
下载掌阅APP,畅读海量书库
立即打开



AMBA规范是一种开放式标准片上互联规范,用于连接和管理SoC中的功能单元/功能模块。它有助于首次开发具有大量控制器和外围设备的多处理器设计。AMBA通过为SoC功能单元/功能模块定义通用接口标准来促进设计重用。
AMBA是一种广泛用于SoC设计的架构,可在芯片总线中找到它。AMBA规范用于设计高级嵌入式微控制器。AMBA的主要目标是提供技术独立性并鼓励模块化系统设计。更进一步,它强烈鼓励开发可重用的外设,同时最大限度地减少硅基础设施。
简言之,它是用来在芯片中将功能单元/功能模块连接在一起的接口。
还有一些和AMBA相关的缩略词,如AHB或AXI。表2.1列出了对其中7个主要接口的相关说明。
表2.1 AMBA中的7个主要接口的相关说明
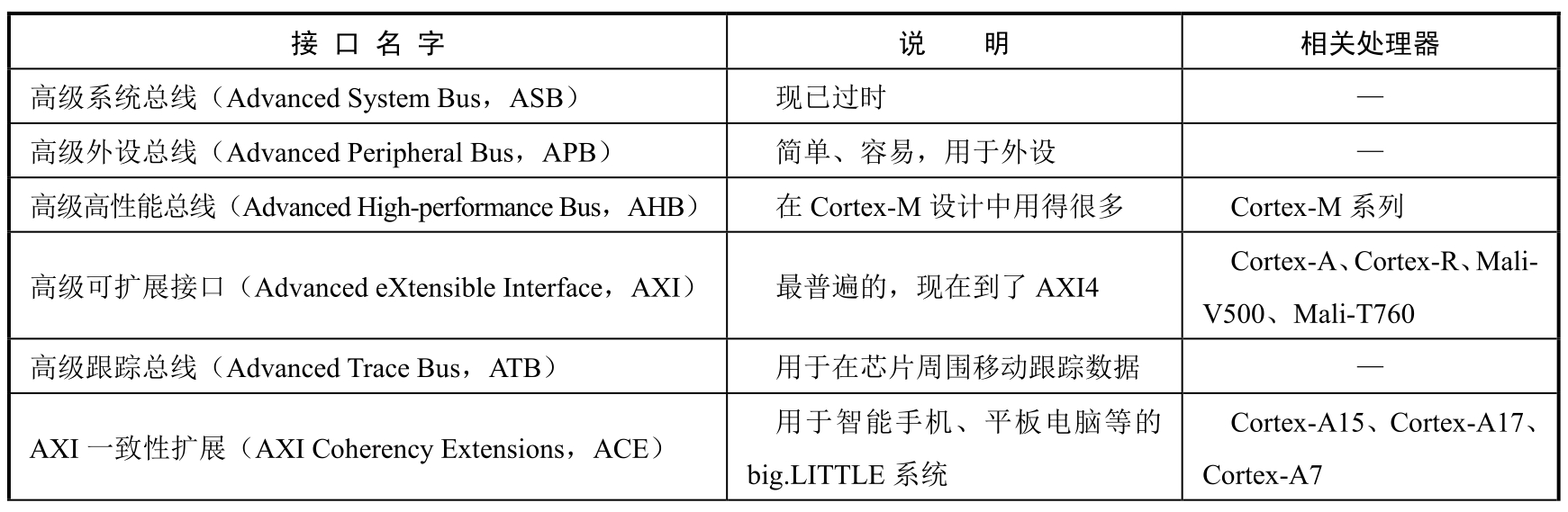
续表

既然它是一个标准,那么它又是怎么一步步出现的呢?AMBA可一直追溯到1995年,那时Arm公司的规模比较小,获得了来自欧盟的一些资金。借助欧盟的支持,AMBA于1996年作为开放式架构推出。尽管AMBA的名字指向微控制器,但是其功能远远超出了微控制器。现在,AMBA广泛应用于各种ASIC和SoC器件中,包括应用处理器,这些处理器通常存在于智能手机等现代便携移动设备中。
AMBA很快就变成了Arm公司的注册商标。SoC的一个重要方面不仅包括它所包含的组件或块,还包括它们互联的方法。AMBA很快成为将控制器或外设IP块推向市场的“事实上的”标准接口。
AMBA 1是AMBA的第一个版本,包括两个总线,即ASB和APB。
在AMBA 2中,增加了AMBA AHB,它是一个单时钟沿协议。AMBA 2广泛应用于基于Arm7和Arm9的设计,至今仍用在基于Arm Cortex-M的设计中。
(1)AMBA 2 AHB接口规范。
AMBA 2 AHB接口规范可在单一频率系统中实现主设备之间的高效率互联。该接口包括AMBA 3 AHB接口的所有功能,但也允许构造中的主设备之间使用仲裁功能。
(2)AMBA 2 APB接口规范。
AMBA 2 APB接口规范支持通过低带宽进行交易,用于访问外设中的寄存器和通过低带宽外设的数据流量。这个高度紧凑的低功耗接口将该数据流量与高性能AMBA 2 AHB互联隔离开来。
2003年,Arm公司推出AMBA 3,包括AXI,以实现更高性能的ATB,作为CoreSight片上调试和跟踪解决方案的一部分,它具体包括以下几部分。
(1)AMBA 3 AXI:提供支持高效数据流量吞吐量的特性。它在5个单向通道之间具有灵活的相对时序,还具有无序数据功能的多个未完成交易,可用于高速操作的流水线互联、电源管理的频率之间的高效桥接、同时地读和写交易,以及高效地支持高初始延迟外设。
(2)AMBA AHB:在单一频率子系统中的简单外设之间使能高效互联,而不需要AMBA 3 AXI性能,其固定的流水线结构和单向通道可与AMBA 2 AHB-Lite规范开发的外设兼容。
(3)AMBA 3 APB:支持用于访问外设的低带宽交易,用于访问外设的配置寄存器和通过低带宽外设的数据流量。高度紧凑的低功耗接口将该数据流量与高性能的AMBA 3 AHB和AMBA 3 AXI互联隔离开来。AMBA 3 APB接口完全向后兼容AMBA 2 APB接口,允许使用现有的APB外设。
(4)AMBA 3 ATB:将用于跟踪系统中跟踪数据的不可知接口添加到AMBA规范中。跟踪组件和总线与外设和互联资源并联,为调试提供可视化功能。
2010年,AMBA 4规范从AMBA 4 AXI4开始引入,并在2011年扩展了与AMBA 4 ACE的系统一致性(该系统一致性允许不同的处理器集群共享并支持Arm的big.LITTLE处理等技术)。这些都广泛用于Arm Cortex-A9和Cortex-A15处理器。
1.性能
1)支持缓存一致性和强化的顺序
ACE使能处理器侦听其他缓存。ACE-Lite使能媒体和I/O主设备侦听并保持与处理器缓存的一致性。
2)时钟频率
AMBA 4规范允许实现通过在不损失吞吐量的情况下进行轻松重定时来实现更高的时钟频率(采用点到点的通道架构)。
3)全局异步本地同步
AMBA 4规范支持全局异步本地同步(Globally Asynchronous Local Synchronous,GALS)技术,用于大量带有不同频率的时钟域,轻松添加寄存器级以实现时序收敛。
2.架构
分离的通道架构通过充分利用深度流水线的SDRAM存储器系统来提高吞吐量。
(1)基于猝发的交易,仅发布起始地址。
(2)发布多个未完成的地址。
(3)完成乱序交易。
(4)具有单独的地址/控制和数据阶段。
3.内容
1)ACE
AMBA 4规范增加了3个额外的通道,用于在ACE主缓存和缓存维护的硬件控制之间共享数据。ACE也增加了屏障支持,以强制执行多个未完成交易的排序,从而最大限度地减少等待前一个交易完成的CPU停止时间。分布式虚拟存储器(Distributed Virtual Memory,DVM)信令维护跨多个主设备的虚拟存储器映射。
2)ACE-Lite
ACE-Lite是ACE信号的一小部分,提供I/O或单向一致性,其中ACE主设备维护ACE-Lite主设备的缓存一致性。ACE-Lite主设备仍然侦听ACE主设备的缓存,但是其他主设备无法侦听ACE-Lite主设备的缓存。ACE-Lite也增加了屏障支持。
3)AXI4
AXI4规范是对AXI3规范的更新,用于在多个主设备使用时提高互联的性能和利用率。它包括以下增强功能。
(1)支持的猝发长度最多为256拍。
(2)服务信令质量。
(3)支持多个区域接口。
4)AXI4-Lite
AXI4-Lite协议是AXI4协议的一个子集,用于与组件中更简单、更小的控制寄存器接口进行通信。AXI4-Lite接口的主要功能如下。
(1)所有交易都是一个猝发长度。
(2)所有数据访问的大小与数据总线的宽度相同。
(3)不支持抢占式访问。
5)AXI-Stream
AXI-Stream协议用于从主设备到从设备的单向数据传输,显著节省了信号布线资源。该协的关键特性如下。
(1)支持同一组共享线路的单个或多个数据流。
(2)支持在同一互联中的多个数据宽度。
(3)非常适合在FPGA中实现。
6)LPI
Q通道和P通道的LPI设计用于管理SoC组件的时钟与电源功能。LPI协议的主要特点如下。
(1)Q通道用于管理自主的分层时钟门控和简单组件的功耗控制功能。
(2)P通道用于管理更复杂的电源控制功能,以提高电源效率。
2013年,引入了AMBA 5 CHI规范,重新设计了高速传输层,旨在减少拥堵。它的架构为了提升可扩展性,以便在组件数量和流量增加时保持性能。这包括在主设备中放置额外的要求以响应相干的侦测交易,这意味着在一个拥堵的系统中可以更容易地保证特定主设备的前进进度。将识别机制分离为主设备标识符和交易标识符,允许以更高效的方式构建互联。AMBA 5架构用于连接完全相干的处理器的接口,如Cortex-A57和Cortex-A53。
1.自适应流量概要
自适应流量概要(Adaptive Traffic Profile,ATP)是一个新的综合流量框架,能够以简单和可移植的方式对系统主设备和从设备高级存储器访问行为进行建模。
流量概要能够用于跨多个工具和设计/验证环境,以帮助设计和验证复杂的SoC。在其他用例中,流量概要实现更简单和更快速的仿真机制,同时具有可预测性和自适应性。
2.AMBA 5 CHI
AMBA 5 CHI规范定义了用于连接完全相干的处理器(如Cortex-A75和Cortex-A55)和动态存储器控制器(如CoreLink DMC-620)接口,以实现高性能和非阻塞互联,如CoreLink CMN-600。它适用于需要一致性的各种应用,包括移动、网络、汽车和数据中心。
该规范将协议和传输层分开,以允许不同的实现,提供在性能、功耗和面积之间的最佳权衡。这种分离允许互联设计范围从一个高效的、小的交叉开关阵列增大到高性能的、大规模的网状网络。
该协议也提供QoS机制以控制系统中多个处理器共享资源的方式,而无须详细了解每个组件,以及它们交互的方式。
AMBA 5 CHI规范当前可供集成SoC或开发IP的合作伙伴或实现它的工具使用。请联系ARM账户经理获取有关副本的详细信息。
新一代、高性能的AMBA 5接口称为CHI,旨在提供从移动电话到高性能计算应用的任何设计点的高性能。它的一些功能如下。
(1)支持多个处理器之间高频率和无阻塞的相干数据传输。
(2)一个分层模型,允许为灵活的拓扑分离通信和传输协议,如交叉开关阵列、环形、网格或ad hoc。
(3)缓存存储,允许加速器或I/O设备将关键数据保存在CPU缓存中,实现低延迟访问。
(4)远程原子操作使能互联执行对共享数据的高频率更新。
(5)端到端的数据保护。
3.ACE5、ACE5-Lite和AXI5
AXI和ACE协议已经被用在各种应用(包括移动、消费、网络、汽车和嵌入式应用)中,实现高频率和高带宽的互联设计。ACE5、ACE5-Lite和AXI5协议扩展了前几代,包括大量性能和可扩展特性,对齐和补充CHI。
一些新特性和选项如下。
(1)原子交易。
(2)缓存存储。
(3)数据保护和毒化信令。
(4)Armv8.1分布式虚拟存储器消息。
(5)服务质量接受信令。
(6)持久性的缓存维护操作(Cache Maintenance Operation,CMO)。
(7)缓存回收交易。
新规范可供下载,包括所有ACE5和AXI5协议变种的完整更新列表与新的可用功能。
4.AHB5
AHB5架构规范广泛用于Cortex-M处理器的接口协议,用于嵌入式设计和其他低延迟SoC。
AHB5建立在上一代AHB-Lite规范的基础上,它有以下两个主要目标。
(1)补充了Armv8-M架构,并将TrustZone安全基础从处理器扩展到整个系统。
(2)实现了与AXI4规范的一致性和对齐,包括在SoC中简化了基于Cortex-A和Cortex-M的系统集成,允许包含AXI和AHB系统的统一TrustZone安全解决方案。
规范中引入的新特性如下。
(1)地址阶段安全/非安全信令,以支持安全或非安全交易。
(2)扩展的存储器类型,用于支持更复杂的系统。
(3)抢占传输支持信号量类型的操作。
由于AHB5被广泛采用,因此AHB5进一步澄清了AHB-Lite协议的属性。
(1)多个从设备选择用于面积效率。
(2)单复制和多复制原子性,使能扩展到多核。
(3)用户信号允许用户扩展,并与AMBA 4 AXI规范保持一致。
目前,AHB5规范可供ARM的合作伙伴下载,旨在为包括实时和物联网核嵌入式微控制器设计在内的应用构建下一代SoC。
5.DTI
DTI(Distributed Translation Interface,分布式转换接口)协议规范与Arm System MMU架构对齐,为转换服务定义可扩展的分布式消息传递协议。在SMMU实现中,通常有以下3个组件。
(1)执行转换表搜索操作的转换控制单元(Translation Control Unit,TCU)。
(2)转换缓冲单元(Translation Buffer Unit,TBU),用于拦截需要转换的交易,并且缓存这些交易,以降低交易延迟。
(3)PCI Express(PCIe)根联合体,包括地址转换服务(Address Translation Service,ATS)。
DTI是一种点对点协议,其中每个通道都由链路、DTI主设备和DTI从设备构成。该规范概述了DTI主设备和DTI从设备之间两种不同的协议。
(1)DTI-TBU:定义了TBU主设备和TCU从设备之间的通信。
(2)DTI-ATS:定义了PCIe根联合体和TCU从设备之间的通信。
6.通用闪存总线
通过在系统和Flash之间提供简单的接口,通用闪存总线(Generic Flash Bus,GFB)简化了在子系统中集成嵌入式Flash控制器。GFB存在于Flash控制器主端和从端之间的边界上。主端有一个通用的Flash控制器,它具有大多数eFlash宏支持的通用功能。
从端具有与处理相关的Flash宏,用于特定的实现。GFB用作访问Flash存储器资源的数据路径,通过其他接口处理控制相关访问。这有利于重用带有不同处理的通用功能。