
下载掌阅APP,畅读海量书库
立即打开



参数量可以在理论上衡量模型的复杂程度,FLOPs可以在理论上衡量模型的计算时间,但拥有较小的参数量或计算量并不总意味着神经网络推理时间的减少,因为这些最先进的紧凑架构引入的许多核心操作不能有效地在基于GPU的机器上实现,模型的真实性能需要在设备上体现。因此,模型的实际计算速度是更重要的指标,可以通过一些时间函数在设备上直接进行统计。
以PyTorch框架为例,torch.profiler是其自带的性能分析工具,可分析模型速度、内存等,其完整的接口如下。
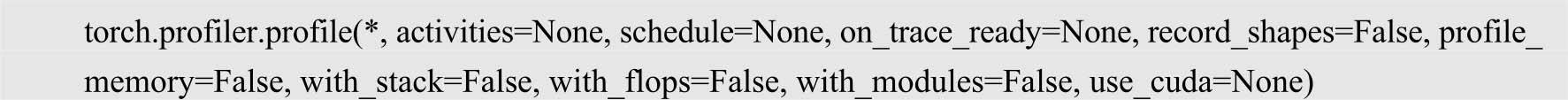
其中,activities参数用于配置是否在CPU或GPU上运行,分别使用参数torch.profiler.ProfilerActivity.CPU和torch.profiler.ProfilerActivity.CUDA;schedule参数用于配置是否收集每个步骤的信息,on_trace_ready参数与schedule参数配合使用;record_shapes参数用于配置是否收集形状信息;profile_memory参数用于配置是否追踪内存使用情况;with_stack参数用于配置是否收集其他信息,如文件与行数;with_flops参数用于配置是否统计FLOPs;with_modules参数用于配置是否分层统计模块信息,可以细化到函数调用;use_cuda参数用于配置是否使用GPU。
下面是用来预测平均时间的一段代码。
