
下载掌阅APP,畅读海量书库
立即打开



作为数据湖的核心架构,Lambda架构主要是提供一种通用的数据湖搭建模式,即利用该模式可以实现历史数据以及实时数据的应用需求。Lambda架构按照不同的应用场景分配到不同的模块(层级)中。
Tips 为什么叫作Lambda架构,据说λ这个字母有三个突出的地方,从上到下,从左到右分别代表着批量、服务以及快速。
Nathan Marz在“Big Data:Principles and best practice of scalable realtime data systems”一书中阐述了Lambda架构的三个基本原则,分别是:
1)容错原则,在Lambda架构中系统的稳定性不受硬件、软件以及人为操作的影响。
2)不可变数据原则,数据应该是按照源系统的原始数据格式进行存储,并且这些数据是不可被改变的。
3)重新计算原则,数据始终存储在数据湖中并且始终处于可以访问的状态,系统可以通过对原始数据进行重新计算以满足新的需求。
接下来我们再深入了解下Lambda架构分层的原理以及它是如何与上述三个原则契合的。
Lambda架构是基于Hadoop构建而成的,Hadoop本身提供分布式计算以及存储的能力,使得Lambda架构自身天然就携带容错能力,即无论是数据错误还是硬件异常等导致的系统异常,系统可以重新计算全部的数据来获得休整之后的结果。Hadoop的这种特性使Lambda架构满足上述提到的容错原则以及重新计算原则。
这些支持重新计算的数据是如何来的呢?按照数据湖设计的思想,需按照数据的原始格式存储到数据湖中。为此各个源系统数据都按照原始格式被数据湖进行集中化管理,这些数据就是支持重新计算原则的基础数据。这种数据存储的形式也构成了数据湖的不可变数据原则。
总的来看,Lambda架构的核心模块主要包括离线处理层、实时计算层以及服务层。服务层基于应用的场景,按照数据需求整合批处理以及实时计算层里面的数据,然后提供对外的数据服务。Lambda架构核心模块如图5-6所示。
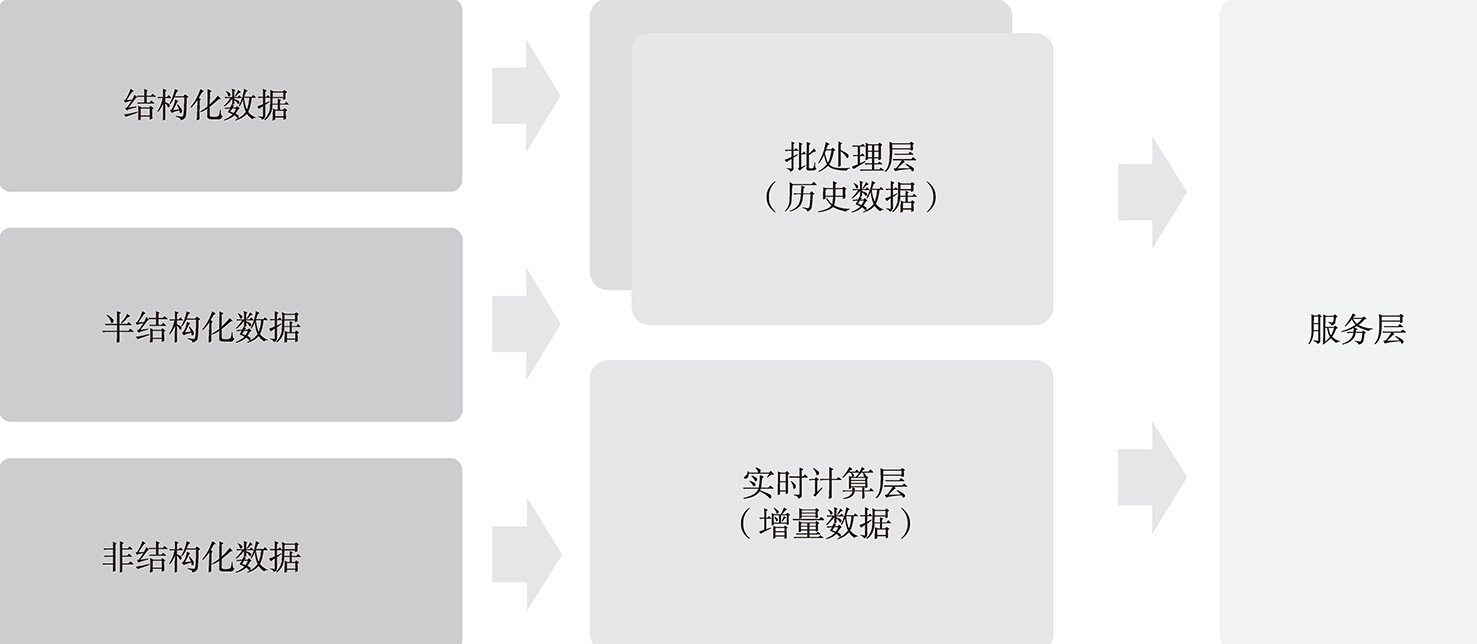
图5-6 Lambda架构核心模块
从业务层面来看,批处理层的主要作用与传统的数据仓库或者大数据架构的数据仓库的数据模型并没有本质的区别。它主要是利用数据仓库中的分层思想,对数据进行持久化存储;之后利用批处理的引擎进行数据计算(基于MapReduce的ETL作业)并将数据存入指定的数据模型中,由数据模型按照指定的业务逻辑生成最终的业务数据供后续的服务层使用。
例如某零售品牌旗下有近100个小程序并已经进行数据埋点,业务人员想通过某些指标来了解小程序的运营情况。例如,每个小程序每天的访问量、用户每日平均访问次数、电商小程序的页面的转换率(被查看的商品用户数与最终购买用户数比值)等。
在批处理层,数据流首先会被持久化地保存到批处理数据仓库中,积累一段时间后,再使用批处理引擎来进行计算。这个时间可以是一小时、一天,也可以是一个月。处理结果最后会导入一个可供应用系统在线查询的数据库上。批处理层中的批处理数据仓库可以是HDFS、Amazon S3或其他数据仓库,批处理引擎可以是MapReduce或Spark。
假如电商平台的数据分析部门想查看全网某天哪些商品的购买次数最多,可以使用批处理引擎对该天数据进行计算。如果用户行为日志数据量非常大,那么在日志上进行一个非常简单的计算可能就需要几个小时。批处理引擎一般会定时启动,对前一天或前几个小时的数据进行处理,并将结果输出到一个数据库中。与用户行为日志动辄几个小时的处理时间相比,直接查询一个在线数据库只需要几毫秒。这里计算购买次数最多商品的例子相对简单,在实际的业务场景中,一般需要做更复杂的统计分析和机器学习计算,耗时相对较长,比如构建用户画像时,根据用户年龄和性别等基础信息分析某类用户最有可能购买哪类商品。
批处理层能保证数据结果的准确性,而且即使程序失败,直接重启即可。此外,批处理引擎的扩展性一般比较好,即使数据量增多,也可以通过增加节点数量来横向扩展。
很明显,假如整个系统只有一个批处理层,会导致用户必须等待很久才能获取计算结果,一般有几个小时的延迟;电商数据分析部门只能查看前一天的统计分析结果,无法获取当前的结果,这对于实时决策来说有一个巨大的时间鸿沟,很可能导致管理者错过最佳决策时间。因此,在批处理层的基础上,Lambda架构增加了一个流处理层,用户行为日志会同时流入流处理层,由流处理引擎生成预处理结果,并导入一个数据库中。这样分析人员就可以查看前一个小时或前几分钟的数据结果,大大增加了整个系统的实时性。但数据流存在时间乱序等问题,使用早期的流处理引擎,只能得到一个近似准确的计算结果,相当于牺牲了一定的准确性来换取实时性。
由于流处理引擎有一些缺点,在准确性、扩展性和容错性上无法直接取代批处理层,只能给用户提供一个近似结果,并不能提供一个一致、准确的结果。因此Lambda架构中出现了批处理和流处理并存的现象。
在线服务层直接面向用户的特定请求,需要将来自批处理层的准确但有延迟的预处理结果和来自流处理层的实时但不够准确的预处理结果做融合。在融合过程中,需要不断将批处理层的数据覆盖流处理层生成的较老的数据。很多数据分析工具在数据融合上下了不少功夫,如Apache Druid。也可以用延迟极低的数据库存储来自批处理层和流处理层的预处理结果,在应用程序中人为对预处理结果进行融合。存储预处理结果的数据库可能是关系型数据库MySQL,也可能是键值(Key-Value)数据库Redis或HBase。
Lambda架构主要分为批处理层以及实时计算层,从技术层面来看,它采用的应用组件也需要满足批处理层以及实时计算层的需求。本节不会深入组件的技术细节进行介绍,而是主要介绍涉及的技术组件。图5-7展示了一种典型的Lambda架构应用层级,主要由5个层级构成,分别是数据获取层、消息层、数据摄取层、批处理层以及实时计算层。其中属于批处理的是数据获取层、批处理层;属于实时计算的主要是消息层、数据摄取层以及实时计算层。
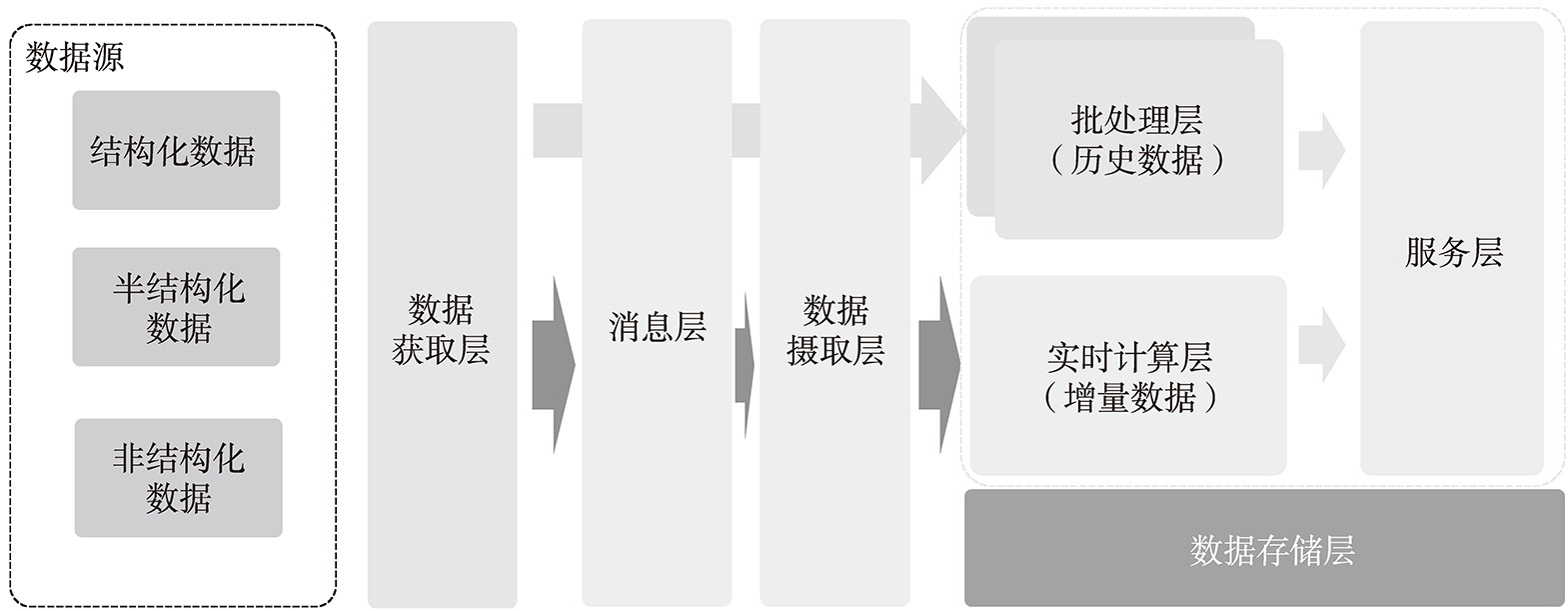
图5-7 Lambda架构应用层级
在上面的内容中我们提到,数据湖需要支持结构化数据、半结构化数据以及非结构化数据等的集中化存储,即数据存储层,之前提到Lambda架构是基于大数据架构的,所以Lambda架构的数据存储层主要是基于Hadoop架构进行数据存储,即HDFS。
批处理主要是针对离线的数据场景,它主要是利用技术组件将结构化数据、半结构数据或者非结构化数据抽取到数据存储中,并利用数据调度等ETL技术完成历史数据的批处理工作。Lamda批处理的主要层级如图5-8所示。
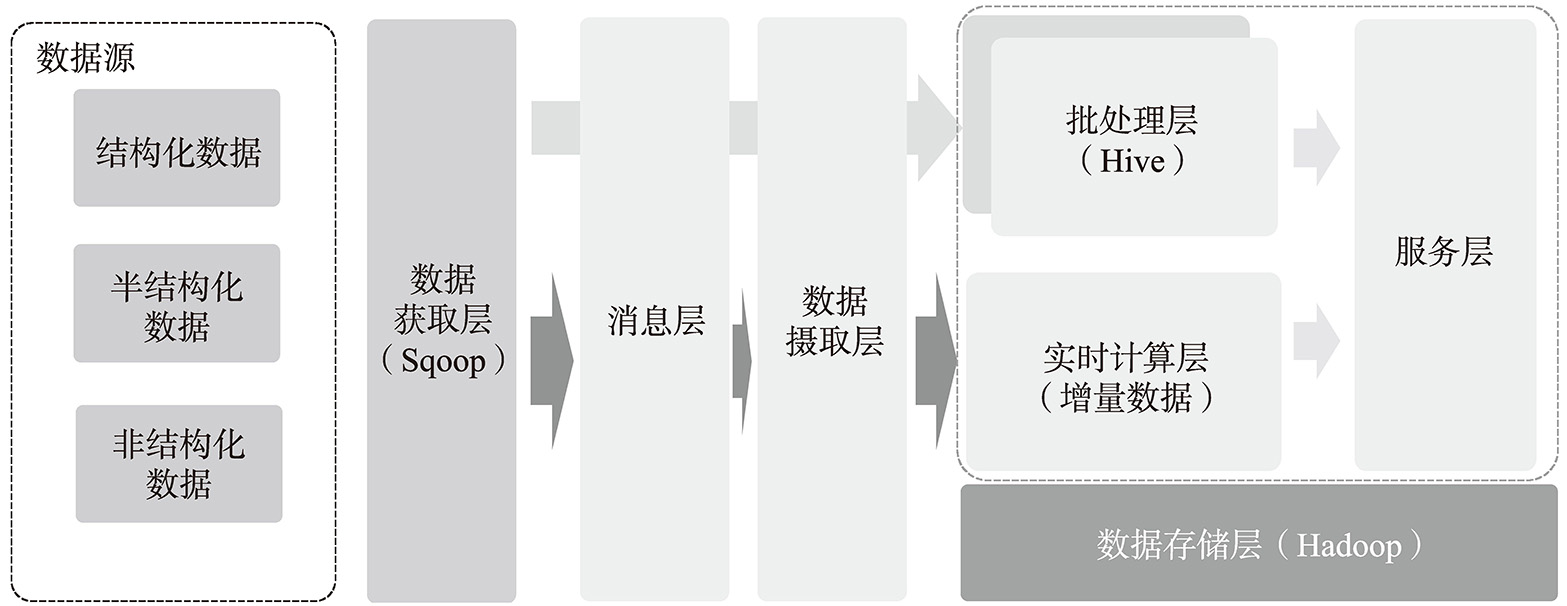
图5-8 Lambda批处理的主要层级
在批处理层中,数据获取层主要是将关系型数据库中的海量数据同步到数据存储层中,Apache Sqoop一般作为主要的技术框架,主要用于关系型数据库、传统数据仓库、NoSQL与Hadoop之间的传输数据。它可以让不同的数据库轻松地与Hadoop生态系统继承在一起,包括但不限于Apache Oozie、Apache Hbase、Apache Hive等。
由于Sqoop无法直接对半结构化数据以及非结构数据进行数据处理,因此,系统开发人员会使用MapReduce对这类数据进行处理,将文件进行格式化处理后,存储到Hadoop体系中进行数据运算。
在批处理层中,数据是按照聚合程度(或建模)分层存储的,Apache Hive作为数据存储的技术框架,负责存储批处理过程中的数据结果。Hive利用Hadoop底层的分布式计算框架,可处理大量数据的预计算结果。可以通过处理所有的历史数据(利用Sqoop 或 MapReduce等方式汇集而来)来实现数据的准确性。
由于Apache Hive利用Hadoop的计算框架,因此基于它的实时查询性能较低,往往在实际使用过程中,会将它产生的最终计算结果通过特定的方式同步到关系型数据库或者缓存中以支持数据的实时查询。
Tips 基于Apache Hive的数据建模方法论与传统的数据仓库并没有本质的区别。
实时计算主要针对实时或者低延迟等场景,主要是基于流式数据进行计算,故相关技术组件需要满足低延迟、高并发、可扩展以及可靠性等特点以保证数据可以准确、及时地被处理。在Lambda架构中,实时计算的主要层级如图5-9所示。
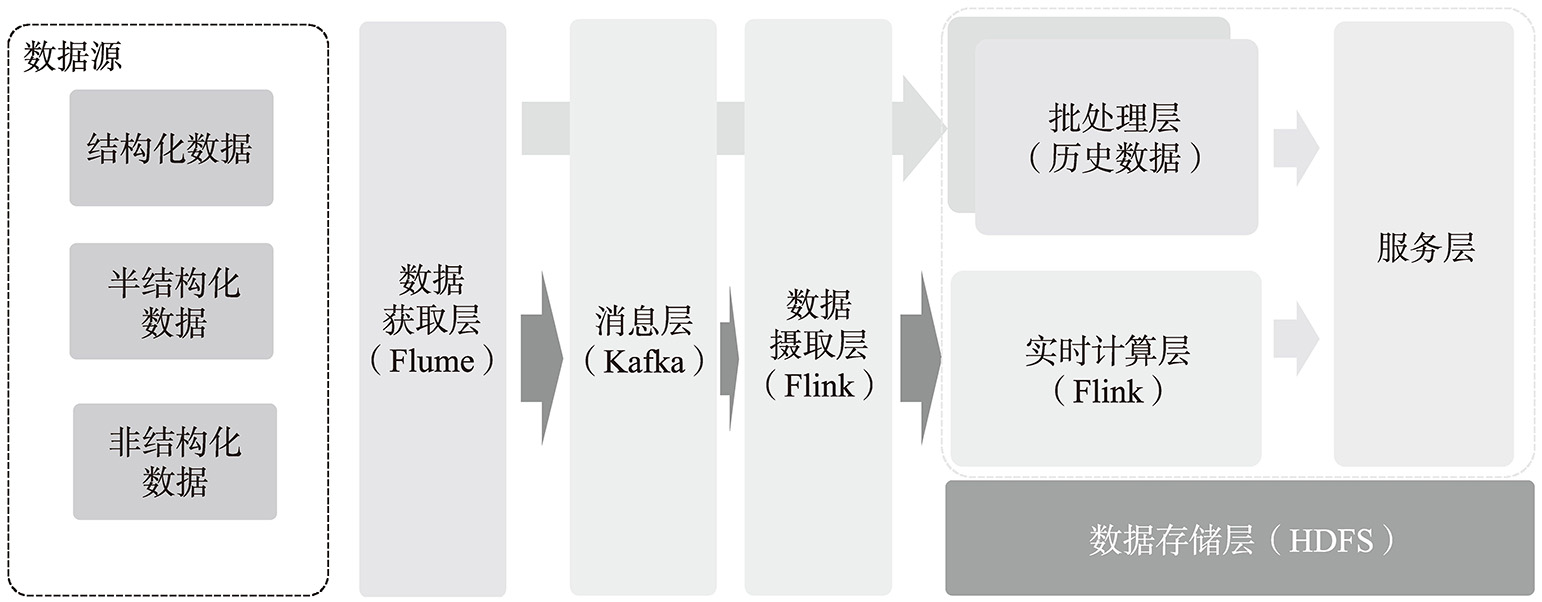
图5-9 Lambda实时计算的主要层级
在实时计算中,需要实时或者低延迟地从数据源将数据发送到Hadoop系统中,以便进行后续的分析,利用Apache Flume这一实时组件可以从各种数据源收集和聚合日志数据写入Hadoop中。后续Flume经过重构,能够兼容不同的数据源以及数据目的地的存储类型,同时在设计的过程中考虑可插拔性以及可扩展性。
Tips Apache Flume主要分为OG 以及NG这2个版本,前者代表Old Generation,主要是指1.0之前的版本;NG代表New Generation,代表后续的版本。
Apache Kafka在第4章已经进行了较为详细的介绍,在实时计算中Kafka作为消息中间件,实现应用与数据解耦的目的。同时Apache Flume中获取的流式数据会以生产者的角色将数据写入消息队列中。基于消息中间件(Kafka),数据流进入数据摄取层。数据摄取层进行多目标分发:一条直接写入Hadoop中,存储到数据存储层;一条在数据摄取层进行必要的计算(聚合)生成特定的业务数据。
在实时计算场景中,数据摄取层需要消费消息层传递过来的消息完成所需要的数据转换或者聚合等操作(类比实时的ETL),并将从消息中获取需要的数据后传递到Lambda层中(批处理层或者实时计算层),所以数据摄取层所生成的数据格式需要能够无缝地与下游进行对接,同时保证数据消费的速率以避免由于数据消费积压而产生延迟的可能性。
Apache Flink作为一款开源分布式流式处理框架,能够满足各类应用的高吞吐、高可用、精准的数据处理要求。它支持精准的一次性处理,且对于延迟抵达的数据或者乱序的数据仍然能够提供精准的处理结果,因此是构建Lambda架构中数据摄取层的优先选项。
而Apache Spark是以微批量方式处理数据。微批量方式在处理实时数据时会存在瓶颈,带来一定的延迟。所以在对实时计算要求较高的场景中,建议采用Apache Flink而非Apache Spark。
在介绍完Lambda架构中主要的层级以及相关的技术选型后,我们将讨论Lambda架构中数据流向的特点。前文图5-9所示的架构图很容易让我们产生数据是从一个层级流入下一个层级并应用的错觉。实际上整个Lambda架构的数据流是异常复杂的。我们举一个简单的场景,针对最近一周消费次数超过3次且最近1小时登录网站超过5次的用户实时推送优惠券。
这里涉及两个方面的数据:第一个方面是最近一周消费次数超过3次。这部分是利用Sqoop从订单系统抽取数据到数据获取层,然后按照周聚合之后得到对应的用户群体;第二个方面是订单数据实时抽取(Apache Flume)到Kafka中,然后接入Apache Flink中进行计算。但是数据摄取层的计算往往并不是按照小时的时间窗口,在具体的应用场景中,数据粒度可能是分钟(即按照分钟对用户进行聚合)。假设这里按照5min的粒度进行聚合,那么每5min就会有一个数据切片存储到数据存储层中。
假设此时有另外一个场景,为最近5min登录次数超过10次的用户发送另外一种优惠信息。这里就会涉及数据复用的场景,对于数据摄取层来说,不可能每次都从数据存储层加载数据,那么就会重新写入消息层中供后续其他应用进行消费。为此Lambda中的数据流如图5-10所示。
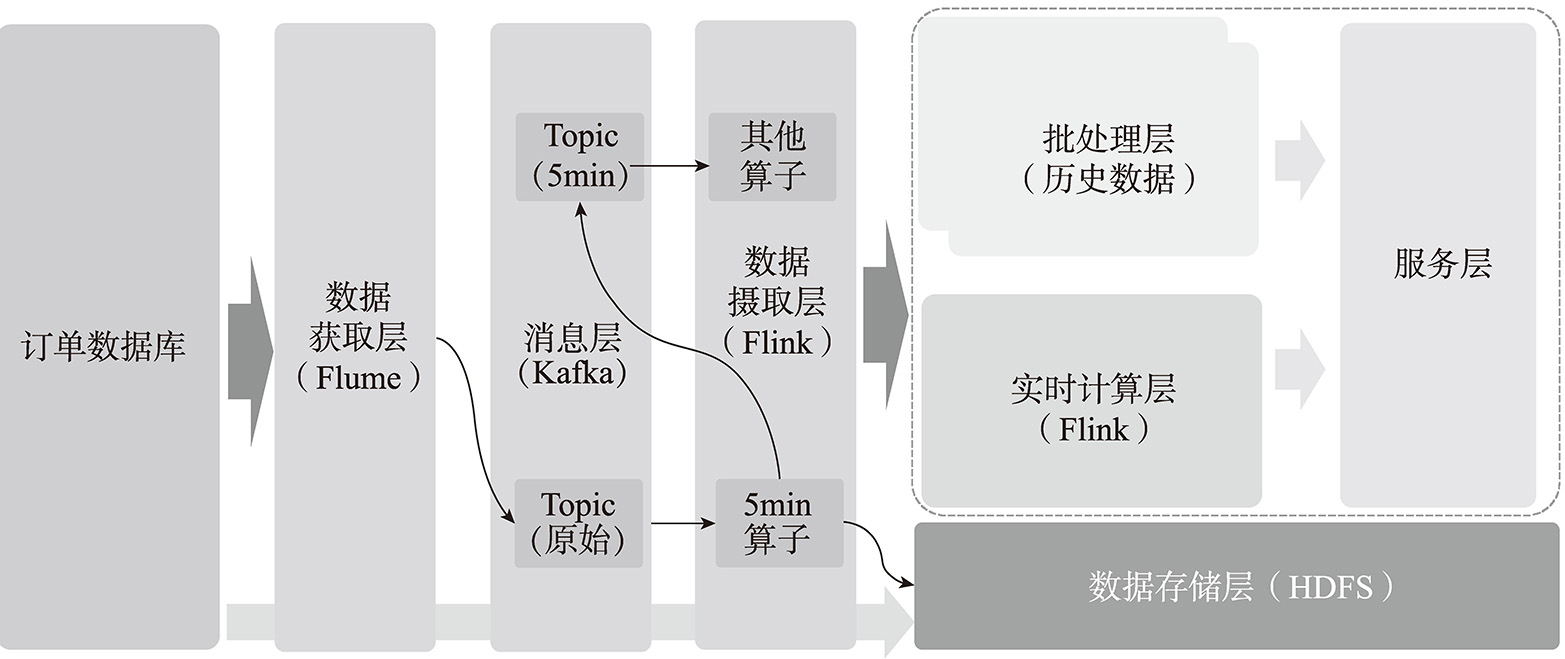
图5-10 Lambda中的数据流
在Lambda体系中关于数据的复用涉及消息层以及数据存储层的规划,这部分需要根据实际情况进行设计以保证整体数据流的可维护性。