
下载掌阅APP,畅读海量书库
立即打开



一个CPU对本地缓存中的数据进行修改的时候,会先把本地数据的状态改成M,接着向其他的CPU发送Invalidate消息,收到其他CPU的Acknowledge应答才完成数据修改,整体流程如图3-15所示。
MESI协议虽然实现了CPU缓存之间的数据强一致协议,但也带来了重大的性能问题。如果严格遵循MESI协议,那么一个CPU修改数据时,其他CPU必须停下当前任务去处理缓存消息,这会大大降低CPU的运作效率。因此,在实际硬件实现上,工程师采用了弱一致性的方案,引入了异步处理的机制。在数据修改的时候采用存储缓冲(Store Buffer)机制,在数据失效时采用失效队列(Invalidate Queue)机制,如图3-16所示。
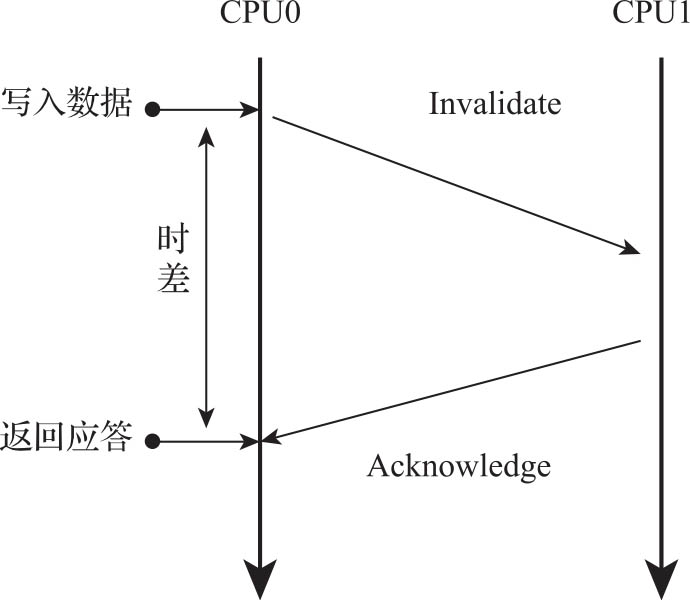
图3-15 CPU缓存数据修改消息传播机制
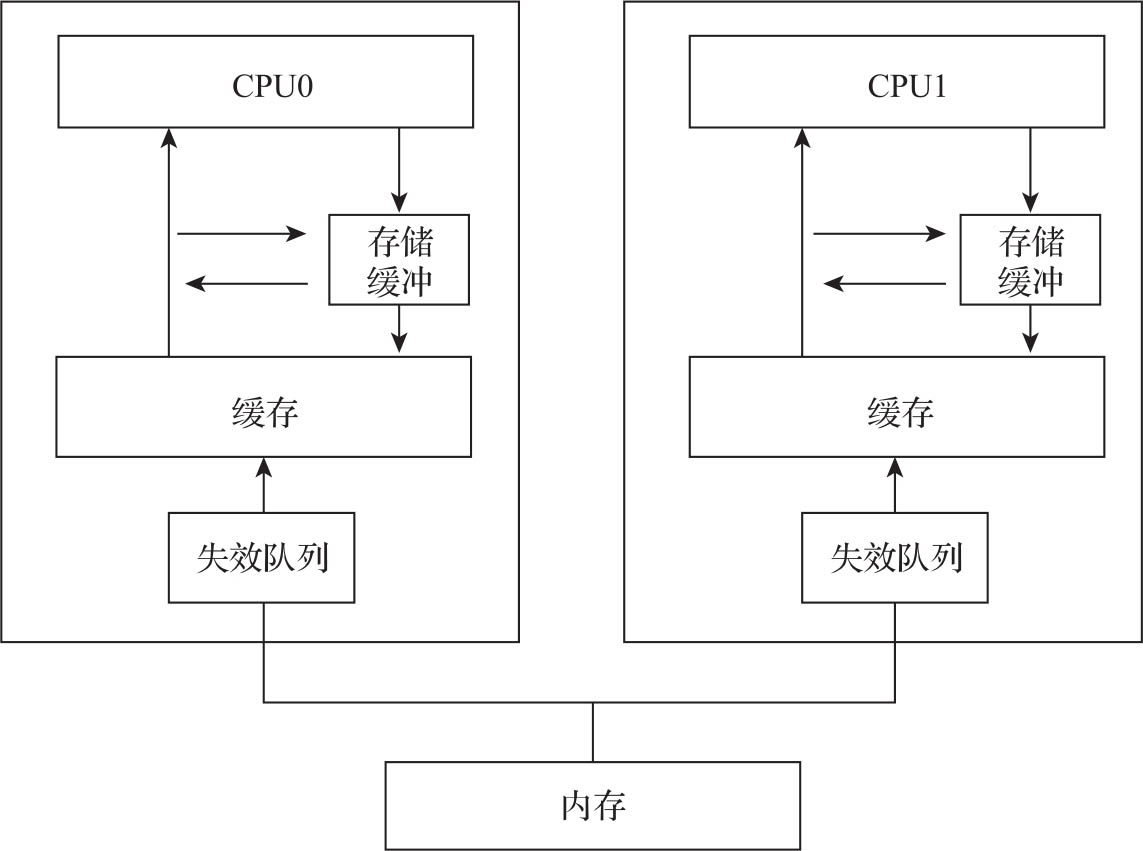
图3-16 存储缓冲与失效队列
在对数据修改时,CPU先会把修改的数据写入存储缓冲中,然后发送数据失效消息。在收到其他CPU的响应消息之后,再把存储缓冲里面的数据写入缓存里。在读数据时,CPU会优先从存储缓冲中读取数据(这个机制叫作存储转发),如果存储缓冲中不存在,才从缓存读取。这样一来,CPU在修改数据时就不用等待其他CPU的响应了,同时可以确保CPU内的数据一致性。但是如果CPU修改多个数据时,会破坏多个数据修改的时序性。
失效队列是用来存放缓存总线发送过来数据失效的消息的。CPU在收到数据失效消息后,先将消息放入到失效队列中,立即返回应答消息。在发送完应答消息后,CPU会检查失效队列中有无该缓存行的失效消息,如果有的话这个时候才处理失效消息。失效队列机制虽然能加快失效消息的响应速度,但是也带来了全局顺序性问题,这与存储缓冲带来的全局一致性问题类似。
代码清单3-10是一个简单的例子,用来演示存储缓冲与失效队列带来的数据一致性问题。
代码清单3-10 CPU缓存带来的数据一致性问题

CPU0执行update方法,CPU1执行read方法,如果在执行之前CPU缓存中已经存在了部分数据,例如CPU0缓存了b,因为是独占的,所以b的状态是E,CPU1缓存了a,因为是独占的,所以a的状态也是E,如图3-17所示。
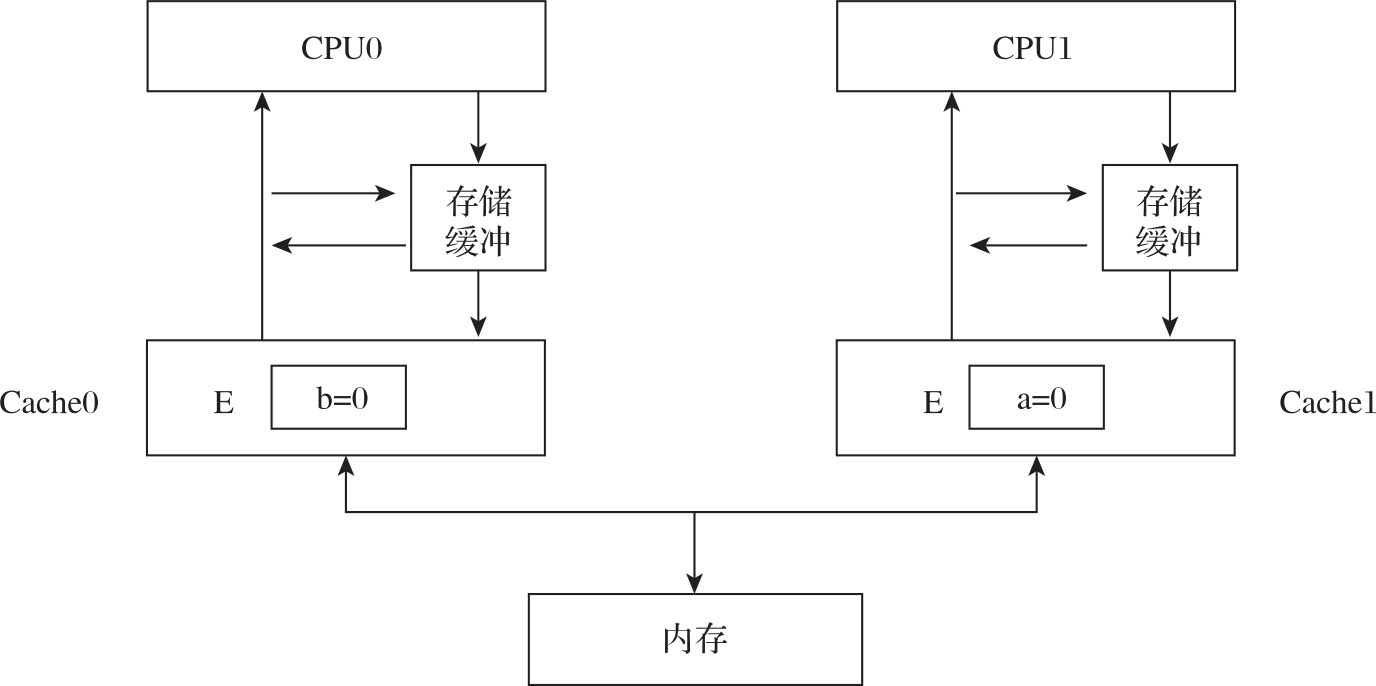
图3-17 CPU缓存导致数据全局一致性丢失
CPU0执行a=1,因为a不在CPU0的缓存中,直接将a=1写到存储缓冲,同时发送一个失效消息,通知CPU1来更新数据。CPU1执行while(b==1),因为b不在缓存中,所以CPU1发送一个数据读取请求。CPU0收到CPU1读取b的消息后,会将对应缓存行的状态改成S。CPU1因为主动发起读取b的请求,所以先知道b变成1,于是将b=1放到缓存中,同时结束while循环。因为a修改的消息还在CPU1的失效队列中没来得及处理,所以CPU1看到的a还是0,导致assert(a==1)抛出异常。从业务逻辑上来说,a的修改先于b的修改,但在CPU1是先感知到了b的修改,没有看到a的修改。
为了修复存储缓冲与失效队列造成数据修改的全局一致性问题,硬件工程师引入了内存屏障的机制。
内存屏障分为写屏障(Store Barrier)与读屏障(Load Barrier)。写屏障会强制刷新存储缓存,会将存储缓存中的数据同步到其他CPU缓存中。读屏障会强制CPU立刻处理失效队列中的所有消息,消息队列中所有要失效的数据会被依次失效。
首先,我们对代码清单3-10例子中的代码稍作调整,如代码清单3-11所示。在a、b两行代码之间,增加一行内存写屏障的代码,确保CPU0的存储缓存中的消息能够及时传递到其他CPU。同时读取a之前也会加上一个内存读屏障,确保CPU1的失效队列中的消息能够被及时处理。
代码清单3-11 CPU内存读写屏障

这个时候在CPU1里面a的状态是I,再读取a的时候能够及时从主内存进行数据同步。通过写屏障与读屏障的保障机制确保a、b修改的全局一致性。
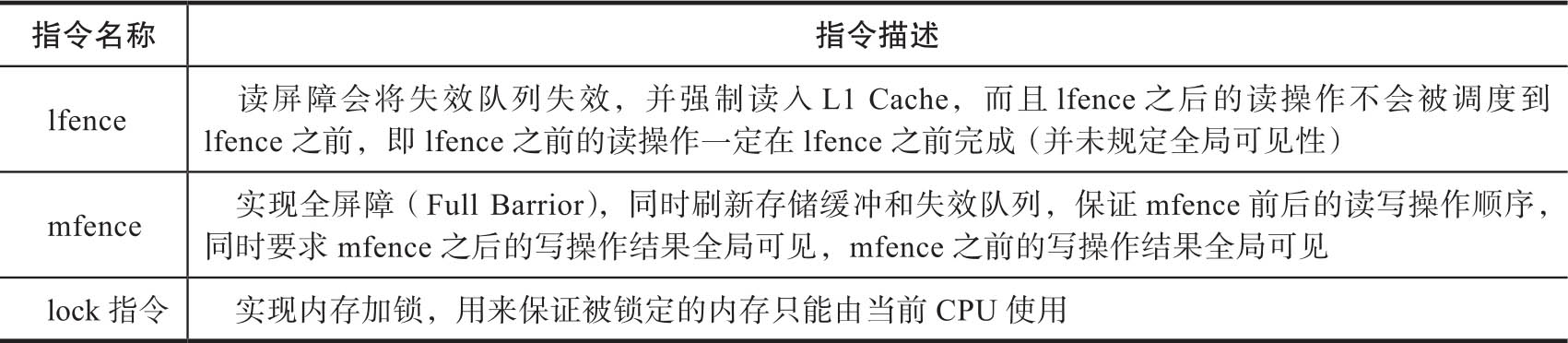
内存屏障需要和CPU缓存直接打交道,需要硬件CPU指令支持。不同的CPU处理器对内存屏障的支持指令也不相同。下面以Intel系列CPU来详细讲解内存屏障的实现方式。Intel处理器提供了4种内存屏障指令,详细信息如表3-7所示。
表3-7 4种内存屏障指令

(续)
Linux基于汇编宏命令构建了3种基础的内存屏障,如代码清单3-12所示。
代码清单3-12 Linux内存屏障指令

从CPU的角度来说,一般就是数据读指令与数据写指令,两条指令总共会出现以下4种组合场景,如表3-8所示。
表3-8 读写指令组合场景

在JVM的源码中,OrderAccess类定义了内存屏障功能,具体实现如代码清单3-13所示。
代码清单3-13 JVM内存屏障实现

内存屏障在不同的操作系统与处理器上有不同的实现,以Linux x86处理器为例,具体实现如代码清单3-14所示。
代码清单3-14 JVM的Linux x86内存屏障实现

从上面代码可以发现,loadload、storestore、loadstore、acquire、release等函数都是调用compiler_barrier函数来实现的。compiler_barrier函数主要有两个功能:一是静止编译器对代码进行编译重排,二是强制使CPU本地缓存失效。fence函数首先是将当前CPU对应缓存的内容刷新到内存,并使其他CPU对应的缓存失效。另外提供了有序的指令,让操作范围无法越过这个内存屏障。接着把CPU本地的缓存直接失效,强制去主内存中读取数据。