
下载掌阅APP,畅读海量书库
立即打开



回顾一下,x64架构兼容传统的32位保护模式。在保护模式下,可以拥有32位的线性地址空间,或者叫虚拟地址空间。32位的线性地址要通过分页转换为物理地址,可以使用32位4KB分页方式、32位4MB分页方式、32位PAE-4KB分页方式和32位PAE-2MB分页方式。
x64架构有自己新增的IA-32e模式,这种模式具有64位的线性地址空间,或者叫虚拟地址空间。为了将64位线性地址转换为物理地址,还引入了新的4级和5级分页方式。
在IA-32e模式下,段部件输出的是64位线性地址。而且,在IA-32e模式下,必须开启分页,分页功能并不是可选的,而是必须开启的,这是硬性要求。所以,这64位的线性地址也是虚拟地址,对应着虚拟内存空间。
64位的线性地址,其范围是从0到0xFFFF FFFF FFFF FFFF(16个F),一共是多大的虚拟内存空间呢?答案是16EB,非常巨大,在可以预见的将来根本用不完,所以需要考虑处理器的制造成本。将64位虚拟地址转换为物理地址,我们的分页系统会很复杂,至少需要6个转换表(见图2-17)。
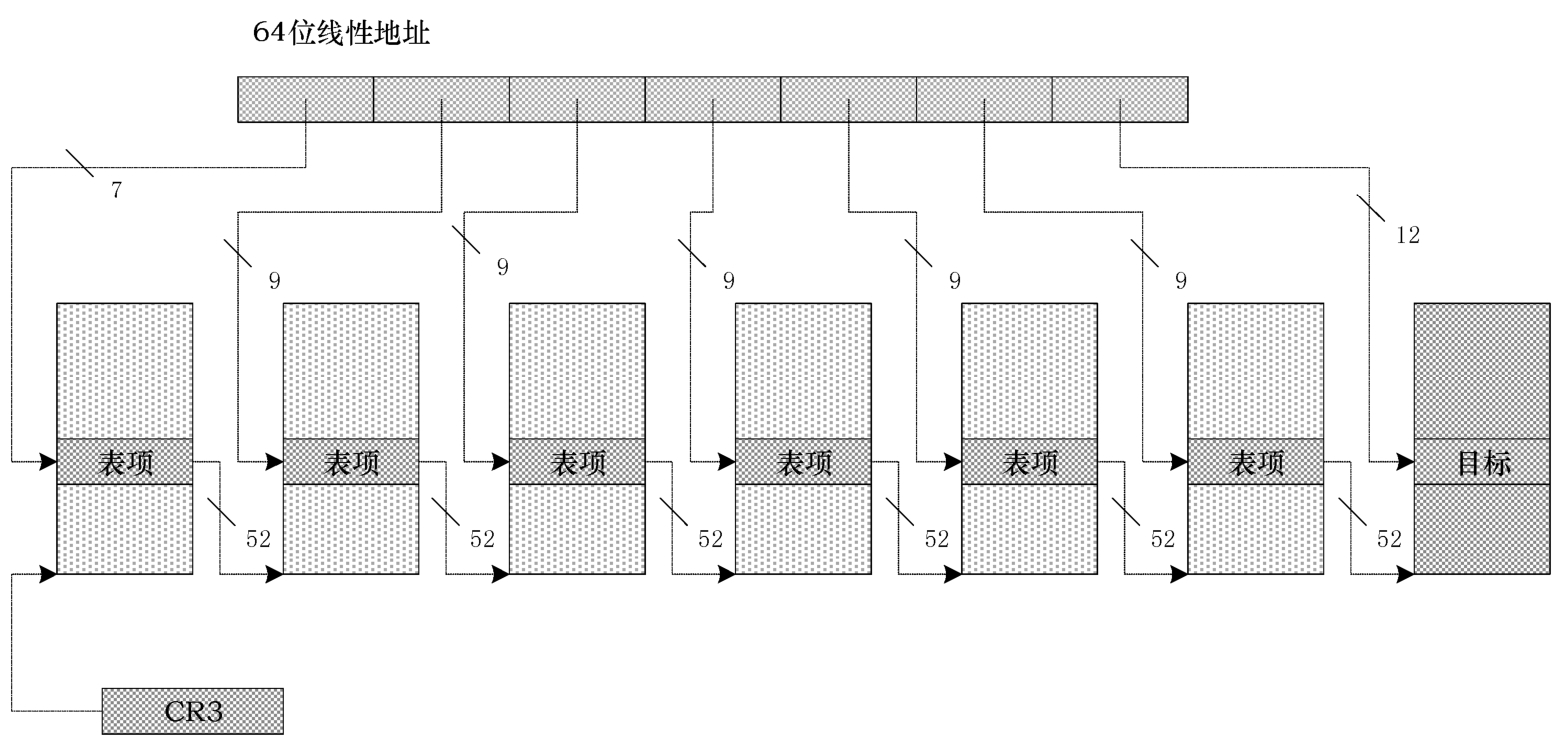
图2-17 技术(理论)层面上的64位4KB分页原理
假定我们要实现一个64位的4KB分页系统,那么,如图2-17所示,64位线性地址的最低12位用来充当页内偏移。
在任何一种形式的分页系统中,每个表格的尺寸都是标准的4KB。为了生成指向下一个表格的52位物理地址,它们的表项至少有64位。因此,每个表格只能有512个表项,需要使用线性地址中的9比特来定位每个表项。
如此一来,就至少需要6个表格,这样的分页系统很复杂。既然我们用不到那么大的线性地址空间,而且制造这样复杂的分页系统成本很高,需要设计复杂的电路,那就不如节省一点,简化一下。
为了平衡处理器的制造成本、硬件复杂性和当时业界对内存的实际需求,对于x64架构的处理器来说,64位的线性地址不需要全都使用,实际有效的部分只有48位。换句话说,在64位线性地址中,只有低48位(位0到位47这一部分)是有效的。这是一个特别选择的长度,兼顾了处理器的制造成本、硬件复杂性和当时业界对内存的实际需求。即使是只有48位的线性地址,也将提供256TB的虚拟地址空间,并且只需要4个级别的分页系统表格。在未来的许多年内,即使是最强大的电脑也用不上如此巨大的内存空间。
既然64位线性地址的低48位是有效的,那么,高16位是什么呢?原则上可以不用管它,它们可能是一些随机值。但是处理器实际上不是这样设计的,它要求64位线性地址必须符合扩高(Canonical)形式。
扩高形式要求线性地址的高16位必须是最高有效位的扩展。因为64位的线性地址只有低48位有效,最高有效位是第48位,或者说位47。所以,线性地址的高16位必须是位47的扩展。如果位47是0,则将这个0扩展到高16位;如果位47是1,则将这个1扩展到高16位。
这里有两个例子,如图2-18所示,这是两个64位的线性地址。在图中,上面这个线性地址的位47是0,要将这一位扩展到高16位,所以高16位是全零。这个线性地址用十六进制表示,是0x00003FE0012F72D8。
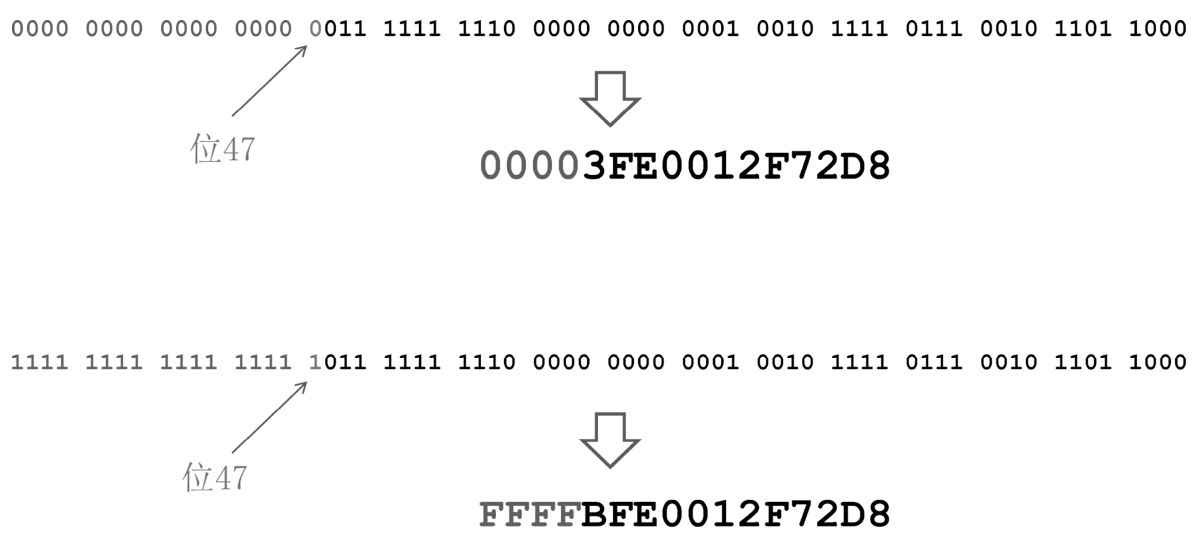
图2-18 扩高地址的例子
相反,在图中,下面这个线性地址的位47是1,要将这一位扩展到高16位,所以高16位是全1。这个线性地址用十六进制表示,是0xFFFFBFE0012F72D8。
那么,为什么非得使用扩高地址呢?在设计x64架构时,AMD公司的工程师们本可以让处理器忽略线性地址的高16位。但是,程序员都是一些喜欢探索、无孔不入的人,他们中的有些人肯定会利用这个位置来保存某些信息。
但是,如果未来的新处理器决定将地址空间扩展到更多位,这些小聪明和小技巧就不好使了。如果这些软件用在很重要的场合,就会导致严重的问题。为了防止这种情况,工程师们决定引入扩高地址,线性地址的高16位必须和位47相同。
扩高地址是强制性的,处理器在进行地址转换时,会检查一个线性地址是否符合扩高形式。如果一个线性地址不是扩高形式,将引发一般保护异常。
如图2-19所示,由于扩高地址的特点,它把整个64位线性地址空间分成了三部分。从0到0x0000 7FFF FFFF FFFF的这一部分线性地址是规范的,毕竟高16位都是位47的扩展,是合法的线性地址范围,所以这一部分线性地址空间是可用的。
但是,从0x0000 8000 0000 0000到0xFFFF 7FFF FFFF FFFF的这一部分线性地址是不符合要求的,高16位并不是位47的扩展,是非法的线性地址范围。所以这一部分线性地址空间是不能用的。
再往上,从0xFFFF 8000 0000 0000到0xFFFF FFFF FFFF FFFF的这一部分,又是符合要求的,高16位都是位47的扩展,是合法的线性地址范围,所以这一部分线性地址空间是可用的。

图2-19 扩高地址的空间分布特点
像保护模式下的虚拟内存管理一样,在x64架构中,每个任务都有自己独立的64位线性地址空间。在实际的编程工作中,我们可以把所有任务共有的全局部分放在图2-19的上面这一部分,把每个任务私有的部分放在图2-19的下面这一部分,在本书中我们就是这样做的。
顺便说一下为什么将Canonical翻译成“扩高”。这个单词通常被翻译成“规范的”和“标准的”。我原先想翻译成“教条”“规范”或者“标准”,但是都不贴切。如果要表达这些意思,还有更好的英语单词,而不必使用Canonical。正因如此,很多中文书里都回避翻译这个词,而是直接使用它的英文单词。
实际上,在很多时候,使用这个单词其实是要表达“非二选一”的意思。就是说,因势利导,而不是在两种之间选一个。
那么,对于线性地址,非二选一是什么意思呢?为了防止程序员自作聪明,线性地址的高16位必须是一样的。在这种情况下,如果要二选一,线性地址的高16位可以统一设置为全0,线性地址的范围是从0x0000 0000 0000 0000到0x0000 FFFF FFFF FFFF;当然,可以统一设置为全1,线性地址的范围是0xFFFF 0000 0000 0000到0xFFFF FFFF FFFF FFFF。
实际上,这里并不是二选一的,而是根据最高有效位进行扩展。所以,官方使用这个单词,就是要表达这样一种情况。
那么,如何翻译才能表达“非二选一”呢?很难,几乎找不到合适的中文词组。我就在想,Canonic,读音听起来像“克闹”,又与“扩高”接近。扩高!扩展高位,扩展最高有效位!“扩高”就这么来的。这是一种音译,用发音来翻译,还能准确表达意思。
前面说过,x64架构支持传统模式,但它还有自己新增的IA-32e模式。我们在前面说过,IA-32e模式包括两个子模式:兼容模式和64位模式。需要说明的是,在IA-32e模式下分页不是可选的,是必须开启的,而且只能使用4级或者5级分页。
先来看兼容模式下的内存访问过程,如图2-20所示。兼容模式用于运行传统的保护模式程序。在兼容模式下,段寄存器用来选择一个段描述符,然后从描述符中取出段的32位线性基地址。
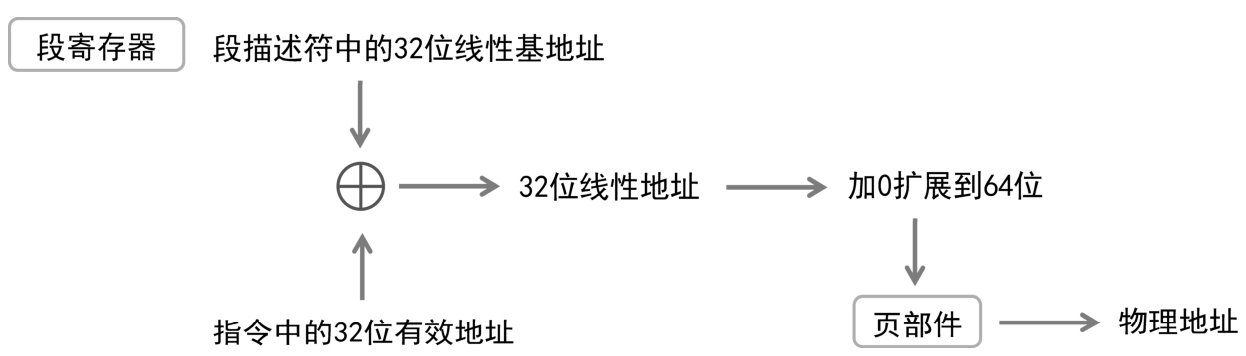
图2-20 兼容模式下的内存访问
访问内存的时候,处理器用这个32位的线性基地址加上指令中的32位有效地址,形成32位的线性地址。进一步地,段部件将这个32位线性地址左侧加0,扩展到64位,然后送到页部件,由页部件转换为物理地址。物理地址的长度取决于处理器。
从这个转换过程可以看出,由于是将32位线性地址左侧加0扩展到64位,所以,在兼容模式下,只能访问4GB的虚拟内存,这和传统的保护模式是一样的。
注意,在兼容模式下,页部件使用新的4级分页机制来转换64位的线性地址,而不是传统的分页机制。分页机制的变化不会对程序的运行有任何影响,毕竟如何分页是操作系统和处理器的事情,应用程序工作在操作系统之上,对底层使用什么分页方式没有任何感知。
最后来看64位模式,如图2-21所示。在64位模式下分段功能被禁止,但并不是完全禁止,而是只分一个段。因为不再分段,所以整个64位的线性地址空间被整体使用。换句话说,在64位模式下,由处理器硬件强制使用平坦模型。
在64位模式下,除了FS和GS,其他段寄存器,包括CS、DS、ES和SS,它们的基地址和段界限部分都被忽略,处理器直接将它们的基地址看成0。因此,除非是在指令中使用了段超越前缀FS和GS,访问内存的时候,处理器直接用0作为段的线性基地址,加上指令中的64位有效地址,形成64位的线性地址,送到页部件转换为物理地址。物理地址的长度取决于处理器。
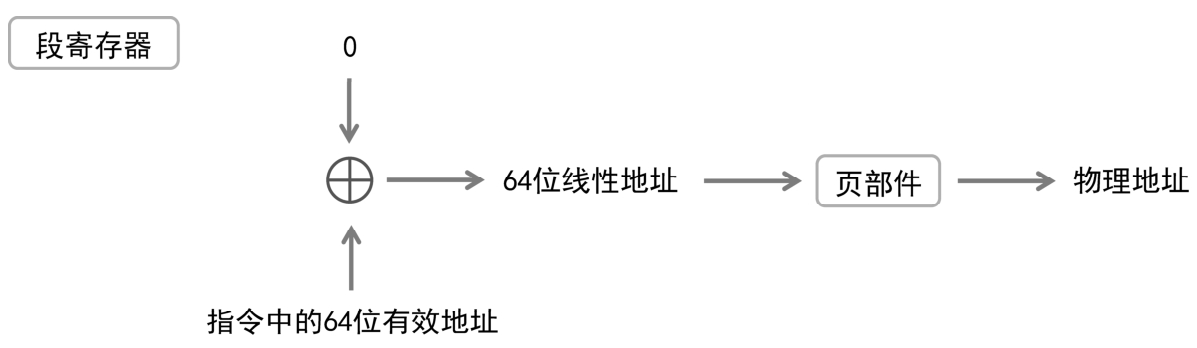
图2-21 64位模式下的内存访问
显然,在64位模式下,段部件输出的线性地址等于指令中指定的有效地址。而且需要注意的是,64位线性地址必须符合扩高形式,否则将产生一般保护异常。线性地址的转换是使用4级或者5级分页将扩高形式的64位线性地址转换为物理地址。有关4级或者5级分页机制的细节,我们将在后面详细介绍。
和IA-32架构的处理器一样,x64架构的处理器依然有6个段寄存器,分别是CS、DS、ES、FS、GS和SS。其中,CS用来执行代码;SS用来执行栈操作;其他4个段寄存器DS、ES、FS和GS用来访问数据。和IA-32架构一样,在每个段寄存器的后面,还有一个隐藏的部分,叫作段描述符高速缓存器,保存着段的线性基地址、界限值和属性。
x64架构的处理器兼容实地址模式。在实地址模式下,段寄存器用于加载一个16位的逻辑段地址,处理器将这个段地址左移4位,形成20位的地址,并加0扩展到32位,保存在段寄存器的隐藏部分,用于后续的内存访问。
x64架构的处理器兼容保护模式。在保护模式和兼容模式下,段寄存器用于加载一个16位的段选择子。处理器用段选择子到描述符表中选择一个段描述符,将描述符的内容加载到段寄存器的隐藏部分,其中包括段的32位线性地址和长度。
在兼容模式下,段寄存器的使用方法和保护模式一样,不再重复;在64位模式下,强制使用平坦模型,分段功能被禁止,但不是完全禁止,段部件还起作用,其特点如下。
在64位模式下,段寄存器CS的基地址部分被忽略并视为0,段界限及很多属性都被忽略并不再检查(除了DPL、L和D等标志),但是要检查有效地址是否为扩高形式。在指令中,段超越前缀“CS:”不起作用。例如:
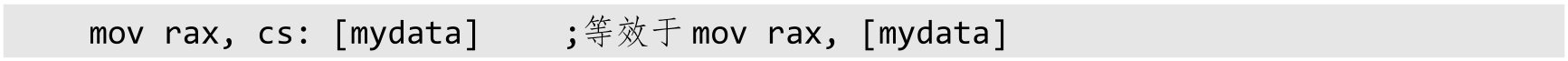
在64位模式下,段寄存器DS、ES和SS不再使用。因此,相关的指令,比如lds和pop es等,不再有效。如果访问内存时使用了这些段寄存器,则按段的基地址为0来对待,而且不检查段界限和属性,只检查生成的虚拟地址是否符合扩高形式。在指令中使用这些段寄存器作为段超越前缀不起作用。例如

在64位模式下,段寄存器FS和GS的基地址部分依然用于地址计算,而不是直接看成0,而且它们的基地址部分用特殊的方法扩展到64位。常规的段寄存器加载指令,比如mov fs,ax或者pop gs,只能操作基地址的低32位,高32位被自动清零,因此只能使用特殊的方法才能加载全部的64位段基地址。具体是什么方法,我们以后再讲。使用这两个段寄存器访问内存时,不检查界限值和属性,但是要检查生成的线性地址是否符合扩高形式。
我们已经学过保护模式的课程,在保护模式下采用分段的内存访问机制,段描述符用来对代码段和数据段进行管理。
如图2-22所示,这是代码段描述符的格式,因描述符较长,分为两个双字。高双字在上,低双字在下。在代码段描述符中,S位,也就是高双字的位12,是1,表明这是一个存储器的段描述符;X位,也就是高双字的位11,是1,表明段是可执行的。
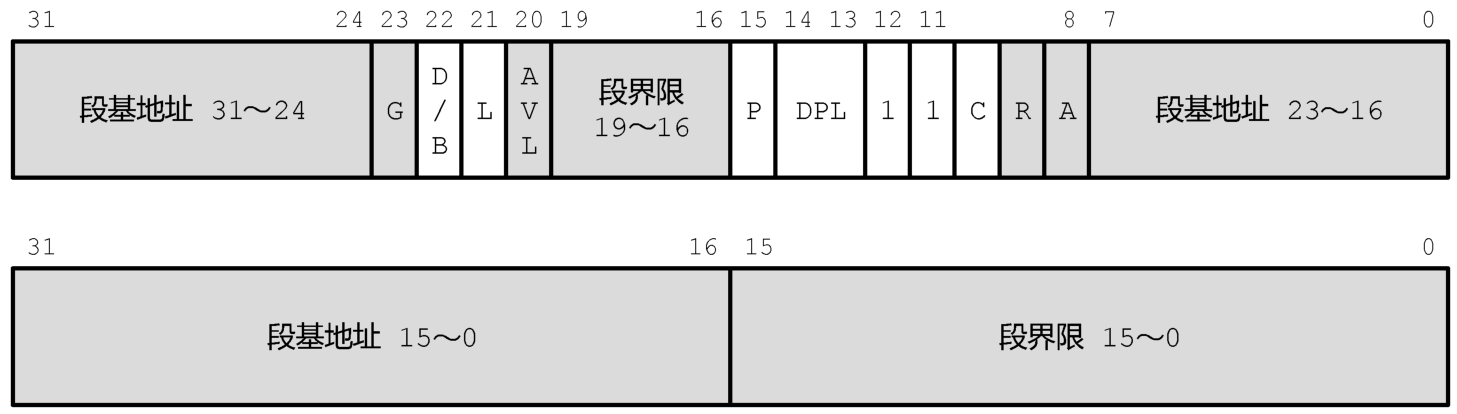
图2-22 代码段描述符
在传统的保护模式下,高双字的位21是保留的,没有使用,要求为0。但是在x64架构新增的IA-32e模式下,这一位叫L位,被用作长模式(Long mode)的标志。只在当处理器运行在IA-32e模式的时候,才能识别和利用这一位。在传统模式看来,L位是无用的,应当为0。
在IA-32e模式下,如果代码段描述符的L位是0,则处理器运行在兼容模式下,执行保护模式的代码。在兼容模式下,处理器对代码段描述符的解释和执行的动作与传统的保护模式相同,不再赘述。如果代码段描述符的L位是1,则处理器按64位模式执行。在64位模式下,分段功能被禁止,但不是完全禁止。代码段寄存器CS依然被用于取指令和执行指令,与之相关的代码段描述符依然是需要的,但很多内容已经被忽略。
如图2-22所示,在64位模式下访问内存时,灰色部分不再使用。不过,在加载段寄存器CS时,这些内容依然会被加载到段描述符高速缓存器,而且要检查高双字的位12和位11,这两位必须是“11”,代表代码段描述符。但是,段基址和段界限被忽略,段基址被直接视为0,段的长度被扩展到整个线性地址空间,所以不再检查段界限,而且G位也被忽略。
和从前一样,代码段中的D位是默认操作尺寸,用来指定处理器执行当前代码段时默认使用的操作尺寸。这一位在保护模式下是有效的,在兼容模式下,即,在L=0的情况下也是有效的。
但是在64位模式下,D位必须始终为0。L=1和D=0的组合使得在64位模式下默认的操作尺寸为32位,默认的地址尺寸为64位,这是64位模式的执行特点;L=1和D=1的组合留给将来使用。
如图2-23所示,这是数据段描述符的格式。因为段描述符较长,所以这里将其分为两个双字。高双字在上,低双字在下。在描述符中,高双字的位12是1,表明这是一个存储器的段描述符;高双字的位11是0,表明段不可执行,不可执行就是只能用来访问数据。因此,高双字的位12和位11合起来是“10”,表明这是一个数据段描述符。
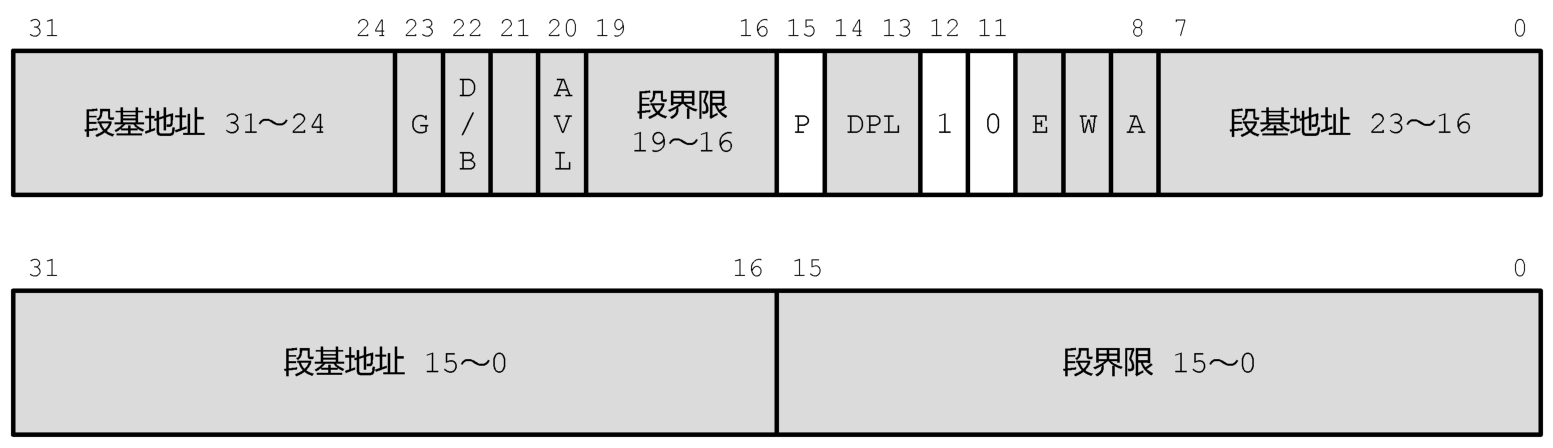
图2-23 数据段描述符
在兼容模式下,处理器对数据段描述符的解释和使用与传统的保护模式相同,不再赘述;在64位模式下,分段功能被禁止(但不是完全禁止,只不过只分一个段),所以如图2-23所示,灰色的部分不再使用。
在64位模式下,对于通过段寄存器DS、ES和SS的内存访问来说,描述符中的段基地址部分被忽略,直接用0作为段基地址;不再检查段界限,所以界限值和G位被忽略;B、E、W和A位被忽略,不再使用;DPL字段被忽略,并且针对数据段访问的特权级检查也不再执行,系统软件可以使用页保护机制来防止未经授权的数据访问。
在64位模式下,对于通过段寄存器FS和GS的内存访问来说,描述符中的段基地址不会被忽略,而是依然用于虚拟地址计算。我们知道,在IA-32模式下,使用64位的线性地址,或者说虚拟地址,但是FS和GS只能从数据段描述符中得到32位的基地址,无法得到全部的64位基地址。要想指定64位的段基地址,必须通过特殊的方法,我们在本书的后面再聊这个话题。
需要特别说明的是,在64位模式下,栈段不再是一个特殊的段,系统强制我们用普通的数据段(向上扩展的段)作为栈段,而且段的基地址为0,不检查段界限。但是,栈的操作机制没有改变,也不会改变,栈依然是向下推进的。在64位模式下,栈操作的尺寸是64位的。
在前面我们已经回顾了32位分页机制,在今天看来,32位的线性地址空间和物理地址空间都已经严重不足,所以在x64架构的IA-32e模式下使用4级和5级分页机制。在4级分页机制下,支持多个尺寸的物理页面。我们以4KB的物理页为例,如图2-24所示,因为最终的物理页是4KB的,所以,要用线性地址的最低12位作为页内偏移。
4级分页机制的特点是,被转换的线性地址只有48位。48位已经用了12位,还剩36位。这36位分成4个9位,分别用来访问4个表格内的表项。这4个表格是页表、页目录表、页目录指针表和4级头表。每个表只能占用一个4KB的自然页面,表项的尺寸是64位的。这样一来,在每个表内只能有512个表项,正好用线性地址中的9个比特来定位全部表项。
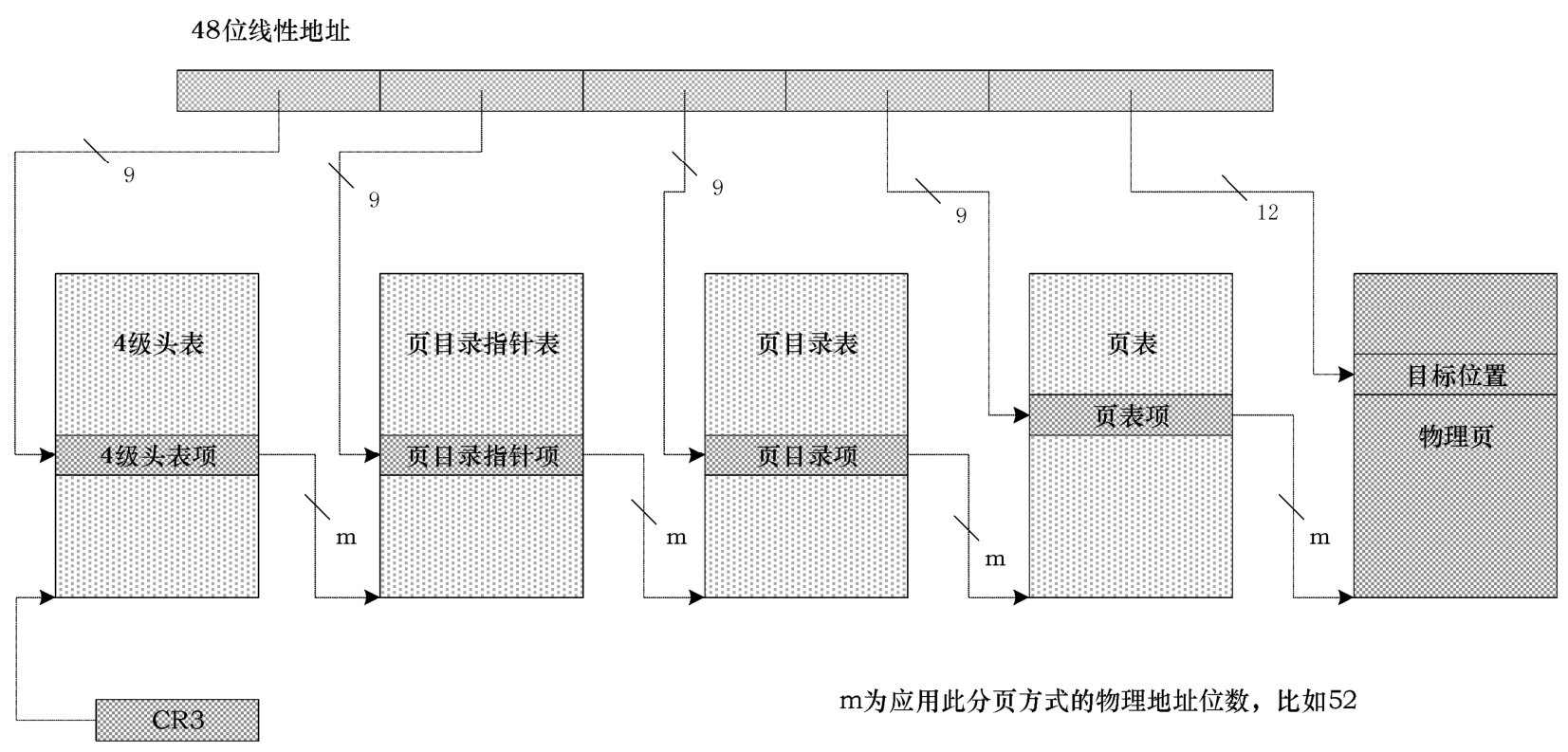
图2-24 IA-32e模式的4级分页示意图
如图2-24所示,线性地址的转换过程是这样的:CR3指向4级头表,在48位线性地址中,先用第一个9比特从4级头表中选择对应的4级头表项,从中得到页目录指针表的物理地址。
然后,再从48位线性地址中取出第二个9比特,从页目录指针表中选择对应的页目录指针项,从中得到页目录表的物理地址。
接着,再从48位线性地址中取出第三个9比特,从页目录表中选择对应的目录项,从中得到页表的物理地址。
最后,从48位线性地址中取出第四个9比特,从页表中选择对应的页表项,从中得到最终要访问的那个页的物理地址。
目前,在IA-32e模式下普遍采用的是4级分页机制。但是截至本书开始创作时,已经出现了可以支持5级分页机制的处理器。比如,最新的INTEL至强第三代“冰湖”处理器支持5级分页,AMD公司也在它们的下一代霄龙7004处理器中提供5级分页支持。
在处理器中,控制寄存器CR4的位12叫作LA57(意思是57位线性地址),为0表明处理器采用4级分页,为1表明处理器采用5级分页。这一位不可修改,而且只能在64位模式下读取。
通过5级分页,虚拟地址从48位扩展到57位,虚拟内存从256TB增加到128PB,处理器的物理地址增加到52位,这种5级分页支持对于当今日益强大且内存密集型的服务器非常重要。
如图2-25所示,这就是5级分页示意图,其实是在4级分页的基础上增加了一个5级头表,被转换的线性地址是57位的,其他方面没有什么变化。
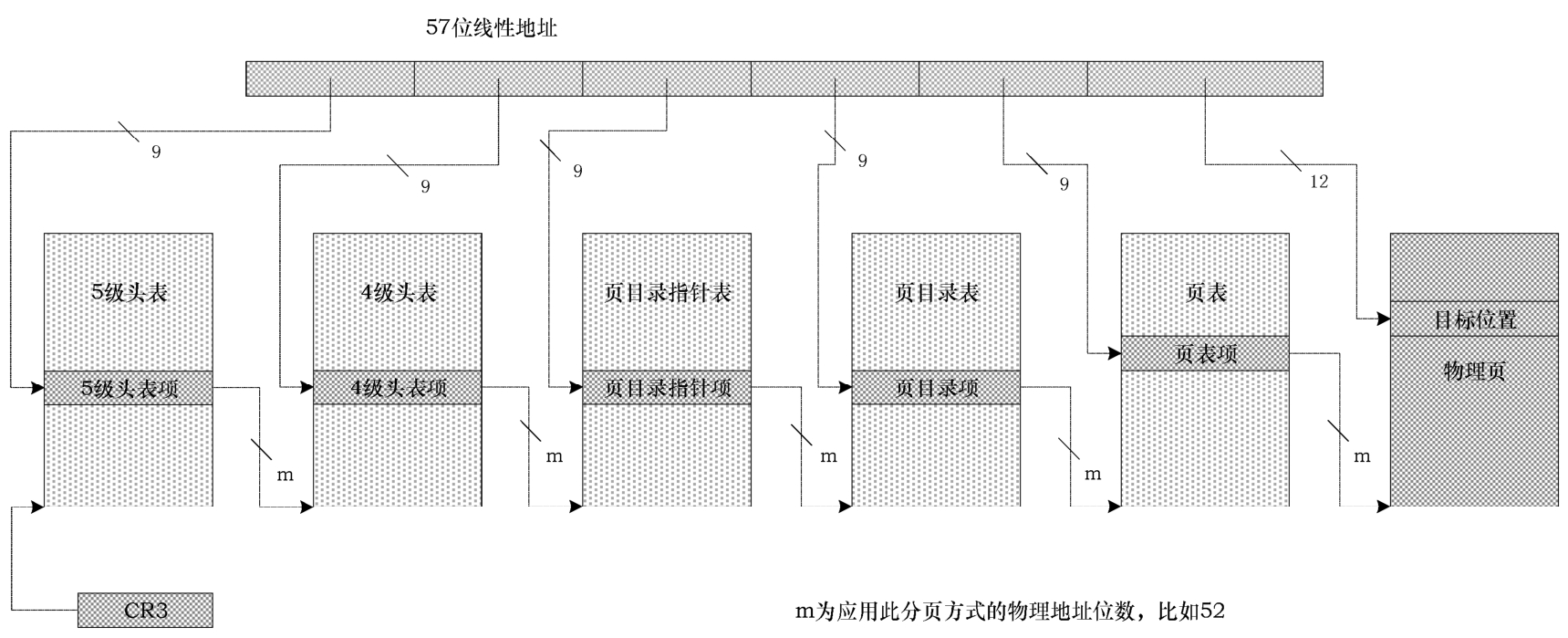
图2-25 IA-32e模式的5级分页示意图