
下载掌阅APP,畅读海量书库
立即打开



1.数据结构
可以用来进行图计算的数据结构有很多种。我们先回顾一下数据结构的分类树。数据结构分为原始数据结构和非原始数据结构,如图3-6所示。
原始数据结构是构造用户定义的数据结构的基础,在不同的编程语言中,对于原始数据结构的定义各不相同,如短整型(Short)、整数(Int)、无符号整数(Unsigned Int)、浮点数(Float、Double)、指针(Pointer)、字符(Char)、字符串(String)、布尔类型(Boolean)等,这里不再赘述,有兴趣的读者可以查询相关的工具书和资料。本书关注的更多是用户系统(图计算框架或图数据库)定义的线性(Linear)或非线性(Non-liniear)数据结构。
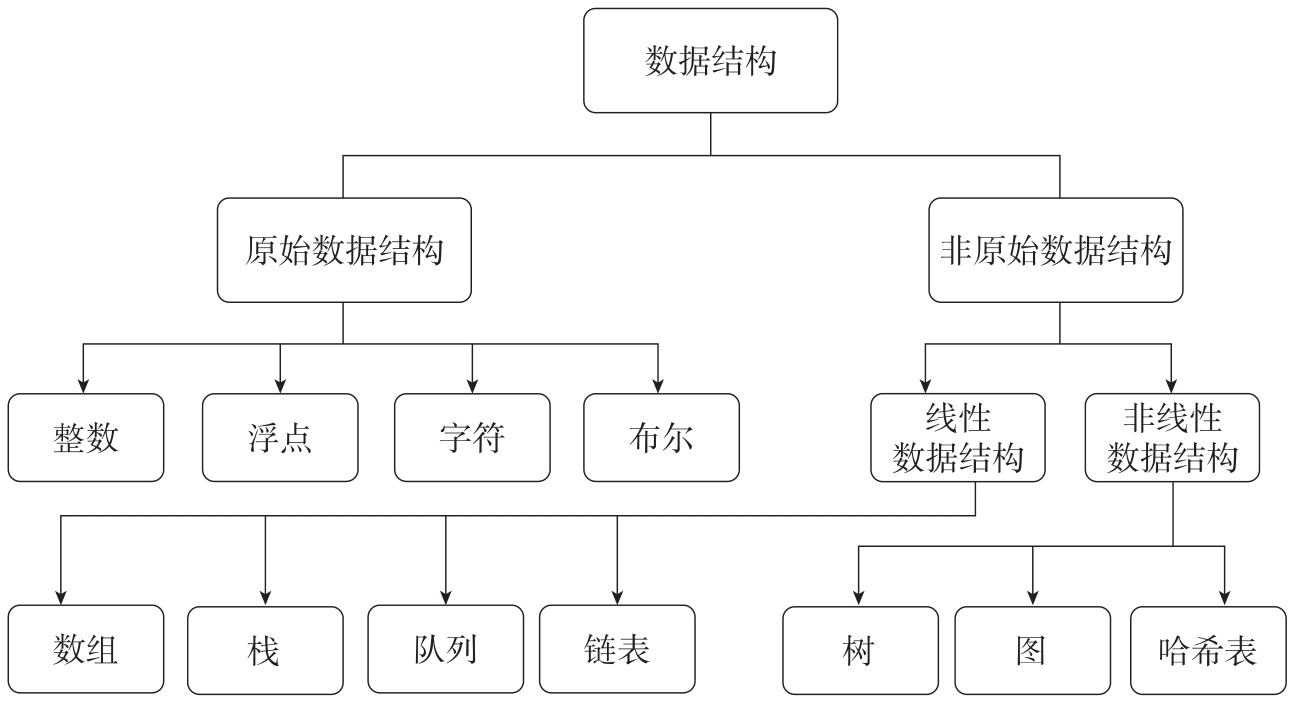
图3-6 数据结构的分类示意图
在不考虑效率的前提下,几乎任何原始数据结构都可以组合完成任何计算,然而它们之间的效率差距是指数级的。如图3-6所示,图数据结构被认为是一种复合型、非线性、高维的数据结构。可以用来构造图数据结构的原始或非原始数据结构有很多种,例如常见的数组(Array)、栈(Stack)、队列(Queue)、链表(Linked List)、向量(Vector)、矩阵(Matrix)、哈希表(Hash Table)、Map、HashMap、树(Tree)、图(Graph)等。
在具体的图计算场景中,使用哪些数据结构需要具体分析,主要考虑以下两个维度:
❑ 效率及算法复杂度。
❑ 读、写需求差异。
以上两个维度经常交织在一起,例如,只读的条件下意味着数据是静态的,显而易见,连续的内存数据结构可以实现最高效的数据吞吐及处理效率。反之,如果数据是动态的,数据结构就需要支持增删改查操作,就需要更复杂的存储逻辑,也意味着计算效率会降低。我们通常说的用空间换时间就包含这种情况。
这里再次重申,在不同的上下文中,图计算的含义可能大相径庭,真正的图数据库是不可能只存不算的,那么它一定需要包含图计算引擎,而数据库级别的图计算引擎毫无疑问需要支持动态的、不断变化的数据;而学术界实现的图计算框架则大多只考虑静态数据(例如Spark的图计算实现方式是需要把数据加载进内存数据结构,一旦进入之后,数据就是静态、不变的)。这两种图计算所适用的场景和各自能完成的工作差异巨大,本书所涉及的内容属于前者—图数据库,对于后者,有兴趣了解的读者可以参考GAP Benchmark
 及其他图计算框架的实现逻辑。至于那些号称是图数据库,但是却没有处理动态数据的能力,还需要和第三方图计算引擎、图挖掘引擎结合的产品,不外乎是挂羊头卖狗肉。
及其他图计算框架的实现逻辑。至于那些号称是图数据库,但是却没有处理动态数据的能力,还需要和第三方图计算引擎、图挖掘引擎结合的产品,不外乎是挂羊头卖狗肉。
图上大体包含以下3种类型的数据:
1)顶点,也被称作点、节点。顶点可以有多个属性,边也如此。有鉴于此,某个类型的顶点的集合可以看作传统数据库中的一张表,而顶点间的基于路径或属性的关联操作则可看作传统关系型数据库中的表连接(Table-join)操作,区别在于图上的连接操作的效率指数级地高于SQL,原因是图计算的复杂度指数级地低于表连接。用最通俗的数学语言来对比,就是表连接经常以乘法的复杂度出现,而图计算则以加法的形式得以实现,也就是说,如果有多张表关联,SQL的复杂度可能是 O ( ABC ……),但是图计算的复杂度则是 O ( A + B + C +……)。
2)边,也被称作关系。一般情况下,一条边会连接两个顶点。如果箭头方向代表连接两个点的边的方向,那么无向边通常需要使用两条边来表达,例如将点 A 和点 B 之间的无向边表达为 A → B + A ← B ,即一条由 A 指向 B 的边,与另一条从 B 出发反向到 A 的边。之所以要表达反向边,是因为如果不存在从 B 到 A 的(反向)边,那么在图上(路径)查询或遍历的时候,将不会找到任何从 B 出发可以直接到达 A 的边,也就意味着图的连通度受到了破坏,或者说数据结构的设计和表达没有100%反映出真实的顶点间的网络连接情况。事实上,某些图数据库或图计算产品存在这种为了节省50%的存储空间而忽略反向边的问题,那么,很多图查询的结果都将是错误的。而那种特殊类型的可以关联多个(≥3)顶点的边,一般都被拆解为两两顶点相连的多条边来表达。需要注意的是,图论当中的另一个概念是单边图与多边图。任意两个顶点间如果存在多条边,且多条边的类型相同的情况下,即为多边图,而单边图只支持两点间最多一条边或每一类Schema只支持最多一条边,超过的情况则需要更为复杂的数据建模方式或额外的数据结构来解决。图3-7形象地展示了两者之间的差异:当两个账户顶点中有多笔交易的时候,单边图的构图方式在存储与计算复杂度方面需要约3倍的存储空间,以及指数级更高的运算复杂度来进行多层交易关系的穿透。也就是说,当在多边图上需要穿透 k 层的时候,在单边图上则要穿透2 k 层,而在每层的计算复杂度相当的情况下,按照乘积的关系,复杂度将会指数级增加。
3)路径,表达的是一组相连的顶点与边的组合。多条路径可以构成一张网络,也称作子图,多张子图的全集合则构成了一张完整的图数据集,我们称为“全图”。很显然,点和边这两大元数据的排列、组合就可以表达图上的全部数据模型—各种各样的点、边、路径、子图。
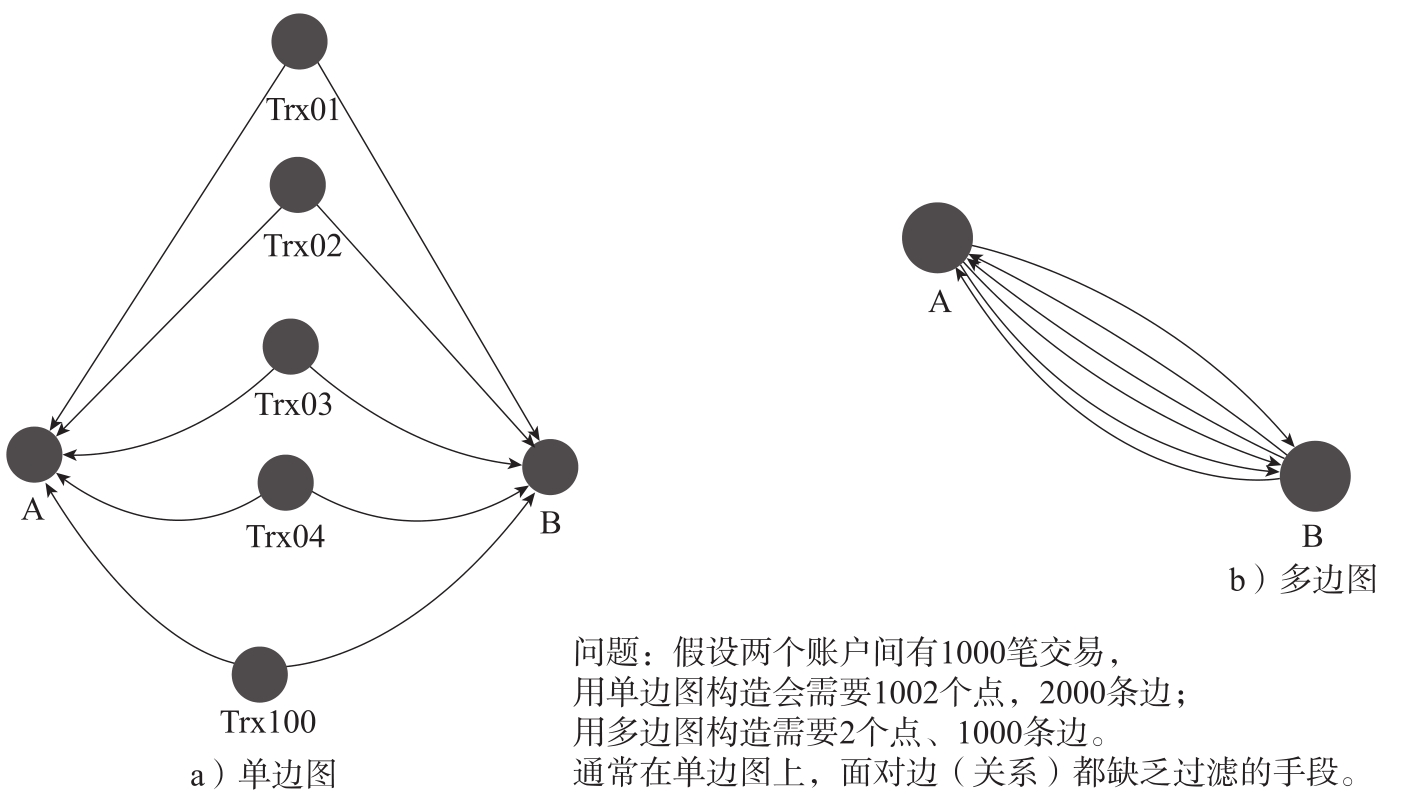
图3-7 单边图与多边图
传统意义上,用来表达图的数据结构有3类:相邻链表(Adjacency List)、相邻矩阵(Adjacency Matrix)和关联矩阵(Incidence Matrix)。
相邻链表以链表为基础数据结构来表达图数据的关联关系,如图3-8所示,左侧的有向图(注意带权重的边)用右侧的相邻链表表达,它包含了第一层的“数组或向量”,其中每个元素对应图中的一个顶点,第二层的数据结构则是每个顶点的出边所直接关联的顶点构成的链表。
注意,图3-8中右侧的相邻链表中只表达了有向图中的单向边—出边(出方向的边),如果从顶点4出发,只能抵达顶点5,却无从知道顶点3可以抵达顶点4,除非用全图遍历的方式搜索,但那样的话效率会相当低下。当然,解决这一问题的另一种方式是在链表中也插入反向边和顶点,类似于上面提及的反向边的概念,可以用额外的字段来表达边的方向。
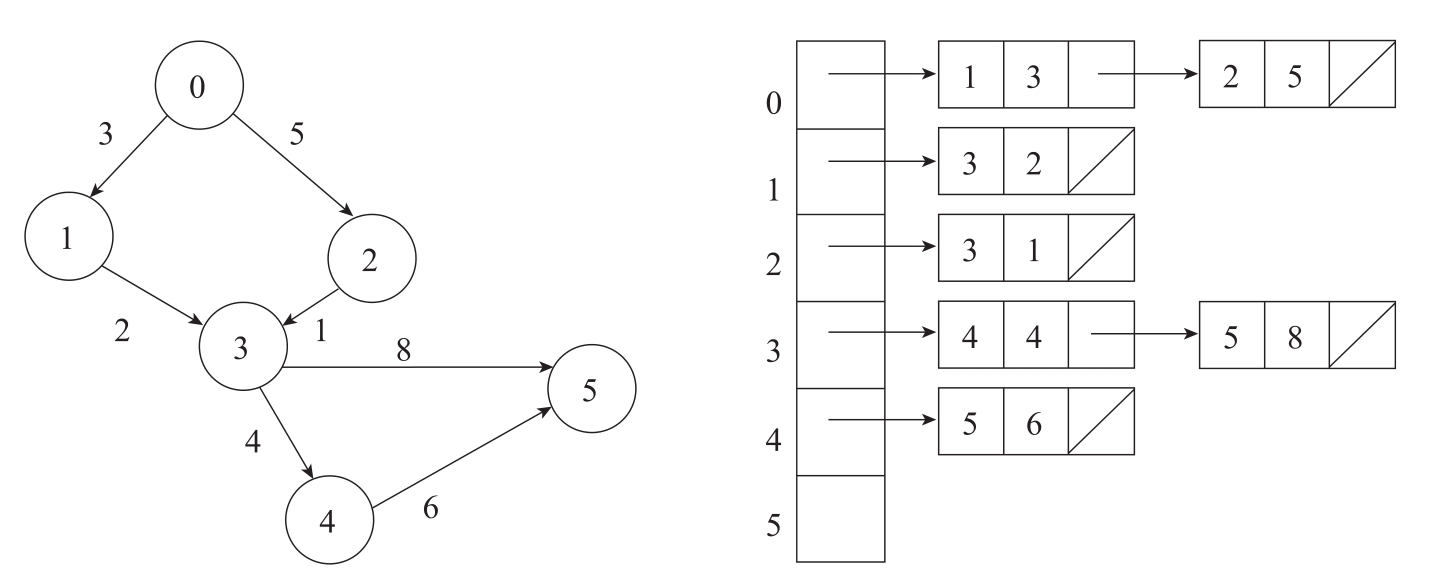
图3-8 用相邻链表(右)来表达单边有向图(左)
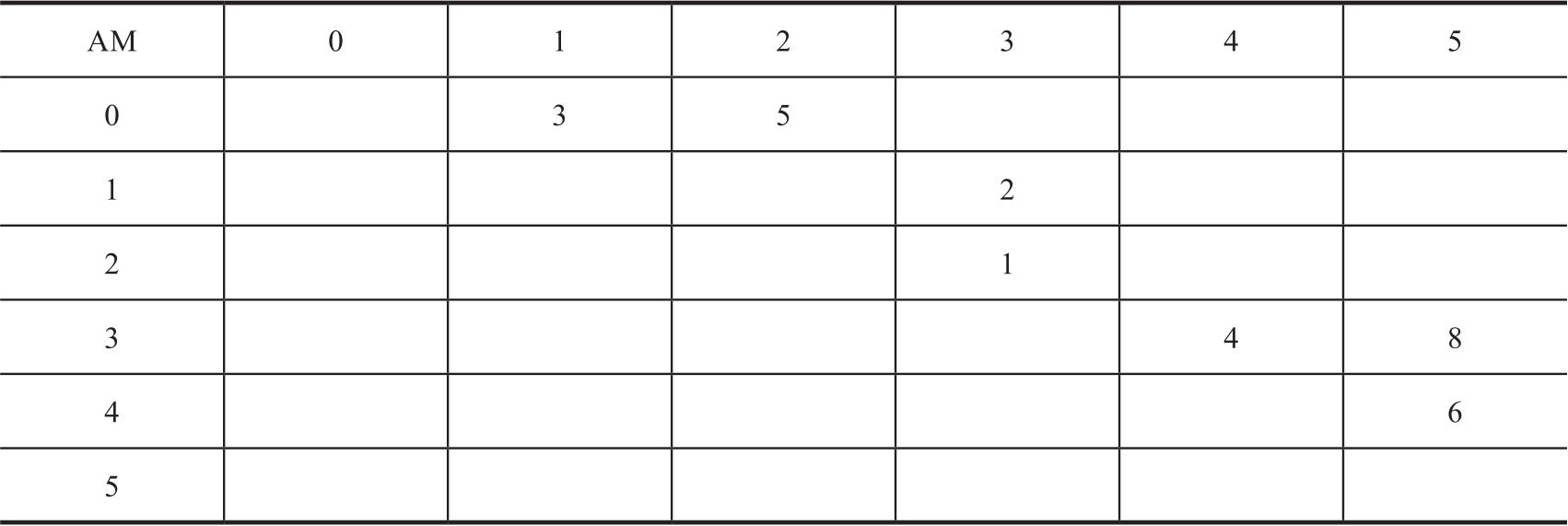
相邻矩阵是一个二维的矩阵,我们可以用一个二维数组的数据结构来表达,其中的每个元素都代表图中是否存在两个顶点之间的一条边。如表3-2中,用相邻矩阵AM来表达图3-8中的有向图,矩阵中的元素代表边,每个元素对应的行、列中的顶点分别是边的起点和终点,矩阵是6×6的,但其中只有7个元素(7条边)是被赋值的。很显然,这是一个相当稀疏的矩阵,占满率只有(7/36)<20%,它所需要的最小存储空间则为36字节(假设每个字节可以表达其所对应的边的权重)。如果是一张有100万顶点的图,其所需的存储空间至少为0.9TB,相比于工业界中动辄亿万量级的图,这还只是属于规模仅其百万分之一的小图所需的存储空间。
表3-2 用相邻矩阵来表达有向图
也许读者会质疑以上相邻矩阵的存储空间的估算被夸大了,那么我们来探讨一下:如果每个矩阵中的元素可以用1个比特位(bit)来表达,那么100万顶点的全图存储空间可以降低到约100GB。然而,我们是假设用1个字节来表达边的权重,如果这个权重的数值超过256,我们或许需要2个字节、4个字节甚至8个字节来进行存储,如果边还有其他多个属性,那么对于存储空间就会有更大的甚至不可想象的需求。现代的GPU是以善于处理矩阵运算而闻名的,不过通常二维矩阵的大小要求小于32K(32768)个顶点。这是可以理解的,因为32K个顶点矩阵的内存存储空间已经达到1GB以上了,这已经占到了GPU内存的25%~50%。换句话说,GPU并不适合用于大图上的运算,除非使用极其复杂的图上的MapReduce方式对大图进行切割、分片来实现分而治之、串行的或并发的处理方式。但是这种分片、切图的处理效率会高吗?此外,GPU也无法替代CPU来进行复杂的过滤、剪枝等查询,因为这些属于通用计算的范畴,并不适合用矩阵运算来实现。
关联矩阵是一种典型的逻辑矩阵,它可以把两种不同的图中的元数据类型顶点和边关联在一起。例如每一行的行首对应顶点,每一列的列首对应边。以前面的有向图为例,我们可以设计一个6×7的二维带权重的关联矩阵,如表3-3所示。
表3-3 关联矩阵示意图
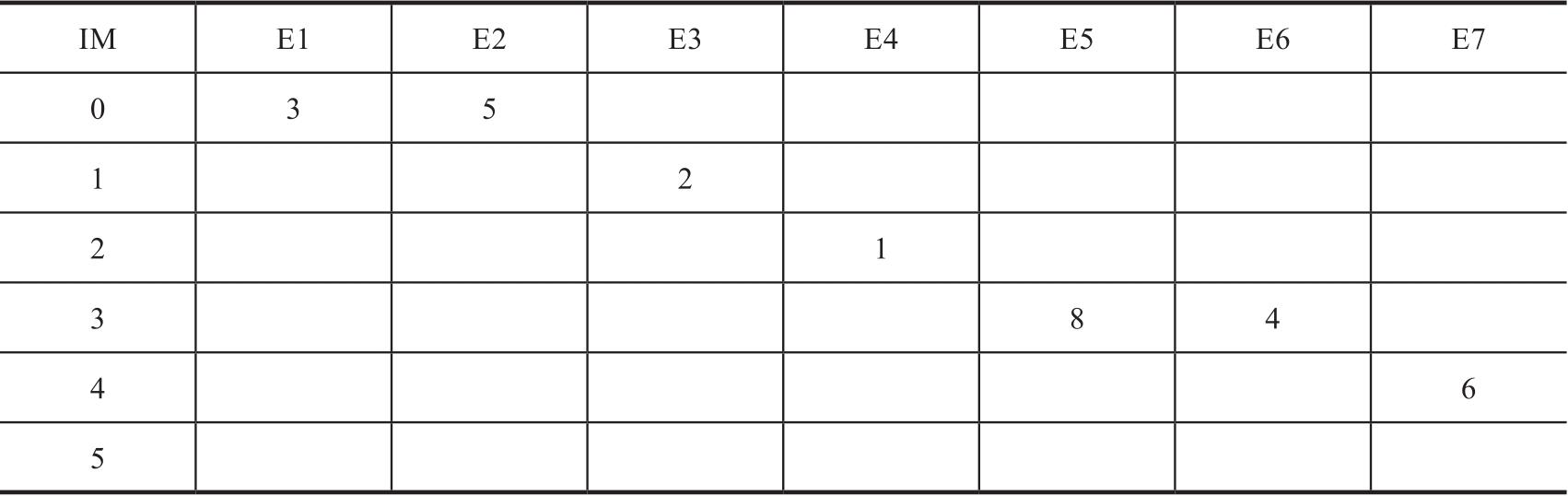
表3-3中的二维矩阵仅能表达无向图或有向图中的单向图,如果要表达反向边或者属性,这种数据结构显然是有缺陷的。
事实上,真正工业界的图数据库极少用以上3种数据结构,因为它们都无法解决真实场景中图数据库必须要面对的几个问题:
❑ 无法表达点、边的属性。
❑ 无法高效利用存储空间(降低存储量)。
❑ 无法进行高性能(低延迟)的计算。
❑ 无法支持动态的增删改查。
❑ 无法支持复杂查询的高并发。
综合以上几点原因,我们可以对上面提及的各种数据结构进行改造,或许就可以更好地支持真实世界的图计算场景。下面结合计算效率来评估与设计图计算所需的数据结构。
2.计算效率
存储低效性或许是相邻矩阵或关联矩阵等数据结构的最大缺点,尽管它有着 O (1)的访问时间复杂度。例如通过数组下标定位任何一条边或顶点所需的时间是恒定的 O (1),相比而言,相邻链表对于存储空间的需求要小得多,在工业界中的应用也更为广泛。例如Meta的社交图谱(其底层的技术架构代码为Tao/Dragon)采用的就是相邻链表的方式,链表中每个顶点表示一个人,而每个顶点下的链表表示这个人的朋友或关注者。
这种设计方式很容易被理解,但是如果遇到热点问题,例如如果一个顶点有1万个邻居,那么链表的长度有10000步,遍历这个链表的时间复杂度为 O (10000)。在链表上的增删改查操作都是一样的复杂度,更准确地说,平均复杂度为 O (5000)。另一个角度来看,链表的并发能力很糟糕,你无法对于一个链表进行并发(写)操作。事实上,Meta的架构中限定了一个用户的朋友不能超过6000人,微信中也有类似的对朋友人数的限制。
现在,让我们思考一个方法,设计一种数据结构可以平衡以下两件事情。
❑ 存储空间:相对可控的、占用更小的存储空间来存放更大量的数据。
❑ 访问速度:低访问延迟,并且对于并发访问友好。
在存储空间维度,我们要尽量避免使用对于稀疏的图或网络来说利用率低下的数据结构,因为大量的空数据占用了大量的空闲空间。以相邻矩阵为例,它只适合用于拓扑结构非常密集的图,如全连通图(所谓全连通指的是图中任意两个顶点都直接关联)。前面提到的有向图,如果全部连通,则至少存在30条有向边(2×6×5/2),如果还存在自己指向自己的边,则存在36条边,那么此时相邻矩阵的存储空间是100%被利用的。
然而,在实际应用场景中,绝大多数的图都是非常稀疏的。如果我们设定图的密度=(边数/全连通图的边数)×100%,大多数图的密度都远低于5%,因此相邻矩阵就显得很低效了。另外,真实世界的图大多是多边图,即每对顶点间可能存在多条边。例如交易网络中的多笔转账关系,这种多边图不适合采用矩阵数据结构来表达(或者说矩阵只适合作为第一层数据结构,它还需要指向其他外部数据结构来表达多边的问题)。
相比于相邻矩阵,相邻链表在存储空间上是大幅节省的,然而相邻链表的数据结构存在访问延迟大、并发访问不友好等问题,因此突破点应该在于如何设计可以支持高并发、低延迟访问的数据结构。在这里,我们尝试设计并采用一种新的数据结构,它具有如下特点:
❑ 访问图中任一顶点的时间复杂度为 O (1)。
❑ 访问图中任意边的时间复杂度为 O (2)或 O (1)。
以上时间复杂度假设可以通过某种哈希函数来实现,最简单的例如通过点或边的ID对应的数组下标来访问具体的点、边元素来实现。顶点定位的时间复杂度为 O (1),边仅需定位出发点(Out-node)和到达点(In-node),时间复杂度为 O (2)。在C++中,以上特点的数据结构最简单的实现方式是采用向量数组(Array of Vector)来表达点和边:

动态向量数组可以实现极低的访问延迟,并且存储空间浪费很少,但并不能解决以下几个问题:
❑ 并发访问支持。
❑ 数据删除时的额外代价(如存储空白空间回填等)。
在工业界中,典型的高性能哈希表的实现有谷歌的SparseHash库,它实现了一种叫作dense_hash_map的哈希表。在C++标准11中实现了unordered_map,它是一种锁链式的哈希表,通过牺牲一定的存储空间来获取快速寻址能力。但是以上两种实现的问题是,它们都没有和底层的硬件(CPU内核)并发算力同步的扩张能力,换句话说是一种单线程哈希表实现,任何时刻只有单读或单写进程占据全部的表资源,这或许可以算作对底层的计算资源的一种浪费。
图(数据集)的存储最主要是处理两种基础(元)数据结构:顶点和边,其他所有的数据结构都是在这两者的基础上衍生而来的,例如各类索引、中间、临时的数据结构,用来实现查询与计算加速等,以及那些需要异构返回的数据结构,如路径、子图等。
我们来分析一下顶点和边的数据结构及其适合的存储方式。
❑ 顶点。每个顶点可以看作内部元素有着某种规则排列的数组,多个顶点的组合就是一个二维数组。如果考虑到顶点的动态变化(增删改查等涉及读、更新、插入等操作)的需求,向量数组是一种可能的方式。
❑ 边。边的数据结构较顶点更为复杂,因为边不仅有一个唯一标识ID,还有起点、终点的ID,边的方向以及其他可能的属性,如权重、时间戳等。显然,用二维数组也可以满足边的存储,剩下需要关注的问题是效率,如存储空间利用率、访问效率、索引数据结构的效率等。
支持点、边结合的数据类型如果是完全静态的,也就是说点或边的数量不会变化,不会增加、减少或更新,也不会发生它们各自属性的变化,那么映射到文件系统上的数据结构就可以作为图存储的核心数据结构。如果真的是这样的话,我们可以复用传统数据库的存储引擎,例如MySQL的InnoDB或MyISAM(ISAM的变种)引擎,更有甚者,只使用磁盘文件就可以支持静态的图数据库。
然而,效率在大多数情况下是不可或缺的。前面“静态”数据的假设在商业化场景中是极少成立的,因为无论是交易系统还是业务管理系统,数据都是动态的、流动的。任何贴近真实业务场景的系统都需要支持对数据(存储引擎)的更新操作。
因此,图数据及其存储与计算引擎的架构设计中有一对重要的概念:非原生图与原生图。所谓非原生图是指它的存储与计算是以传统的表结构(行或列数据库)的方式进行的;而原生图则采用更能直接反映关联关系的方式构造而成,也因此会有更高效的存储和计算效率。
如果用关系型数据库MySQL、宽列数据库HBase或二维的KV数据库Cassandra来作为底层存储引擎,也可以把点、边数据以表(或列表)的方式存储起来,它们在进行图查询与计算时的逻辑大体如图3-9所示。举个例子,查询某位员工隶属于多少个部门,返回该员工姓名、员工编号、部门名称、部门编号等信息。用关系型数据库来表达这个简单的查询,要涉及3张表:员工表、部门表和员工ID-部门ID对照表。
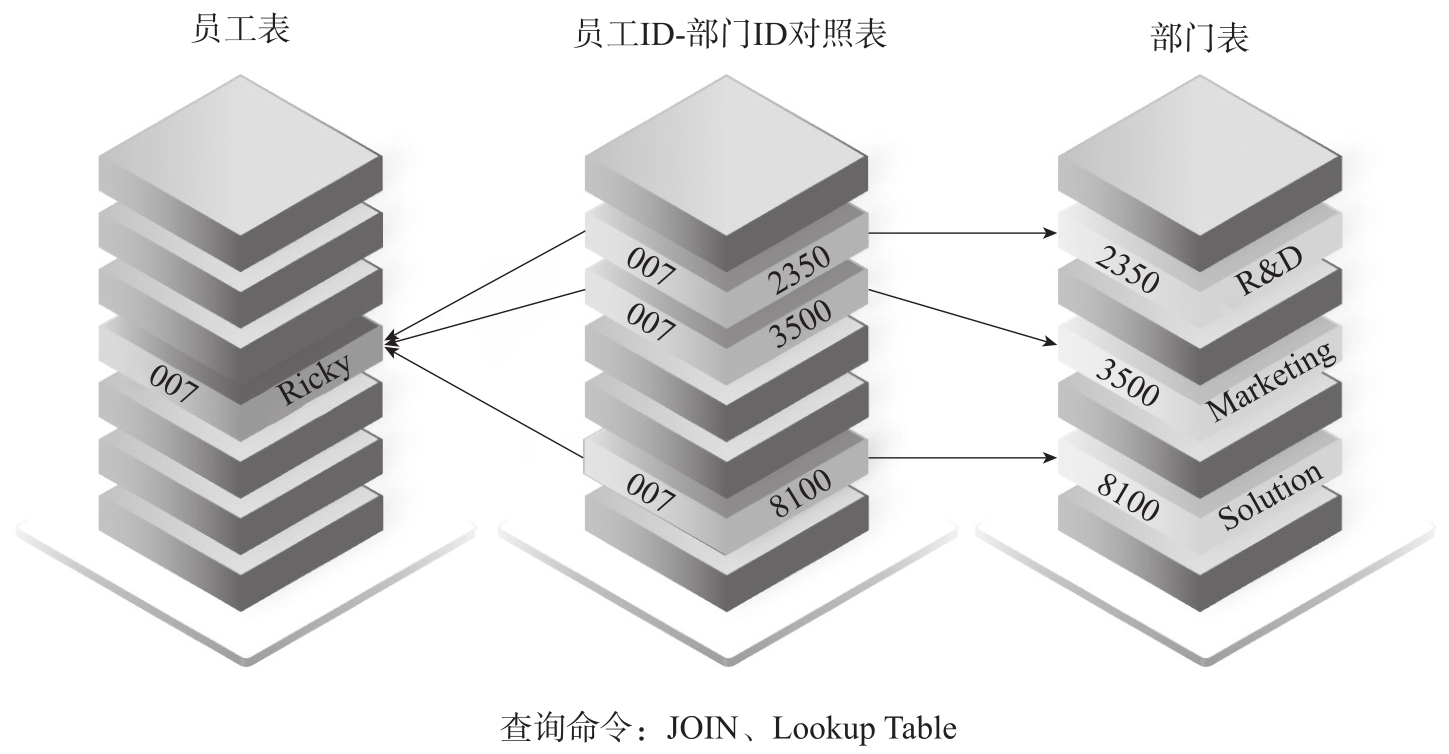
图3-9 非原生图(关系型、SQL类数据库)存储查询模式示意图
整个查询过程分为如下几步:
①在员工表中,定位007号员工。
②在员工ID-部门ID对照表中,定位ID=007所对应的全部部门ID。
③在部门表中,定位步骤②中的全部ID所对应的部门名称。
④组装以上①~③步骤中的全部信息,返回。
前面介绍过数据库存储加速的概念,上面每个步骤的时间复杂度如表3-4所示。
表3-4 SQL查询(时间)复杂度
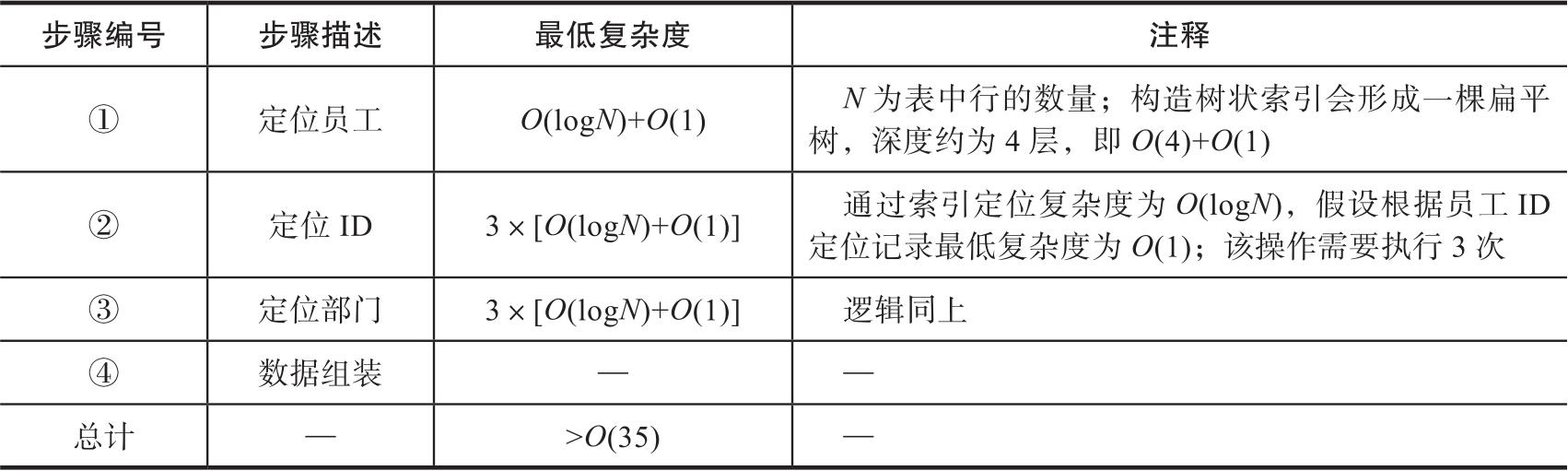
表3-4的查询(时间)复杂度并没有考虑任何硬盘操作的物理延迟,或文件系统上的定位寻址的时间,实际的时间复杂度在这样简单的一个查询操作中,如果数据量在千万以上,可能会以分钟计。如果是更复杂的查询,涉及多表之间复杂的关联,则可能会造成多次扫表操作,试想在硬盘上这个操作的复杂度和时延会是何等量级。
如果用原生图的“近邻无索引”模式来完成以上查询,整个流程如图3-10所示。
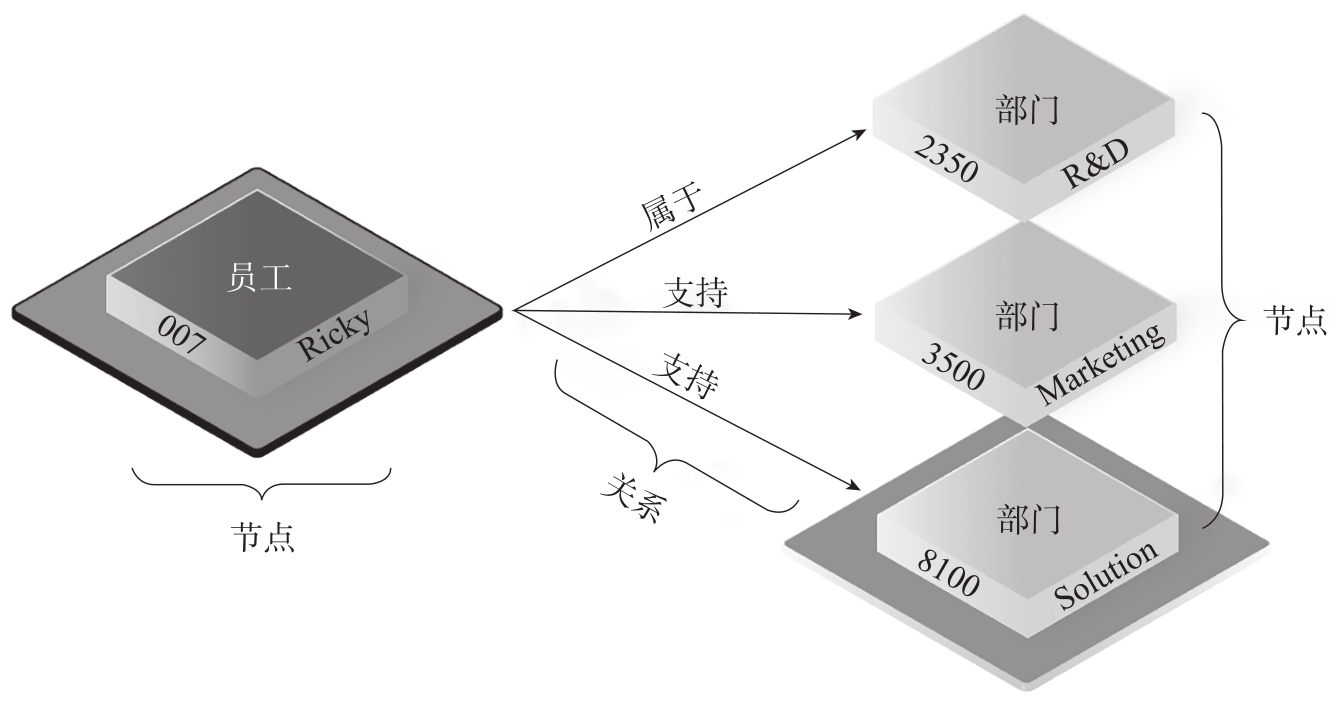
图3-10 原生图查询逻辑示意图
原生图上的查询步骤细分如下:
①在图存储数据结构中定位员工。
②从该员工顶点出发,通过员工-部门关系,找到它所隶属的部门。
③返回员工、员工编号、部门、部门编号。
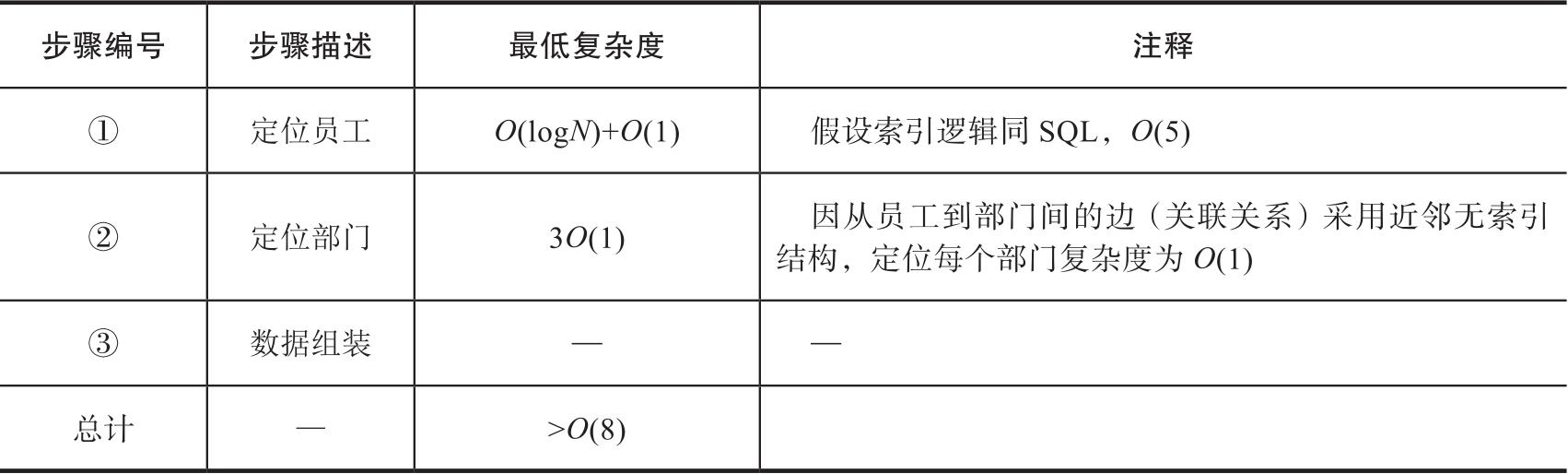
以上第①步定位的时间复杂度与非原生图(SQL)基本相当,但是第②步会有明显的缩短。因为近邻无索引的数据结构,员工顶点通过3条边直接链接到3个部门。如果SQL查询方式的最优解是 O (35),原生图则可以做到 O (8),分解如表3-5所示。
表3-5 原生图查询(时间)复杂度
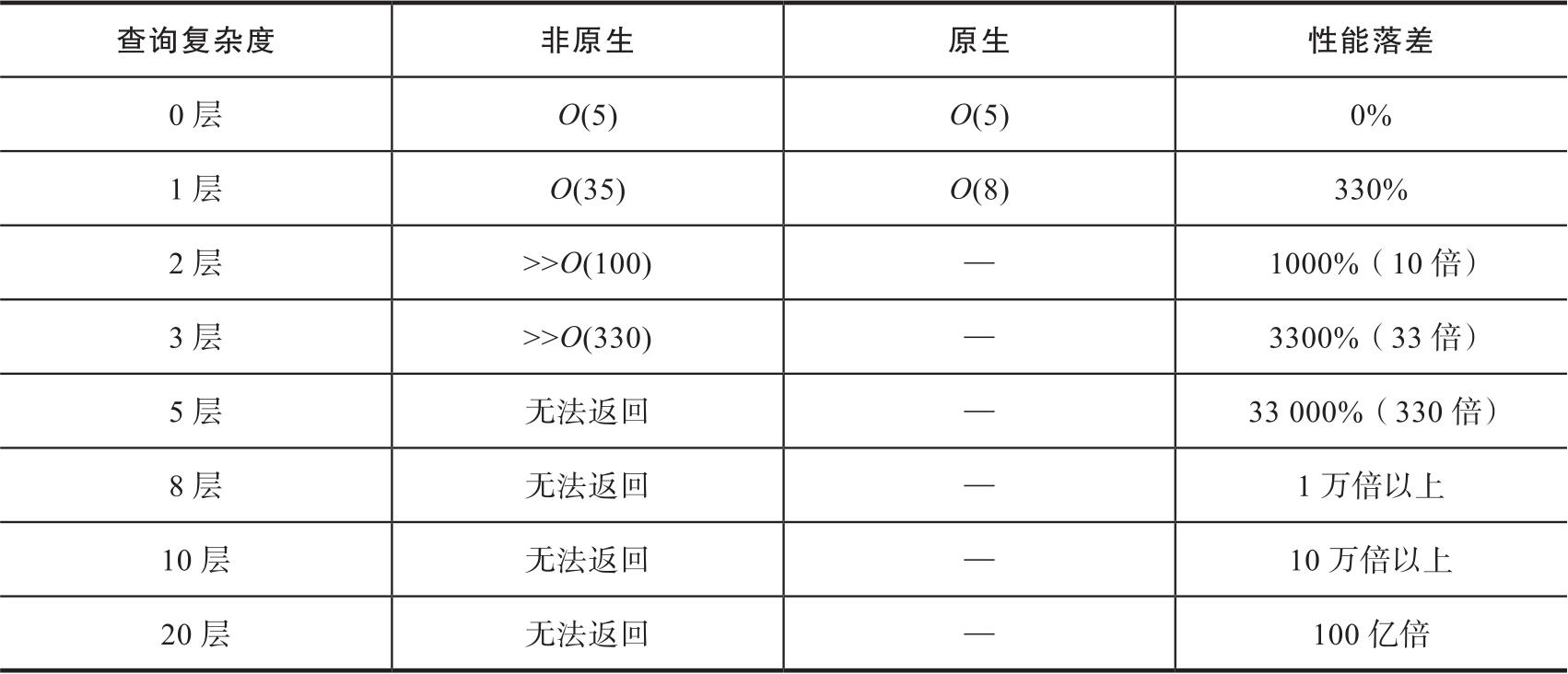
从以上例子可以看出,原生图与非原生图在时间复杂度上存在较大的性能差异。如表3-6所示,以较简单的一度(1-hop)查询为例,原生图比非原生图有330%的性能提升。如果是更为复杂、深度更大的查询,则会产生乘积的提升效果,也就是说,随着深度增加而性能差异指数级飙升。
表3-6 非原生图与原生图性能落差示意
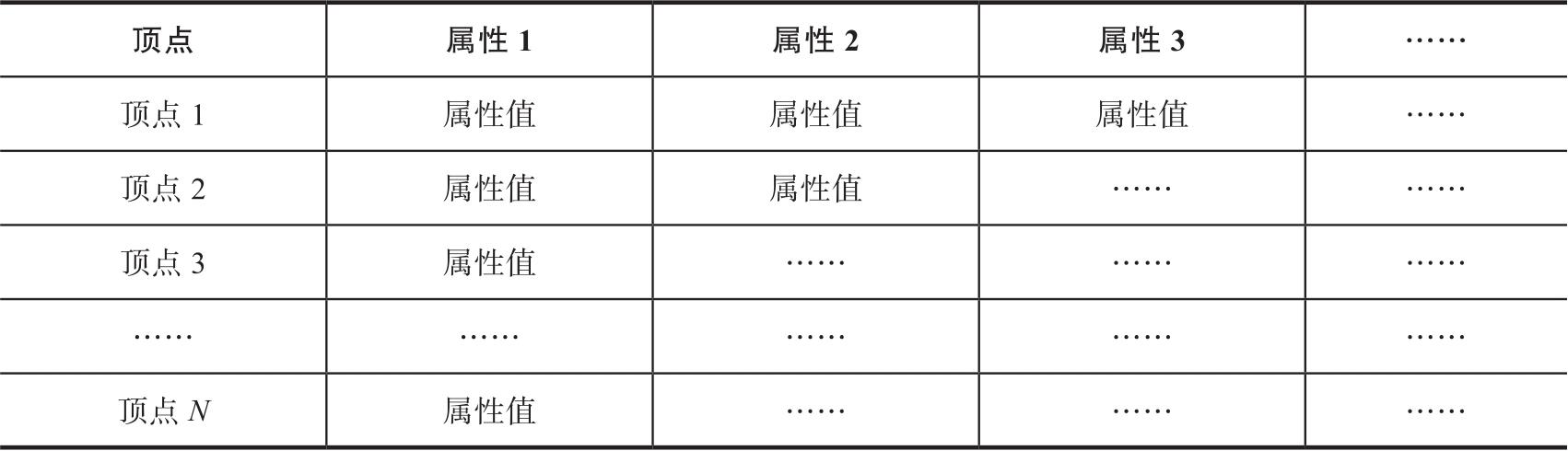
那么,在原生图存储与计算的数据结构下,如果采用顶点ID与属性一体化的设计,可以把所有的顶点(含属性)看作一张大表(Map或类似的复合型数据结构),如表3-7所示。当然,顶点及其属性也可以分离存储,这样处理的优点在于,一方面,分离意味着以顶点ID为骨架的数据结构非常精简,可以获得极高的索引加速、读写加速的效果;另一方面,属性因为可能有很多个(列),分离后更方便在分布式架构中以分布式的方法存放,如以多文件、多实例多文件等方式存放,以此获得更高的并发写入速度。缺点在于增加了额外的寻址、跳转等操作的耗时,以及数据结构与架构的整体设计的复杂度。
表3-7 原生图元数据(实体)存储结构
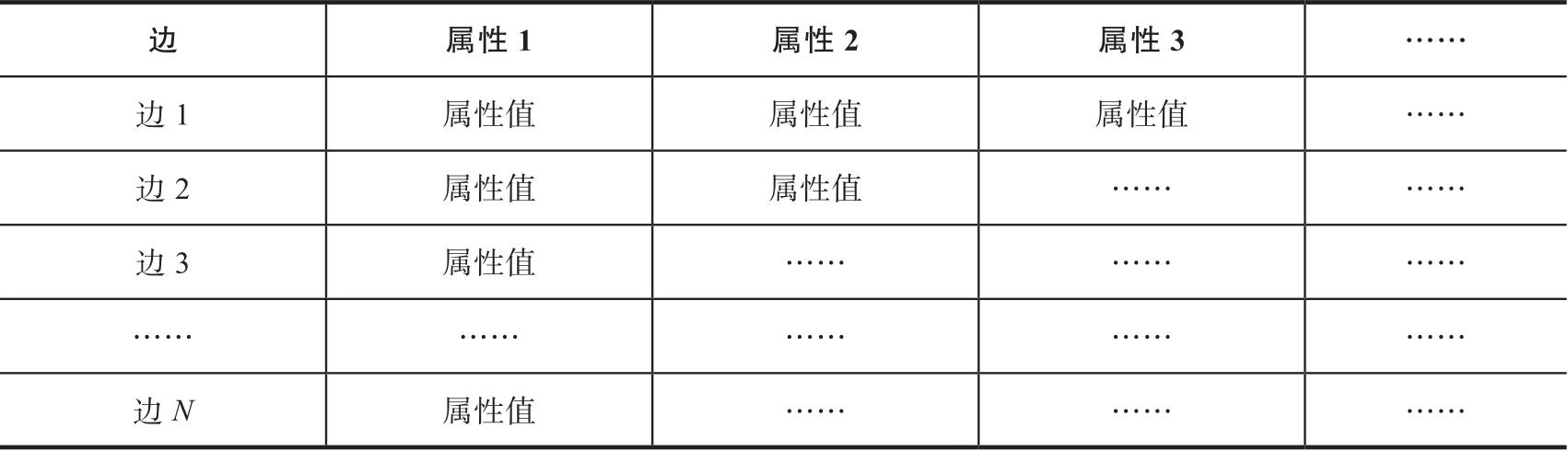
边及其属性也可以用类似的逻辑,无论是整体存储还是分离存储。边的存储比顶点存储更复杂的地方在于,边的属性设计更为复杂(表3-8),我们可能需要考虑如下几点:
❑ 边是否需要方向?
❑ 边的方向如何表达?
❑ 边的起点和终点如何表达?
❑ 边能否关联多个起点或多个终点?
❑ 边为什么需要其他属性?
表3-8 原生图元数据(关系)存储结构
以上问题没有唯一的标准答案。例如边的方向问题,我们可以通过在一条以行存储模式(Row-store)连续存储的边记录中向后放置起点ID与终点ID的方式来表达边的方向。当然,这个问题很快就会触发另一个问题,如何表达反向边(逆边)的概念?这是图计算、图数据库的存储与计算中一个非常重要的概念。假设我们在记录中存放了一条如下的边:

当我们通过索引加速数据结构找到边ID或起点ID时,我们可以顺序读取其后的终点ID,然后在图中继续进行遍历查询。但是,如果我们先找到终点ID时,如何反向(逆向)读取到起点ID来同样地进行遍历查询呢?这个问题的答案也不止一个,我们可以设计不同类型的数据结构来解决,例如,在边记录中设置一个边方向标识属性,然后每一条边记录会正反方向各存储一遍:

当然,还有其他很多种解决方案,例如以顶点为中心的方式存储,包含点自身的属性,以及与它关联的顶点及属性的序列,这种方式同样也可以被看作近邻无索引存储,并且不再需要设置单独的边数据结构了。这种方式的优缺点不在此展开论述,有兴趣的读者可以进行独立的延展分析。
反之,我们也可以以边为中心设计存储数据结构。实际上这种结构在学术界和社交网络图分析中非常常见,例如Twitter用户之间的关系网络仅使用一个边文件即可表达,文件中的每一行的记录仅两列,其中第一列为起点,第二列为终点,每一行的记录表达为第二列用户关注第一列用户,如表3-9所示。
表3-9 边中心存储结构(以Twitter用户之间的关系网络为例)
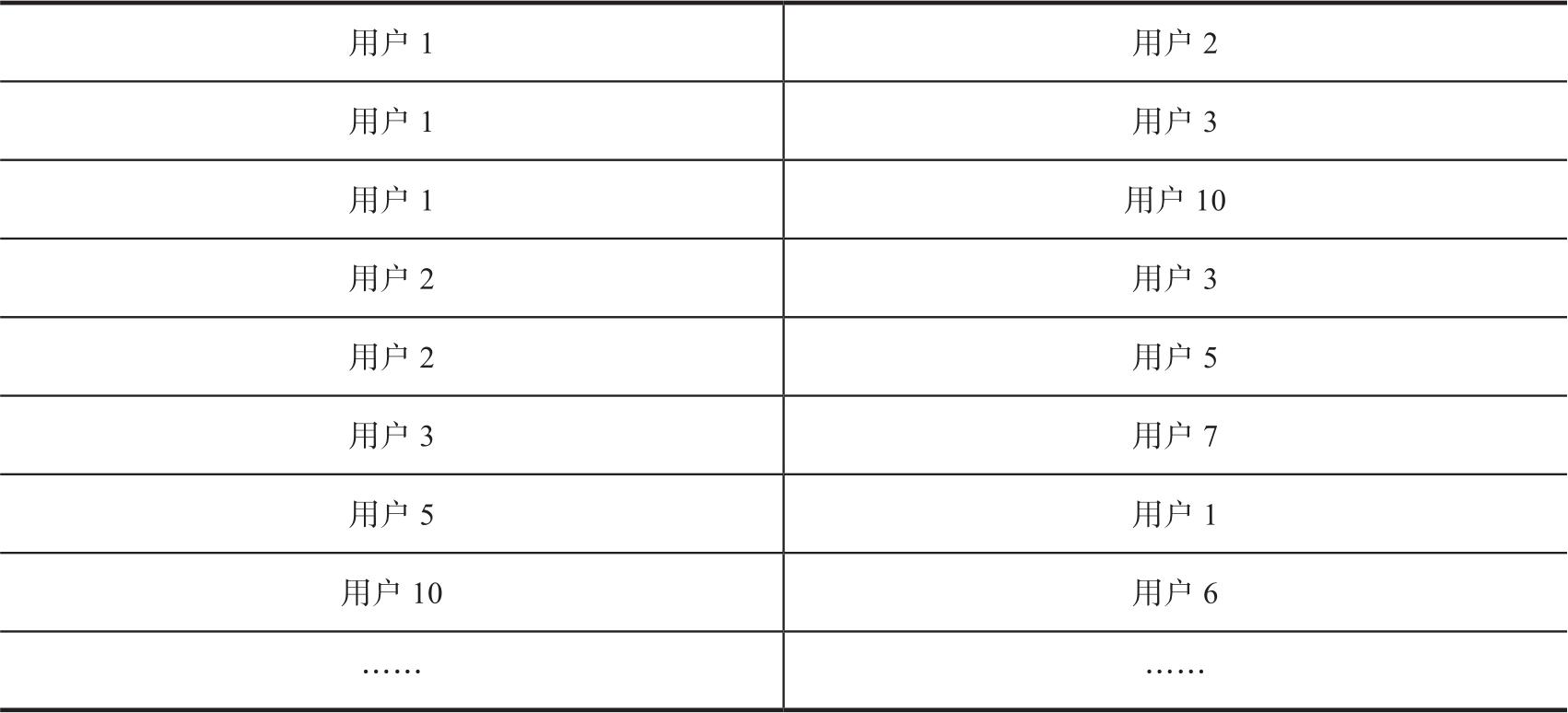
在表3-9的基础上,每一行记录的存储逻辑可以得到大幅扩展,例如加入边的唯一ID来进行全局索引定位,加入更多的边的属性,加入边的方向,或者以自动扩展的方式对每一条原始的表达关注关系的边自动增加一条反向的表达被关注关系的边。
在表3-7所表达的顶点实体列表中,细心的读者一定会提出一个问题:如何存放异构类型的实体(顶点)数据?因为在传统的数据中,不同类型的实体会以不同的表的形式聚合,如我们之前讨论的员工表、部门表、公司实体表,以及不同实体间的关联关系映射表等。在图数据库的存储逻辑中,异构的数据(以实体或关系为例)通过定义Schema可以很好地对数据进行结构化区分,进而能够实现查询加速。如果不支持Schema(比如图数据库Neo4j就并不支持Schema,它是通过一种类似于标签的方式来实现数据类型结构化的),那么所有的数据就只能通过属性字段来区分。尽管图数据库经常被归类为NoSQL类型的数据库,并且NoSQL的特点之一就是支持Schema-free,但是从数据分类管理以及查询效率的角度上看,定义Schema是有其积极意义的,因此也会产生一种兼容并蓄的设计实现方式,例如嬴图数据库通过Demi-schema来同时支持Schema或Schema-free。