
下载掌阅APP,畅读海量书库
立即打开



数据在收集后,往往包含噪声、数据缺失和数据不规则等问题,因此需要对其进行清洗和整理工作,主要包括以下内容。
规范化管理后的数据才有可能形成一个标准的数据集。数据规范化管理的第一步是统一数据命名。通常爬取和收集的数据没有统一、连续的命名,因此需要制定统一的格式,而命名通常不要含中文字符和不合法字符等,在后续使用过程中不能对数据集进行重命名,否则会造成数据无法回溯的问题,进而导致数据丢失。
另外,图像等数据还需要统一格式,如把一批图片数据统一为JPG格式,防止在某些平台或批量脚本处理中不能正常处理。
数据集一般包括训练集和验证集,有的也包括测试集。
训练集用于模型训练,验证集用于对训练参数进行调优,因此我们通常关注验证集的精度等指标。测试集用于评估模型的泛化能力。我们一般要求训练集和验证集满足同分布,测试集则可以不同。
在不同场景下收集的数据往往具有较大的差异性,对应任务的难度也不同。
以图1.6中的图片为例,有的样本目标大、图片清晰、角度小,识别难度低;有的样本目标小、图片模糊、角度大,或者存在遮挡,识别难度高,因此我们通常在标注的时候进行分级。

图1.6 容易样本和困难样本
在许多开源数据集的评测中,都能看到将完整的数据集划分为困难(Hard)、中等难度(Medium)和容易(Easy)三个子数据集,因此模型也可以针对这三个子数据集分别统计指标,并各自侧重不同的问题。如容易的样本用于快速验证模型,中等难度的样本用于评估模型的泛化能力,困难的样本用于评估模型的先进性。
收集数据时通常无法严格控制来源,比如爬虫爬取的数据可能存在很多噪声。例如,用搜索引擎收集猫的图片,收集的数据可能存在非猫的图片,这时就需要人工或者使用相关检测算法来去除不符合要求的图片。数据的去噪一般对数据的标注工作有很大的帮助,能提高标注的效率。
收集的数据重复或者高度相似是数据收集经常遇到的问题,这会影响数据集的多样性,从而降低数据集的质量。比如在各大搜索引擎爬取同一类图片时就会有重复数据,其中许多下载后的图片仅文件名字或分辨率不同,或者只有微小的差异。又如从视频中获取图片时,帧之间的相似度很高。大量的重复数据对提高模型精度意义不大,甚至可能造成模型过拟合,因此需要进行数据去重。
对于图像任务来说,较简单的数据去重方案为逐像素比较,去掉完全相同的图片,或者利用各种图像相似度算法去除相似图片。
在整理完所有数据之后,一定要及时完成数据存储与备份。备份应该一式多份且在多个地方存储,一般存储在本机、服务器、移动硬盘等处,并定时更新,减小数据丢失的可能性。数据无价,希望读者能够重视数据备份问题。
对于1.1节的图像识别任务来说,我们需要准备两类数据:一类是微笑的人脸,另一类是没有微笑的人脸。但实际上进行模型训练时,我们只需要关注嘴唇部位的状态就行,因此需要对收集的人脸图像进行预处理。图1.7所示是本次数据预处理的流程,包括人脸检测、人脸关键点检测、嘴唇区域提取等步骤。
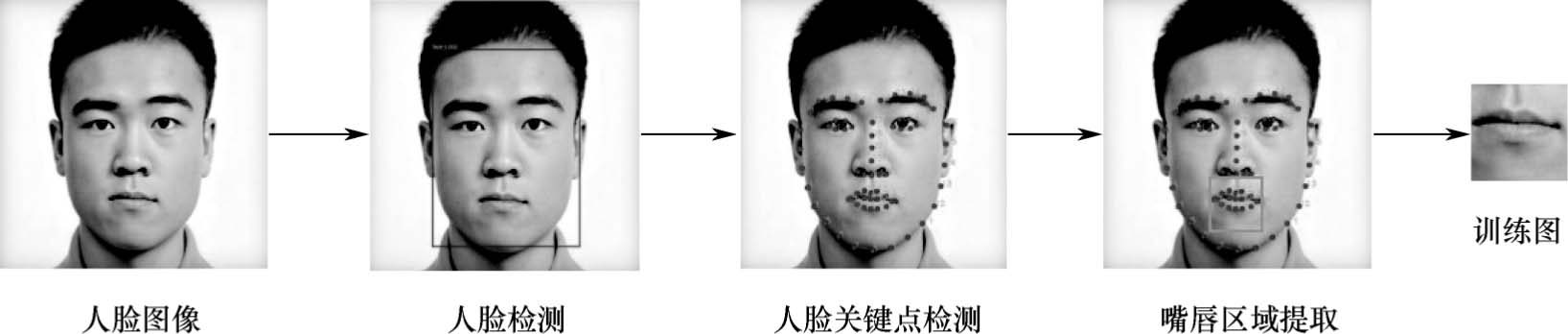
图1.7 数据预处理流程
基于该流程,我们获得了一个基本的数据集,包含500张微笑表情的图片和500张非微笑表情的图片,存放在data目录下。图1.8中展示了一些非微笑表情样本与微笑表情样本。
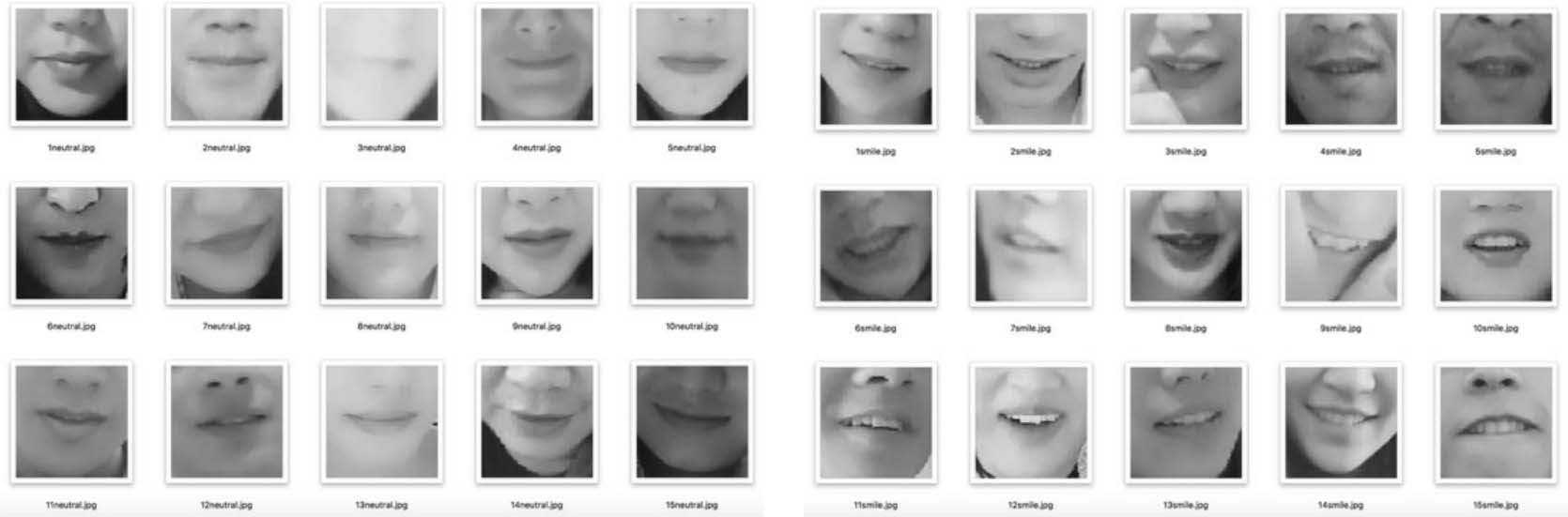
图1.8 非微笑表情样本(左边5列)与微笑表情样本(右边5列)