
下载掌阅APP,畅读海量书库
立即打开



在2.1节中已经了解了urllib的一些功能,而requests模块是在urllib的基础上做了封装,让使用者更加方便地调用。requests模块属于第三方的模块,需要单独安装后才能使用。下面讲解requests模块如何安装和使用。
使用Python进行项目开发时,由于不同的项目需要,可能会配置多个开发环境,不同开发环境之间的项目依赖包如果混合在一起,则可能会引起意想不到的错误。通过虚拟环境隔离不同开发环境,方便不同开发环境的共存。安装虚拟环境的具体操作步骤如下。
01 virtualenv是Python的虚拟环境包,如图2-1所示,运行如下命令实现安装virtualenv。

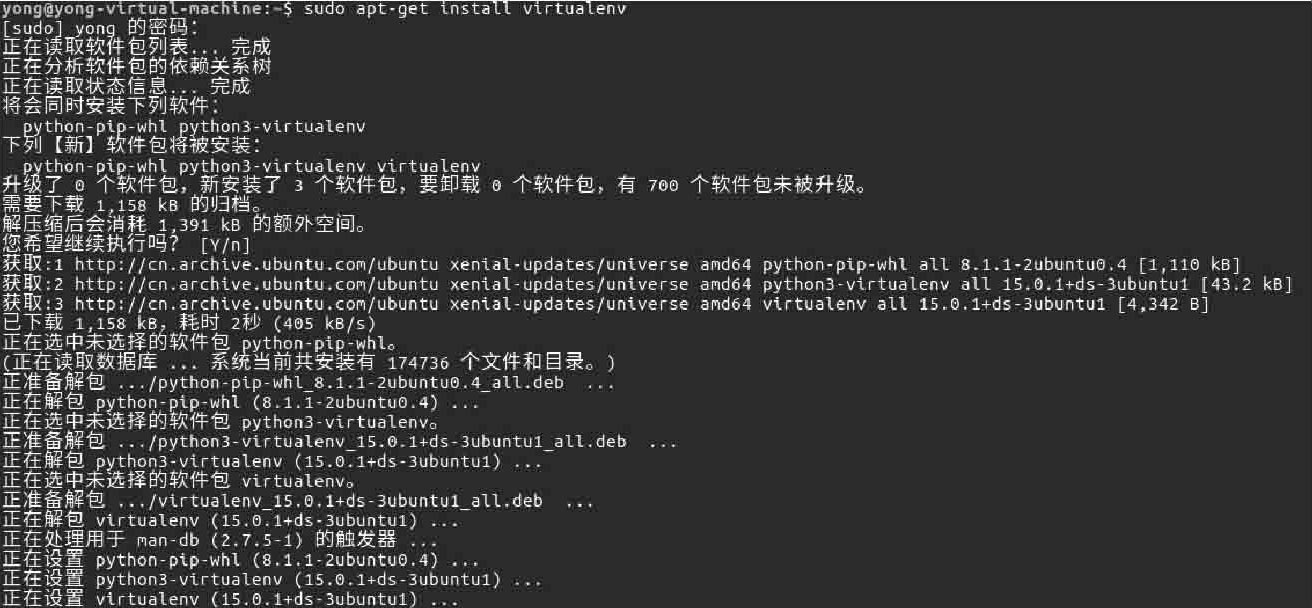
图2-1 安装virtualenv
02 virtualenvwrapper是virtualenv的扩展包,用于更方便地管理虚拟环境,如图2-2所示,运行如下命令实现安装virtualenvwrapper。

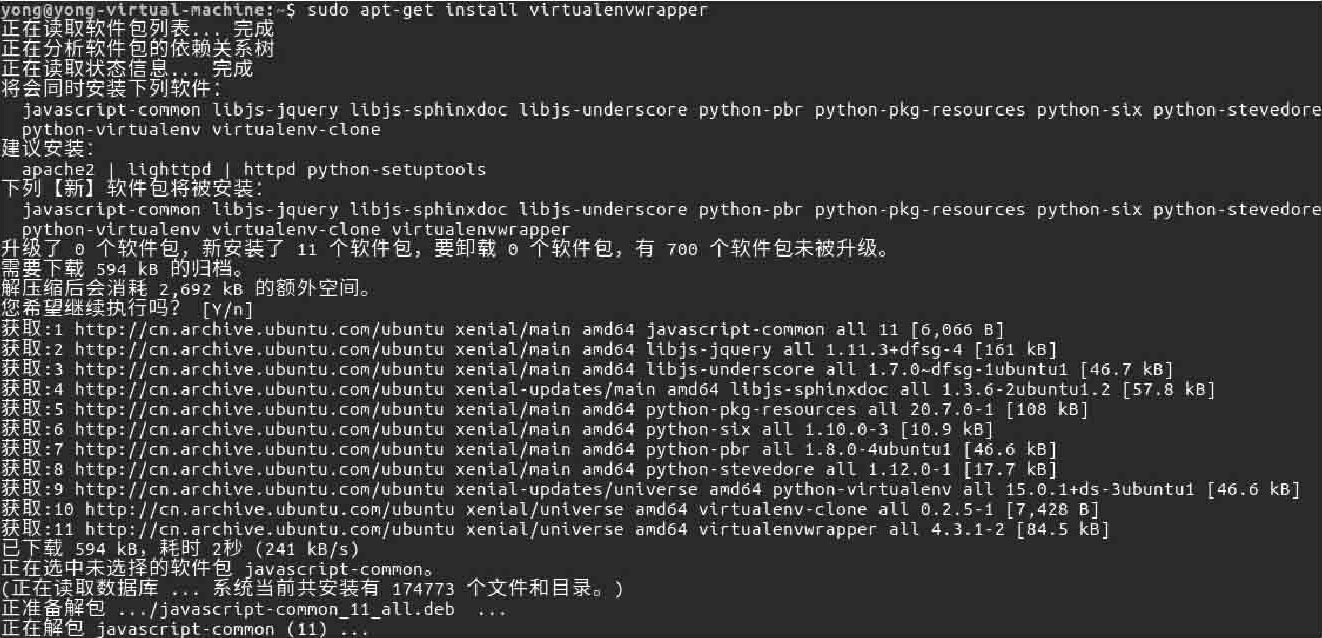
图2-2 安装virtualenvwrapper
安装好之后,此时还不能使用virtualenvwrapper,实际上需要运行virtualenvwrapper.sh文件才行。配置虚拟环境的具体操作步骤如下。
01如图2-3所示,运行如下命令实现查看virtualenvwrapper的安装路径。
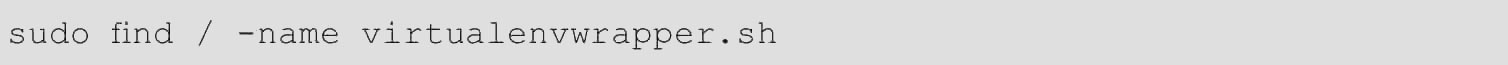

图2-3 查看virtualenvwrapper的安装路径
02如图2-4所示,运行如下命令实现创建目录用来存放虚拟环境。


图2-4 创建目录用来存放虚拟环境
03如图2-5所示,运行如下命令实现编辑家目录下的.bashrc文件。

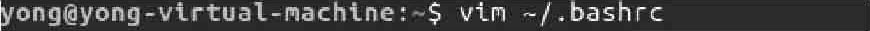
图2-5 编辑家目录下的.bashrc文件
04如图2-6所示,在文件.bashrc结尾添加如下两行代码。

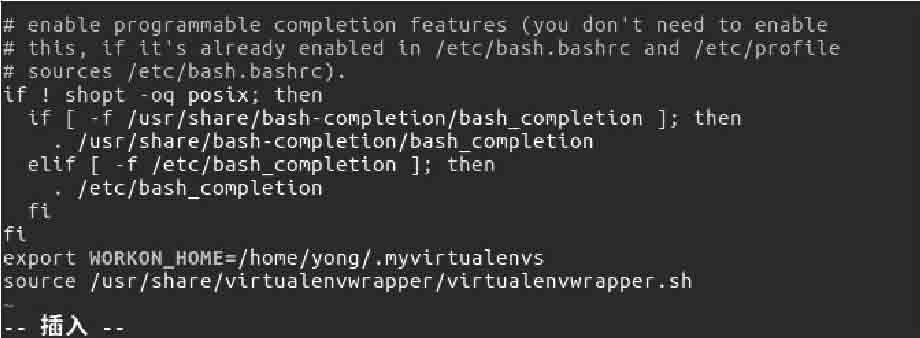
图2-6 在文件.bashrc结尾添加两行代码
05如图2-7所示,刷新运行.bashrc文件中的内容。


图2-7 刷新运行.bashrc文件中的内容
此时virtualenvwrapper就可以使用了。
配置好virtualenvwrapper,就可以使用它的功能管理虚拟环境了。常用的一些代码指令如下。

安装好虚拟环境后,就可以创建相互隔离的虚拟环境了。创建爬虫的虚拟环境的具体操作步骤如下。
01如图2-8所示,运行如下命令实现进入本地虚拟环境的目录文件夹。


图2-8 进入本地虚拟环境的目录文件夹
02如图2-9所示,运行如下命令实现创建Python 3的虚拟环境。


图2-9 创建Python 3的虚拟环境
此时左侧的小括号显示已经进入了爬虫的虚拟环境。
创建好虚拟环境后,进入虚拟环境,就可以使用pip命令安装requests模块了。在虚拟环境下安装模块的具体操作步骤如下。
01如图2-10所示,运行如下命令实现进入指定的虚拟环境。


图2-10 进入指定的虚拟环境
02如图2-11所示,运行如下命令实现在虚拟环境中安装requests包。

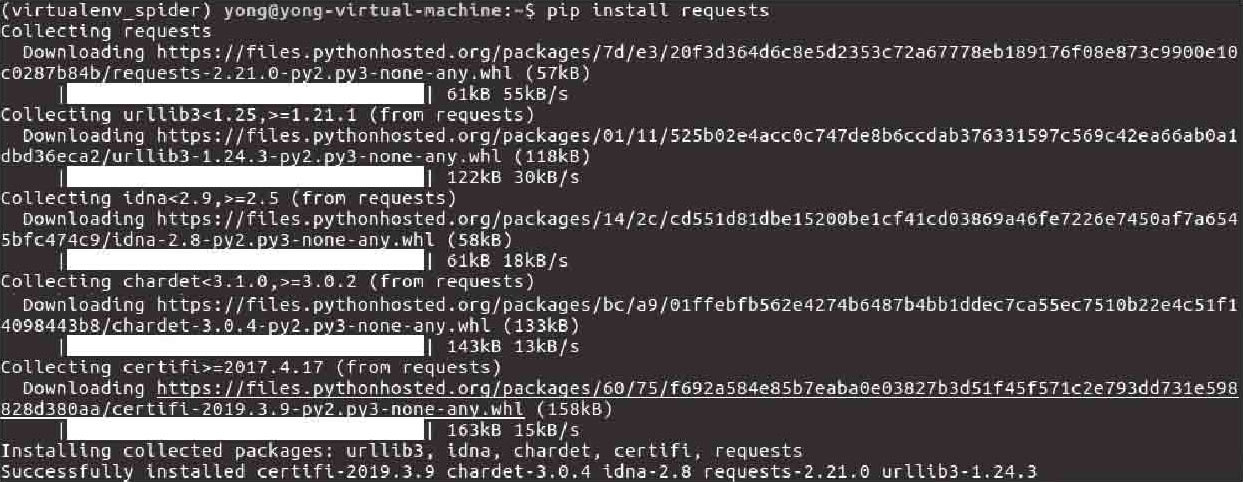
图2-11 在虚拟环境中安装requests包
此时requests模块已经安装成功了。
在2.2.1小节中已经成功安装了requests模块,下面将介绍requests模块的基础功能。
常用的请求方式有两种,分别是get和post,对应着requests.get()和requests.post()方法。它们的语法如下。

url是请求的地址,如果发送get请求,则使用params传参;如果发送post请求,则使用data传参。返回值是本次请求对应的响应对象。
其他参数后面再进行讲解。
【范例2.2-1】使用requests发送请求和携带参数(源码路径:ch02/2.2/2.2-1.py)
范例文件2.2-1.py的具体实现代码如下。

【运行结果】
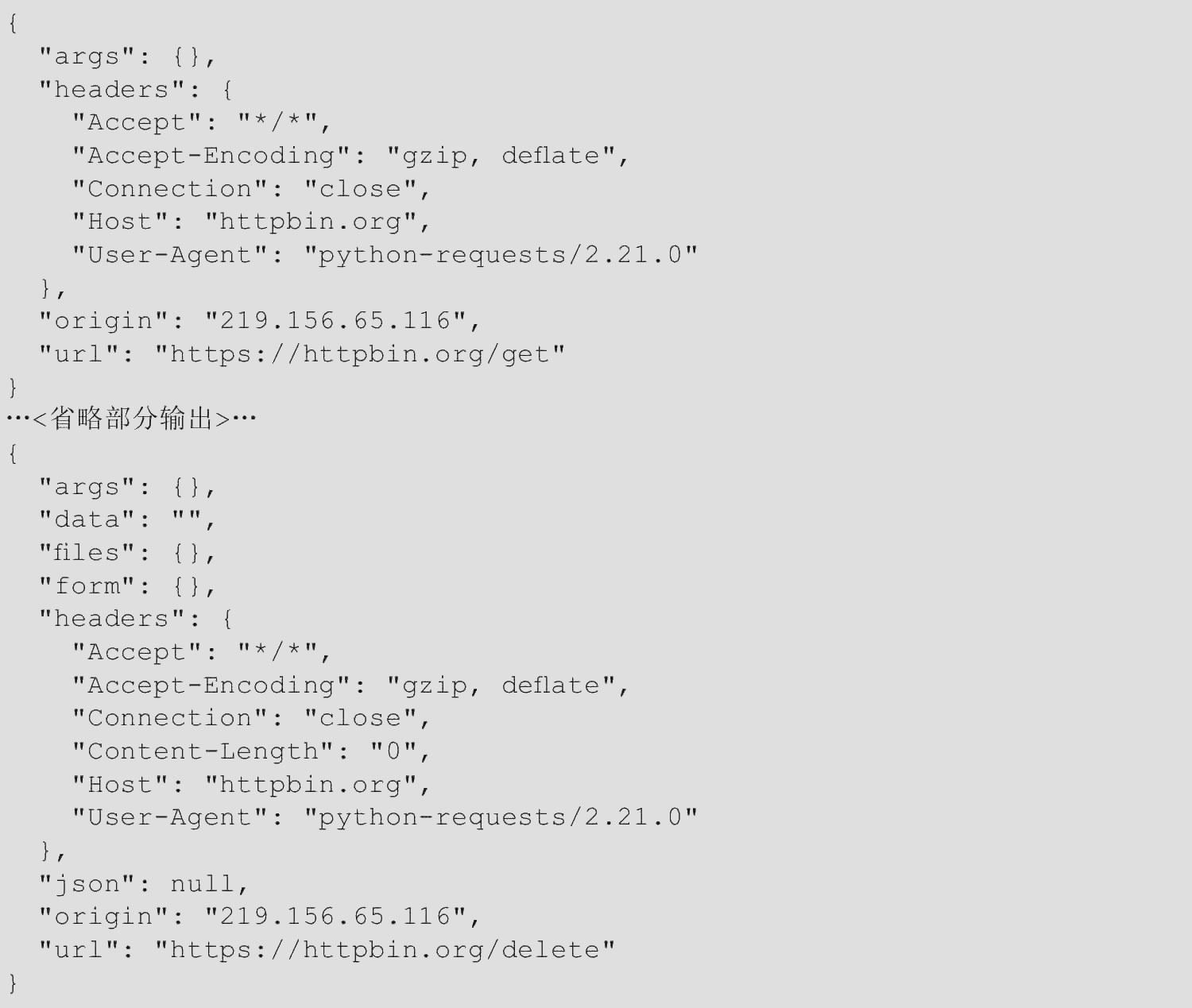
【范例分析】
(1)requests可以很方便地完成发送各种请求,封装了对应的方法,常用的是get和post,如果需要传递参数,则get使用params, post使用data。
(2)requests得到响应对象r, r.text表示获取的是解码之后的内容,而r.content表示获取的是字节。
提示
如果参数中含有中文,则自动进行urlencode编码,不需要使用者再手动实现编码。
使用requests发送请求,得到一个响应对象,代码如下。

上面的代码中r表示获取的响应对象,r.text将自动解码来自服务器的内容。大多数unicode字符集都是可以成功解码的。r.content是返回的字节类型。
当发出请求时,requests会根据HTTP标头对响应的编码进行有根据的猜测。访问时使用由请求猜测的文本编码r.text。可以使用r.encoding属性找出请求正在使用的编码,并进行更改,代码如下。

如果更改编码,则请求将在调用r.text时使用r.encoding的新值重新进行编码。如果希望在任何可以应用特殊逻辑来计算内容编码的情况下执行此操作,例如,HTML和XML可以在其正文中指定其编码,在这种情况下,就应该使用r.content来查找编码,然后设置r.encoding为相应的编码。这样就能使用正确的编码解析r.text了。
如果需要,那么请求也可以使用自定义编码。如果已创建自己的编码并将其注册到codecs模块,则只需使用编解码器名称作为r.encoding的值,然后由requests来处理编码。
提示
如果返回的是文本,那么通常使用r.content.decoe('utf-8')手动指定编码格式进行解码,这样更加直观方便。
如果想将HTTP标头添加到请求中,则只需将dict传递给headers参数即可,代码如下。

如果希望发送一些表单编码数据(类似于HTML表单),则只需将字典传递给data参数即可。在发出请求时,数据字典将自动进行表单编码,代码如下。
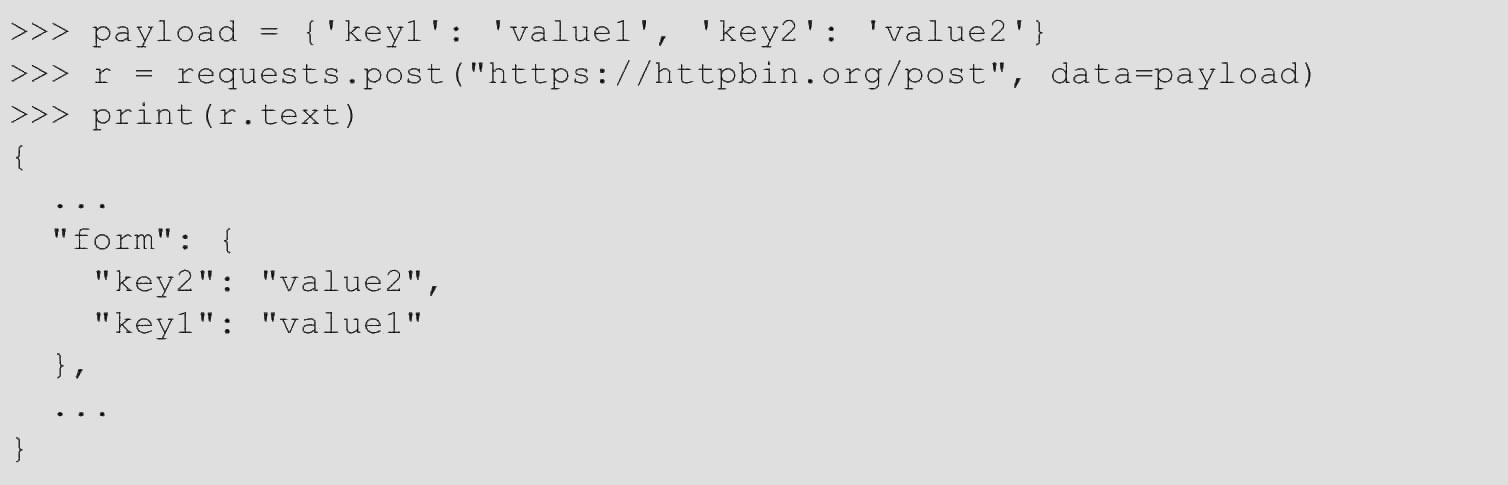
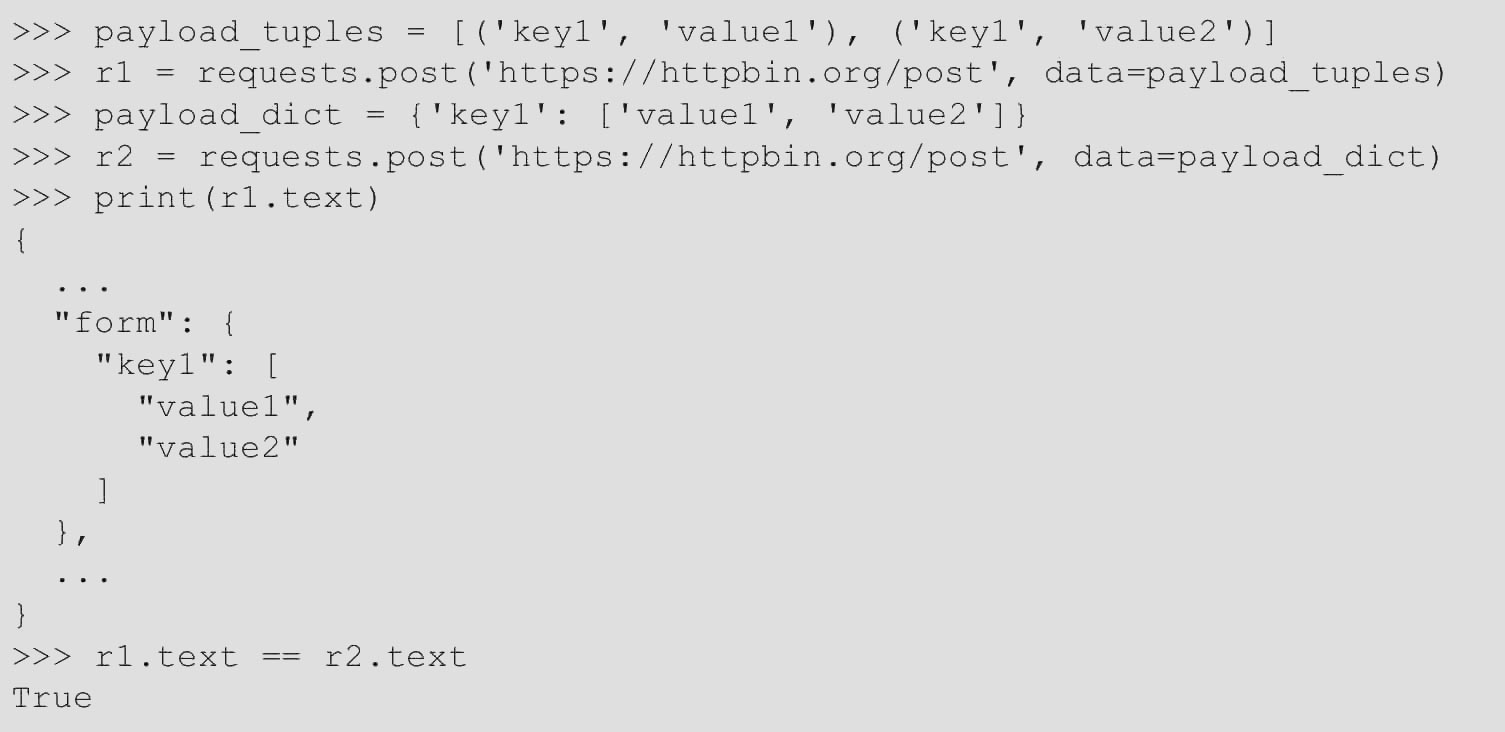
data参数中一个键可以有多个值,这可以通过创建data元组列表或以列表作为值的字典来完成。当表单具有使用相同键的多个元素时,这尤其有用,代码如下。
有时可能希望发送非表单编码的数据。如果传递的是string而不是dict,则该数据将直接发布。例如,GitHub API v3接受JSON编码的post/patch数据,代码如下。

dict也可以使用json参数(在版本2.4.2中添加)直接传递,它将自动进行编码,代码如下。

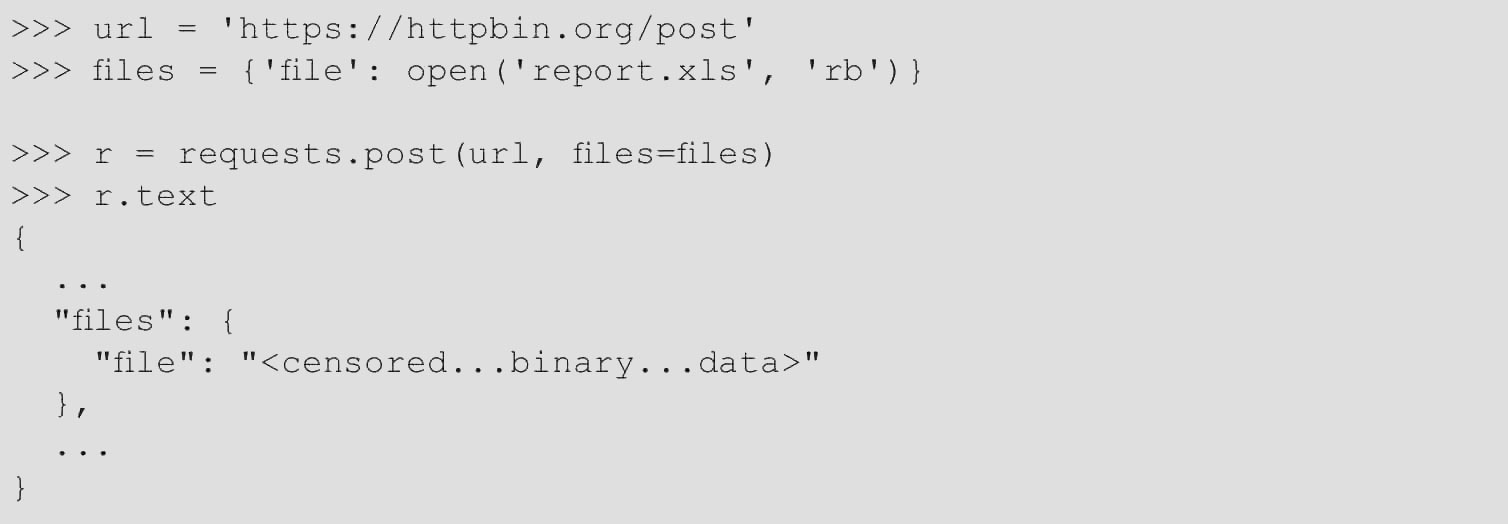
在请求中使用json参数,会将header中的Content-Type更改为application/json。文件上传也必须使用post请求,代码如下。
提示
建议以二进制模式打开文件。这是因为请求可能会尝试为您提供Content-Length标头,如果是,则此值将被设置为文件中的字节数。如果以文本模式打开文件,则可能会出现错误。
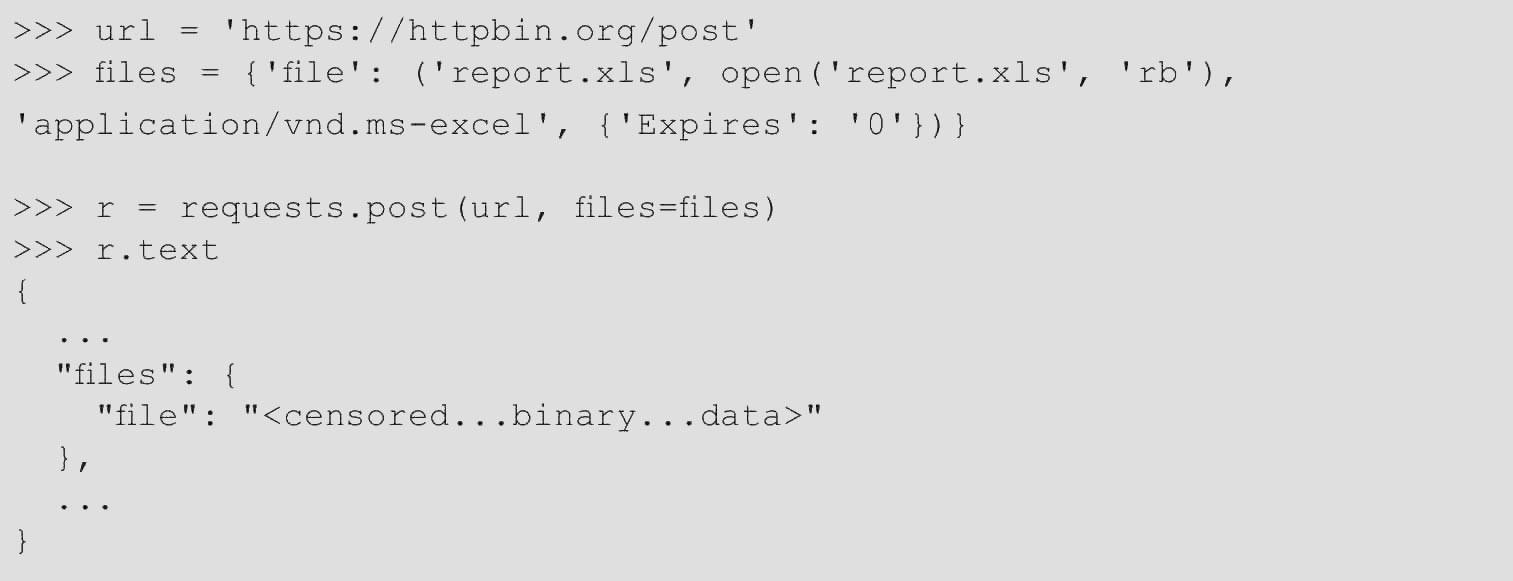
文件上传也可以显式设置文件名,content_type和header,代码如下。
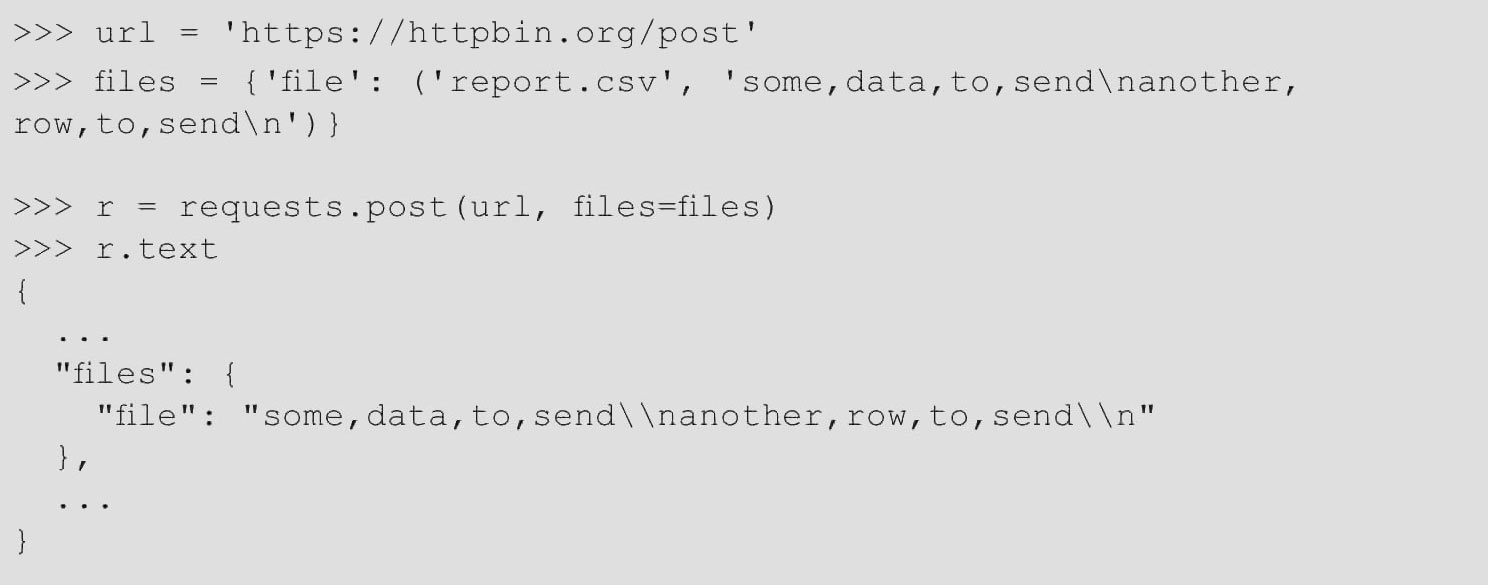
如果需要,则可以发送要作为文件接收的字符串,代码如下。
提示
如果要将非常大的文件作为请求发布,则可能需要流式传输请求。默认情况下,requests不支持此功能,但有一个单独的包requests-toolbelt可以。
通过响应对象的status_code属性可以查看响应状态代码,代码如下。

请求还附带内置状态代码查找对象,以便于参考,代码如下。

如果发出错误的请求(4××客户端错误或5××服务器错误响应),则可以使用以下命令提出Response.raise_for_status()。
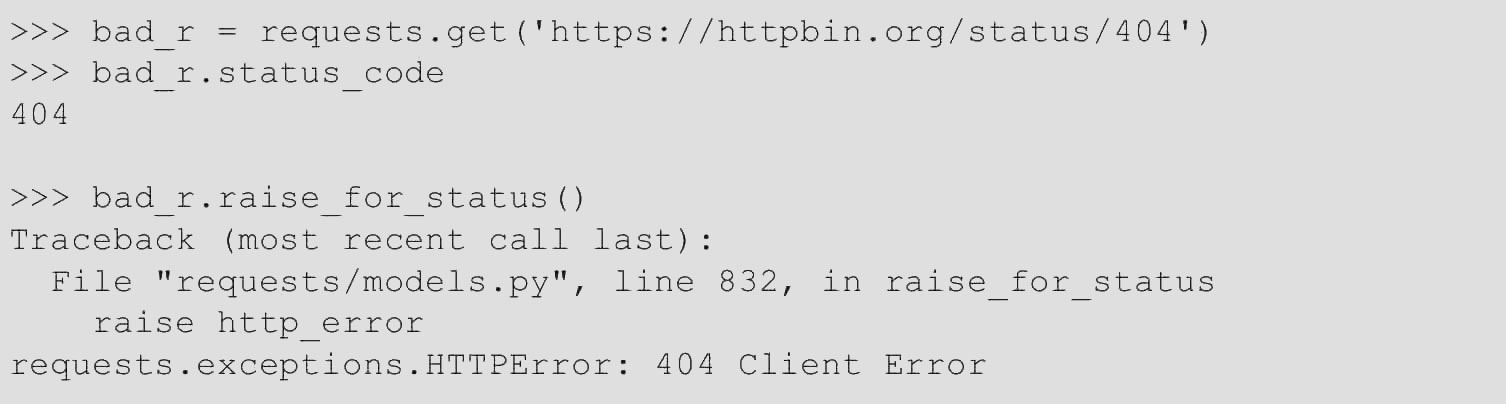
但是,如果status_code为200,则调用raise_for_status()时会得到None。
通过响应对象可以查看服务器的响应头,是一个字典类型,代码如下。

根据RFC 7230,HTTP标头名称不区分大小写。因此,可以使用所需的任何大写字母访问标头,代码如下。
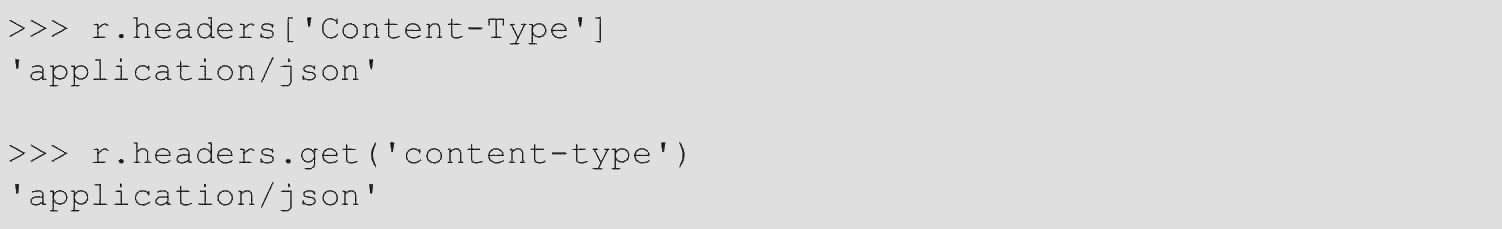
如果响应包含一些Cookie,则可以快速访问它们,代码如下。

要将自己的Cookie发送到服务器,可以使用cookies参数,代码如下。

Cookie以一个RequestsCookieJar对象的形式返回,其作用类似于dict,但还提供了更完整的界面,适用于多个域或路径。Cookie包也可以传递给请求,代码如下。

默认情况下,Requests将为除head外的所有动词执行位置重定向。可以使用Response对象的history属性来跟踪重定向。该Response.history列表包含为完成请求而创建的Response对象。该列表从最旧的响应到最新的响应排序。
例如,GitHub将所有HTTP请求重定向到HTTPS,代码如下。
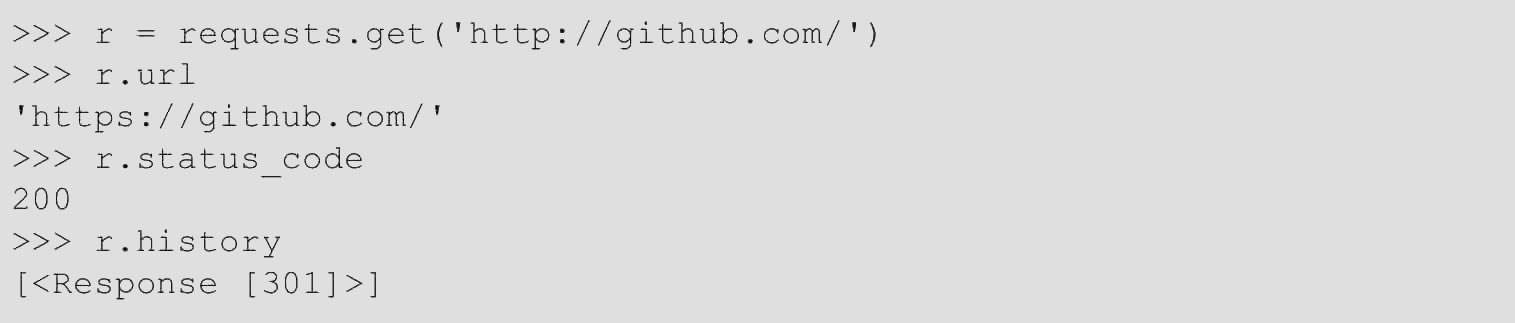
如果使用的是get、options、post、put、patch或delete,则可以使用allow_redirects参数禁用重定向处理,代码如下。

如果使用的是head,则还可以启用重定向,代码如下。

可以使用timeout参数告知请求在给定秒数后停止等待响应。几乎所有生产代码都应该在几乎所有请求中使用此参数。如果不这样做,则可能会导致程序无限期挂起,代码如下。

提示
timeout不是整个响应下载的时间限制。相反,如果服务器在timeout秒数内没有发出响应(更准确地说,如果在timeout秒数内在底层套接字上没有接收到任何字节),则会引发异常。如果未明确指定超时,则请求不会超时。
如果出现网络问题(如DNS故障、拒绝连接等),则请求将引发ConnectionError异常。
如果HTTP请求返回不成功的状态代码,则Response.raise_for_status()将会引发HTTPError异常。
如果请求超时,则会引发超时异常。
如果请求超过配置的最大重定向数,则会引发TooManyRedirects异常。
请求显式引发的所有异常都继承自requests.exceptions.RequestException。
在2.2.2小节中已经了解了requests模块的一些基础功能,下面介绍requests模块的一些更高级的功能。
Session对象允许跨请求保留某些参数。它也会在同一个Session实例发出的所有请求之间保持Cookie。因此,如果向同一主机发送多个请求,则将重用底层TCP连接,从而带来显著的性能提升。
Session对象具有主要的Requests API的所有方法。Session对象可以在请求中保留一些Cookie,代码如下。

上面的代码使用Session对象s向url1发送请求,对应的响应中会设置一些Cookie,保存到了s中,下次使用s向url2发送请求,会将同一domain下的Cookie发送给url2对应的服务器。这样就实现了Cookie的保留。
Session对象还可用于向请求方法提供默认数据。这是通过向Session对象上的属性提供数据来完成的,代码如下。

传递给请求方法的任何字典都将与设置的会话级值合并。方法级参数覆盖会话参数。
但需要注意的是,即使使用会话,方法级参数也不会在请求之间保持不变。此示例仅发送带有第一个请求的Cookie,但不发送第二个请求,代码如下。

如果要手动将Cookie添加到会话中,则可使用Cookie实用程序功能来操作Session.cookies。
会话也可以用作上下文管理器,代码如下。

这将确保一旦with退出块就关闭会话,即使发生未处理的异常也是如此。
每当调用requests.get()都会做两件事。第一件事是构建一个Request对象,该对象将被发送到服务器以请求或查询某些资源。第二件事是获取Response对象,一旦Request从服务器获得响应,就会生成一个Response对象。该Response对象包含服务器返回的所有信息,还包含Request最初创建的对象。以下是从维基百科服务器获取一些非常重要信息的简单请求。
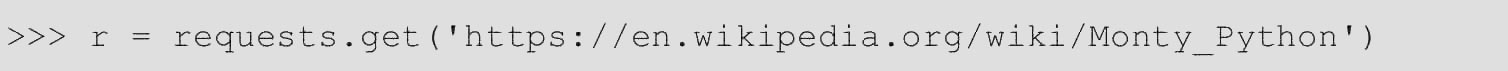
如果想要访问服务器发回的headers,则可以这样做,代码如下。

但是,如果想要获取发送服务器的headers,则只需访问请求,然后访问请求的headers,代码如下。

当从API调用或会话调用中接收一个Response对象时,request属性实际上是使用了PreparedRequest。在某些情况下,可能希望在发送请求之前对正文或标题(或其他任何内容)做一些额外的处理,代码如下。
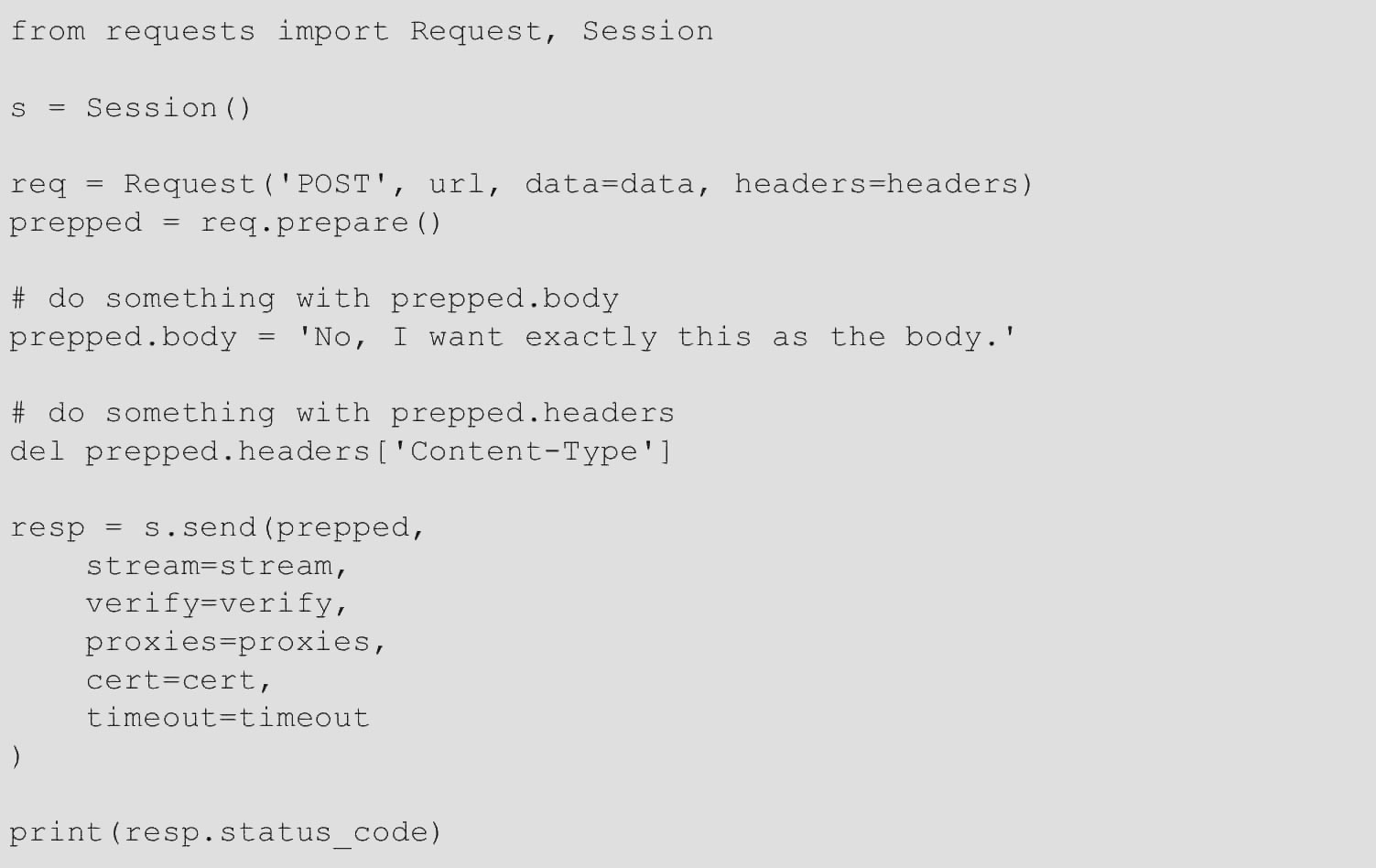
由于没有对该Request对象执行任何特殊操作,因此可以立即准备并修改该PreparedRequest对象,然后把它和其他参数一起发送到requests.*或Session.*。
但是,上面的代码将失去拥有Requests Session对象的一些优势,尤其Session级别的状态,如Cookie将不会应用于这样的请求。为了得到一个带有状态的PreparedRequest,可以用Session.prepare_request()取代Request.prepare()的调用,代码如下。
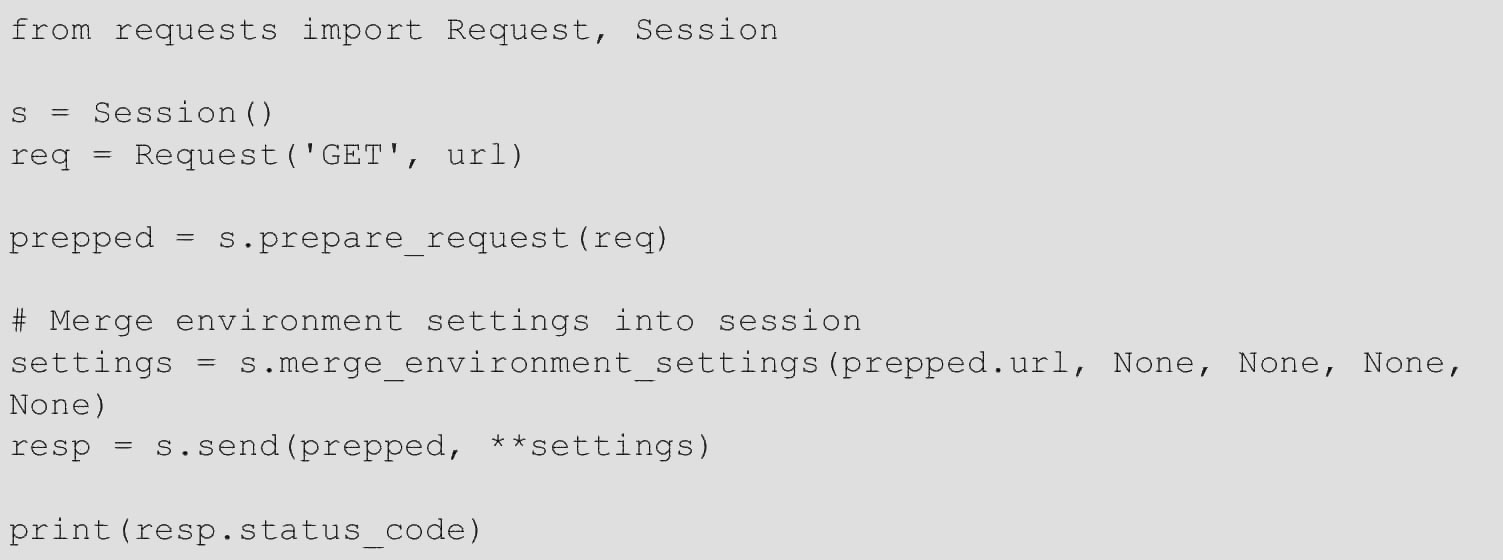
当使用准备好的请求流时,它并不会考虑到用户环境。如果通过设置环境变量来更改请求行为,就可能会带来一些问题。例如,REQUESTS_CA_BUNDLE不会考虑指定的自签名SSL证书。结果是抛出SSL:CERTIFICATE_VERIFY_FAILED。可以通过将环境设置合并到会话中来解决此问题,代码如下。
请求验证HTTPS请求的SSL证书,就像Web浏览器一样。默认情况下,启用SSL验证,如果无法验证证书,则Requests将抛出SSLError,代码如下。

由于该域名(https://requestb.in)没有设置SSL,因此会引发SSLError异常。可以将verify路径传递给具有受信任CA证书的CA_BUNDLE文件或目录,代码如下。
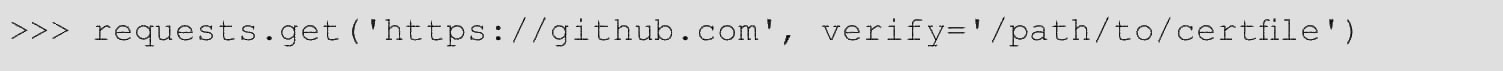
提示
如果verify设置为目录的路径,则必须使用OpenSSL附带的c_rehash实用程序处理该目录。
此可信CA的列表也可以通过REQUESTS_CA_BUNDLE环境变量指定。
如果verify设置为False,则请求也可以忽略对SSL证书的验证,代码如下。

默认情况下,verify设置为True。选项verify仅适用于主机证书。
可以指定本地证书作为客户端证书,可以是单个文件(包含私钥和证书)或一个包含两个文件路径的元组,代码如下。

上面的代码是每次发送请求都需要设定cert的路径,也可以设置持久的,只需要设置一次,以后可以直接使用,代码如下。

当登录12306时会提示用户安装证书。当访问有证书验证要求的站点时,就使用上面的代码。
如果指定了错误的路径或无效的证书,则Requests将抛出SSLError,代码如下。

提示
本地证书的私钥必须未加密。目前,请求不支持使用加密密钥。Requests默认附带了一套它信任的根证书,来自Mozilla trust store。然而,它们在每次Requests更新时才会更新。这意味着如果固定使用某一版本的Requests,则证书有可能已经太旧了。从Requests 2.4.0版之后,如果系统中装了certifi包,则Requests会试图使用它里面的证书。这样用户就可以在不修改代码的情况下更新他们的可信任证书了。
默认情况下,当发出请求时,会立即下载响应正文。可以覆盖此行为并推迟下载响应正文,直到使用参数访问该Response.content属性stream,代码如下。

此时只下载了响应头,并且连接保持打开状态,因此允许以有条件的方式进行内容检索,代码如下。

可以使用Response.iter_content()方法和Response.iter_lines()方法进一步控制工作流程。另外,也可以从底层urllib3读取未解码的urllib3.HTTPResponse的Response.raw。
如果在发出请求时设置stream为True,则请求无法将连接释放回连接地,除非消耗了所有的数据或调用了Response.close。这可能导致连接效率低下。如果在使用stream=True的同时还在部分读取请求正文(或根本没有读取请求正文),就应该在with声明中提出请求以确保它始终关闭,代码如下。

归功于urllib3,keep-alive在会话中100%自动保持连接,在会话中发出的任何请求都将自动重用相应的连接。
需要注意的是,只有在读取了所有正文数据后,才会将连接释放回连接池中以供重用,所以一定要设置stream为False或读取Response对象的content属性。
请求支持流式上传,允许发送大型流或文件而无须将其读入内存。要使用流式上传,只需提供一个类文件对象,代码如下。

请求还支持传出和传入请求的分块传输编码。要发送块编码请求,只需提供一个生成器(或任何没有长度的迭代器),代码如下。

对于分块编码请求,最好使用Response.iter_content()对其数据进行迭代。在理想情况下,必须设置stream=True,这样就可以通过调用iter_content并将chunk_size参数设为None,从而进行分块的迭代。如果要设置块的最大体积,则可以将chunk_size参数设置为任何整数。
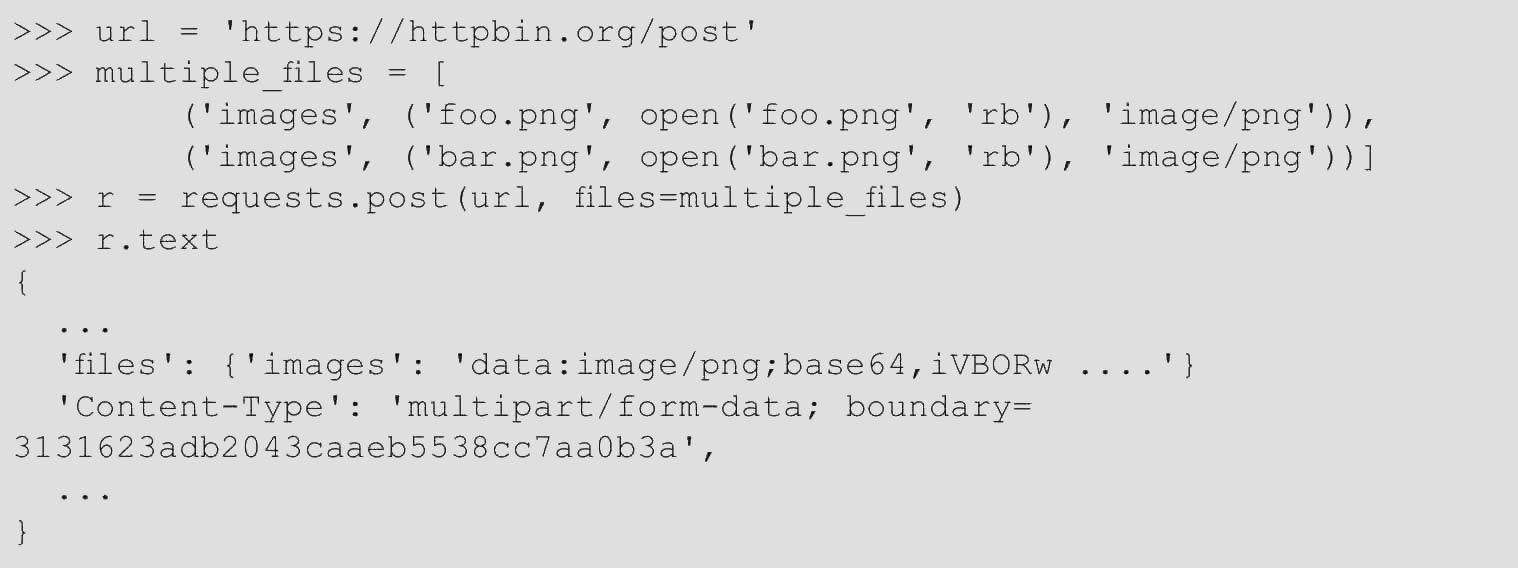
可以在一个请求中发送多个文件。例如,假设要将多个图像文件上传到一个HTML表单,可以使用一个多文件字段“images”,代码如下。

要实现,只需将文件设到一个元组的列表中,其中元组结构为(form_field_name, file_info),代码如下。
请求有一个钩子系统,可以使用它来操纵部分请求过程或信号事件处理。可以通过将字典传递给request参数来基于每个请求分配一个钩子函数,代码如下。

可以为单个请求添加多个挂钩,如一次调用两个钩子,代码如下。

还可以向Session实例添加挂钩。然后,每次向会话发出请求时,都会调用添加的任何挂钩,代码如下。

一个Session可以有多个钩子,它们将按照添加的顺序调用。
请求允许使用自己指定的身份验证机制。
任何作为auth参数传递给请求方法的可调用对象,都有机会在调度请求之前修改它。
自定义的身份验证机制是作为子类AuthBase来实现的,并且很容易定义。请求在requests.auth中提供了两种常见的身份验证方案:HTTPBasicAuth和HTTPDigestAuth。
例如,有一个Web服务,只有在X-Pizza标头设置为密码值时才会响应,代码如下。

然后,可以使用PizzaAuth提出请求,代码如下。

获取Response.iter_lines()后可以轻松地遍历流,代码如下。

当使用decode_unicode=True时,如果服务器没有提供编码,则需要设计编码,代码如下。

iter_lines不保证重进入时的安全性。多次调用此方法会导致某些接收的数据丢失。如果需要在多个位置调用它,就应该使用生成的迭代器对象,代码如下。

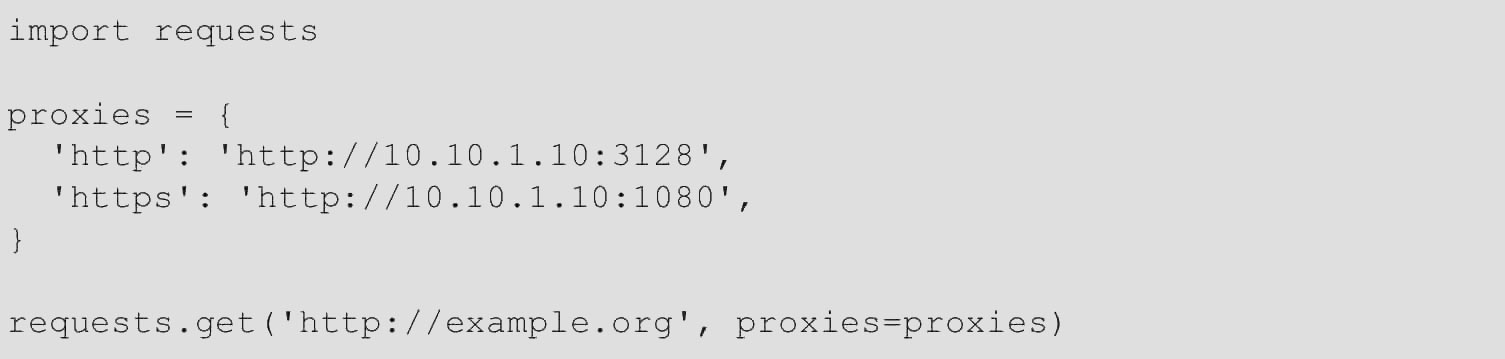
如果需要使用代理,则可以通过为任何请求方法提供proxies参数来配置各个请求,代码如下。
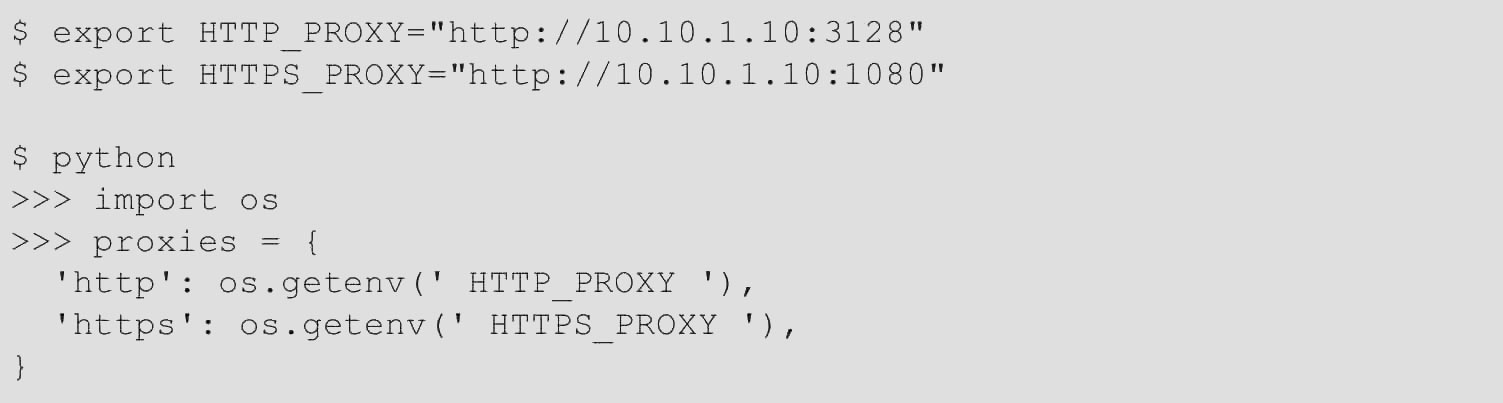
还可以通过环境变量HTTP_PROXY和HTTPS_PROXY来配置代理,代码如下。
如果代理需要使用HTTP Basic Auth,则可以使用http://user:password@host/syntax语法,代码如下。

许多Web服务都需要身份验证,并且有许多不同的类型。下面介绍请求中可用的各种身份验证形式。
许多需要身份验证的Web服务都接受HTTP Basic Auth。这是最简单的类型,并且Requests直接支持它。使用HTTP Basic Auth发出请求非常简单,代码如下。

事实上,HTTP Basic Auth很常见,以至于Requests提供了一种简写的使用方式,代码如下。

像这样在元组中提供凭证与前一个HTTP Basic Auth示例是完全相同的。
如果参数没有给出身份验证方法auth,则Requests将尝试从用户的netrc文件中获取URL主机名的身份验证凭据。netrc文件覆盖使用headers=设置的原始HTTP身份验证标头。如果找到主机名的凭据,则使用HTTP Basic Auth发送请求。
另一种非常流行的HTTP身份验证形式是摘要式身份验证,请求对它的支持也是开箱即用的,代码如下。

对于多个Web API,一种常见的身份验证形式是OAuth。requests-oauthlib库允许请求用户轻松进行OAuth 1身份验证请求,代码如下。

有关OAuth流程如何工作的更多信息,请参阅OAuth官方网站。
requests-oauthlib库还处理OAuth 2,这是支持OpenID Connect的身份验证机制。有关各种OAuth 2凭据管理流程的详细信息,请参阅requests-oauthlib OAuth 2文档。
请求旨在允许轻松快速地插入其他形式的身份验证。开源社区的成员经常为更复杂或不太常用的身份验证形式编写身份验证处理程序。在请求组织下汇集了一些最好的,包括Kerberos和NTLM。
如果想使用这些形式的任何一种身份验证,则可以直接访问它们的GitHub页面并按照说明进行操作。
如果无法找到所需的身份验证形式的良好实现,则可以自己实现它。请求可以轻松添加自己的身份验证形式。
要想实现,可以从AuthBase继承一个子类,并实现__call__()方法,代码如下。

当身份验证处理程序附加到请求时,将在请求设置期间调用该处理程序。因此,__call__()方法必须执行使身份验证生效所需的任何操作。某些形式的身份验证还会添加挂钩以提供进一步的功能。