都与感知机并无二致。
更重要的是,它和主流的符号主义思想完全背道而驰,形成了一种学术路线之争,自然会引发学术同行的质疑和论战。联结主义的代表马文·明斯基和西摩尔·派普特(Seymour Papert)在1969年出版的《感知机》这本书中指出了感知机神经网络的一个致命问题:神经网络可以很好地完成“与”“或”“非”的逻辑运算,却无法完成异或(exclusive-OR,缩写成XOR)这一人类可以简单处理的逻辑运算,这是由于像感知机这样单层的神经网络(只有一层输入层和一层输出层)无法解决非线性分割问题。
要解决这一问题,只能通过多层神经网络,也就是深度学习的方法,但由于当时计算能力有限,根本无法解决多层神经网络造成计算量激增的问题。
作为人工智能的先驱,明斯基的著作在该领域有巨大的影响力,且他对单层神经网络缺点的论证几乎无懈可击,这在当时人们的头脑中烙下思想钢印:“神经网络连最基本的逻辑运算都无法完成,更不可能具有智能。”
从此之后,研究者对神经网络研究的热情大减,甚至视之为人工智能研究的“异端”。由于在学术论战中落败,罗森布拉特从此一蹶不振,并在《感知机》出版不久后的1971年,不幸在自己43岁生日当天溺水身亡。而在该书出版的同一年,年仅46岁的皮茨在收容所孤独死去。4个月之后,麦卡洛克也在医院过世。
短短两年间,几位领军人物相继离世,这对整个联结主义学派乃至人工智能领域来说都是沉重的打击,有关神经网络的研究进入了一个长达几十年的低潮期,直到辛顿引领的深度学习潮流出现,才上演了王者归来的大戏。
可以看到,符号主义和联结主义思潮在20世纪60年代相继出现,但各自都遭遇了挑战和挫折。尽管符号主义是当时的“显学”,但也遇到了研究的瓶颈,无法满足人们对人工智能不切实际的预期。而联结主义则在路线斗争中落于下风,被讥讽为“炼金术”,难以获得资金和人才的支持。当然,受限于时代,计算技术、数据存储技术的发展都刚刚萌芽,人工智能的研究者们很难将他们的设想化为现实,这也是人工智能屡屡遭遇寒冬的客观原因。
进入21世纪,相关科学技术飞速发展,特别是芯片技术的迭代为越来越强大和便宜的算力提供了技术基础。另外,人类社会正式进入数字化时代,大量知识的线上化和数据化给世人提供了前所未见的数据量。如果我们将任何人工智能的应用都看作由算法、算力和数据三个引擎所驱动的话,那么此时人工智能的研究者终于获得了足够强大的工具。人工智能经历的漫长寒冬终将结束,春天即将到来,而首先解冻的是尘封已久的神经网络。
再次带领神经网络崛起的人就是辛顿,他如今被大多数人尊称为“深度学习之父”。也许是受到作为生物学家的父亲影响,辛顿从年轻时起就对人脑的结构和工作原理着迷,他坚信模拟人脑的构造是通向人工智能的正确道路。但是如上文所述,在20世纪七八十年代,对神经网络的研究几乎进入冻结状态,大部分人认为模拟人脑是天方夜谭,根本不可能实现。辛顿的研究方向四处碰壁,斯坦福大学和卡内基-梅隆大学等人工智能研究重镇都对他的研究不感兴趣,辛顿最终落脚加拿大,因为当时只有多伦多大学愿意资助他的人工智能研究。
真理也许真是常常掌握在少数人手中,辛顿对神经网络的研究多年来不断遭受同行的质疑和嘲讽,连多伦多大学本校的教授都认为神经网络是“科研炼金术”,让学生离这个课题远点。辛顿却不为所动,一直坚持不懈地发表了大量研究成果,直到在2006年发表论文,提出了深度学习的概念。这里的深度学习实际上就是多层神经网络的机器学习法。深度学习属于机器学习的范畴,也是机器学习最为重要的一个分支。之前我们提到,神经网络之所以长期没有得到发展,其中一个重要的原因是人们没有找到训练多层神经网络的方法,而辛顿的主要贡献就是破解了这个难题,提出了反向传播算法。
假设一个深度神经网络要解决的问题是识别图片里的猫,一开始神经网络没有经过训练,给出了一个非常离谱的答案“大象”。大象和猫肯定天差地别,这个巨大的差别就是成本函数。反向传播就是通过喂给网络无数张猫的图片,不断调整网络中无数个参数的权重,直到网络能够每次都正确识别出猫。“从大象到猫”的过程,就是深度学习网络训练的过程,在机器学习里,又被称为梯度下降。
由于神经网络生成的结果是由百亿甚至千亿个参数之间相互作用产生的,人类根本无法预测和掌握这个过程的因果关系,这也是大模型不可解释性的根本来源。这与人脑工作原理的不可解释性在本质上是一致的。
深度学习最厉害的地方,是它理论上能解决任何可以用函数表示的问题。只要有正确的输出数据,那么神经网络就可以通过无数次的训练,来调整其神经元权重,获得正确的答案,这就是深度学习的过程。
有了反向传播算法,理论上机器可以自主学习任何需要人类智能的任务,因为在计算机的语言里,所有数据都是由0和1组成的,包括图片、文字、音频和视频。举例来说,神经网络可以识别图片,那它就可以识别音频和文字。可以说这完全打开了一个新世界的大门,让人们看到了无限的可能性,机器不再依赖一条条编程,而可以通过训练来学习任何知识。
此前神经网络的研究之所以会长期停滞,是因为深度神经网络这个算法在20世纪五六十年代的发现实在是远远超前于时代,当时既没有足够快速的CPU(中央处理器)/GPU来计算海量神经元的参数,也没有足够多的、高质量的标注数据来训练模型。计算机硬件在摩尔定律下快速发展,加上全球互联网化带来了数据大爆炸,再加上辛顿这样执着的天才提出深度学习的概念,人类才能走出迈向通用人工智能的第一步。
当然,深度神经网络第一个让世界震惊的应用还是在图像识别领域。有了深度神经网络这个先进的算法,那么数据和算力的问题如何解决呢?这时我们就要请出讲人工智能发展史不得不提到的人物,被称为“AI教母”的李飞飞教授。
李飞飞一直深耕于计算机视觉的研究,她从儿童识别图像的过程获得了灵感。人类的眼球平均每200毫秒就移动一次,如果将眼睛视为一个照相机,那么一个三岁的儿童就已经看过上亿张图片了。李飞飞认为,正是因为通过如此大量的学习,人脑才具备视觉识别的能力,要让计算机具备视觉识别能力,就需要大量的训练材料。
受此启发,她和普林斯顿大学的李凯教授在2007年建立了图片数据库ImageNet,用来促进计算机图形识别技术的训练。这一决定也遭遇了极大的阻力,很多人都劝告她,要想拿到终身教职就赶快放弃,但李飞飞却不为所动,一直坚持数据库的建设。由于图片标注需要大量人工劳动,李飞飞想到了通过云计算技术进行众包,请全球160多个国家近5万名网民对互联网上的图片进行标注。到2009年,ImageNet上已经包含了2200个类别的150亿张经过清洗、分类和标注的图片。并且这个数据库完全开源,免费提供给全球所有研究者。可以说李飞飞创建的ImageNet大大加速了人工智能图像识别技术的发展,也让全世界看到了深度学习的无限潜力。
从2010年起,每年都会举办“ImageNet大规模视觉识别挑战赛”(ImageNet Large Scale Visual Recognition Challenge,简称ILSVRC),看哪一款参赛程序能以最高的正确率对物体和场景进行分类和检测。这种能够量化且带有对抗性质的活动,十分容易牵动公众的目光。当时没有人预料到,辛顿的深度神经网络在赛上的首秀将震惊世界。
今天回看,历史中充满的无数巧合推动人工智能技术走向发展和成熟。在辛顿发表深度学习论文的同一年——2006年,另一位在计算科学领域举足轻重的美国华裔,英伟达的创始人和CEO黄仁勋宣布,公司将推出统一计算设备架构(Compute Unified Device Architecture,简称CUDA)平台。CUDA是一种并行计算平台和编程模型,允许开发人员利用GPU的并行性进行通用计算。这种能力使科学家、工程师和研究人员能够利用GPU处理大规模的计算问题。CUDA平台的推出,给了普通科研人员强大且低成本的算力资源。英伟达也因此垄断了后来的科学计算及人工智能算力市场,其后续推出的专门针对人工智能计算的V100和A100显卡,也成了大模型所需巨大算力的源泉。
此时的辛顿正在和他的两名学生伊利亚·苏茨克沃(Ilya Sutskever)和亚历克斯·克里切夫斯基(Alex Krizhevsky)一起,研究深度神经网络在计算机识别方面的应用,在李飞飞的ImageNet和黄仁勋的CUDA平台的帮助下,算力和数据的问题都迎刃而解。最终他们成功设计出一个具有8个中间层,包含400多万个参数的深度神经网络,并在2张GTX580显卡上训练了大约1周的时间。与今天动辄上千亿参数的大模型相比,400万个参数的模型显得微不足道,但这却是当时最先进的图像识别神经网络。
2012年,辛顿的团队带着他们最新的研究成果参加了ImageNet大规模视觉识别挑战赛,并一举夺得了当年的桂冠。由于他们参赛时还没有给程序起名字,后来人们就用论文第一作者的名字将其命名为AlexNet。AlexNet的表现异常出色,其比赛得分远远领先于其他没有采用深度学习的算法。它的成功也让人工智能领域的学者们意识到了深度神经网络的巨大潜力。此后,其他研究团队纷纷效仿,设计了层数和参数更多的神经网络。
2015年是另一个人工智能领域的里程碑之年。
首先,来自微软研究院的152层的残差网络(ResNet)以仅3.57%的错误率赢得了ILSVRC比赛的冠军。而人类志愿者在这个竞赛里,通过肉眼辨识图像的平均错误率是5.1%。从2015年起,机器在对图像进行识别和分类这项技能上的成绩事实上已经超越了人类。这是人工智能在认知领域方面超越人类的一个案例,更是深度神经网络的一个巨大成功,而且它似乎还可以作为令人难以抗拒的“神经网络规模越大,能力越强”的一个有力论据,为后来大模型的诞生埋下伏笔。
同样在2015年,在距离多伦多4000多公里的硅谷,萨姆·奥尔特曼、埃隆·马斯克和彼得·蒂尔等一群志同道合的创业者意识到了人工智能,特别是深度学习的潜力,于是联手建立了一家人工智能创业公司,名字叫OpenAI。而他们招揽的第一个人工智能技术专家,就是AlexNet的三位作者之一,辛顿的得意弟子伊利亚。他从待遇优厚的谷歌研究团队辞职,加入OpenAI,担任首席科学家。
与硅谷跨洋对望的中国,一群学者、创业者、从业者和企业家,也在孜孜不倦地探索人工智能的边界。
早在2014年,阿里云的人工智能平台PAI就已诞生,这个平台的全称是Platform for AI,当时阿里巴巴就在思考如何用人工智能来处理大数据。直到2017年,PAI开始对外提供服务,并在新一轮生成式AI浪潮中,为大模型的全生命周期提供人工智能工程化服务。2018年之后,阿里云开始自研深度语言模型、自然语言预处理模型,逐一实现在人工智能技术上的单项能力突破,而这些循序渐进的尝试,都为阿里云2023年迎来生成式AI打下了坚实基础。
2014年,阿里巴巴在硅谷成立数据科学与技术研究院(iDST),以储备人工智能的技术和人才。2017年,大规模视频分类比赛ACM MM LSVC——相当于视频识别领域的ILSVRC——公布了本年度最佳成绩,阿里巴巴iDST团队的深度学习模型凭借87.41%的平均准确率夺得冠军。同样是2017年,iDST被重新整合为达摩院,阿里巴巴宣布投入1000亿元人民币的研发资金,支持达摩院进行包括人工智能在内的尖端技术的研究。站在今天回看历史,所有这一切,将为后来阿里巴巴通义系列大模型的诞生埋下重要伏笔。
与阿里云中国总部杭州相隔1000多公里的清华大学,将成为大模型时代人工智能研究的另一个重镇,它将撑起中国大模型创业的半壁江山。2015年,杨植麟从清华大学毕业,远赴美国求学。他和张鹏曾先后师从清华大学计算机系教授唐杰,研究知识工程相关工作——一项起源于符号主义AI的研究。那时他们应该想不到,自己日后将分别成为月之暗面和智谱AI这两家大模型领军企业的CEO。同样是从清华大学毕业的王小川在2015年被《经济观察报》评为年度行业领军人物,此后他将经历事业的“大落大起”,并将凭借百川智能回到大模型创业的潮头。
舞台已经就位,英雄正在登场,大模型时代的大幕将徐徐拉开。