
下载掌阅APP,畅读海量书库
立即打开



由之前的分析可知,高并发应用系统的定义是,既需要存在高并发场景,又需要具备高并发处理能力。具体为用户会同时向应用系统发送大量请求,而应用系统在接收到这些高并发请求时,能够正常处理每个请求并在预期的时间内返回响应结果给用户,达到响应时间短、吞吐量高、能够支撑大量的并发在线用户这几个指标。而在高并发应用系统的设计与实现层面,主要是从单机和分布式两个维度来考虑高并发的应对策略。
单机高并发主要是指应用系统需要充分利用服务器的CPU、内存等硬件资源来加快每个请求的处理速度,从而提高单台服务器在单位时间内的吞吐量。在应用系统的实现层面,主要包括基于多线程设计来实现对CPU多个核心的利用,基于内存来进行缓存设计,减少对数据库的访问,加快数据的存取操作的速度等。
单台服务器的资源是有限的,故每台服务器所能处理的请求数量也是有限的。当并发量过大导致超出了单台服务器的处理能力时,需要采取分布式高并发策略。分布式高并发是指基于分布式系统架构和集群部署来实现对应用系统的横向拓展。基于负载均衡机制来分发并发请求流量到多台机器,避免所有并发请求都集中在单台服务器来处理,从而解决单台服务器在应对高并发流量时的性能瓶颈问题。
不管是采用分布式系统架构,还是采用集中式的单体应用架构,应用系统都需要在机器的操作系统上运行,利用CPU、内存等硬件资源来处理请求。所以作为应用系统的开发人员,需要从软件的角度来考虑如何在有限的硬件资源条件下,最大化地利用单机的硬件资源来加快请求的处理速度,使应用系统可以处理更多的请求。提升单台服务器的并发处理能力也是实现高并发应用系统需要考虑的首要因素。
在服务端请求的处理层面,每个请求都会交给一个服务端线程来处理。这个线程需要获取CPU时间片,才能得到真正执行,并在执行完成之后返回处理结果给用户。如果应用系统只有一个处理线程,则所有请求都会在该线程排队处理,此时很容易出现由于某个请求的处理时间过长而影响其他所有请求的处理。与此同时,如今服务器的CPU一般都会包含多个核心,所以如果应用程序使用单线程,则无法充分利用CPU的多个核心来实现请求的并发和并行处理,造成了CPU资源的浪费。
在应用系统设计层面,需要考虑使用多个处理线程来实现请求的并发和并行处理,加快请求的整体处理速度,使应用系统在相同的时间范围内可以处理更多的请求,提高应用系统的整体性能。不过在进行多线程设计时,需要注意并不是应用系统开启的请求处理线程越多越好,而是需要结合服务器的CPU的核心数量来设计一个合理的线程数量。
由之前关于并发和并行的分析可知,如果线程数量少于CPU的核心数量,则每个线程可以在CPU的各个核心并行执行;如果多于CPU的核心数量,则某些线程需要在同一个核心轮流调度执行。不过由于CPU的处理速度很快,虽然这多个在同一个CPU核心执行的线程是轮流调度执行,但是在用户看来也相当于是同时执行的。所以一般的多线程设计经验是线程数量需要略多于CPU的核心数量,具体多少需要结合压力测试来确定一个最合适的数量。
通过多线程设计可以实现对CPU多核资源的充分利用,实现请求的并发和并行处理,加快请求的处理速度,提高应用系统的整体吞吐量。不过如果某个请求的处理时间很长也会影响到系统的整体吞吐量。对于高并发系统而言,请求处理耗时较长的一个主要原因就是数据库读写问题。由于数据库自身实现的特点,如基于磁盘文件存储数据的数据库在处理高并发读写请求时很容易出现性能瓶颈问题。针对这个问题,由于内存访问速度快于磁盘访问速度,所以可以进行缓存设计,利用内存来对数据库的数据进行缓存,减少对数据库的访问。
基于多线程设计来实现请求的并发和并行处理,基于内存来实现数据缓存是应用系统开发中比较常见的高并发应对策略。除此之外,一个比较容易让人忽略的地方就是没有对服务器的网络带宽进行优化。
每个服务器的网络带宽的大小通常是固定的,由于所有数据都需要通过网络在客户端与服务端之间传输,如果带宽较小而需要传输的数据较多,那么此时也会加大客户端与服务端之间的传输时延。所以为了实现在有限的网络带宽中传输更多的数据,可以考虑对应用系统的请求和响应数据进行压缩处理,如HTTP 2.0协议通过压缩首部的字段来减少需要传输的数据量。还可以基于二进制数据来传输数据,二进制数据相对于文本数据体积更小,所以可以减少数据传输量,加快数据传输,使得单台机器在单位时间内可以进行更多的数据传输。
单机高并发的实现手段主要包括:通过多线程设计来充分利用CPU的多个核心,从而实现请求的并发和并行处理,加快请求的处理速度,使得应用系统在单位时间内可以处理更多的请求;使用内存进行缓存设计来加快数据存取速度,减少对数据库的访问,加快请求处理速度;可以基于数据压缩、使用二进制格式数据等方式来减少每个请求的数据传输量,从而增大单位时间的数据传输量,最大化地利用单台服务器有限的硬件资源来提升系统的并发处理能力。
不过,单机高并发更多是从单台机器硬件资源的充分利用角度来应对高并发请求流量。单机高并发应对策略只能使单体应用,或者是分布式应用的某个子系统的并发处理能力得到提升,并不能从根本上解决高并发应用系统的整体高并发请求流量的处理问题。当并发量过大时,如果只是使用单台服务器来部署应用,则无论如何对应用系统进行优化,当服务器资源耗尽时,应用系统也很容易出现性能问题,甚至出现服务器宕机、进程崩溃的情况。
可能有人会说可以提升单台服务器的硬件资源来提升单台服务器的处理能力,如增加CPU的核心数、增大内存、使用SSD固态硬盘、加大网络带宽等来对应用系统的并发处理能力进行纵向提升。不过这会增加企业的成本,并且硬件资源方面的提升是很容易遇到瓶颈的,当应用系统的并发流量过大时,单台机器很容易再次出现过载问题。
所以为了提高应用系统在应对高并发请求流量时的拓展能力,现代应用系统一般都是采用分布式架构和集群部署来实现应用系统的水平拓展。具体为分散并发流量到各个子系统,并且根据并发流量的大小来动态调整集群机器的数量。
采用分布式系统架构是指将单体应用的多个功能模块拆分为多个子系统,每个子系统以独立进程的方式在不同的机器部署,实现将不同业务功能的请求分发到不同机器上的各个子系统,由各个子系统来独立处理自身请求的目的。
通过分布式系统架构设计可以解决高并发流量都在单体应用集中处理的问题,即如果所有请求流量都集中在单体应用,则对单体应用所运行的机器硬件资源的要求会非常高,增加了企业成本;同时单体应用不同功能的耦合度较高并且运行在同一个进程中,很难针对某个功能,如单独对请求并发量高的功能进行集群部署来实现水平拓展。
不过分布式系统也会遇到单体应用所不存在的问题,一个典型例子是方法调用问题。与单体应用的不同功能模块之间的相互调用都是在一个进程内通过方法调用来完成不同的是,分布式系统的不同子系统之间需要通过网络通信来进行远程方法调用。所以针对某个请求,如果需要多个子系统协作完成,由于存在网络传输延迟,分布式系统的响应时间可能会比单体应用更长。
不过在高并发场景中,由于分布式系统的不同功能拆分为多个独立的子系统,并且各个子系统都是独立部署在不同机器,所以可以通过集群的方式来拓展对应的子系统。子系统的每个部署实例处理一部分请求,故每个部署实例负载较低,可以快速完成请求的处理和响应。
对于单体应用,即使是通过集群来部署,每个部署实例也需要处理所有功能的请求,故每个部署实例的负载还是比较高。特别是在处理高并发请求流量时,单体应用很容易出现由于系统过载而响应缓慢的情况,所以在高并发场景中,虽然增加了网络调用等开销,分布式系统的整体性能还是要高于单体应用。
刚刚提到了集群部署,采用集群部署是指在多台机器,并且一般是在多台硬件资源配置较低的廉价机器上部署同一个业务服务,即以上提到的子系统。通过集群部署可以将对该业务服务的请求流量分散到集群的这多台机器节点上运行的服务实例,每个服务实例处理该服务的部分请求,所有服务实例完成的请求流量的总和构成该业务服务的总吞吐量。其中集群请求流量分发一般会采用负载均衡算法,如轮询、随机、哈希等,将某个请求分发给集群的某个机器节点来处理。
通过集群部署可以加大系统可支撑的并发请求量,并且由于每个机器节点只负责处理部分请求,故系统负载较低,请求处理速度较快,提高了服务的整体性能。除此之外,集群部署还可以提高服务的可用性,因为拥有多台机器提供相同的服务,如果其中某台机器宕机了,其他机器可以继续提供服务,避免了单点故障问题。
一个典型的基于分布式架构设计与集群部署的应用系统的整体架构如图1.2所示。
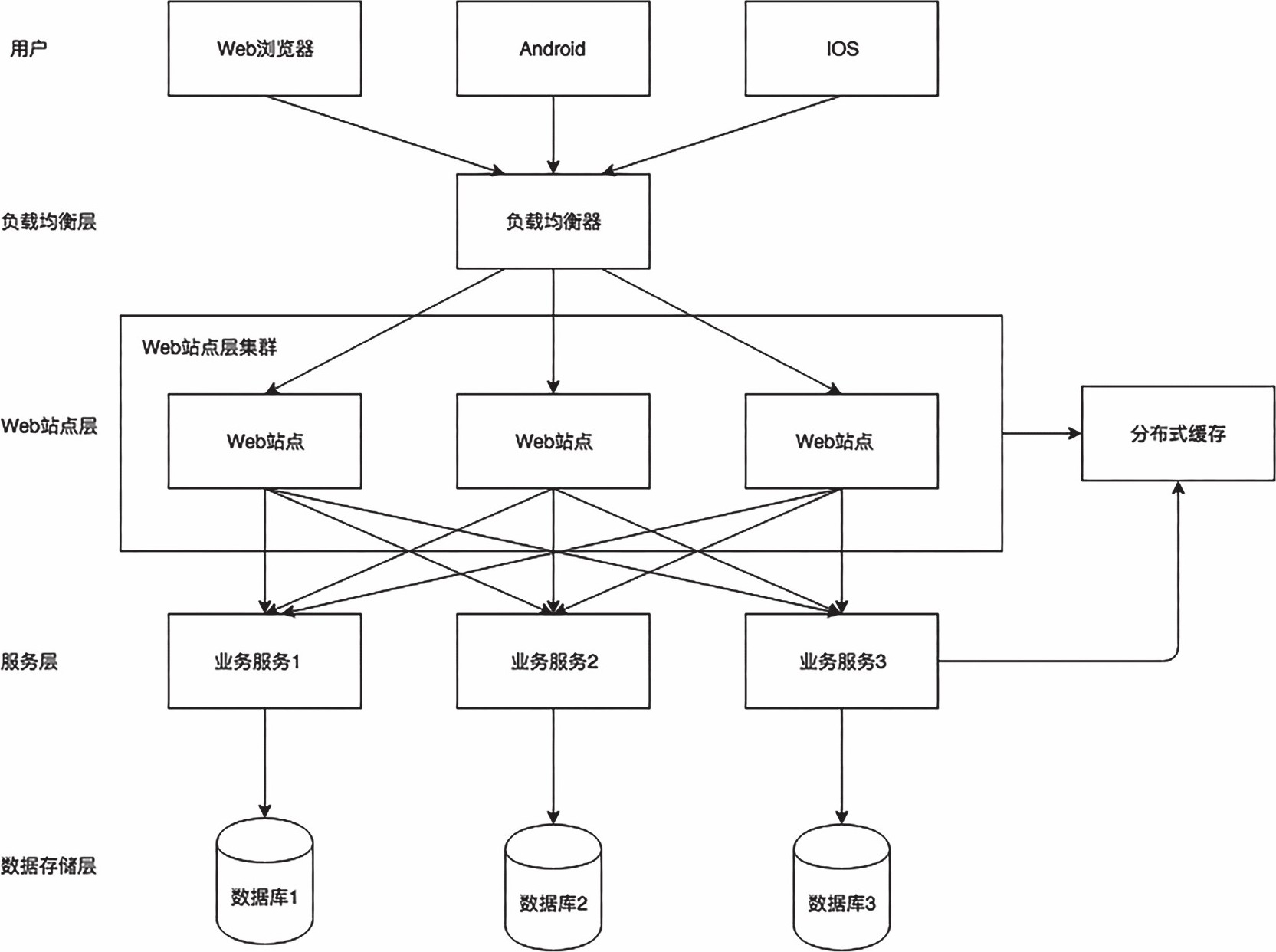
图1.2 基于分布式架构设计与集群部署的应用系统的整体架构
在架构设计层面,分布式系统架构采用的是一种分层架构,不过与单体应用的分层架构不同,单体应用的分层架构,如典型的MVC架构,是代码层面的分层;分布式系统的分层架构是在系统部署层面的分层,一般需要与集群部署结合起来使用。如图1.2所示,从上到下依次分为负载均衡层、Web站点层(API网关层)、服务层、数据存储层。
其中负载均衡层主要是接收客户端的请求并分发给对应的Web站点层集群的某个机器节点来处理。由于负载均衡层不需要进行实际的业务处理,只需要进行请求转发,所以性能较高,可以应对高并发的请求流量。负载均衡的实现方式一般包括软件负载均衡和硬件负载均衡两种,后续章节将进行详细分析。
Web站点层一般使用集群部署,主要是接收负载均衡层分发过来的请求,然后根据请求的业务特点,调用服务层对应的服务(子系统)来处理该请求。服务层主要是各个业务服务系统,这与单体应用中各个功能模块是对应的。同时不同业务服务之间的调用一般都是在局域网内部完成的,故性能较高。
最后是数据存储层,不同业务服务可以使用自身独立的数据存储,如不同的数据库。这点是对单体应用中所有数据都存储在一个数据库的优化。这样可以分散不同业务服务的数据读写请求到不同的数据库服务器,避免集中式的数据库访问,提高数据的整体读写性能。除此之外,Web站点层和服务层都可以根据自身业务特点进行缓存设计,通过在内存中存储数据,可以加快数据的访问速度,解决数据库读写或者热点数据读写的性能问题。