
下载掌阅APP,畅读海量书库
立即打开



通信是指多智能体之间能够用某种通信语言进行信息交换,它是智能体之间进行信息共享、任务分配和组织交互的基础,可以显著提高多智能体系统的灵活性和适应性。因此,对于多智能体的协调与合作,探讨有效的信息交换的通信和网络模式具有重要意义。
智能体是一个物理或抽象的实体,具有环境感知、信息交互和自主决策的能力。多智能体系统是由多个智能体及其相应的组织规则和信息交互协议构成的,是能够完成特定任务的一类复杂系统。由于多智能体系统中的信息与资源往往是局部的、分散的,单个智能体总是处于部分可观测环境中而不了解环境整体状况,并且其所具备的感知、存储和计算通信的能力相对有限,无法独立完成整个任务。因此,智能体之间须通过协商或者竞争来协调各自的目标与行为,从而共同解决大规模的复杂性问题。
通信是智能体之间进行交互和组织的基础。智能体通过通信来交流信息,如观察、意图或经验等,从而获得比局部信息更多、更全局的信息,以及获得其他智能体的意图、目标和动作,以便更好地协调它们的行为,提高协作效率。
多智能体通信可以分为直接通信和间接通信两种 [1] 。以多机器人系统为例,机器人之间直接通信时通过无线电、以太网等媒介使一个机器人的行为或状态被其他机器人知晓,需要实时收发、传输大量消息,会受到通信带宽的限制。间接通信时,其行为或状态先影响外部环境,其他机器人通过使用传感器来感知环境而相互作用。虽然无法直接传递消息,但没有带宽限制,可扩展性强。
直接通信是采用智能体进行彼此共享信息的外部通信方法,通过特定的介质(如文本、声音或光)以共同制定的规则或特定的协议直接在智能体之间实现信息的传递。通信协议指定通信过程和构造、编码消息的格式。直接通信的唯一目的是传递信息,如言语行为或无线电信息的传输。更具体地说,直接通信是针对特定接收者的通信,可以是一对一的,也可以是一对多的 [2] 。基于特定的协议,消息交换可以是私有的(即在两个或选定的组成员之间)、本地的(即在邻近的邻居之间)或全局的(即在所有成员之间)。
这种直接通信的方式可以使信息、数据在智能体之间高效、快速地进行交换和传递,但同时也会受到吞吐量、延迟、局部性、智能体类别(同构/异构)等条件的约束。在群体智能理论中,具有相同的动力学模型/内部架构的是同构智能体,反之则是异构的。内部架构是指本地目标、传感器能力、内部状态和可能的动作等。同构智能体之间的区别在于其位置和动作作用的部分环境,例如,在经典的捕食者—猎物场景中,捕食者之间是同构的。
常见的直接通信例子包括消息传递和黑板发布/修改消息,如图2-1所示。
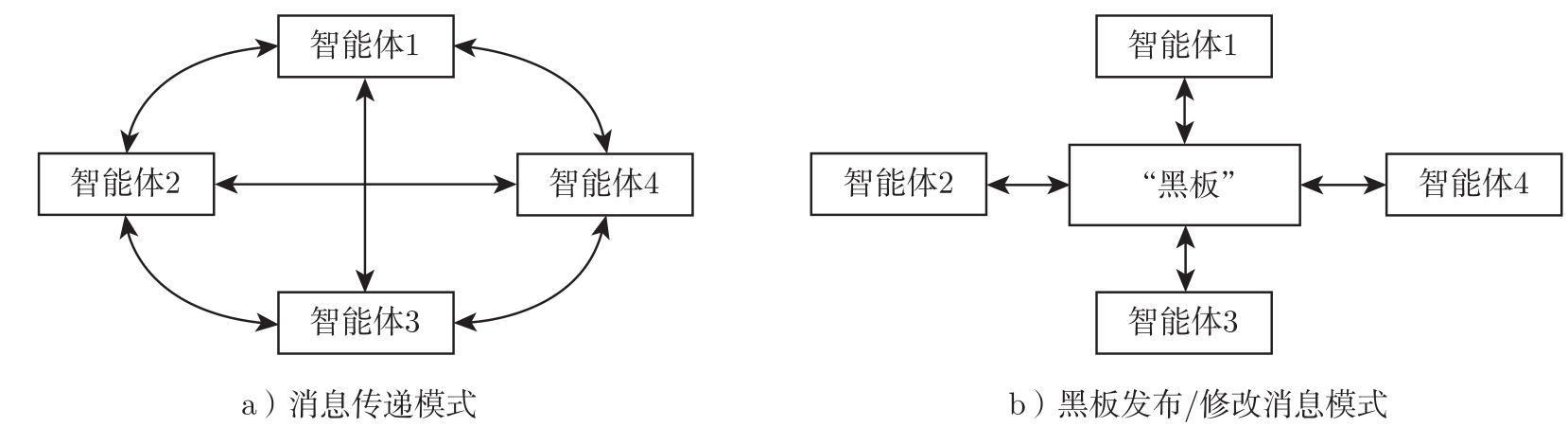
图2-1 多智能体通信方法
1.消息传递
以消息对话形式在智能体之间直接传递信息,但当智能体数目很大时,通信传输开销很高,并且需要考虑实现的复杂性。它包括点对点方式、广播方式。
❑ 点对点方式。通信双方建立直接的通信链路,发送方必须知道系统中接收方的指定位置。以多智能体机器人系统为例,一般采用TCP/IP保证信息包安全到达,实现端到端的确认。
❑ 广播方式。该方式在分布式系统中使用广泛,智能体一次向所有智能体广播消息,而不是发送到特定地址。但消息广播需要大量的带宽,并在实践中产生额外的通信延迟。可以将智能体空间结构化为组,利用组结构的形式进行广播消息传递。每个智能体都至少是一个组的成员,智能体广播一条消息,发送到组内的多个成员,实现分组广播消息传递。此外,并非每个智能体都能提供有用的信息,冗余信息甚至可能损害多智能体学习过程。在针对特定接收对象的广播消息中,消息会被所有智能体接收到。但若消息中的部分内容是针对某个特定智能体的,则该部分内容会附加对应标记;若该智能体发现这个标记,则予以处理,否则不予理会。
例2.1.1 I2C(Individually Inferred Communication)算法 [3] 采用点对点方式进行通信,在每个时间步上,先验网络 b (·)将智能体获得的局部观测 o i 和与之进行通信智能体的ID( j )作为输入,输出信念(Belief)值表明是否与智能体 j 进行通信。基于此,智能体 i 通过通信信道向智能体 j 发送一个请求,智能体 j 使用消息 m j 响应,消息内容可以是局部观测的编码。智能体 i 将接收到的消息送入消息编码网络 e i (·)来产生编码信息 c i ,最终策略网络输出动作的分布 π i ( a i | c i ,o i )。
例2.1.2
TarMAC(Targeted Multi-Agent Communication)算法
[4]
采用广播方式将消息发送给所有智能体,使用基于签名的软注意力机制允许智能体对接收到的无关紧要的消息“视而不见”。发送的每条消息均由两部分组成:用于编码接收者特性的签名
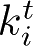 和包含实际消息的值
和包含实际消息的值
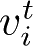 。接收端的每个智能体都根据其隐藏状态
。接收端的每个智能体都根据其隐藏状态
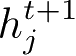 预测一个询问向量
预测一个询问向量
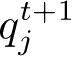 ,与所有
N
个消息的签名进行点乘,采用softmax函数获得每条接收消息的注意力权重
α
ji
。在这个框架中,虽然所有智能体之间还是全连接的,但是每个智能体在处理信息时,都会考虑对于不同智能体信息的权重,即注意力机制。消息发送方和接收方有相似的签名和问询向量时,注意力权重
α
ji
高代表智能体
i
对智能体
j
发送的消息较为关注。因此,在智能体
i
收集到的信息中,智能体
j
的信息所占比重大。
,与所有
N
个消息的签名进行点乘,采用softmax函数获得每条接收消息的注意力权重
α
ji
。在这个框架中,虽然所有智能体之间还是全连接的,但是每个智能体在处理信息时,都会考虑对于不同智能体信息的权重,即注意力机制。消息发送方和接收方有相似的签名和问询向量时,注意力权重
α
ji
高代表智能体
i
对智能体
j
发送的消息较为关注。因此,在智能体
i
收集到的信息中,智能体
j
的信息所占比重大。
2.黑板发布/修改消息
黑板是通信对话参与者都可以访问的共享数据结构,各个智能体通过对黑板内容的直接读取和写入来实现智能体之间的通信和数据共享。多智能体系统中的黑板本身也可以看作一个智能体,其他智能体生成包含有关其内部状态和周围环境信息等的消息,按照相应的协议以显式格式与黑板进行通信。这种方式的特点是集中数据共享,但当系统中的智能体数量较多时,共享数据存储区中的数据量会呈指数增长,各个智能体在访问黑板时要从大量信息中搜索,并且共享数据结构,难以灵活使用异构数据源。
例2.1.3 文献[5]对捕食者—猎物(Predator and Prey, PP)场景使用共享黑板作为通信方法,所有捕食者智能体同时与一个黑板通信。每次迭代时,采用遗传算法的每个捕食者智能体从二进制符号{0, 1}中选择长度为 l 的字符串作为通信符号放置在黑板上,每个智能体都可以读取黑板上所有智能体的通信字符串,以决定下一步动作和要向黑板发送什么内容。这里的黑板可以看作一组状态节点,整个多智能体系统相当于一个包含状态节点可能状态集合的有限状态机(Finite State Machine, FSM),具体来说是Mealy型状态机,而它的输出取决于当前状态和输入。
文献[5]讨论了在30×30的“离散网格(Grid)”世界中多个合作的捕食者共同捕获随机移动猎物的场景。在该仿真场景中,不允许两个捕食者智能体同时占据同一单元。如果两个智能体想要移动到相同的单元,就会被阻塞并保持在当前的位置。单个智能体通常有自己的内部状态,其他智能体是无法观察到的。另外,每个捕食者的观察范围都是有限的,既看不到彼此,也不知道彼此的位置,因此产生了隐藏状态问题,从而可以验证通信的需求。捕食者智能体所获得的感官信息包括猎物的活动范围和方位,并且可以访问黑板内容;所有与黑板通信的捕食者都可以提供信息。黑板上的符号数为 ml , m 是捕食者智能体的数量, l 是长度为 l 的字符串。黑板上所有符号的串联表示整个多智能体系统的状态,通过与黑板通信消除每个智能体观察到的环境状态的分歧。
每个追逐场景的开始,捕食者和猎物被随机放置在不同的单元内,4个捕食者智能体可以同时上、下、左、右移动,而不是轮流移动,一直持续到捕获到猎物为止,或者5000个时间步都没有捕获则结束。捕食者在捕获猎物时会得到奖励,因此性能指标是捕获猎物所花费的时间步数。重复1000次仿真,在无通信的情况下,捕食者捕获随机猎物平均需要110个时间步,而使用黑板进行通信交换信息后则可以在不到70个时间步里快速捕获猎物,显著提高了捕获性能。
3.消息内容
一旦在智能体之间建立通信连接,智能体应决定将哪些信息共享。由于多智能体系统通常假设环境是部分可观测性的,所以传输局部观察到的信息对于协调来说至关重要,而如何编码本地信息则成为消息传输的关键内容之一。
例2.1.4 对于合作关系的智能体,文献[6]中表明可以对以下三种消息内容编码提高团队整体性能:
❑ 共享即时的传感器信息来告知他人当前状态,如瞬时获得的感知、奖励等。
❑ 以分幕的形式共享有关自己过去的经历而其他智能体可能还没有经历过的信息,如<状态,动作,奖励>序列。
❑ 共享与其当前策略相关的知识,如强化学习智能体共享策略<状态,动作,效用(Utility)>。可以细分为两种情况:
- 所有智能体使用相同的策略,每一个智能体都独立的更新全局策略。
- 以一定的频率交换各自的策略,每一个智能体独立更新自己的策略,周期性地进行策略平均共享来相互补充。交流的频率越高,训练速度越快。
围绕例2.1.3中的捕食者—猎物追逐场景进行仿真,结果表明,对于 n 个独立的智能体分别训练来说, n 个通信合作的智能体捕获猎物所需要的步数更少,可达到更好的学习效果。
4.通信限制
已有许多研究强化学习中多个智能体之间使用的通信协议和语言,但是智能体之间的交互是有成本的,通信带宽和容量也是有限的。带宽指通信链路上每秒最大所能传送的数据量(比特)。针对实际通信应用中会受到带宽的限制问题,一些工作通过防止建立不必要的通信连接或传输更简洁的消息来降低通信开销。
例2.1.5 SchedNet算法 [7] 针对有限带宽,使用基于权重的调度机制从 n 个智能体中决定 K 个智能体同时广播它们的消息。由神经网络直接将局部观测结果编码成消息向量: o i → m i ,调度向量 c i 选择性地将 K 个智能体的编码消息通过无线信道广播给所有智能体,例如 m =[010, 111, 101], c =[110], m ⊗ c =010111,从而解决通信资源有限以及智能体竞争通信的问题。同样在例2.1.3的捕食者—猎物场景中测试算法,性能指标是捕获猎物所需的时间步数,算法性能优于无通信的IDQN算法和COMA算法,并且比RR(Round Robin,通信系统中所有智能体按顺序调度的一种规范调度方法)调度性能提高了43%,证明这种智能调度方法能更好地完成任务。
例2.1.6
VBC(Variance Based Control)算法
[8]
侧重于减少智能体之间传输的信息来降低通信开销。具体而言,VBC算法在智能体消息编码器输出的方差上引入了一个额外的损失项,从而有效提取和利用消息中有意义的部分。在每个时间步,智能体
i
的局部动作生成器先计算基于局部观测
o
i
的动作价值函数
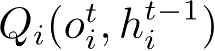 ,当动作价值中的最大值和第二大值之间的差异大于置信阈值
δ
1
时才会广播通信请求。在接收到通信请求时,智能体
j
的消息编码器输出
,当动作价值中的最大值和第二大值之间的差异大于置信阈值
δ
1
时才会广播通信请求。在接收到通信请求时,智能体
j
的消息编码器输出
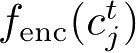 ,其方差大于阈值
δ
2
才会响应请求。消息编码器用多层感知机(Multi-Layer Perception, MLP)进行消息编码,包括两个全连接层和一个Leaky ReLU层。消息编码器的输入是另一个智能体
i
局部动作生成器的中间变量
c
i
,输出
f
enc
(
c
i
)。通过只在智能体之间交换有用的信息,VBC算法减少通信开销。文献[8]从理论上证明了算法的稳定性。在星际争霸6个任务中,VBC算法比其他基准算法获得的胜率高20%,通信开销比SchedNet算法低2~10倍。在合作导航、捕食者—猎物场景中进行测试,也获得了更低的通信开销。
,其方差大于阈值
δ
2
才会响应请求。消息编码器用多层感知机(Multi-Layer Perception, MLP)进行消息编码,包括两个全连接层和一个Leaky ReLU层。消息编码器的输入是另一个智能体
i
局部动作生成器的中间变量
c
i
,输出
f
enc
(
c
i
)。通过只在智能体之间交换有用的信息,VBC算法减少通信开销。文献[8]从理论上证明了算法的稳定性。在星际争霸6个任务中,VBC算法比其他基准算法获得的胜率高20%,通信开销比SchedNet算法低2~10倍。在合作导航、捕食者—猎物场景中进行测试,也获得了更低的通信开销。
间接通信的定义是通过改变世界环境而隐含地将信息从一个智能体传递到另一个智能体 [1] ,即智能体的行为或状态首先影响外部环境,然后环境的改变会影响其他智能体的行为或状态,智能体只通过本身的传感器来获取周围环境信息来实现群体间的协作。自然界有很多类似的例子,如将脚印留在雪中,留下一小块面包屑以便找到回家的路,以及其他在环境中放置物品来进行提示等。
许多针对间接通信的研究从社交昆虫使用信息素来标记路径中汲取了灵感。这里,信息素是化合物,其存在和浓度可以被同伴感知,尽管可能会扩散和蒸发,但仍可以在环境中持续很长时间。使用信息素来实现间接通信,可以在没有集中化的情况下快速适应不断变化的环境信息。从某种意义上说,信息素沉积物可能被视为所有智能体共享的大型黑板或状态效用表格,但不同的是信息素只能在局部检测到,智能体只读取或改变自身在环境中某点的信息素浓度。
1.共识主动性(Stigmergy)
共识主动性起初是由法国昆虫学家Pierre-Paul Grassé提出的概念,用来解释没有直接通信且智力非常有限的昆虫为何可以协作处理复杂的任务。共识主动性 [7,9-12] 启发自蚁群协同机制,蚁群寻找食物的过程中会分泌信息素遗留在经过的路径上,其他的蚂蚁会感知到信息素,向信息素浓度高的位置移动,最终到达正确的目标位置。若将智能体视作蚂蚁个体,它处在充满信息素的特定空间内,接收来自环境的状态输入并做出动作决策。移动后的智能体产生新的信息素,这会影响原有环境中的信息素,更新后的环境会将新的状态输入给智能体,从而构成了一个闭环。
共识主动性的概念表明单个智能体可以通过共享环境间接通信,而当单个智能体造成环境改变时,其他智能体也会响应这种改变,并做出相应的变动,实现相互间的信息交互和彼此间的自主协调。由于共识主动性可以实现复杂、协调的活动,而无须智能体之间的直接通信,也无须集中控制调控,因此随着个体数目的增加,通信开销的增幅较小。鉴于此,基于共识主动性的间接通信方式可用于在不可预测的环境中构建稳健可靠的系统。
作为对共享环境进行局部修改而交互、协调的一种间接介导的机制,共识主动性通常由媒介(Medium)、动作(Action)、状态(Condition)和痕迹(Trace)4部分组成,它们共同构成与周围环境之间的反馈回路,如图2-2所示。
❑ 媒介。媒介在多智能体协作中起着信息聚合器的作用。由于媒介的存在,智能体和它们周围的环境可以建立高效的共识主动性交互,从而使得环境中分散的智能体能与其他智能体间接通信。有时,媒介会被认为和环境等效,重新将媒介定义为所有智能体都可以控制和可感知的那部分环境 [13] ,这是确保不同智能体可以通过媒介相互作用的必要条件。
❑ 动作。动作是一种导致环境状态发生变化的因果过程,具有前因以及随之而来的效果。在人工智能中使用的简单的基于智能体的模型中,前因通常为状态,动作则指定该状态的后续转换。
❑ 状态。指定动作下的环境状态。
❑ 痕迹。智能体在媒介中留下痕迹作为动作导致环境变化的指示,不同的智能体在媒介中留下的痕迹会扩散并且以自发的方式进一步融合。然后这些痕迹的变化模式就被视作其他智能体后续动作的相互影响。痕迹可以有不同表示,比如化学物质(如自然界中的信息素)、人工数字信息素(表示有关系统的信息,通过外部环境中的存储设备存储)、物理标记(如2D条形码、射频识别标签、颜色标签)等。
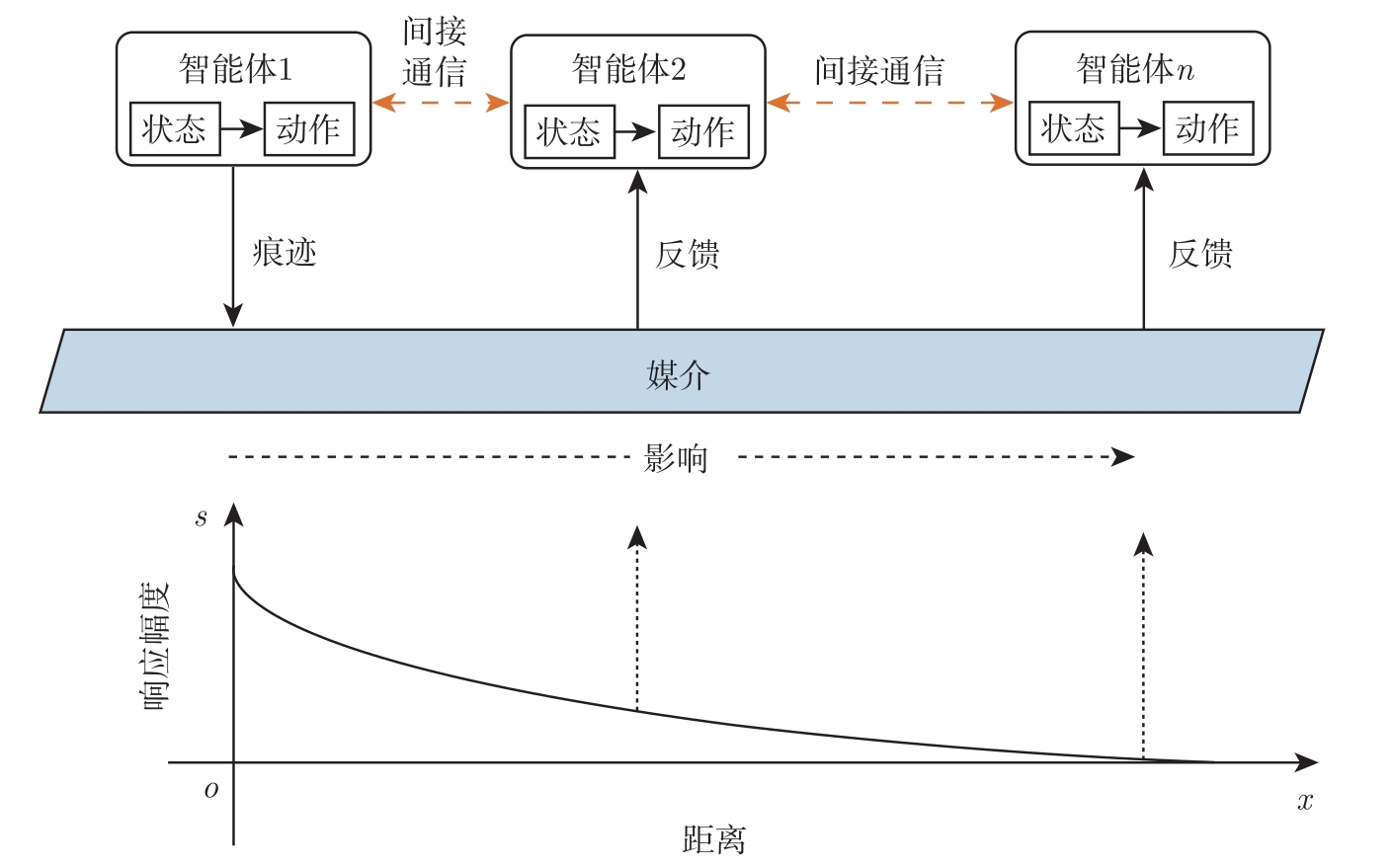
图2-2 共识主动性学习机制
具有共识主动性的智能体根据局部状态选择动作后会在环境中留下痕迹,以影响其他智能体的状态。媒介是充满痕迹的指定空间,如数字信息素地图,响应幅度取决于具有共识主动性智能体之间的距离 x 和痕迹在媒介中的强度。
许多的研究都是基于信息素/数字信息素实现的,其动态特性是:
❑ 聚集:同一区域内的信息素可以线性叠加;
❑ 扩散:智能体释放的信息素有残留后会以一定扩散率向周围区域扩散;
❑ 挥发:智能体占据位置上的信息素会以一定衰减率减少。
群体智能中模仿自然界蚁群觅食行为的模拟进化算法——蚁群优化算法(Ant Colony Optimization, ACO) [14-15] 是一类元启发式搜索算法,它通过共识主动性这种间接通信方式来彼此协作,具有较强的可靠性、稳健性和全局搜索能力。蚂蚁觅食过程中在其所经过的路径上留下信息素,在运动过程中感受到信息素的存在及其强度,以此指导自己的运动方向。大批蚂蚁组成的蚁群行为表现出一种信息的正反馈现象,即某条路上走过的蚂蚁越多,后来者选择该路径的概率就越大。然后蚂蚁用自己的信息素强化选定的路径。信息素会因挥发而减少,蚂蚁朝着信息素浓度高的方向前进。蚁群通过这种信息交换方式与互相协作找到蚁穴到食物源的最短路径,该算法可以用来求解各种与组合优化路径相关的组合优化问题,例如在旅行商问题的求解上表现出很强的优越性。
2.共识主动性应用举例
❑ 通信网络自适应路由: 路由是整个网络控制系统的核心,为有线网络开发的群体智能路由算法可以在没有全局信息的通信网络中找到近似最优的路由。
例2.1.7 Ant-Based Control(ABC)算法 [16] 使用蚂蚁作为探索智能体,遍历网络节点并更新路由指标(信息素)来实现智能体间接通信。ABC算法综合考虑路线的长度和沿线的拥挤程度来选择路由,两种路由任务分别是进行概率决策的探索蚂蚁和做出确定性决策的实际调用(选择目的地对应列中信息素最多的链路)。每个源节点S都会发出许多探索蚂蚁,这些蚂蚁都朝着随机选择的目的地D前进,到达D时从网络中删除。网络结构及节点路由表如图2-3所示。在节点路由表中,行包括所有邻节点,列包括所有可能的目的地,每个条目都对应于特定邻节点指向特定目的地的链路上的信息素量,这些信息素量在每一列中归一化,可以作为选择最佳链路的概率。
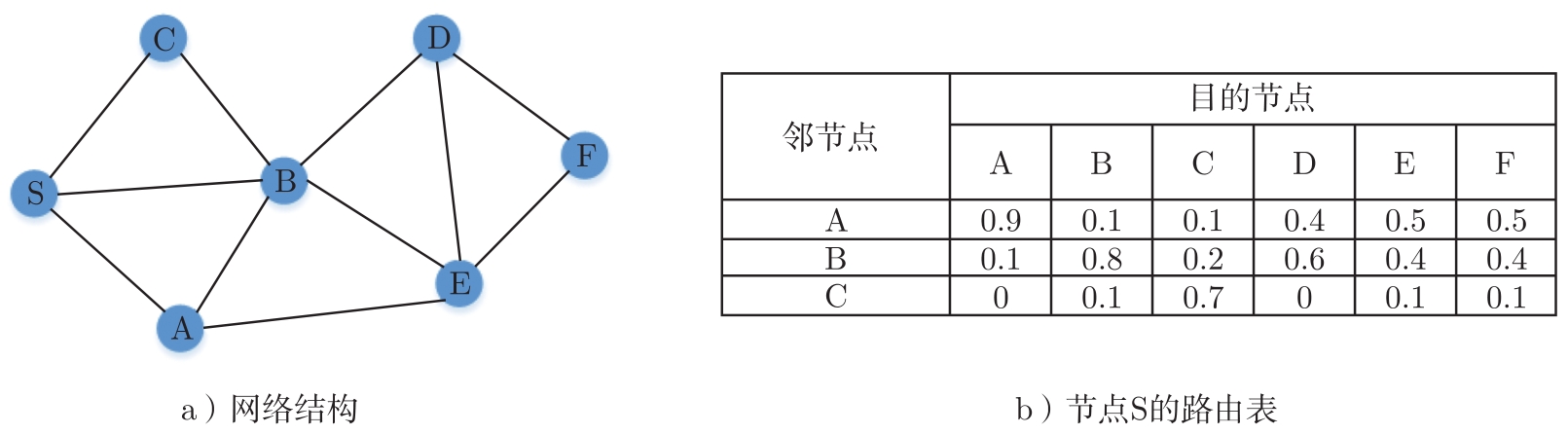
图2-3 网络结构及节点S的路由表
由于网络链接是双向的,探索蚂蚁在途中的每个节点(如节点C)处更新C处路由表中与源节点S对应的条目。具体来说,路由表中对应于蚂蚁刚刚出现过的节点信息素量的概率根据公式
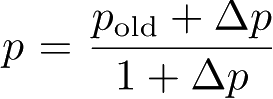 更新,该节点路由表中的其他条目根据
更新,该节点路由表中的其他条目根据
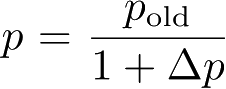 降低。基于经验值文献[16]给出
降低。基于经验值文献[16]给出
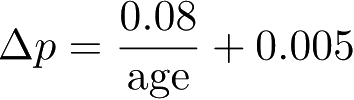 ,其中age是蚂蚁自源节点以来所经过的时间步数,这使得系统对那些沿着较短的路径移动的蚂蚁有更强烈的响应。探索蚂蚁通过生成一个随机数来选择下一个节点,并根据它们在路由表中的概率来选择一条链路。蚂蚁和呼叫都在同一个队列中行进,呼叫以路由表中目的地对应列中的最高概率对链路做出确定性的选择,但不会留下任何信息素。呼叫阻塞的节点在时间步数上给探索蚂蚁一个延迟的反馈,这种延迟随着拥塞程度的增加而增加。这可以暂时减少蚂蚁从拥塞节点流向其邻节点的流量,防止影响蚂蚁路由到拥塞节点的路由表。并且由于延迟蚂蚁的age的增加,根据Δ
p
的计算公式,它们对路由表的影响变小,而路由表又会决定新呼叫的路由。网络性能是通过呼叫失败来衡量的,与使用固定的最短路由途径算法相比,使用ABC路由方案会显示出更少的呼叫失败,同时表现出许多有吸引力的分布式控制功能。
,其中age是蚂蚁自源节点以来所经过的时间步数,这使得系统对那些沿着较短的路径移动的蚂蚁有更强烈的响应。探索蚂蚁通过生成一个随机数来选择下一个节点,并根据它们在路由表中的概率来选择一条链路。蚂蚁和呼叫都在同一个队列中行进,呼叫以路由表中目的地对应列中的最高概率对链路做出确定性的选择,但不会留下任何信息素。呼叫阻塞的节点在时间步数上给探索蚂蚁一个延迟的反馈,这种延迟随着拥塞程度的增加而增加。这可以暂时减少蚂蚁从拥塞节点流向其邻节点的流量,防止影响蚂蚁路由到拥塞节点的路由表。并且由于延迟蚂蚁的age的增加,根据Δ
p
的计算公式,它们对路由表的影响变小,而路由表又会决定新呼叫的路由。网络性能是通过呼叫失败来衡量的,与使用固定的最短路由途径算法相比,使用ABC路由方案会显示出更少的呼叫失败,同时表现出许多有吸引力的分布式控制功能。
❑ 交通管理: 交通流观测和交通拥堵信息通常是使用放置在主干道上的感应门计数通过特定位置的车辆来得到的,作为当前信息广播给车辆。交通拥塞控制是一种集中机制,可以用作间接通信的共识主动性机制实现去中心化交通拥堵管理。在交通运输和多智能体系统领域,动态短期记忆一直是研究的热点。近年来,探测车辆信息或智能手机提供的更短期的交通信息,这种短期的流量信息就被建模成共识主动性,用于间接通信进行智能体之间的合作,使分布式交通拥堵管理的动态协调方法成为可能。
例2.1.8 文献[17]中,共识主动性信息分为长期和短期两种,数值实验的评价指标是在24个节点的道路网络中,300辆车从各自起点到各自终点所花费的总时间。长期共识主动性信息是每条道路 l 、每 x 个小时更新值 v l =ave+sd×0.05,ave是花费时间的平均值,sd是道路上所有存储数据的标准差。短期共识主动性信息是每5min更新值 v s =ave+sd s ×0.05,其中的sd s 是最近5min存储数据的标准差;如果最近5min内没有车辆经过,则该链路 v s = v 0 。将长短期信息结合 v ls = v s ×(1 -w )+ v l × w ,则每隔5min内的所有探测车辆都会根据长期和短期共识主动性信息找到到达目的地节点的最佳路径。此外,文献[17]还引入基于预期的共识主动性信息 v a ,其根据该道路探测车辆的总数和道路容量等信息。如果车辆多, v a 就会短暂增加,并据此搜索最佳路线。实验结果均表明,与所有车辆通过Dijkstra搜索最佳路径而不共享任何流量信息相比,车辆通过共识主动性机制在拥塞等情况下动态选择路线,花费的总时间显著降低。
❑ 群体机器人跟踪与搜索动态目标: 在未知环境中进行目标搜索是机器人技术的基本问题之一,与单个但性能更高的机器人相比,目标搜索任务可以由一组自动移动的机器人执行。第11章将会讲到,由于群体效应,群体机器人系统在实施这些任务时可能具有更好的性能。群体机器人的协作依赖于通信,直接通信需实时传输和接收大量信息,并且会收到通信带宽的限制。间接通信虽无法直接将信息传递给机器人,但没有带宽的限制,使得机器人系统的大小可以扩展。个体只需要解码和修改环境中留下的信息,并据此确定自己的行为。
例2.1.9 文献[18]提出了一种共识主动性机制的群体机器人跟踪与搜索动态目标的模型。在执行搜索和跟踪任务时,机器人无法在整个过程中知道目标的位置和运动趋势,它们可以获得的有关目标的唯一信息是检测到的信号强度。将无线RFID标签作为机器人间接通信的信息素载体,RFID标签中存储的数据形式取决于部署在搜索区域中的信息素模型。每个机器人都带有RFID读取器,根据读取的RFID标签中的信息素向量和探测到的目标信号强度,机器人决定自身的运动速度和方向。同时,将从标签中读取的矢量信息素(包含大小和方向)和根据自己的运动经验得出的中间向量(有助于生成矢量信息素)生成一个新的向量信息素来重新写入这个标签。在整个搜索和跟踪过程中,机器人通过这种方式间接交互。所有标签载体形成完整的包含目标信号强度梯度特征的信息素向量地图,达成对目标的搜索与追踪效果。这种通信模式降低了对机器人通信能力的要求,使群体具有更强的可扩展性。
文献[18]分别在平台仿真和真实世界中进行试验,验证了目标做三角形和做圆形运动轨迹时的两种情况。结果表明,共识主动性机制使得机器人可以在短时间内找到目标,并保持对目标的近距离轨道跟踪。此外,使用不同数目的机器人,这种机制仍然可行,表明基于共识主动性机制的方案是具有可扩展性的。
大多数应用中的协调过程集中在信息素的维护上,但参与者本身缺乏学习行为策略的能力。例如,ACO算法中的协调过程导致信息素浓度增加,但智能体的行为策略是预先确定的,以概率的方式在几种浓度中选择。在更多实际情况下,不能预先确定所涉及的智能体的行为策略,并且智能体必须在维持协调的同时调整自己的策略。在多智能体强化学习中,每个智能体都可以通过与周围环境交互来学习其行为策略,Aras等人 [19] 从概念上描述了如何将共识主动性的某些方面引入多智能体强化学习中,并指出共识主动性不同于Markov决策过程(Markov Decision Process, MDP)的两个特性:
❑ 非静态空间,如蚂蚁从一个特定的、信息素空的状态空间开始,并对其进行转化。
❑ 非静态奖励功能,如蚂蚁没有特定的地点来收集所有死去的蚂蚁,所以一开始的奖励函数是没有定义的。
在许多基于信息素的学习方法中,强化学习算法采用固定的信息素铺设过程,在探索空间或更新状态—动作效用估计的时候,使用当前信息素的数量来表示额外的传感信息。
例2.1.10 Phe-Q算法(Pheromone-Q Learning) [20-21] 将合成信息素与Q学习相结合,在Q学习更新方程中引入了一个必须最大化的置信因子。在捕食者—猎物场景中,绘制不同epoch的连续Q值之间的均方根误差曲线,将该值小于某阈值作为学习收敛标准。对比采用合成信息素进行通信的Phe-Q学习和无通信的Q学习,前者的收敛速度更快。
Phe-Q中的信息素有两个可能的离散值:寻找食物时信息素的沉积值
φ
s
、带着食物返回洞穴时信息素的沉积值
φ
n
。信息素在一个单元格内聚集直到达到饱和状态,以
φ
e
的速率蒸发,直到没有智能体访问该单元格来补充信息素。信息素以
φ
d
的速率扩散到相邻的单元格内,该速率与曼哈顿距离成反比。合成信息素
Φ
(
s
) 是一个标量值
Φ
∈ [0, 255],表示环境中某个单元格
s
的信息素浓度。
N
a
是所选动作
a
之后相邻单元的集合。信念因子
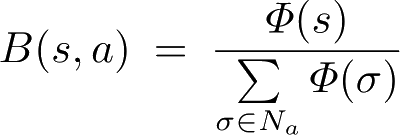 ,是当前状态实际信息素浓度和相邻单元信息素浓度之和的比值,它整合了信息素的基本动态性质:聚集、蒸发和扩散。把信念因子引入Q学习的更新方程中,使其随Q值一起最大化:
,是当前状态实际信息素浓度和相邻单元信息素浓度之和的比值,它整合了信息素的基本动态性质:聚集、蒸发和扩散。把信念因子引入Q学习的更新方程中,使其随Q值一起最大化:
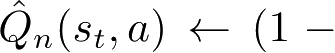
 。
ξ
是epoch≥0的激活函数,随着成功执行任务的智能体数量而增加。智能体既没有对周围环境的先验知识,也没有对食物位置或巢穴的先验知识。在早期探索中,智能体会在较小的程度上相信信息素地图,所有智能体都偏向于探索。智能体在找到食物及返回巢穴时获得奖励。
。
ξ
是epoch≥0的激活函数,随着成功执行任务的智能体数量而增加。智能体既没有对周围环境的先验知识,也没有对食物位置或巢穴的先验知识。在早期探索中,智能体会在较小的程度上相信信息素地图,所有智能体都偏向于探索。智能体在找到食物及返回巢穴时获得奖励。
文献[22]整理了多智能体系统组织形式的范例,给出了关键特征、优缺点分析,并指出组织方式具有一定目的,组织的形状、大小和特征会影响最终系统的性能和行为。
集中式结构(Centralized)是系统根据一定的规则和策略分为若干子系统,各个子系统由具有全局知识和协调功能的领导智能体进行集中管理,可以根据全局信息选择(联合)行动,完成任务的动态分配与资源的动态调度,协调各个协作智能体之间的竞争与合作。此类全局信息是通过完全可观察性或通信得到的,其他智能体只能与领导智能体进行信息交流或交换,然后执行指令,彼此之间不存在任何交互。
集中式结构比较容易实现系统的管理、控制和调度,因此具有良好的协调性,但当领导智能体发生故障时,整个多智能体系统将会出现信息阻塞,进而导致系统瘫痪等。所以,由于集中式结构信息交互方式的固有弊端,因此很难处理大规模的任务,例如复杂传感器网络、智能电网、云计算网络和大数据网络等。
集中式结构有很多实现方式,其中联邦学习是一种典型的实现方法。具体而言,经典的联邦学习场景包括一个中央服务器和一组客户端设备。每个客户端从中央服务器下载模型,利用本地数据进行训练,将更新后的参数返回给中央服务器;中央服务器将接收到的、各客户端返回的参数进行聚合,更新模型,再把最新的模型反馈到每个客户端。经过多轮迭代,最终得到一个趋近于集中式机器学习结果的模型。在这个过程中,不同的客户端都是相同且完整的模型,它们之间不交流、不依赖。联邦学习能够联合训练机器学习模型,同时仅在本地保存私有信息的数据。在这种情况下,智能体可以获得一个训练有素的机器学习模型,而不损害它们的隐私。当智能体不愿意进行策略参数等信息的共享时,联邦学习算法保证智能体之间只传输有限的抽象信息,从而满足各个智能体对于隐私的需求。
集中式结构如图2-4a所示。
去中心化(Decentralized)结构中的各个智能体彼此独立、完全平等、无逻辑上的主从关系,没有统一的控制中心,网络中的任一节点停止工作或退出都不会影响系统整体的运作。这使得多智能体系统具有良好的容错性、开放性和可拓展性。
随着移动无线通信和物联网技术的快速发展,出现了许多需要智能体之间协作的场景,如无人机部署、分布式控制、行业自动化领域、移动人群感测和计算等。由于计算资源有限,加之超低时延和超高可靠性的需求,传统的集中控制方法通常是不切实际的。与集中式结构不同,去中心化结构中的每个智能体仅与其邻居之间进行信息交流或交换。因此,针对系统中个别智能体失效或智能体之间的链路出现故障等情形,去中心化结构具有很强的鲁棒性。但是,由于去中心化结构中的每个智能体能够获取的仅仅是自己的局部观测,对全局信息的访问受限于局部交互,所以智能体之间的协同仍然存在困难,依赖于共享一些信息,如环境信息、资源利用信息、任务求解进展状况信息等。这需要提供存储和访问机制,单靠消息传递机制不能有效解决。各个智能体根据系统的目标、状态,以及自身的状态、能力、资源和知识,利用通信网络相互协商与谈判,确定各自的任务,协调各自的行为活动。
去中心化结构如图2-4b所示。
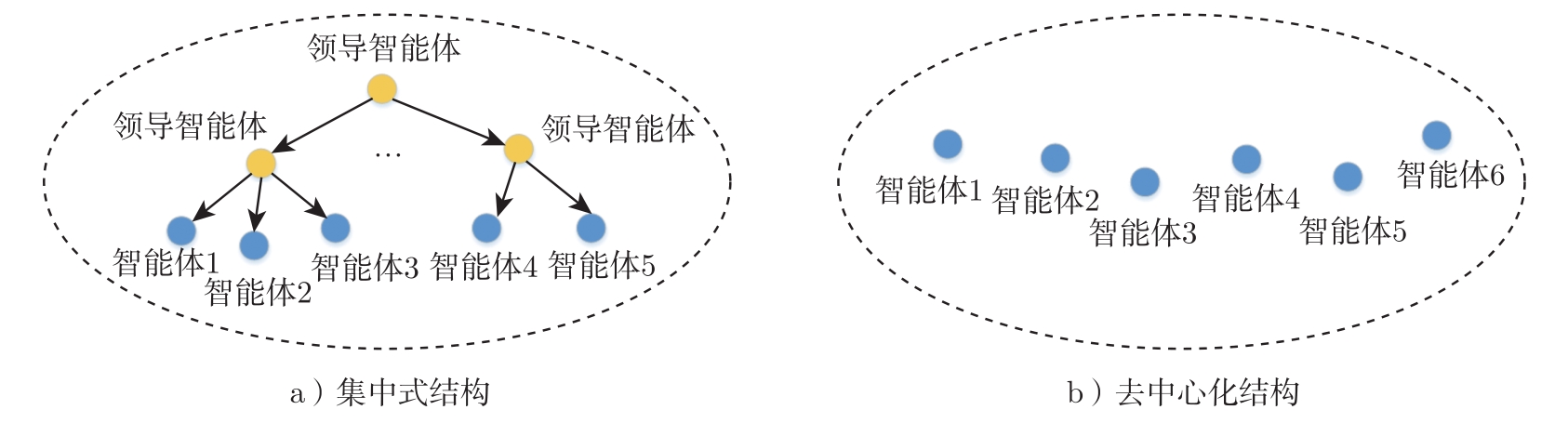
图2-4 集中式和去中心化结构
自组织网络(Self-Organized Network)没有预先的网络基础设施,没有明确的外部控制,智能体之间通过局部交互来实现全局系统行为,并且是动态变化的。
自组织网络的特点:
❑ 去中心化:通信网络可以由通信节点自行组织,网络中没有严格意义上的控制中心来控制通信行为。在通信过程中,所有通信节点都是平等的,每个通信节点都可以随时加入和离开网络,从而可以防止出现控制中心被破坏而全网瘫痪的危险,具有很强的鲁棒性。
❑ 多跳通信:由于通信距离受限,如果通信网络拓扑结构很大,两个节点之间没有直接的通信联系,就需要借助其他节点的中继转发实现,即多跳通信实现。
❑ 自组织性:不依赖基础设施,网络中的各节点可以相互协调,遵循自组织原则选择通信对象,动态更改潜在的网络结构。即使网络发生动态变化,也可迅速调整其拓扑结构来保持必要的通信能力。
❑ 动态拓扑:网络节点可随时接入,生成新的通信拓扑网络结构。
群体智能中自组织机制的特点 [23] :
❑ 正反馈:自组织系统中的正反馈驱动系统中的智能体选择为集体提供最大收益的动作。共识主动性系统中的正反馈是吸引越来越多的智能体参与解决问题的过程。
❑ 负反馈:用于平衡正反馈,稳定系统,确保一个决定或少数几个糟糕的决定不会影响到整个问题解决过程,防止过早收敛到次优解决方案。例如,信息素的挥发特性,使其必须不断加强才能在环境中持续存在。
❑ 波动:这些与系统的随机性有关,这种随机性通常对于新兴结构至关重要,有助于发现新的解决方案,摆脱停滞。例如,随机游走、错误、随机任务切换等。
❑ 多重交互:这种交互作用可以是直接的或者间接的。例如,采用共识主动性通过环境间接相互作用。
例2.2.1 文献[24]提出了基于群体智能的无线传感网络自组织方法(SI-SO),通过目标的运动来自适应地确定唤醒传感器的网络节点,从而减少能源消耗,并且保证传感性能。将传感器视为具有基本功能的蚂蚁(智能体),信息素可以看作蚂蚁之间的通信方法。节点根据唤醒概率确定是否随机醒来。如果在醒来状态,那么它将进行探测并做一些简单的计算,否则它只是存储能量而不进行工作;如果目标被探测到,它就会放置单位信息素,否则不放置。每个周期内节点产生的信息素都会扩散至周围 K 个邻居节点,并且扩散的信息素会随着时间分解。目标运动会造成信息损失,移动得越快,信息素分解得越快。如此传递信息,每个蚂蚁都可以知道邻居的工作情况,基于累积的信息素来自适应和最佳地确定每个传感器的唤醒概率,将无线传感网络自组织的问题转换成群体智能优化问题。
该算法的仿真场景是:目标以6m/s的恒定速度穿越200m×200m的矩形监视区,该区域有500个传感器节点随机分散,每个传感器检测范围
R
s
=15m,周期为1s。评价指标是利用率,
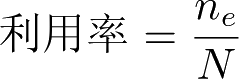 ,其中
n
e
是
t
时刻检测目标的唤醒节点的有用数量、
N
是
t
时刻唤醒节点总数。一开始由于目标存在的不确定性,SI-SO算法的节点利用率与500个传感器全部唤醒的利用率是相近的;从第10s开始检测到目标之后,虽然检测目标的唤醒节点有用数量相近,但SI-SO算法的唤醒节点总数仅略高于50个,最终其利用率远高于500个传感器全部唤醒的利用率。
,其中
n
e
是
t
时刻检测目标的唤醒节点的有用数量、
N
是
t
时刻唤醒节点总数。一开始由于目标存在的不确定性,SI-SO算法的节点利用率与500个传感器全部唤醒的利用率是相近的;从第10s开始检测到目标之后,虽然检测目标的唤醒节点有用数量相近,但SI-SO算法的唤醒节点总数仅略高于50个,最终其利用率远高于500个传感器全部唤醒的利用率。
文献[25]将多智能体系统学习过程分为两类:中心化学习(Centralized Learning)和去中心化学习(Decentralized Learning)。中心化学习是指学习过程的所有部分通过一个完全独立于其他智能体的智能体执行,其他智能体之间不需要进行任何交互;如果几个智能体参与同样的学习过程就为去中心化学习。在一个多智能体系统中,可能会存在几个中心化学习者同一时间试图获得相同的或不同的学习目标,同时,另外几组智能体会经历不同的去中心化学习过程,二者的学习目标可能是不同的,也可能是相同的。
多智能体学习中,环境会根据当前的学习效果的评估,给学习者提供反馈。根据反馈类型的不同区分为3种主要的方法:监督学习、无监督学习、基于奖励的学习 [1] 。
❑ 监督学习:环境作为“教师”提供正确的输出,即反馈指定了学习者所期望的动作,学习的目的是尽可能地匹配这一期望的动作。
❑ 无监督学习:环境作为“观察者”没有提供反馈,学习的目标是基于试验和自组织的过程来找到有用的和期望的活动。
❑ 基于奖励的学习:环境作为“批评者”提供学习者成果的质量评估(即奖励),学习的目标是将奖励最大化。由于多智能体相互作用中的固有复杂性,监督学习方法反馈给智能体提供给定情况的正确行为在实际应用中不占优势。多智能体学习的绝大多数研究都使用了基于奖励的方法,这大致分为两个方面:
- 估计价值函数的强化学习方法。
- 随机搜索方法,如进化计算,模拟退火(Simulated Annealing)和随机爬山,它们直接学习行为,而无须引入价值函数。
强化学习的方法可以更清晰地研究智能群体间的规律与协调方式,寻找更高效的协同模型来提高多智能体系统的性能。策略网络和价值网络的参数记作
θ
i
和
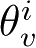 。针对部分可观测的假设,第
i
个智能体的局部观测
O
i
是全局状态
S
的一部分,所有局部观测的总和构成全局状态
S
=[
O
1
, O
2
,...,
O
m
]。每个智能体的策略网络和价值网络即为
。针对部分可观测的假设,第
i
个智能体的局部观测
O
i
是全局状态
S
的一部分,所有局部观测的总和构成全局状态
S
=[
O
1
, O
2
,...,
O
m
]。每个智能体的策略网络和价值网络即为
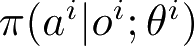 和
和
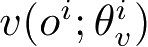 。如果是完全可观测的情况,则有
O
1
=
O
2
=···=
O
m
=
S
。
。如果是完全可观测的情况,则有
O
1
=
O
2
=···=
O
m
=
S
。
❑ 完全中心化(Fully Centralized)。智能体 i 只负责与环境交互,把观测到的 o i 和 r i 发送给中央控制器。中央控制器的输入状态 s 是所有智能体观测值的拼接,它有一个价值网络 v ( s ; θ v )和每个智能体的策略网络 π ( a i | s ; θ i ),拥有全局信息,统一负责训练和决策,输出所有智能体的联合动作。优点是利用完整信息做中心化决策,可以将单智能体算法扩展,收敛性可以得到保证;缺点是通信延迟会造成训练和决策速度变慢,并且随着智能体数量的增多,输入维度线性增加,输出的动作空间呈指数增加。
❑ 完全去中心化(Fully Decentralized)。智能体 i 作为独立个体,用局部观测代替全局状态来独立与环境进行交互以获取 o i 和 r i ,训练自己的策略网络 π ( a i | o i ; θ i )。整个过程无须中央控制器的参与,无须任何通信,并且可以做到实时决策。缺点是完全看作单智能体情况,而忽略了多智能体之间彼此可能的影响,训练的收敛性得不到保证。
❑ 中心化训练+去中心化决策(Centralized Training with Decentralized Execu-tion, CTDE)。智能体 i 都有自己的策略网络 π ( a i | o i ; θ i ),中央控制器拥有价值网络 v ( s ; θ v ),训练时由中央控制器帮助智能体训练策略网络。训练结束后,每个智能体都根据自己的策略网络和局部观测 o i 进行决策。该架构是目前最广泛采用的架构。
表2-1汇总了多智能体强化学习中的3种组织架构及是否需要通信。
表2-1 多智能体强化学习中的3种组织架构及是否需要通信

部分可观测性是多智能体强化学习中的一个常见假设。基于这一假设,分布在环境中的智能体只获得本地的观察结果,而不了解环境整体状况,容易受到非平稳性问题影响,其他智能体的变化和调整策略也会影响自己的决策。因此,通信是部分可观测性假设下协调多个智能体行为的有效机制。在多智能体强化学习领域,智能体可以通过通信来提高整体学习性能并实现其目标。
多智能体通信过程中的通信对象,通常采用预定义或启发式的方法进行规定。预定义的固定拓扑结构限定特定智能体之间的通信,从而限制了潜在的合作可能性,可以采用学习的方法让智能体来决定其通信对象,在学习过程中动态更改潜在的网络结构,即形成自组织的通信架构。
多智能体通信过程中的通信拓扑结构,反映出各实体之间的结构关系,这是实现各种通信协议的基础,也关系到最终的通信性能。如果将智能体和智能体之间的连接关系分别当作多智能体网络中的节点和边,根据文献[26]的分析,基于通信的多智能体强化学习方法的通信拓扑结构分为5种:完全连接(Fully Connected)结构、星形(Star)结构、树状(Tree)结构、相邻(Neighboring)结构以及分层(Hierarchical)结构,如图2-5所示。
❑ 完全连接结构。智能体需要与其他所有智能体进行通信,当智能体数量较大时需要高带宽。
例2.3.1 DIAL算法 [27] 采用中心化训练、去中心化决策架构。它将附加的通信动作添加到每个智能体的动作集中,除了选定的当前动作外,还会生成一条跨智能体的消息通过通信信道发送给其他智能体,来增强智能体对环境的感知能力。但是,这种类型的通信信道存在于所有独立学习智能体之间,使DIAL随着智能体数量增加而变得非常复杂。
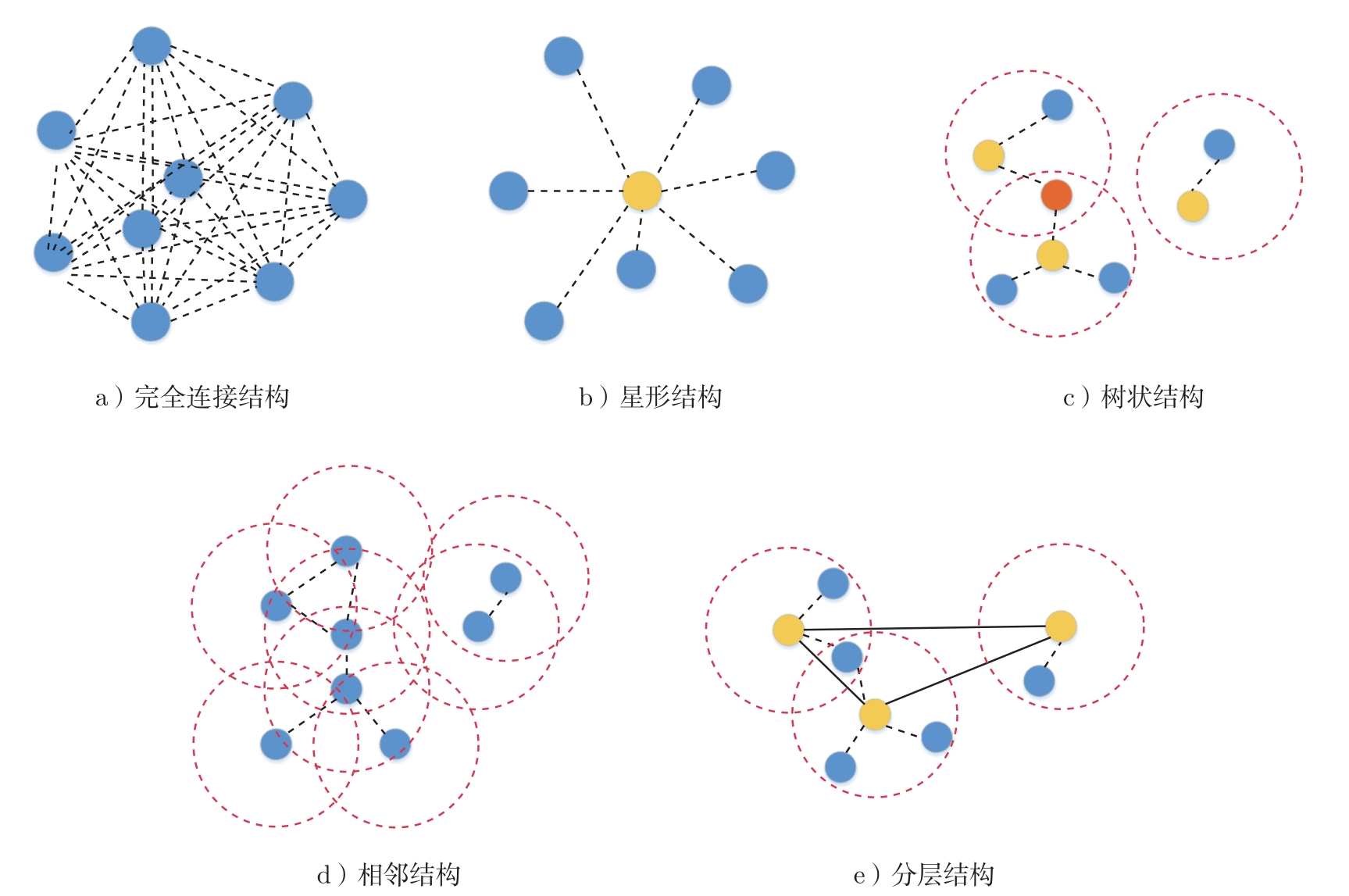
图2-5 常见的通信拓扑结构
❑ 星形结构。智能体只与单个虚拟的中心智能体进行通信,这可能会造成中心智能体通信带宽和信息提取方面的瓶颈问题。
例2.3.2 CommNet算法 [28] 学习一个所有智能体共享的神经网络以便处理局部观测。CommNet算法从所有智能体收集消息并计算平均值,然后将平均值单元生成的消息进行广播。每个智能体都把收到的广播消息作为下一个时间步的输入信号。因此,CommNet算法需要与所有智能体进行即时通信。
例2.3.3 在CommNet的基础上,IC3Net算法 [29] 在一个可观察的领域与某些而非全部智能体进行通信。具体而言,对于IC3Net算法,只有附近的智能体才能参与由概率门机制确定的通信组,并且每个智能体都采用个性化奖励,而不是CommNet中使用的全局共享奖励,从而在竞争或混合环境中显示出更多不同的行为。
❑ 树状结构。智能体只与邻居智能体进行通信,但必须在组之间顺序通信。只有在两组交集时才实现组间通信,因此会产生较高的时间复杂性。
例2.3.4 ATOC(Attentional Communication)算法 [30] 设计了一个注意力单元来接收智能体的局部观察和动作意图,并确定智能体是否应与其他智能体进行通信以在其可观察的领域进行合作。由发起者选择合作者来组成协调策略的通信组,通信组仅在必要时动态更改并保留。利用双向LSTM单元作为通信信道连接通信组中的智能体,选择性地输出合作决策的重要信息,能使智能体在动态通信环境中学习协调的策略。
❑ 相邻结构。智能体与邻居智能体同时通信以降低通信成本。
例2.3.5 DGN算法 [31] 将多智能体环境建模成一个图网络,每层图网络都利用注意力机制对邻居节点信息进行加权来更新自己节点的状态。根据图网络更新规则,每次都利用邻居信息来更新自身节点信息,邻居也在利用其邻居进行更新。因此随着卷积层增加,每个智能体的感知域随之扩大,从而可以处理智能体邻居数量不确定的问题。
❑ 分层结构。这是一种基于通信群组的拓扑结构,将智能体分为不同的组,每个群组都包含一个高级智能体及若干个低级智能体。群组内可以通信,群组间也可以进行通信。
例2.3.6 LSC(Learning Structured Communication)算法 [26] 采用基于群组的分层通信结构,组内信息聚合是群组低级智能体与高级智能体之间通信时,由高级智能体将群组内的所有信息聚合,形成本群组对于环境的感知;组间共享是不同群组的高级智能体通信,从而形成对环境的全局感知;组内共享是群组内的高级智能体将获取到的信息与低级智能体进行共享,如图2-6所示。
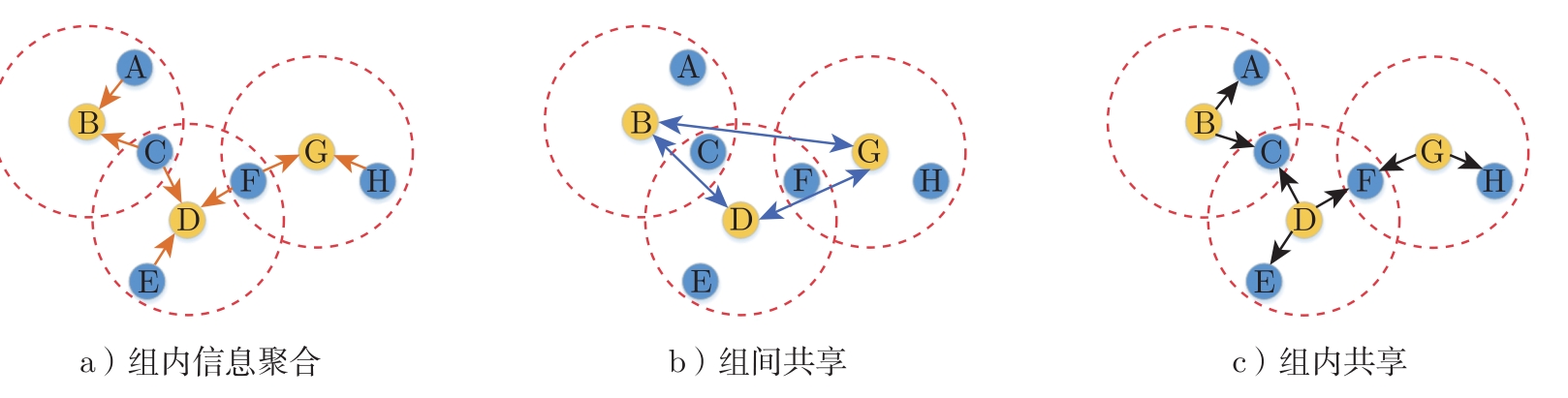
图2-6 LSC通信的3个步骤
通过上面的分析可以发现:完全连接的结构和星形结构可以确保所有智能体之间都进行信息共享,但是由于智能体之间的状态、消息存在差异性,对于协作任务的重要程度也有所不同,这种全通信可能会引入大量冗余的信息,从而造成通信带宽与计算资源浪费,使得提取有价值的消息困难,影响通信效率,增大通信成本;树状结构和相邻结构将通信对象限制为邻居,可以避免单点瓶颈问题,但为了实现全部可访问性需进行多轮通信,并且有限的通信可能会限制协作范围;分层结构基于群组的分层通信结构,在保证通信的全面性的同时降低通信成本。
[1] PANAIT L, LUKE S. Cooperative multi-agent learning: the state of the art[J]. Autonomous agents and multi-agent systems, 2005, 11(3): 387-434.
[2] MATARIC M J. Using communication to reduce locality in distributed multiagent learning[J]. Journal of experimental and theoretical artificial intelligence, 1998, 10(3): 357-369.
[3] DING Z, HUANG T, LU Z. Learning individually inferred communication for multi-agent cooperation[J]. Advances in Neural Information Processing Systems, 2020, 33: 22069-22079.
[4] DAS A, GERVET T, ROMOFF J, et al. TarMAC:targeted multi-agent communication[C]//CHAUDHURI K, SALAKHUTDINOV R. Proceedings of Machine Learning Research: volume 97 Proceedings of the 36th International Conference on Machine Learning. PMLR, 2019: 1538-1546.
[5] JIM K C, GILES C L. Talking helps: evolving communicating agents for the predator-prey pursuit problem[J]. Artificial Life, 2000, 6(3): 237-254.
[6] TAN M. Multi-agent reinforcement learning: independent vs. cooperative agents[C]//Proceedings of the tenth international conference on machine learning. Amherst: Morgan Kaufmann Publishers Inc., 1993: 330-337.
[7] KIM D, MOON S, HOSTALLERO D, et al. Learning to schedule communication in multiagent reinforcement learning[Z]. 2019.
[8] ZHANG S Q, ZHANG Q, LIN J. Efficient communication in multi-agent reinforcement learning via variance based control[J]. Advances in Neural Information Processing Systems, 2019, 32: 3235-3244.
[9] HADELI, VALCKENAERS P, KOLLINGBAUM M, et al. Multi-agent coordination and control using stigmergy[J]. Computers in Industry, 2004, 53(1): 75-96.
[10] CORREIA L, SEBASTIãO A M, SANTANA P. On the role of stigmergy in cognition[J]. Progress in Artificial Intelligence, 2017, 6: 1-8.
[11] MASOUMI B, MEYBODI M R. Speeding up learning automata based multi agent systems using the concepts of stigmergy and entropy[J]. Expert Systems with Applications, 2011, 38(7): 8105-8118.
[12] JOHANSSON R, SAFFIOTTI A. Navigating by stigmergy: a realization on an RFID floor for minimalistic robots[C]//IEEE International Conference on Robotics and Automation. Kobe, 2009: 245-252.
[13] HEYLIGHEN F. Stigmergy as a universal coordination mechanism i: Definition and components[J]. Cognitive Systems Research, 2016, 38: 4-13.
[14] DORIGO M, BIRATTARI M, STüTZLE T. Ant colony optimization[J]. IEEE Computational Intelligence Magazine, 2007, 1(4): 28-39.
[15] DORIGO M, MANIEZZO V, COLORNI A. Ant system: optimization by a colony of cooperating agents[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 1996, 26(1): 29-41.
[16] SCHOONDERWOERD R, HOLLAND O E, BRUTEN J L, et al. Ant-based load balancing in telecommunications networks[J]. Adaptive behavior, 1997, 5(2): 169-207.
[17] KANAMORI R, TAKAHASHI J, ITO T. Evaluation of anticipatory stigmergy strategies for traffic management[C]//2012 IEEE Vehicular Networking Conference (VNC). New York:IEEE, 2012: 33-39.
[18] TANG Q, XU Z, YU F, et al. Dynamic target searching and tracking with swarm robots based on stigmergy mechanism[J]. Robotics and Autonomous Systems, 2019, 120: 103251.
[19] DUTECH A, CHARPILLET F, ARAS R. Stigmergy in multiagent reinforcement learning[Z]. 2004.
[20] MONEKOSSO N, REMAGNINO P. Phe-q: a pheromone based q-learning[C]//Australian Joint Conference on Artificial Intelligence. Berlin: Springer, 2001: 345-355.
[21] MONEKOSSO N, REMAGNINO P. The analysis and performance evaluation of the pheromone-q-learning algorithm[J]. Expert Systems, 2004, 21(2): 80-91.
[22] HORLING B, LESSER V. A survey of multi-agent organizational paradigms[J]. The Knowledge engineering review, 2004, 19(4): 281-316.
[23] BONABEAU E, THERAULAZ G, DORIGO M, et al. Swarm intelligence: from natural to artificial systems: number 1[M]. Oxford: Oxford university press, 1999.
[24] RUI W, YAN L, GANGQIANG Y, et al. Swarm intelligence for the self-organization of wireless sensor network[C]//2006 IEEE International Conference on Evolutionary Computation. New York: IEEE, 2006: 838-842.
[25] SEN S, WEISS G. Learning in multiagent systems[J]. Multiagent systems: A modern approach to distributed artificial intelligence, 1999: 259-298.
[26] SHENG J, WANG X, JIN B, et al. Learning structured communication for multi-agent reinforcement learning[Z]. 2020.
[27] FOERSTER J, ASSAEL I A, DE FREITAS N, et al. Learning to communicate with deep multi-agent reinforcement learning[J]. Advances in neural information processing systems, 2016, 29: 2145-2153.
[28] SUKHBAATAR S, SZLAM A, FERGUS R. Learning multiagent communication with back-propagation[J]. Advances in Neural Information Processing Systems, 2016, 29: 2252-2260.
[29] SINGH A, JAIN T, SUKHBAATAR S. Learning when to communicate at scale in multiagent cooperative and competitive tasks[Z]. 2018.
[30] JIANG J, LU Z. Learning attentional communication for multi-agent cooperation[Z]. 2018.
[31] JIANG J, DUN C, HUANG T, et al. Graph convolutional reinforcement learning[Z]. 2018.