
下载掌阅APP,畅读海量书库
立即打开



DataX 是阿里开源的一个异构数据源离线同步工具,是阿里巴巴集团内广泛使用的离线数据同步工具/平台。DataX实现了包括 MySQL、Oracle、SQLServer、PostgreSQL、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
任何一款数据同步工具都主要分为两个部分:数据抽取和数据同步。也就是说,连接源系统按照某种规则抽取数据,并暂时性地存储到数据缓冲区中,之后通过网络将数据同步到指定的目标源。为了提高整体数据抽取的效率,一般抽取工具都会提供并发的配置(抽取或者同步时)。
DataX作为一款异构数据源的同步工具,满足多种类型的数据库类型同步,同时可以灵活调整以满足数据类型的扩展以及抽取作业的配置的需求。
在数据抽取的任务中,主要存在如下3个概念,分别是作业(Job)、任务(Task)以及任务组(Task Group)。
1)作业,是DataX的一个数据同步作业,即一个数据源某个具体的数据表同步到目标源则称为一个作业。例如将MySQL中的某数据表同步到Hive中则称为一个作业。
2)任务,是DataX的最小可执行单位,即一个数据同步作业按照拆分策略可以拆分成多个任务,提高数据同步的并发能力,进而提高数据同步的效率。
3)任务组,是将任务按照一定规则组装起来,并按照一定并发数量统一执行其内部的任务,系统默认的并发数是5。
Tips 这样设计的原因是任务的粒度太细、并发高,但是后台进程管理成本较高,而作业的粒度较粗、并发较低,后台管理成本较低。故通过任务组进行折中。
当某一个作业执行时,DataX内部存在监控对应的任务组执行状态的进程,当所有的任务组任务执行完成后,作业成功退出。DataX官方提供的不同组件之间的关系图如图4-5所示。
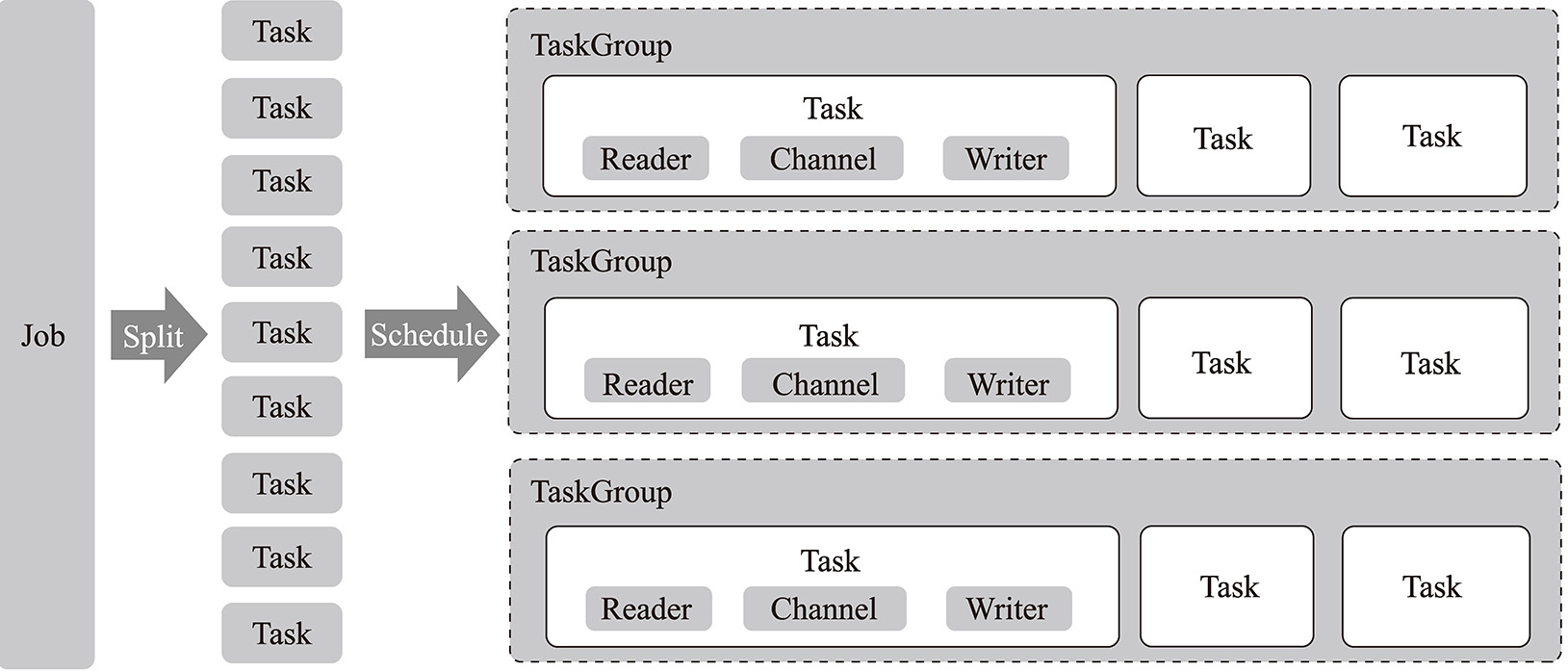
图4-5 DataX组件关系图
介绍完DataX的基础概念之后,我们来看一下DataX是如何进行数据同步的。
DataX作为离线数据同步框架,采用Framework+Plugin架构构建。它将数据源读取和写入抽象为读/写插件,纳入整个同步框架中。而Framework负责管理读插件与写插件之间的通信渠道(Channel)。
读插件为数据采集模块,负责采集数据源的数据,将数据发送给Framework;写插件为数据写入模块,负责不断从Framework(通信渠道)取数据,并将数据写入目的端;Framework用于连接读插件和写插件,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
这三者之间的关系如图4-6表示。

图4-6 读插件、写插件以及Framework的关系
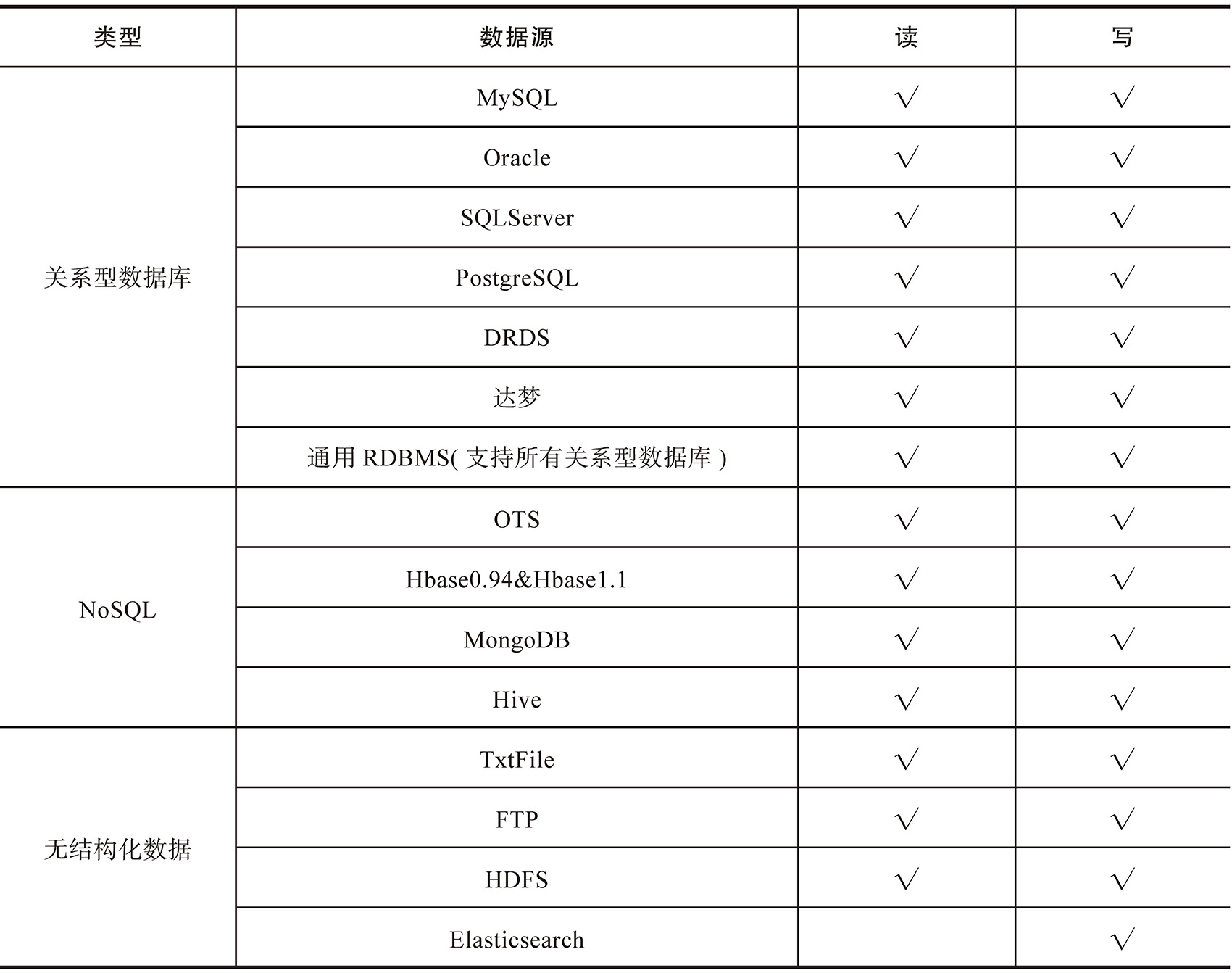
基于这样的设计,通过拓展读插件或者写插件就可以实现不同数据源的数据同步。截至最新的DataX3.0 版本,DataX已经支持主流的关系型数据库的读写,例如MySQL、PostgreSQL、Oracle等,同时支持HBase等NoSQL以及TxtFile等无结构化数据,如表4-2所示。
表4-2 DataX支持的主要数据源展示
此外,基于这种插件式的配置,DataX从逻辑上将不同类型的数据源进行解耦,将复杂的、网状的同步链路变成星型数据链路,DataX则作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步,如图4-7所示。
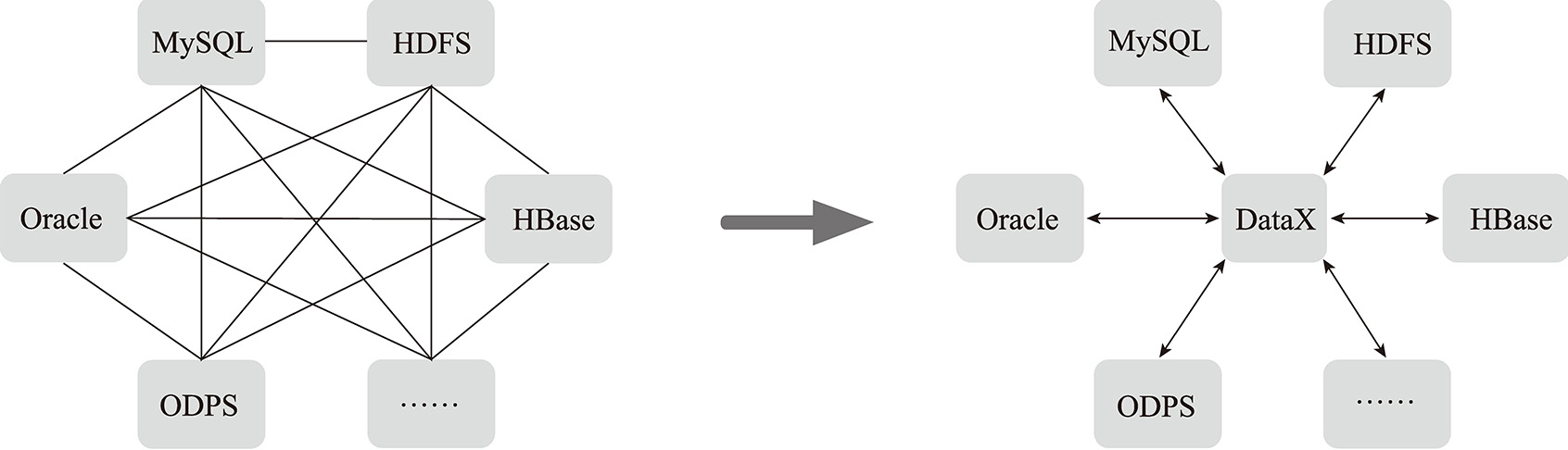
图4-7 基于DataX的数据传输链路
在数据传输过程中很容易出现某个任务执行失败的场景,DataX内部提供了线程级别的重试机制,可针对失败的任务进行重试。
然而DataX本身并没有提供分布式部署的功能,如果想实现DataX的分布式抽取的功能,需要利用第三方组件,例如HAProxy。
通过上面内容的介绍,我们了解到一个作业是通过读插件抽取源系统数据,缓存到内存中,再通过通信渠道,并利用写插件完成数据向目标端的写入。在这个过程中涉及如下几个因素:
1)源端可以承受的并发上限,以及源端与DataX所在的网络环境。
2)DataX配置的并发抽取的源端的性能以及DataX将抽取的数据同步到目标端的性能。
3)由于读插件与写插件之间的数据交换主要是通过通信渠道进行维护,那么通信渠道的并发度也是影响传输效率的因素。
在一个DataX作业同步中,上述几个组件之间的关系图如图4-8所示。
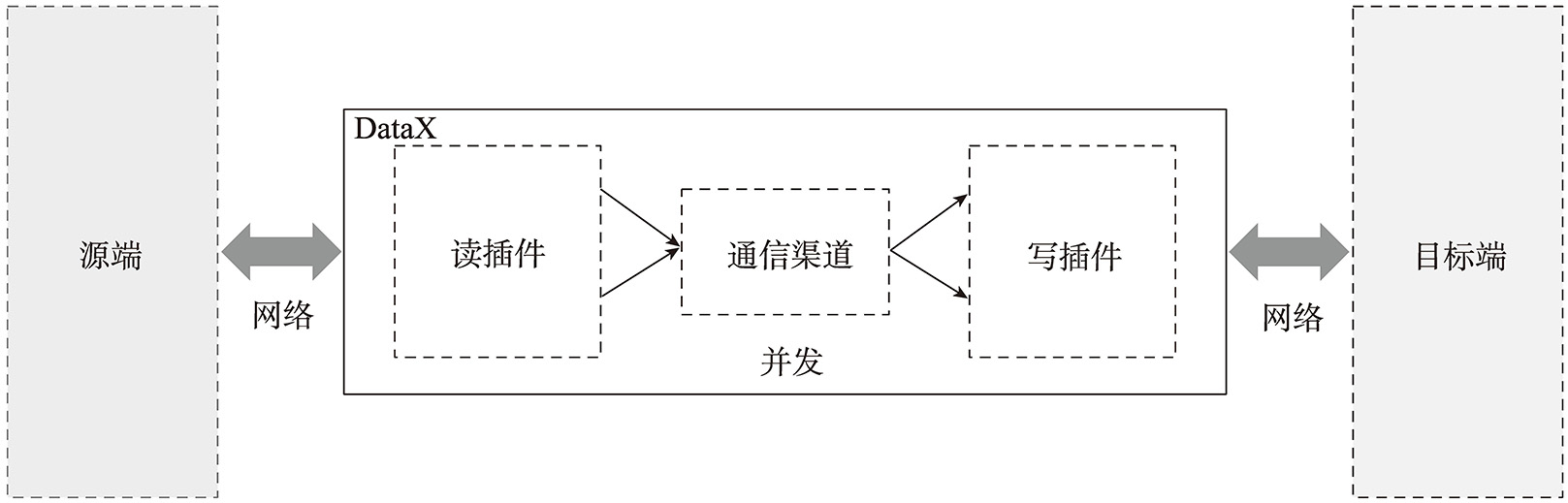
图4-8 DataX同步中组件的关系图
因此,优化DataX的策略是在源端以及目标端性能可以承受的基础上,尽量提高传输的效率以及DataX内部的并发度。
从网络层面来说,将源端、DataX 服务以及目标端放在同一个网络环境中,并且采用万兆网卡进行通信,将会提高数据传输的效率,减少数据传输的延迟。
从DataX内部来说,通信渠道作为读/写数据转换通道,可以从两个方面进行优化,一是提升每个通信渠道的传输速度,二是优化通信渠道的并发度。前者在配置文件中可以根据实际情况进行限制;后者通过配置全局限速(或Records)以及单通信渠道限速(或者Records)进行间接设置(全局限速/单通信渠道限速=通信渠道个数),同时也可以直接配置通信渠道个数,对应的具体参数如表4-3所示。
表4-3 DataX Channel配置关键参数
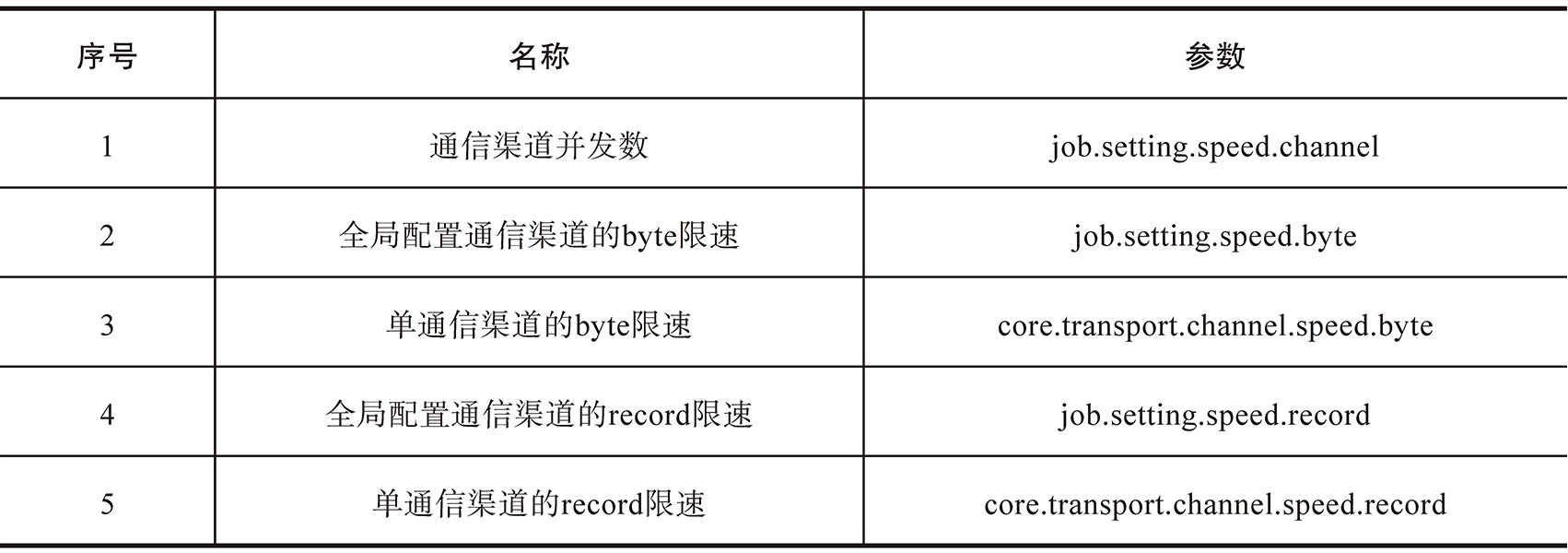
需要注意的是,如果Reader端的Channel并发数生效,那么Writer端的并发数默认就是Reader端的Channel的个数。
Tips 上面5个参数可以计算出来3个值,分别是BPS(Byte限速的比值),TPS(Record限速的比值)以及设置的Channel值,这三者的优先级为BPS与TPS大于设置的Channel值;如果BPS与TPS都设置则取二者中的最小值,如果任意设置一个则取该值;如果都未设置则取设置的Channel值。这里有一个前提就是该表需要配置splitPK且不为null。
此外并发数量增加意味着需要更多的内存空间,DataX是通过反射生成记录的实例,这会导致新生代内存开销增加以及触发GC,因此JVM中需要增加可用堆的内存以及新生代占比。
当然DataX的优化远不止这些,但是任何优化都是基于DataX本身架构的特点以及实际情况进行综合考虑的。
数据同步工具是任何数据平台都不可或缺的一个角色。DataX作为一款优秀的数据同步工具,提供了高性能的异构数据同步能力以及容错机制,但是从使用的友好度来看,它更多是一个后端运行的数据同步工具,且未提供较为友好的后台配置界面。截至目前,存在一个开源项目DataX-Web,它基于DataX提供界面配置功能,可以满足一定的作业及调度配置功能。
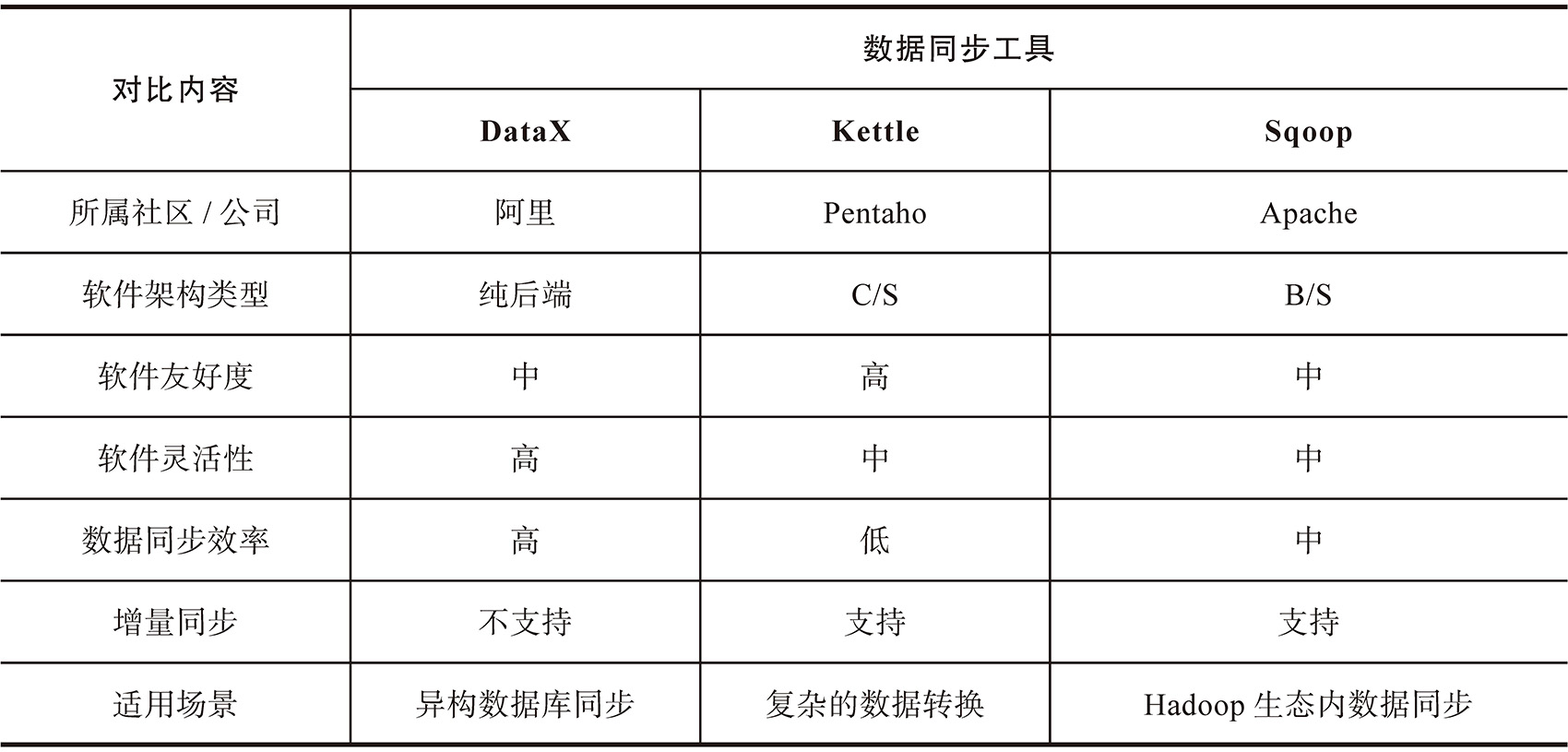
开源的数据同步工具较多,除DataX以外相对比较流行的工具还有Kettle(现被称为Pentaho Data Integration)以及Sqoop等。这三者在侧重点以及开发作业上有着较大的区别。
Kettle作为老牌的国外开源ETL工具,是用Java编写的,有着跨平台运行的能力。它采用C/S框架进行ETL作业的开发,即提供图形化的界面以及组件构建数据同步作业,当然它也提供较为简单的数据量同步的并发控制。
Sqoop主要是用于大数据生态与关系型数据库之间的同步工具,例如将Oracle数据同步到HDFS中、将Hive数据同步到MySQL中等。它还针对Hadoop相关组件的数据同步进行针对性的优化,提高此种场景下的数据同步能力。
针对上述工具的特点,下面主要从所属社区/公司、软件架构类型、软件友好度、软件灵活性、数据同步效率、增量同步以及适用场景等方面对工具进行对比,为数据工具选型提供参考。数据同步工具对比详情如表4-4所示。
表4-4 数据同步工具对比详情
无论是DataX还是上一节介绍的Airflow,这些组件都是离线场景下企业数据平台所需要的组件:前者提供数据同步能力,后者提供作业调度能力。然而随着企业应用的发展,企业对于实时场景的诉求逐步增加。对于实时计算场景,任何架构都无法绕开消息中间件,在接下来的章节中,我们将介绍一款高并发的消息中间件——Kafka,期望可以通过它让读者掌握高并发的原理。